 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Explaining Neural Matrix Factorization with Gradient Rollback
Oct 14, 2020




Explaining the predictions of neural black-box models is an important problem, especially when such models are used in applications where user trust is crucial. Estimating the influence of training examples on a learned neural model's behavior allows us to identify training examples most responsible for a given prediction and, therefore, to faithfully explain the output of a black-box model. The most generally applicable existing method is based on influence functions, which scale poorly for larger sample sizes and models. We propose gradient rollback, a general approach for influence estimation, applicable to neural models where each parameter update step during gradient descent touches a smaller number of parameters, even if the overall number of parameters is large. Neural matrix factorization models trained with gradient descent are part of this model class. These models are popular and have found a wide range of applications in industry. Especially knowledge graph embedding methods, which belong to this class, are used extensively. We show that gradient rollback is highly efficient at both training and test time. Moreover, we show theoretically that the difference between gradient rollback's influence approximation and the true influence on a model's behavior is smaller than known bounds on the stability of stochastic gradient descent. This establishes that gradient rollback is robustly estimating example influence. We also conduct experiments which show that gradient rollback provides faithful explanations for knowledge base completion and recommender datasets.
Modeling and Prediction of Rigid Body Motion with Planar Non-Convex Contact
Oct 05, 2020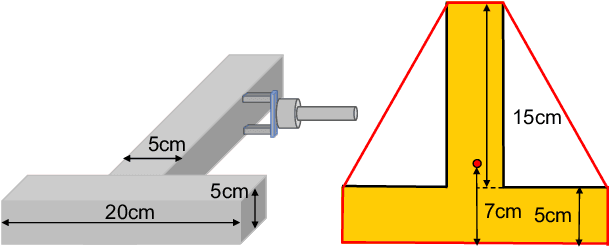
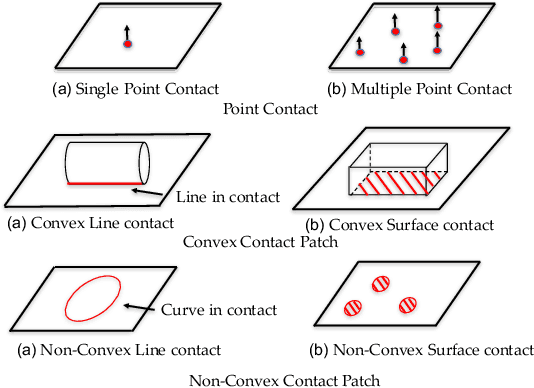
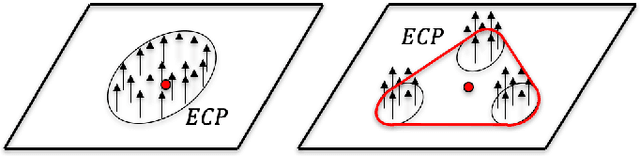
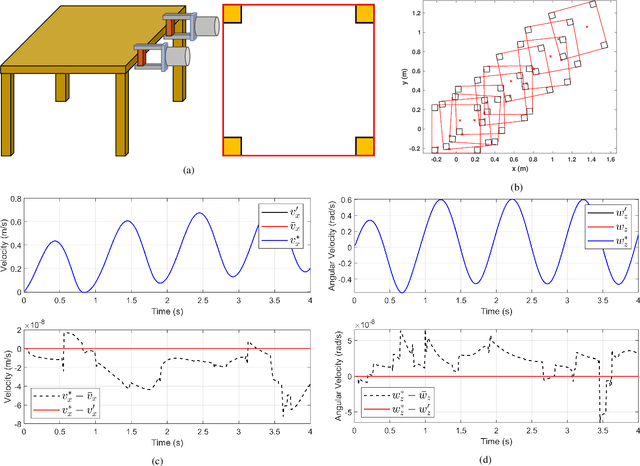
We present a principled method for motion prediction via dynamic simulation for rigid bodies in intermittent contact with each other where the contact region is a planar non-convex contact patch. Such methods are useful in planning and control for robotic manipulation. The planar non-convex contact patch can either be a topologically connected set or disconnected set. Most work in rigid body dynamic simulation assume that the contact between objects is a point contact, which may not be valid in many applications. In this paper, by using the convex hull of the contact patch, we build on our recent work on simulating rigid bodies with convex contact patches for simulating motion of objects with planar non-convex contact patches. We formulate a discrete-time mixed complementarity problem where we solve the contact detection and integration of the equations of motion simultaneously. We solve for the equivalent contact point (ECP) and contact impulse of each contact patch simultaneously along with the state, i.e., configuration and velocity of the objects. We prove that although we are representing a patch contact by an equivalent point, our model for enforcing non-penetration constraints ensure that there is no artificial penetration between the contacting rigid bodies. We provide empirical evidence to show that our method can seamlessly capture transition among different contact modes like patch contact, multiple or single point contact.
TensorFlow with user friendly Graphical Framework for object detection API
Jun 11, 2020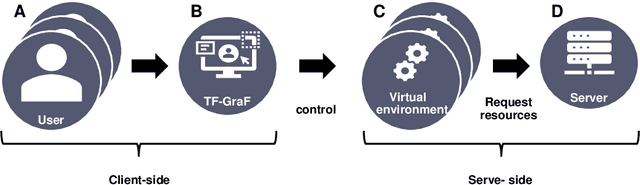
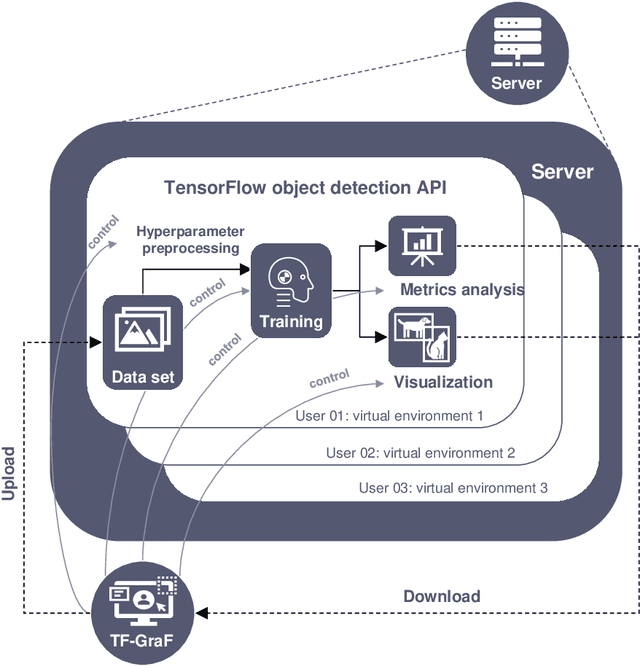
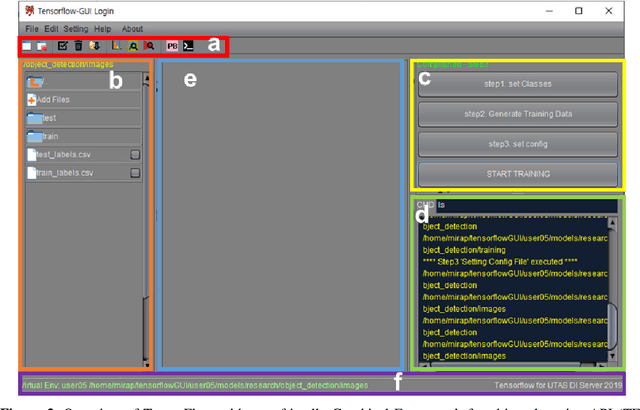
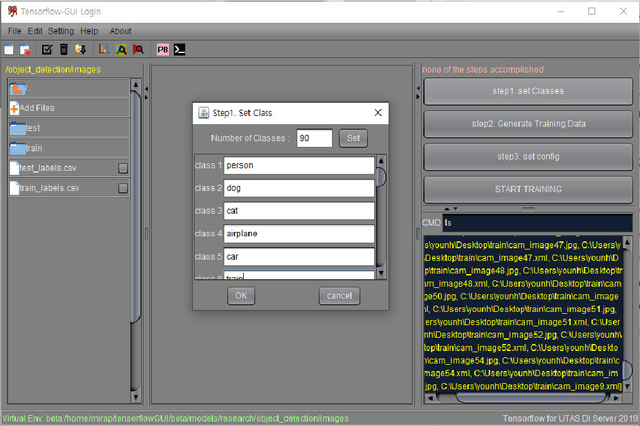
TensorFlow is an open-source framework for deep learning dataflow and contains application programming interfaces (APIs) of voice analysis, natural language process, and computer vision. Especially, TensorFlow object detection API in computer vision field has been widely applied to technologies of agriculture, engineering, and medicine but barriers to entry of the framework usage is still high through command-line interface (CLI) and code for amateurs and beginners of information technology (IT) field. Therefore, this is aim to develop an user friendly Graphical Framework for object detection API on TensorFlow which is called TensorFlow Graphical Framework (TF-GraF). The TF-GraF provides independent virtual environments according to user accounts in server-side, additionally, execution of data preprocessing, training, and evaluation without CLI in client-side. Furthermore, hyperparameter setting, real-time observation of training process, object visualization of test images, and metrics evaluations of test data can also be operated via TF-GraF. Especially, TF-GraF supports flexible model selection of SSD, Faster-RCNN, RFCN, and Mask-RCNN including convolutional neural networks (inceptions and ResNets) through GUI environment. Consequently, TF-GraF allows anyone, even without any previous knowledge of deep learning frameworks, to design, train and deploy machine intelligence models without coding. Since TF-GraF takes care of setting and configuration, it allows anyone to use deep learning technology for their project without spending time to install complex software and environment.
NullSpaceNet: Nullspace Convoluional Neural Network with Differentiable Loss Function
Apr 25, 2020



We propose NullSpaceNet, a novel network that maps from the pixel level input to a joint-nullspace (as opposed to the traditional feature space), where the newly learned joint-nullspace features have clearer interpretation and are more separable. NullSpaceNet ensures that all inputs from the same class are collapsed into one point in this new joint-nullspace, and the different classes are collapsed into different points with high separation margins. Moreover, a novel differentiable loss function is proposed that has a closed-form solution with no free-parameters. NullSpaceNet exhibits superior performance when tested against VGG16 with fully-connected layer over 4 different datasets, with accuracy gain of up to 4.55%, a reduction in learnable parameters from 135M to 19M, and reduction in inference time of 99% in favor of NullSpaceNet. This means that NullSpaceNet needs less than 1% of the time it takes a traditional CNN to classify a batch of images with better accuracy.
Going Deeper With Directly-Trained Larger Spiking Neural Networks
Oct 29, 2020
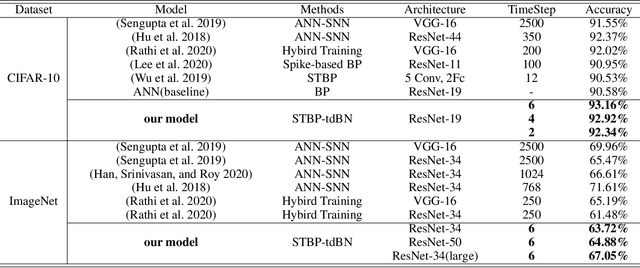
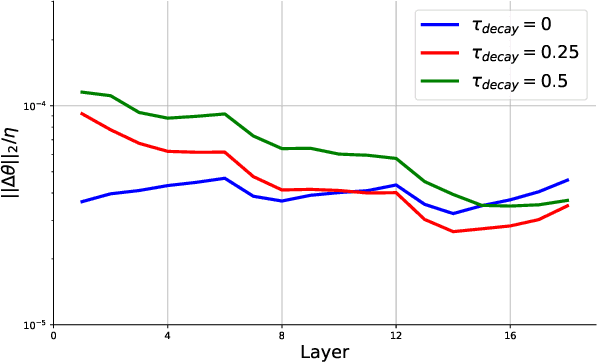
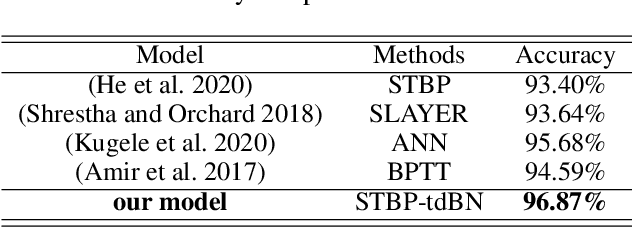
Spiking neural networks (SNNs) are promising in a bio-plausible coding for spatio-temporal information and event-driven signal processing, which is very suited for energy-efficient implementation in neuromorphic hardware. However, the unique working mode of SNNs makes them more difficult to train than traditional networks. Currently, there are two main routes to explore the training of deep SNNs with high performance. The first is to convert a pre-trained ANN model to its SNN version, which usually requires a long coding window for convergence and cannot exploit the spatio-temporal features during training for solving temporal tasks. The other is to directly train SNNs in the spatio-temporal domain. But due to the binary spike activity of the firing function and the problem of gradient vanishing or explosion, current methods are restricted to shallow architectures and thereby difficult in harnessing large-scale datasets (e.g. ImageNet). To this end, we propose a threshold-dependent batch normalization (tdBN) method based on the emerging spatio-temporal backpropagation, termed "STBP-tdBN", enabling direct training of a very deep SNN and the efficient implementation of its inference on neuromorphic hardware. With the proposed method and elaborated shortcut connection, we significantly extend directly-trained SNNs from a shallow structure ( < 10 layer) to a very deep structure (50 layers). Furthermore, we theoretically analyze the effectiveness of our method based on "Block Dynamical Isometry" theory. Finally, we report superior accuracy results including 93.15 % on CIFAR-10, 67.8 % on DVS-CIFAR10, and 67.05% on ImageNet with very few timesteps. To our best knowledge, it's the first time to explore the directly-trained deep SNNs with high performance on ImageNet.
Dense-View GEIs Set: View Space Covering for Gait Recognition based on Dense-View GAN
Sep 26, 2020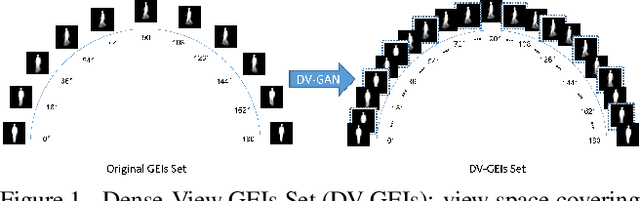
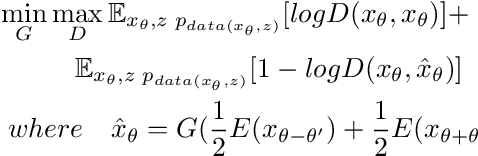
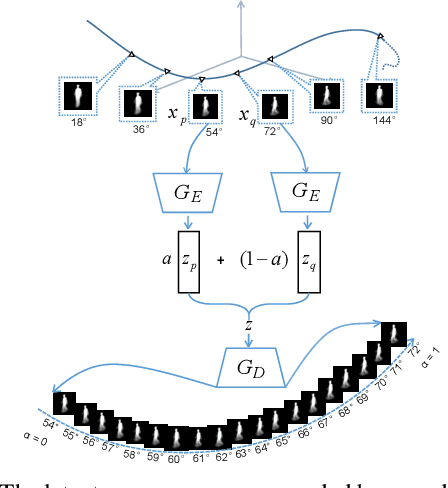

Gait recognition has proven to be effective for long-distance human recognition. But view variance of gait features would change human appearance greatly and reduce its performance. Most existing gait datasets usually collect data with a dozen different angles, or even more few. Limited view angles would prevent learning better view invariant feature. It can further improve robustness of gait recognition if we collect data with various angles at 1 degree interval. But it is time consuming and labor consuming to collect this kind of dataset. In this paper, we, therefore, introduce a Dense-View GEIs Set (DV-GEIs) to deal with the challenge of limited view angles. This set can cover the whole view space, view angle from 0 degree to 180 degree with 1 degree interval. In addition, Dense-View GAN (DV-GAN) is proposed to synthesize this dense view set. DV-GAN consists of Generator, Discriminator and Monitor, where Monitor is designed to preserve human identification and view information. The proposed method is evaluated on the CASIA-B and OU-ISIR dataset. The experimental results show that DV-GEIs synthesized by DV-GAN is an effective way to learn better view invariant feature. We believe the idea of dense view generated samples will further improve the development of gait recognition.
Two-Stage Clustering of Household Electricity Load Shapes based on Temporal Pattern & Peak Demand
Aug 10, 2020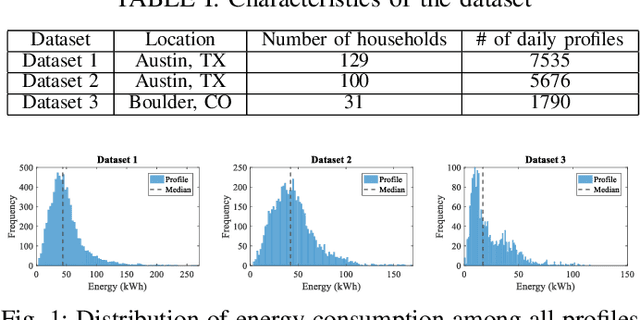
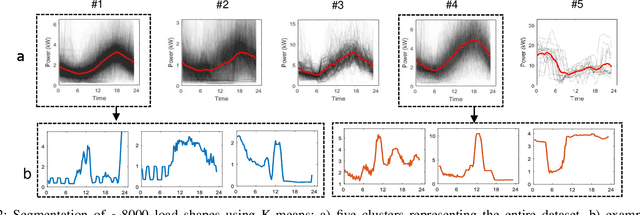
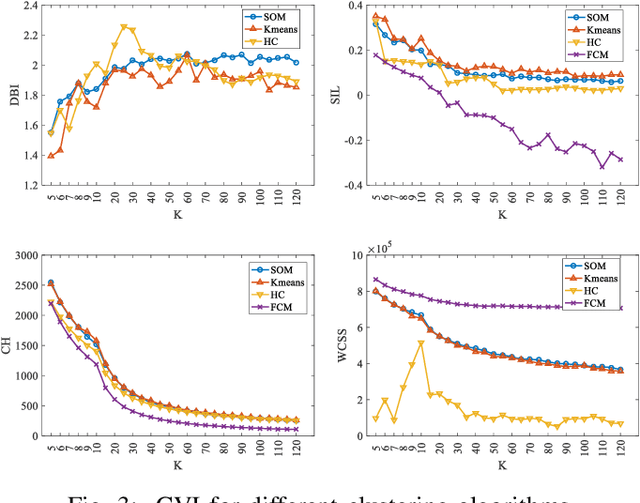
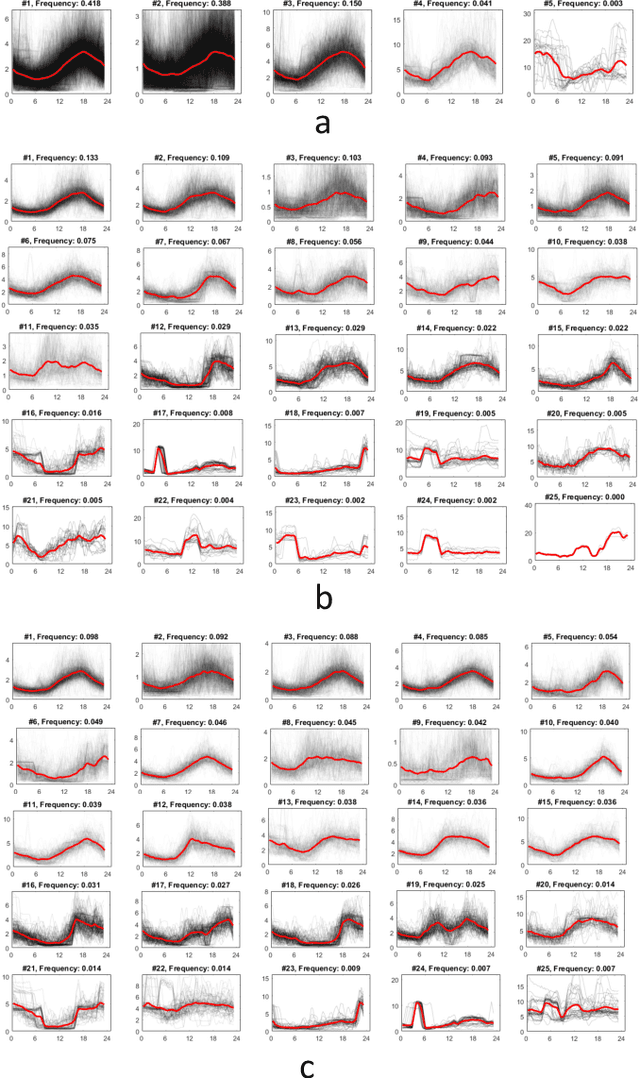
Analyzing smart meter data to understand energy consumption patterns helps utilities and energy providers perform customized demand response operations. Existing energy consumption segmentation techniques use assumptions that could result in reduced quality of clusters in representing their members. We address this limitation by introducing a two-stage clustering method that more accurately captures load shape temporal patterns and peak demands. In the first stage, load shapes are clustered by allowing a large number of clusters to accurately capture variations in energy use patterns and cluster centroids are extracted by accounting for shape misalignments. In the second stage, clusters of similar centroid and power magnitude range are merged by using Dynamic Time Warping. We used three datasets consisting of ~250 households (~15000 profiles) to demonstrate the performance improvement, compared to baseline methods, and discuss the impact on energy management.
DAER to Reject Seeds with Dual-loss Additional Error Regression
Sep 16, 2020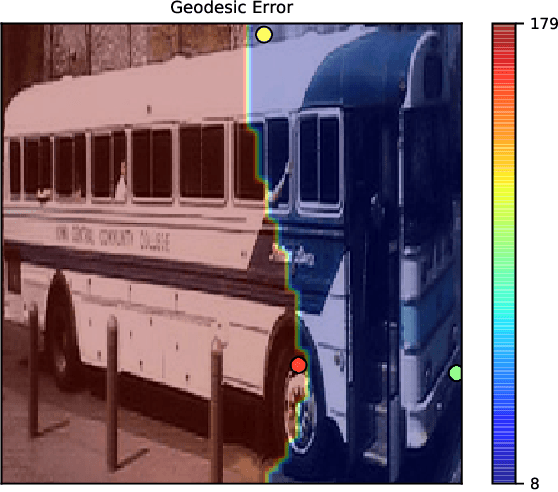
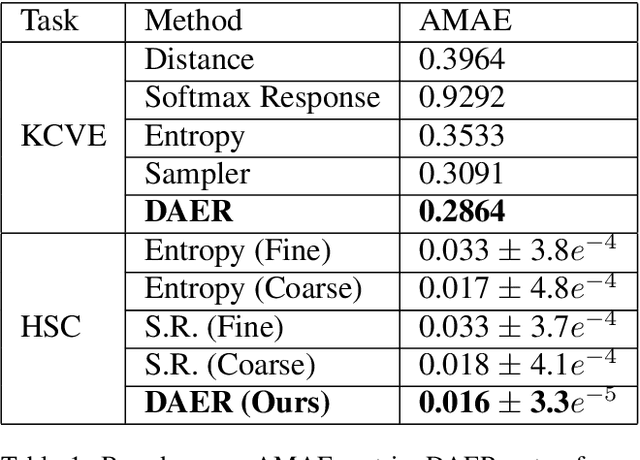
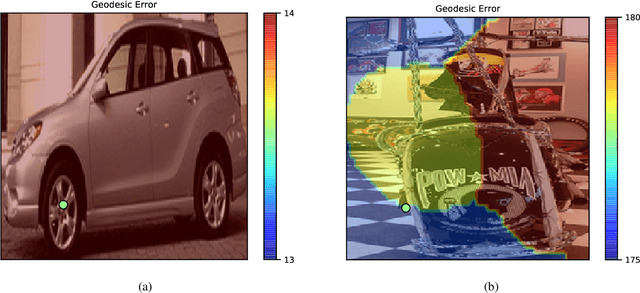
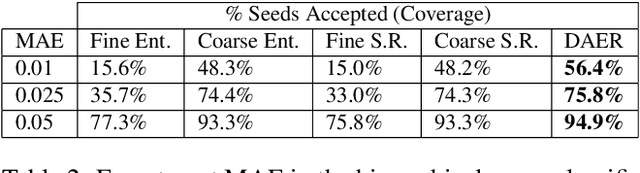
Many vision tasks require side information at inference time---a seed---to fully specify the problem. For example, an initial object segmentation is needed for video object segmentation. To date, all such work makes the tacit assumption that the seed is a good one. However, in practice, from crowd-sourcing to noisy automated seeds, this is not the case. We hence propose the novel problem of seed rejection---determining whether to reject a seed based on expected degradation relative to the gold-standard. We provide a formal definition to this problem, and focus on two challenges: distinguishing poor primary inputs from poor seeds and understanding the model's response to noisy seeds conditioned on the primary input. With these challenges in mind, we propose a novel training method and evaluation metrics for the seed rejection problem. We then validate these metrics and methods on two problems which use seeds as a source of additional information: keypoint-conditioned viewpoint estimation with crowdsourced seeds and hierarchical scene classification with automated seeds. In these experiments, we show our method reduces the required number of seeds that need to be reviewed for a target performance by up to 23% over strong baselines.
Model-Reference Reinforcement Learning for Collision-Free Tracking Control of Autonomous Surface Vehicles
Aug 17, 2020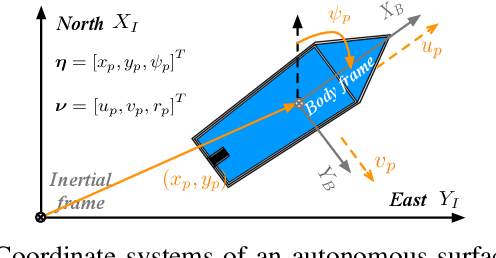
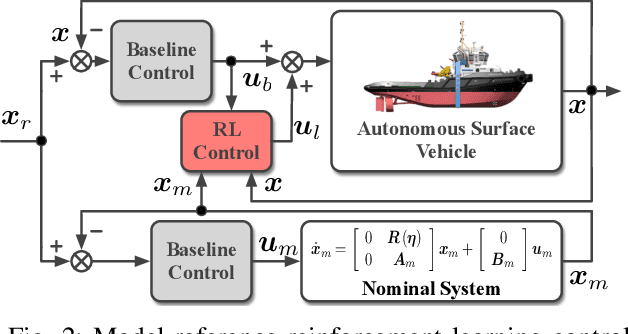
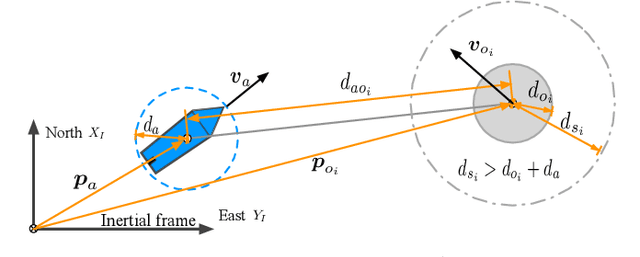
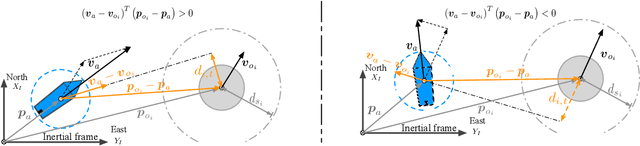
This paper presents a novel model-reference reinforcement learning algorithm for the intelligent tracking control of uncertain autonomous surface vehicles with collision avoidance. The proposed control algorithm combines a conventional control method with reinforcement learning to enhance control accuracy and intelligence. In the proposed control design, a nominal system is considered for the design of a baseline tracking controller using a conventional control approach. The nominal system also defines the desired behaviour of uncertain autonomous surface vehicles in an obstacle-free environment. Thanks to reinforcement learning, the overall tracking controller is capable of compensating for model uncertainties and achieving collision avoidance at the same time in environments with obstacles. In comparison to traditional deep reinforcement learning methods, our proposed learning-based control can provide stability guarantees and better sample efficiency. We demonstrate the performance of the new algorithm using an example of autonomous surface vehicles.
Monocular Rotational Odometry with Incremental Rotation Averaging and Loop Closure
Oct 05, 2020
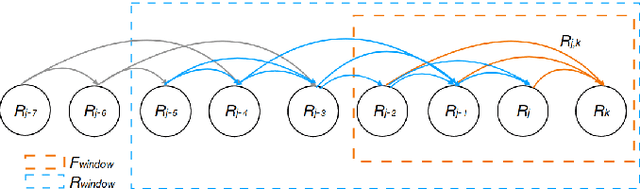
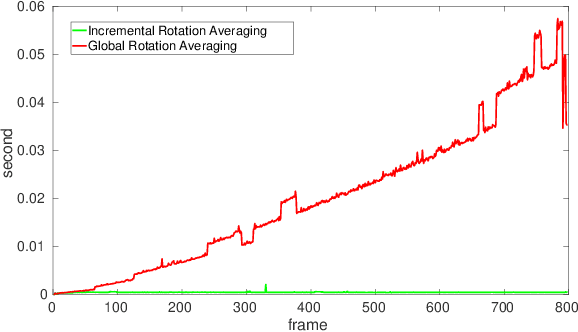
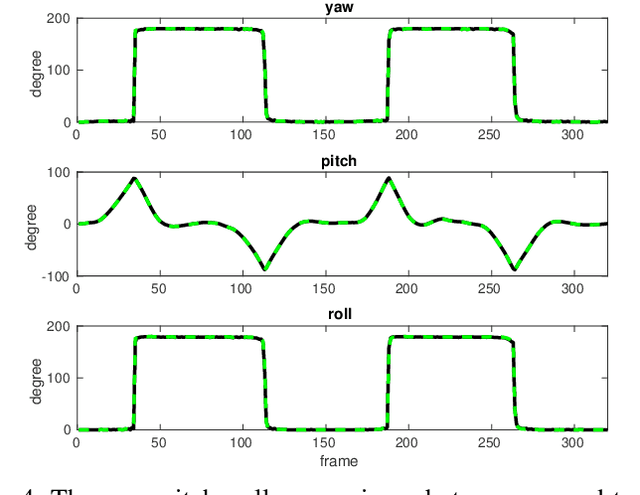
Estimating absolute camera orientations is essential for attitude estimation tasks. An established approach is to first carry out visual odometry (VO) or visual SLAM (V-SLAM), and retrieve the camera orientations (3 DOF) from the camera poses (6 DOF) estimated by VO or V-SLAM. One drawback of this approach, besides the redundancy in estimating full 6 DOF camera poses, is the dependency on estimating a map (3D scene points) jointly with the 6 DOF poses due to the basic constraint on structure-and-motion. To simplify the task of absolute orientation estimation, we formulate the monocular rotational odometry problem and devise a fast algorithm to accurately estimate camera orientations with 2D-2D feature matches alone. Underpinning our system is a new incremental rotation averaging method for fast and constant time iterative updating. Furthermore, our system maintains a view-graph that 1) allows solving loop closure to remove camera orientation drift, and 2) can be used to warm start a V-SLAM system. We conduct extensive quantitative experiments on real-world datasets to demonstrate the accuracy of our incremental camera orientation solver. Finally, we showcase the benefit of our algorithm to V-SLAM: 1) solving the known rotation problem to estimate the trajectory of the camera and the surrounding map, and 2)enabling V-SLAM systems to track pure rotational motions.