 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Unpaired Deep Learning for Accelerated MRI using Optimal Transport Driven CycleGAN
Aug 29, 2020
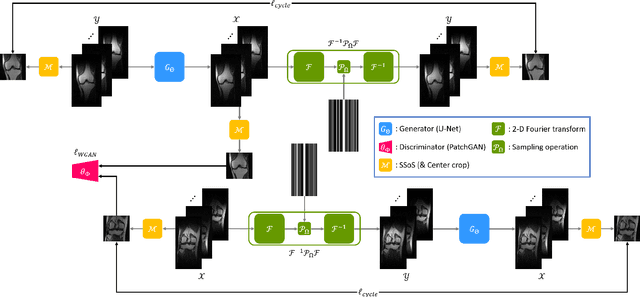

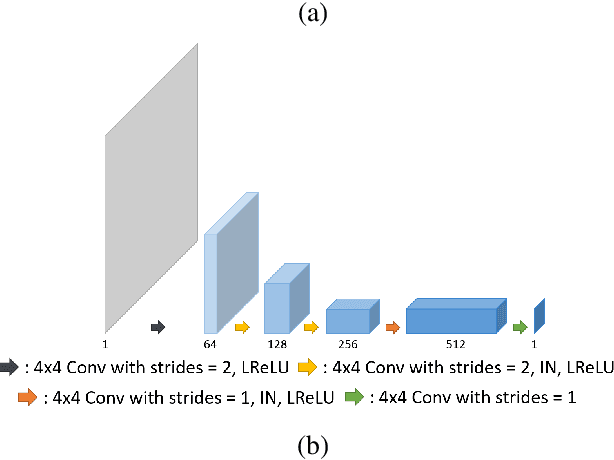

Recently, deep learning approaches for accelerated MRI have been extensively studied thanks to their high performance reconstruction in spite of significantly reduced runtime complexity. These neural networks are usually trained in a supervised manner, so matched pairs of subsampled and fully sampled k-space data are required. Unfortunately, it is often difficult to acquire matched fully sampled k-space data, since the acquisition of fully sampled k-space data requires long scan time and often leads to the change of the acquisition protocol. Therefore, unpaired deep learning without matched label data has become a very important research topic. In this paper, we propose an unpaired deep learning approach using a optimal transport driven cycle-consistent generative adversarial network (OT-cycleGAN) that employs a single pair of generator and discriminator. The proposed OT-cycleGAN architecture is rigorously derived from a dual formulation of the optimal transport formulation using a specially designed penalized least squares cost. The experimental results show that our method can reconstruct high resolution MR images from accelerated k- space data from both single and multiple coil acquisition, without requiring matched reference data.
Predicting Future Sales of Retail Products using Machine Learning
Aug 18, 2020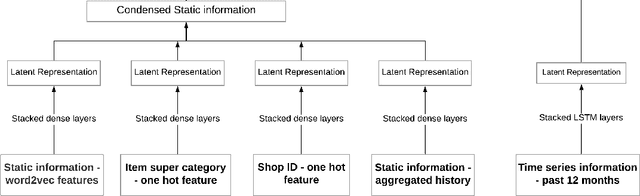
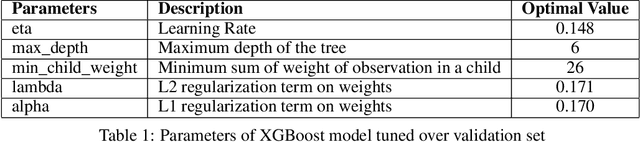
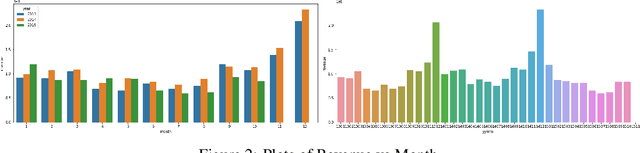
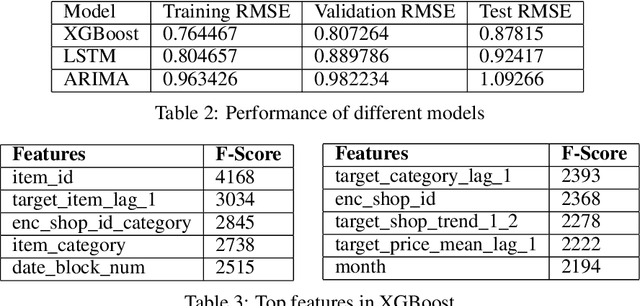
Techniques for making future predictions based upon the present and past data, has always been an area with direct application to various real life problems. We are discussing a similar problem in this paper. The problem statement is provided by Kaggle, which also serves as an ongoing competition on the Kaggle platform. In this project, we worked with a challenging time-series dataset consisting of daily sales data, kindly provided by one of the largest Russian software firms - 1C Company. The objective is to predict the total sales for every product and store in the next month given the past data. In order to perform forecasting for next month, we have deployed eXtreme Gradient Boosting (XGBoost) and Long Short Term Memory (LSTM) based network architecture to perform learning task. Root mean squared error (RMSE) between the actual and predicted target values is used to evaluate the performance, and make comparisons between the deployed algorithms. It has been found that XGBoost fared better than LSTM over this dataset which can be attributed to its relatively higher sparsity.
An Empirical Study on Large-Scale Multi-Label Text Classification Including Few and Zero-Shot Labels
Oct 04, 2020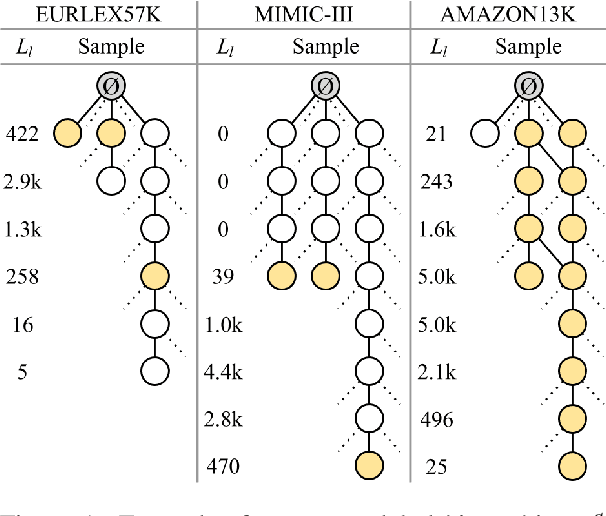
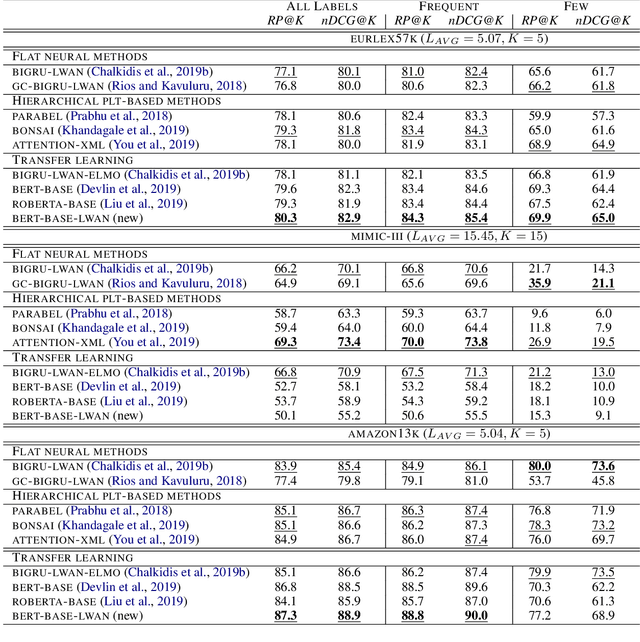
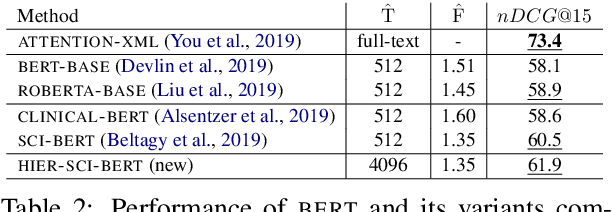
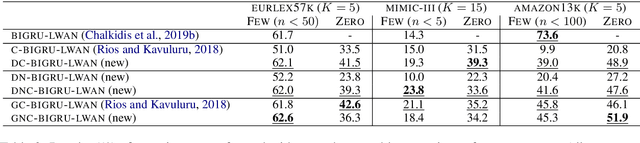
Large-scale Multi-label Text Classification (LMTC) has a wide range of Natural Language Processing (NLP) applications and presents interesting challenges. First, not all labels are well represented in the training set, due to the very large label set and the skewed label distributions of LMTC datasets. Also, label hierarchies and differences in human labelling guidelines may affect graph-aware annotation proximity. Finally, the label hierarchies are periodically updated, requiring LMTC models capable of zero-shot generalization. Current state-of-the-art LMTC models employ Label-Wise Attention Networks (LWANs), which (1) typically treat LMTC as flat multi-label classification; (2) may use the label hierarchy to improve zero-shot learning, although this practice is vastly understudied; and (3) have not been combined with pre-trained Transformers (e.g. BERT), which have led to state-of-the-art results in several NLP benchmarks. Here, for the first time, we empirically evaluate a battery of LMTC methods from vanilla LWANs to hierarchical classification approaches and transfer learning, on frequent, few, and zero-shot learning on three datasets from different domains. We show that hierarchical methods based on Probabilistic Label Trees (PLTs) outperform LWANs. Furthermore, we show that Transformer-based approaches outperform the state-of-the-art in two of the datasets, and we propose a new state-of-the-art method which combines BERT with LWANs. Finally, we propose new models that leverage the label hierarchy to improve few and zero-shot learning, considering on each dataset a graph-aware annotation proximity measure that we introduce.
CONDA-PM -- A Systematic Review and Framework for Concept Drift Analysis in Process Mining
Sep 08, 2020
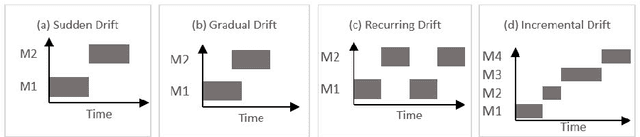
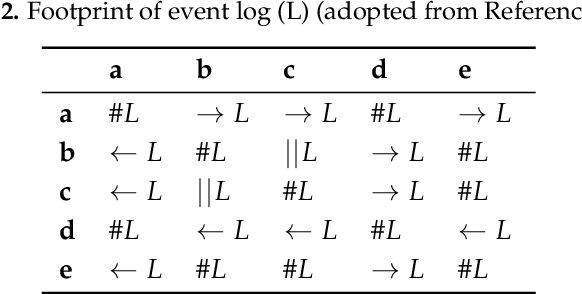
Business processes evolve over time to adapt to changing business environments. This requires continuous monitoring of business processes to gain insights into whether they conform to the intended design or deviate from it. The situation when a business process changes while being analysed is denoted as Concept Drift. Its analysis is concerned with studying how a business process changes, in terms of detecting and localising changes and studying the effects of the latter. Concept drift analysis is crucial to enable early detection and management of changes, that is, whether to promote a change to become part of an improved process, or to reject the change and make decisions to mitigate its effects. Despite its importance, there exists no comprehensive framework for analysing concept drift types, affected process perspectives, and granularity levels of a business process. This article proposes the CONcept Drift Analysis in Process Mining (CONDA-PM) framework describing phases and requirements of a concept drift analysis approach. CONDA-PM was derived from a Systematic Literature Review (SLR) of current approaches analysing concept drift. We apply the CONDA-PM framework on current approaches to concept drift analysis and evaluate their maturity. Applying CONDA-PM framework highlights areas where research is needed to complement existing efforts.
* 45 pages, 11 tables, 13 figures
Algorithm Based on One Monocular Video Delivers Highly Valid and Reliable Gait Parameters
Sep 08, 2020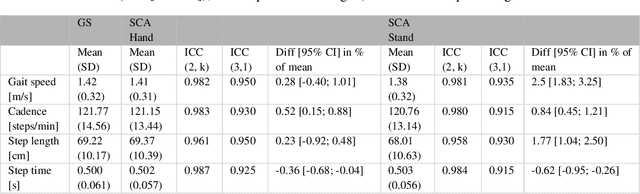
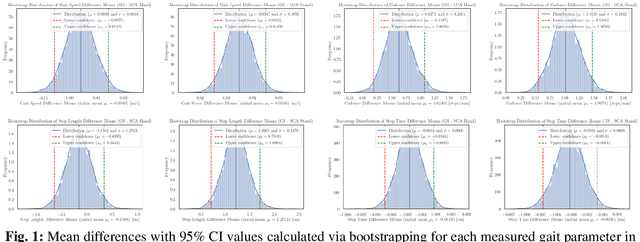
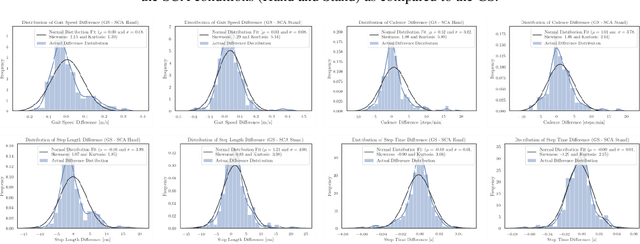
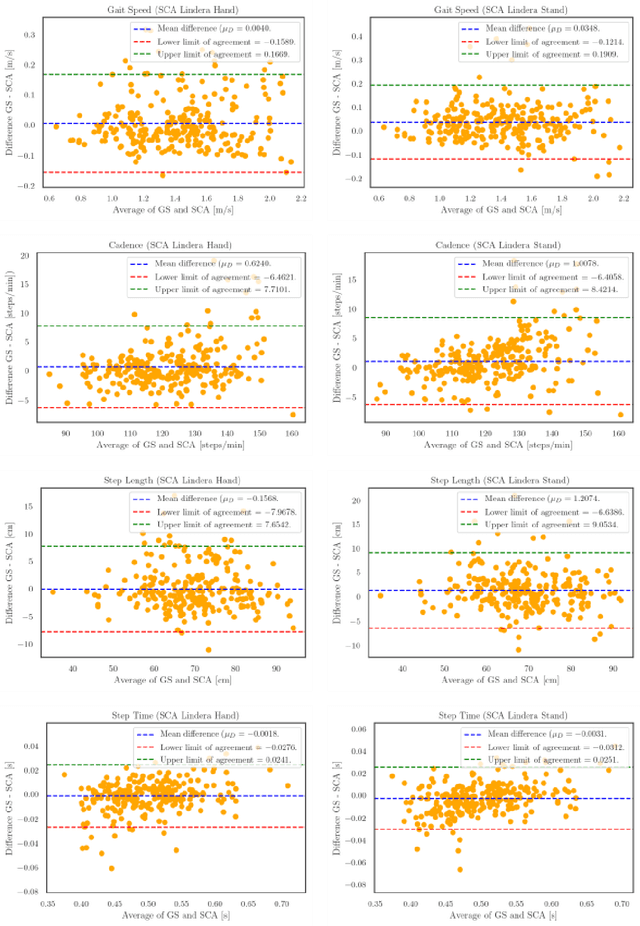
Despite its paramount importance for manifold use cases (e.g., in the health care industry, sports, rehabilitation and fitness assessment), sufficiently valid and reliable gait parameter measurement is still limited to high-tech gait laboratories in large clinics. Here, we demonstrate the excellent validity and test-retest repeatability of a novel gait assessment system which is built upon modern convolutional neuronal networks to extract three-dimensional skeleton joints from monocular frontal-view videos of walking humans. The validity study is based on a comparison to the GAITRite pressure-sensitive walkway system. All measured gait parameters (gait speed, cadence, step length and step time) showed excellent concurrent validity for multiple walk trials at normal and fast gait speeds. The test-retest-repeatability is on the same level as the GAITRite system. In conclusion, we are convinced that our results can pave the way for cost, space and operationally effective gait analysis in broad mainstream applications. Most sensor-based systems are costly, must be operated by extensively trained personnel (e.g., motion capture systems) or - even if not quite as costly - still possess considerable complexity (e.g. wearable sensors). In contrast, a video sufficient for the assessment method presented here can be obtained by anyone, without much training, via a smartphone camera.
The Scattering Compositional Learner: Discovering Objects, Attributes, Relationships in Analogical Reasoning
Jul 08, 2020
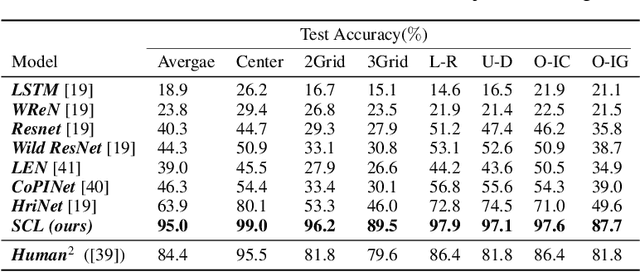
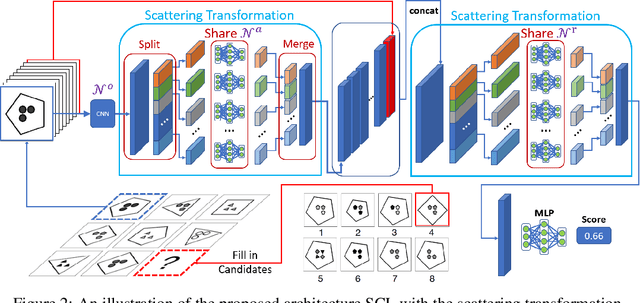
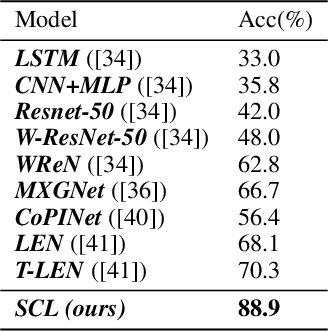
In this work, we focus on an analogical reasoning task that contains rich compositional structures, Raven's Progressive Matrices (RPM). To discover compositional structures of the data, we propose the Scattering Compositional Learner (SCL), an architecture that composes neural networks in a sequence. Our SCL achieves state-of-the-art performance on two RPM datasets, with a 48.7% relative improvement on Balanced-RAVEN and 26.4% on PGM over the previous state-of-the-art. We additionally show that our model discovers compositional representations of objects' attributes (e.g., shape color, size), and their relationships (e.g., progression, union). We also find that the compositional representation makes the SCL significantly more robust to test-time domain shifts and greatly improves zero-shot generalization to previously unseen analogies.
Mining and modeling complex leadership-followership dynamics of movement data
Oct 04, 2020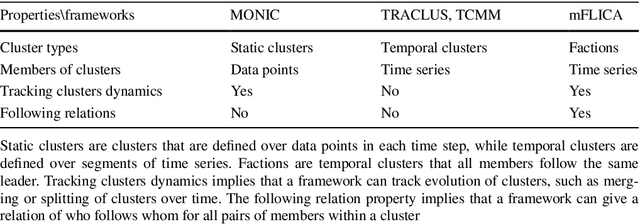
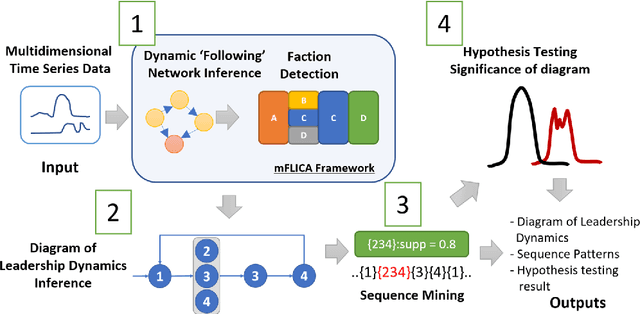

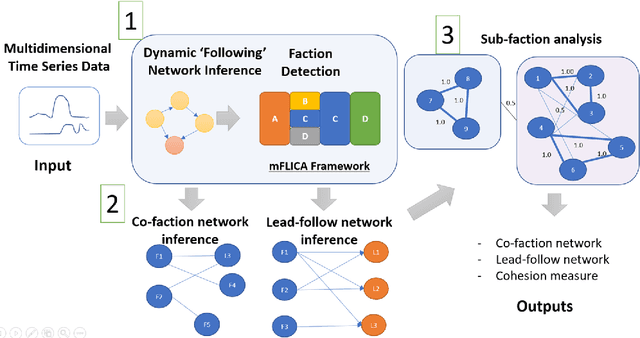
Leadership and followership are essential parts of collective decision and organization in social animals, including humans. In nature, relationships of leaders and followers are dynamic and vary with context or temporal factors. Understanding dynamics of leadership and followership, such as how leaders and followers change, emerge, or converge, allows scientists to gain more insight into group decision-making and collective behavior in general. However, given only data of individual activities, it is challenging to infer the dynamics of leaders and followers. In this paper, we focus on mining and modeling frequent patterns of leading and following. We formalize new computational problems and propose a framework that can be used to address several questions regarding group movement. We use the leadership inference framework, mFLICA, to infer the time series of leaders and their factions from movement datasets and then propose an approach to mine and model frequent patterns of both leadership and followership dynamics. We evaluate our framework performance by using several simulated datasets, as well as the real-world dataset of baboon movement to demonstrate the applications of our framework. These are novel computational problems and, to the best of our knowledge, there are no existing comparable methods to address them. Thus, we modify and extend an existing leadership inference framework to provide a non-trivial baseline for comparison. Our framework performs better than this baseline in all datasets. Our framework opens the opportunities for scientists to generate testable scientific hypotheses about the dynamics of leadership in movement data.
* This accepted manuscript is made publicly available 12 months after official publication, which is complied with the publisher policy. The final publication is available at link.springer.com
Protein Conformational States: A First Principles Bayesian Method
Aug 05, 2020
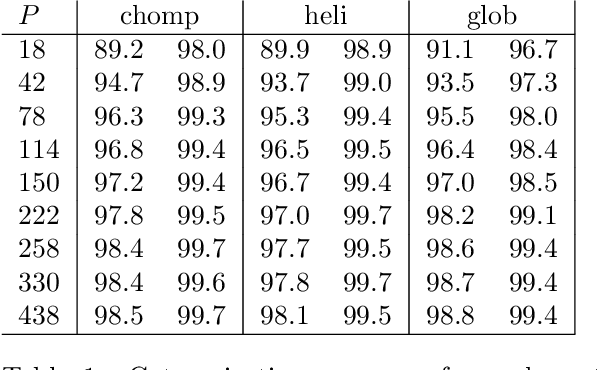
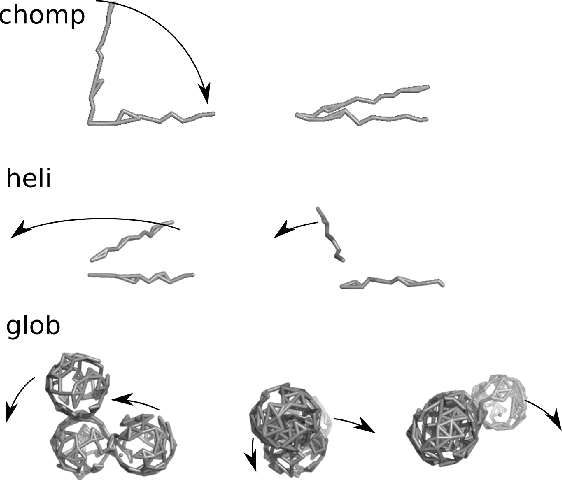
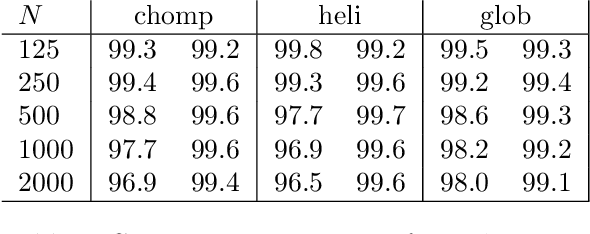
Automated identification of protein conformational states from simulation of an ensemble of structures is a hard problem because it requires teaching a computer to recognize shapes. We adapt the naive Bayes classifier from the machine learning community for use on atom-to-atom pairwise contacts. The result is an unsupervised learning algorithm that samples a `distribution' over potential classification schemes. We apply the classifier to a series of test structures and one real protein, showing that it identifies the conformational transition with > 95% accuracy in most cases. A nontrivial feature of our adaptation is a new connection to information entropy that allows us to vary the level of structural detail without spoiling the categorization. This is confirmed by comparing results as the number of atoms and time-samples are varied over 1.5 orders of magnitude. Further, the method's derivation from Bayesian analysis on the set of inter-atomic contacts makes it easy to understand and extend to more complex cases.
Lie Algebraic Unscented Kalman Filter for Pose Estimation
Apr 30, 2020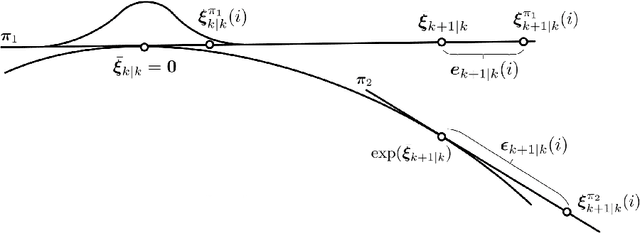
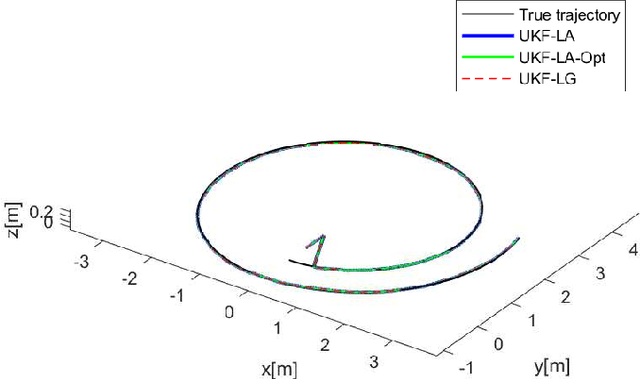
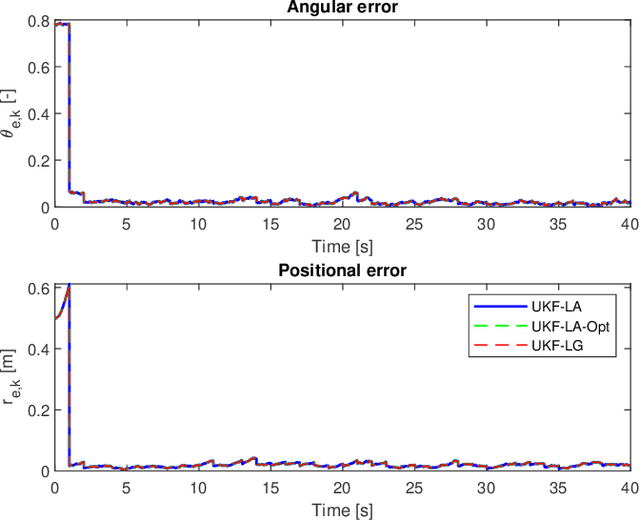
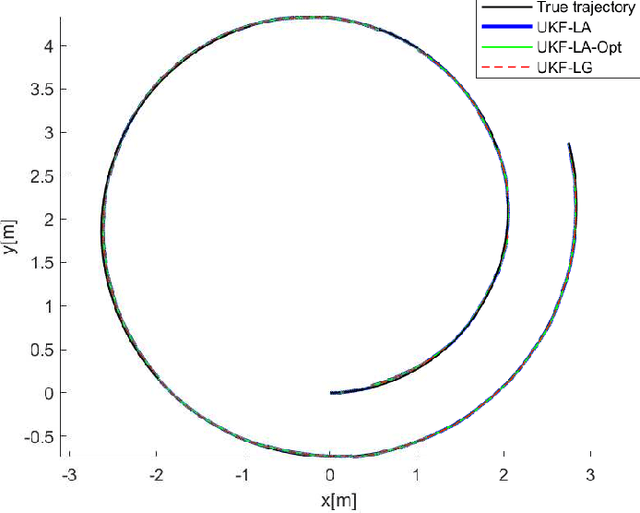
An unscented Kalman filter for matrix Lie groups is proposed where the time propagation of the state is formulated on the Lie algebra. This is done with the kinematic differential equation of the logarithm, where the inverse of the right Jacobian is used. The sigma points can then be expressed as logarithms in vector form, and time propagation of the sigma points and the computation of the mean and the covariance can be done on the Lie algebra. The resulting formulation is to a large extent based on logarithms in vector form, and is therefore closer to the UKF for systems in $\mathbb{R}^n$. This gives an elegant and well-structured formulation which provides additional insight into the problem, and which is computationally efficient. The proposed method is in particular formulated and investigated on the matrix Lie group $SE(3)$. A discussion on right and left Jacobians is included, and a novel closed form solution for the inverse of the right Jacobian on $SE(3)$ is derived, which gives a compact representation involving fewer matrix operations. The proposed method is validated in simulations.
Online Training of an Opto-Electronic Reservoir Computer Applied to Real-Time Channel Equalisation
Oct 20, 2016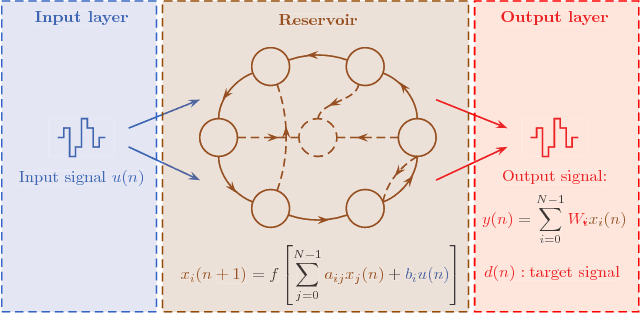
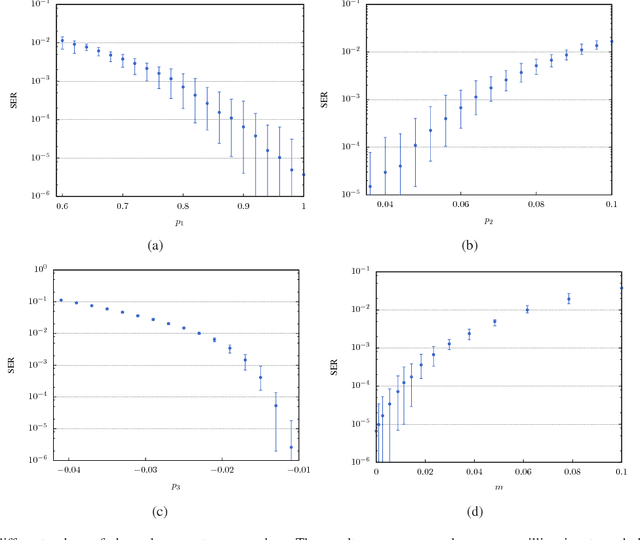
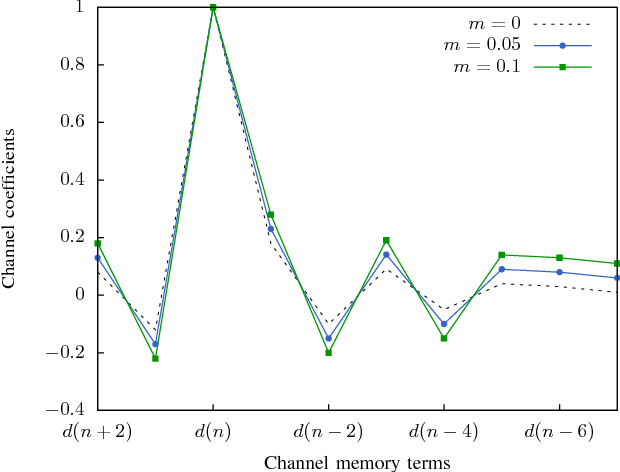
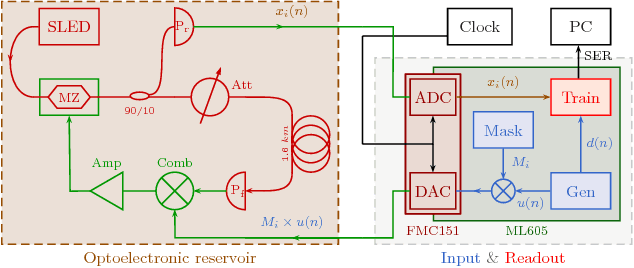
Reservoir Computing is a bio-inspired computing paradigm for processing time dependent signals. The performance of its analogue implementation are comparable to other state of the art algorithms for tasks such as speech recognition or chaotic time series prediction, but these are often constrained by the offline training methods commonly employed. Here we investigated the online learning approach by training an opto-electronic reservoir computer using a simple gradient descent algorithm, programmed on an FPGA chip. Our system was applied to wireless communications, a quickly growing domain with an increasing demand for fast analogue devices to equalise the nonlinear distorted channels. We report error rates up to two orders of magnitude lower than previous implementations on this task. We show that our system is particularly well-suited for realistic channel equalisation by testing it on a drifting and a switching channels and obtaining good performances
* 13 pages, 10 figures