 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ProSelfLC: Progressive Self Label Correction for Training Robust Deep Neural Networks
Jun 08, 2020
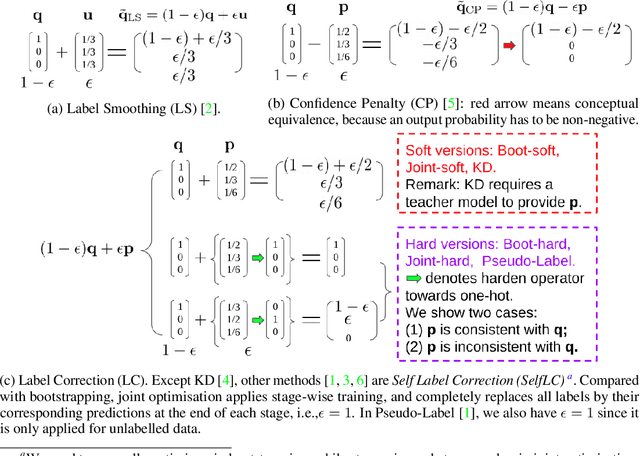

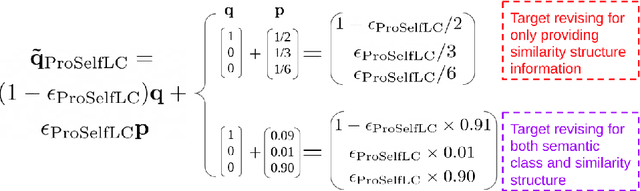
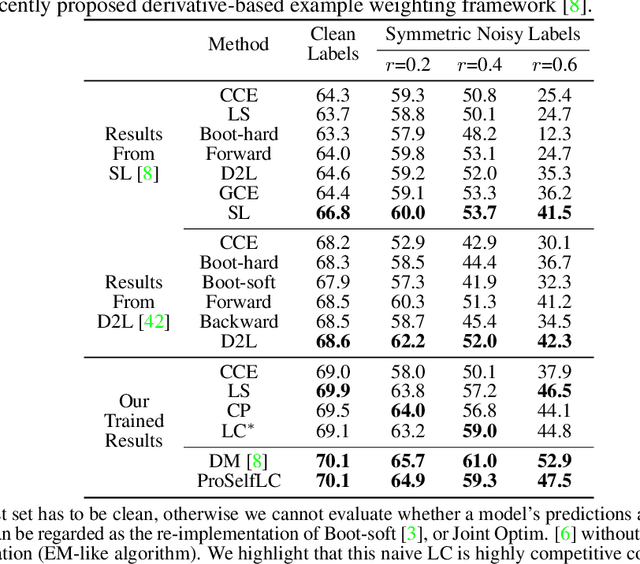
We systematically study popular target modification approaches in supervised learning. We show that they can be connected mathematically through entropy and KL divergence. This uncovers that some methods penalise while the others reward low entropy. Additionally, some of them are suboptimal because they do not leverage the knowledge of a model itself; some rely on extra learners or stage-wise training that may require a human intervention thus being difficult to optimise; most importantly, there does not exist an automatic way to decide how much we trust a predicted label distribution, let alone exploiting it. To resolve these issues, taking two well-accepted expertise: deep neural networks learn meaningful patterns before fitting noise [1] and minimum entropy regularisation principle [2], we propose a simple end-to-end method named ProSelfLC, which is endorsed by long learning time and high prediction confidence. Specifically, given a data point, we progressively trust more its predicted label distribution than its annotated one if a model has been trained for a long time and outputs a highly confident prediction (low entropy). By extensive experiments, we show: (1) ProSelfLC can revise an example's one-hot label distribution by adding the perceptual similarity structure information so that its learning target becomes structured and soft; (2) When being applied to noisy labels, it can correct their semantic classes; (3) It outperforms existing methods with the lowest entropy, which indicates it is right for a learner to be confident in correct patterns.
Paraphrase Generation as Zero-Shot Multilingual Translation: Disentangling Semantic Similarity from Lexical and Syntactic Diversity
Aug 11, 2020
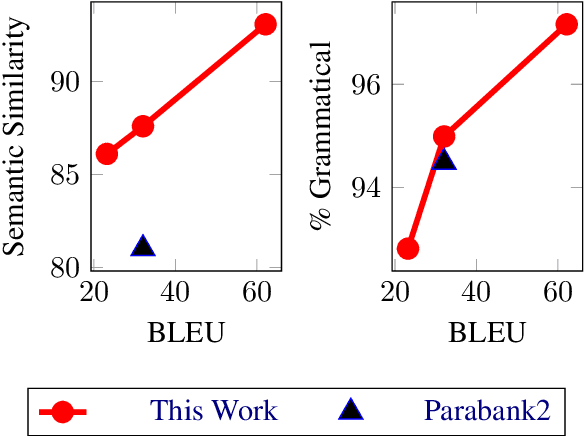
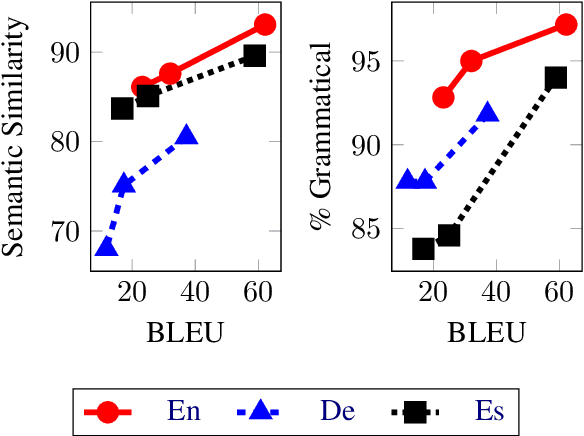
Recent work has shown that a multilingual neural machine translation (NMT) model can be used to judge how well a sentence paraphrases another sentence in the same language; however, attempting to generate paraphrases from the model using beam search produces trivial copies or near copies. We introduce a simple paraphrase generation algorithm which discourages the production of n-grams that are present in the input. Our approach enables paraphrase generation in many languages from a single multilingual NMT model. Furthermore, the trade-off between semantic similarity and lexical/syntactic diversity between the input and output can be controlled at generation time. We conduct human evaluation to compare our method to a paraphraser trained on a large English synthetic paraphrase database and find that our model produces paraphrases that better preserve semantic meaning and grammatically, for the same level of lexical/syntactic diversity. Additional smaller human assessments demonstrate our approach also works in non-English languages.
Faster Binary Embeddings for Preserving Euclidean Distances
Oct 01, 2020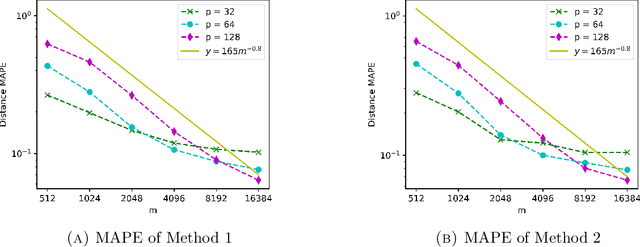
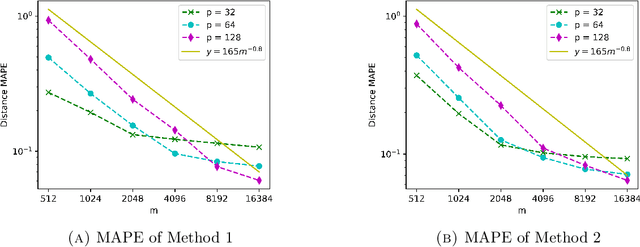
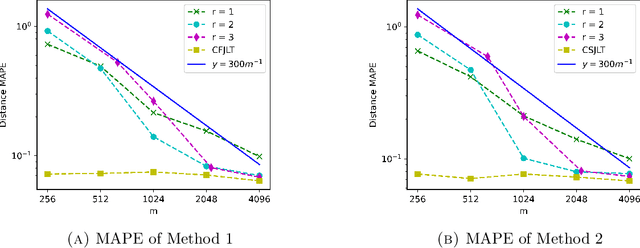
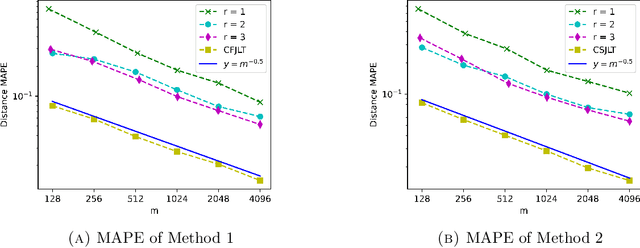
We propose a fast, distance-preserving, binary embedding algorithm to transform a high-dimensional dataset $\mathcal{T}\subseteq\mathbb{R}^n$ into binary sequences in the cube $\{\pm 1\}^m$. When $\mathcal{T}$ consists of well-spread (i.e., non-sparse) vectors, our embedding method applies a stable noise-shaping quantization scheme to $A x$ where $A\in\mathbb{R}^{m\times n}$ is a sparse Gaussian random matrix. This contrasts with most binary embedding methods, which usually use $x\mapsto \mathrm{sign}(Ax)$ for the embedding. Moreover, we show that Euclidean distances among the elements of $\mathcal{T}$ are approximated by the $\ell_1$ norm on the images of $\{\pm 1\}^m$ under a fast linear transformation. This again contrasts with standard methods, where the Hamming distance is used instead. Our method is both fast and memory efficient, with time complexity $O(m)$ and space complexity $O(m)$. Further, we prove that the method is accurate and its associated error is comparable to that of a continuous valued Johnson-Lindenstrauss embedding plus a quantization error that admits a polynomial decay as the embedding dimension $m$ increases. Thus the length of the binary codes required to achieve a desired accuracy is quite small, and we show it can even be compressed further without compromising the accuracy. To illustrate our results, we test the proposed method on natural images and show that it achieves strong performance.
Quantum exploration algorithms for multi-armed bandits
Jul 14, 2020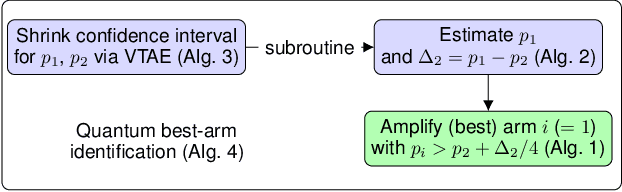
Identifying the best arm of a multi-armed bandit is a central problem in bandit optimization. We study a quantum computational version of this problem with coherent oracle access to states encoding the reward probabilities of each arm as quantum amplitudes. Specifically, we show that we can find the best arm with fixed confidence using $\tilde{O}\bigl(\sqrt{\sum_{i=2}^n\Delta^{\smash{-2}}_i}\bigr)$ quantum queries, where $\Delta_{i}$ represents the difference between the mean reward of the best arm and the $i^\text{th}$-best arm. This algorithm, based on variable-time amplitude amplification and estimation, gives a quadratic speedup compared to the best possible classical result. We also prove a matching quantum lower bound (up to poly-logarithmic factors).
MAFF-Net: Filter False Positive for 3D Vehicle Detection with Multi-modal Adaptive Feature Fusion
Sep 23, 2020

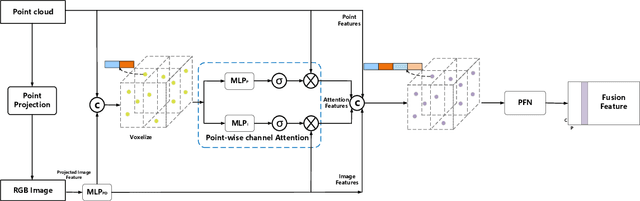
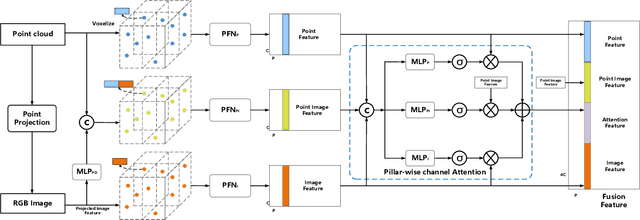
3D vehicle detection based on multi-modal fusion is an important task of many applications such as autonomous driving. Although significant progress has been made, we still observe two aspects that need to be further improvement: First, the specific gain that camera images can bring to 3D detection is seldom explored by previous works. Second, many fusion algorithms run slowly, which is essential for applications with high real-time requirements(autonomous driving). To this end, we propose an end-to-end trainable single-stage multi-modal feature adaptive network in this paper, which uses image information to effectively reduce false positive of 3D detection and has a fast detection speed. A multi-modal adaptive feature fusion module based on channel attention mechanism is proposed to enable the network to adaptively use the feature of each modal. Based on the above mechanism, two fusion technologies are proposed to adapt to different usage scenarios: PointAttentionFusion is suitable for filtering simple false positive and faster; DenseAttentionFusion is suitable for filtering more difficult false positive and has better overall performance. Experimental results on the KITTI dataset demonstrate significant improvement in filtering false positive over the approach using only point cloud data. Furthermore, the proposed method can provide competitive results and has the fastest speed compared to the published state-of-the-art multi-modal methods in the KITTI benchmark.
Learning Event-triggered Control from Data through Joint Optimization
Aug 11, 2020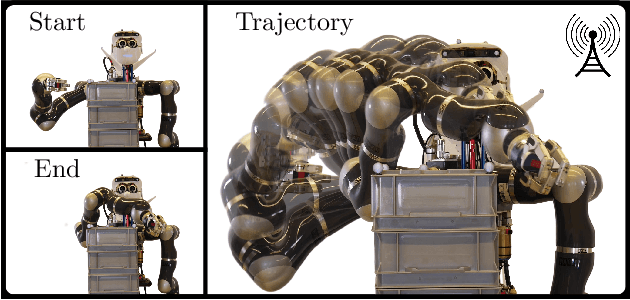
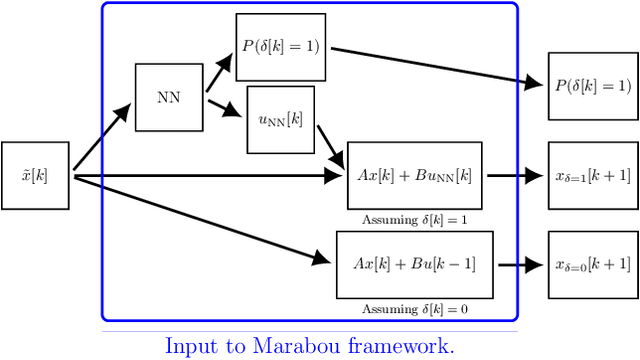
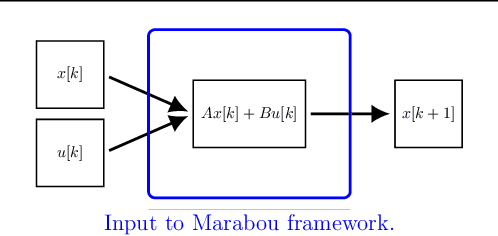
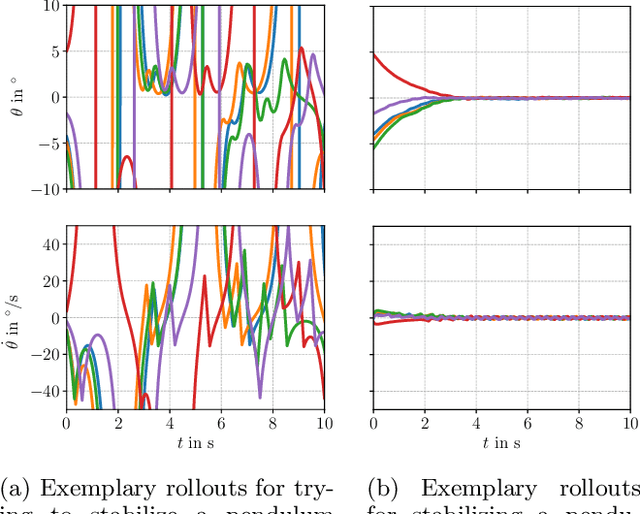
We present a framework for model-free learning of event-triggered control strategies. Event-triggered methods aim to achieve high control performance while only closing the feedback loop when needed. This enables resource savings, e.g., network bandwidth if control commands are sent via communication networks, as in networked control systems. Event-triggered controllers consist of a communication policy, determining when to communicate, and a control policy, deciding what to communicate. It is essential to jointly optimize the two policies since individual optimization does not necessarily yield the overall optimal solution. To address this need for joint optimization, we propose a novel algorithm based on hierarchical reinforcement learning. The resulting algorithm is shown to accomplish high-performance control in line with resource savings and scales seamlessly to nonlinear and high-dimensional systems. The method's applicability to real-world scenarios is demonstrated through experiments on a six degrees of freedom real-time controlled manipulator. Further, we propose an approach towards evaluating the stability of the learned neural network policies.
Understanding Information Processing in Human Brain by Interpreting Machine Learning Models
Oct 17, 2020
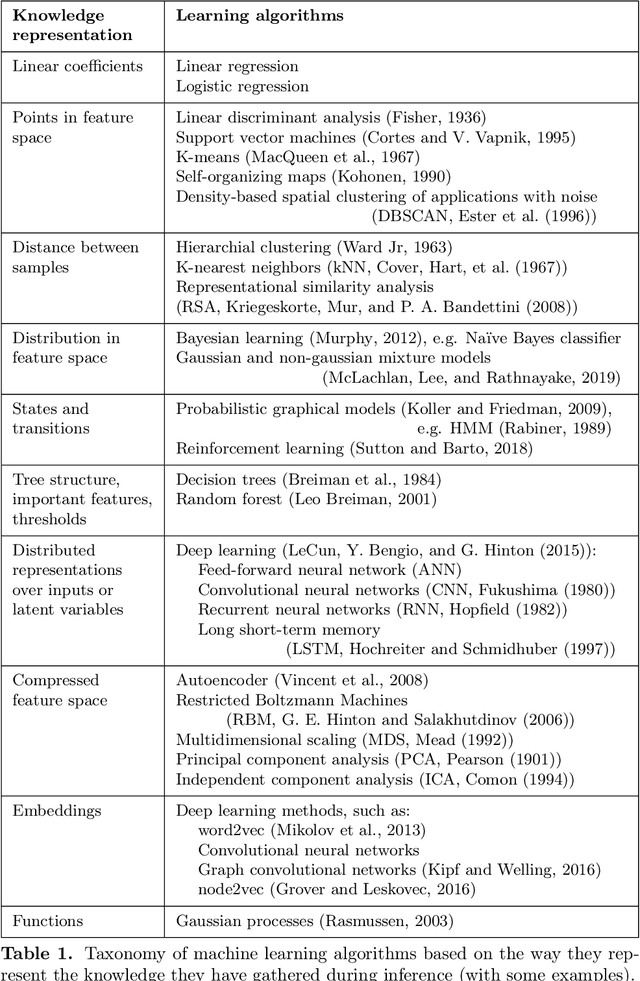
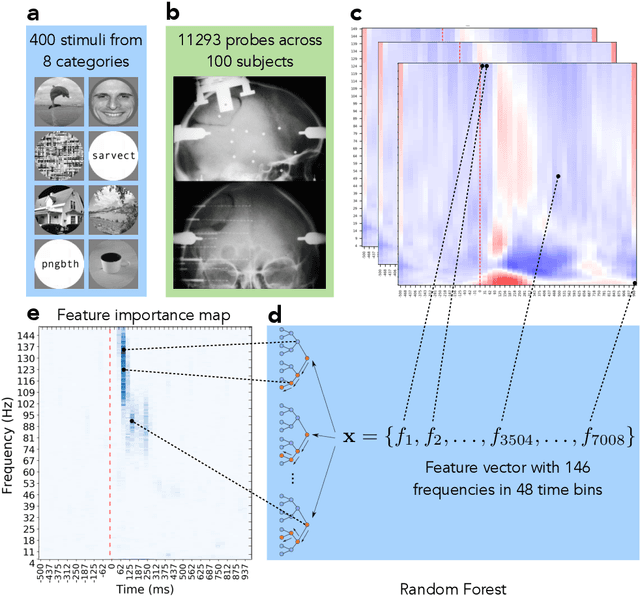

The thesis explores the role machine learning methods play in creating intuitive computational models of neural processing. Combined with interpretability techniques, machine learning could replace human modeler and shift the focus of human effort to extracting the knowledge from the ready-made models and articulating that knowledge into intuitive descroptions of reality. This perspective makes the case in favor of the larger role that exploratory and data-driven approach to computational neuroscience could play while coexisting alongside the traditional hypothesis-driven approach. We exemplify the proposed approach in the context of the knowledge representation taxonomy with three research projects that employ interpretability techniques on top of machine learning methods at three different levels of neural organization. The first study (Chapter 3) explores feature importance analysis of a random forest decoder trained on intracerebral recordings from 100 human subjects to identify spectrotemporal signatures that characterize local neural activity during the task of visual categorization. The second study (Chapter 4) employs representation similarity analysis to compare the neural responses of the areas along the ventral stream with the activations of the layers of a deep convolutional neural network. The third study (Chapter 5) proposes a method that allows test subjects to visually explore the state representation of their neural signal in real time. This is achieved by using a topology-preserving dimensionality reduction technique that allows to transform the neural data from the multidimensional representation used by the computer into a two-dimensional representation a human can grasp. The approach, the taxonomy, and the examples, present a strong case for the applicability of machine learning methods to automatic knowledge discovery in neuroscience.
Decoder Modulation for Indoor Depth Completion
May 18, 2020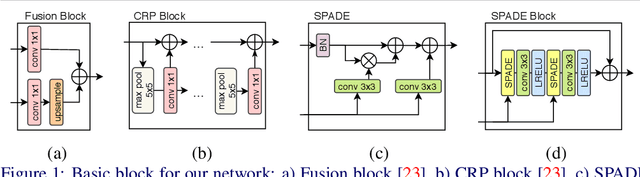
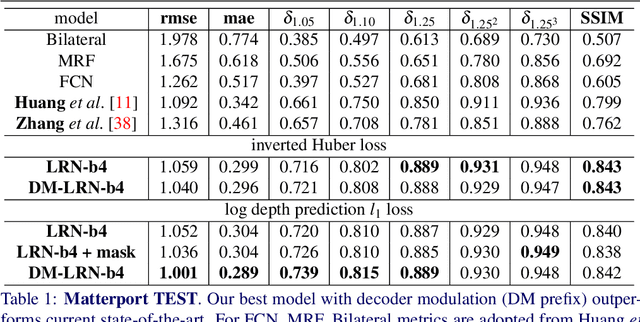

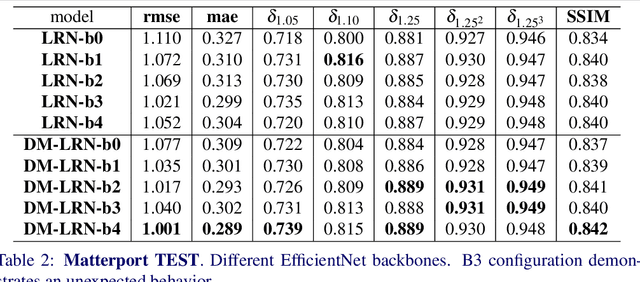
Accurate depth map estimation is an essential step in scene spatial mapping for AR applications and 3D modeling. Current depth sensors provide time-synchronized depth and color images in real-time, but have limited range and suffer from missing and erroneous depth values on transparent or glossy surfaces. We investigate the task of depth completion that aims at improving the accuracy of depth measurements and recovering the missing depth values using additional information from corresponding color images. Surprisingly, we find that a simple baseline model based on modern encoder-decoder architecture for semantic segmentation achieves state-of-the-art accuracy on standard depth completion benchmarks. Then, we show that the accuracy can be further improved by taking into account a mask of missing depth values. The main contributions of our work are two-fold. First, we propose a modified decoder architecture, where features from raw depth and color are modulated by features from the mask via Spatially-Adaptive Denormalization (SPADE). Second, we introduce a new loss function for depth estimation based on a direct comparison of log depth prediction with ground truth values. The resulting model outperforms current state-of-the-art by a large margin on the challenging Matterport3D dataset.
Energy-Aware Multi-Server Mobile Edge Computing: A Deep Reinforcement Learning Approach
Dec 22, 2019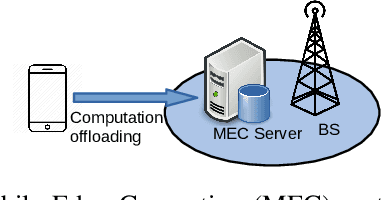
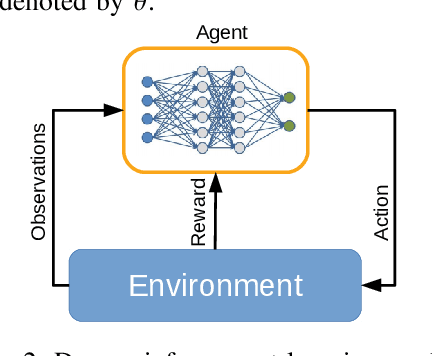
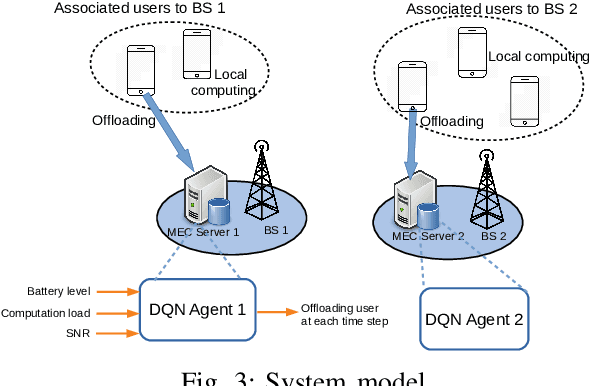
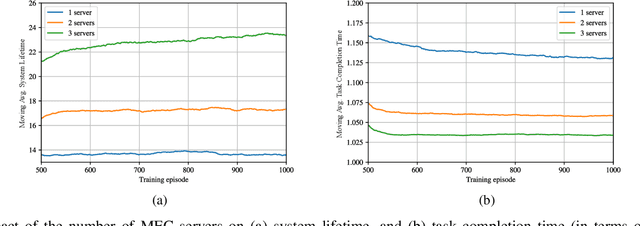
We investigate the problem of computation offloading in a mobile edge computing architecture, where multiple energy-constrained users compete to offload their computational tasks to multiple servers through a shared wireless medium. We propose a multi-agent deep reinforcement learning algorithm, where each server is equipped with an agent, observing the status of its associated users and selecting the best user for offloading at each step. We consider computation time (i.e., task completion time) and system lifetime as two key performance indicators, and we numerically demonstrate that our approach outperforms baseline algorithms in terms of the trade-off between computation time and system lifetime.
PECAIQR: A Model for Infectious Disease Applied to the Covid-19 Epidemic
Jun 17, 2020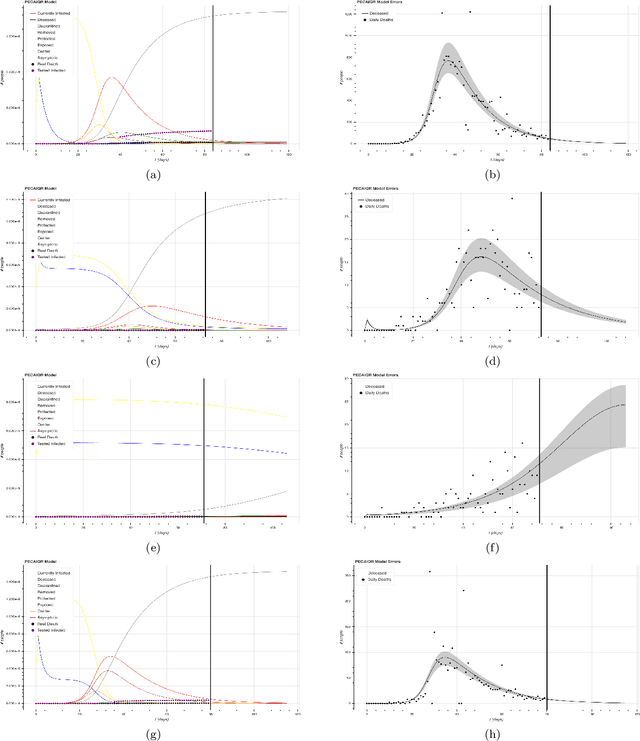
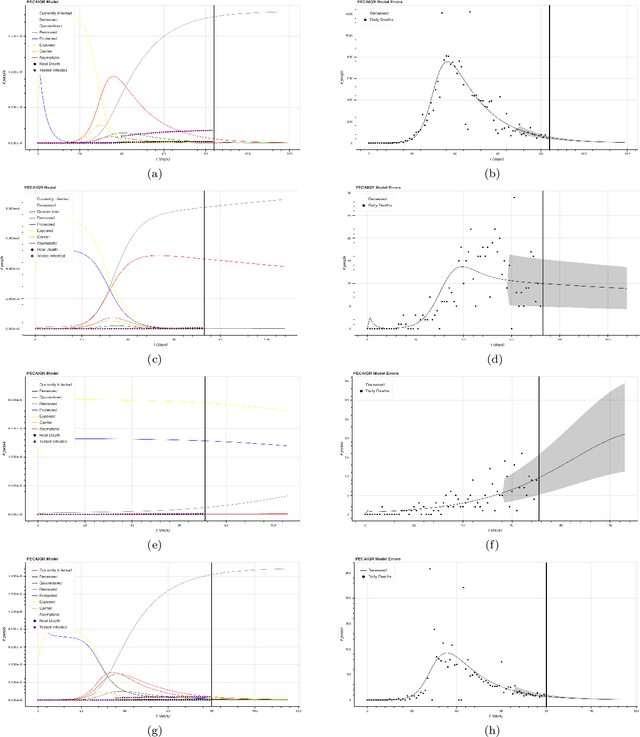
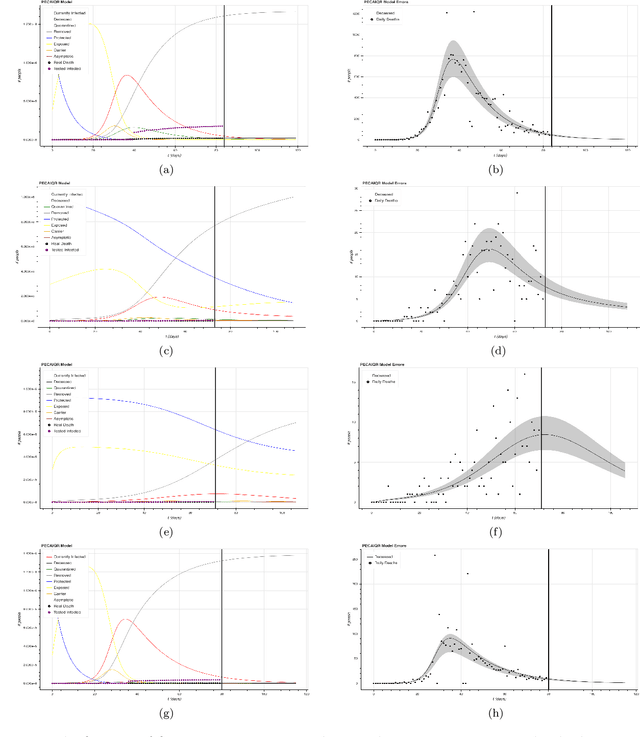
The Covid-19 pandemic has made clear the need to improve modern multivariate time-series forecasting models. Current state of the art predictions of future daily deaths and, especially, hospital resource usage have confidence intervals that are unacceptably wide. Policy makers and hospitals require accurate forecasts to make informed decisions on passing legislation and allocating resources. We used US county-level data on daily deaths and population statistics to forecast future deaths. We extended the SIR epidemiological model to a novel model we call the PECAIQR model. It adds several new variables and parameters to the naive SIR model by taking into account the ramifications of the partial quarantining implemented in the US. We fitted data to the model parameters with numerical integration. Because of the fit degeneracy in parameter space and non-constant nature of the parameters, we developed several methods to optimize our fit, such as training on the data tail and training on specific policy regimes. We use cross-validation to tune our hyper parameters at the county level and generate a CDF for future daily deaths. For predictions made from training data up to May 25th, we consistently obtained an averaged pinball loss score of 0.096 on a 14 day forecast. We finally present examples of possible avenues for utility from our model. We generate longer-time horizon predictions over various 1-month windows in the past, forecast how many medical resources such as ventilators and ICU beds will be needed in counties, and evaluate the efficacy of our model in other countries.