 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
What Do You See? Evaluation of Explainable Artificial Intelligence (XAI) Interpretability through Neural Backdoors
Sep 22, 2020
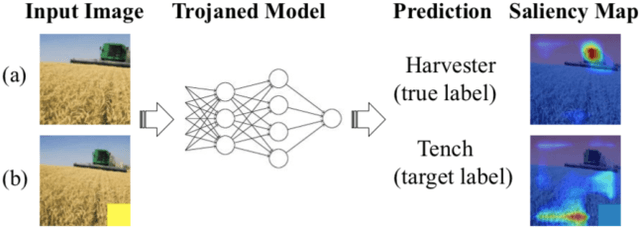
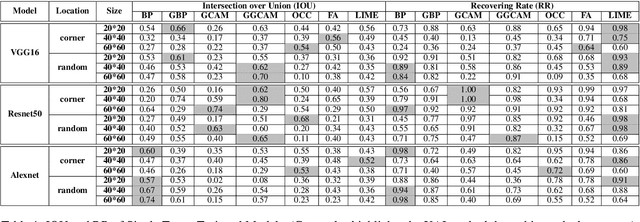
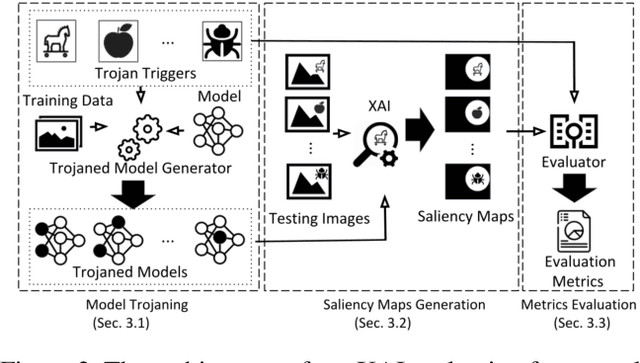
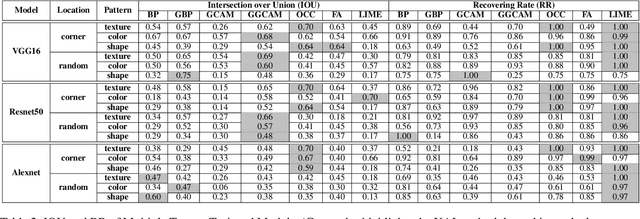
EXplainable AI (XAI) methods have been proposed to interpret how a deep neural network predicts inputs through model saliency explanations that highlight the parts of the inputs deemed important to arrive a decision at a specific target. However, it remains challenging to quantify correctness of their interpretability as current evaluation approaches either require subjective input from humans or incur high computation cost with automated evaluation. In this paper, we propose backdoor trigger patterns--hidden malicious functionalities that cause misclassification--to automate the evaluation of saliency explanations. Our key observation is that triggers provide ground truth for inputs to evaluate whether the regions identified by an XAI method are truly relevant to its output. Since backdoor triggers are the most important features that cause deliberate misclassification, a robust XAI method should reveal their presence at inference time. We introduce three complementary metrics for systematic evaluation of explanations that an XAI method generates and evaluate seven state-of-the-art model-free and model-specific posthoc methods through 36 models trojaned with specifically crafted triggers using color, shape, texture, location, and size. We discovered six methods that use local explanation and feature relevance fail to completely highlight trigger regions, and only a model-free approach can uncover the entire trigger region.
On Box-Cox Transformation for Image Normality and Pattern Classification
Apr 15, 2020
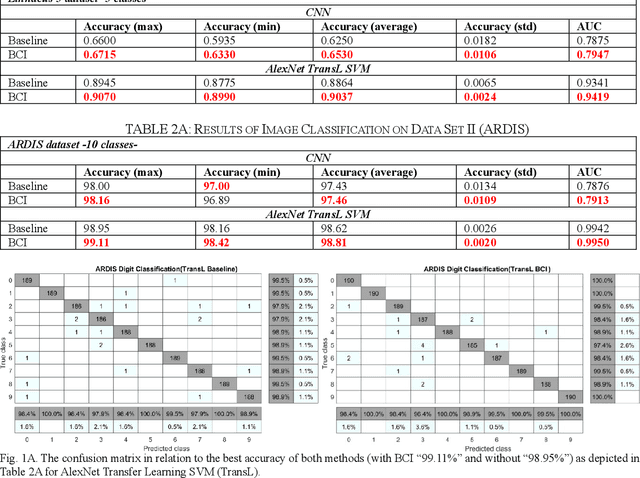
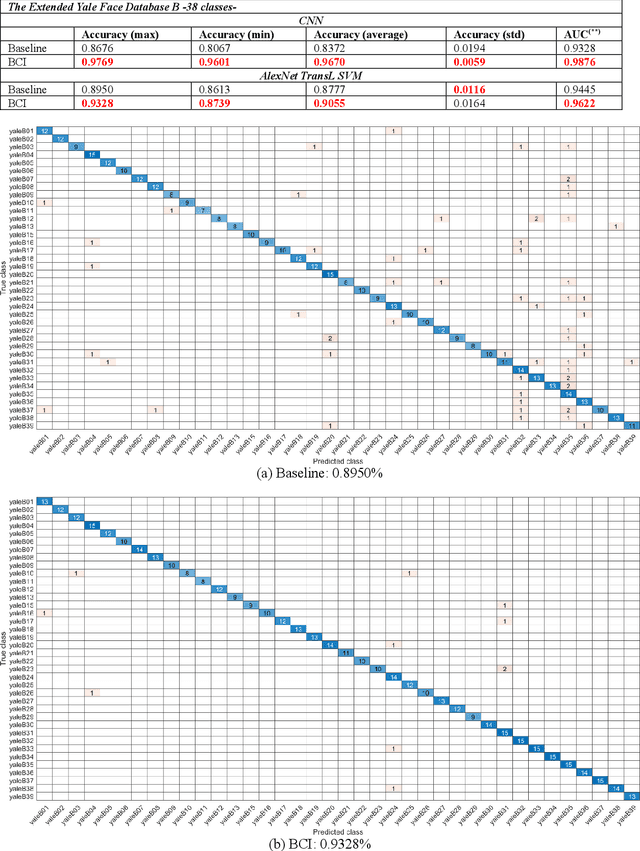
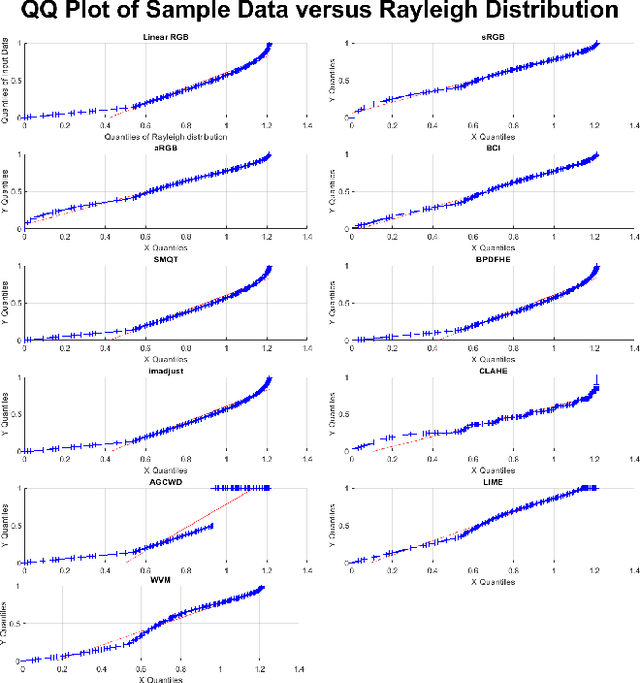
A unique member of the power transformation family is known as the Box-Cox transformation. The latter can be seen as a mathematical operation that leads to finding the optimum lambda ({\lambda}) value that maximizes the log-likelihood function to transform a data to a normal distribution and to reduce heteroscedasticity. In data analytics, a normality assumption underlies a variety of statistical test models. This technique, however, is best known in statistical analysis to handle one-dimensional data. Herein, this paper revolves around the utility of such a tool as a pre-processing step to transform two-dimensional data, namely, digital images and to study its effect. Moreover, to reduce time complexity, it suffices to estimate the parameter lambda in real-time for large two-dimensional matrices by merely considering their probability density function as a statistical inference of the underlying data distribution. We compare the effect of this light-weight Box-Cox transformation with well-established state-of-the-art low light image enhancement techniques. We also demonstrate the effectiveness of our approach through several test-bed data sets for generic improvement of visual appearance of images and for ameliorating the performance of a colour pattern classification algorithm as an example application. Results with and without the proposed approach, are compared using the state-of-the art transfer/deep learning which are discussed in the Appendix. To the best of our knowledge, this is the first time that the Box-Cox transformation is extended to digital images by exploiting histogram transformation.
Curriculum Learning with Diversity for Supervised Computer Vision Tasks
Sep 22, 2020

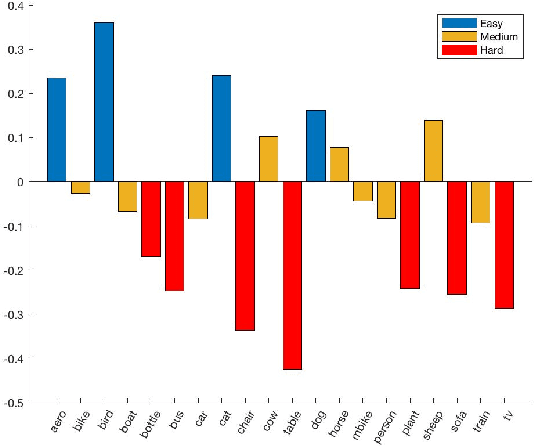
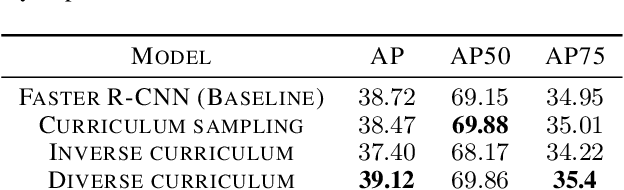
Curriculum learning techniques are a viable solution for improving the accuracy of automatic models, by replacing the traditional random training with an easy-to-hard strategy. However, the standard curriculum methodology does not automatically provide improved results, but it is constrained by multiple elements like the data distribution or the proposed model. In this paper, we introduce a novel curriculum sampling strategy which takes into consideration the diversity of the training data together with the difficulty of the inputs. We determine the difficulty using a state-of-the-art estimator based on the human time required for solving a visual search task. We consider this kind of difficulty metric to be better suited for solving general problems, as it is not based on certain task-dependent elements, but more on the context of each image. We ensure the diversity during training, giving higher priority to elements from less visited classes. We conduct object detection and instance segmentation experiments on Pascal VOC 2007 and Cityscapes data sets, surpassing both the randomly-trained baseline and the standard curriculum approach. We prove that our strategy is very efficient for unbalanced data sets, leading to faster convergence and more accurate results, when other curriculum-based strategies fail.
Characters as Graphs: Recognizing Online Handwritten Chinese Characters via Spatial Graph Convolutional Network
Apr 20, 2020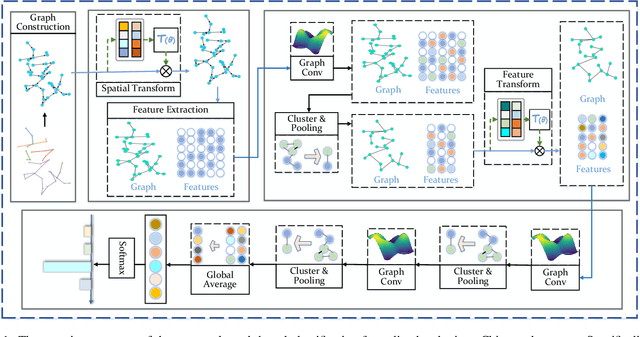
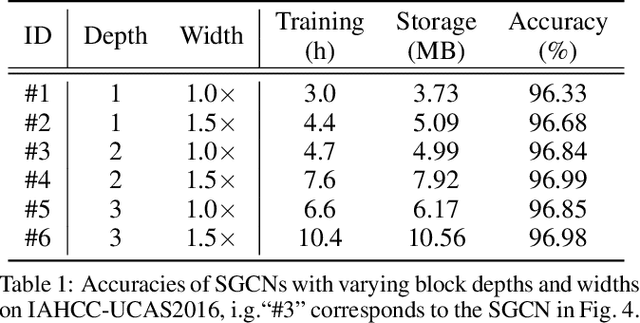
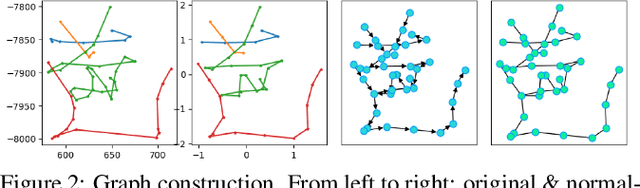
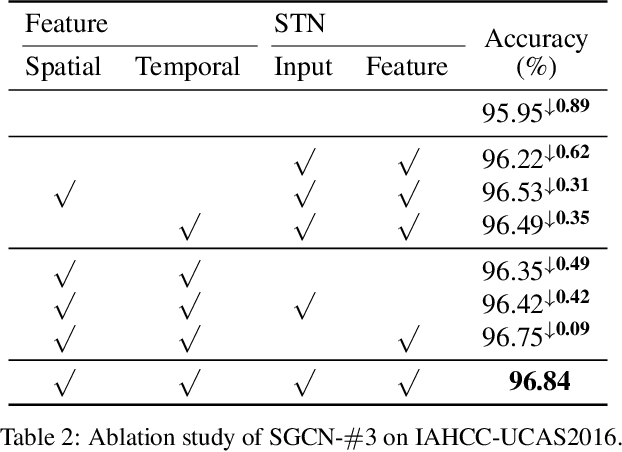
Chinese is one of the most widely used languages in the world, yet online handwritten Chinese character recognition (OLHCCR) remains challenging. To recognize Chinese characters, one popular choice is to adopt the 2D convolutional neural network (2D-CNN) on the extracted feature images, and another one is to employ the recurrent neural network (RNN) or 1D-CNN on the time-series features. Instead of viewing characters as either static images or temporal trajectories, here we propose to represent characters as geometric graphs, retaining both spatial structures and temporal orders. Accordingly, we propose a novel spatial graph convolution network (SGCN) to effectively classify those character graphs for the first time. Specifically, our SGCN incorporates the local neighbourhood information via spatial graph convolutions and further learns the global shape properties with a hierarchical residual structure. Experiments on IAHCC-UCAS2016, ICDAR-2013, and UNIPEN datasets demonstrate that the SGCN can achieve comparable recognition performance with the state-of-the-art methods for character recognition.
Hot-Starting the Ac Power Flow with Convolutional Neural Networks
Apr 20, 2020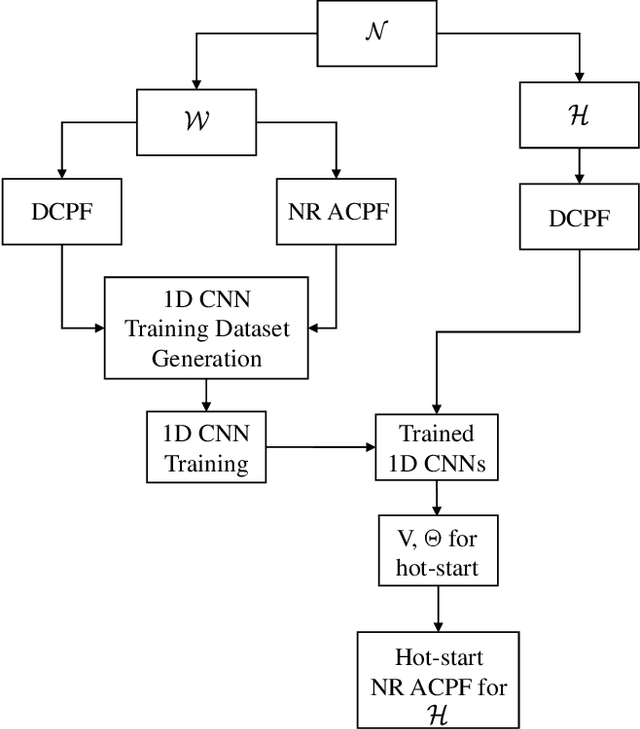
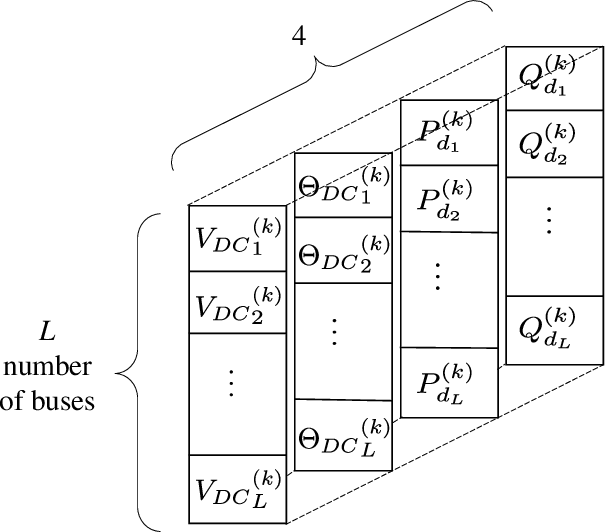
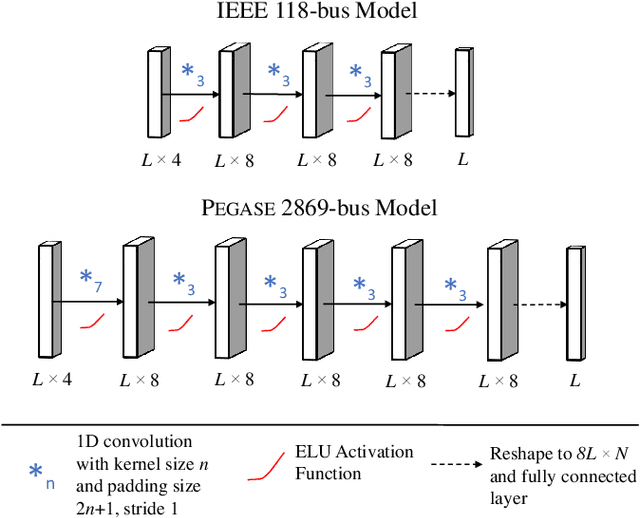
Obtaining good initial conditions to solve the Newton-Raphson (NR) based ac power flow (ACPF) problem can be a very difficult task. In this paper, we propose a framework to obtain the initial bus voltage magnitude and phase values that decrease the solution iterations and time for the NR based ACPF model, using the dc power flow (DCPF) results and one dimensional convolutional neural networks (1D CNNs). We generate the dataset used to train the 1D CNNs by sampling from a distribution of load demands, and by computing the DCPF and ACPF results for each sample. Experiments on the IEEE 118-bus and \textsc{Pegase} 2869-bus study systems show that we can achieve 33.56\% and 30.06\% reduction in solution time, and 66.47% and 49.52% reduction in solution iterations per case, respectively. We include the 1D CNN architectures and the hyperparameters used, which can be expanded on by the future studies on this topic.
GraphTCN: Spatio-Temporal Interaction Modeling for Human Trajectory Prediction
Mar 16, 2020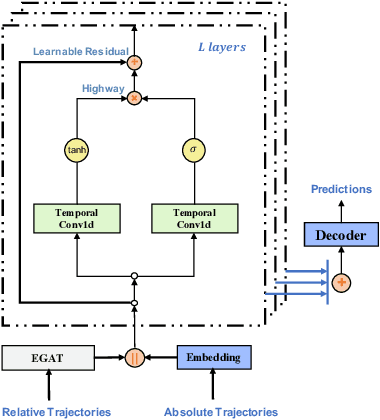
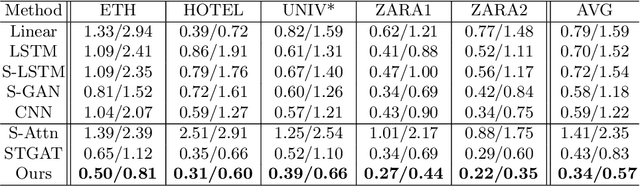

Trajectory prediction is a fundamental and challenging task to forecast the future path of the agents in autonomous applications with multi-agent interaction, where the agents need to predict the future movements of their neighbors to avoid collisions. To respond timely and precisely to the environment, high efficiency and accuracy are required in the prediction. Conventional approaches, e.g., LSTM-based models, take considerable computation costs in the prediction, especially for the long sequence prediction. To support a more efficient and accurate trajectory prediction, we instead propose a novel CNN-based spatial-temporal graph framework GraphTCN, which captures the spatial and temporal interactions in an input-aware manner. The spatial interaction between agents at each time step is captured with an edge graph attention network (EGAT), and the temporal interaction across time step is modeled with a modified gated convolutional network (CNN). In contrast to conventional models, both the spatial and temporal modeling in GraphTCN are computed within each local time window. Therefore, GraphTCN can be executed in parallel for much higher efficiency, and meanwhile with accuracy comparable to best-performing approaches. Experimental results confirm that GraphTCN achieves noticeably better performance in terms of both efficiency and accuracy compared with state-of-the-art methods on various trajectory prediction benchmark datasets.
Recurrent Neural Network Control of a Hybrid Dynamic Transfemoral Prosthesis with EdgeDRNN Accelerator
Mar 05, 2020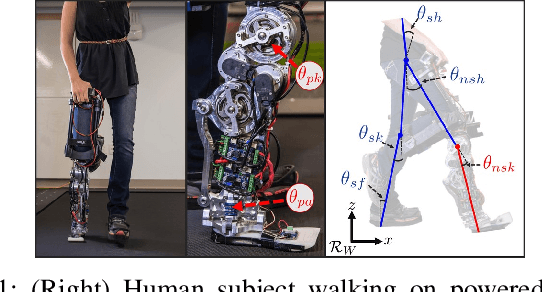
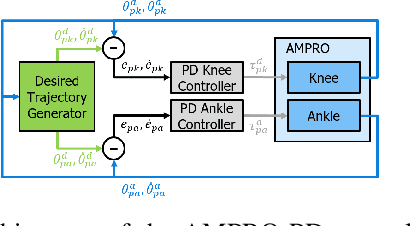
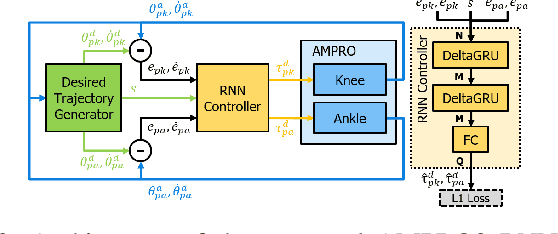
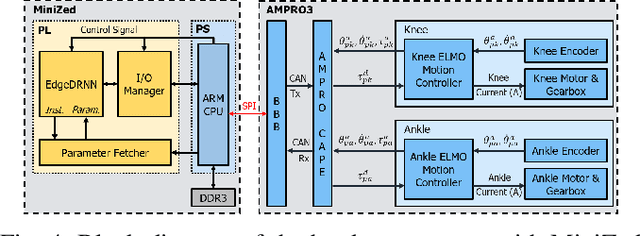
Lower leg prostheses could improve the life quality of amputees by increasing comfort and reducing energy to locomote, but currently control methods are limited in modulating behaviors based upon the human's experience. This paper describes the first steps toward learning complex controllers for dynamical robotic assistive devices. We provide the first example of behavioral cloning to control a powered transfemoral prostheses using a Gated Recurrent Unit (GRU) based recurrent neural network (RNN) running on a custom hardware accelerator that exploits temporal sparsity. The RNN is trained on data collected from the original prosthesis controller. The RNN inference is realized by a novel EdgeDRNN accelerator in real-time. Experimental results show that the RNN can replace the nominal PD controller to realize end-to-end control of the AMPRO3 prosthetic leg walking on flat ground and unforeseen slopes with comparable tracking accuracy. EdgeDRNN computes the RNN about 240 times faster than real time, opening the possibility of running larger networks for more complex tasks in the future. Implementing an RNN on this real-time dynamical system with impacts sets the ground work to incorporate other learned elements of the human-prosthesis system into prosthesis control.
Monitoring and Diagnosability of Perception Systems
May 27, 2020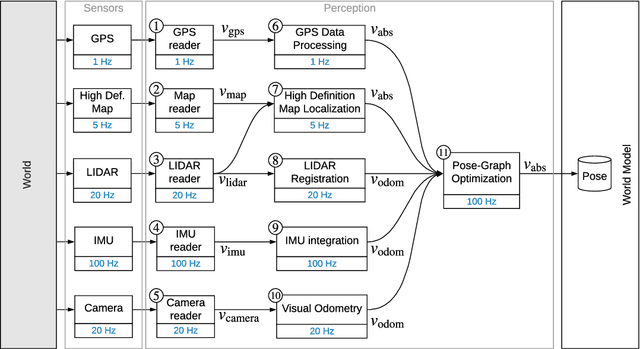
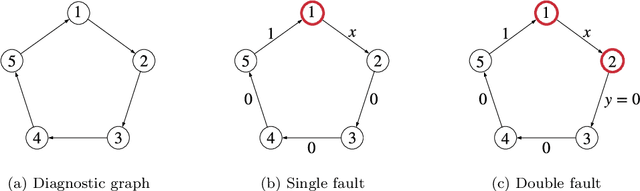
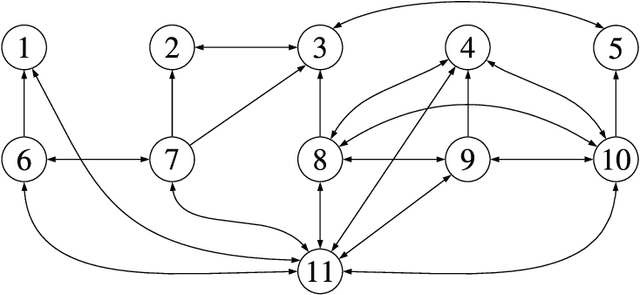
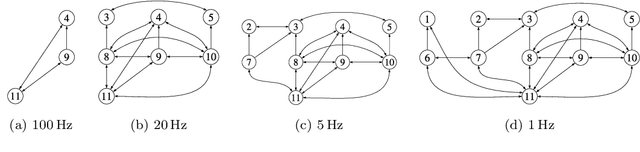
Perception is a critical component of high-integrity applications of robotics and autonomous systems, such as self-driving cars. In these applications, failure of perception systems may put human life at risk, and a broad adoption of these technologies relies on the development of methodologies to guarantee and monitor safe operation as well as detect and mitigate failures. Despite the paramount importance of perception systems, currently there is no formal approach for system-level monitoring. In this work, we propose a mathematical model for runtime monitoring and fault detection of perception systems. Towards this goal, we draw connections with the literature on self-diagnosability for multiprocessor systems, and generalize it to (i) account for modules with heterogeneous outputs, and (ii) add a temporal dimension to the problem, which is crucial to model realistic perception systems where modules interact over time. This contribution results in a graph-theoretic approach that, given a perception system, is able to detect faults at runtime and allows computing an upper-bound on the number of faulty modules that can be detected. Our second contribution is to show that the proposed monitoring approach can be elegantly described with the language of topos theory, which allows formulating diagnosability over arbitrary time intervals.
Generator Versus Segmentor: Pseudo-healthy Synthesis
Sep 12, 2020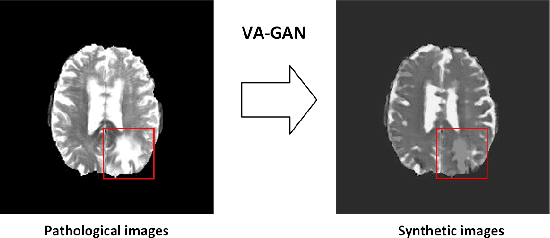
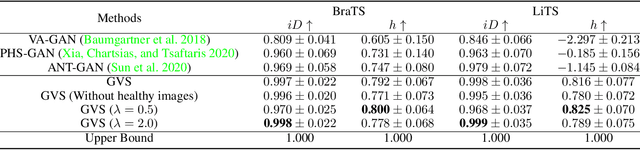
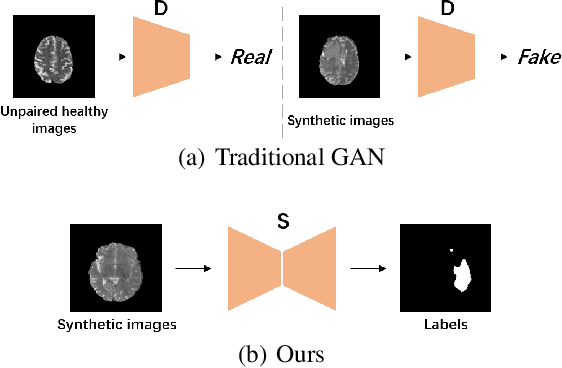
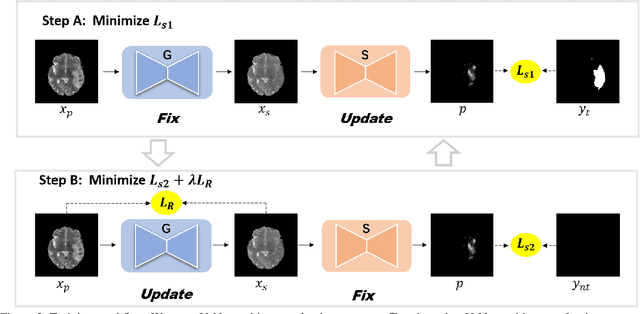
Pseudo-healthy synthesis is defined as synthesizing a subject-specific 'healthy' image from a pathological one, with applications ranging from segmentation to anomaly detection. In recent years, the existing GAN-based methods proposed for pseudo-healthy synthesis aim to eliminate the global differences between synthetic and healthy images. In this paper, we discuss the problems of these approaches, which are the style transfer and artifacts respectively. To address these problems, we consider the local differences between the lesions and normal tissue. To achieve this, we propose an adversarial training regime that alternatively trains a generator and a segmentor. The segmentor is trained to distinguish the synthetic lesions (i.e. the region in synthetic images corresponding to the lesions in the pathological ones) from the normal tissue, while the generator is trained to deceive the segmentor by transforming lesion regions into lesion-free-like ones and preserve the normal tissue at the same time. Qualitative and quantitative experimental results on public datasets BraTS and LiTS demonstrate that the proposed method outperforms state-of-the-art methods by preserving style and removing the artifacts. Our implementation is publicly available at https://github.com/Au3C2/Generator-Versus-Segmentor
Strategy for Boosting Pair Comparison and Improving Quality Assessment Accuracy
Oct 01, 2020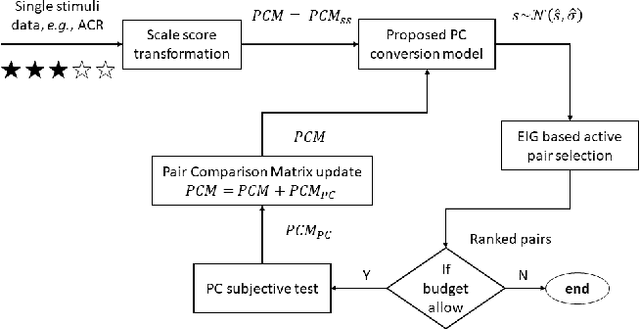
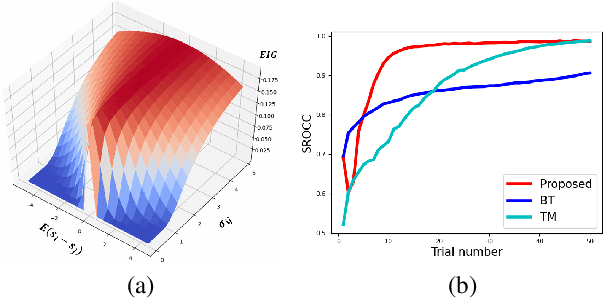
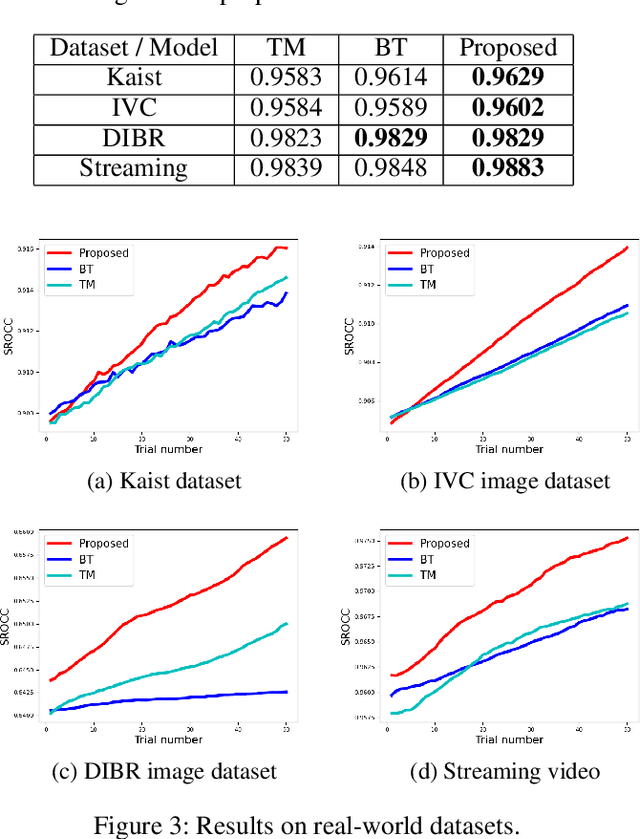
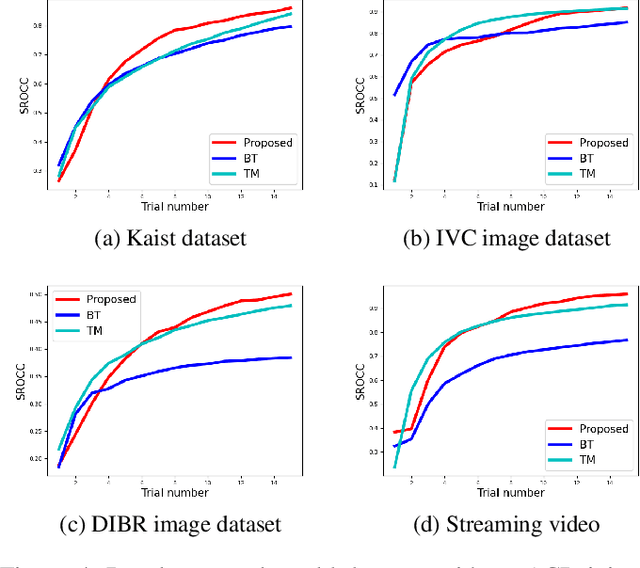
The development of rigorous quality assessment model relies on the collection of reliable subjective data, where the perceived quality of visual multimedia is rated by the human observers. Different subjective assessment protocols can be used according to the objectives, which determine the discriminability and accuracy of the subjective data. Single stimulus methodology, e.g., the Absolute Category Rating (ACR) has been widely adopted due to its simplicity and efficiency. However, Pair Comparison (PC) is of significant advantage over ACR in terms of discriminability. In addition, PC avoids the influence of observers' bias regarding their understanding of the quality scale. Nevertheless, full pair comparison is much more time-consuming. In this study, we therefore 1) employ a generic model to bridge the pair comparison data and ACR data, where the variance term could be recovered and the obtained information is more complete; 2) propose a fusion strategy to boost pair comparisons by utilizing the ACR results as initialization information; 3) develop a novel active batch sampling strategy based on Minimum Spanning Tree (MST) for PC. In such a way, the proposed methodology could achieve the same accuracy of pair comparison but with the compelxity as low as ACR. Extensive experimental results demonstrate the efficiency and accuracy of the proposed approach, which outperforms the state of the art approaches.