 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Clinically Translatable Direct Patlak Reconstruction from Dynamic PET with Motion Correction Using Convolutional Neural Network
Sep 13, 2020
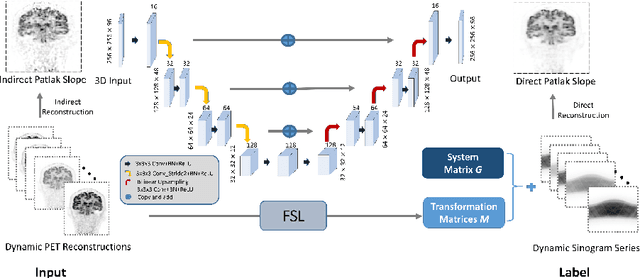

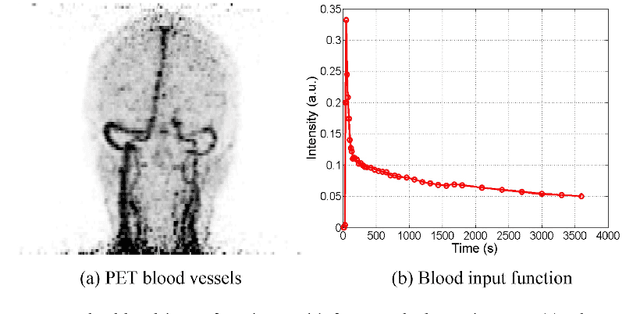
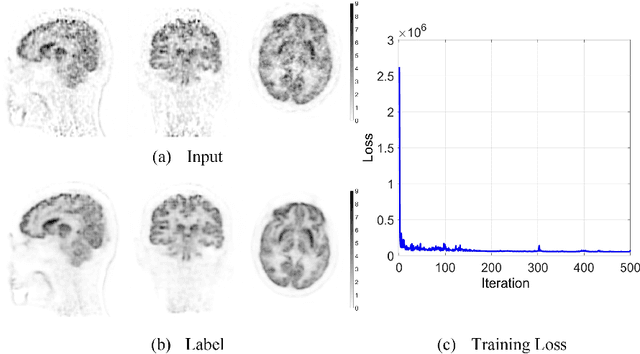
Patlak model is widely used in 18F-FDG dynamic positron emission tomography (PET) imaging, where the estimated parametric images reveal important biochemical and physiology information. Because of better noise modeling and more information extracted from raw sinogram, direct Patlak reconstruction gains its popularity over the indirect approach which utilizes reconstructed dynamic PET images alone. As the prerequisite of direct Patlak methods, raw data from dynamic PET are rarely stored in clinics and difficult to obtain. In addition, the direct reconstruction is time-consuming due to the bottleneck of multiple-frame reconstruction. All of these impede the clinical adoption of direct Patlak reconstruction.In this work, we proposed a data-driven framework which maps the dynamic PET images to the high-quality motion-corrected direct Patlak images through a convolutional neural network. For the patient motion during the long period of dynamic PET scan, we combined the correction with the backward/forward projection in direct reconstruction to better fit the statistical model. Results based on fifteen clinical 18F-FDG dynamic brain PET datasets demonstrates the superiority of the proposed framework over Gaussian, nonlocal mean and BM4D denoising, regarding the image bias and contrast-to-noise ratio.
Bayesian Neural Architecture Search using A Training-Free Performance Metric
Jan 29, 2020


Recurrent neural networks (RNNs) are a powerful approach for time series prediction. However, their performance is strongly affected by their architecture and hyperparameter settings. The architecture optimization of RNNs is a time-consuming task, where the search space is typically a mixture of real, integer and categorical values. To allow for shrinking and expanding the size of the network, the representation of architectures often has a variable length. In this paper, we propose to tackle the architecture optimization problem with a variant of the Bayesian Optimization (BO) algorithm. To reduce the evaluation time of candidate architectures the Mean Absolute Error Random Sampling (MRS), a training-free method to estimate the network performance, is adopted as the objective function for BO. Also, we propose three fixed-length encoding schemes to cope with the variable-length architecture representation. The result is a new perspective on accurate and efficient design of RNNs, that we validate on three problems. Our findings show that 1) the BO algorithm can explore different network architectures using the proposed encoding schemes and successfully designs well-performing architectures, and 2) the optimization time is significantly reduced by using MRS, without compromising the performance as compared to the architectures obtained from the actual training procedure.
Unsupervised Audio Source Separation using Generative Priors
May 28, 2020
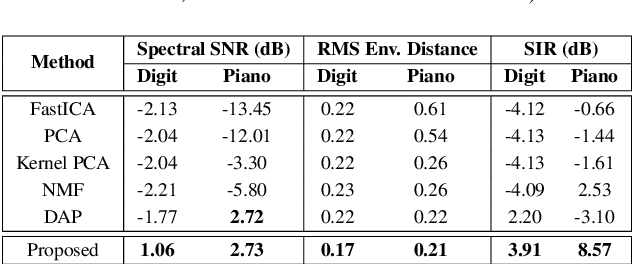
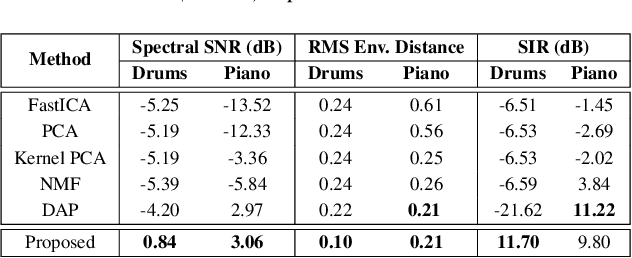
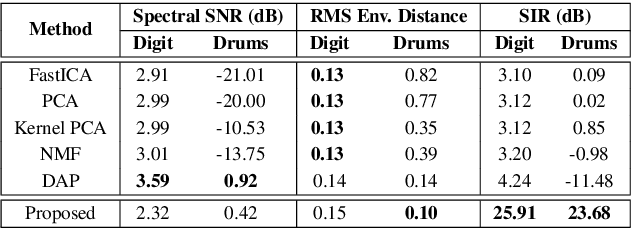
State-of-the-art under-determined audio source separation systems rely on supervised end-end training of carefully tailored neural network architectures operating either in the time or the spectral domain. However, these methods are severely challenged in terms of requiring access to expensive source level labeled data and being specific to a given set of sources and the mixing process, which demands complete re-training when those assumptions change. This strongly emphasizes the need for unsupervised methods that can leverage the recent advances in data-driven modeling, and compensate for the lack of labeled data through meaningful priors. To this end, we propose a novel approach for audio source separation based on generative priors trained on individual sources. Through the use of projected gradient descent optimization, our approach simultaneously searches in the source-specific latent spaces to effectively recover the constituent sources. Though the generative priors can be defined in the time domain directly, e.g. WaveGAN, we find that using spectral domain loss functions for our optimization leads to good-quality source estimates. Our empirical studies on standard spoken digit and instrument datasets clearly demonstrate the effectiveness of our approach over classical as well as state-of-the-art unsupervised baselines.
How to Find a Point in the Convex Hull Privately
Mar 30, 2020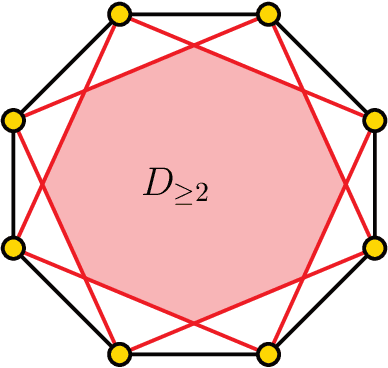
We study the question of how to compute a point in the convex hull of an input set $S$ of $n$ points in ${\mathbb R}^d$ in a differentially private manner. This question, which is trivial non-privately, turns out to be quite deep when imposing differential privacy. In particular, it is known that the input points must reside on a fixed finite subset $G\subseteq{\mathbb R}^d$, and furthermore, the size of $S$ must grow with the size of $G$. Previous works focused on understanding how $n$ needs to grow with $|G|$, and showed that $n=O\left(d^{2.5}\cdot8^{\log^*|G|}\right)$ suffices (so $n$ does not have to grow significantly with $|G|$). However, the available constructions exhibit running time at least $|G|^{d^2}$, where typically $|G|=X^d$ for some (large) discretization parameter $X$, so the running time is in fact $\Omega(X^{d^3})$. In this paper we give a differentially private algorithm that runs in $O(n^d)$ time, assuming that $n=\Omega(d^4\log X)$. To get this result we study and exploit some structural properties of the Tukey levels (the regions $D_{\ge k}$ consisting of points whose Tukey depth is at least $k$, for $k=0,1,...$). In particular, we derive lower bounds on their volumes for point sets $S$ in general position, and develop a rather subtle mechanism for handling point sets $S$ in degenerate position (where the deep Tukey regions have zero volume). A naive approach to the construction of the Tukey regions requires $n^{O(d^2)}$ time. To reduce the cost to $O(n^d)$, we use an approximation scheme for estimating the volumes of the Tukey regions (within their affine spans in case of degeneracy), and for sampling a point from such a region, a scheme that is based on the volume estimation framework of Lov\'asz and Vempala (FOCS 2003) and of Cousins and Vempala (STOC 2015). Making this framework differentially private raises a set of technical challenges that we address.
GECKO: Reconciling Privacy, Accuracy and Efficiency in Embedded Deep Learning
Oct 02, 2020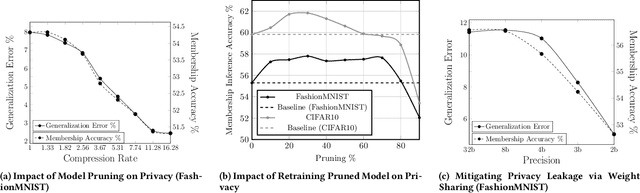
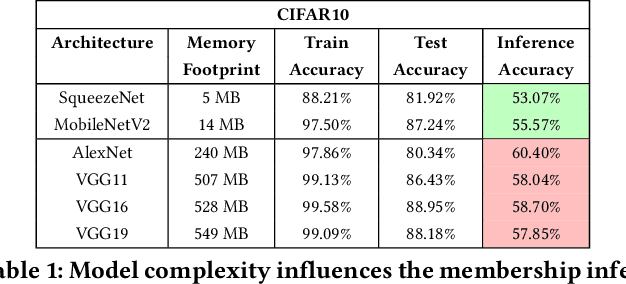
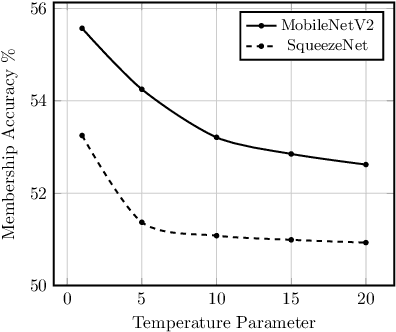
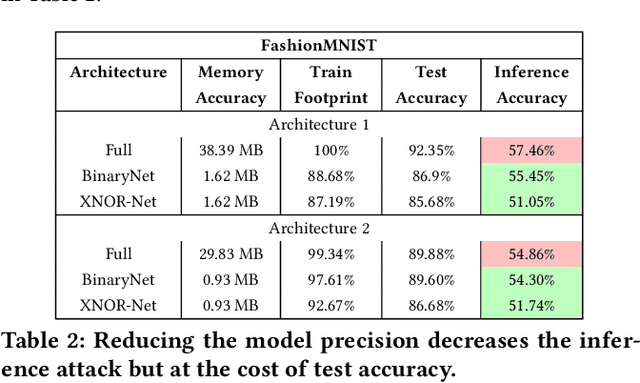
Embedded systems demand on-device processing of data using Neural Networks (NNs) while conforming to the memory, power and computation constraints, leading to an efficiency and accuracy tradeoff. To bring NNs to edge devices, several optimizations such as model compression through pruning, quantization, and off-the-shelf architectures with efficient design have been extensively adopted. These algorithms when deployed to real world sensitive applications, requires to resist inference attacks to protect privacy of users training data. However, resistance against inference attacks is not accounted for designing NN models for IoT. In this work, we analyse the three-dimensional privacy-accuracy-efficiency tradeoff in NNs for IoT devices and propose Gecko training methodology where we explicitly add resistance to private inferences as a design objective. We optimize the inference-time memory, computation, and power constraints of embedded devices as a criterion for designing NN architecture while also preserving privacy. We choose quantization as design choice for highly efficient and private models. This choice is driven by the observation that compressed models leak more information compared to baseline models while off-the-shelf efficient architectures indicate poor efficiency and privacy tradeoff. We show that models trained using Gecko methodology are comparable to prior defences against black-box membership attacks in terms of accuracy and privacy while providing efficiency.
Control Framework for a Hybrid-steel Bridge Inspection Robot
Sep 01, 2020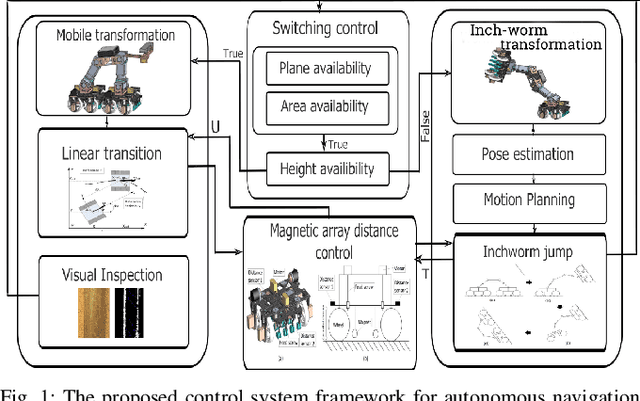
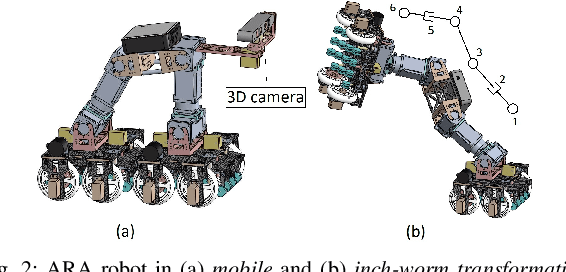
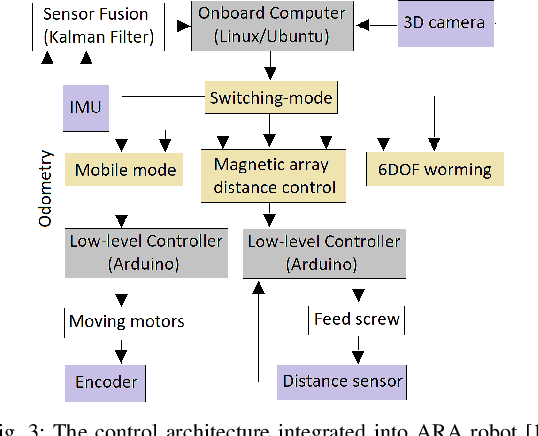
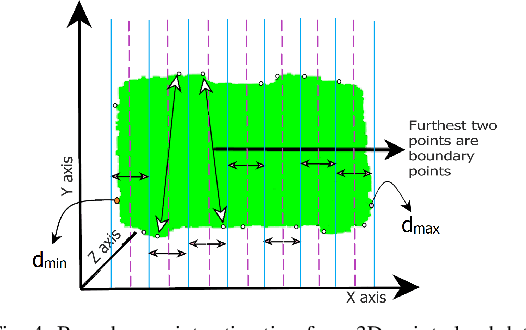
Autonomous navigation of steel bridge inspection robots is essential for proper maintenance. The majority of existing robotic solutions for bridge inspection require human intervention to assist in the control and navigation. In this paper, a control system framework has been proposed for a previously designed ARA robot [1], which facilitates autonomous real-time navigation and minimizes human involvement. The mechanical design and control framework of ARA robot enables two different configurations, namely the mobile and inch-worm transformation. In addition, a switching control was developed with 3D point clouds of steel surfaces as the input which allows the robot to switch between mobile and inch-worm transformation. The surface availability algorithm (considers plane, area, and height) of the switching control enables the robot to perform inch-worm jumps autonomously. Themobiletransformationallows the robot to move on continuous steel surfaces and perform visual inspection of steel bridge structures. Practical experiments on actual steel bridge structures highlight the effective performance of ARA robot with the proposed control framework for autonomous navigation during a visual inspection of steel bridges.
Lifelong Control of Off-grid Microgrid with Model Based Reinforcement Learning
May 16, 2020
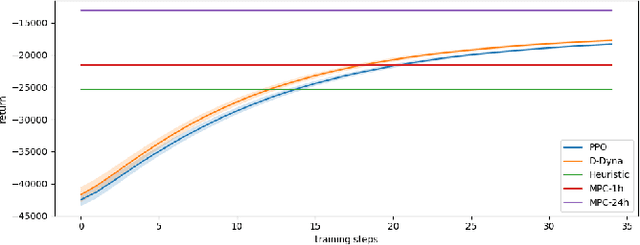
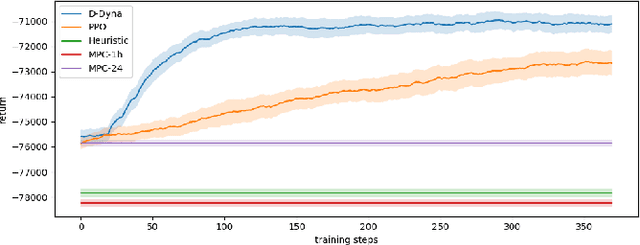
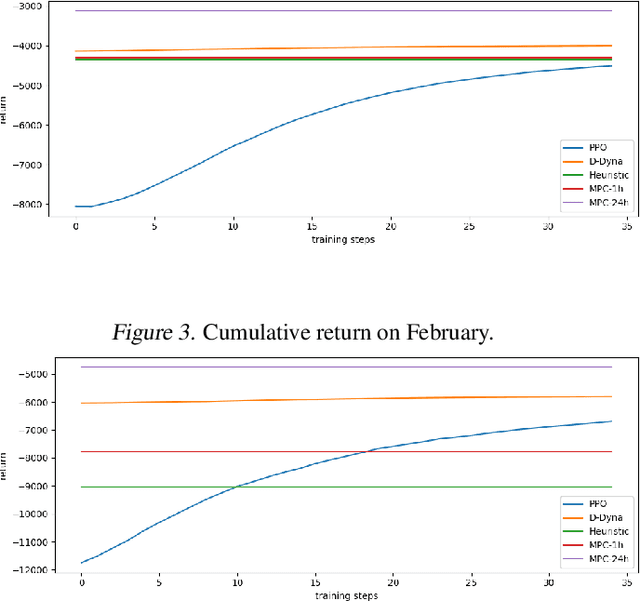
The lifelong control problem of an off-grid microgrid is composed of two tasks, namely estimation of the condition of the microgrid devices and operational planning accounting for the uncertainties by forecasting the future consumption and the renewable production. The main challenge for the effective control arises from the various changes that take place over time. In this paper, we present an open-source reinforcement framework for the modeling of an off-grid microgrid for rural electrification. The lifelong control problem of an isolated microgrid is formulated as a Markov Decision Process (MDP). We categorize the set of changes that can occur in progressive and abrupt changes. We propose a novel model based reinforcement learning algorithm that is able to address both types of changes. In particular the proposed algorithm demonstrates generalisation properties, transfer capabilities and better robustness in case of fast-changing system dynamics. The proposed algorithm is compared against a rule-based policy and a model predictive controller with look-ahead. The results show that the trained agent is able to outperform both benchmarks in the lifelong setting where the system dynamics are changing over time.
Deep learning denoising for EOG artifacts removal from EEG signals
Sep 12, 2020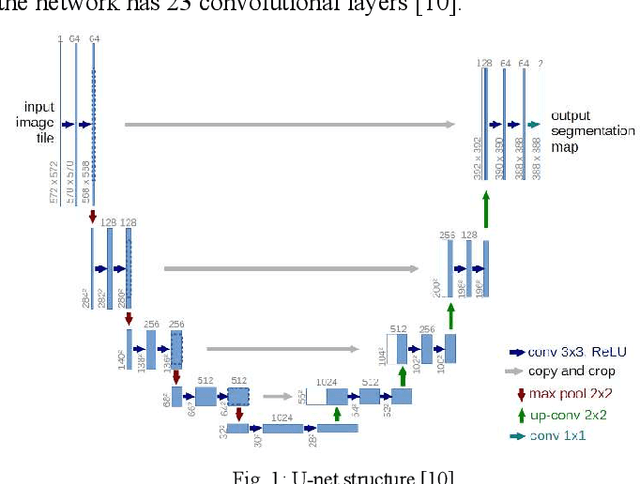
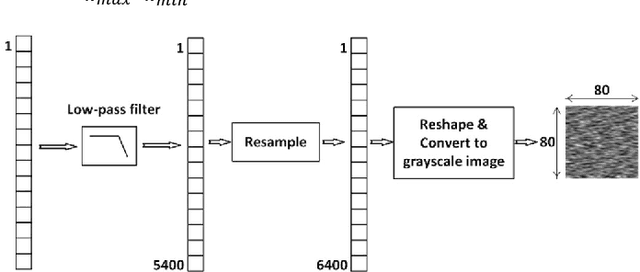

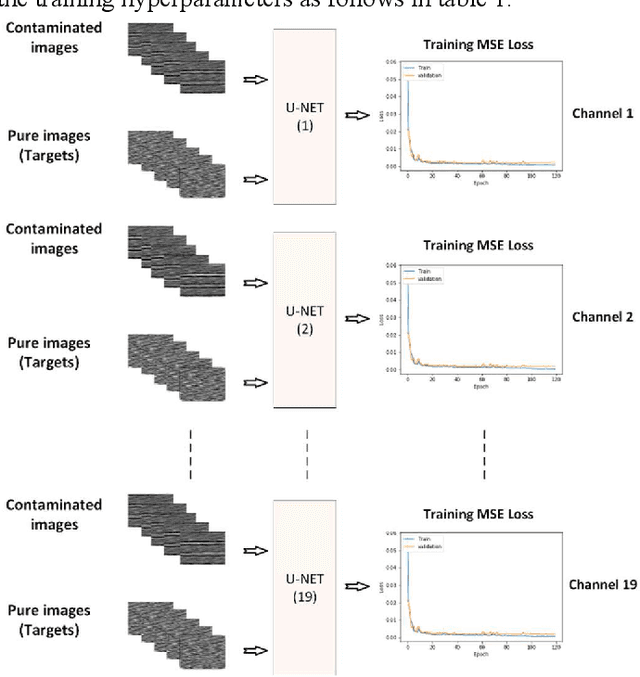
There are many sources of interference encountered in the electroencephalogram (EEG) recordings, specifically ocular, muscular, and cardiac artifacts. Rejection of EEG artifacts is an essential process in EEG analysis since such artifacts cause many problems in EEG signals analysis. One of the most challenging issues in EEG denoising processes is removing the ocular artifacts where Electrooculographic (EOG), and EEG signals have an overlap in both frequency and time domains. In this paper, we build and train a deep learning model to deal with this challenge and remove the ocular artifacts effectively. In the proposed scheme, we convert each EEG signal to an image to be fed to a U-NET model, which is a deep learning model usually used in image segmentation tasks. We proposed three different schemes and made our U-NET based models learn to purify contaminated EEG signals similar to the process used in the image segmentation process. The results confirm that one of our schemes can achieve a reliable and promising accuracy to reduce the Mean square error between the target signal (Pure EEGs) and the predicted signal (Purified EEGs).
Incremental Text to Speech for Neural Sequence-to-Sequence Models using Reinforcement Learning
Aug 07, 2020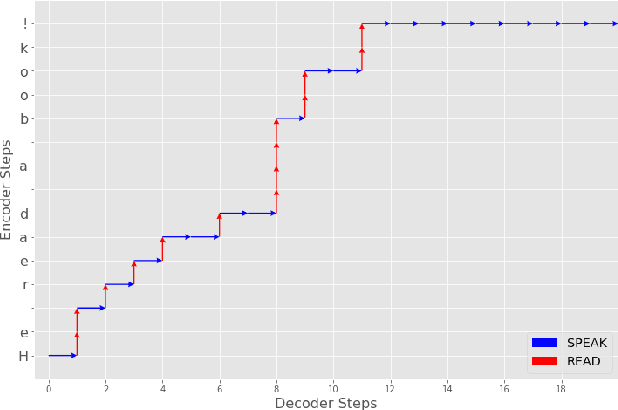

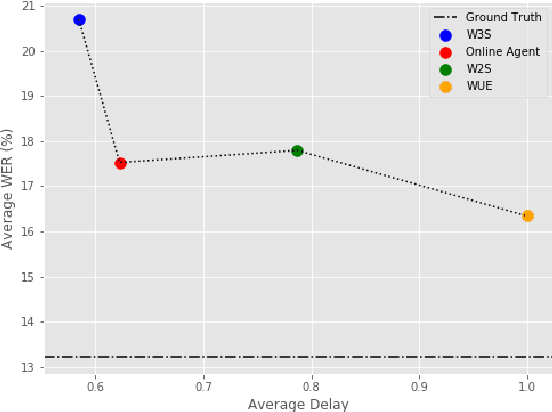
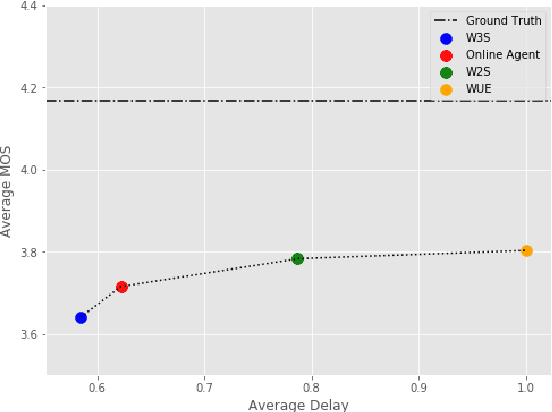
Modern approaches to text to speech require the entire input character sequence to be processed before any audio is synthesised. This latency limits the suitability of such models for time-sensitive tasks like simultaneous interpretation. Interleaving the action of reading a character with that of synthesising audio reduces this latency. However, the order of this sequence of interleaved actions varies across sentences, which raises the question of how the actions should be chosen. We propose a reinforcement learning based framework to train an agent to make this decision. We compare our performance against that of deterministic, rule-based systems. Our results demonstrate that our agent successfully balances the trade-off between the latency of audio generation and the quality of synthesised audio. More broadly, we show that neural sequence-to-sequence models can be adapted to run in an incremental manner.
Adaptable Multi-Domain Language Model for Transformer ASR
Aug 14, 2020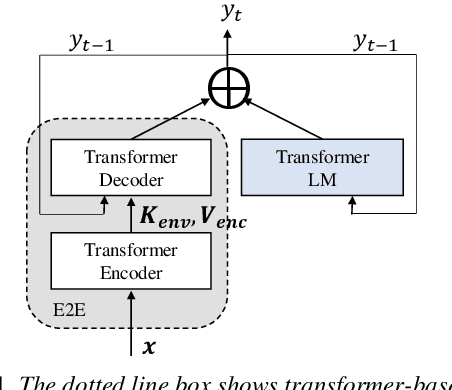
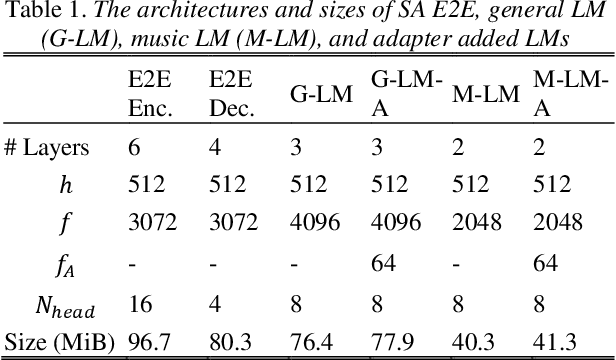
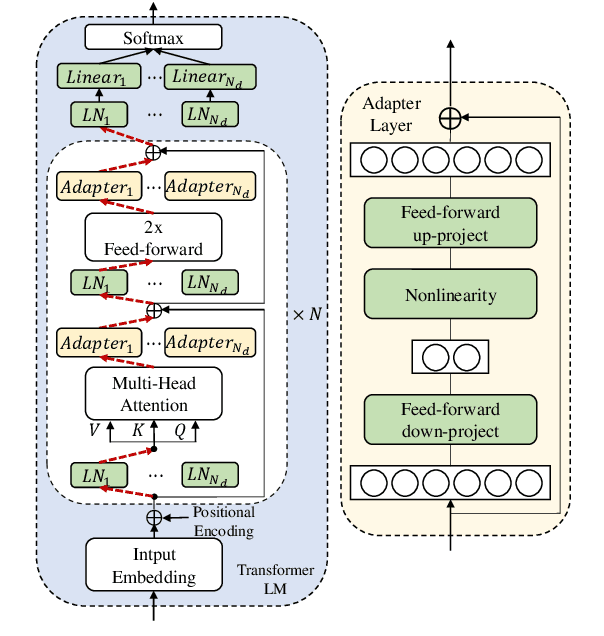
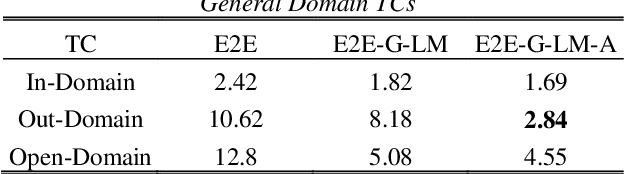
We propose an adapter based multi-domain Transformer based language model (LM) for Transformer ASR. The model consists of a big size common LM and small size adapters. The model can perform multi-domain adaptation with only the small size adapters and its related layers. The proposed model can reuse the full fine-tuned LM which is fine-tuned using all layers of an original model. The proposed LM can be expanded to new domains by adding about 2% of parameters for a first domain and 13% parameters for after second domain. The proposed model is also effective in reducing the model maintenance cost because it is possible to omit the costly and time-consuming common LM pre-training process. Using proposed adapter based approach, we observed that a general LM with adapter can outperform a dedicated music domain LM in terms of word error rate (WER).