 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Volumetric Ambient Occlusion
Aug 19, 2020

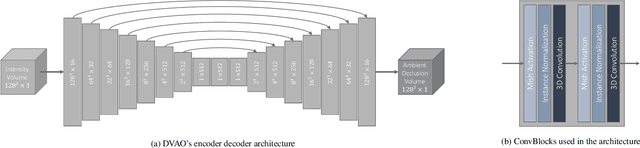
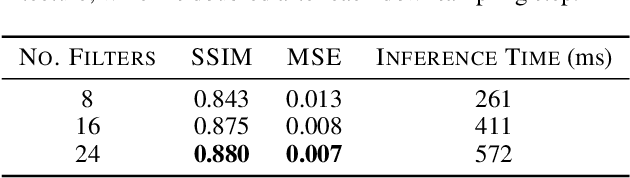

We present a novel deep learning based technique for volumetric ambient occlusion in the context of direct volume rendering. Our proposed Deep Volumetric Ambient Occlusion (DVAO) approach can predict per-voxel ambient occlusion in volumetric data sets, while considering global information provided through the transfer function. The proposed neural network only needs to be executed upon change of this global information, and thus supports real-time volume interaction. Accordingly, we demonstrate DVAOs ability to predict volumetric ambient occlusion, such that it can be applied interactively within direct volume rendering. To achieve the best possible results, we propose and analyze a variety of transfer function representations and injection strategies for deep neural networks. Based on the obtained results we also give recommendations applicable in similar volume learning scenarios. Lastly, we show that DVAO generalizes to a variety of modalities, despite being trained on computed tomography data only.
SLCRF: Subspace Learning with Conditional Random Field for Hyperspectral Image Classification
Oct 07, 2020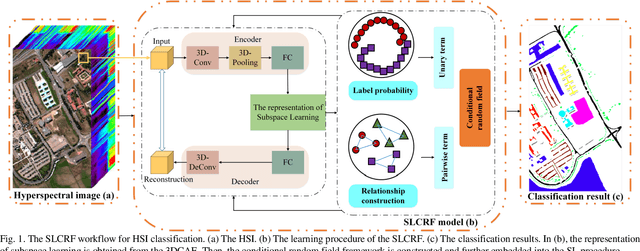

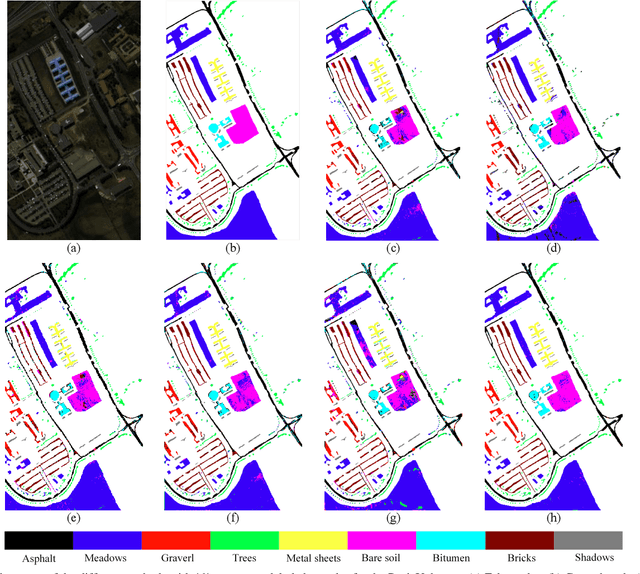
Subspace learning (SL) plays an important role in hyperspectral image (HSI) classification, since it can provide an effective solution to reduce the redundant information in the image pixels of HSIs. Previous works about SL aim to improve the accuracy of HSI recognition. Using a large number of labeled samples, related methods can train the parameters of the proposed solutions to obtain better representations of HSI pixels. However, the data instances may not be sufficient enough to learn a precise model for HSI classification in real applications. Moreover, it is well-known that it takes much time, labor and human expertise to label HSI images. To avoid the aforementioned problems, a novel SL method that includes the probability assumption called subspace learning with conditional random field (SLCRF) is developed. In SLCRF, first, the 3D convolutional autoencoder (3DCAE) is introduced to remove the redundant information in HSI pixels. In addition, the relationships are also constructed using the spectral-spatial information among the adjacent pixels. Then, the conditional random field (CRF) framework can be constructed and further embedded into the HSI SL procedure with the semi-supervised approach. Through the linearized alternating direction method termed LADMAP, the objective function of SLCRF is optimized using a defined iterative algorithm. The proposed method is comprehensively evaluated using the challenging public HSI datasets. We can achieve stateof-the-art performance using these HSI sets.
Unsupervised seismic facies classification using deep convolutional autoencoder
Aug 05, 2020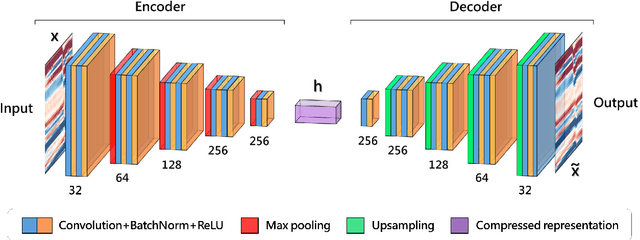
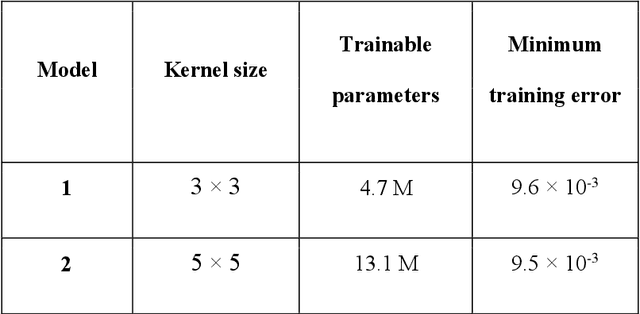

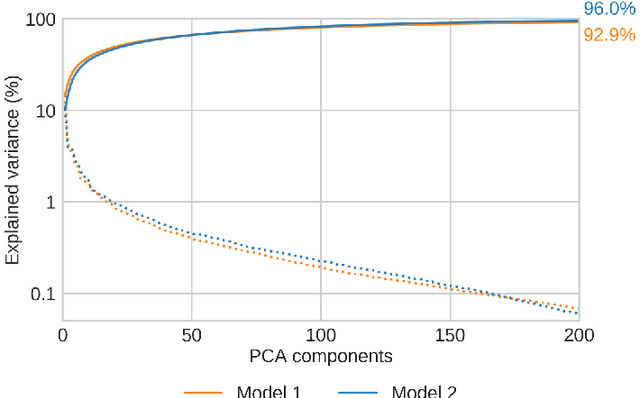
With the increased size and complexity of seismic surveys, manual labeling of seismic facies has become a significant challenge. Application of automatic methods for seismic facies interpretation could significantly reduce the manual labor and subjectivity of a particular interpreter present in conventional methods. A recently emerged group of methods is based on deep neural networks. These approaches are data-driven and require large labeled datasets for network training. We apply a deep convolutional autoencoder for unsupervised seismic facies classification, which does not require manually labeled examples. The facies maps are generated by clustering the deep-feature vectors obtained from the input data. Our method yields accurate results on real data and provides them instantaneously. The proposed approach opens up possibilities to analyze geological patterns in real time without human intervention.
Real-time Model-based Image Color Correction for Underwater Robots
Apr 12, 2019
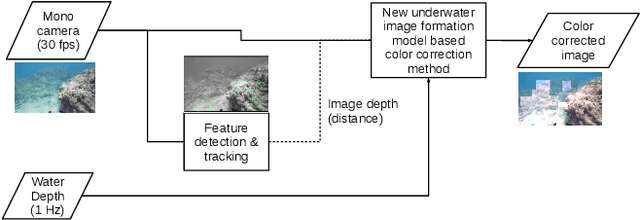
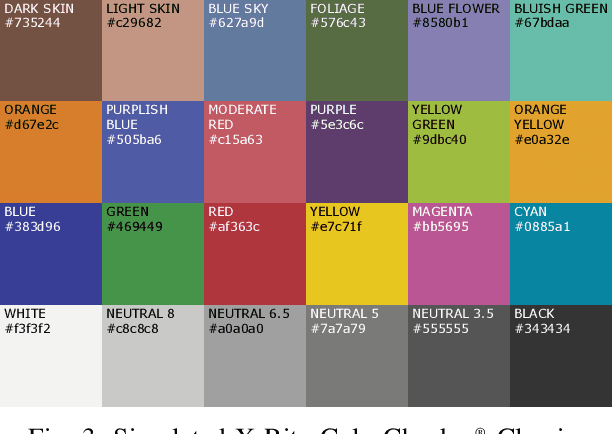

Recently, a new underwater imaging formation model presented that the coefficients related to the direct and backscatter transmission signals are dependent on the type of water, camera specifications, water depth, and imaging range. This paper proposes an underwater color correction method that integrates this new model on an underwater robot, using information from a pressure depth sensor for water depth and a visual odometry system for estimating scene distance. Experiments were performed with and without a color chart over coral reefs and a shipwreck in the Caribbean. We demonstrate the performance of our proposed method by comparing it with other statistic-, physic-, and learning-based color correction methods. Applications for our proposed method include improved 3D reconstruction and more robust underwater robot navigation.
Lightweight 3D Human Pose Estimation Network Training Using Teacher-Student Learning
Jan 15, 2020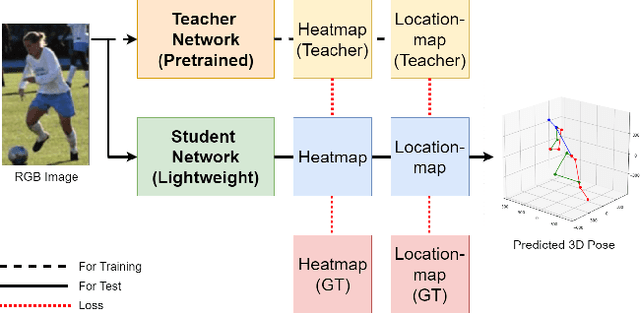
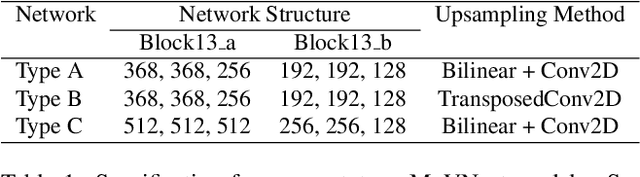
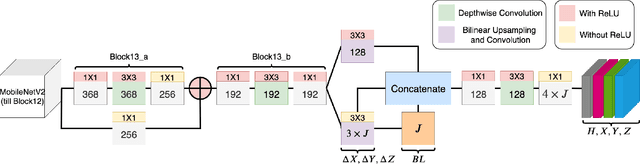
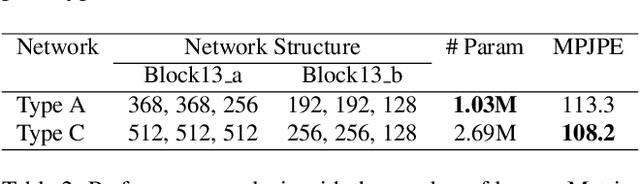
We present MoVNect, a lightweight deep neural network to capture 3D human pose using a single RGB camera. To improve the overall performance of the model, we apply the teacher-student learning method based knowledge distillation to 3D human pose estimation. Real-time post-processing makes the CNN output yield temporally stable 3D skeletal information, which can be used in applications directly. We implement a 3D avatar application running on mobile in real-time to demonstrate that our network achieves both high accuracy and fast inference time. Extensive evaluations show the advantages of our lightweight model with the proposed training method over previous 3D pose estimation methods on the Human3.6M dataset and mobile devices.
Detecting total hip replacement prosthesis design on preoperative radiographs using deep convolutional neural network
Nov 27, 2019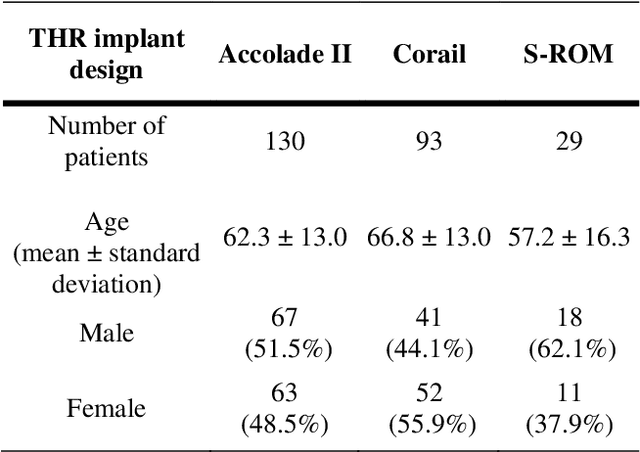
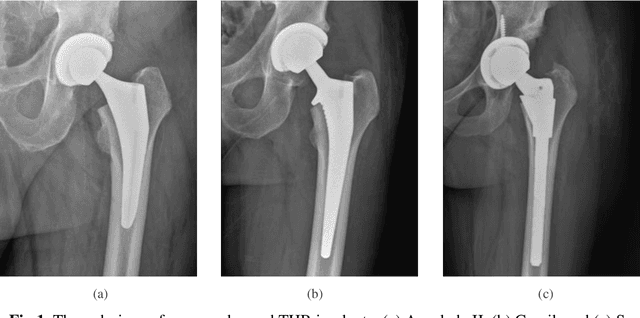
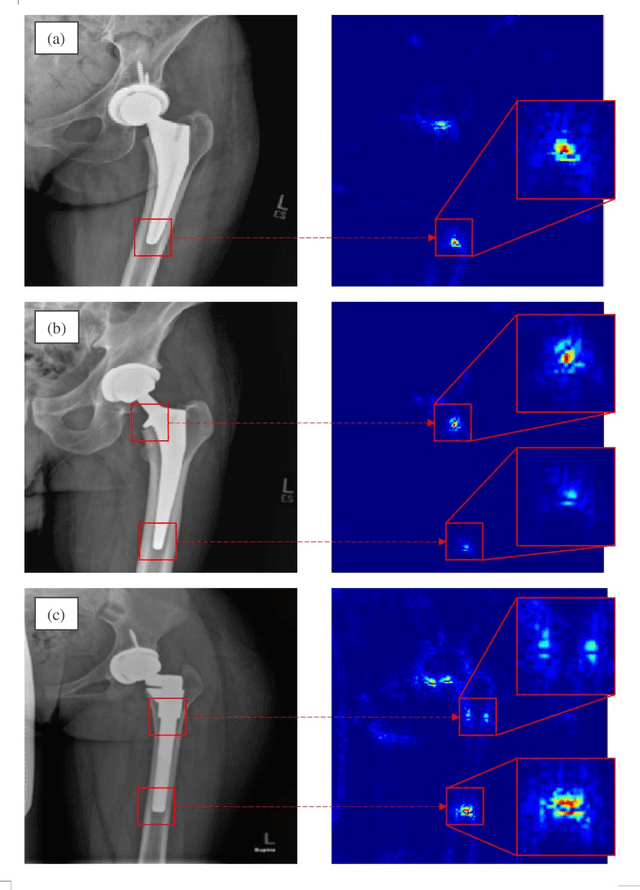
Identifying the design of a failed implant is a key step in preoperative planning of revision total joint arthroplasty. Manual identification of the implant design from radiographic images is time consuming and prone to error. Failure to identify the implant design preoperatively can lead to increased operating room time, more complex surgery, increased blood loss, increased bone loss, increased recovery time, and overall increased healthcare costs. In this study, we present a novel, fully automatic and interpretable approach to identify the design of total hip replacement (THR) implants from plain radiographs using deep convolutional neural network (CNN). CNN achieved 100% accuracy in identification of three commonly used THR implant designs. Such CNN can be used to automatically identify the design of a failed THR implant preoperatively in just a few seconds, saving time and improving the identification accuracy. This can potentially improve patient outcomes, free practitioners time, and reduce healthcare costs.
Feature Engineering for Data-driven Traffic State Forecast in Urban Road Networks
Sep 17, 2020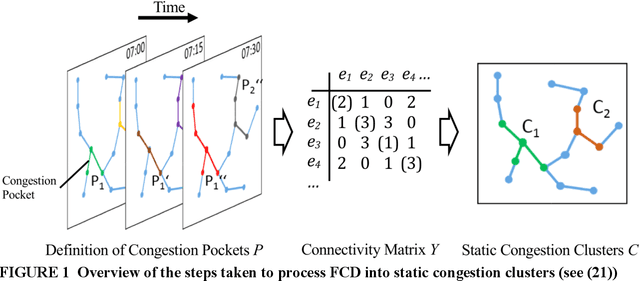
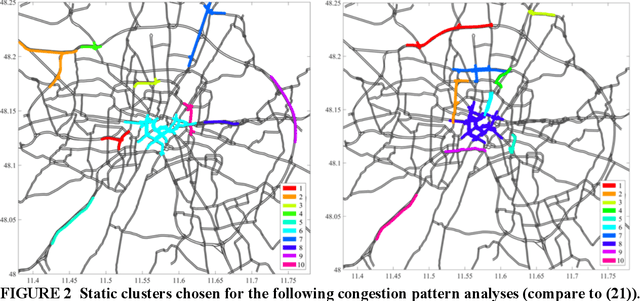
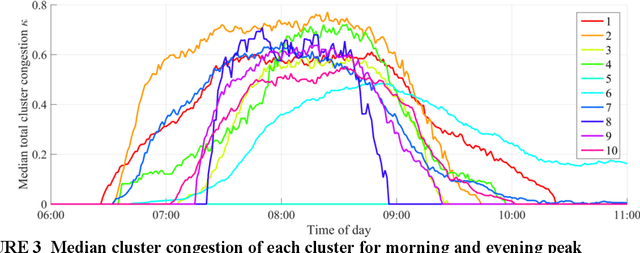
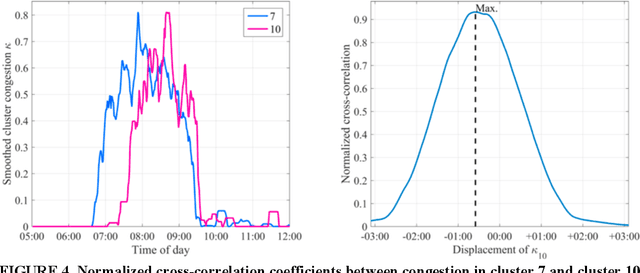
Most traffic state forecast algorithms when applied to urban road networks consider only the links in close proximity to the target location. However, for longer-term forecasts also the traffic state of more distant links or regions of the network are expected to provide valuable information for a data-driven algorithm. This paper studies these expectations of using a network clustering algorithm and one year of Floating Car (FCD) collected by a large fleet of vehicles. First, a clustering algorithm is applied to the data in order to extract congestion-prone regions in the Munich city network. The level of congestion inside these clusters is analyzed with the help of statistical tools. Clear spatio-temporal congestion patterns and correlations between the clustered regions are identified. These correlations are integrated into a K- Nearest Neighbors (KNN) travel time prediction algorithm. In a comparison with other approaches, this method achieves the best results. The statistical results and the performance of the KNN predictor indicate that the consideration of the network-wide traffic is a valuable feature for predictors and a promising way to develop more accurate algorithms in the future.
Learning to Optimise General TSP Instances
Oct 23, 2020
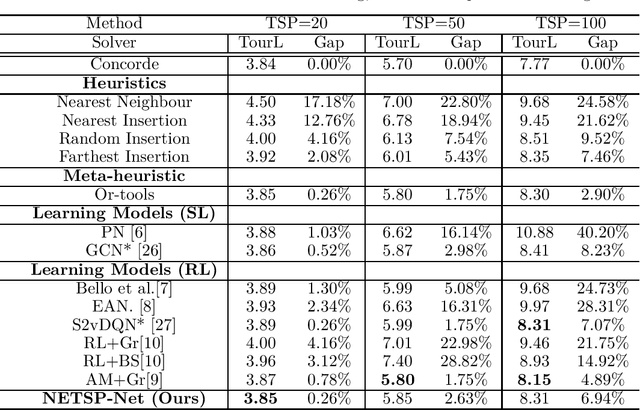
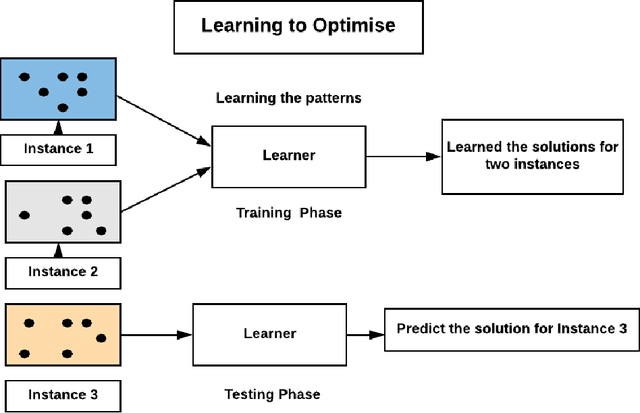
The Travelling Salesman Problem (TSP) is a classical combinatorial optimisation problem. Deep learning has been successfully extended to meta-learning, where previous solving efforts assist in learning how to optimise future optimisation instances. In recent years, learning to optimise approaches have shown success in solving TSP problems. However, they focus on one type of TSP problem, namely ones where the points are uniformly distributed in Euclidean spaces and have issues in generalising to other embedding spaces, e.g., spherical distance spaces, and to TSP instances where the points are distributed in a non-uniform manner. An aim of learning to optimise is to train once and solve across a broad spectrum of (TSP) problems. Although supervised learning approaches have shown to achieve more optimal solutions than unsupervised approaches, they do require the generation of training data and running a solver to obtain solutions to learn from, which can be time-consuming and difficult to find reasonable solutions for harder TSP instances. Hence this paper introduces a new learning-based approach to solve a variety of different and common TSP problems that are trained on easier instances which are faster to train and are easier to obtain better solutions. We name this approach the non-Euclidean TSP network (NETSP-Net). The approach is evaluated on various TSP instances using the benchmark TSPLIB dataset and popular instance generator used in the literature. We performed extensive experiments that indicate our approach generalises across many types of instances and scales to instances that are larger than what was used during training.
Matched Queues with Matching Batch Pair (m, n)
Sep 06, 2020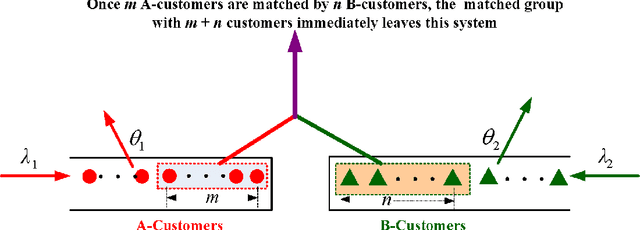
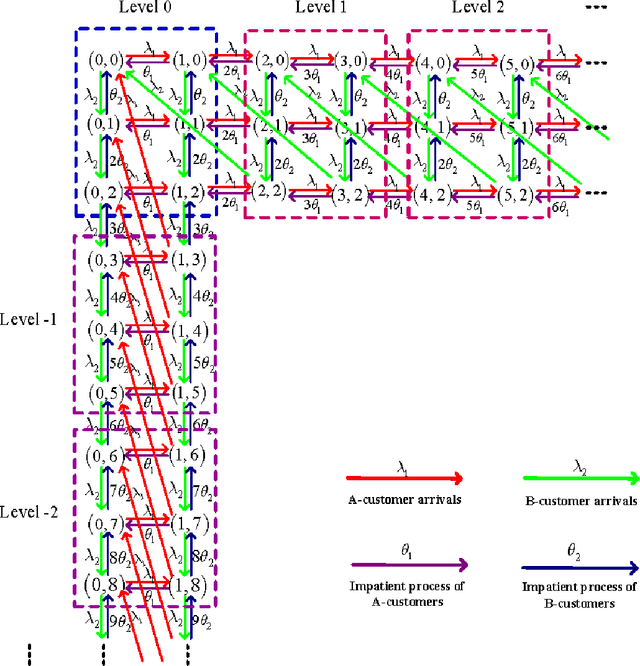
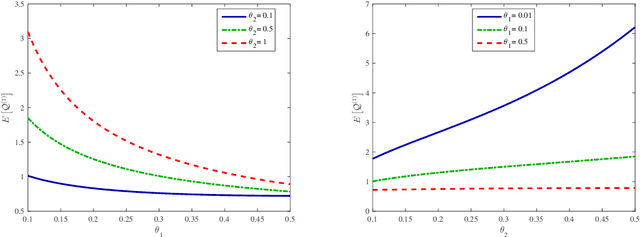
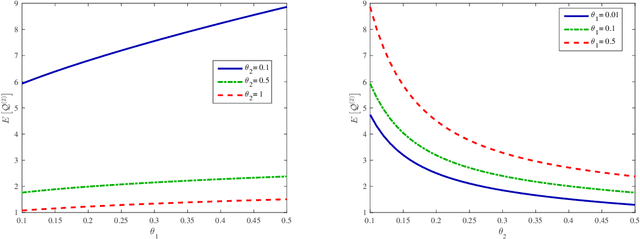
In this paper, we discuss an interesting but challenging bilateral stochastically matching problem: A more general matched queue with matching batch pair (m, n) and two types (i.e., types A and B) of impatient customers, where the arrivals of A- and B-customers are both Poisson processes, m A-customers and n B-customers are matched as a group which leaves the system immediately, and the customers' impatient behavior is to guarantee the stability of the system. We show that this matched queue can be expressed as a novel bidirectional level-dependent quasi-birth-and-death (QBD) process. Based on this, we provide a detailed analysis for this matched queue, including the system stability, the average stationary queue lengthes, and the average sojourn time of any A-customer or B-customer. We believe that the methodology and results developed in this paper can be applicable to dealing with more general matched queueing systems, which are widely encountered in various practical areas, for example, sharing economy, ridesharing platform, bilateral market, organ transplantation, taxi services, assembly systems, and so on.
Back to Event Basics: Self-Supervised Learning of Image Reconstruction for Event Cameras via Photometric Constancy
Sep 17, 2020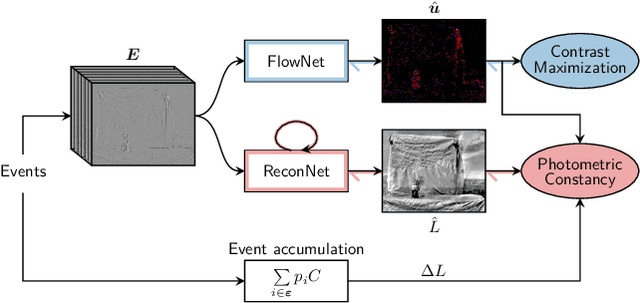

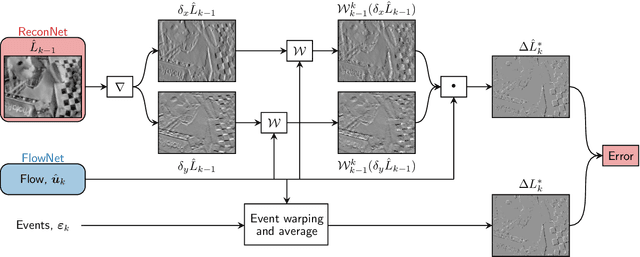
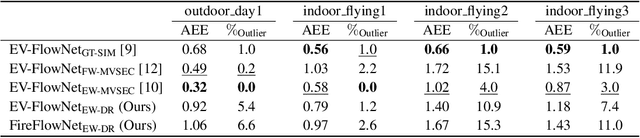
Event cameras are novel vision sensors that sample, in an asynchronous fashion, brightness increments with low latency and high temporal resolution. The resulting streams of events are of high value by themselves, especially for high speed motion estimation. However, a growing body of work has also focused on the reconstruction of intensity frames from the events, as this allows bridging the gap with the existing literature on appearance- and frame-based computer vision. Recent work has mostly approached this intensity reconstruction problem using neural networks trained with synthetic, ground-truth data. Nevertheless, since accurate ground truth is only available in simulation, these methods are subject to the reality gap and, to ensure generalizability, their training datasets need to be carefully designed. In this work, we approach, for the first time, the reconstruction problem from a self-supervised learning perspective. Our framework combines estimated optical flow and the event-based photometric constancy to train neural networks without the need for any ground-truth or synthetic data. Results across multiple datasets show that the performance of the proposed approach is in line with the state-of-the-art.