 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Generating Handwriting via Decouple Style Descriptors
Aug 26, 2020
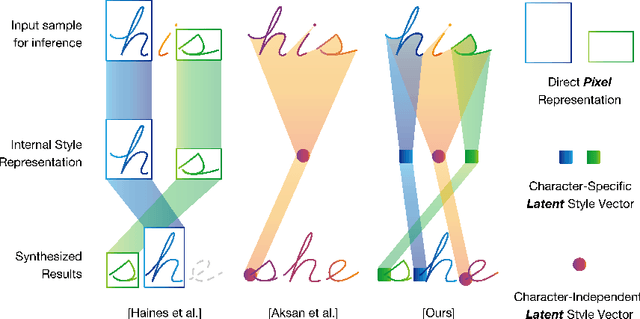

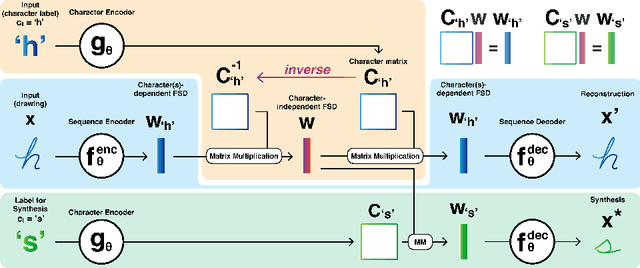

Representing a space of handwriting stroke styles includes the challenge of representing both the style of each character and the overall style of the human writer. Existing VRNN approaches to representing handwriting often do not distinguish between these different style components, which can reduce model capability. Instead, we introduce the Decoupled Style Descriptor (DSD) model for handwriting, which factors both character- and writer-level styles and allows our model to represent an overall greater space of styles. This approach also increases flexibility: given a few examples, we can generate handwriting in new writer styles, and also now generate handwriting of new characters across writer styles. In experiments, our generated results were preferred over a state of the art baseline method 88% of the time, and in a writer identification task on 20 held-out writers, our DSDs achieved 89.38% accuracy from a single sample word. Overall, DSDs allows us to improve both the quality and flexibility over existing handwriting stroke generation approaches.
A Comparison of Few-Shot Learning Methods for Underwater Optical and Sonar Image Classification
May 10, 2020
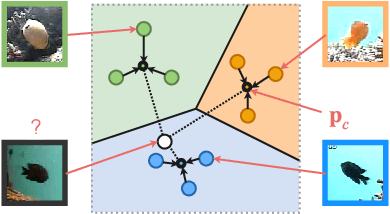
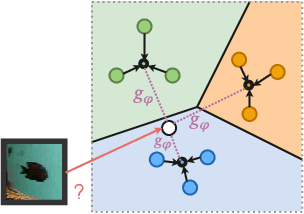
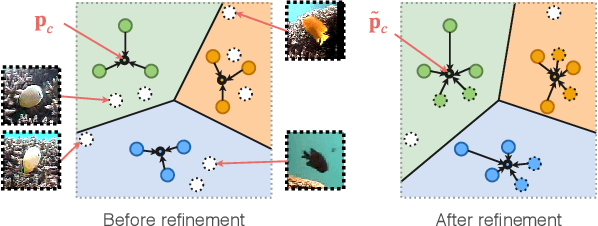
Deep convolutional neural networks have shown to perform well in underwater object recognition tasks, on both optical and sonar images. However, many such methods require hundreds, if not thousands, of images per class to generalize well to unseen examples. This is restricting in situations where obtaining and labeling larger volumes of data is impractical, such as observing a rare object, performing real-time operations, or operating in new underwater environments. Finding an algorithm capable of learning from only a few samples could reduce the time spent obtaining and labeling datasets, and accelerate the training of deep-learning models. To the best of our knowledge, this is the first paper to evaluate and compare several Few-Shot Learning (FSL) methods using underwater optical and side-scan sonar imagery. Our results show that FSL methods offer a significant advantage over the traditional transfer learning methods that employ fine-tuning of pre-trained models. Our findings show that FSL methods are not too far from being used on real-world robotics scenarios and expanding the capabilities of autonomous underwater systems.
Learning an Adaptive Model for Extreme Low-light Raw Image Processing
Apr 22, 2020
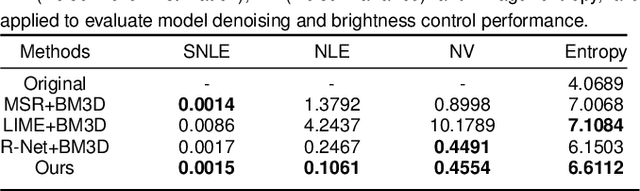
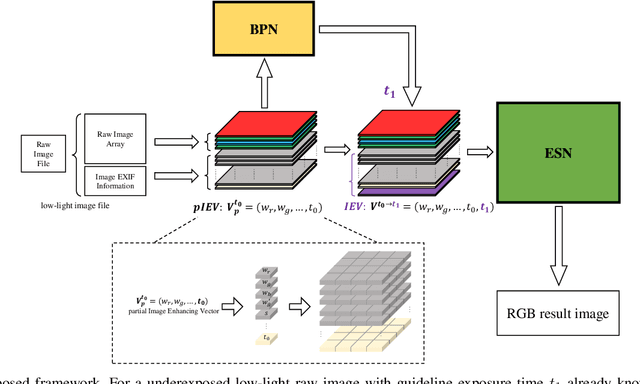
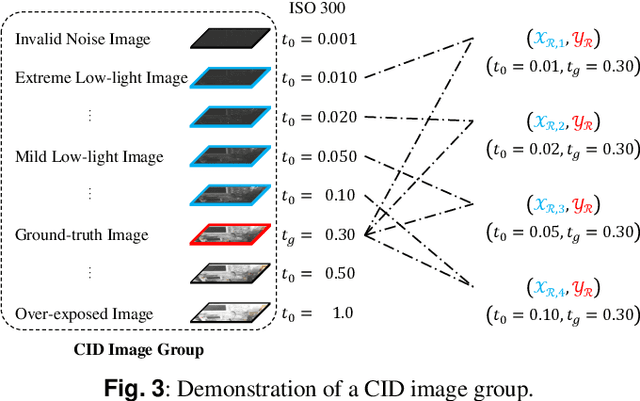
Low-light images suffer from severe noise and low illumination. Current deep learning models that are trained with real-world images have excellent noise reduction, but a ratio parameter must be chosen manually to complete the enhancement pipeline. In this work, we propose an adaptive low-light raw image enhancement network to avoid parameter-handcrafting and to improve image quality. The proposed method can be divided into two sub-models: Brightness Prediction (BP) and Exposure Shifting (ES). The former is designed to control the brightness of the resulting image by estimating a guideline exposure time $t_1$. The latter learns to approximate an exposure-shifting operator $ES$, converting a low-light image with real exposure time $t_0$ to a noise-free image with guideline exposure time $t_1$. Additionally, structural similarity (SSIM) loss and Image Enhancement Vector (IEV) are introduced to promote image quality, and a new Campus Image Dataset (CID) is proposed to overcome the limitations of the existing datasets and to supervise the training of the proposed model. Using the proposed model, we can achieve high-quality low-light image enhancement from a single raw image. In quantitative tests, it is shown that the proposed method has the lowest Noise Level Estimation (NLE) score compared with the state-of-the-art low-light algorithms, suggesting a superior denoising performance. Furthermore, those tests illustrate that the proposed method is able to adaptively control the global image brightness according to the content of the image scene. Lastly, the potential application in video processing is briefly discussed.
Neuromorphic Nearest-Neighbor Search Using Intel's Pohoiki Springs
Apr 27, 2020



Neuromorphic computing applies insights from neuroscience to uncover innovations in computing technology. In the brain, billions of interconnected neurons perform rapid computations at extremely low energy levels by leveraging properties that are foreign to conventional computing systems, such as temporal spiking codes and finely parallelized processing units integrating both memory and computation. Here, we showcase the Pohoiki Springs neuromorphic system, a mesh of 768 interconnected Loihi chips that collectively implement 100 million spiking neurons in silicon. We demonstrate a scalable approximate k-nearest neighbor (k-NN) algorithm for searching large databases that exploits neuromorphic principles. Compared to state-of-the-art conventional CPU-based implementations, we achieve superior latency, index build time, and energy efficiency when evaluated on several standard datasets containing over 1 million high-dimensional patterns. Further, the system supports adding new data points to the indexed database online in O(1) time unlike all but brute force conventional k-NN implementations.
Reinforcement Learning with Quantum Variational Circuits
Aug 25, 2020
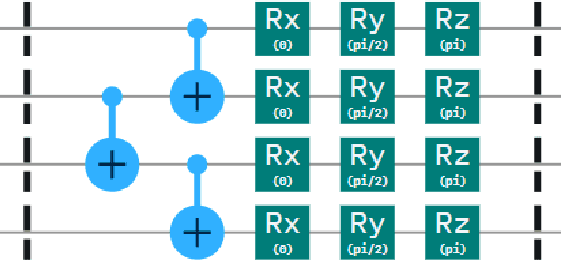

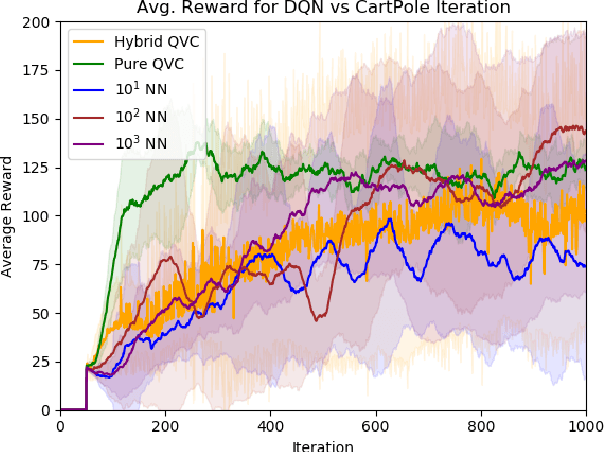
The development of quantum computational techniques has advanced greatly in recent years, parallel to the advancements in techniques for deep reinforcement learning. This work explores the potential for quantum computing to facilitate reinforcement learning problems. Quantum computing approaches offer important potential improvements in time and space complexity over traditional algorithms because of its ability to exploit the quantum phenomena of superposition and entanglement. Specifically, we investigate the use of quantum variational circuits, a form of quantum machine learning. We present our techniques for encoding classical data for a quantum variational circuit, we further explore pure and hybrid quantum algorithms for DQN and Double DQN. Our results indicate both hybrid and pure quantum variational circuit have the ability to solve reinforcement learning tasks with a smaller parameter space. These comparison are conducted with two OpenAI Gym environments: CartPole and Blackjack, The success of this work is indicative of a strong future relationship between quantum machine learning and deep reinforcement learning.
Robust Uncertainty-Aware Multiview Triangulation
Aug 05, 2020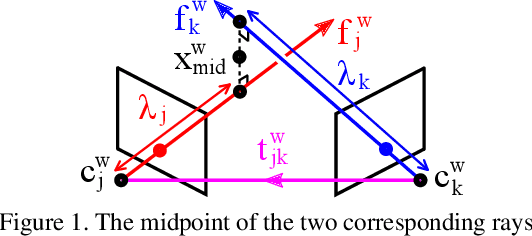

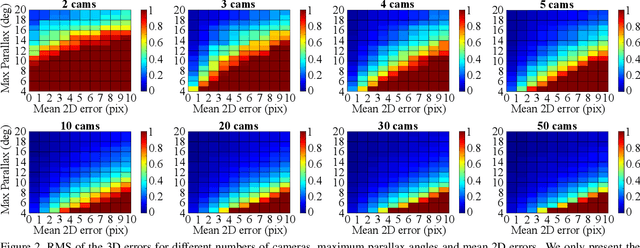
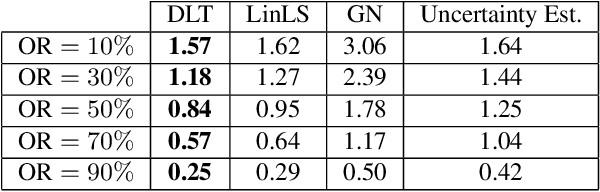
We propose a robust and efficient method for multiview triangulation and uncertainty estimation. Our contribution is threefold: First, we propose an outlier rejection scheme using two-view RANSAC with the midpoint method. By prescreening the two-view samples prior to triangulation, we achieve the state-of-the-art efficiency. Second, we compare different local optimization methods for refining the initial solution and the inlier set. With an iterative update of the inlier set, we show that the optimization provides significant improvement in accuracy and robustness. Third, we model the uncertainty of a triangulated point as a function of three factors: the number of cameras, the mean reprojection error and the maximum parallax angle. Learning this model allows us to quickly interpolate the uncertainty at test time. We validate our method through an extensive evaluation.
Chest X-ray Image Phase Features for Improved Diagnosis of COVID-19 Using Convolutional Neural Network
Nov 06, 2020
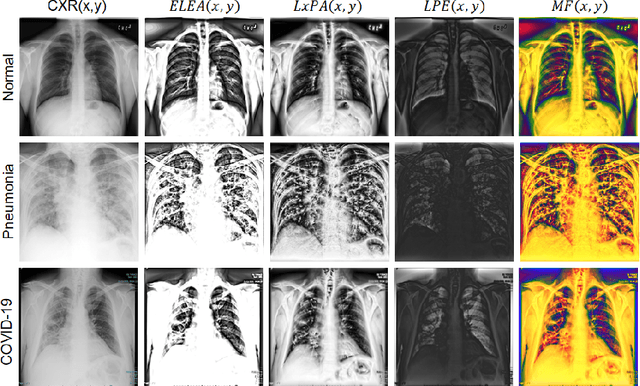

Recently, the outbreak of the novel Coronavirus disease 2019 (COVID-19) pandemic has seriously endangered human health and life. Due to limited availability of test kits, the need for auxiliary diagnostic approach has increased. Recent research has shown radiography of COVID-19 patient, such as CT and X-ray, contains salient information about the COVID-19 virus and could be used as an alternative diagnosis method. Chest X-ray (CXR) due to its faster imaging time, wide availability, low cost and portability gains much attention and becomes very promising. Computational methods with high accuracy and robustness are required for rapid triaging of patients and aiding radiologist in the interpretation of the collected data. In this study, we design a novel multi-feature convolutional neural network (CNN) architecture for multi-class improved classification of COVID-19 from CXR images. CXR images are enhanced using a local phase-based image enhancement method. The enhanced images, together with the original CXR data, are used as an input to our proposed CNN architecture. Using ablation studies, we show the effectiveness of the enhanced images in improving the diagnostic accuracy. We provide quantitative evaluation on two datasets and qualitative results for visual inspection. Quantitative evaluation is performed on data consisting of 8,851 normal (healthy), 6,045 pneumonia, and 3,323 Covid-19 CXR scans. In Dataset-1, our model achieves 95.57\% average accuracy for a three classes classification, 99\% precision, recall, and F1-scores for COVID-19 cases. For Dataset-2, we have obtained 94.44\% average accuracy, and 95\% precision, recall, and F1-scores for detection of COVID-19. Conclusions: Our proposed multi-feature guided CNN achieves improved results compared to single-feature CNN proving the importance of the local phase-based CXR image enhancement.
M3Lung-Sys: A Deep Learning System for Multi-Class Lung Pneumonia Screening from CT Imaging
Oct 07, 2020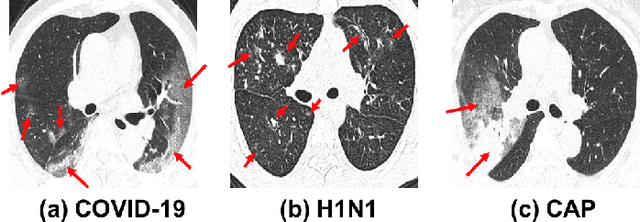
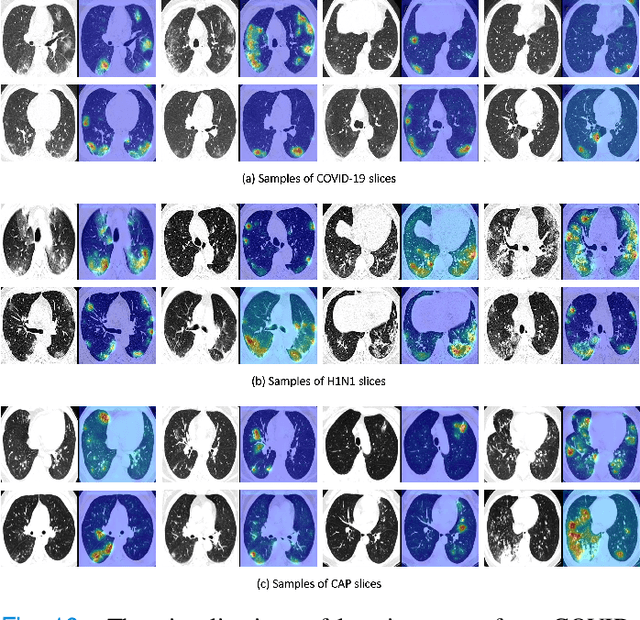
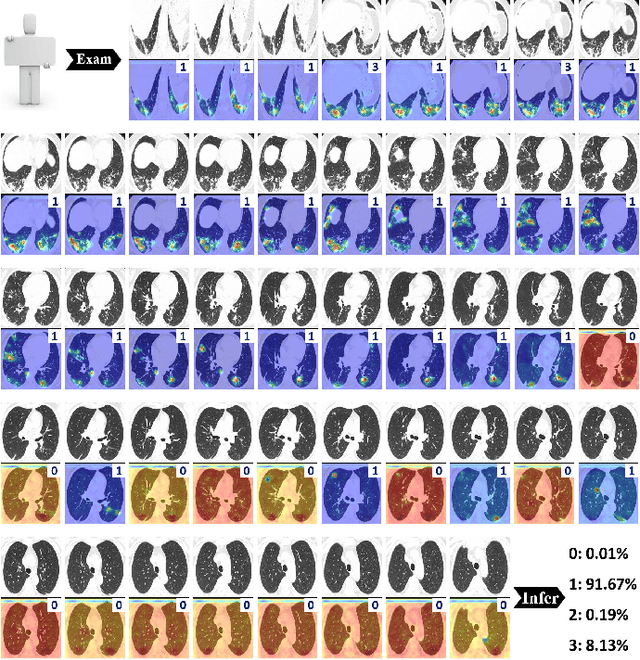
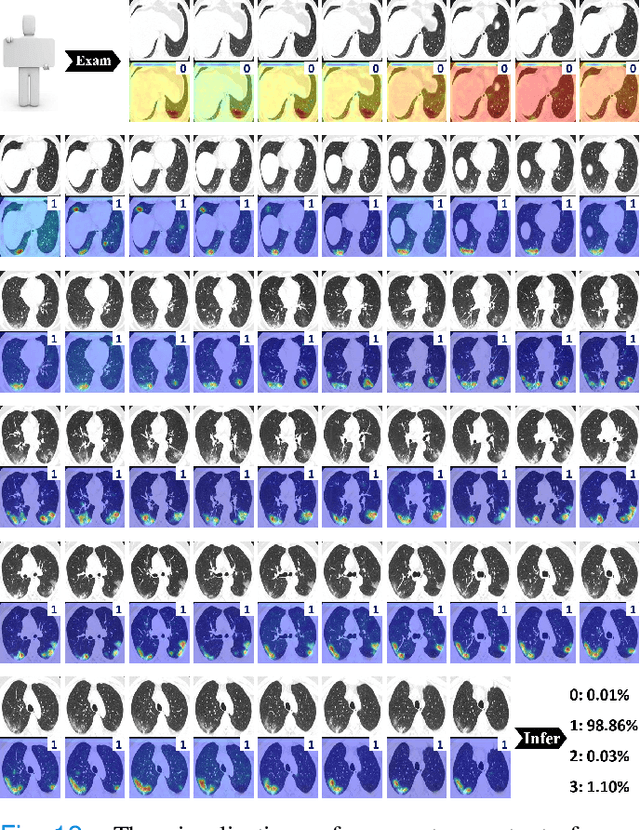
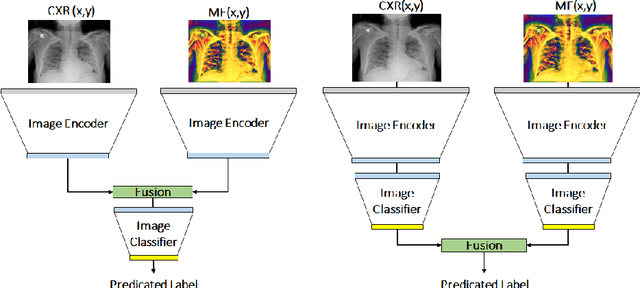
To counter the outbreak of COVID-19, the accurate diagnosis of suspected cases plays a crucial role in timely quarantine, medical treatment, and preventing the spread of the pandemic. Considering the limited training cases and resources (e.g, time and budget), we propose a Multi-task Multi-slice Deep Learning System (M3Lung-Sys) for multi-class lung pneumonia screening from CT imaging, which only consists of two 2D CNN networks, i.e., slice- and patient-level classification networks. The former aims to seek the feature representations from abundant CT slices instead of limited CT volumes, and for the overall pneumonia screening, the latter one could recover the temporal information by feature refinement and aggregation between different slices. In addition to distinguish COVID-19 from Healthy, H1N1, and CAP cases, our M 3 Lung-Sys also be able to locate the areas of relevant lesions, without any pixel-level annotation. To further demonstrate the effectiveness of our model, we conduct extensive experiments on a chest CT imaging dataset with a total of 734 patients (251 healthy people, 245 COVID-19 patients, 105 H1N1 patients, and 133 CAP patients). The quantitative results with plenty of metrics indicate the superiority of our proposed model on both slice- and patient-level classification tasks. More importantly, the generated lesion location maps make our system interpretable and more valuable to clinicians.
InstanceFlow: Visualizing the Evolution of Classifier Confusion on the Instance Level
Aug 25, 2020
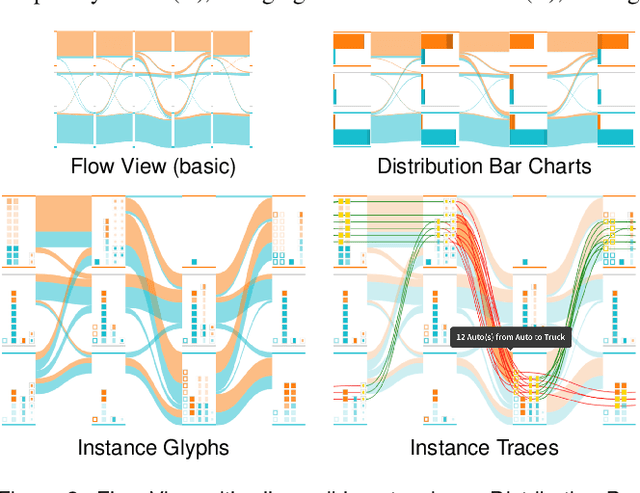
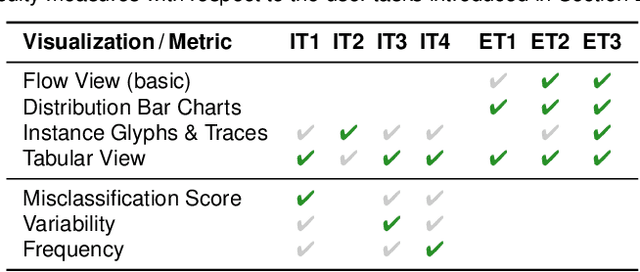
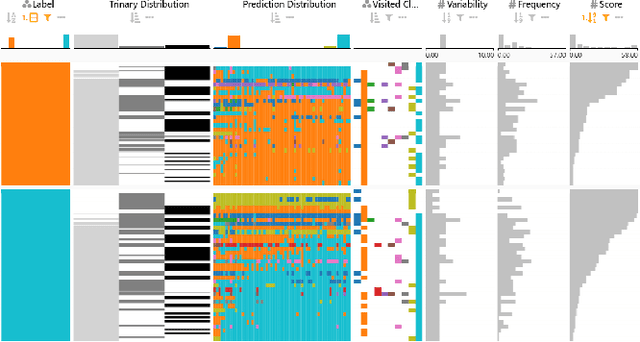
Classification is one of the most important supervised machine learning tasks. During the training of a classification model, the training instances are fed to the model multiple times (during multiple epochs) in order to iteratively increase the classification performance. The increasing complexity of models has led to a growing demand for model interpretability through visualizations. Existing approaches mostly focus on the visual analysis of the final model performance after training and are often limited to aggregate performance measures. In this paper we introduce InstanceFlow, a novel dual-view visualization tool that allows users to analyze the learning behavior of classifiers over time on the instance-level. A Sankey diagram visualizes the flow of instances throughout epochs, with on-demand detailed glyphs and traces for individual instances. A tabular view allows users to locate interesting instances by ranking and filtering. In this way, InstanceFlow bridges the gap between class-level and instance-level performance evaluation while enabling users to perform a full temporal analysis of the training process.
Time Series Deinterleaving of DNS Traffic
Jul 16, 2018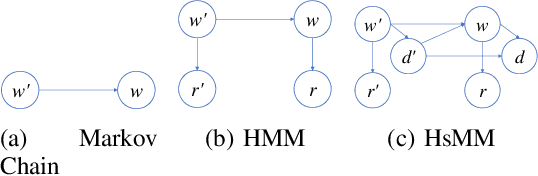
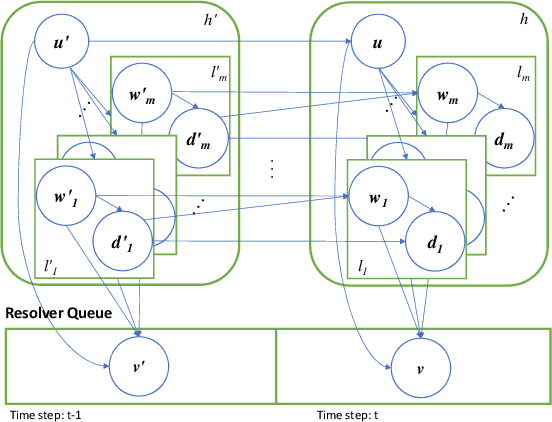
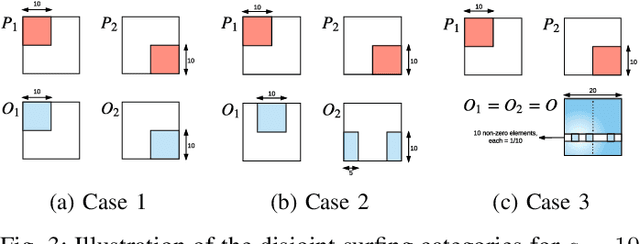

Stream deinterleaving is an important problem with various applications in the cybersecurity domain. In this paper, we consider the specific problem of deinterleaving DNS data streams using machine-learning techniques, with the objective of automating the extraction of malware domain sequences. We first develop a generative model for user request generation and DNS stream interleaving. Based on these we evaluate various inference strategies for deinterleaving including augmented HMMs and LSTMs on synthetic datasets. Our results demonstrate that state-of-the-art LSTMs outperform more traditional augmented HMMs in this application domain.