 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Using Monte Carlo dropout and bootstrap aggregation for uncertainty estimation in radiation therapy dose prediction with deep learning neural networks
Nov 01, 2020
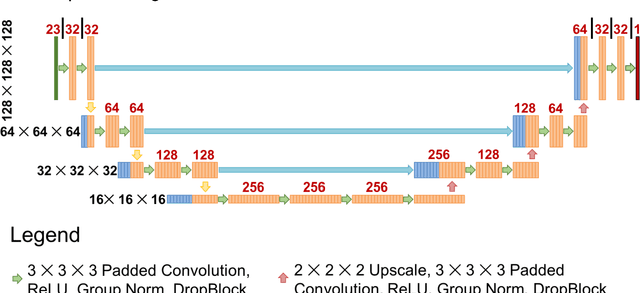
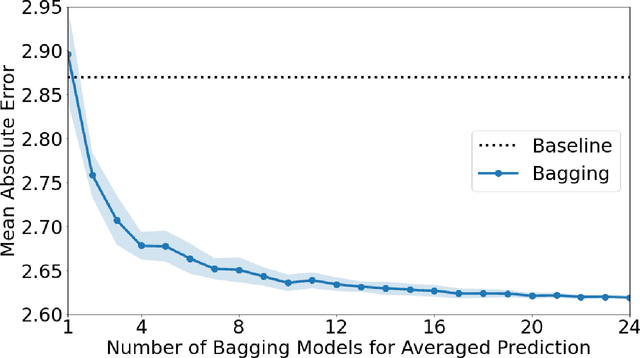
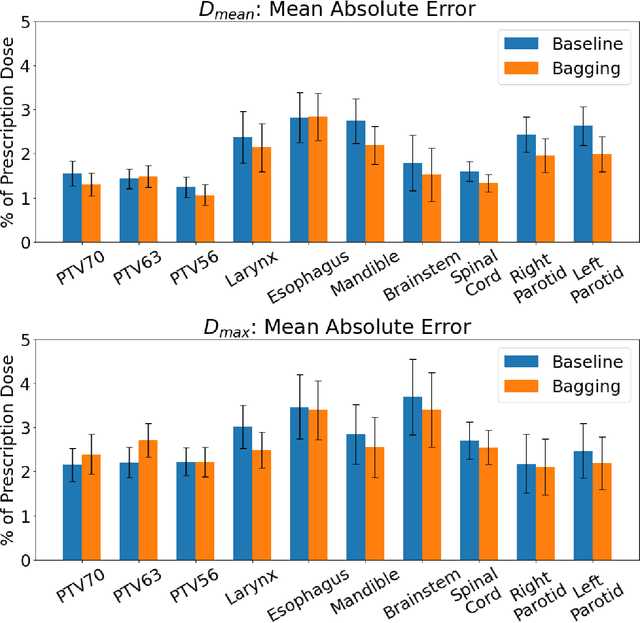
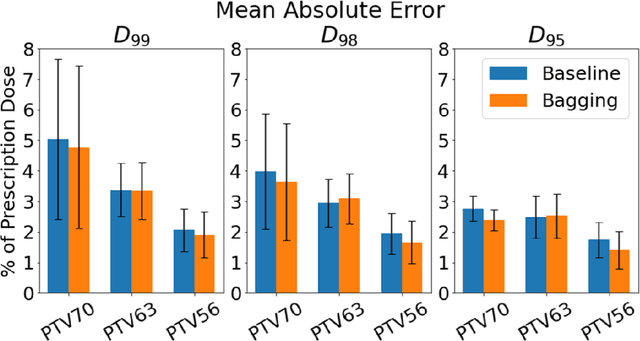
Recently, artificial intelligence technologies and algorithms have become a major focus for advancements in treatment planning for radiation therapy. As these are starting to become incorporated into the clinical workflow, a major concern from clinicians is not whether the model is accurate, but whether the model can express to a human operator when it does not know if its answer is correct. We propose to use Monte Carlo dropout (MCDO) and the bootstrap aggregation (bagging) technique on deep learning models to produce uncertainty estimations for radiation therapy dose prediction. We show that both models are capable of generating a reasonable uncertainty map, and, with our proposed scaling technique, creating interpretable uncertainties and bounds on the prediction and any relevant metrics. Performance-wise, bagging provides statistically significant reduced loss value and errors in most of the metrics investigated in this study. The addition of bagging was able to further reduce errors by another 0.34% for Dmean and 0.19% for Dmax, on average, when compared to the baseline framework. Overall, the bagging framework provided significantly lower MAE of 2.62, as opposed to the baseline framework's MAE of 2.87. The usefulness of bagging, from solely a performance standpoint, does highly depend on the problem and the acceptable predictive error, and its high upfront computational cost during training should be factored in to deciding whether it is advantageous to use it. In terms of deployment with uncertainty estimations turned on, both frameworks offer the same performance time of about 12 seconds. As an ensemble-based metaheuristic, bagging can be used with existing machine learning architectures to improve stability and performance, and MCDO can be applied to any deep learning models that have dropout as part of their architecture.
Rethinking Recurrent Neural Networks and other Improvements for Image Classification
Jul 30, 2020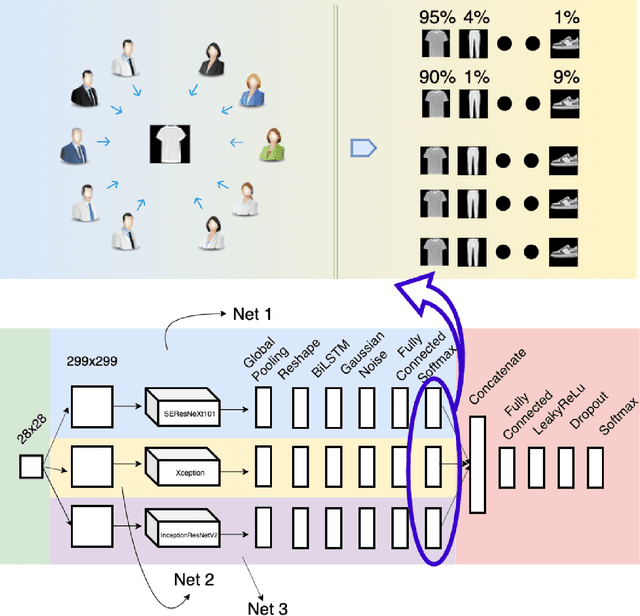
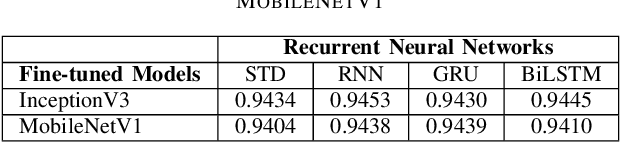
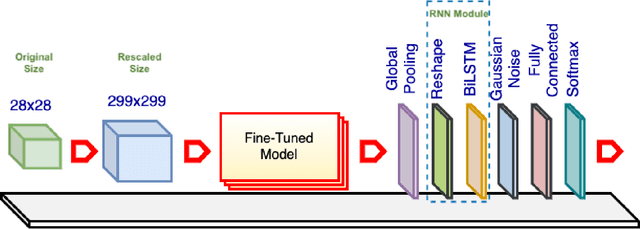
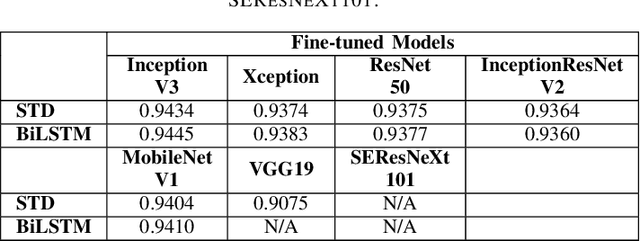
For a long history of Machine Learning which dates back to several decades, Recurrent Neural Networks (RNNs) have been mainly used for sequential data and time series or generally 1D information. Even in some rare researches on 2D images, the networks merely learn and generate data sequentially rather than for recognition of images. In this research, we propose to integrate RNN as an additional layer in designing image recognition's models. Moreover, we develop End-to-End Ensemble Multi-models that are able to learn experts' predictions from several models. Besides, we extend training strategy and softmax pruning which overall leads our designs to perform comparably to top models on several datasets. The source code of the methods provided in this article is available in https://github.com/leonlha/e2e-3m and http://nguyenhuuphong.me.
Symplectic Gaussian Process Regression of Hamiltonian Flow Maps
Sep 11, 2020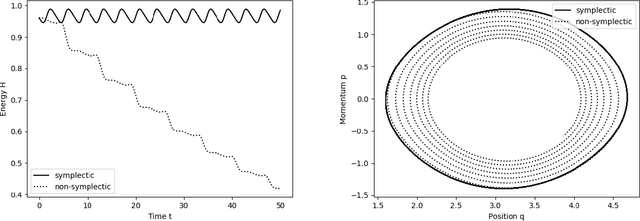
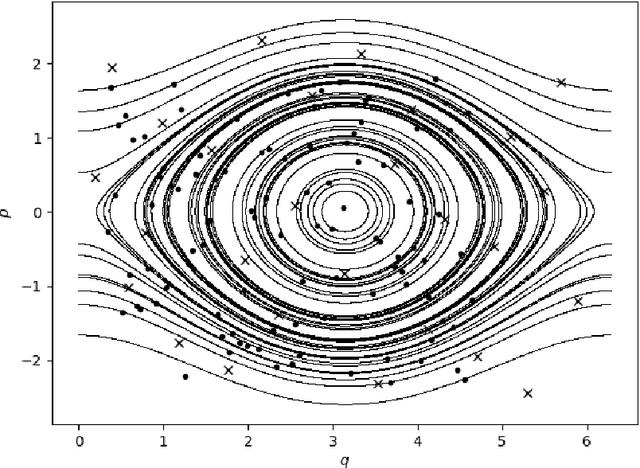
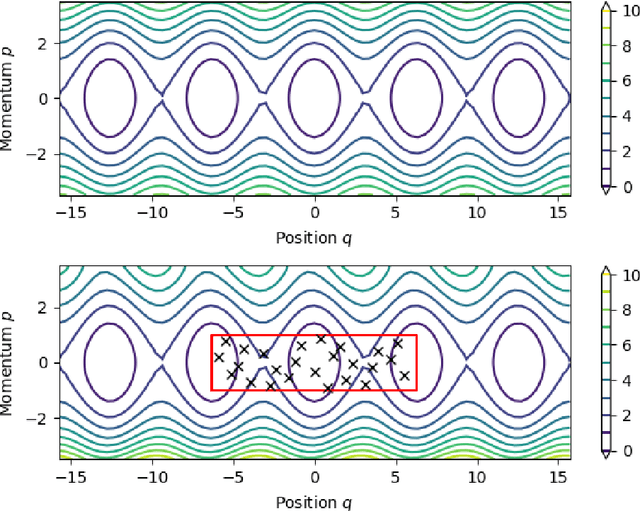
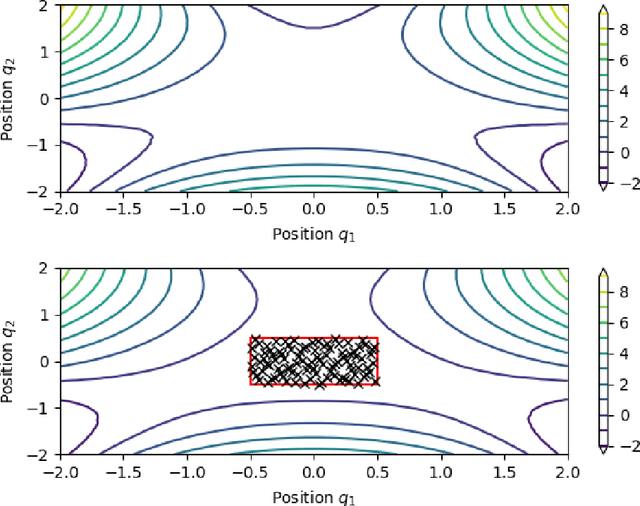
We present an approach to construct appropriate and efficient emulators for Hamiltonian flow maps. Intended future applications are long-term tracing of fast charged particles in accelerators and magnetic plasma confinement configurations. The method is based on multi-output Gaussian process regression on scattered training data. To obtain long-term stability the symplectic property is enforced via the choice of the matrix-valued covariance function. Based on earlier work on spline interpolation we observe derivatives of the generating function of a canonical transformation. A product kernel produces an accurate implicit method, whereas a sum kernel results in a fast explicit method from this approach. Both correspond to a symplectic Euler method in terms of numerical integration. These methods are applied to the pendulum and the H\'enon-Heiles system and results compared to an symmetric regression with orthogonal polynomials. In the limit of small mapping times, the Hamiltonian function can be identified with a part of the generating function and thereby learned from observed time-series data of the system's evolution. Besides comparable performance of implicit kernel and spectral regression for symplectic maps, we demonstrate a substantial increase in performance for learning the Hamiltonian function compared to existing approaches.
Accelerating 2PC-based ML with Limited Trusted Hardware
Sep 11, 2020



This paper describes the design, implementation, and evaluation of Otak, a system that allows two non-colluding cloud providers to run machine learning (ML) inference without knowing the inputs to inference. Prior work for this problem mostly relies on advanced cryptography such as two-party secure computation (2PC) protocols that provide rigorous guarantees but suffer from high resource overhead. Otak improves efficiency via a new 2PC protocol that (i) tailors recent primitives such as function and homomorphic secret sharing to ML inference, and (ii) uses trusted hardware in a limited capacity to bootstrap the protocol. At the same time, Otak reduces trust assumptions on trusted hardware by running a small code inside the hardware, restricting its use to a preprocessing step, and distributing trust over heterogeneous trusted hardware platforms from different vendors. An implementation and evaluation of Otak demonstrates that its CPU and network overhead converted to a dollar amount is 5.4$-$385$\times$ lower than state-of-the-art 2PC-based works. Besides, Otak's trusted computing base (code inside trusted hardware) is only 1,300 lines of code, which is 14.6$-$29.2$\times$ lower than the code-size in prior trusted hardware-based works.
Evaluation of machine learning algorithms for Health and Wellness applications: a tutorial
Aug 31, 2020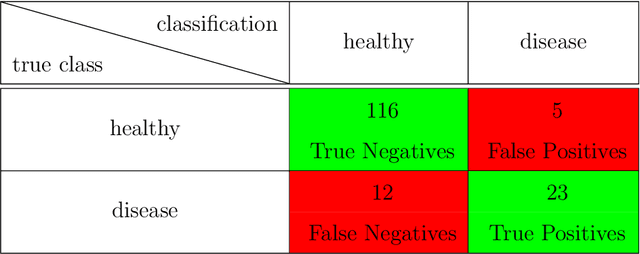
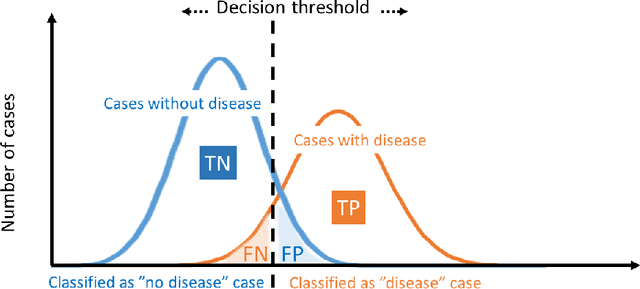
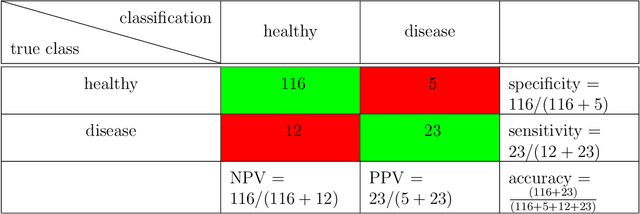
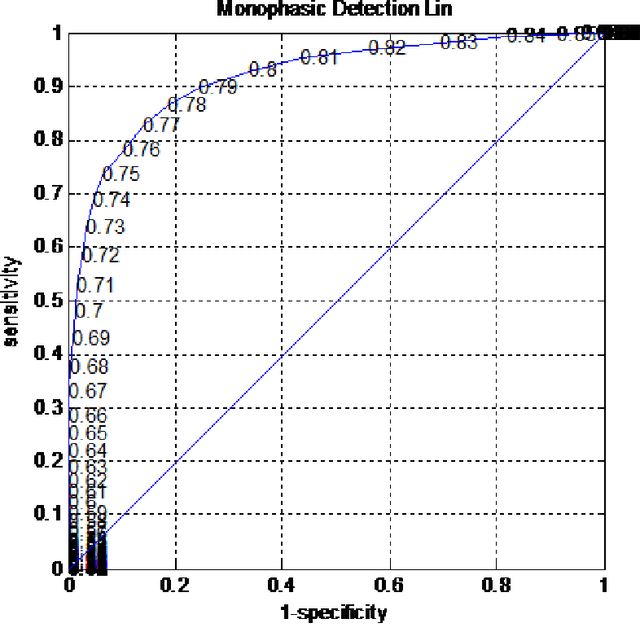
Research on decision support applications in healthcare, such as those related to diagnosis, prediction, treatment planning, etc., have seen enormously increased interest recently. This development is thanks to the increase in data availability as well as advances in artificial intelligence and machine learning research. Highly promising research examples are published daily. However, at the same time, there are some unrealistic expectations with regards to the requirements for reliable development and objective validation that is needed in healthcare settings. These expectations may lead to unmet schedules and disappointments (or non-uptake) at the end-user side. It is the aim of this tutorial to provide practical guidance on how to assess performance reliably and efficiently and avoid common traps. Instead of giving a list of do's and don't s, this tutorial tries to build a better understanding behind these do's and don't s and presents both the most relevant performance evaluation criteria as well as how to compute them. Along the way, we will indicate common mistakes and provide references discussing various topics more in-depth.
Fast, Structured Clinical Documentation via Contextual Autocomplete
Jul 29, 2020

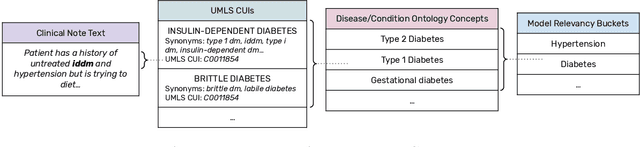

We present a system that uses a learned autocompletion mechanism to facilitate rapid creation of semi-structured clinical documentation. We dynamically suggest relevant clinical concepts as a doctor drafts a note by leveraging features from both unstructured and structured medical data. By constraining our architecture to shallow neural networks, we are able to make these suggestions in real time. Furthermore, as our algorithm is used to write a note, we can automatically annotate the documentation with clean labels of clinical concepts drawn from medical vocabularies, making notes more structured and readable for physicians, patients, and future algorithms. To our knowledge, this system is the only machine learning-based documentation utility for clinical notes deployed in a live hospital setting, and it reduces keystroke burden of clinical concepts by 67% in real environments.
TrajectoryNet: A Dynamic Optimal Transport Network for Modeling Cellular Dynamics
Feb 09, 2020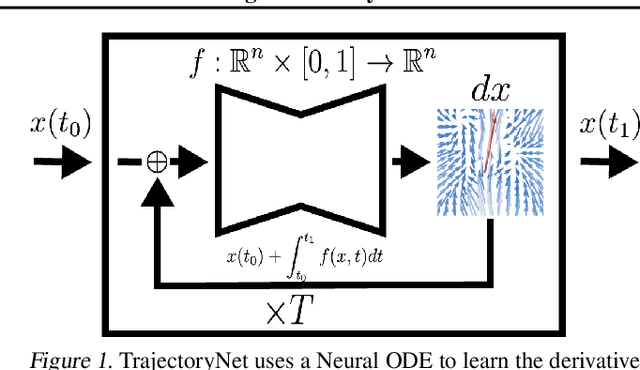
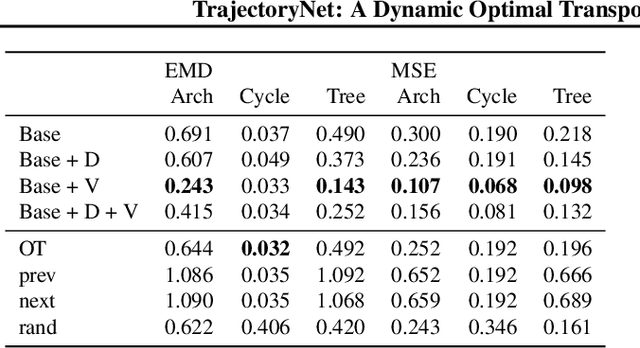
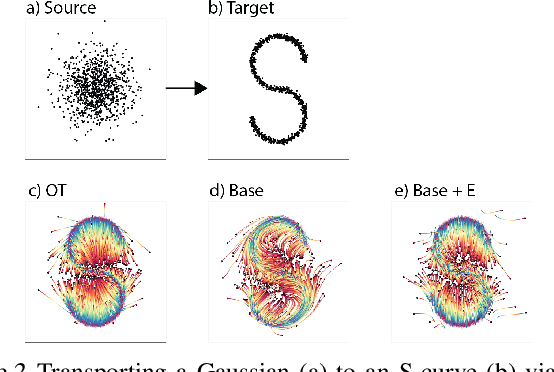
It is increasingly common to encounter data from dynamic processes captured by static cross-sectional measurements over time, particularly in biomedical settings. Recent attempts to model individual trajectories from this data use optimal transport to create pairwise matchings between time points. However, these methods cannot model continuous dynamics and non-linear paths that entities can take in these systems. To address this issue, we establish a link between continuous normalizing flows and dynamic optimal transport, that allows us to model the expected paths of points over time. Continuous normalizing flows are generally under constrained, as they are allowed to take an arbitrary path from the source to the target distribution. We present TrajectoryNet, which controls the continuous paths taken between distributions. We show how this is particularly applicable for studying cellular dynamics in data from single-cell RNA sequencing (scRNA-seq) technologies, and that TrajectoryNet improves upon recently proposed static optimal transport-based models that can be used for interpolating cellular distributions.
Machine Learning Clustering Techniques for Selective Mitigation of Critical Design Features
Aug 31, 2020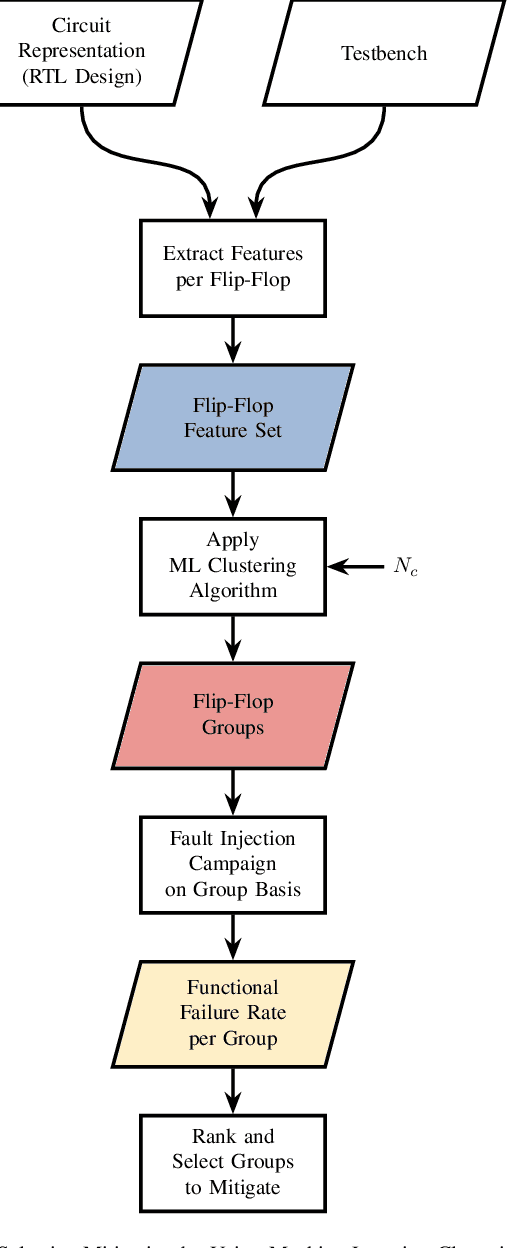
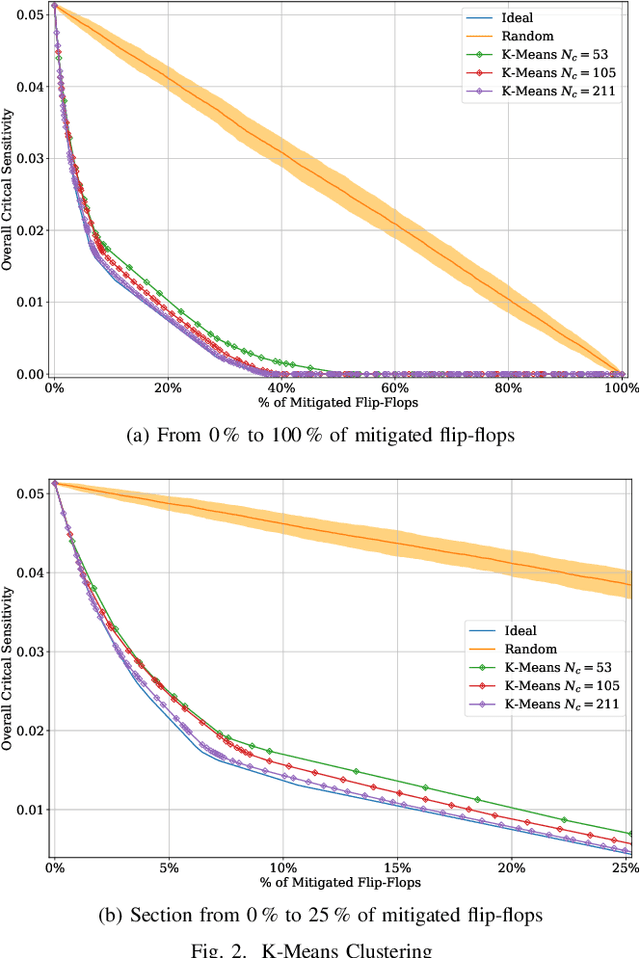
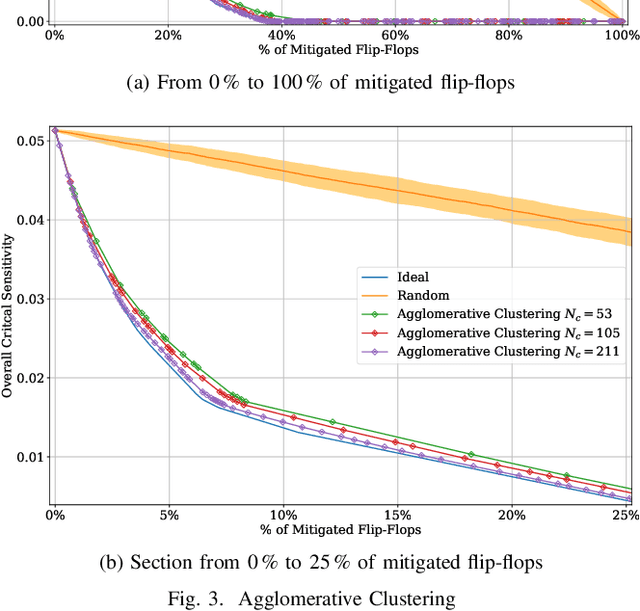
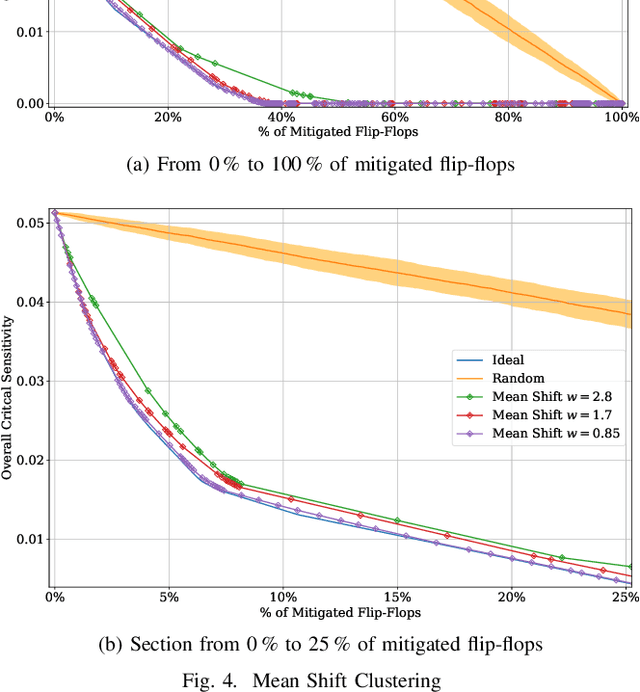
Selective mitigation or selective hardening is an effective technique to obtain a good trade-off between the improvements in the overall reliability of a circuit and the hardware overhead induced by the hardening techniques. Selective mitigation relies on preferentially protecting circuit instances according to their susceptibility and criticality. However, ranking circuit parts in terms of vulnerability usually requires computationally intensive fault-injection simulation campaigns. This paper presents a new methodology which uses machine learning clustering techniques to group flip-flops with similar expected contributions to the overall functional failure rate, based on the analysis of a compact set of features combining attributes from static elements and dynamic elements. Fault simulation campaigns can then be executed on a per-group basis, significantly reducing the time and cost of the evaluation. The effectiveness of grouping similar sensitive flip-flops by machine learning clustering algorithms is evaluated on a practical example.Different clustering algorithms are applied and the results are compared to an ideal selective mitigation obtained by exhaustive fault-injection simulation.
Optimal HDR and Depth from Dual Cameras
Mar 12, 2020
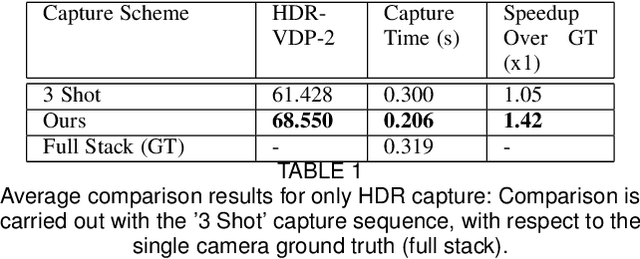
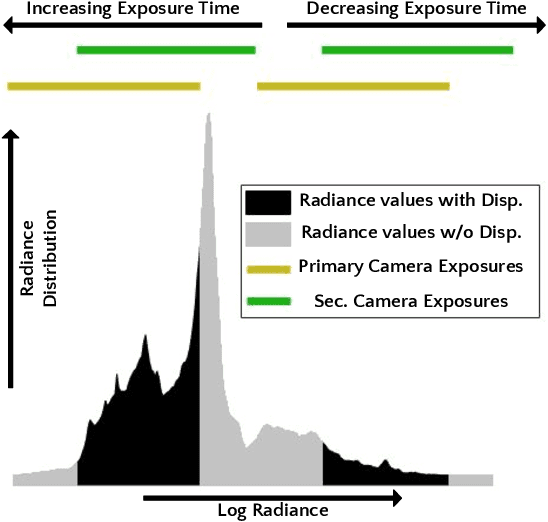
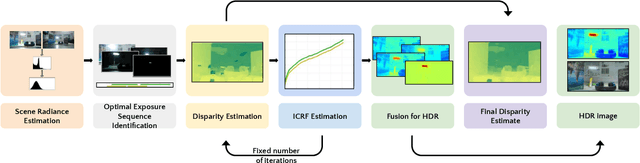
Dual camera systems have assisted in the proliferation of various applications, such as optical zoom, low-light imaging and High Dynamic Range (HDR) imaging. In this work, we explore an optimal method for capturing the scene HDR and disparity map using dual camera setups. Hasinoff et al. (2010) have developed a noise optimal framework for HDR capture from a single camera. We generalize this to the dual camera set-up for estimating both HDR and disparity map. It may seem that dual camera systems can capture HDR in a shorter time. However, disparity estimation is a necessary step, which requires overlap among the images captured by the two cameras. This may lead to an increase in the capture time. To address this conflicting requirement, we propose a novel framework to find the optimal exposure and ISO sequence by minimizing the capture time under the constraints of an upper bound on the disparity error and a lower bound on the per-exposure SNR. We show that the resulting optimization problem is non-convex in general and propose an appropriate initialization technique. To obtain the HDR and disparity map from the optimal capture sequence, we propose a pipeline which alternates between estimating the camera ICRFs and the scene disparity map. We demonstrate that our optimal capture sequence leads to better results than other possible capture sequences. Our results are also close to those obtained by capturing the full stereo stack spanning the entire dynamic range. Finally, we present for the first time a stereo HDR dataset consisting of dense ISO and exposure stack captured from a smartphone dual camera. The dataset consists of 6 scenes, with an average of 142 exposure-ISO image sequence per scene.
Visual Neural Decomposition to Explain Multivariate Data Sets
Sep 11, 2020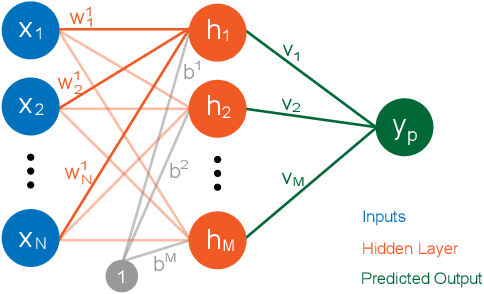
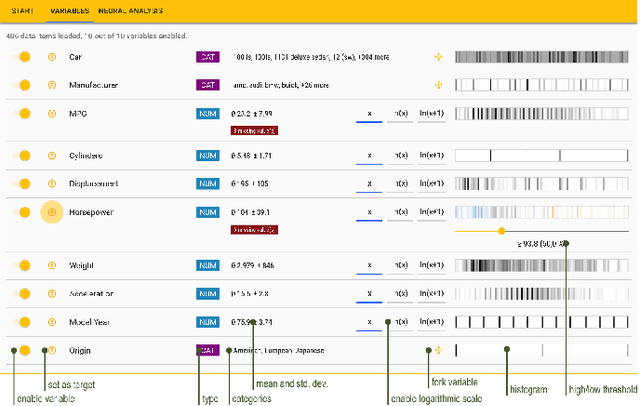

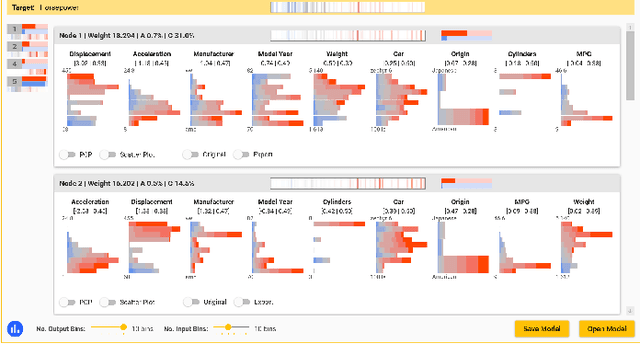
Investigating relationships between variables in multi-dimensional data sets is a common task for data analysts and engineers. More specifically, it is often valuable to understand which ranges of which input variables lead to particular values of a given target variable. Unfortunately, with an increasing number of independent variables, this process may become cumbersome and time-consuming due to the many possible combinations that have to be explored. In this paper, we propose a novel approach to visualize correlations between input variables and a target output variable that scales to hundreds of variables. We developed a visual model based on neural networks that can be explored in a guided way to help analysts find and understand such correlations. First, we train a neural network to predict the target from the input variables. Then, we visualize the inner workings of the resulting model to help understand relations within the data set. We further introduce a new regularization term for the backpropagation algorithm that encourages the neural network to learn representations that are easier to interpret visually. We apply our method to artificial and real-world data sets to show its utility.