 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Adaptable Multi-Domain Language Model for Transformer ASR
Aug 14, 2020
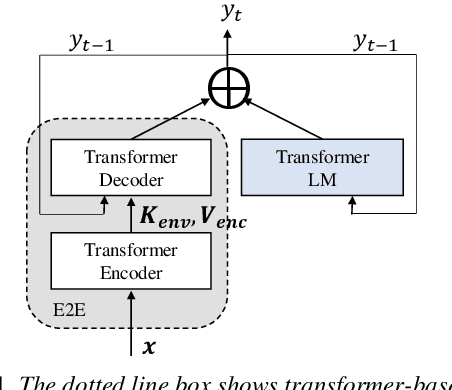
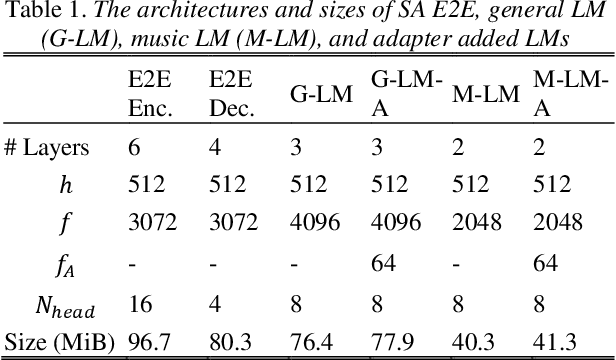
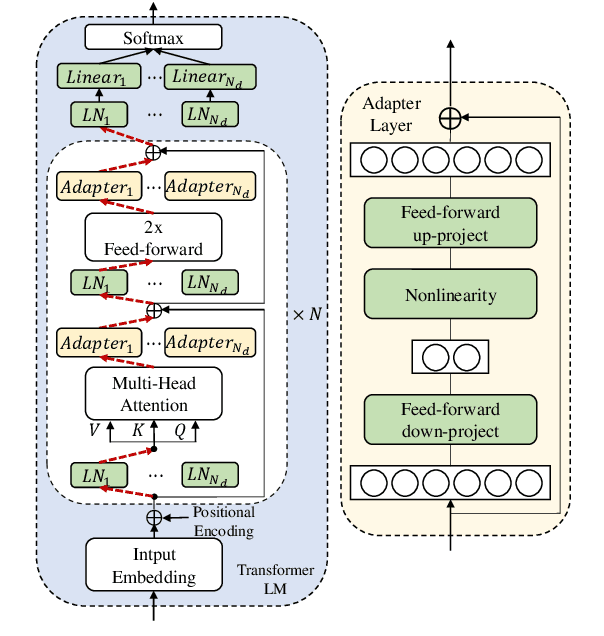
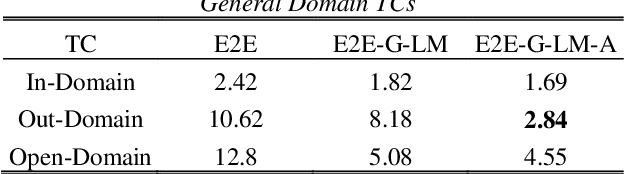
We propose an adapter based multi-domain Transformer based language model (LM) for Transformer ASR. The model consists of a big size common LM and small size adapters. The model can perform multi-domain adaptation with only the small size adapters and its related layers. The proposed model can reuse the full fine-tuned LM which is fine-tuned using all layers of an original model. The proposed LM can be expanded to new domains by adding about 2% of parameters for a first domain and 13% parameters for after second domain. The proposed model is also effective in reducing the model maintenance cost because it is possible to omit the costly and time-consuming common LM pre-training process. Using proposed adapter based approach, we observed that a general LM with adapter can outperform a dedicated music domain LM in terms of word error rate (WER).
Multi-Agent Reinforcement Learning in NOMA-aided UAV Networks for Cellular Offloading
Oct 18, 2020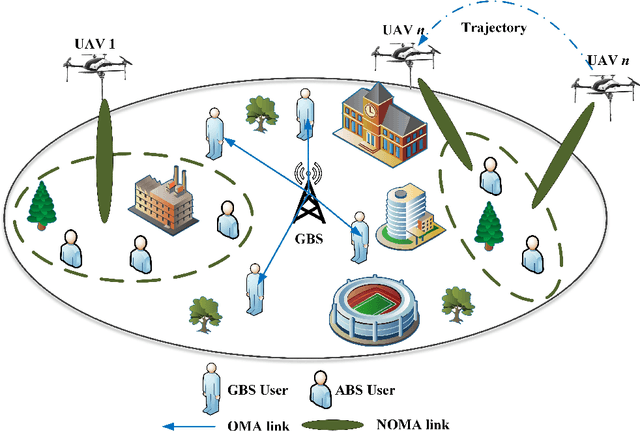
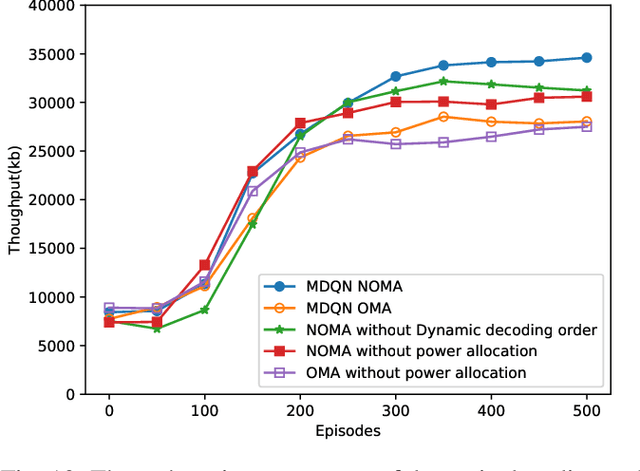
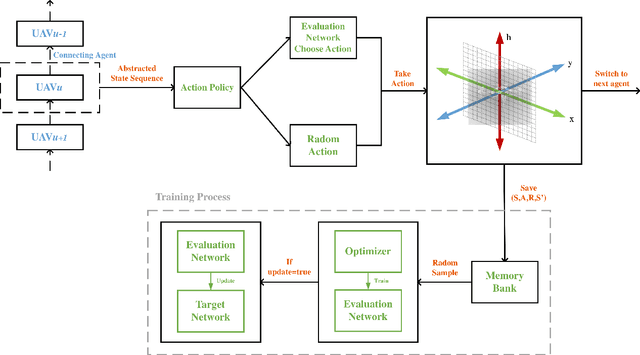
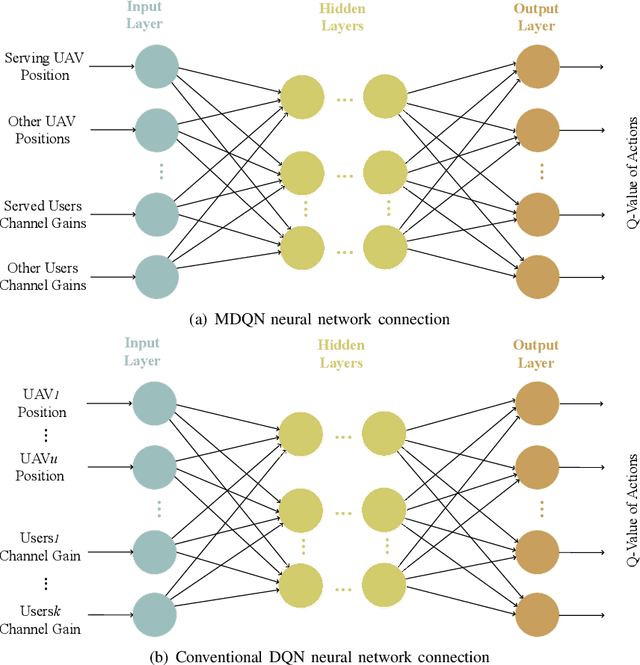
A novel framework is proposed for cellular offloading with the aid of multiple unmanned aerial vehicles (UAVs), while the non-orthogonal multiple access (NOMA) technique is employed at each UAV to further improve the spectrum efficiency of the wireless network. The optimization problem of joint three-dimensional (3D) trajectory design and power allocation is formulated for maximizing the throughput. Since ground mobile users are considered as roaming continuously, the UAVs need to be re-deployed timely based on the movement of users. In an effort to solve this pertinent dynamic problem, a K-means based clustering algorithm is first adopted for periodically partitioning users. Afterward, a mutual deep Q-network (MDQN) algorithm is proposed to jointly determine the optimal 3D trajectory and power allocation of UAVs. In contrast to the conventional DQN algorithm, the MDQN algorithm enables the experience of multi-agent to be input into a shared neural network to shorten the training time with the assistance of state abstraction. Numerical results demonstrate that: 1) the proposed MDQN algorithm is capable of converging under minor constraints and has a faster convergence rate than the conventional DQN algorithm in the multi-agent case; 2) The achievable sum rate of the NOMA enhanced UAV network is 23% superior to the case of orthogonal multiple access (OMA); 3) By designing the optimal 3D trajectory of UAVs with the aid of the MDON algorithm, the sum rate of the network enjoys 142% and 56% gains than that of invoking the circular trajectory and the 2D trajectory, respectively.
Artificial Intelligence Assisted Collaborative Edge Caching in Small Cell Networks
May 16, 2020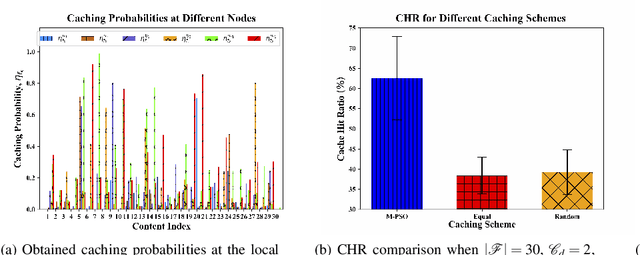
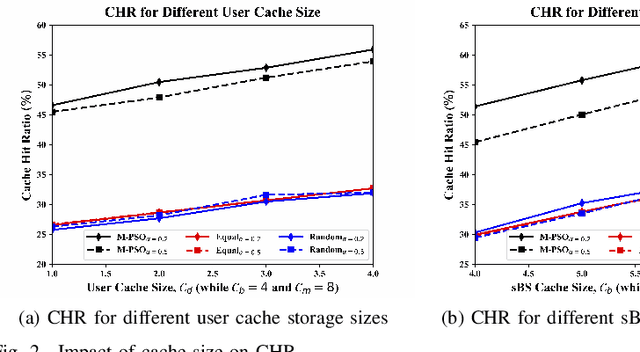
Edge caching is a new paradigm that has been exploited over the past several years to reduce the load for the core network and to enhance the content delivery performance. Many existing caching solutions only consider homogeneous caching placement due to the immense complexity associated with the heterogeneous caching models. Unlike these legacy modeling paradigms, this paper considers heterogeneous (1) content preference of the users and (2) caching models at the edge nodes. Besides, collaboration among these spatially distributed edge nodes is used aiming to maximize the cache hit ratio (CHR) in a two-tier heterogeneous network platform. However, due to complex combinatorial decision variables, the formulated problem is hard to solve in the polynomial time. Moreover, there does not even exist a ready-to-use tool or software to solve the problem. Thanks to artificial intelligence (AI), based on the methodologies of the conventional particle swarm optimization (PSO), we propose a modified PSO (M-PSO) to efficiently solve the complex constraint problem in a reasonable time. Using numerical analysis and simulation, we validate that the proposed algorithm significantly enhances the CHR performance when comparing to that of the existing baseline caching schemes.
Block-wise Image Transformation with Secret Key for Adversarially Robust Defense
Oct 02, 2020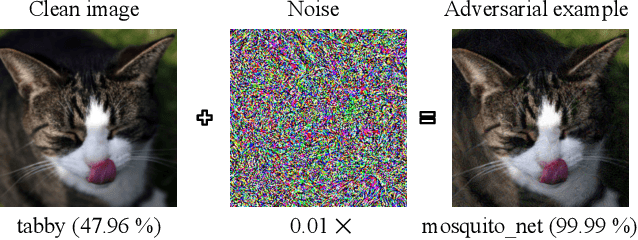
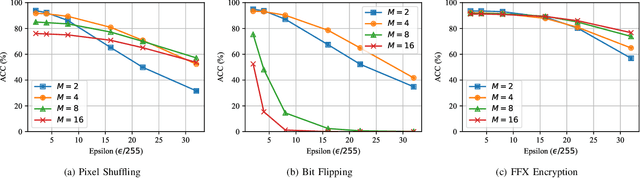
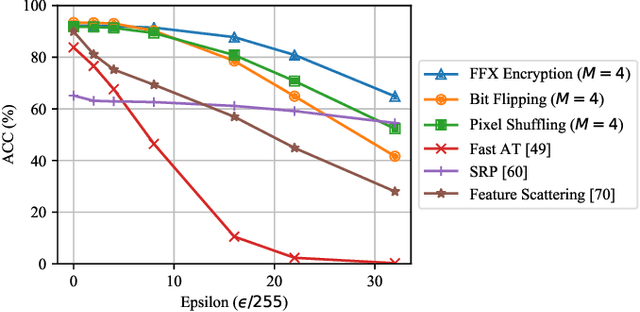
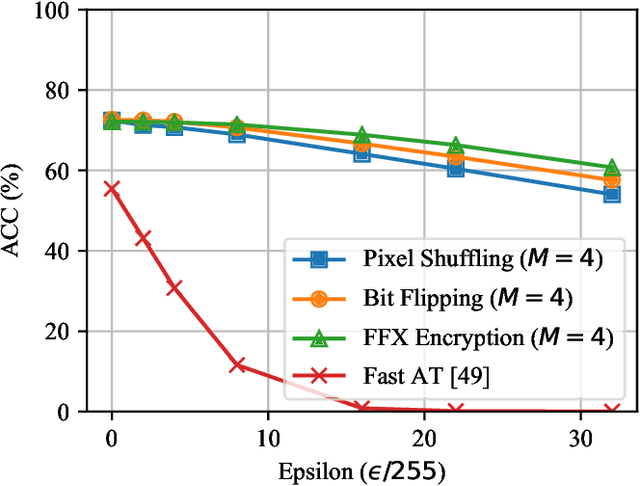
In this paper, we propose a novel defensive transformation that enables us to maintain a high classification accuracy under the use of both clean images and adversarial examples for adversarially robust defense. The proposed transformation is a block-wise preprocessing technique with a secret key to input images. We developed three algorithms to realize the proposed transformation: Pixel Shuffling, Bit Flipping, and FFX Encryption. Experiments were carried out on the CIFAR-10 and ImageNet datasets by using both black-box and white-box attacks with various metrics including adaptive ones. The results show that the proposed defense achieves high accuracy close to that of using clean images even under adaptive attacks for the first time. In the best-case scenario, a model trained by using images transformed by FFX Encryption (block size of 4) yielded an accuracy of 92.30% on clean images and 91.48% under PGD attack with a noise distance of 8/255, which is close to the non-robust accuracy (95.45%) for the CIFAR-10 dataset, and it yielded an accuracy of 72.18% on clean images and 71.43% under the same attack, which is also close to the standard accuracy (73.70%) for the ImageNet dataset. Overall, all three proposed algorithms are demonstrated to outperform state-of-the-art defenses including adversarial training whether or not a model is under attack.
Histogram of gradients of Time-Frequency Representations for Audio scene detection
Aug 20, 2015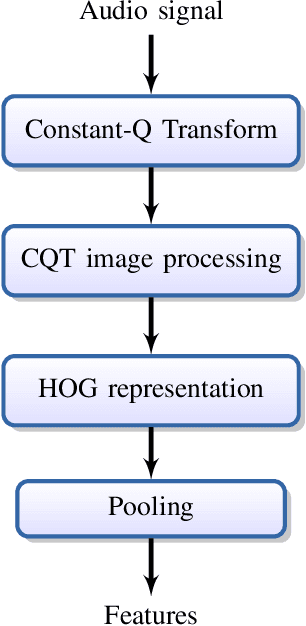
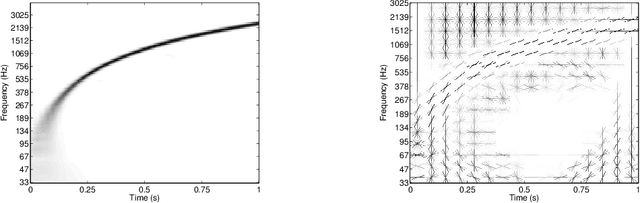
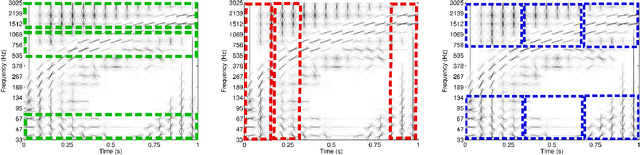
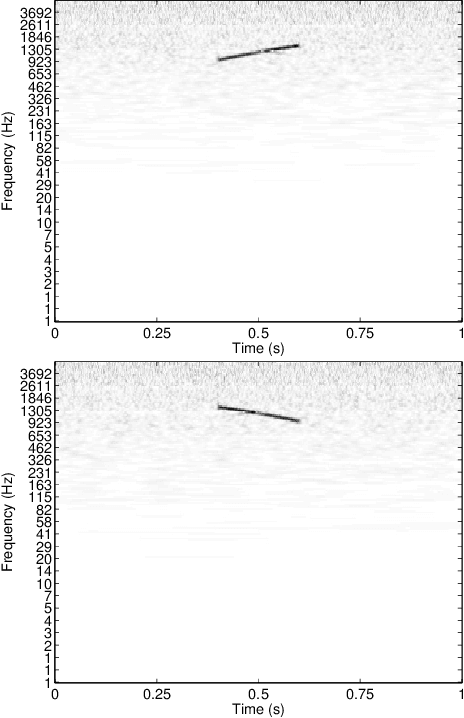
This paper addresses the problem of audio scenes classification and contributes to the state of the art by proposing a novel feature. We build this feature by considering histogram of gradients (HOG) of time-frequency representation of an audio scene. Contrarily to classical audio features like MFCC, we make the hypothesis that histogram of gradients are able to encode some relevant informations in a time-frequency {representation:} namely, the local direction of variation (in time and frequency) of the signal spectral power. In addition, in order to gain more invariance and robustness, histogram of gradients are locally pooled. We have evaluated the relevance of {the novel feature} by comparing its performances with state-of-the-art competitors, on several datasets, including a novel one that we provide, as part of our contribution. This dataset, that we make publicly available, involves $19$ classes and contains about $900$ minutes of audio scene recording. We thus believe that it may be the next standard dataset for evaluating audio scene classification algorithms. Our comparison results clearly show that our HOG-based features outperform its competitors
Skyline: Interactive In-Editor Computational Performance Profiling for Deep Neural Network Training
Aug 20, 2020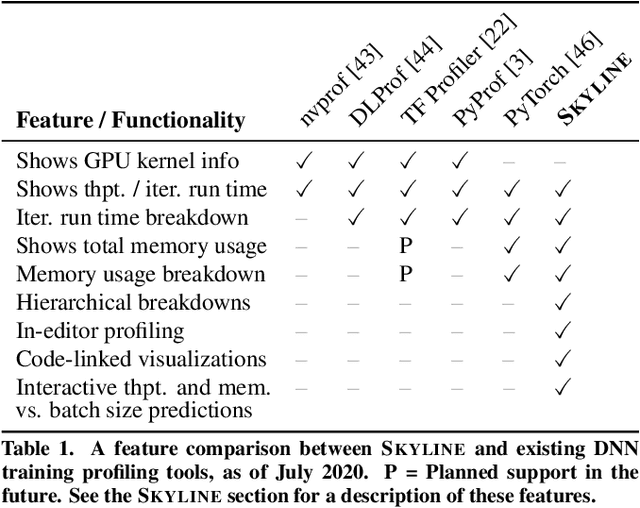
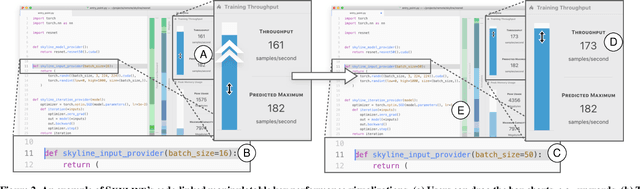
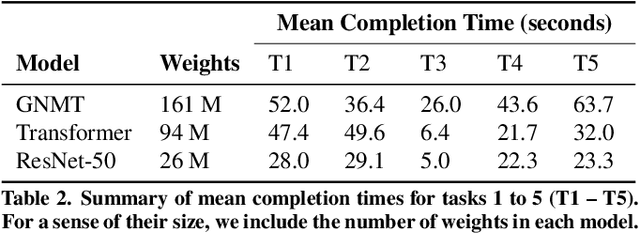
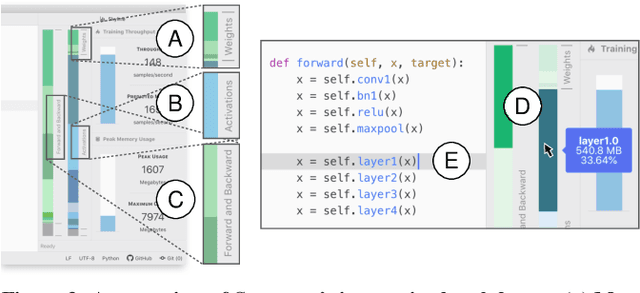
Training a state-of-the-art deep neural network (DNN) is a computationally-expensive and time-consuming process, which incentivizes deep learning developers to debug their DNNs for computational performance. However, effectively performing this debugging requires intimate knowledge about the underlying software and hardware systems---something that the typical deep learning developer may not have. To help bridge this gap, we present Skyline: a new interactive tool for DNN training that supports in-editor computational performance profiling, visualization, and debugging. Skyline's key contribution is that it leverages special computational properties of DNN training to provide (i) interactive performance predictions and visualizations, and (ii) directly manipulatable visualizations that, when dragged, mutate the batch size in the code. As an in-editor tool, Skyline allows users to leverage these diagnostic features to debug the performance of their DNNs during development. An exploratory qualitative user study of Skyline produced promising results; all the participants found Skyline to be useful and easy to use.
1st Place Solutions for Waymo Open Dataset Challenges - 2D and 3D Tracking
Jun 28, 2020
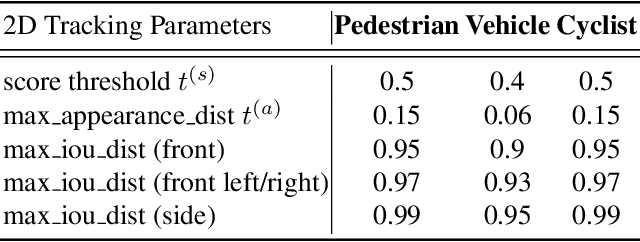
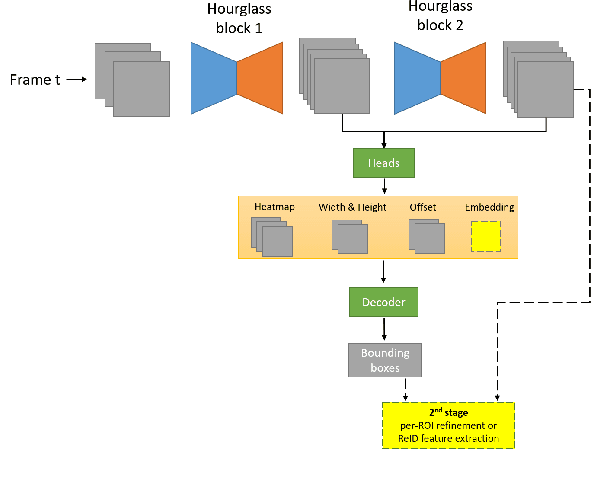
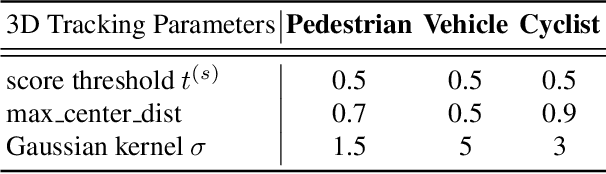
This technical report presents the online and real-time 2D and 3D multi-object tracking (MOT) algorithms that reached the 1st places on both Waymo Open Dataset 2D tracking and 3D tracking challenges. An efficient and pragmatic online tracking-by-detection framework named HorizonMOT is proposed for camera-based 2D tracking in the image space and LiDAR-based 3D tracking in the 3D world space. Within the tracking-by-detection paradigm, our trackers leverage our high-performing detectors used in the 2D/3D detection challenges and achieved 45.13% 2D MOTA/L2 and 63.45% 3D MOTA/L2 in the 2D/3D tracking challenges.
Constructing a Knowledge Graph from Unstructured Documents without External Alignment
Aug 20, 2020
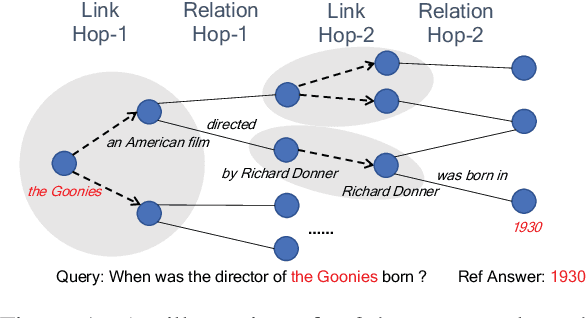
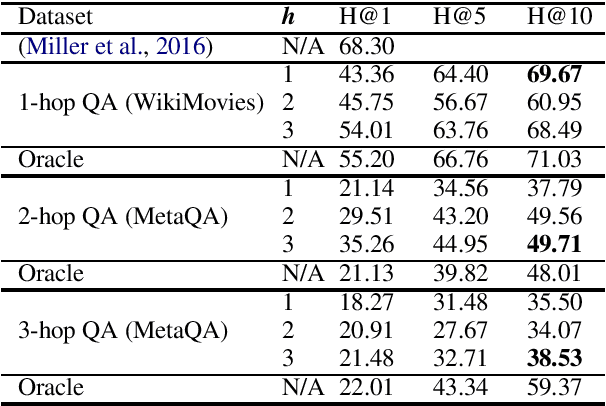

Knowledge graphs (KGs) are relevant to many NLP tasks, but building a reliable domain-specific KG is time-consuming and expensive. A number of methods for constructing KGs with minimized human intervention have been proposed, but still require a process to align into the human-annotated knowledge base. To overcome this issue, we propose a novel method to automatically construct a KG from unstructured documents that does not require external alignment and explore its use to extract desired information. To summarize our approach, we first extract knowledge tuples in their surface form from unstructured documents, encode them using a pre-trained language model, and link the surface-entities via the encoding to form the graph structure. We perform experiments with benchmark datasets such as WikiMovies and MetaQA. The experimental results show that our method can successfully create and search a KG with 18K documents and achieve 69.7% hits@10 (close to an oracle model) on a query retrieval task.
The Monte Carlo Transformer: a stochastic self-attention model for sequence prediction
Jul 15, 2020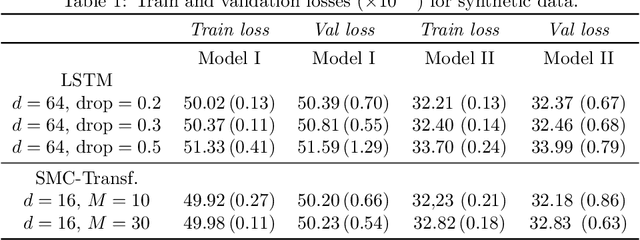
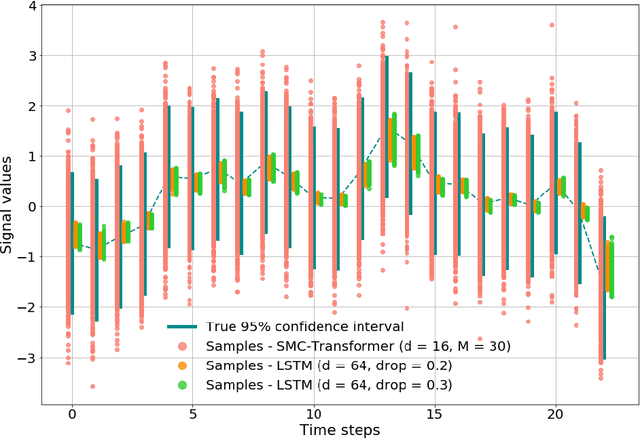
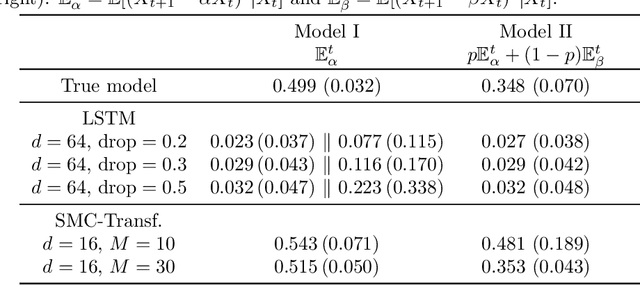
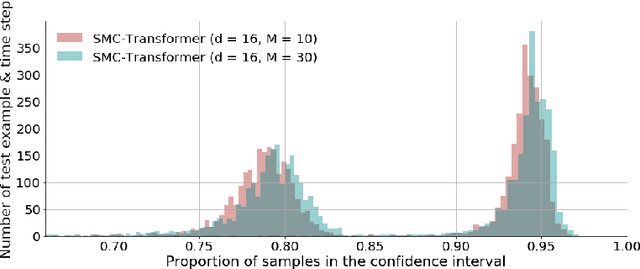
This paper introduces the Sequential Monte Carlo Transformer, an original approach that naturally captures the observations distribution in a recurrent architecture. The keys, queries, values and attention vectors of the network are considered as the unobserved stochastic states of its hidden structure. This generative model is such that at each time step the received observation is a random function of these past states in a given attention window. In this general state-space setting, we use Sequential Monte Carlo methods to approximate the posterior distributions of the states given the observations, and then to estimate the gradient of the log-likelihood. We thus propose a generative model providing a predictive distribution, instead of a single-point estimate.
An embedded deep learning system for augmented reality in firefighting applications
Sep 22, 2020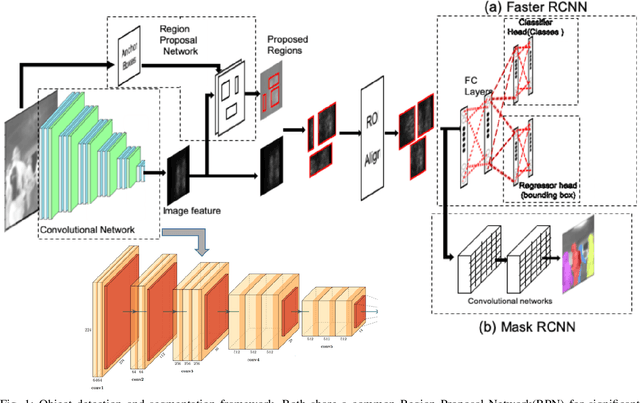
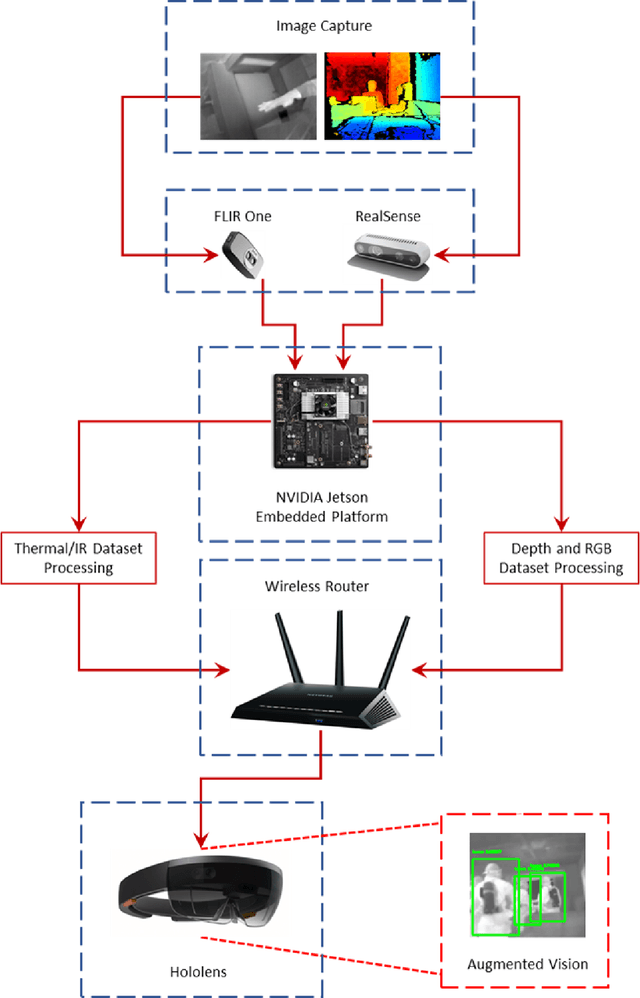


Firefighting is a dynamic activity, in which numerous operations occur simultaneously. Maintaining situational awareness (i.e., knowledge of current conditions and activities at the scene) is critical to the accurate decision-making necessary for the safe and successful navigation of a fire environment by firefighters. Conversely, the disorientation caused by hazards such as smoke and extreme heat can lead to injury or even fatality. This research implements recent advancements in technology such as deep learning, point cloud and thermal imaging, and augmented reality platforms to improve a firefighter's situational awareness and scene navigation through improved interpretation of that scene. We have designed and built a prototype embedded system that can leverage data streamed from cameras built into a firefighter's personal protective equipment (PPE) to capture thermal, RGB color, and depth imagery and then deploy already developed deep learning models to analyze the input data in real time. The embedded system analyzes and returns the processed images via wireless streaming, where they can be viewed remotely and relayed back to the firefighter using an augmented reality platform that visualizes the results of the analyzed inputs and draws the firefighter's attention to objects of interest, such as doors and windows otherwise invisible through smoke and flames.