 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Input Dropout for Spatially Aligned Modalities
Feb 07, 2020




Computer vision datasets containing multiple modalities such as color, depth, and thermal properties are now commonly accessible and useful for solving a wide array of challenging tasks. However, deploying multi-sensor heads is not possible in many scenarios. As such many practical solutions tend to be based on simpler sensors, mostly for cost, simplicity and robustness considerations. In this work, we propose a training methodology to take advantage of these additional modalities available in datasets, even if they are not available at test time. By assuming that the modalities have a strong spatial correlation, we propose Input Dropout, a simple technique that consists in stochastic hiding of one or many input modalities at training time, while using only the canonical (e.g. RGB) modalities at test time. We demonstrate that Input Dropout trivially combines with existing deep convolutional architectures, and improves their performance on a wide range of computer vision tasks such as dehazing, 6-DOF object tracking, pedestrian detection and object classification.
Accurate, Low-Latency Visual Perception for Autonomous Racing:Challenges, Mechanisms, and Practical Solutions
Jul 28, 2020
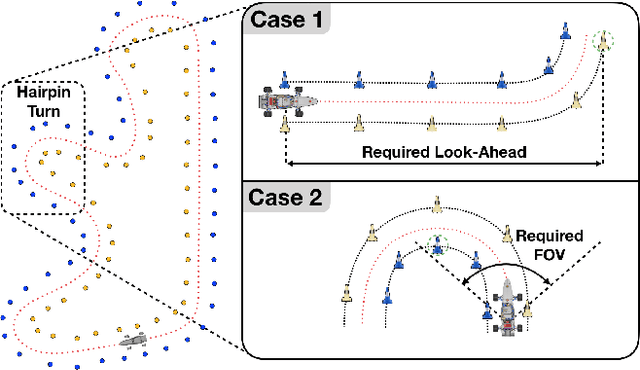
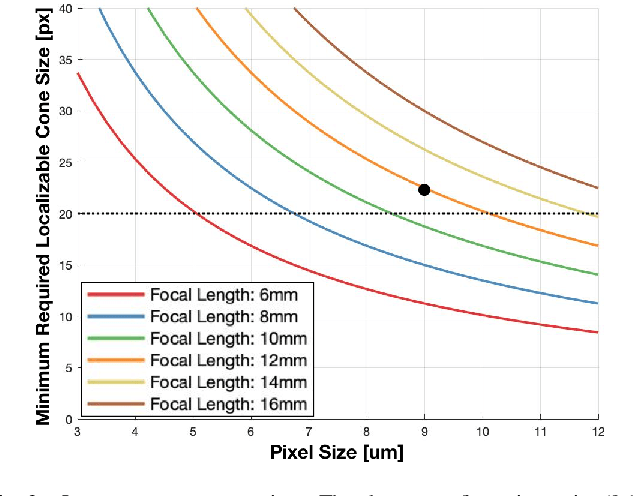

Autonomous racing provides the opportunity to test safety-critical perception pipelines at their limit. This paper describes the practical challenges and solutions to applying state-of-the-art computer vision algorithms to build a low-latency, high-accuracy perception system for DUT18 Driverless (DUT18D), a 4WD electric race car with podium finishes at all Formula Driverless competitions for which it raced. The key components of DUT18D include YOLOv3-based object detection, pose estimation, and time synchronization on its dual stereovision/monovision camera setup. We highlight modifications required to adapt perception CNNs to racing domains, improvements to loss functions used for pose estimation, and methodologies for sub-microsecond camera synchronization among other improvements. We perform a thorough experimental evaluation of the system, demonstrating its accuracy and low-latency in real-world racing scenarios.
Stochastic Optimization Forests
Aug 17, 2020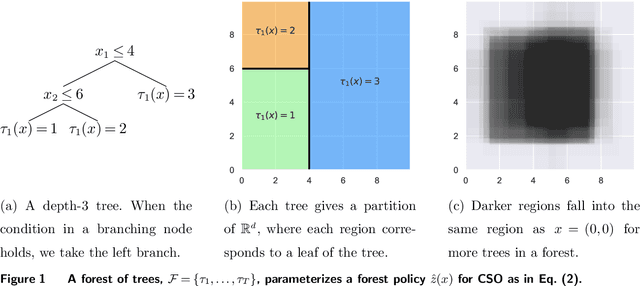

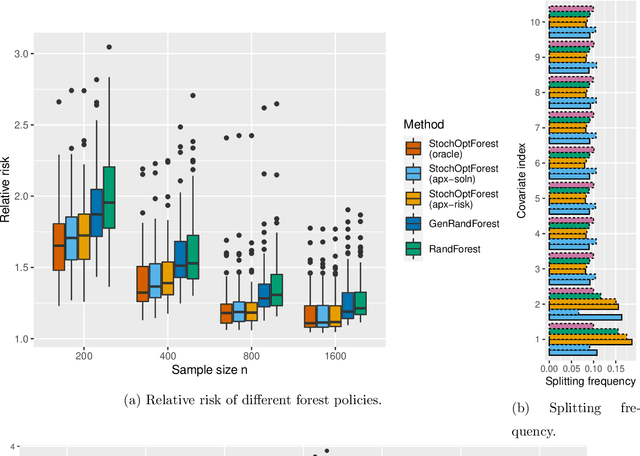
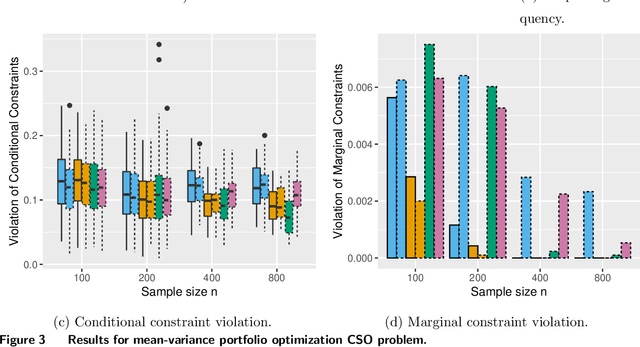
We study conditional stochastic optimization problems, where we leverage rich auxiliary observations (e.g., customer characteristics) to improve decision-making with uncertain variables (e.g., demand). We show how to train forest decision policies for this problem by growing trees that choose splits to directly optimize the downstream decision quality, rather than splitting to improve prediction accuracy as in the standard random forest algorithm. We realize this seemingly computationally intractable problem by developing approximate splitting criteria that utilize optimization perturbation analysis to eschew burdensome re-optimization for every candidate split, so that our method scales to large-scale problems. Our method can accommodate both deterministic and stochastic constraints. We prove that our splitting criteria consistently approximate the true risk. We extensively validate its efficacy empirically, demonstrating the value of optimization-aware construction of forests and the success of our efficient approximations. We show that our approximate splitting criteria can reduce running time hundredfold, while achieving performance close to forest algorithms that exactly re-optimize for every candidate split.
SummPip: Unsupervised Multi-Document Summarization with Sentence Graph Compression
Jul 20, 2020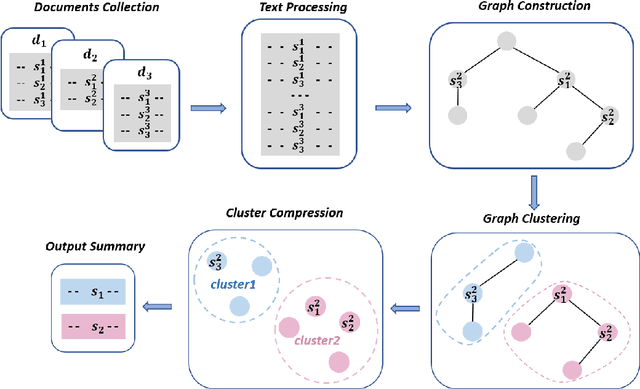
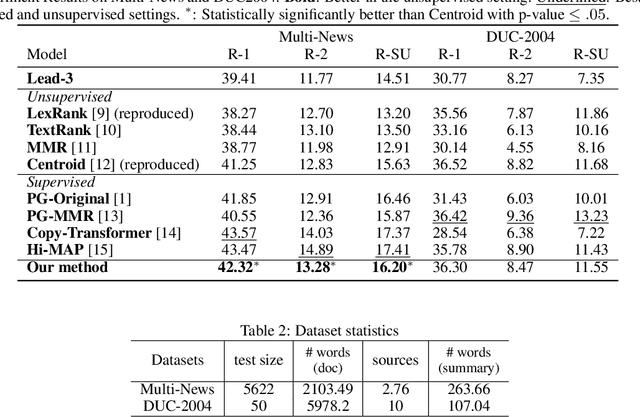
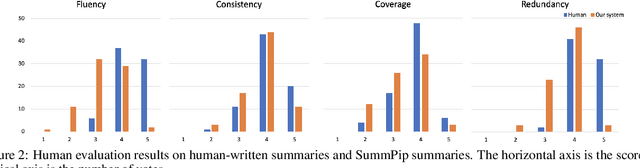
Obtaining training data for multi-document summarization (MDS) is time consuming and resource-intensive, so recent neural models can only be trained for limited domains. In this paper, we propose SummPip: an unsupervised method for multi-document summarization, in which we convert the original documents to a sentence graph, taking both linguistic and deep representation into account, then apply spectral clustering to obtain multiple clusters of sentences, and finally compress each cluster to generate the final summary. Experiments on Multi-News and DUC-2004 datasets show that our method is competitive to previous unsupervised methods and is even comparable to the neural supervised approaches. In addition, human evaluation shows our system produces consistent and complete summaries compared to human written ones.
Sparse Gaussian Processes for Continuous-Time Trajectory Estimation on Matrix Lie Groups
May 17, 2017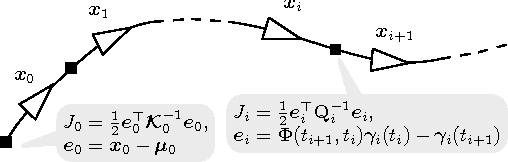
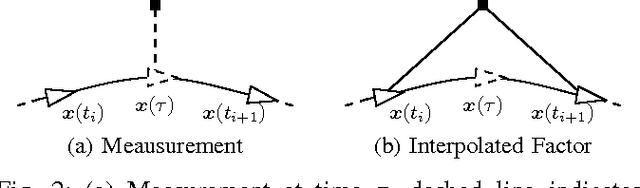
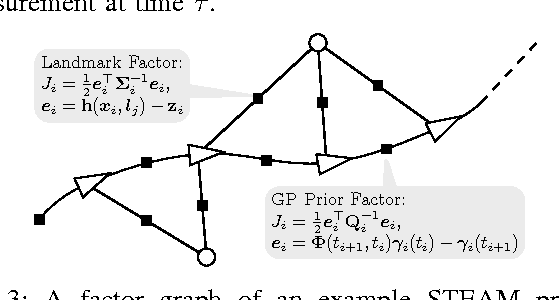
Continuous-time trajectory representations are a powerful tool that can be used to address several issues in many practical simultaneous localization and mapping (SLAM) scenarios, like continuously collected measurements distorted by robot motion, or during with asynchronous sensor measurements. Sparse Gaussian processes (GP) allow for a probabilistic non-parametric trajectory representation that enables fast trajectory estimation by sparse GP regression. However, previous approaches are limited to dealing with vector space representations of state only. In this technical report we extend the work by Barfoot et al. [1] to general matrix Lie groups, by applying constant-velocity prior, and defining locally linear GP. This enables using sparse GP approach in a large space of practical SLAM settings. In this report we give the theory and leave the experimental evaluation in future publications.
Machine Learning for Motor Learning: EEG-based Continuous Assessment of Cognitive Engagement for Adaptive Rehabilitation Robots
Feb 19, 2020
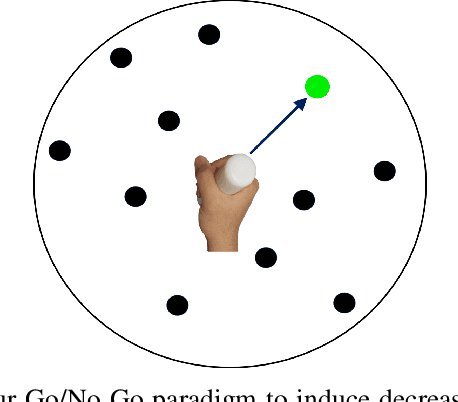
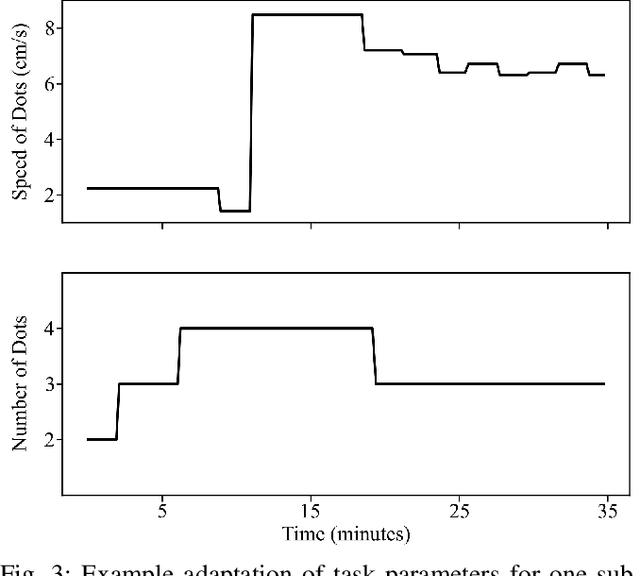
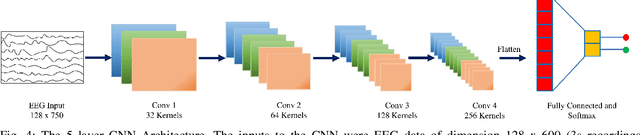
Although cognitive engagement (CE) is crucial for motor learning, it remains underutilized in rehabilitation robots, partly because its assessment currently relies on subjective and gross measurements taken intermittently. Here, we propose an end-to-end computational framework that assesses CE in real-time, using electroencephalography (EEG) signals as objective measurements. The framework consists of i) a deep convolutional neural network (CNN) that extracts task-discriminative spatiotemporal EEG to predict the level of CE for two classes -- cognitively engaged vs. disengaged; and ii) a novel sliding window method that predicts continuous levels of CE in real-time. We evaluated our framework on 8 subjects using an in-house Go/No-Go experiment that adapted its gameplay parameters to induce cognitive fatigue. The proposed CNN had an average leave-one-out accuracy of 88.13\%. The CE prediction correlated well with a commonly used behavioral metric based on self-reports taken every 5 minutes ($\rho$=0.93). Our results objectify CE in real-time and pave the way for using CE as a rehabilitation parameter for tailoring robotic therapy to each patient's needs and skills.
A Modified Bayesian Optimization based Hyper-Parameter Tuning Approach for Extreme Gradient Boosting
Apr 10, 2020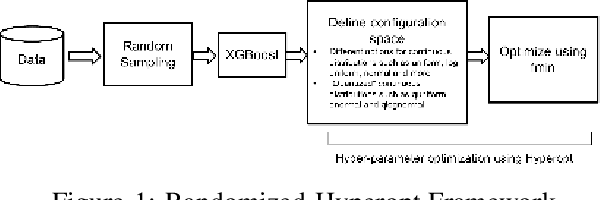
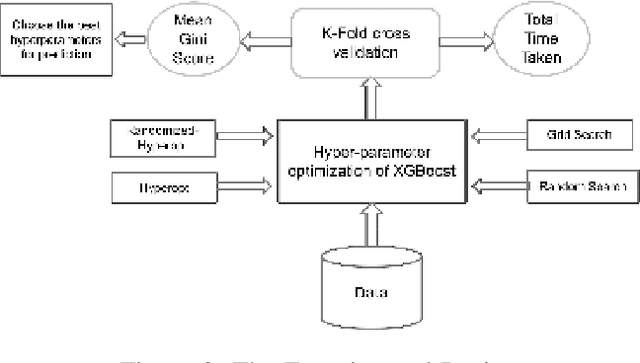
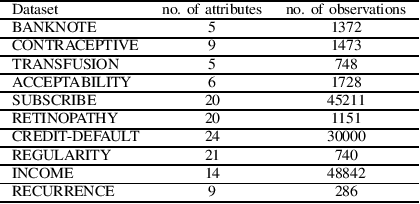
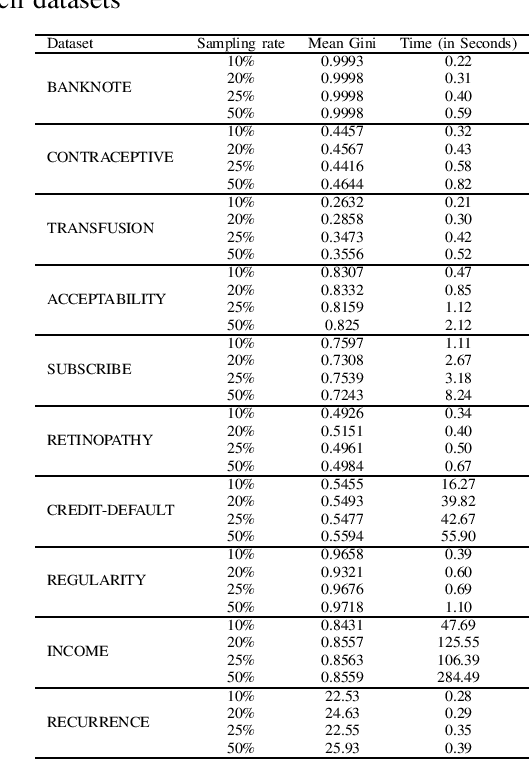
It is already reported in the literature that the performance of a machine learning algorithm is greatly impacted by performing proper Hyper-Parameter optimization. One of the ways to perform Hyper-Parameter optimization is by manual search but that is time consuming. Some of the common approaches for performing Hyper-Parameter optimization are Grid search Random search and Bayesian optimization using Hyperopt. In this paper, we propose a brand new approach for hyperparameter improvement i.e. Randomized-Hyperopt and then tune the hyperparameters of the XGBoost i.e. the Extreme Gradient Boosting algorithm on ten datasets by applying Random search, Randomized-Hyperopt, Hyperopt and Grid Search. The performances of each of these four techniques were compared by taking both the prediction accuracy and the execution time into consideration. We find that the Randomized-Hyperopt performs better than the other three conventional methods for hyper-paramter optimization of XGBoost.
Forecasting Framework for Open Access Time Series in Energy
Jun 02, 2016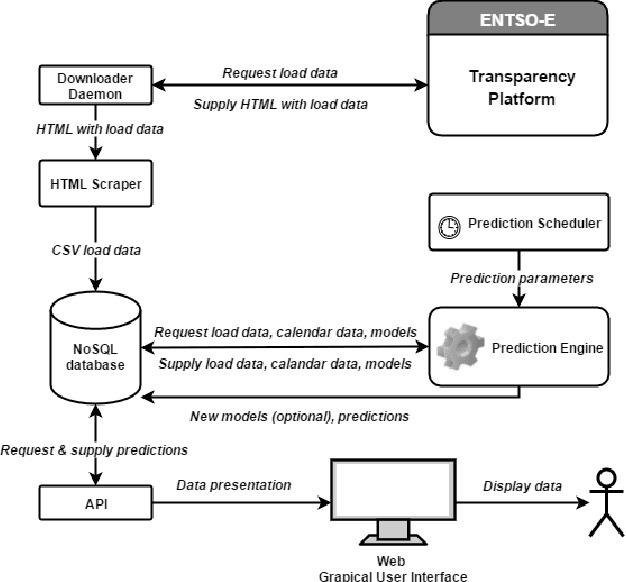
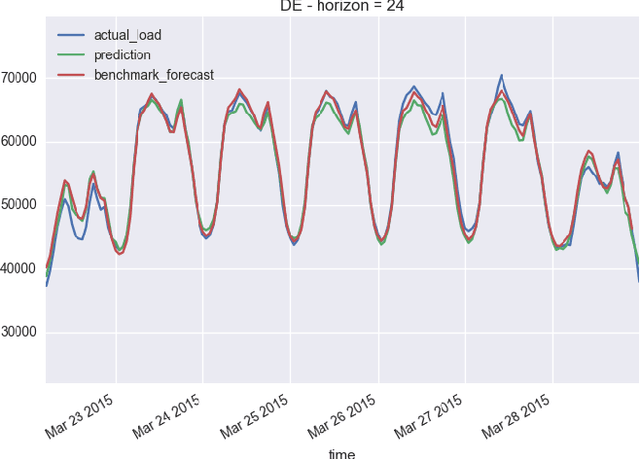
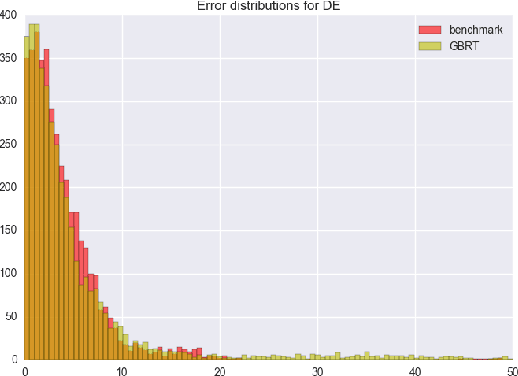
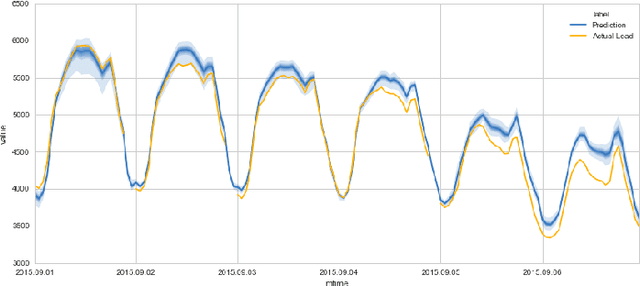
In this paper we propose a framework for automated forecasting of energy-related time series using open access data from European Network of Transmission System Operators for Electricity (ENTSO-E). The framework provides forecasts for various European countries using publicly available historical data only. Our solution was benchmarked using the actual load data and the country provided estimates (where available). We conclude that the proposed system can produce timely forecasts with comparable prediction accuracy in a number of cases. We also investigate the probabilistic case of forecasting - that is, providing a probability distribution rather than a simple point forecast - and incorporate it into a web based API that provides quick and easy access to reliable forecasts.
Multifunctionality in a Reservoir Computer
Aug 10, 2020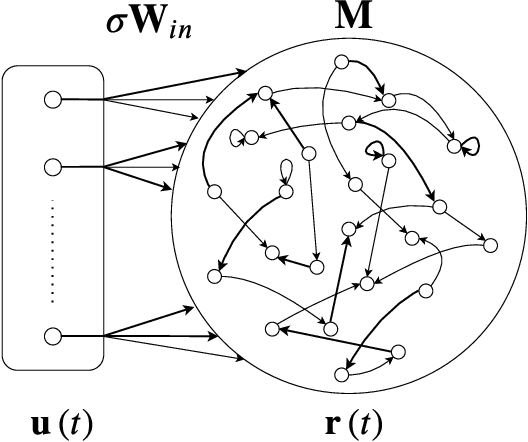
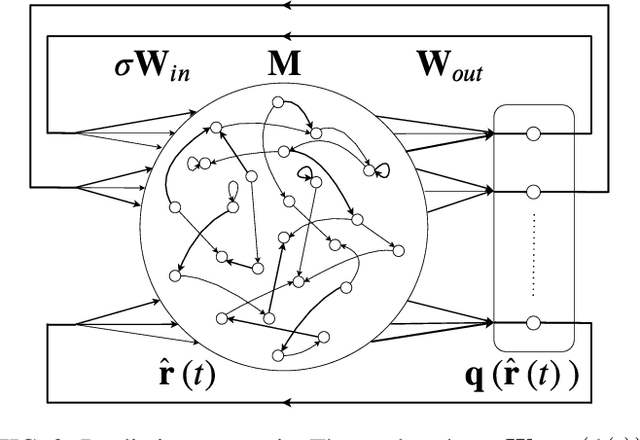
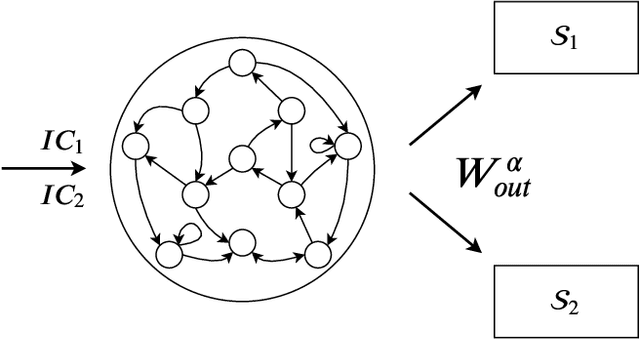
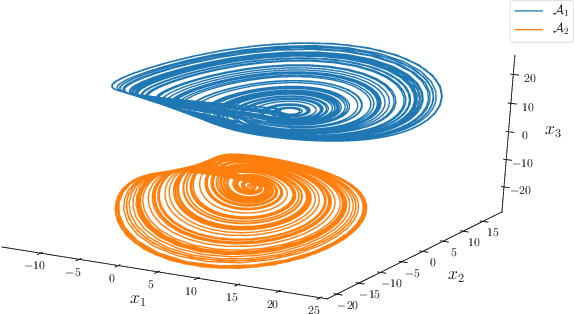
Multifunctionality is a well observed phenomenological feature of biological neural networks and considered to be of fundamental importance to the survival of certain species over time. These multifunctional neural networks are capable of performing more than one task without changing any network connections. In this paper we investigate how this neurological idiosyncrasy can be achieved in an artificial setting with a modern machine learning paradigm known as `Reservoir Computing'. A training technique is designed to enable a Reservoir Computer to perform tasks of a multifunctional nature. We explore the critical effects that changes in certain parameters can have on the Reservoir Computers' ability to express multifunctionality. We also expose the existence of several `untrained attractors'; attractors which dwell within the prediction state space of the Reservoir Computer that were not part of the training. We conduct a bifurcation analysis of these untrained attractors and discuss the implications of our results.
Predicting Injectable Medication Adherence via a Smart Sharps Bin and Machine Learning
Apr 02, 2020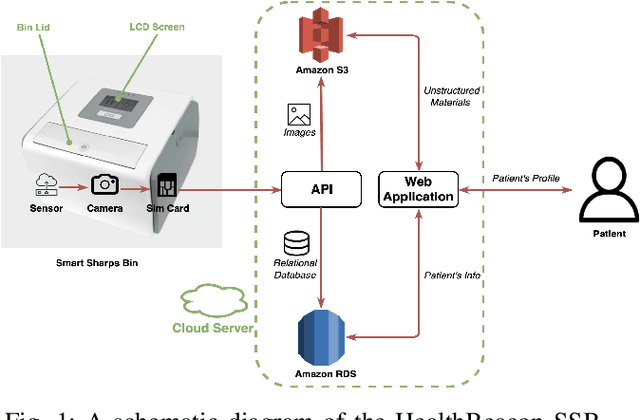
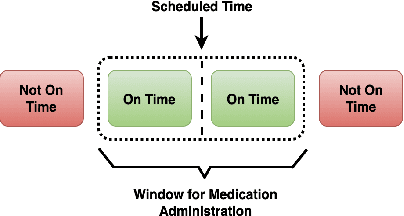
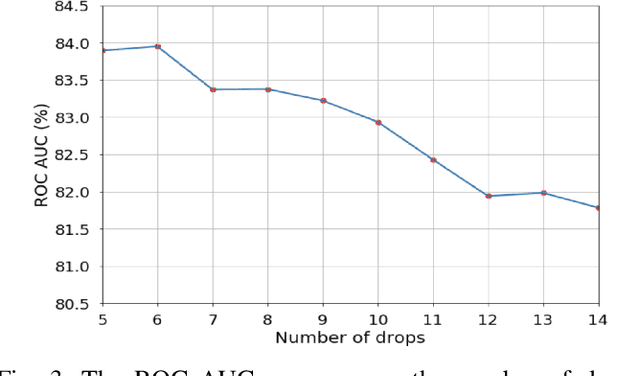
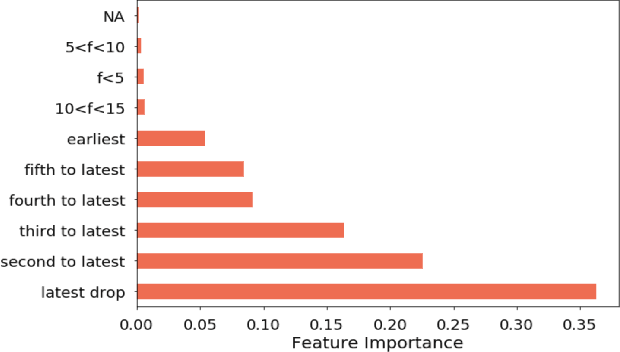
Medication non-adherence is a widespread problem affecting over 50% of people who have chronic illness and need chronic treatment. Non-adherence exacerbates health risks and drives significant increases in treatment costs. In order to address these challenges, the importance of predicting patients' adherence has been recognised. In other words, it is important to improve the efficiency of interventions of the current healthcare system by prioritizing resources to the patients who are most likely to be non-adherent. Our objective in this work is to make predictions regarding individual patients' behaviour in terms of taking their medication on time during their next scheduled medication opportunity. We do this by leveraging a number of machine learning models. In particular, we demonstrate the use of a connected IoT device; a "Smart Sharps Bin", invented by HealthBeacon Ltd.; to monitor and track injection disposal of patients in their home environment. Using extensive data collected from these devices, five machine learning models, namely Extra Trees Classifier, Random Forest, XGBoost, Gradient Boosting and Multilayer Perception were trained and evaluated on a large dataset comprising 165,223 historic injection disposal records collected from 5,915 HealthBeacon units over the course of 3 years. The testing work was conducted on real-time data generated by the smart device over a time period after the model training was complete, i.e. true future data. The proposed machine learning approach demonstrated very good predictive performance exhibiting an Area Under the Receiver Operating Characteristic Curve (ROC AUC) of 0.86.