 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A High Probability Analysis of Adaptive SGD with Momentum
Jul 28, 2020
Stochastic Gradient Descent (SGD) and its variants are the most used algorithms in machine learning applications. In particular, SGD with adaptive learning rates and momentum is the industry standard to train deep networks. Despite the enormous success of these methods, our theoretical understanding of these variants in the nonconvex setting is not complete, with most of the results only proving convergence in expectation and with strong assumptions on the stochastic gradients. In this paper, we present a high probability analysis for adaptive and momentum algorithms, under weak assumptions on the function, stochastic gradients, and learning rates. We use it to prove for the first time the convergence of the gradients to zero in high probability in the smooth nonconvex setting for Delayed AdaGrad with momentum.
Back to Event Basics: Self-Supervised Learning of Image Reconstruction for Event Cameras via Photometric Constancy
Sep 17, 2020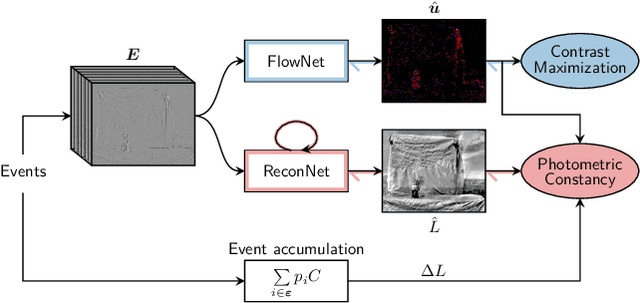

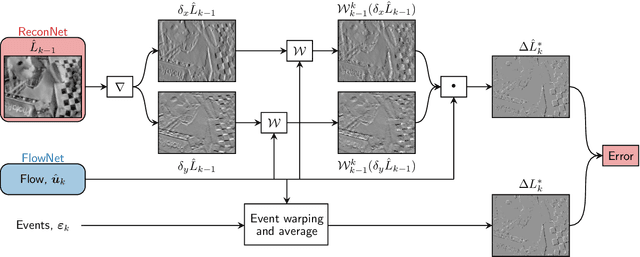
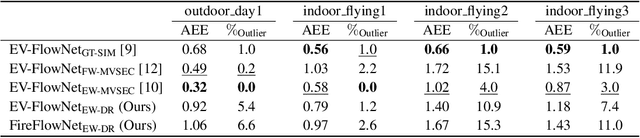
Event cameras are novel vision sensors that sample, in an asynchronous fashion, brightness increments with low latency and high temporal resolution. The resulting streams of events are of high value by themselves, especially for high speed motion estimation. However, a growing body of work has also focused on the reconstruction of intensity frames from the events, as this allows bridging the gap with the existing literature on appearance- and frame-based computer vision. Recent work has mostly approached this intensity reconstruction problem using neural networks trained with synthetic, ground-truth data. Nevertheless, since accurate ground truth is only available in simulation, these methods are subject to the reality gap and, to ensure generalizability, their training datasets need to be carefully designed. In this work, we approach, for the first time, the reconstruction problem from a self-supervised learning perspective. Our framework combines estimated optical flow and the event-based photometric constancy to train neural networks without the need for any ground-truth or synthetic data. Results across multiple datasets show that the performance of the proposed approach is in line with the state-of-the-art.
Efficient Framework for Learning Code Representations through Semantic-Preserving Program Transformations
Sep 06, 2020
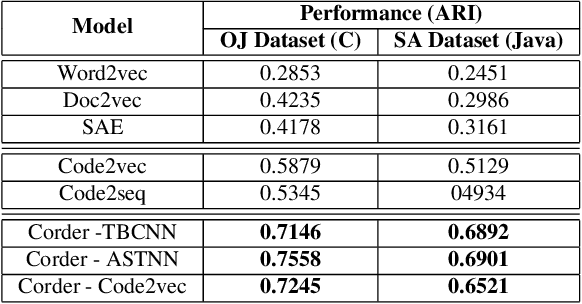
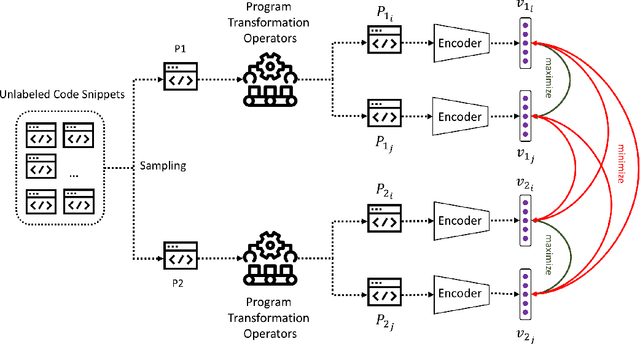
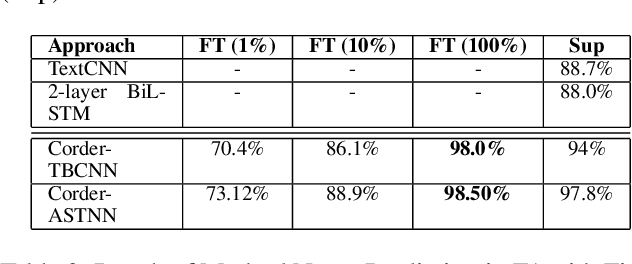
Recent learning techniques for the representation of code depend mostly on human-annotated (labeled) data. In this work, we are proposing Corder, a self-supervised learning system that can learn to represent code without having to label data. The key innovation is that we train the source code model by asking it to recognize similar and dissimilar code snippets through a contrastive learning paradigm. We use a set of semantic-preserving transformation operators to generate snippets that are syntactically diverse but semantically equivalent. The contrastive learning objective, at the same time, maximizes agreement between different views of the same snippets and minimizes agreement between transformed views of different snippets. We train different instances of Corder on 3 neural network encoders, which are Tree-based CNN, ASTNN, and Code2vec over 2.5 million unannotated Java methods mined from GitHub. Our result shows that the Corder pre-training improves code classification and method name prediction with large margins. Furthermore, the code vectors generated by Corder are adapted to code clustering which has been shown to significantly beat the other baselines.
Robust Reinforcement Learning: A Case Study in Linear Quadratic Regulation
Aug 25, 2020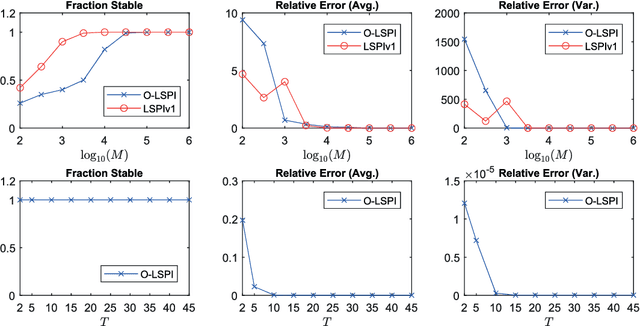
This paper studies the robustness aspect of reinforcement learning algorithms in the presence of errors. Specifically, we revisit the benchmark problem of discrete-time linear quadratic regulation (LQR) and study the long-standing open question: Under what conditions is the policy iteration method robustly stable for dynamical systems with unbounded, continuous state and action spaces? Using advanced stability results in control theory, it is shown that policy iteration for LQR is inherently robust to small errors and enjoys local input-to-state stability: whenever the error in each iteration is bounded and small, the solutions of the policy iteration algorithm are also bounded, and, moreover, enter and stay in a small neighborhood of the optimal LQR solution. As an application, a novel off-policy optimistic least-squares policy iteration for the LQR problem is proposed, when the system dynamics are subjected to additive stochastic disturbances. The proposed new results in robust reinforcement learning are validated by a numerical example.
What is SemEval evaluating? A Systematic Analysis of Evaluation Campaigns in NLP
May 28, 2020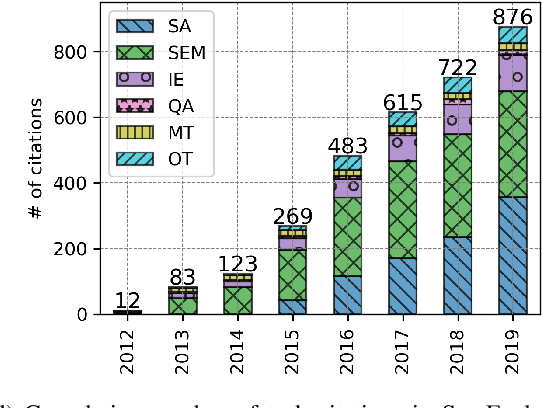
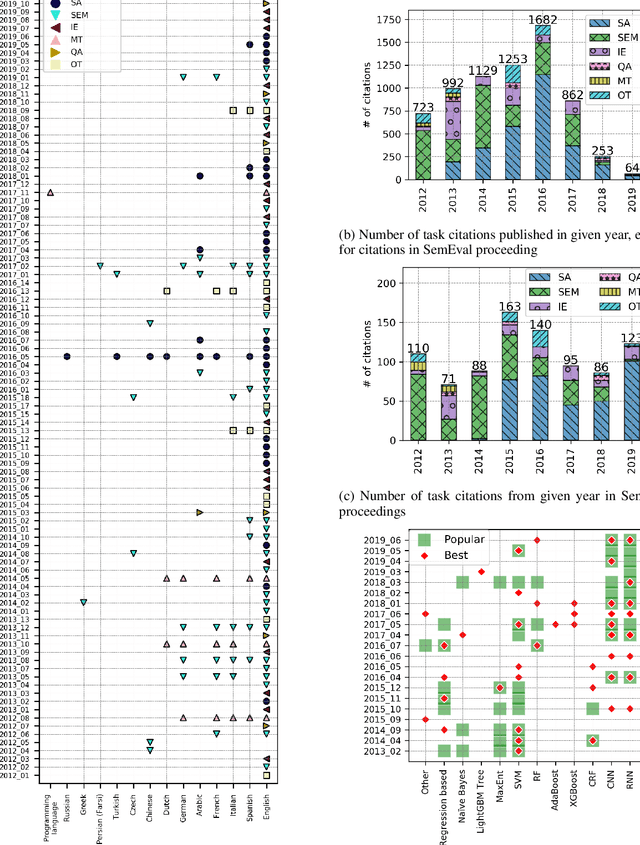
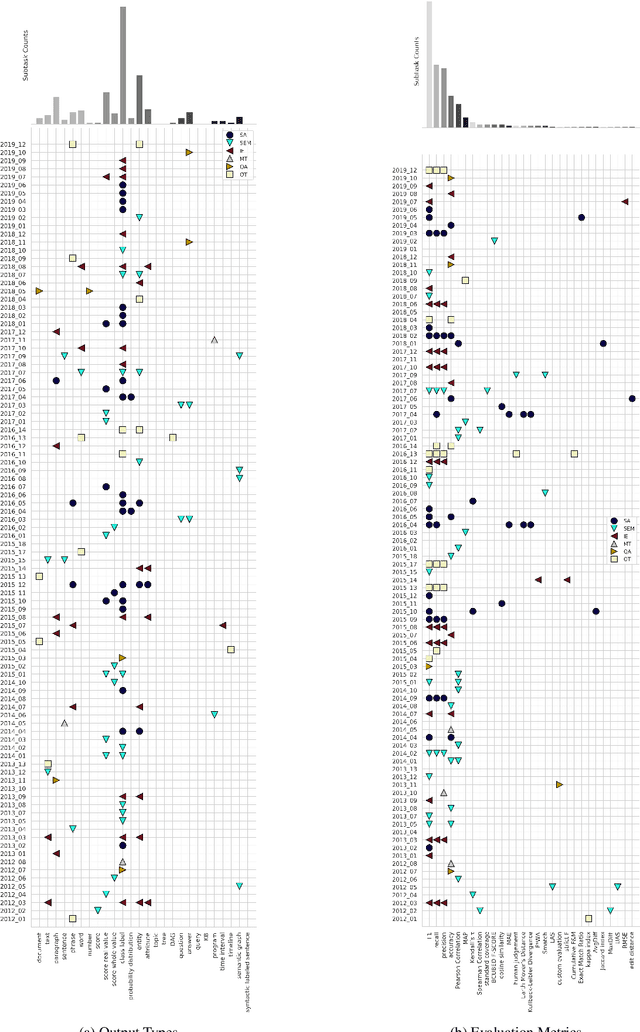
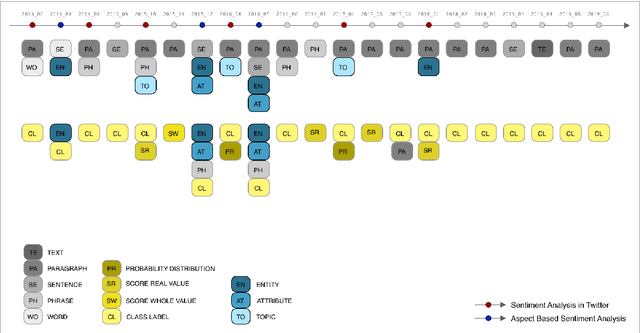
SemEval is the primary venue in the NLP community for the proposal of new challenges and for the systematic empirical evaluation of NLP systems. This paper provides a systematic quantitative analysis of SemEval aiming to evidence the patterns of the contributions behind SemEval. By understanding the distribution of task types, metrics, architectures, participation and citations over time we aim to answer the question on what is being evaluated by SemEval.
Uncertainty-aware Self-supervised 3D Data Association
Aug 18, 2020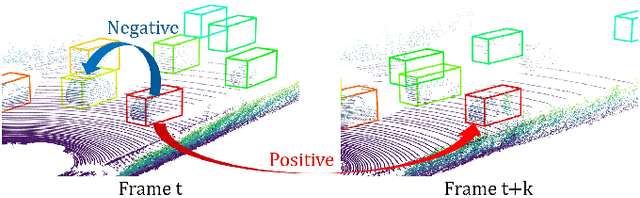

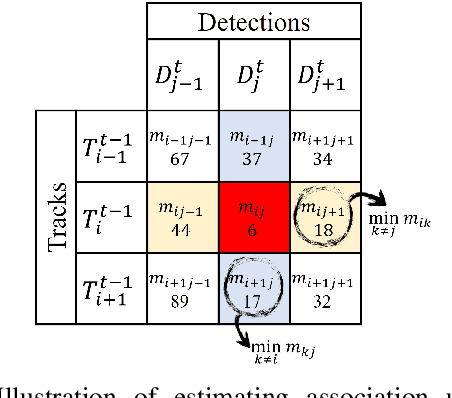
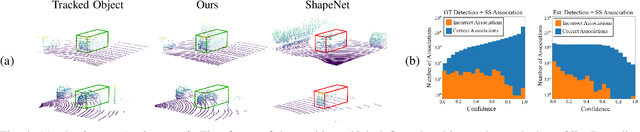
3D object trackers usually require training on large amounts of annotated data that is expensive and time-consuming to collect. Instead, we propose leveraging vast unlabeled datasets by self-supervised metric learning of 3D object trackers, with a focus on data association. Large scale annotations for unlabeled data are cheaply obtained by automatic object detection and association across frames. We show how these self-supervised annotations can be used in a principled manner to learn point-cloud embeddings that are effective for 3D tracking. We estimate and incorporate uncertainty in self-supervised tracking to learn more robust embeddings, without needing any labeled data. We design embeddings to differentiate objects across frames, and learn them using uncertainty-aware self-supervised training. Finally, we demonstrate their ability to perform accurate data association across frames, towards effective and accurate 3D tracking. Project videos and code are at https://jianrenw.github.io/Self-Supervised-3D-Data-Association.
The Annotation Guideline of LST20 Corpus
Aug 12, 2020
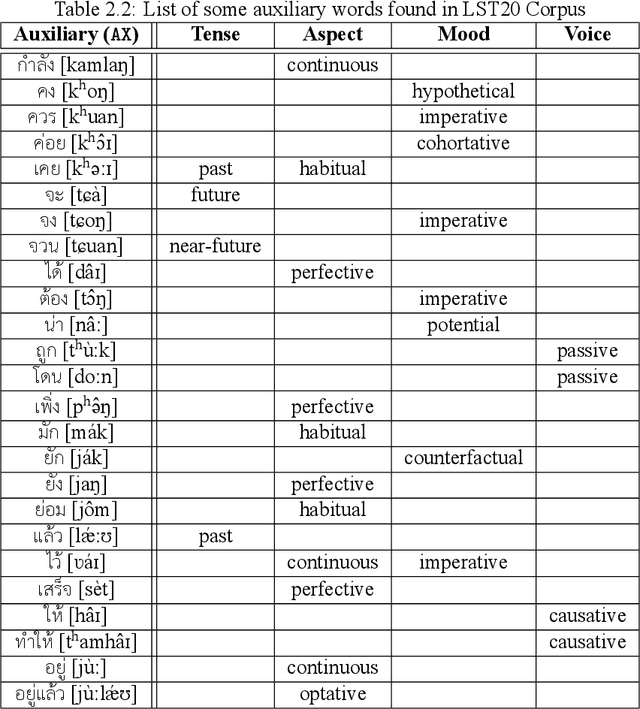
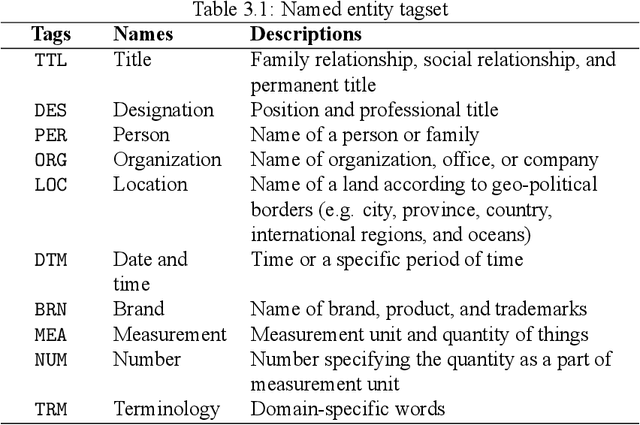

This report presents the annotation guideline for LST20, a large-scale corpus with multiple layers of linguistic annotation for Thai language processing. Our guideline consists of five layers of linguistic annotation: word segmentation, POS tagging, named entities, clause boundaries, and sentence boundaries. The dataset complies to the CoNLL-2003-style format for ease of use. LST20 Corpus offers five layers of linguistic annotation as aforementioned. At a large scale, it consists of 3,164,864 words, 288,020 named entities, 248,962 clauses, and 74,180 sentences, while it is annotated with 16 distinct POS tags. All 3,745 documents are also annotated with 15 news genres. Regarding its sheer size, this dataset is considered large enough for developing joint neural models for NLP. With the existence of this publicly available corpus, Thai has become a linguistically rich language for the first time.
Distributional Generalization: A New Kind of Generalization
Sep 17, 2020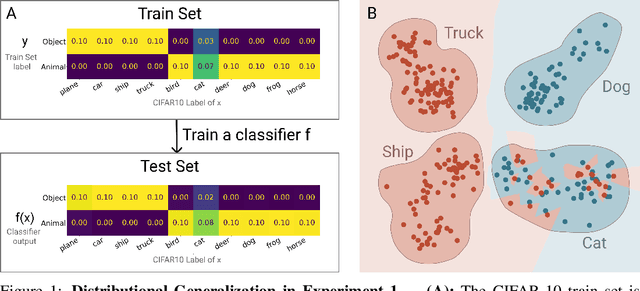

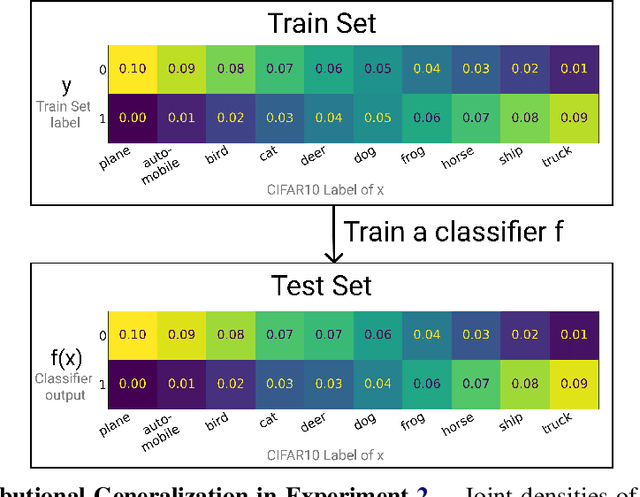

We introduce a new notion of generalization-- Distributional Generalization-- which roughly states that outputs of a classifier at train and test time are close *as distributions*, as opposed to close in just their average error. For example, if we mislabel 30% of dogs as cats in the train set of CIFAR-10, then a ResNet trained to interpolation will in fact mislabel roughly 30% of dogs as cats on the *test set* as well, while leaving other classes unaffected. This behavior is not captured by classical generalization, which would only consider the average error and not the distribution of errors over the input domain. This example is a specific instance of our much more general conjectures which apply even on distributions where the Bayes risk is zero. Our conjectures characterize the form of distributional generalization that can be expected, in terms of problem parameters (model architecture, training procedure, number of samples, data distribution). We verify the quantitative predictions of these conjectures across a variety of domains in machine learning, including neural networks, kernel machines, and decision trees. These empirical observations are independently interesting, and form a more fine-grained characterization of interpolating classifiers beyond just their test error.
Deep Active Graph Representation Learning
Oct 30, 2020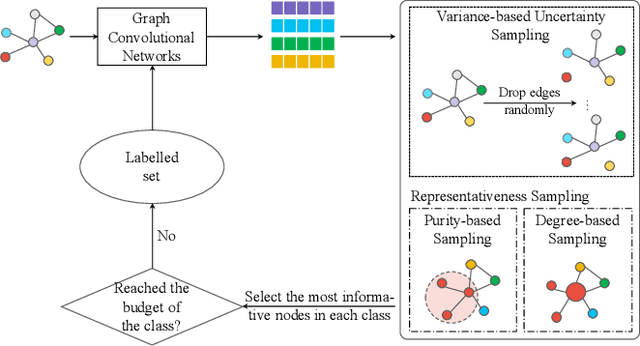
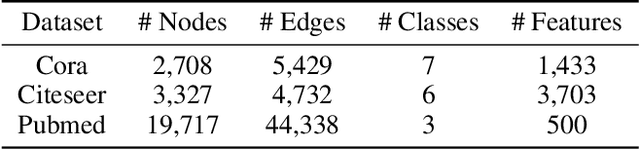
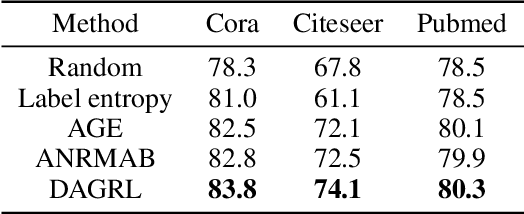
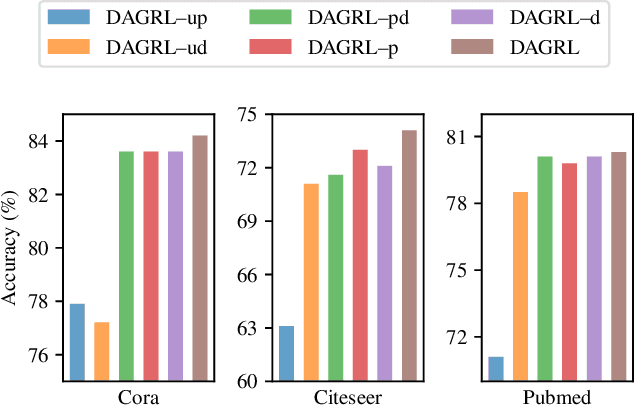
Graph neural networks (GNNs) aim to learn graph representations that preserve both attributive and structural information. In this paper, we study the problem of how to select high-quality nodes for training GNNs, considering GNNs are sensitive to different training datasets. Active learning (AL), whose purpose is to find the most informative instances to maximize the performance of the model, is a promising approach to solve this problem. Previous attempts have combined AL with graph representation learning by designing several selection criteria to measure how informative a node is. However, these methods do not directly utilize both the rich semantic and structural information and are prone to select sparsely-connected nodes (i.e. nodes having few neighbors) and low-purity nodes (i.e. nodes having noisy inter-class edges), which are less effective for training GNN models. To address these problems, we present a Deep Active Graph Representation Learning framework (DAGRL), in which three novel selection criteria are proposed. Specifically, we propose to measure the uncertainty of nodes via random topological perturbation. Besides, we propose two novel representativeness sampling criteria, which utilize both the structural and label information to find densely-connected nodes with many intra-class edges, hence enhance the performance of GNN models significantly. Then, we combine these three criteria with time-sensitive scheduling in accordance to the training progress of GNNs. Furthermore, considering the different size of classes, we employ a novel cluster-aware node selection policy, which ensures the number of selected nodes in each class is proportional to the size of the class. Comprehensive experiments on three public datasets show that our method outperforms previous baselines by a significant margin, which demonstrates its effectiveness.
Structure-Adaptive Sequential Testing for Online False Discovery Rate Control
Feb 28, 2020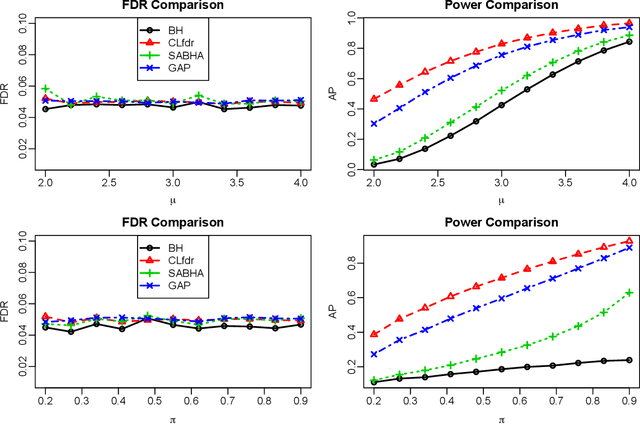
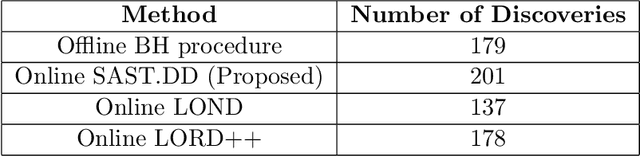
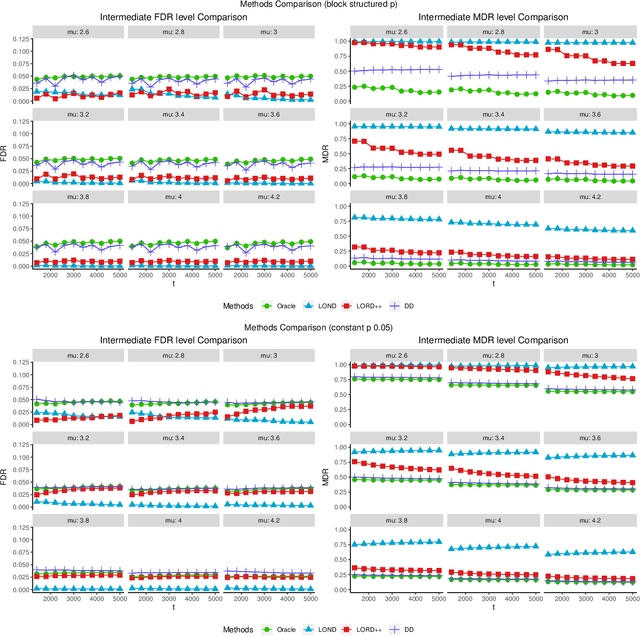
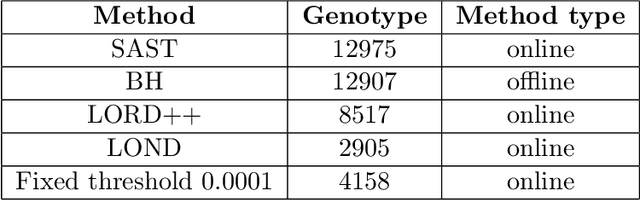
Consider the online testing of a stream of hypotheses where a real--time decision must be made before the next data point arrives. The error rate is required to be controlled at {all} decision points. Conventional \emph{simultaneous testing rules} are no longer applicable due to the more stringent error constraints and absence of future data. Moreover, the online decision--making process may come to a halt when the total error budget, or alpha--wealth, is exhausted. This work develops a new class of structure--adaptive sequential testing (SAST) rules for online false discover rate (FDR) control. A key element in our proposal is a new alpha--investment algorithm that precisely characterizes the gains and losses in sequential decision making. SAST captures time varying structures of the data stream, learns the optimal threshold adaptively in an ongoing manner and optimizes the alpha-wealth allocation across different time periods. We present theory and numerical results to show that the proposed method is valid for online FDR control and achieves substantial power gain over existing online testing rules.