 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Active learning with RESSPECT: Resource allocation for extragalactic astronomical transients
Oct 12, 2020
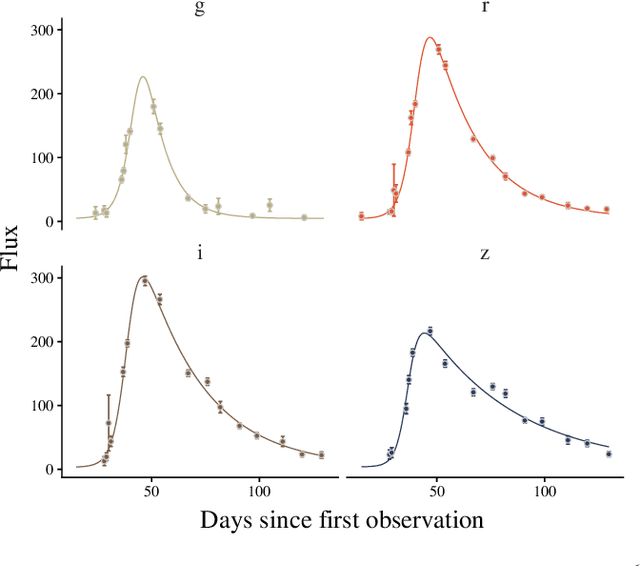
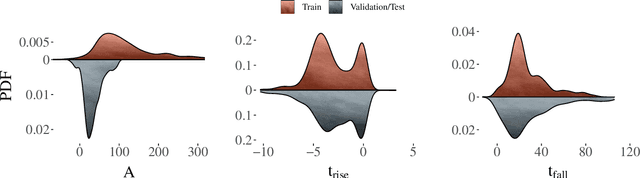
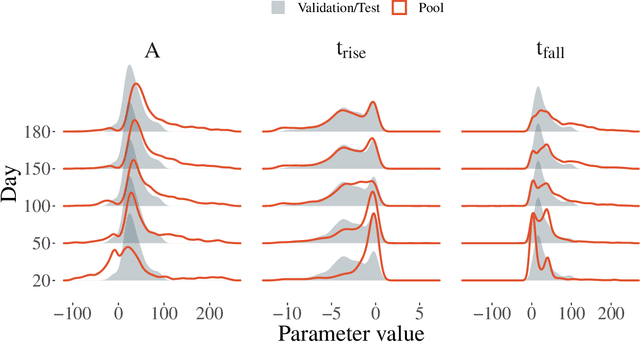
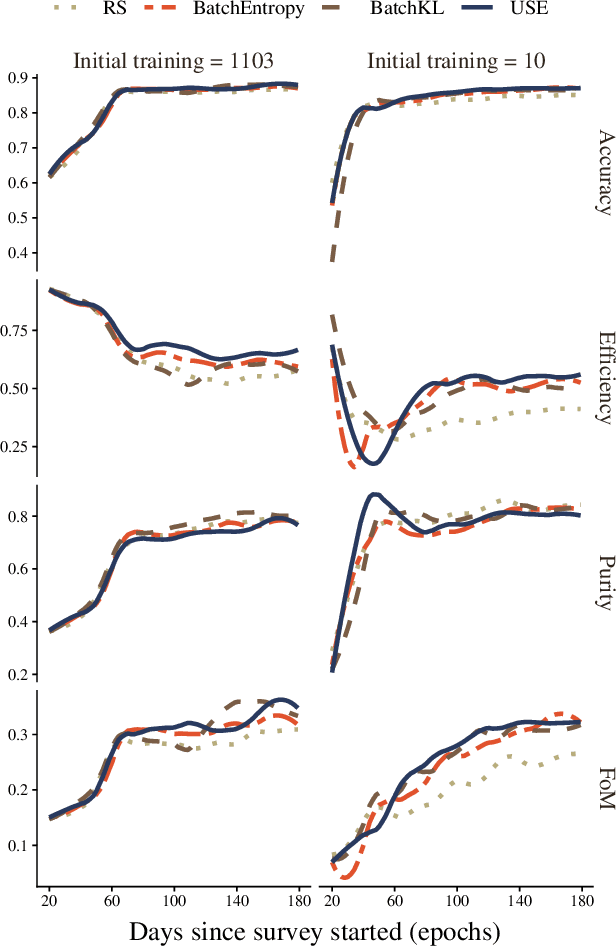
The recent increase in volume and complexity of available astronomical data has led to a wide use of supervised machine learning techniques. Active learning strategies have been proposed as an alternative to optimize the distribution of scarce labeling resources. However, due to the specific conditions in which labels can be acquired, fundamental assumptions, such as sample representativeness and labeling cost stability cannot be fulfilled. The Recommendation System for Spectroscopic follow-up (RESSPECT) project aims to enable the construction of optimized training samples for the Rubin Observatory Legacy Survey of Space and Time (LSST), taking into account a realistic description of the astronomical data environment. In this work, we test the robustness of active learning techniques in a realistic simulated astronomical data scenario. Our experiment takes into account the evolution of training and pool samples, different costs per object, and two different sources of budget. Results show that traditional active learning strategies significantly outperform random sampling. Nevertheless, more complex batch strategies are not able to significantly overcome simple uncertainty sampling techniques. Our findings illustrate three important points: 1) active learning strategies are a powerful tool to optimize the label-acquisition task in astronomy, 2) for upcoming large surveys like LSST, such techniques allow us to tailor the construction of the training sample for the first day of the survey, and 3) the peculiar data environment related to the detection of astronomical transients is a fertile ground that calls for the development of tailored machine learning algorithms.
AutoCount: Unsupervised Segmentation and Counting of Organs in Field Images
Jul 17, 2020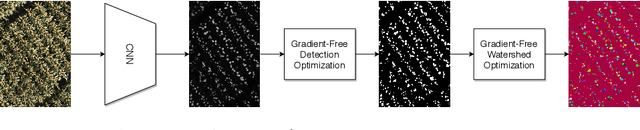

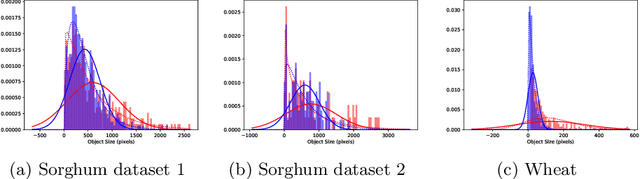

Counting plant organs such as heads or tassels from outdoor imagery is a popular benchmark computer vision task in plant phenotyping, which has been previously investigated in the literature using state-of-the-art supervised deep learning techniques. However, the annotation of organs in field images is time-consuming and prone to errors. In this paper, we propose a fully unsupervised technique for counting dense objects such as plant organs. We use a convolutional network-based unsupervised segmentation method followed by two post-hoc optimization steps. The proposed technique is shown to provide competitive counting performance on a range of organ counting tasks in sorghum (S. bicolor) and wheat (T. aestivum) with no dataset-dependent tuning or modifications.
Decoupling Representation Learning from Reinforcement Learning
Sep 14, 2020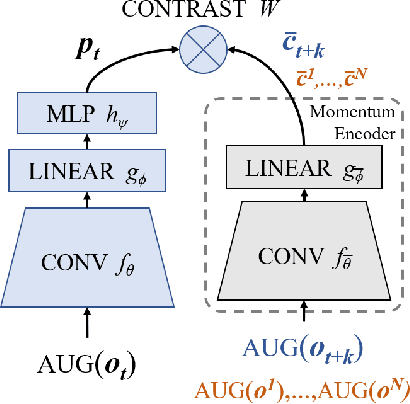

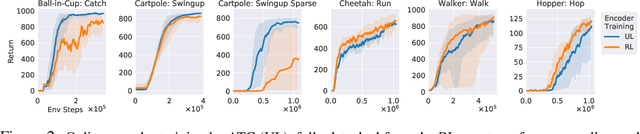
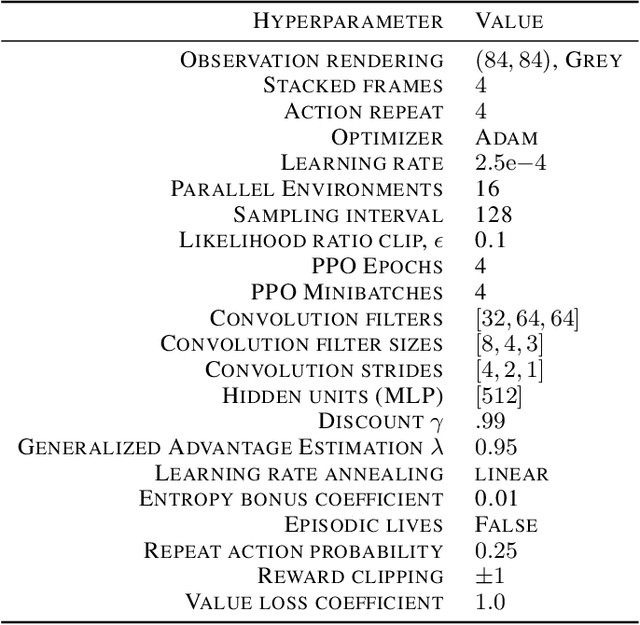
In an effort to overcome limitations of reward-driven feature learning in deep reinforcement learning (RL) from images, we propose decoupling representation learning from policy learning. To this end, we introduce a new unsupervised learning (UL) task, called Augmented Temporal Contrast (ATC), which trains a convolutional encoder to associate pairs of observations separated by a short time difference, under image augmentations and using a contrastive loss. In online RL experiments, we show that training the encoder exclusively using ATC matches or outperforms end-to-end RL in most environments. Additionally, we benchmark several leading UL algorithms by pre-training encoders on expert demonstrations and using them, with weights frozen, in RL agents; we find that agents using ATC-trained encoders outperform all others. We also train multi-task encoders on data from multiple environments and show generalization to different downstream RL tasks. Finally, we ablate components of ATC, and introduce a new data augmentation to enable replay of (compressed) latent images from pre-trained encoders when RL requires augmentation. Our experiments span visually diverse RL benchmarks in DeepMind Control, DeepMind Lab, and Atari, and our complete code is available at https://github.com/astooke/rlpyt/rlpyt/ul.
Reducing statistical time-series problems to binary classification
Jun 07, 2013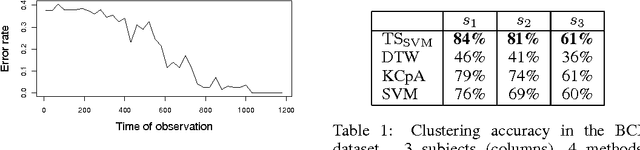
We show how binary classification methods developed to work on i.i.d. data can be used for solving statistical problems that are seemingly unrelated to classification and concern highly-dependent time series. Specifically, the problems of time-series clustering, homogeneity testing and the three-sample problem are addressed. The algorithms that we construct for solving these problems are based on a new metric between time-series distributions, which can be evaluated using binary classification methods. Universal consistency of the proposed algorithms is proven under most general assumptions. The theoretical results are illustrated with experiments on synthetic and real-world data.
Human-centric Dialog Training via Offline Reinforcement Learning
Oct 12, 2020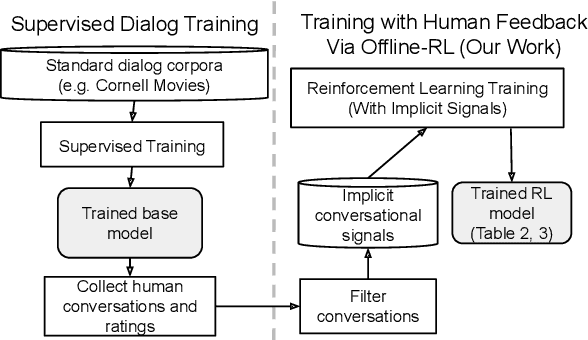
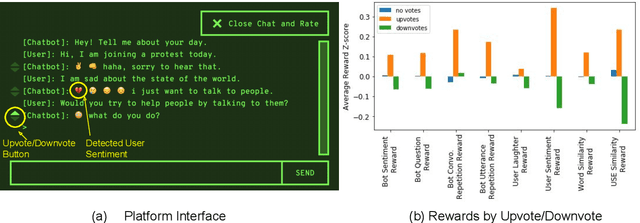
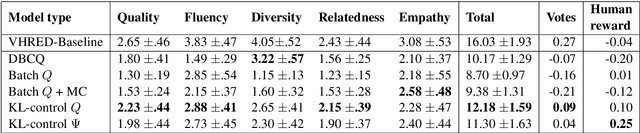
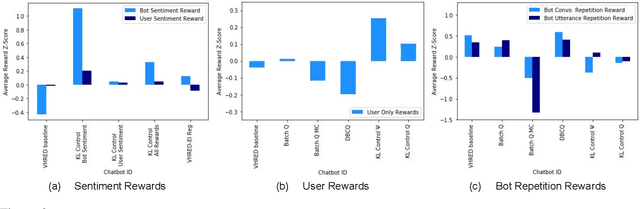
How can we train a dialog model to produce better conversations by learning from human feedback, without the risk of humans teaching it harmful chat behaviors? We start by hosting models online, and gather human feedback from real-time, open-ended conversations, which we then use to train and improve the models using offline reinforcement learning (RL). We identify implicit conversational cues including language similarity, elicitation of laughter, sentiment, and more, which indicate positive human feedback, and embed these in multiple reward functions. A well-known challenge is that learning an RL policy in an offline setting usually fails due to the lack of ability to explore and the tendency to make over-optimistic estimates of future reward. These problems become even harder when using RL for language models, which can easily have a 20,000 action vocabulary and many possible reward functions. We solve the challenge by developing a novel class of offline RL algorithms. These algorithms use KL-control to penalize divergence from a pre-trained prior language model, and use a new strategy to make the algorithm pessimistic, instead of optimistic, in the face of uncertainty. We test the resulting dialog model with ratings from 80 users in an open-domain setting and find it achieves significant improvements over existing deep offline RL approaches. The novel offline RL method is viable for improving any existing generative dialog model using a static dataset of human feedback.
Dual-Mandate Patrols: Multi-Armed Bandits for Green Security
Sep 14, 2020


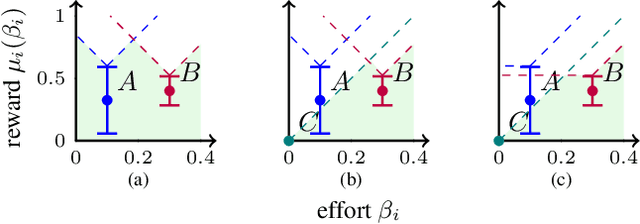
Conservation efforts in green security domains to protect wildlife and forests are constrained by the limited availability of defenders (i.e., patrollers), who must patrol vast areas to protect from attackers (e.g., poachers or illegal loggers). Defenders must choose how much time to spend in each region of the protected area, balancing exploration of infrequently visited regions and exploitation of known hotspots. We formulate the problem as a stochastic multi-armed bandit, where each action represents a patrol strategy, enabling us to guarantee the rate of convergence of the patrolling policy. However, a naive bandit approach would compromise short-term performance for long-term optimality, resulting in animals poached and forests destroyed. To speed up performance, we leverage smoothness in the reward function and decomposability of actions. We show a synergy between Lipschitz-continuity and decomposition as each aids the convergence of the other. In doing so, we bridge the gap between combinatorial and Lipschitz bandits, presenting a no-regret approach that tightens existing guarantees while optimizing for short-term performance. We demonstrate that our algorithm, LIZARD, improves performance on real-world poaching data from Cambodia.
Temporal Answer Set Programming
Sep 14, 2020
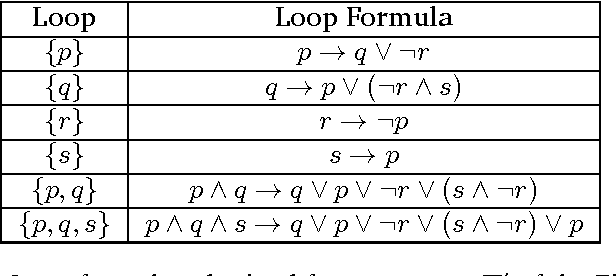
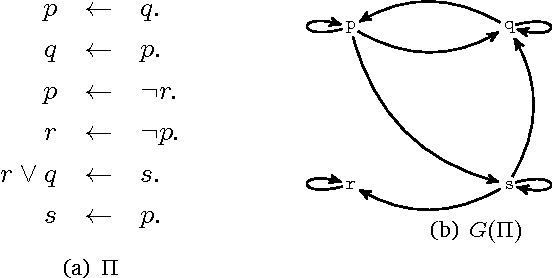
We present an overview on Temporal Logic Programming under the perspective of its application for Knowledge Representation and declarative problem solving. Such programs are the result of combining usual rules with temporal modal operators, as in Linear-time Temporal Logic (LTL). We focus on recent results of the non-monotonic formalism called Temporal Equilibrium Logic (TEL) that is defined for the full syntax of LTL, but performs a model selection criterion based on Equilibrium Logic, a well known logical characterization of Answer Set Programming (ASP). We obtain a proper extension of the stable models semantics for the general case of arbitrary temporal formulas. We recall the basic definitions for TEL and its monotonic basis, the temporal logic of Here-and-There (THT), and study the differences between infinite and finite traces. We also provide other useful results, such as the translation into other formalisms like Quantified Equilibrium Logic or Second-order LTL, and some techniques for computing temporal stable models based on automata. In a second part, we focus on practical aspects, defining a syntactic fragment called temporal logic programs closer to ASP, and explain how this has been exploited in the construction of the solver TELINGO.
Online Community Detection for Event Streams on Networks
Sep 03, 2020

A common goal in network modeling is to uncover the latent community structure present among nodes. For many real-world networks, observed connections consist of events arriving as streams, which are then aggregated to form edges, ignoring the temporal dynamic component. A natural way to take account of this temporal dynamic component of interactions is to use point processes as the foundation of the network models for community detection. Computational complexity hampers the scalability of such approaches to large sparse networks. To circumvent this challenge, we propose a fast online variational inference algorithm for learning the community structure underlying dynamic event arrivals on a network using continuous-time point process latent network models. We provide regret bounds on the loss function of this procedure, giving theoretical guarantees on performance. The proposed algorithm is illustrated, using both simulation studies and real data, to have comparable performance in terms of community structure in terms of community recovery to non-online variants. Our proposed framework can also be readily modified to incorporate other popular network structures.
A Gradient Flow Framework For Analyzing Network Pruning
Sep 24, 2020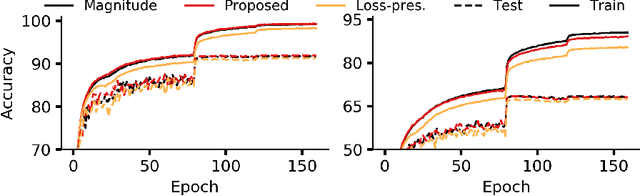
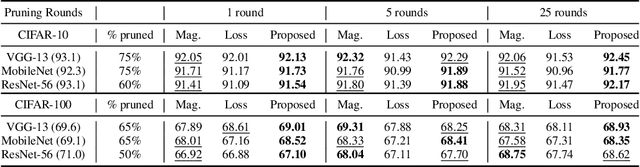
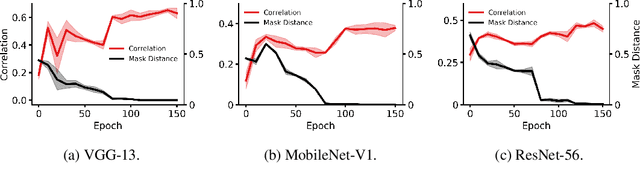
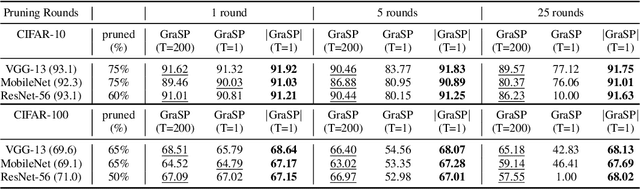
Recent network pruning methods focus on pruning models early-on in training. To estimate the impact of removing a parameter, these methods use importance measures that were originally designed for pruning trained models. Despite lacking justification for their use early-on in training, models pruned using such measures result in surprisingly minimal accuracy loss. To better explain this behavior, we develop a general, gradient-flow based framework that relates state-of-the-art importance measures through an order of time-derivative of the norm of model parameters. We use this framework to determine the relationship between pruning measures and evolution of model parameters, establishing several findings related to pruning models early-on in training: (i) magnitude-based pruning removes parameters that contribute least to reduction in loss, resulting in models that converge faster than magnitude-agnostic methods; (ii) loss-preservation based pruning preserves first-order model evolution dynamics and is well-motivated for pruning minimally trained models; and (iii) gradient-norm based pruning affects second-order model evolution dynamics, and increasing gradient norm via pruning can produce poorly performing models. We validate our claims on several VGG-13, MobileNet-V1, and ResNet-56 models trained on CIFAR-10 and CIFAR-100. Code available at https://github.com/EkdeepSLubana/flowandprune.
OT-Flow: Fast and Accurate Continuous Normalizing Flows via Optimal Transport
May 29, 2020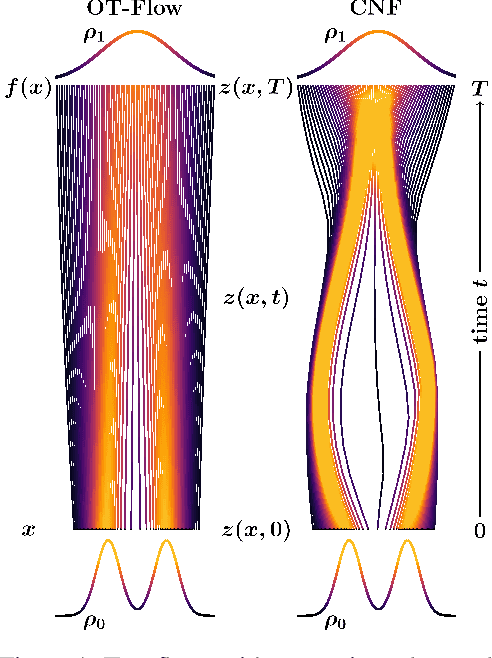

A normalizing flow is an invertible mapping between an arbitrary probability distribution and a standard normal distribution; it can be used for density estimation and statistical inference. Computing the flow follows the change of variables formula and thus requires invertibility of the mapping and an efficient way to compute the determinant of its Jacobian. To satisfy these requirements, normalizing flows typically consist of carefully chosen components. Continuous normalizing flows (CNFs) are mappings obtained by solving a neural ordinary differential equation (ODE). The neural ODE's dynamics can be chosen almost arbitrarily while ensuring invertibility. Moreover, the log-determinant of the flow's Jacobian can be obtained by integrating the trace of the dynamics' Jacobian along the flow. Our proposed OT-Flow approach tackles two critical computational challenges that limit a more widespread use of CNFs. First, OT-Flow leverages optimal transport (OT) theory to regularize the CNF and enforce straight trajectories that are easier to integrate. Second, OT-Flow features exact trace computation with time complexity equal to trace estimators used in existing CNFs. On five high-dimensional density estimation and generative modeling tasks, OT-Flow performs competitively to a state-of-the-art CNF while on average requiring one-fourth of the number of weights with 17x speedup in training time and 28x speedup in inference.