 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sanity-Checking Pruning Methods: Random Tickets can Win the Jackpot
Sep 22, 2020


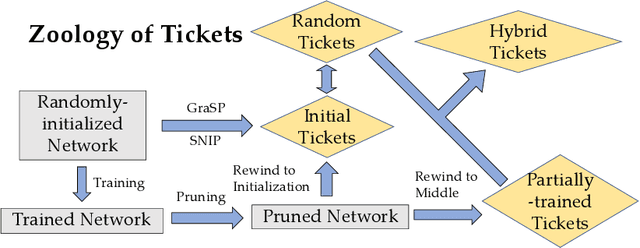

Network pruning is a method for reducing test-time computational resource requirements with minimal performance degradation. Conventional wisdom of pruning algorithms suggests that: (1) Pruning methods exploit information from training data to find good subnetworks; (2) The architecture of the pruned network is crucial for good performance. In this paper, we conduct sanity checks for the above beliefs on several recent unstructured pruning methods and surprisingly find that: (1) A set of methods which aims to find good subnetworks of the randomly-initialized network (which we call "initial tickets"), hardly exploits any information from the training data; (2) For the pruned networks obtained by these methods, randomly changing the preserved weights in each layer, while keeping the total number of preserved weights unchanged per layer, does not affect the final performance. These findings inspire us to choose a series of simple \emph{data-independent} prune ratios for each layer, and randomly prune each layer accordingly to get a subnetwork (which we call "random tickets"). Experimental results show that our zero-shot random tickets outperforms or attains similar performance compared to existing "initial tickets". In addition, we identify one existing pruning method that passes our sanity checks. We hybridize the ratios in our random ticket with this method and propose a new method called "hybrid tickets", which achieves further improvement.
A divide-and-conquer algorithm for quantum state preparation
Aug 04, 2020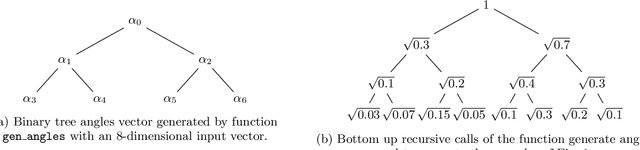
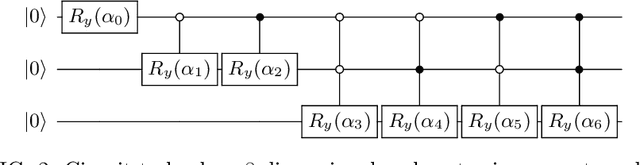
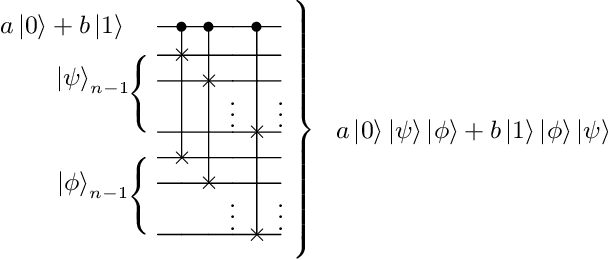
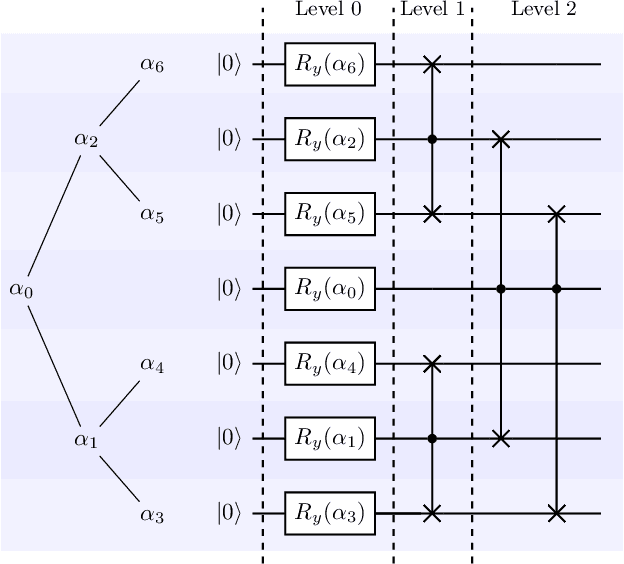
Advantages in several fields of research and industry are expected with the rise of quantum computers. However, the computational cost to load classical data in quantum computers can impose restrictions on possible quantum speedups. Known algorithms to create arbitrary quantum states require quantum circuits with depth O(N) to load an N-dimensional vector. Here, we show that it is possible to load an N-dimensional vector with a quantum circuit with polylogarithmic depth and entangled information in ancillary qubits. Results show that we can efficiently load data in quantum devices using a divide-and-conquer strategy to exchange computational time for space. We demonstrate a proof of concept on a real quantum device and present two applications for quantum machine learning. We expect that this new loading strategy allows the quantum speedup of tasks that require to load a significant volume of information to quantum devices.
Graphing Contributions in Natural Language Processing Research: Intra-Annotator Agreement on a Trial Dataset
Oct 09, 2020
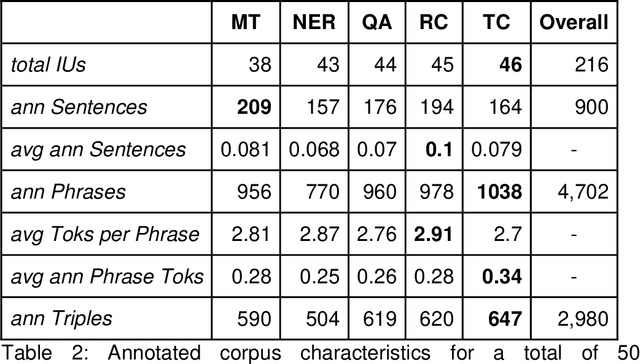
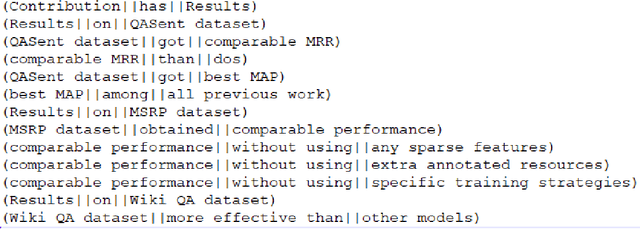
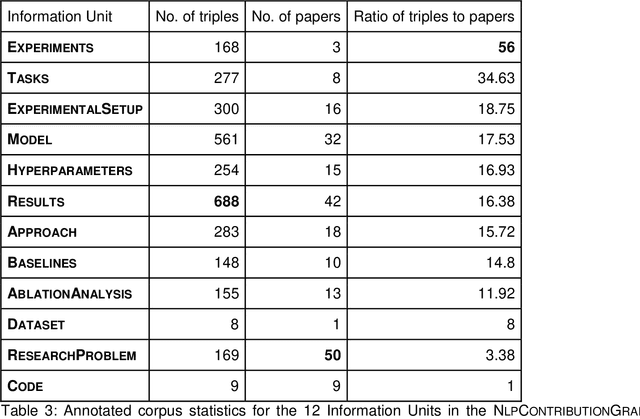
Purpose: To stabilize the NLPContributionGraph scheme for the surface structuring of contributions information in Natural Language Processing (NLP) scholarly articles via a two-stage annotation methodology: first stage - to define the scheme; and second stage - to stabilize the graphing model. Approach: Re-annotate, a second time, the contributions-pertinent information across 50 prior-annotated NLP scholarly articles in terms of a data pipeline comprising: contribution-centered sentences, phrases, and triples. To this end specifically, care was taken in the second annotation stage to reduce annotation noise while formulating the guidelines for our proposed novel NLP contributions structuring scheme. Findings: The application of NLPContributionGraph on the 50 articles resulted in finally in a dataset of 900 contribution-focused sentences, 4,702 contribution-information-centered phrases, and 2,980 surface-structured triples. The intra-annotation agreement between the first and second stages, in terms of F1, was 67.92% for sentences, 41.82% for phrases, and 22.31% for triples indicating that with an increased granularity of the information, the annotation decision variance is greater. Practical Implications: Demonstrate NLPContributionGraph data integrated in the Open Research Knowledge Graph (ORKG), a next-generation KG-based digital library with compute enabled over structured scholarly knowledge, as a viable aid to assist researchers in their day-to-day tasks. Value: NLPContributionGraph is a novel scheme to obtain research contribution-centered graphs from NLP articles which to the best of our knowledge does not exist in the community. And our quantitative evaluations over the two-stage annotation tasks offer insights into task difficulty.
Cable Estimation-Based Control for Wire-Borne Underactuated Brachiating Robots: A Combined Direct-Indirect Adaptive Robust Approach
Aug 11, 2020
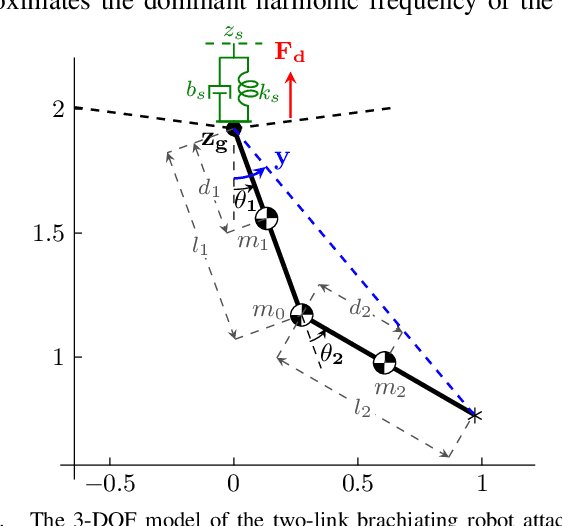
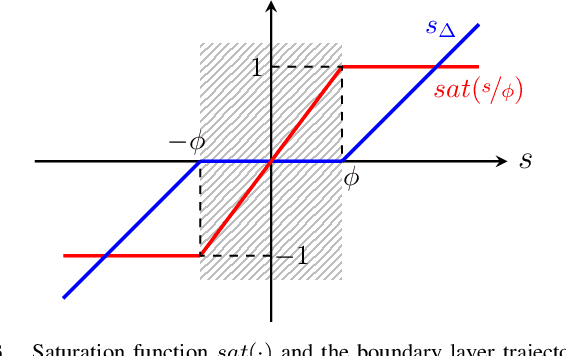
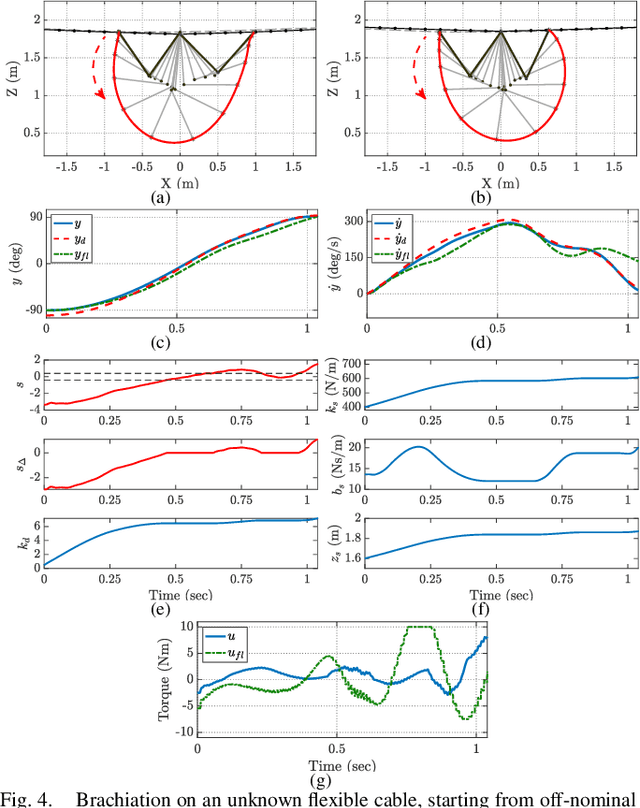
In this paper, we present an online adaptive robust control framework for underactuated brachiating robots traversing flexible cables. Since the dynamic model of a flexible body is unknown in practice, we propose an indirect adaptive estimation scheme to approximate the unknown dynamic effects of the flexible cable as an external force with parametric uncertainties. A boundary layer-based sliding mode control is then designed to compensate for the residual unmodeled dynamics and time-varying disturbances, in which the control gain is updated by an auxiliary direct adaptive control mechanism. Stability analysis and derivation of adaptation laws are carried out through a Lyapunov approach, which formally guarantees the stability and tracking performance of the robot-cable system. Simulation experiments and comparison with a baseline controller show that the combined direct-indirect adaptive robust control framework achieves reliable tracking performance and adaptive system identification, enabling the robot to traverse flexible cables in the presence of unmodeled dynamics, parametric uncertainties and unstructured disturbances.
Pretrained Generalized Autoregressive Model with Adaptive Probabilistic Label Clusters for Extreme Multi-label Text Classification
Jul 05, 2020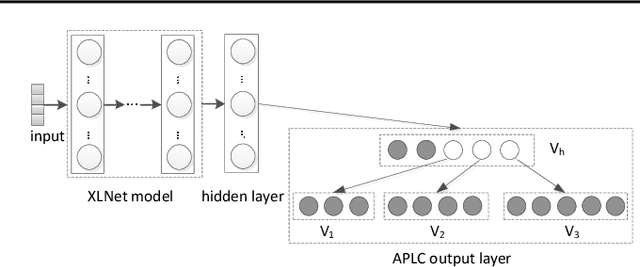
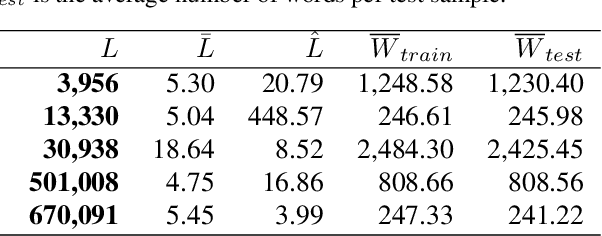
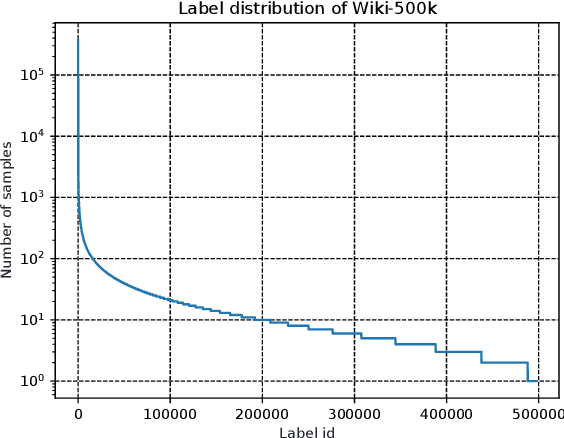
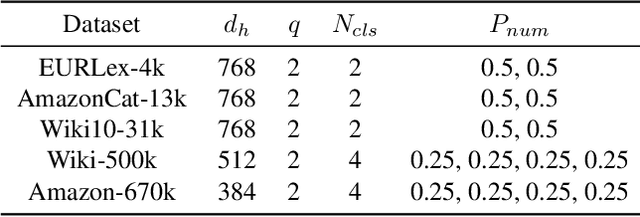
Extreme multi-label text classification (XMTC) is a task for tagging a given text with the most relevant labels from an extremely large label set. We propose a novel deep learning method called APLC-XLNet. Our approach fine-tunes the recently released generalized autoregressive pretrained model (XLNet) to learn a dense representation for the input text. We propose Adaptive Probabilistic Label Clusters (APLC) to approximate the cross entropy loss by exploiting the unbalanced label distribution to form clusters that explicitly reduce the computational time. Our experiments, carried out on five benchmark datasets, show that our approach significantly outperforms existing state-of-the-art methods. Our source code is available publicly at https://github.com/huiyegit/APLC_XLNet.
Compositional Video Synthesis with Action Graphs
Jun 27, 2020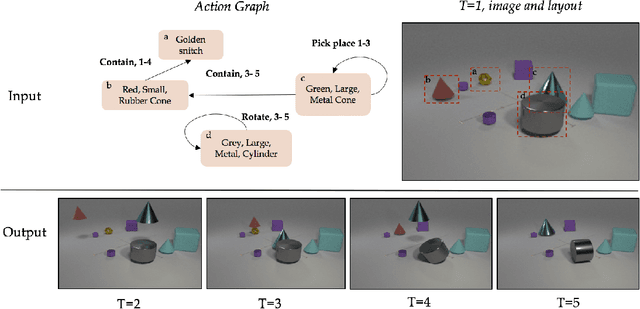
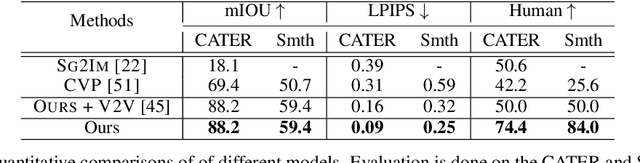
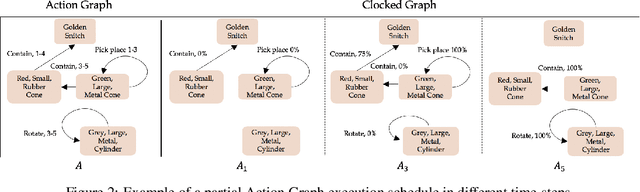
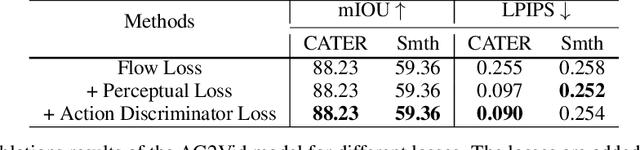
Videos of actions are complex spatio-temporal signals, containing rich compositional structures. Current generative models are limited in their ability to generate examples of object configurations outside the range they were trained on. Towards this end, we introduce a generative model (AG2Vid) based on Action Graphs, a natural and convenient structure that represents the dynamics of actions between objects over time. Our AG2Vid model disentangles appearance and position features, allowing for more accurate generation. AG2Vid is evaluated on the CATER and Something-Something datasets and outperforms other baselines. Finally, we show how Action Graphs can be used for generating novel compositions of unseen actions.
Reconfigurable Behavior Trees: Towards an Executive Framework Meeting High-level Decision Making and Control Layer Features
Jul 21, 2020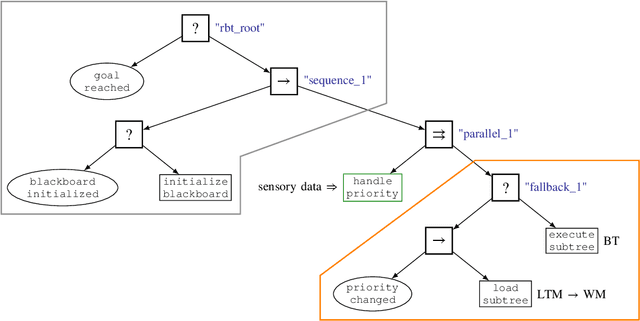
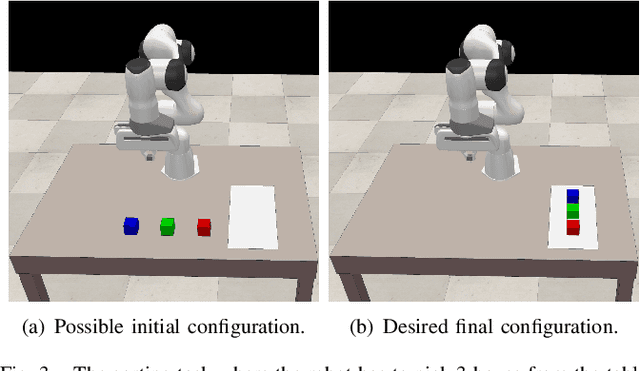
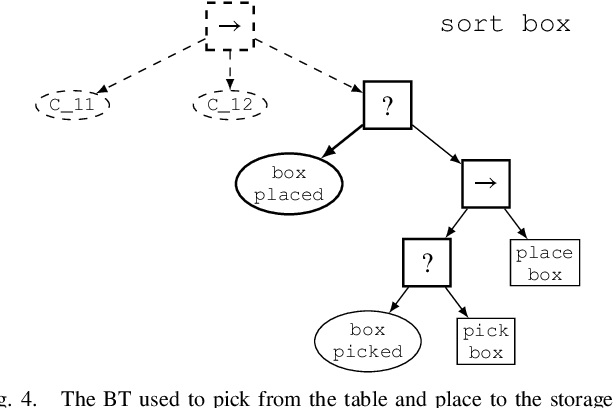
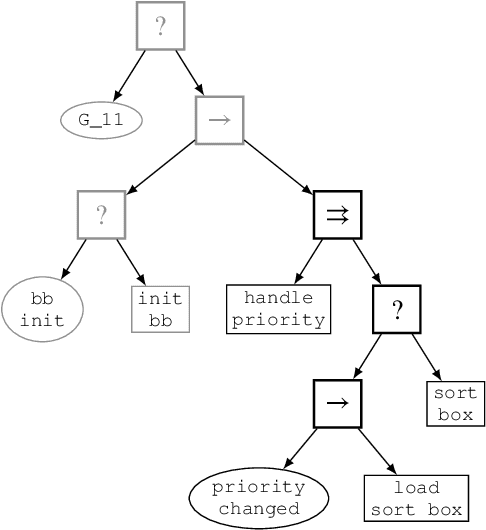
Behavior Trees constitute a widespread AI tool which has been successfully spun out in robotics. Their advantages include simplicity, modularity, and reusability of code. However, Behavior Trees remain a high-level decision making engine; control features cannot be easily integrated. This paper proposes the Reconfigurable Behavior Trees (RBTs), an extension of the traditional BTs that considers physical constraints from the robotic environment in the decision making process. We endow RBTs with continuous sensory information that permits the online monitoring of the task execution. The resulting stimulus-driven architecture is capable of dynamically handling changes in the executive context while keeping the execution time low. The proposed framework is evaluated on a set of robotic experiments. The results show that RBTs are a promising approach for robotic task representation, monitoring, and execution.
DistilE: Distiling Knowledge Graph Embeddings for Faster and Cheaper Reasoning
Sep 13, 2020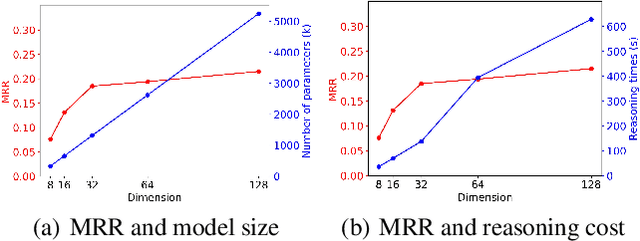
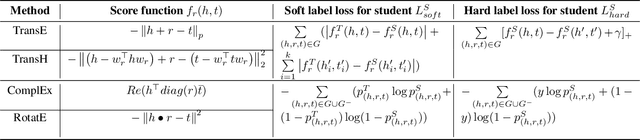

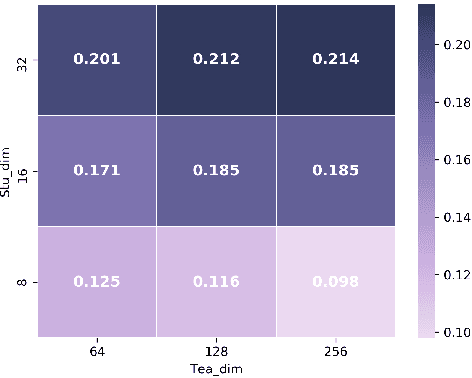
Knowledge Graph Embedding (KGE) is a popular method for KG reasoning and usually a higher dimensional one ensures better reasoning capability. However, high-dimensional KGEs pose huge challenges to storage and computing resources and are not suitable for resource-limited or time-constrained applications, for which faster and cheaper reasoning is necessary. To address this problem, we propose DistilE, a knowledge distillation method to build low-dimensional student KGE from pre-trained high-dimensional teacher KGE. We take the original KGE loss as hard label loss and design specific soft label loss for different KGEs in DistilE. We also propose a two-stage distillation approach to make the student and teacher adapt to each other and further improve the reasoning capability of the student. Our DistilE is general enough to be applied to various KGEs. Experimental results of link prediction show that our method successfully distills a good student which performs better than a same dimensional one directly trained, and sometimes even better than the teacher, and it can achieve 2 times - 8 times embedding compression rate and more than 10 times faster inference speed than the teacher with a small performance loss. We also experimentally prove the effectiveness of our two-stage training proposal via ablation study.
Toward Enabling a Reliable Quality Monitoring System for Additive Manufacturing Process using Deep Convolutional Neural Networks
Mar 06, 2020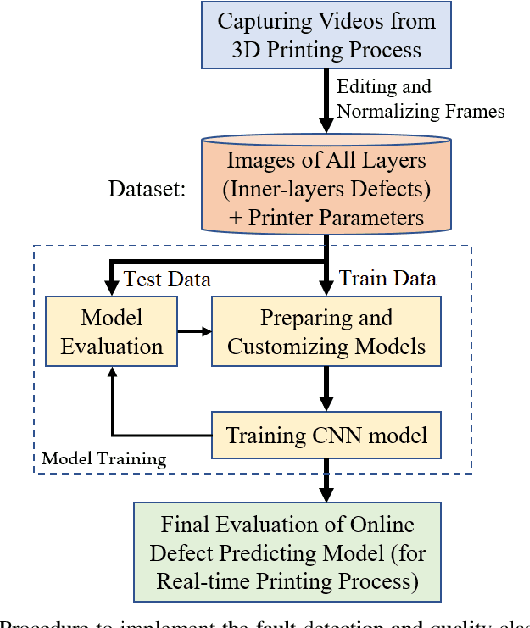
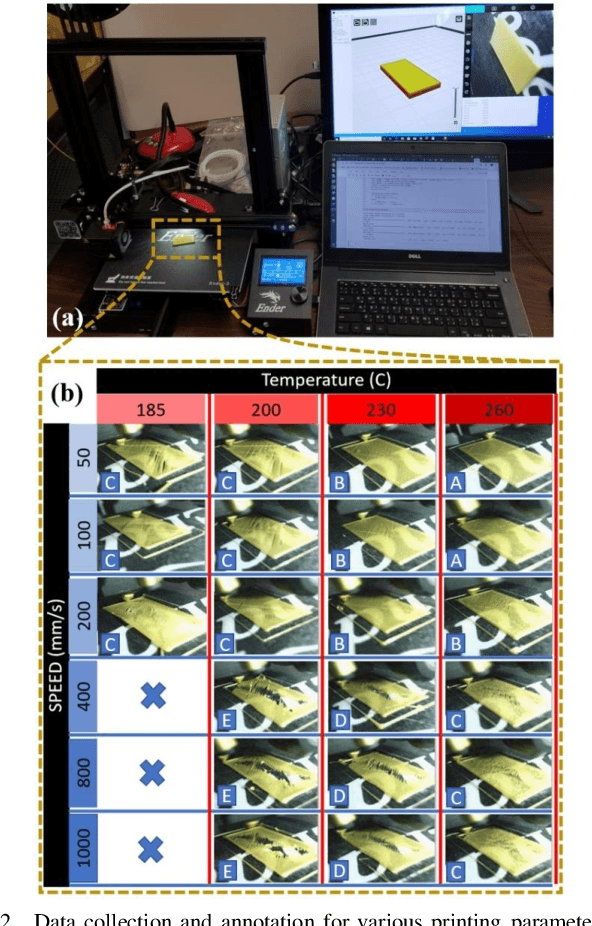
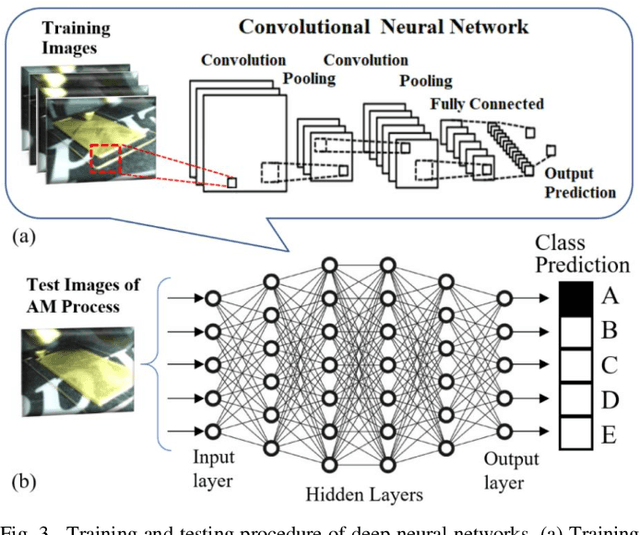
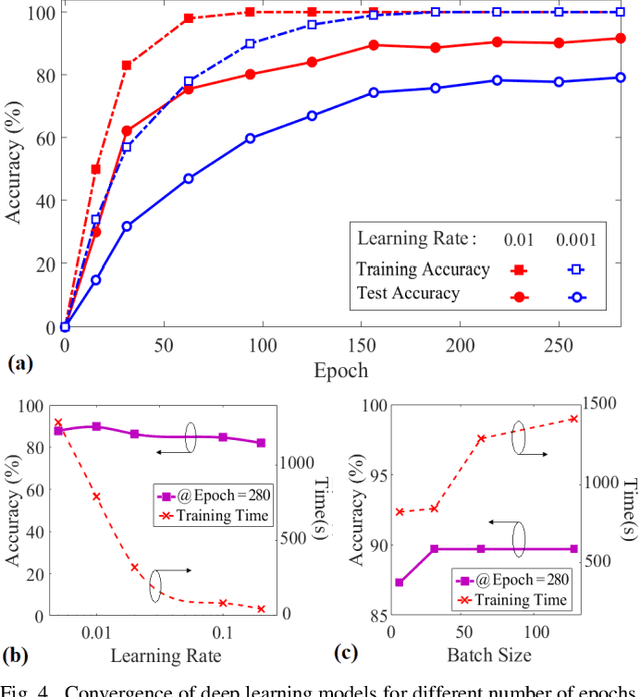
Additive Manufacturing (AM) is a crucial component of the smart industry. In this paper, we propose an automated quality grading system for the AM process using a deep convolutional neural network (CNN) model. The CNN model is trained offline using the images of the internal and surface defects in the layer-by-layer deposition of materials and tested online by studying the performance of detecting and classifying the failure in AM process at different extruder speeds and temperatures. The model demonstrates the accuracy of 94% and specificity of 96%, as well as above 75% in three classifier measures of the Fscore, the sensitivity, and precision for classifying the quality of the printing process in five grades in real-time. The proposed online model adds an automated, consistent, and non-contact quality control signal to the AM process that eliminates the manual inspection of parts after they are entirely built. The quality monitoring signal can also be used by the machine to suggest remedial actions by adjusting the parameters in real-time. The proposed quality predictive model serves as a proof-of-concept for any type of AM machines to produce reliable parts with fewer quality hiccups while limiting the waste of both time and materials.
Toward Fast and Optimal Robotic Pick-and-Place on a Moving Conveyor
Dec 17, 2019
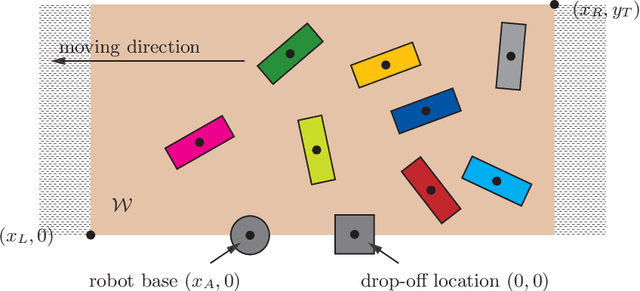
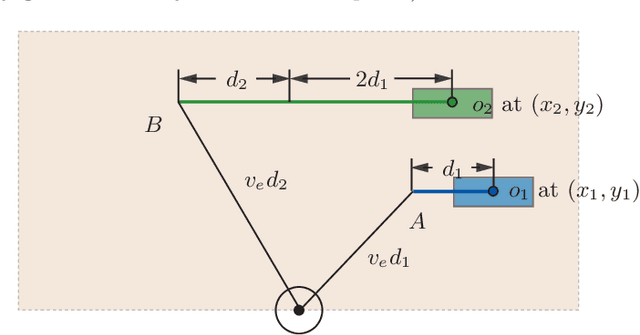
Robotic pick-and-place (PnP) operations on moving conveyors find a wide range of industrial applications. In practice, simple greedy heuristics (e.g., prioritization based on the time to process a single object) are applied that achieve reasonable efficiency. We show analytically that, under a simplified telescoping robot model, these greedy approaches do not ensure time optimality of PnP operations. To address the shortcomings of classical solutions, we develop algorithms that compute optimal object picking sequences for a predetermined finite horizon. Employing dynamic programming techniques and additional heuristics, our methods scale to up to tens to hundreds of objects. In particular, the fast algorithms we develop come with running time guarantees, making them suitable for real-time PnP applications demanding high throughput. Extensive evaluation of our algorithmic solution over dominant industrial PnP robots used in real-world applications, i.e., Delta robots and Selective Compliance Assembly Robot Arm (SCARA) robots, shows that a typical efficiency gain of around 10-40% over greedy approaches can be realized.