 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Event-Based Control for Online Training of Neural Networks
Mar 20, 2020
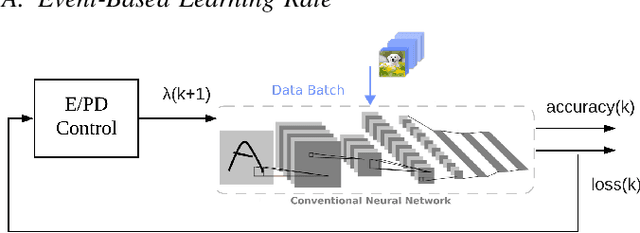
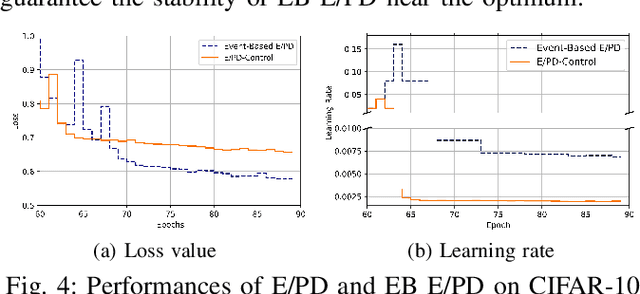
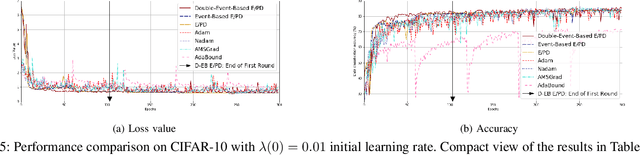
Convolutional Neural Network (CNN) has become the most used method for image classification tasks. During its training the learning rate and the gradient are two key factors to tune for influencing the convergence speed of the model. Usual learning rate strategies are time-based i.e. monotonous decay over time. Recent state-of-the-art techniques focus on adaptive gradient algorithms i.e. Adam and its versions. In this paper we consider an online learning scenario and we propose two Event-Based control loops to adjust the learning rate of a classical algorithm E (Exponential)/PD (Proportional Derivative)-Control. The first Event-Based control loop will be implemented to prevent sudden drop of the learning rate when the model is approaching the optimum. The second Event-Based control loop will decide, based on the learning speed, when to switch to the next data batch. Experimental evaluationis provided using two state-of-the-art machine learning image datasets (CIFAR-10 and CIFAR-100). Results show the Event-Based E/PD is better than the original algorithm (higher final accuracy, lower final loss value), and the Double-Event-BasedE/PD can accelerate the training process, save up to 67% training time compared to state-of-the-art algorithms and even result in better performance.
Improving Relational Regularized Autoencoders with Spherical Sliced Fused Gromov Wasserstein
Oct 05, 2020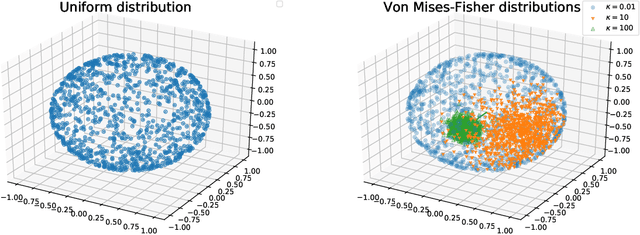
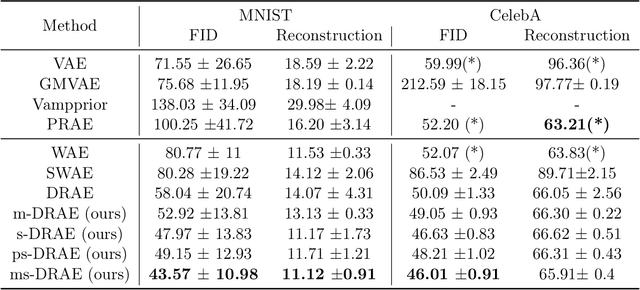
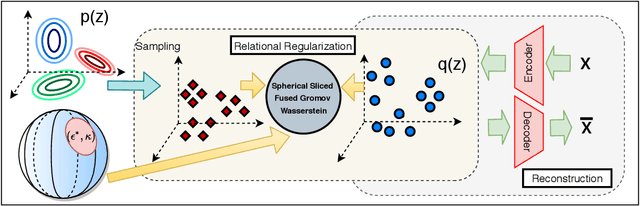
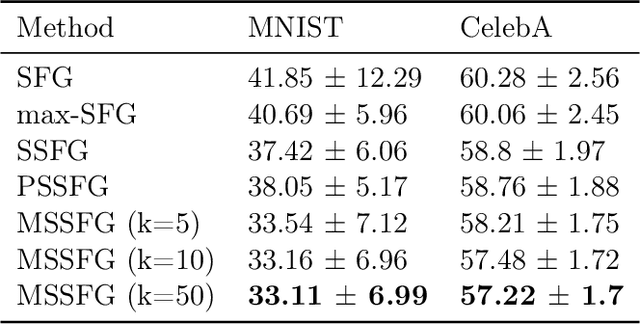
Relational regularized autoencoder (RAE) is a framework to learn the distribution of data by minimizing a reconstruction loss together with a relational regularization on the latent space. A recent attempt to reduce the inner discrepancy between the prior and aggregated posterior distributions is to incorporate sliced fused Gromov-Wasserstein (SFG) between these distributions. That approach has a weakness since it treats every slicing direction similarly, meanwhile several directions are not useful for the discriminative task. To improve the discrepancy and consequently the relational regularization, we propose a new relational discrepancy, named spherical sliced fused Gromov Wasserstein (SSFG), that can find an important area of projections characterized by a von Mises-Fisher distribution. Then, we introduce two variants of SSFG to improve its performance. The first variant, named mixture spherical sliced fused Gromov Wasserstein (MSSFG), replaces the vMF distribution by a mixture of von Mises-Fisher distributions to capture multiple important areas of directions that are far from each other. The second variant, named power spherical sliced fused Gromov Wasserstein (PSSFG), replaces the vMF distribution by a power spherical distribution to improve the sampling time in high dimension settings. We then apply the new discrepancies to the RAE framework to achieve its new variants. Finally, we conduct extensive experiments to show that the new proposed autoencoders have favorable performance in learning latent manifold structure, image generation, and reconstruction.
Entanglement-Embedded Recurrent Network Architecture: Tensorized Latent State Propagation and Chaos Forecasting
Jun 10, 2020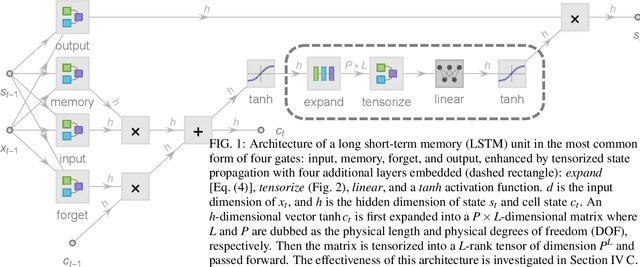
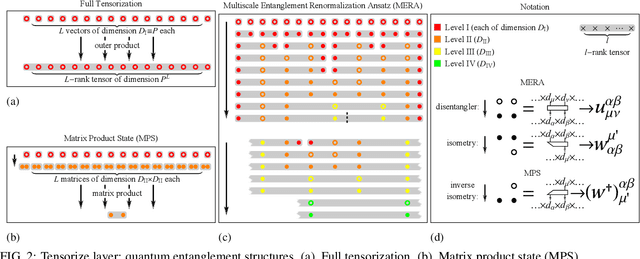
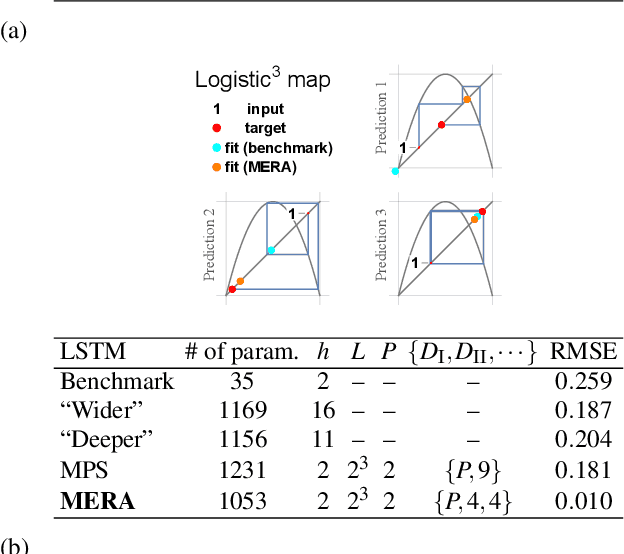
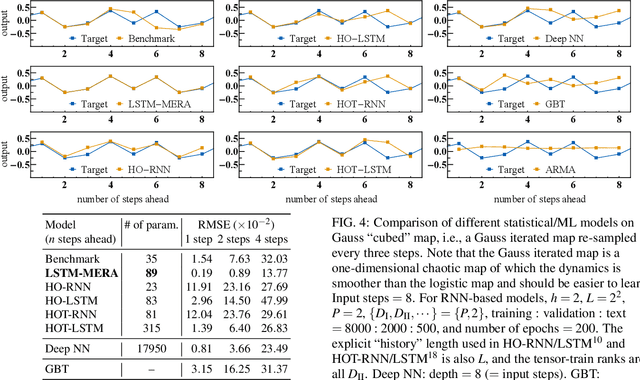
Chaotic time series forecasting has been far less understood despite its tremendous potential in theory and real-world applications. Traditional statistical/ML methods are inefficient to capture chaos in nonlinear dynamical systems, especially when the time difference $\Delta t$ between consecutive steps is so large that a trivial, ergodic local minimum would most likely be reached instead. Here, we introduce a new long-short-term-memory (LSTM)-based recurrent architecture by tensorizing the cell-state-to-state propagation therein, keeping the long-term memory feature of LSTM while simultaneously enhancing the learning of short-term nonlinear complexity. We stress that the global minima of chaos can be most efficiently reached by tensorization where all nonlinear terms, up to some polynomial order, are treated explicitly and weighted equally. The efficiency and generality of our architecture are systematically tested and confirmed by theoretical analysis and experimental results. In our design, we have explicitly used two different many-body entanglement structures---matrix product states (MPS) and the multiscale entanglement renormalization ansatz (MERA)---as physics-inspired tensor decomposition techniques, from which we find that MERA generally performs better than MPS, hence conjecturing that the learnability of chaos is determined not only by the number of free parameters but also the tensor complexity---recognized as how entanglement entropy scales with varying matricization of the tensor.
Motivations and Preliminary Design for Mid-Air Deployment of a Science Rotorcraft on Mars
Oct 13, 2020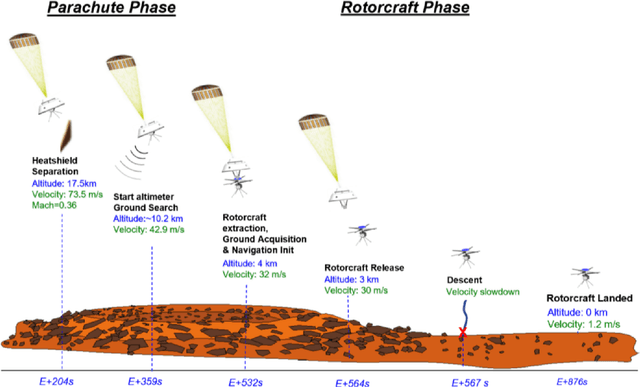
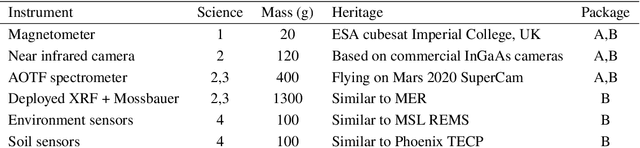
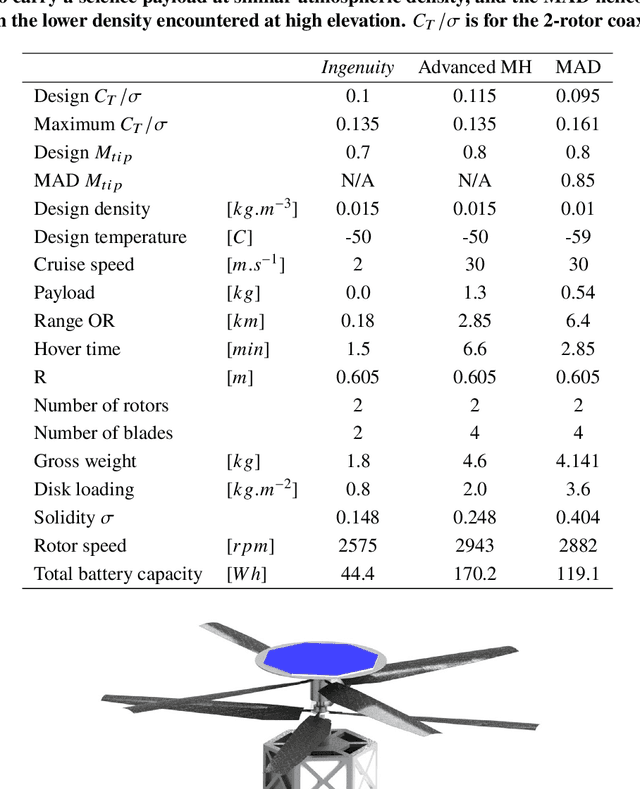
Mid-Air Deployment (MAD) of a rotorcraft during Entry, Descent and Landing (EDL) on Mars eliminates the need to carry a propulsion or airbag landing system. This reduces the total mass inside the aeroshell by more than 100 kg and simplifies the aeroshell architecture. MAD's lighter and simpler design is likely to bring the risk and cost associated with the mission down. Moreover, the lighter entry mass enables landing in the Martian highlands, at elevations inaccessible to current EDL technologies. This paper proposes a novel MAD concept for a Mars helicopter. We suggest a minimum science payload package to perform relevant science in the highlands. A variant of the Ingenuity helicopter is proposed to provide increased deceleration during MAD, and enough lift to fly the science payload in the highlands. We show in simulation that the lighter aeroshell results in a lower terminal velocity (30 m/s) at the end of the parachute phase of the EDL, and at higher altitudes than other approaches. After discussing the aerodynamics, controls, guidance, and mechanical challenges associated with deploying at such speed, we propose a backshell architecture that addresses them to release the helicopter in the safest conditions. Finally, we implemented the helicopter model and aerodynamic descent perturbations in the JPL Dynamics and Real-Time Simulation (DARTS)framework. Preliminary performance evaluation indicates landing and helicopter operation scan be achieved up to 5 km MOLA (Mars Orbiter Laser Altimeter reference).
Anomaly Detection in Unsupervised Surveillance Setting Using Ensemble of Multimodal Data with Adversarial Defense
Jul 17, 2020
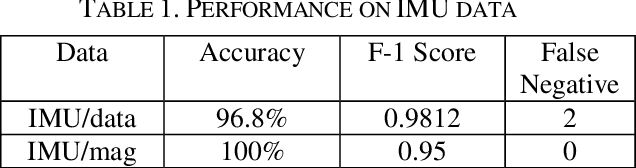
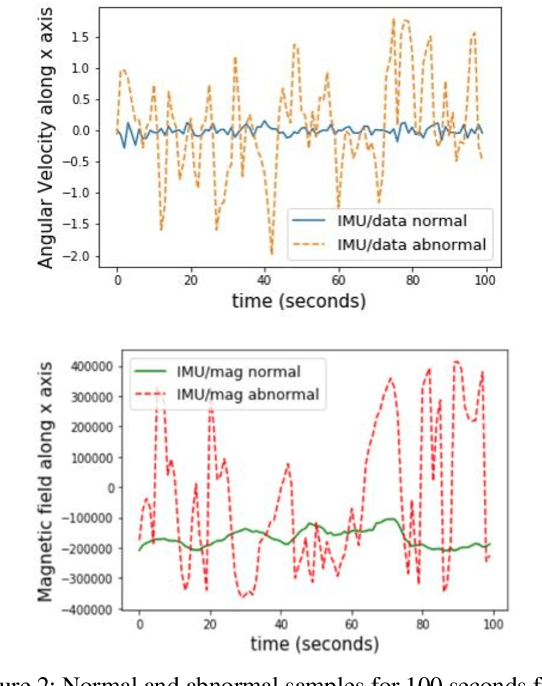
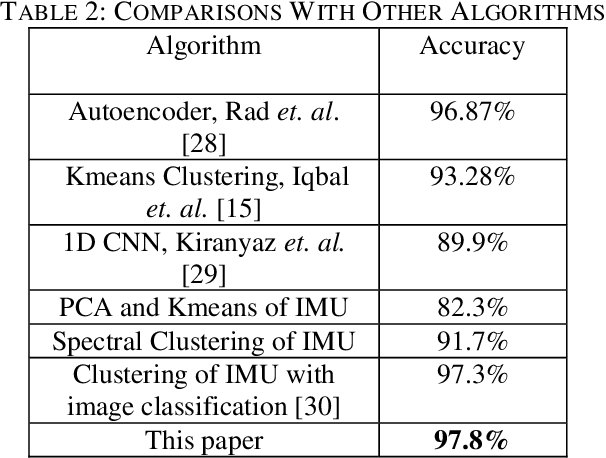
Autonomous aerial surveillance using drone feed is an interesting and challenging research domain. To ensure safety from intruders and potential objects posing threats to the zone being protected, it is crucial to be able to distinguish between normal and abnormal states in real-time. Additionally, we also need to consider any device malfunction. However, the inherent uncertainty embedded within the type and level of abnormality makes supervised techniques less suitable since the adversary may present a unique anomaly for intrusion. As a result, an unsupervised method for anomaly detection is preferable taking the unpredictable nature of attacks into account. Again in our case, the autonomous drone provides heterogeneous data streams consisting of images and other analog or digital sensor data, all of which can play a role in anomaly detection if they are ensembled synergistically. To that end, an ensemble detection mechanism is proposed here which estimates the degree of abnormality of analyzing the real-time image and IMU (Inertial Measurement Unit) sensor data in an unsupervised manner. First, we have implemented a Convolutional Neural Network (CNN) regression block, named AngleNet to estimate the angle between a reference image and current test image, which provides us with a measure of the anomaly of the device. Moreover, the IMU data are used in autoencoders to predict abnormality. Finally, the results from these two pipelines are ensembled to estimate the final degree of abnormality. Furthermore, we have applied adversarial attack to test the robustness and security of the proposed approach and integrated defense mechanism. The proposed method performs satisfactorily on the IEEE SP Cup-2020 dataset with an accuracy of 97.8%. Additionally, we have also tested this approach on an in-house dataset to validate its robustness.
WaveCycleGAN2: Time-domain Neural Post-filter for Speech Waveform Generation
Apr 09, 2019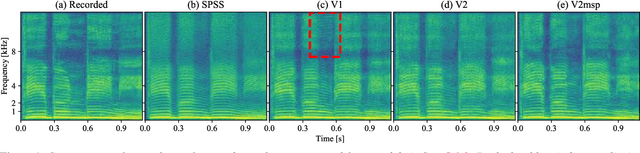
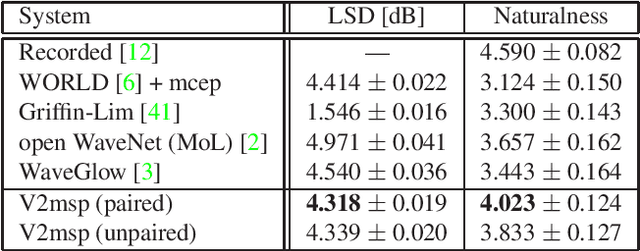
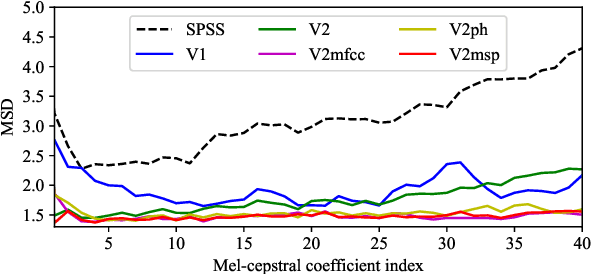
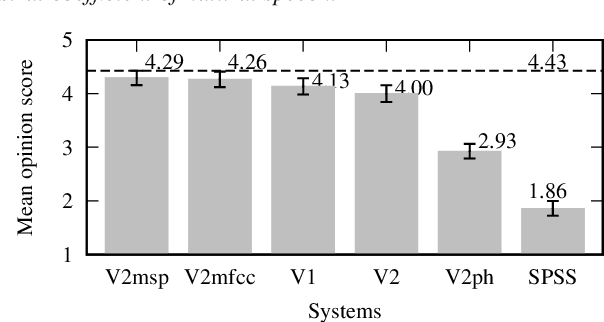
WaveCycleGAN has recently been proposed to bridge the gap between natural and synthesized speech waveforms in statistical parametric speech synthesis and provides fast inference with a moving average model rather than an autoregressive model and high-quality speech synthesis with the adversarial training. However, the human ear can still distinguish the processed speech waveforms from natural ones. One possible cause of this distinguishability is the aliasing observed in the processed speech waveform via down/up-sampling modules. To solve the aliasing and provide higher quality speech synthesis, we propose WaveCycleGAN2, which 1) uses generators without down/up-sampling modules and 2) combines discriminators of the waveform domain and acoustic parameter domain. The results show that the proposed method 1) alleviates the aliasing well, 2) is useful for both speech waveforms generated by analysis-and-synthesis and statistical parametric speech synthesis, and 3) achieves a mean opinion score comparable to those of natural speech and speech synthesized by WaveNet (open WaveNet) and WaveGlow while processing speech samples at a rate of more than 150 kHz on an NVIDIA Tesla P100.
3D_DEN: Open-ended 3D Object Recognition using Dynamically Expandable Networks
Sep 15, 2020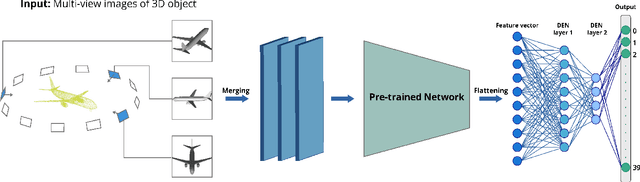
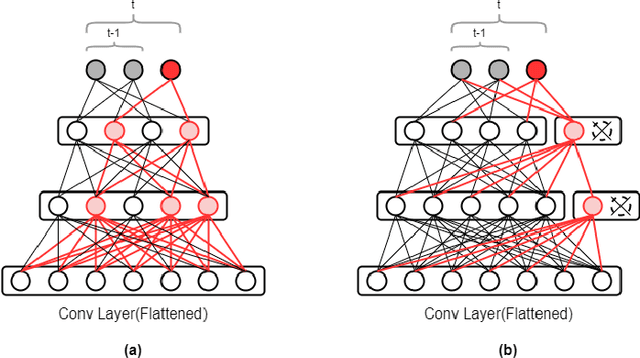
Service robots, in general, have to work independently and adapt to the dynamic changes in the environment. One important aspect in such scenarios is to continually learn to recognize new objects when they become available. This combines two main research problems namely continual learning and 3D object recognition. Most of the existing research approaches include the use of deep Convolutional Neural Networks (CNNs) focusing on image datasets. A modified approach might be needed for continually learning 3D objects. A major concern in using CNNs is the problem of catastrophic forgetting when a model tries to learn new data. In spite of various recent proposed solutions to mitigate this problem, there still exist a few side-effects (such as time/computational complexity) of such solutions. We propose a model capable of learning 3D objects in an open-ended fashion by employing deep transfer learning-based approach combined with dynamically expandable layers, which also makes sure that these side-effects are minimized to a great extent. We show that this model sets a new state-of-the-art standard not only with regards to accuracy but also for computational complexity.
End-to-end Learning for OFDM: From Neural Receivers to Pilotless Communication
Oct 13, 2020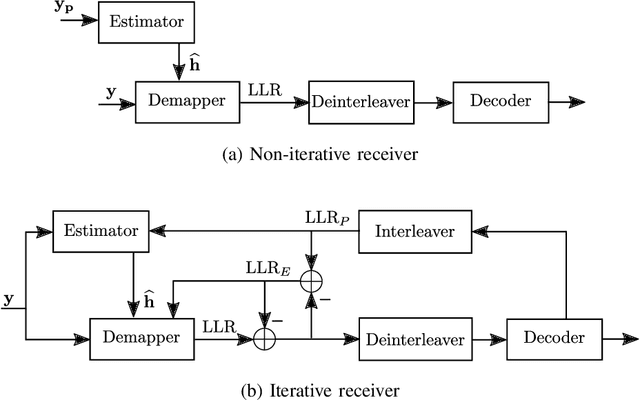
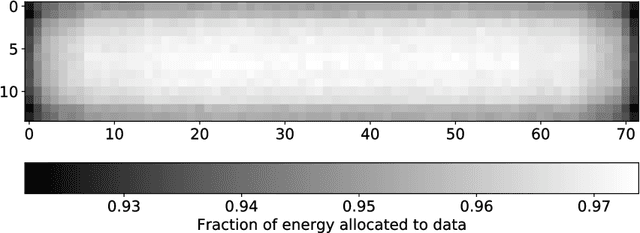
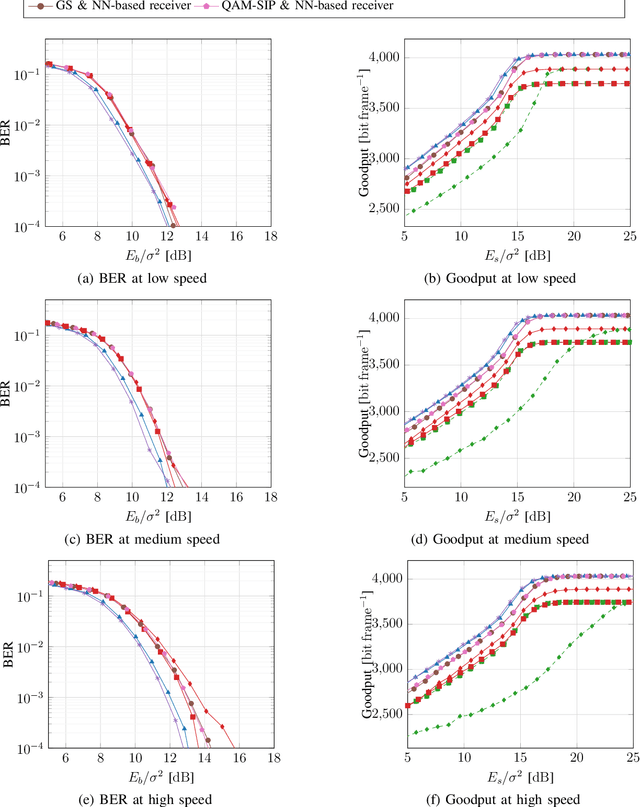
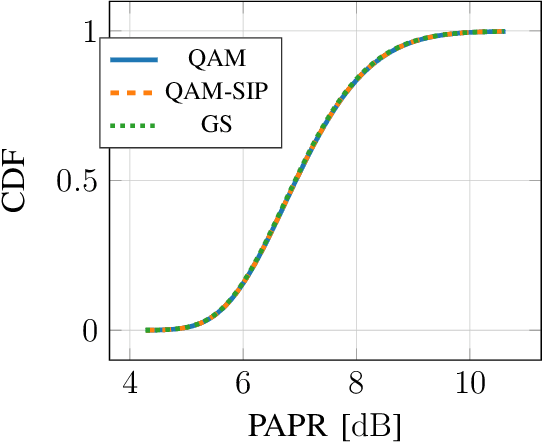
Previous studies have demonstrated that end-to-end learning enables significant shaping gains over additive white Gaussian noise (AWGN) channels. However, its benefits have not yet been quantified over realistic wireless channel models. This work aims to fill this gap by exploring the gains of end-to-end learning over a frequency- and time-selective fading channel using orthogonal frequency division multiplexing (OFDM). With imperfect channel knowledge at the receiver, the shaping gains observed on AWGN channels vanish. Nonetheless, we identify two other sources of performance improvements. The first comes from a neural network (NN)-based receiver operating over a large number of subcarriers and OFDM symbols which allows to significantly reduce the number of orthogonal pilots without loss of bit error rate (BER). The second comes from entirely eliminating orthognal pilots by jointly learning a neural receiver together with either superimposed pilots (SIPs), linearly combined with conventional quadrature amplitude modulation (QAM), or an optimized constellation geometry. The learned geometry works for a wide range of signal-to-noise ratios (SNRs), Doppler and delay spreads, has zero mean and does hence not contain any form of superimposed pilots. Both schemes achieve the same BER as the pilot-based baseline with around 7% higher throughput. Thus, we believe that a jointly learned transmitter and receiver are a very interesting component for beyond-5G communication systems which could remove the need and associated control overhead for demodulation reference signals (DMRSs).
Approximate spectral clustering using both reference vectors and topology of the network generated by growing neural gas
Sep 15, 2020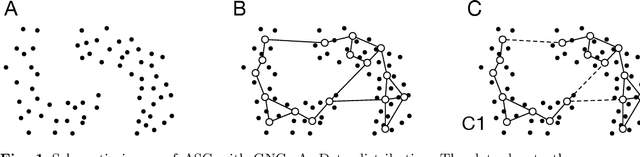
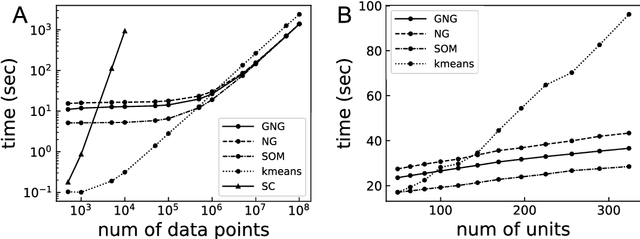
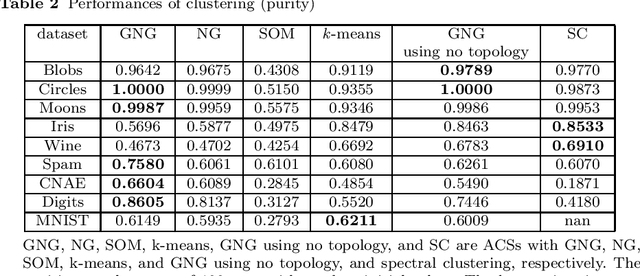
Spectral clustering (SC) is one of the most popular clustering methods and often outperforms traditional clustering methods. SC uses the eigenvectors of a Laplacian matrix calculated from a similarity matrix of a dataset. SC has serious drawbacks that are the significant increase in the computational complexity derived from the eigendecomposition and the memory space complexities to store the similarity matrix. To address the issues, I develop a new approximate spectral clustering using the network generated by growing neural gas (GNG), called ASC with GNG in this study. The proposed method uses not only reference vectors for vector quantization but also the topology of the network for extraction of the topological relationship between data points in a dataset. The similarity matrix used by ASC with GNG is made from both the reference vectors and the topology of the network generated by GNG. Using the network generated from a dataset by GNG, we achieve to reduce the computational and space complexities and to improve clustering quality. This paper demonstrates that the proposed method effectively reduces the computational time. Moreover, the results of this study show that the proposed method displays equal to or better performance of clustering than SC.
Hyper-spectral NIR and MIR data and optimal wavebands for detection of apple tree diseases
Apr 24, 2020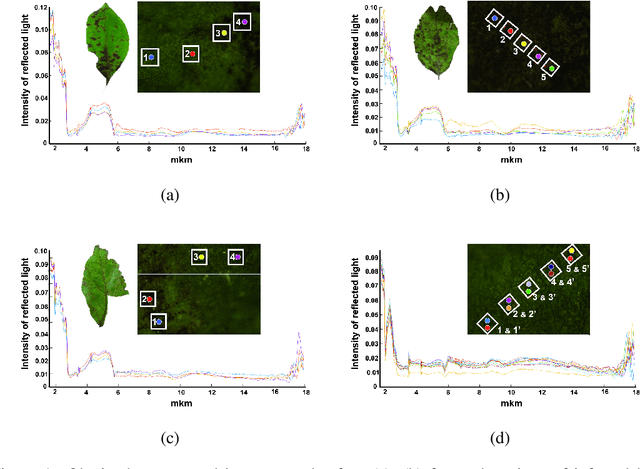

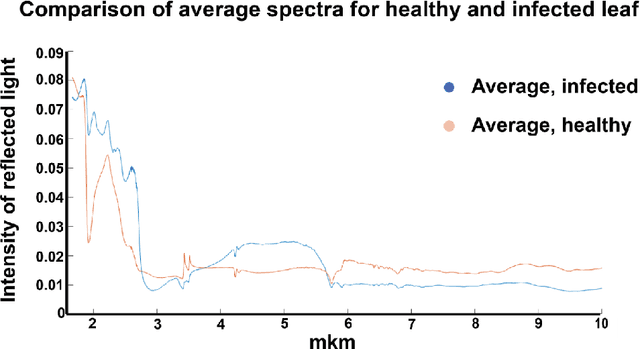
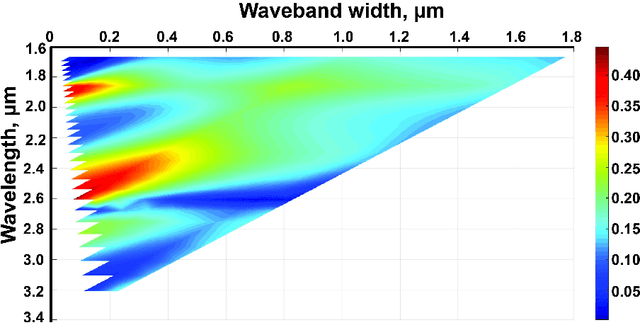
Plant diseases can lead to dramatic losses in yield and quality of food, becoming a problem of high priority for farmers. Apple scab, moniliasis, and powdery mildew are the most significant apple tree diseases worldwide and may cause between 50% and 60% in yield losses annually; they are controlled by fungicide use with huge financial and time expenses. This research proposes a modern approach for analyzing the spectral data in Near-Infrared and Mid-Infrared ranges of the apple tree diseases at different stages. Using the obtained spectra, we found optimal spectral bands for detecting particular disease and discriminating it from other diseases and healthy trees. The proposed instrument will provide farmers with accurate, real-time information on different stages of apple tree diseases, enabling more effective timing, and selecting the fungicide application, resulting in better control and increasing yield. The obtained dataset, as well as scripts in Matlab for processing data and finding optimal spectral bands, are available via the link: https://yadi.sk/d/ZqfGaNlYVR3TUA