 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Protect, Show, Attend and Tell: Image Captioning Model with Ownership Protection
Aug 25, 2020
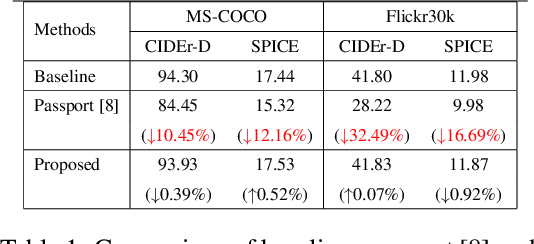
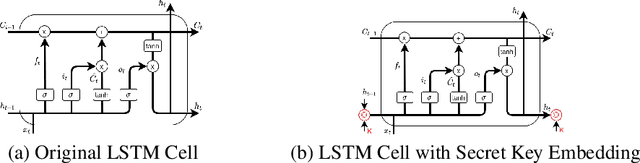
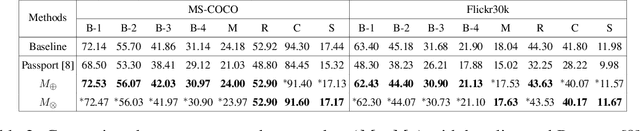

By and large, existing Intellectual Property Right (IPR) protection on deep neural networks typically i) focus on image classification task only, and ii) follow a standard digital watermarking framework that were conventionally used to protect the ownership of multimedia and video content. This paper demonstrates that current digital watermarking framework is insufficient to protect image captioning task that often regarded as one of the frontier A.I. problems. As a remedy, this paper studies and proposes two different embedding schemes in the hidden memory state of a recurrent neural network to protect image captioning model. From both theoretically and empirically points, we prove that a forged key will yield an unusable image captioning model, defeating the purpose on infringement. To the best of our knowledge, this work is the first to propose ownership protection on image captioning task. Also, extensive experiments show that the proposed method does not compromise the original image captioning performance on all common captioning metrics on Flickr30k and MS-COCO datasets, and at the same time it is able to withstand both removal and ambiguity attacks.
Sparse Gaussian Processes for Continuous-Time Trajectory Estimation on Matrix Lie Groups
May 17, 2017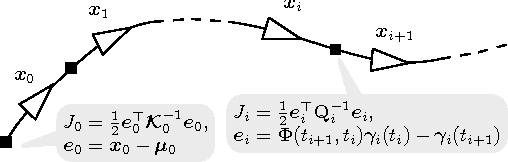
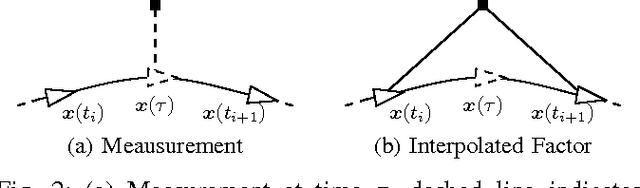
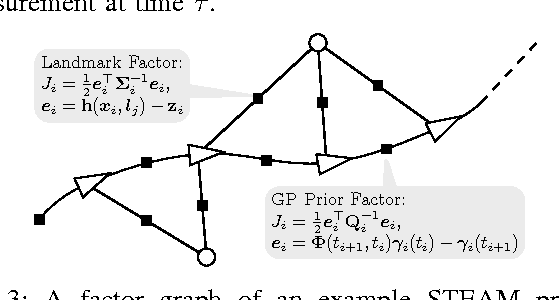
Continuous-time trajectory representations are a powerful tool that can be used to address several issues in many practical simultaneous localization and mapping (SLAM) scenarios, like continuously collected measurements distorted by robot motion, or during with asynchronous sensor measurements. Sparse Gaussian processes (GP) allow for a probabilistic non-parametric trajectory representation that enables fast trajectory estimation by sparse GP regression. However, previous approaches are limited to dealing with vector space representations of state only. In this technical report we extend the work by Barfoot et al. [1] to general matrix Lie groups, by applying constant-velocity prior, and defining locally linear GP. This enables using sparse GP approach in a large space of practical SLAM settings. In this report we give the theory and leave the experimental evaluation in future publications.
Multimodal Joint Attribute Prediction and Value Extraction for E-commerce Product
Sep 15, 2020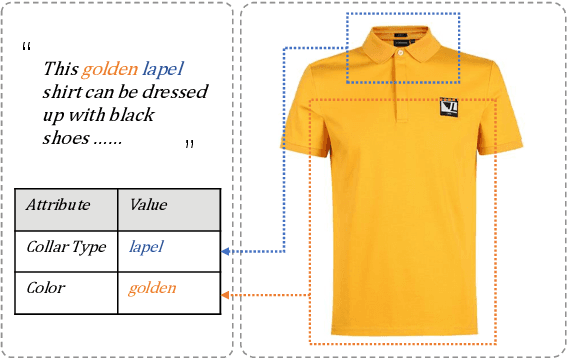
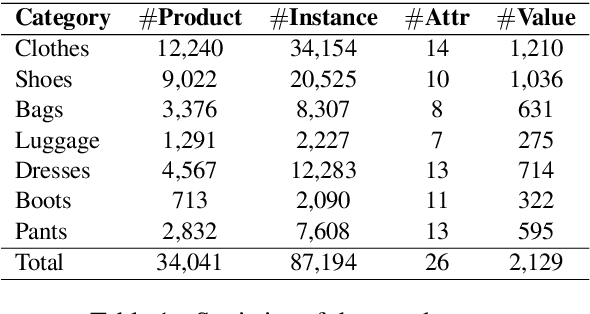
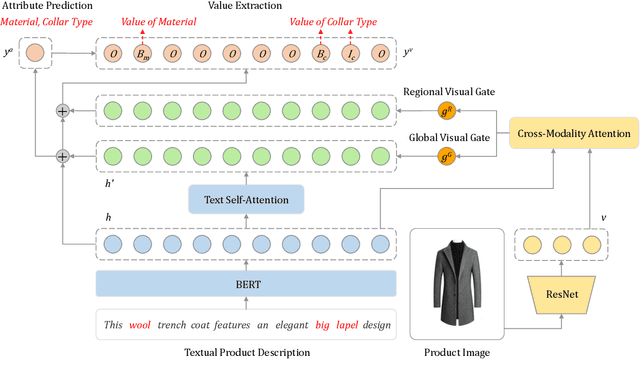
Product attribute values are essential in many e-commerce scenarios, such as customer service robots, product recommendations, and product retrieval. While in the real world, the attribute values of a product are usually incomplete and vary over time, which greatly hinders the practical applications. In this paper, we propose a multimodal method to jointly predict product attributes and extract values from textual product descriptions with the help of the product images. We argue that product attributes and values are highly correlated, e.g., it will be easier to extract the values on condition that the product attributes are given. Thus, we jointly model the attribute prediction and value extraction tasks from multiple aspects towards the interactions between attributes and values. Moreover, product images have distinct effects on our tasks for different product attributes and values. Thus, we selectively draw useful visual information from product images to enhance our model. We annotate a multimodal product attribute value dataset that contains 87,194 instances, and the experimental results on this dataset demonstrate that explicitly modeling the relationship between attributes and values facilitates our method to establish the correspondence between them, and selectively utilizing visual product information is necessary for the task. Our code and dataset will be released to the public.
Towards End-to-end Car License Plate Location and Recognition in Unconstrained Scenarios
Aug 25, 2020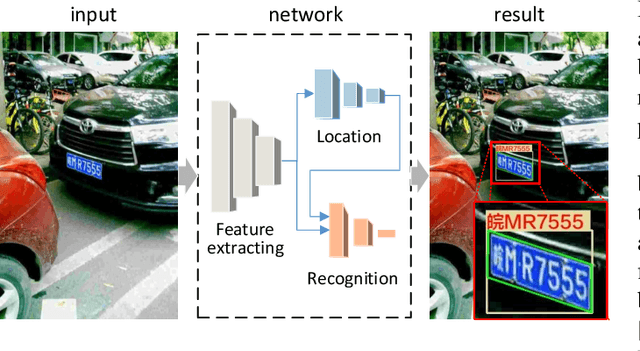
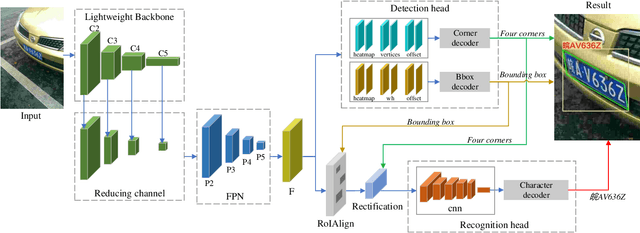
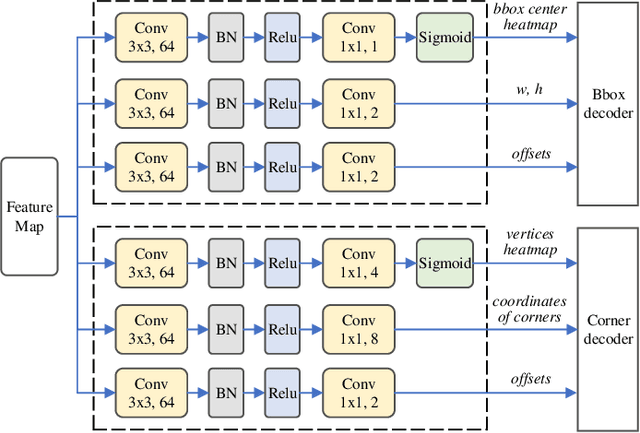
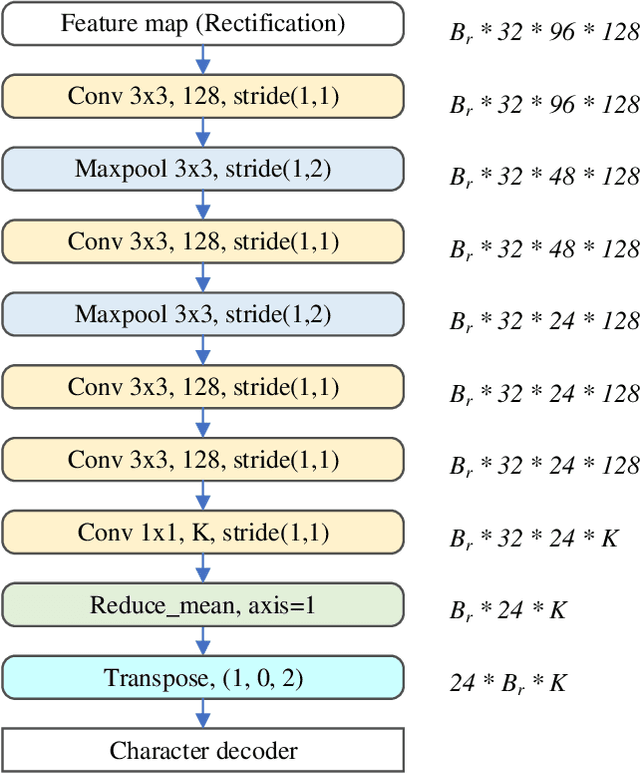
Benefiting from the rapid development of convolutional neural networks, the performance of car license plate detection and recognition has been largely improved. Nonetheless, challenges still exist especially for real-world applications. In this paper, we present an efficient and accurate framework to solve the license plate detection and recognition tasks simultaneously. It is a lightweight and unified deep neural network, that can be optimized end-to-end and work in real-time. Specifically, for unconstrained scenarios, an anchor-free method is adopted to efficiently detect the bounding box and four corners of a license plate, which are used to extract and rectify the target region features. Then, a novel convolutional neural network branch is designed to further extract features of characters without segmentation. Finally, recognition task is treated as sequence labelling problems, which are solved by Connectionist Temporal Classification (CTC) directly. Several public datasets including images collected from different scenarios under various conditions are chosen for evaluation. A large number of experiments indicate that the proposed method significantly outperforms the previous state-of-the-art methods in both speed and precision.
A simulation environment for drone cinematography
Oct 03, 2020
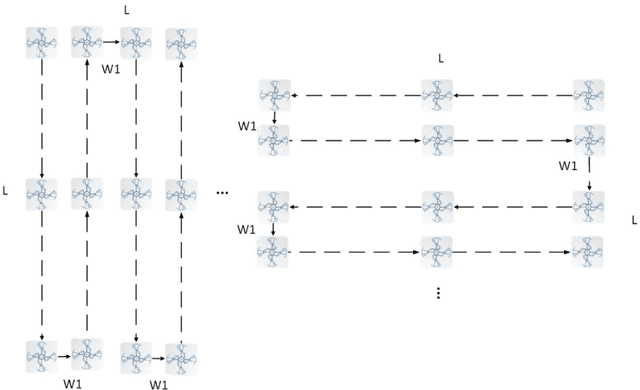
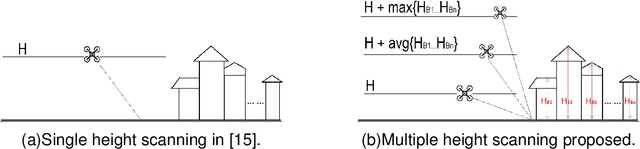

In this paper, we present a workflow for the simulation of drone operations exploiting realistic background environments constructed within Unreal Engine 4 (UE4). Methods for environmental image capture, 3D reconstruction (photogrammetry) and the creation of foreground assets are presented along with a flexible and user-friendly simulation interface. Given the geographical location of the selected area and the camera parameters employed, the scanning strategy and its associated flight parameters are first determined for image capture. Source imagery can be extracted from virtual globe software or obtained through aerial photography of the scene (e.g. using drones). The latter case is clearly more time consuming but can provide enhanced detail, particularly where coverage of virtual globe software is limited. The captured images are then used to generate 3D background environment models employing photogrammetry software. The reconstructed 3D models are then imported into the simulation interface as background environment assets together with appropriate foreground object models as a basis for shot planning and rehearsal. The tool supports both free-flight and parameterisable standard shot types along with programmable scenarios associated with foreground assets and event dynamics. It also supports the exporting of flight plans. Camera shots can also be designed to provide suitable coverage of any landmarks which need to appear in-shot. This simulation tool will contribute to enhanced productivity, improved safety (awareness and mitigations for crowds and buildings), improved confidence of operators and directors and ultimately enhanced quality of viewer experience.
The Right Tool for the Job: Matching Model and Instance Complexities
May 09, 2020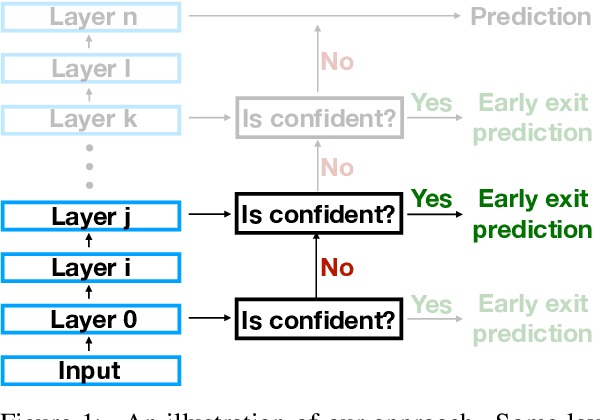
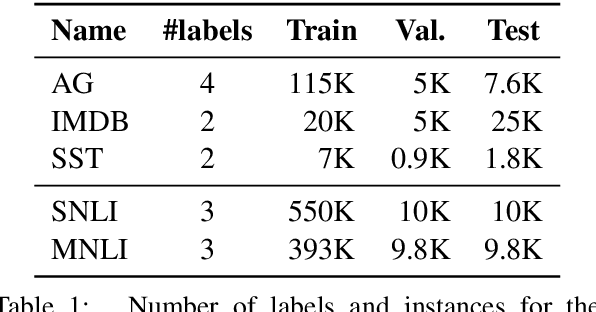
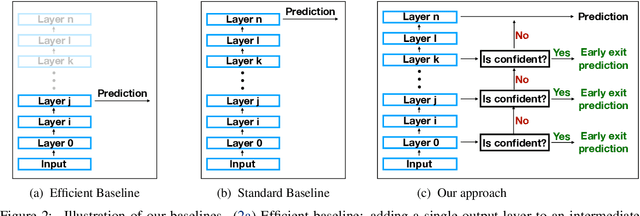
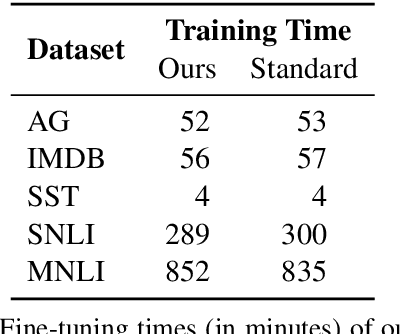
As NLP models become larger, executing a trained model requires significant computational resources incurring monetary and environmental costs. To better respect a given inference budget, we propose a modification to contextual representation fine-tuning which, during inference, allows for an early (and fast) "exit" from neural network calculations for simple instances, and late (and accurate) exit for hard instances. To achieve this, we add classifiers to different layers of BERT and use their calibrated confidence scores to make early exit decisions. We test our proposed modification on five different datasets in two tasks: three text classification datasets and two natural language inference benchmarks. Our method presents a favorable speed/accuracy tradeoff in almost all cases, producing models which are up to five times faster than the state of the art, while preserving their accuracy. Our method also requires almost no additional training resources (in either time or parameters) compared to the baseline BERT model. Finally, our method alleviates the need for costly retraining of multiple models at different levels of efficiency; we allow users to control the inference speed/accuracy tradeoff using a single trained model, by setting a single variable at inference time. We publicly release our code.
A memory of motion for visual predictive control tasks
Feb 28, 2020

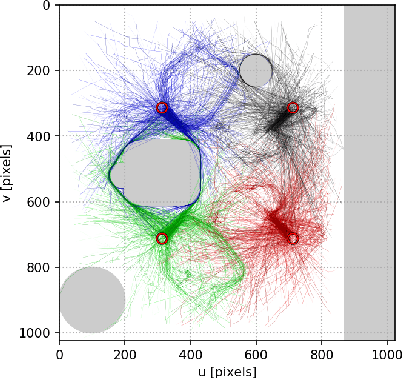
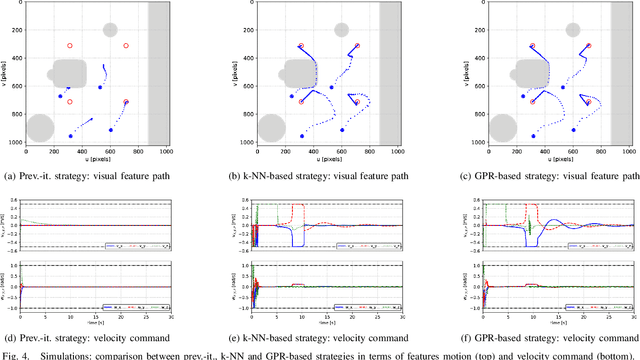
This paper addresses the problem of efficiently achieving visual predictive control tasks. To this end, a memory of motion, containing a set of trajectories built off-line, is used for leveraging precomputation and dealing with difficult visual tasks. Standard regression techniques, such as k-nearest neighbors and Gaussian process regression, are used to query the memory and provide on-line a warm-start and a way point to the control optimization process. The proposed technique allows the control scheme to achieve high performance and, at the same time, keep the computational time limited. Simulation and experimental results, carried out with a 7-axis manipulator, show the effectiveness of the approach.
Solving Stochastic Compositional Optimization is Nearly as Easy as Solving Stochastic Optimization
Aug 25, 2020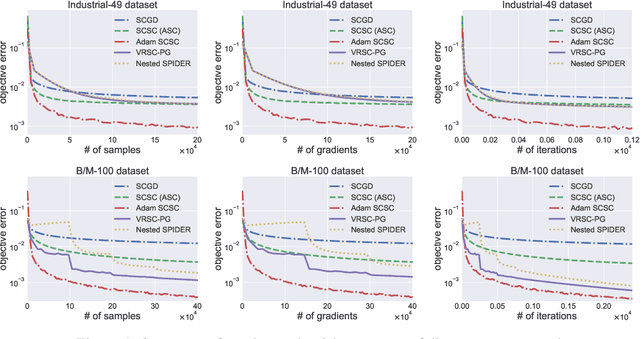
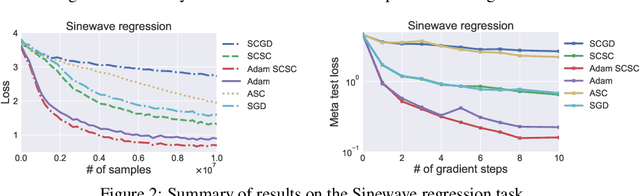
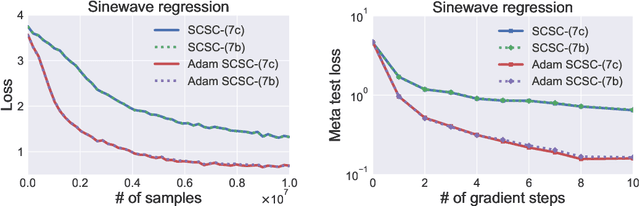
Stochastic compositional optimization generalizes classic (non-compositional) stochastic optimization to the minimization of compositions of functions. Each composition may introduce an additional expectation. The series of expectations may be nested. Stochastic compositional optimization is gaining popularity in applications such as reinforcement learning and meta learning. This paper presents a new Stochastically Corrected Stochastic Compositional gradient method (SCSC). SCSC runs in a single-time scale with a single loop, uses a fixed batch size, and guarantees to converge at the same rate as the stochastic gradient descent (SGD) method for non-compositional stochastic optimization. This is achieved by making a careful improvement to a popular stochastic compositional gradient method. It is easy to apply SGD-improvement techniques to accelerate SCSC. This helps SCSC achieve state-of-the-art performance for stochastic compositional optimization. In particular, we apply Adam to SCSC, and the exhibited rate of convergence matches that of the original Adam on non-compositional stochastic optimization. We test SCSC using the portfolio management and model-agnostic meta-learning tasks.
Dimension reduction in recurrent networks by canonicalization
Jul 23, 2020Many recurrent neural network machine learning paradigms can be formulated using state-space representations. The classical notion of canonical state-space realization is adapted in this paper to accommodate semi-infinite inputs so that it can be used as a dimension reduction tool in the recurrent networks setup. The so called input forgetting property is identified as the key hypothesis that guarantees the existence and uniqueness (up to system isomorphisms) of canonical realizations for causal and time-invariant input/output systems with semi-infinite inputs. A second result uses the notion of optimal reduction borrowed from the theory of symmetric Hamiltonian systems to construct canonical realizations out of input forgetting but not necessarily canonical ones. These two procedures are implemented and studied in detail in the framework of linear fading memory input/output systems.
Anomaly Detection Models for IoT Time Series Data
Nov 30, 2018
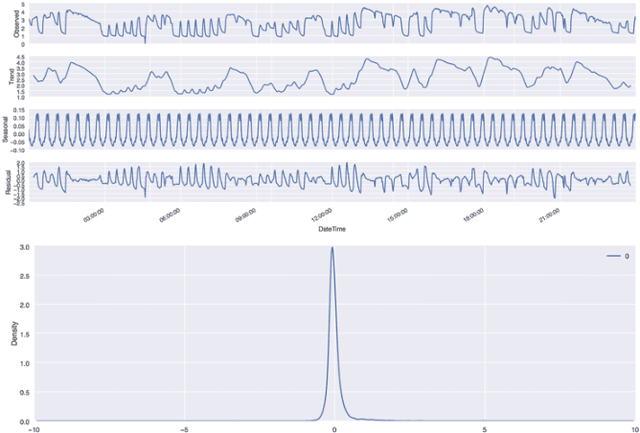
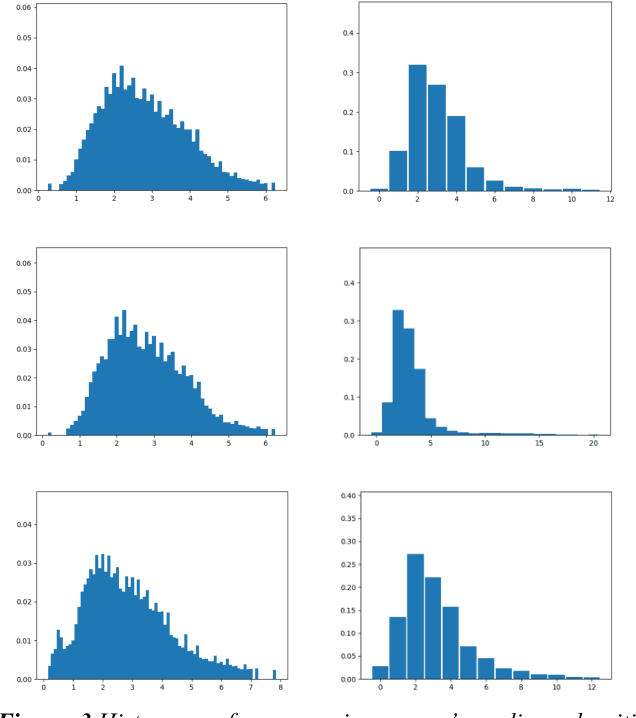
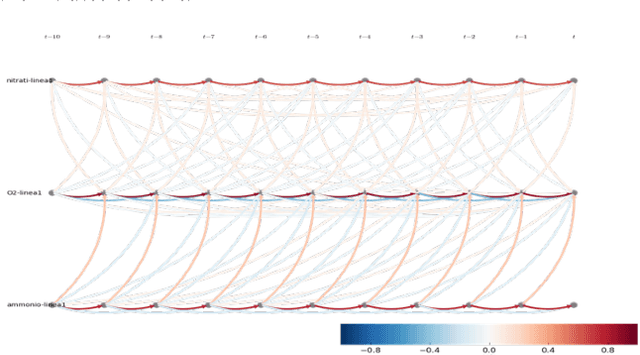
Insitu sensors and Wireless Sensor Networks (WSNs) have become more and more popular in the last decade, due to their potential to be used in various applications of many different fields. As of today, WSNs are pretty much used by any monitoring system: from those that are health care related, to those that are used for environmental forecasting or surveillance purposes. All applications that make use of insitu sensors, strongly rely on their correct operation, which however, is quite difficult to guarantee. These sensors in fact, are typically cheap and prone to malfunction. Additionally, for many tasks (e.g. environmental forecasting), sensors are also deployed under potentially harsh weather condition, making their breakage even more likely. The high probability of erroneous readings or data corruption during transmission, brings up the problem of ensuring quality of the data collected by sensors. Since WSNs have to operate continuously and therefore generate very large volumes of data every day, the quality control process has to be automated, scalable and fast enough to be applicable to streaming data. The most common approach to ensure the quality of sensors data, consists in automated detection of erroneous readings or anomalous behaviours of sensors. In the literature, this strategy is known as anomaly detection and can be pursued in many different ways.