 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Advancing VAD Systems Based on Multi-Task Learning with Improved Model Structures
Dec 19, 2023
In a speech recognition system, voice activity detection (VAD) is a crucial frontend module. Addressing the issues of poor noise robustness in traditional binary VAD systems based on DFSMN, the paper further proposes semantic VAD based on multi-task learning with improved models for real-time and offline systems, to meet specific application requirements. Evaluations on internal datasets show that, compared to the real-time VAD system based on DFSMN, the real-time semantic VAD system based on RWKV achieves relative decreases in CER of 7.0\%, DCF of 26.1\% and relative improvement in NRR of 19.2\%. Similarly, when compared to the offline VAD system based on DFSMN, the offline VAD system based on SAN-M demonstrates relative decreases in CER of 4.4\%, DCF of 18.6\% and relative improvement in NRR of 3.5\%.
Generative AI Beyond LLMs: System Implications of Multi-Modal Generation
Dec 22, 2023As the development of large-scale Generative AI models evolve beyond text (1D) generation to include image (2D) and video (3D) generation, processing spatial and temporal information presents unique challenges to quality, performance, and efficiency. We present the first work towards understanding this new system design space for multi-modal text-to-image (TTI) and text-to-video (TTV) generation models. Current model architecture designs are bifurcated into 2 categories: Diffusion- and Transformer-based models. Our systematic performance characterization on a suite of eight representative TTI/TTV models shows that after state-of-the-art optimization techniques such as Flash Attention are applied, Convolution accounts for up to 44% of execution time for Diffusion-based TTI models, while Linear layers consume up to 49% of execution time for Transformer-based models. We additionally observe that Diffusion-based TTI models resemble the Prefill stage of LLM inference, and benefit from 1.1-2.5x greater speedup from Flash Attention than Transformer-based TTI models that resemble the Decode phase. Since optimizations designed for LLMs do not map directly onto TTI/TTV models, we must conduct a thorough characterization of these workloads to gain insights for new optimization opportunities. In doing so, we define sequence length in the context of TTI/TTV models and observe sequence length can vary up to 4x in Diffusion model inference. We additionally observe temporal aspects of TTV workloads pose unique system bottlenecks, with Temporal Attention accounting for over 60% of total Attention time. Overall, our in-depth system performance characterization is a critical first step towards designing efficient and deployable systems for emerging TTI/TTV workloads.
SRMAC -- Smoothed Recursive Moving Average Crossover for Real-Time Systolic Peak Detection in Photoplethysmography
Dec 15, 2023Purpose. Photoplethysmography (PPG) is a non-invasive technique that measures changes in blood flow volume through optical means. Previous research has established the feasibility of PPG peak detection based on the crossover of moving averages. This paper proposes the Smoothed Recuarsive Moving Average Crossover, which eliminates the need for post-processing and nonlinear pre-processing of previous crossover-based peak detectors. The proposed model is advantageous regarding memory and computational complexity, making it attractive for implementations on embedded devices. Methods. Along with this paper, we make available a novel dataset comprising 66 minutes of PPG recordings. The optimization and assessment of the proposed peak detection model use this dataset. Its optimization is accomplished with the simple random search heuristic, while the leave-subject-out cross-validation method provides the means to assess its performance. The source code for all experiments reported in this research is also available in an online repository. Results. The experimental study examines the performance of the proposed model considering different arrangements of the PPG data. The experiments show that the proposed model performs better than the previous crossover-based approach from the literature regarding the precision and recall metrics. More specifically, our model has an average precision of 0.9937 and an average recall of 0.9968. Conclusion. The contribution of this research to the scientific community and literature is twofold. The dataset we collected is open for any researcher, and we improve upon the leading edge on crossover-based PPG peak detection. This improvement comes in terms of performance metrics and computational cost.
Featurizing Koopman Mode Decomposition
Dec 20, 2023This article introduces an advanced Koopman mode decomposition (KMD) technique -- coined Featurized Koopman Mode Decomposition (FKMD) -- that uses time embedding and Mahalanobis scaling to enhance analysis and prediction of high dimensional dynamical systems. The time embedding expands the observation space to better capture underlying manifold structure, while the Mahalanobis scaling, applied to kernel or random Fourier features, adjusts observations based on the system's dynamics. This aids in featurizing KMD in cases where good features are not a priori known. We show that our method improves KMD predictions for a high dimensional Lorenz attractor and for a cell signaling problem from cancer research.
Space-Time Diffusion Features for Zero-Shot Text-Driven Motion Transfer
Nov 28, 2023We present a new method for text-driven motion transfer - synthesizing a video that complies with an input text prompt describing the target objects and scene while maintaining an input video's motion and scene layout. Prior methods are confined to transferring motion across two subjects within the same or closely related object categories and are applicable for limited domains (e.g., humans). In this work, we consider a significantly more challenging setting in which the target and source objects differ drastically in shape and fine-grained motion characteristics (e.g., translating a jumping dog into a dolphin). To this end, we leverage a pre-trained and fixed text-to-video diffusion model, which provides us with generative and motion priors. The pillar of our method is a new space-time feature loss derived directly from the model. This loss guides the generation process to preserve the overall motion of the input video while complying with the target object in terms of shape and fine-grained motion traits.
Exploiting the capacity of deep networks only at training stage for nonlinear black-box system identification
Dec 27, 2023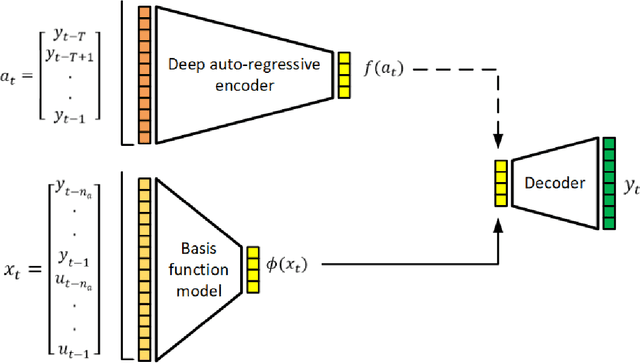
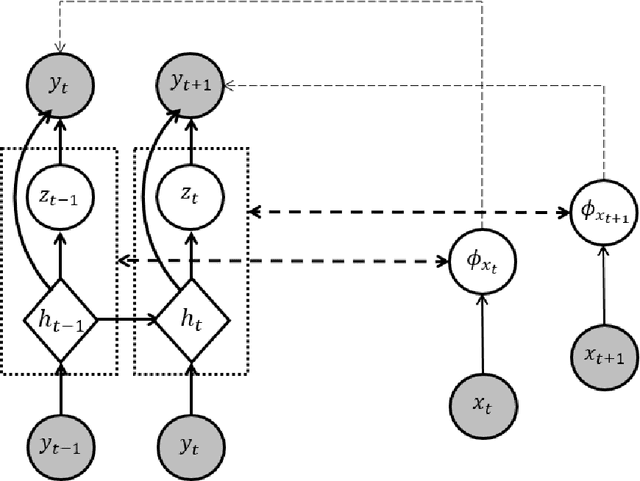
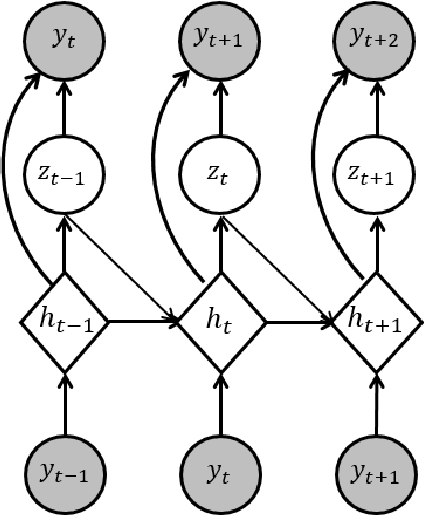
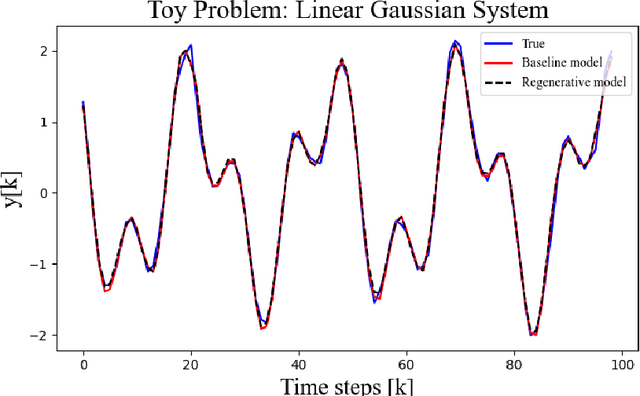
To benefit from the modeling capacity of deep models in system identification, without worrying about inference time, this study presents a novel training strategy that uses deep models only at the training stage. For this purpose two separate models with different structures and goals are employed. The first one is a deep generative model aiming at modeling the distribution of system output(s), called the teacher model, and the second one is a shallow basis function model, named the student model, fed by system input(s) to predict the system output(s). That means these isolated paths must reach the same ultimate target. As deep models show a great performance in modeling of highly nonlinear systems, aligning the representation space learned by these two models make the student model to inherit the approximation power of the teacher model. The proposed objective function consists of the objective of each student and teacher model adding up with a distance penalty between the learned latent representations. The simulation results on three nonlinear benchmarks show a comparative performance with examined deep architectures applied on the same benchmarks. Algorithmic transparency and structure efficiency are also achieved as byproducts.
Evolutionary Swarm Robotics: Dynamic Subgoal-Based Path Formation and Task Allocation for Exploration and Navigation in Unknown Environments
Dec 27, 2023This research paper addresses the challenges of exploration and navigation in unknown environments from an evolutionary swarm robotics perspective. Path formation plays a crucial role in enabling cooperative swarm robots to accomplish these tasks. The paper presents a method called the sub-goal-based path formation, which establishes a path between two different locations by exploiting visually connected sub-goals. Simulation experiments conducted in the Argos simulator demonstrate the successful formation of paths in the majority of trials. Furthermore, the paper tackles the problem of inter-collision (traffic) among a large number of robots engaged in path formation, which negatively impacts the performance of the sub-goal-based method. To mitigate this issue, a task allocation strategy is proposed, leveraging local communication protocols and light signal-based communication. The strategy evaluates the distance between points and determines the required number of robots for the path formation task, reducing unwanted exploration and traffic congestion. The performance of the sub-goal-based path formation and task allocation strategy is evaluated by comparing path length, time, and resource reduction against the A* algorithm. The simulation experiments demonstrate promising results, showcasing the scalability, robustness, and fault tolerance characteristics of the proposed approach.
K-Space Beamforming for an Array of Quantum Sensors
Dec 27, 2023In this paper we present a novel beamforming technique that can be used with an array of quantum sensors. The transmit waveform is a short-duration frequency comb constructed using a finite number of sinusoidal tones separated by a fixed offset. Each element in the array is tuned to one of the tones. When the radiated signal is received by the aperture, each array element accumulates phase at a different rate since it is matched to only one frequency component of the comb waveform. The result is that over the duration of the received pulse, progressively higher spatial frequencies are generated across the aperture. By summing the outputs of all the array elements, a strong peak is created in k-space at the precise time instant when the phases of all the array elements align. The k-space coordinates of the output can then be transformed to angles as discussed in the paper. This paper also describes how to set waveform parameters and the separation between array elements. A desirable advantage of the proposed approach is that the received signal is amplified by the coherent integration gain of the entire spatial aperture.
Hardware-Aware DNN Compression via Diverse Pruning and Mixed-Precision Quantization
Dec 23, 2023Deep Neural Networks (DNNs) have shown significant advantages in a wide variety of domains. However, DNNs are becoming computationally intensive and energy hungry at an exponential pace, while at the same time, there is a vast demand for running sophisticated DNN-based services on resource constrained embedded devices. In this paper, we target energy-efficient inference on embedded DNN accelerators. To that end, we propose an automated framework to compress DNNs in a hardware-aware manner by jointly employing pruning and quantization. We explore, for the first time, per-layer fine- and coarse-grained pruning, in the same DNN architecture, in addition to low bit-width mixed-precision quantization for weights and activations. Reinforcement Learning (RL) is used to explore the associated design space and identify the pruning-quantization configuration so that the energy consumption is minimized whilst the prediction accuracy loss is retained at acceptable levels. Using our novel composite RL agent we are able to extract energy-efficient solutions without requiring retraining and/or fine tuning. Our extensive experimental evaluation over widely used DNNs and the CIFAR-10/100 and ImageNet datasets demonstrates that our framework achieves $39\%$ average energy reduction for $1.7\%$ average accuracy loss and outperforms significantly the state-of-the-art approaches.
SSFlowNet: Semi-supervised Scene Flow Estimation On Point Clouds With Pseudo Label
Dec 23, 2023In the domain of supervised scene flow estimation, the process of manual labeling is both time-intensive and financially demanding. This paper introduces SSFlowNet, a semi-supervised approach for scene flow estimation, that utilizes a blend of labeled and unlabeled data, optimizing the balance between the cost of labeling and the precision of model training. SSFlowNet stands out through its innovative use of pseudo-labels, mainly reducing the dependency on extensively labeled datasets while maintaining high model accuracy. The core of our model is its emphasis on the intricate geometric structures of point clouds, both locally and globally, coupled with a novel spatial memory feature. This feature is adept at learning the geometric relationships between points over sequential time frames. By identifying similarities between labeled and unlabeled points, SSFlowNet dynamically constructs a correlation matrix to evaluate scene flow dependencies at individual point level. Furthermore, the integration of a flow consistency module within SSFlowNet enhances its capability to consistently estimate flow, an essential aspect for analyzing dynamic scenes. Empirical results demonstrate that SSFlowNet surpasses existing methods in pseudo-label generation and shows adaptability across varying data volumes. Moreover, our semi-supervised training technique yields promising outcomes even with different smaller ratio labeled data, marking a substantial advancement in the field of scene flow estimation.