 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A General Framework for Charger Scheduling Optimization Problems
Sep 28, 2020
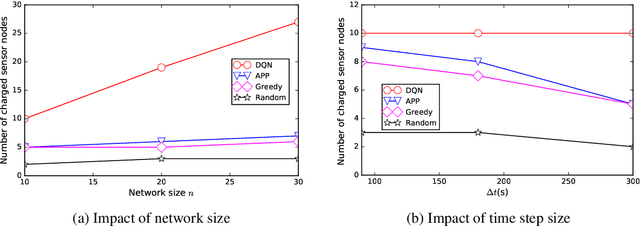
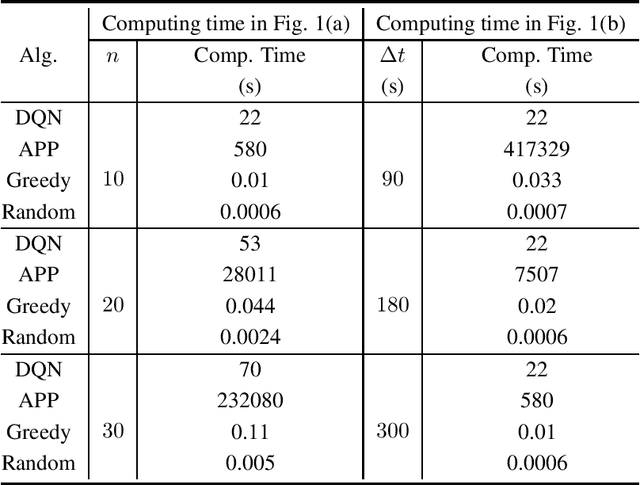
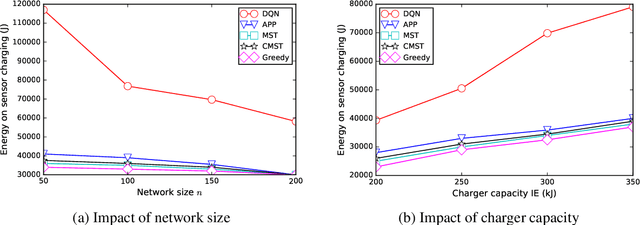
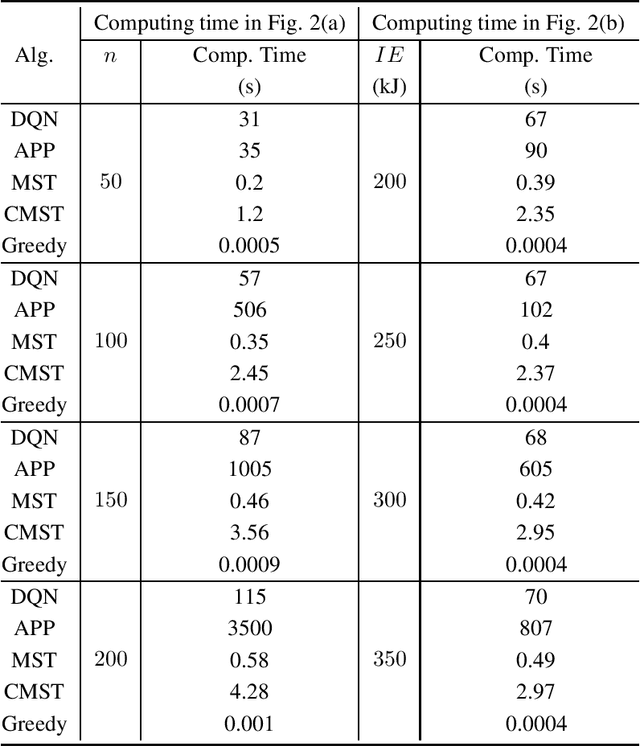
This paper presents a general framework to tackle a diverse range of NP-hard charger scheduling problems, optimizing the trajectory of mobile chargers to prolong the life of Wireless Rechargeable Sensor Network (WRSN), a system consisting of sensors with rechargeable batteries and mobile chargers. Existing solutions to charger scheduling problems require problem-specific design and a trade-off between the solution quality and computing time. Instead, we observe that instances of the same type of charger scheduling problem are solved repeatedly with similar combinatorial structure but different data. We consider searching an optimal charger scheduling as a trial and error process, and the objective function of a charging optimization problem as reward, a scalar feedback signal for each search. We propose a deep reinforcement learning-based charger scheduling optimization framework. The biggest advantage of the framework is that a diverse range of domain-specific charger scheduling strategy can be learned automatically from previous experiences. A framework also simplifies the complexity of algorithm design for individual charger scheduling optimization problem. We pick three representative charger scheduling optimization problems, design algorithms based on the proposed deep reinforcement learning framework, implement them, and compare them with existing ones. Extensive simulation results show that our algorithms based on the proposed framework outperform all existing ones.
Psoriasis Severity Assessment with a Similarity-Clustering Machine Learning Approach Reduces Intra- and Inter-observation variation
Sep 18, 2020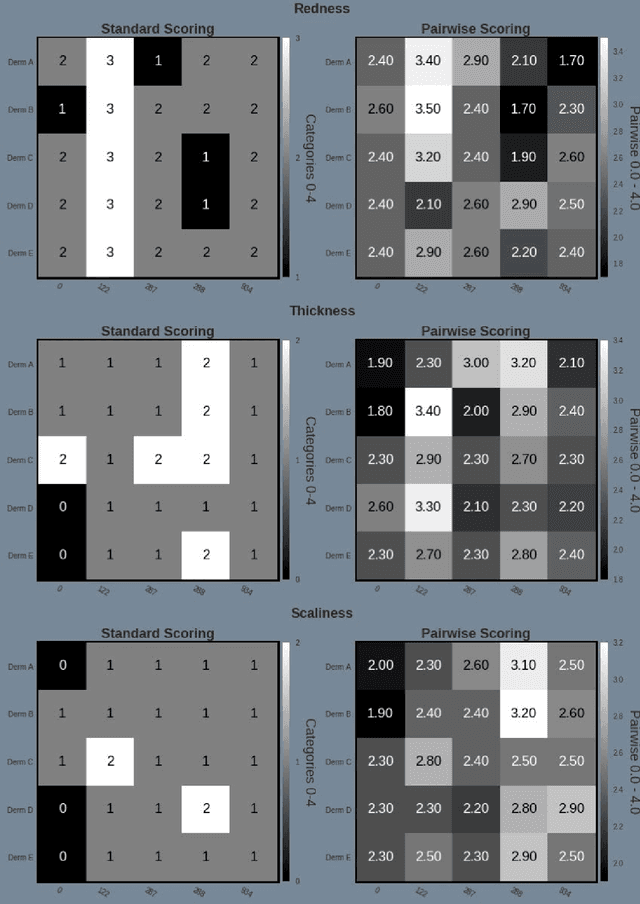
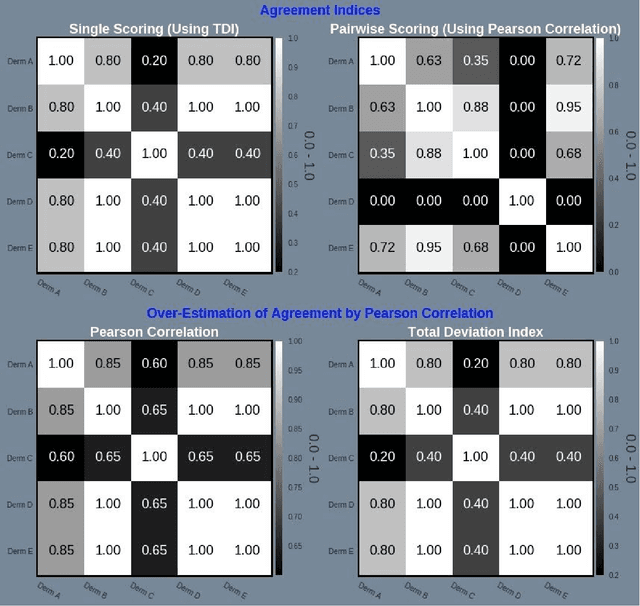
Psoriasis is a complex disease with many variations in genotype and phenotype. General advancements in medicine has further complicated both assessments and treatment for both physicians and dermatologist alike. Even with all of our technological progress we still primarily use the assessment tool Psoriasis Area and Severity Index (PASI) for severity assessments which was developed in the 1970s. In this study we evaluate a method involving digital images, a comparison web application and similarity clustering, developed to improve the assessment tool in terms of intra- and inter-observer variation. Images of patients was collected from a mobile device. Images were captured of the same lesion area taken approximately 1 week apart. Five dermatologists evaluated the severity of psoriasis by modified-PASI, absolute scoring and a relative pairwise PASI scoring using similarity-clustering and conducted using a web-program displaying two images at a time. mPASI scoring of single photos by the same or different dermatologist showed mPASI ratings of 50% to 80%, respectively. Repeated mPASI comparison using similarity clustering showed consistent mPASI ratings > 95%. Pearson correlation between absolute scoring and pairwise scoring progression was 0.72.
MARS: Multi-macro Architecture SRAM CIM-Based Accelerator with Co-designed Compressed Neural Networks
Oct 24, 2020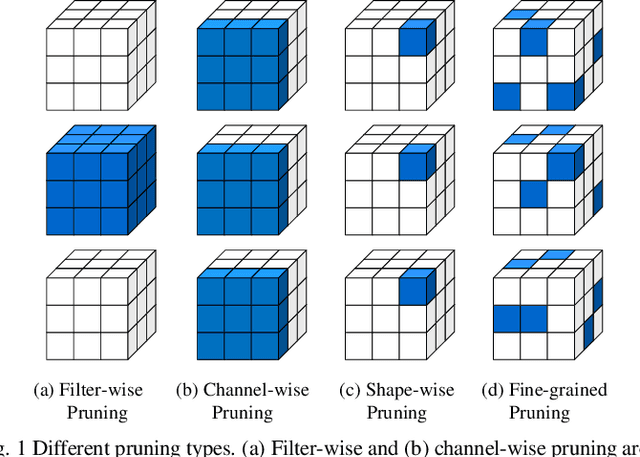
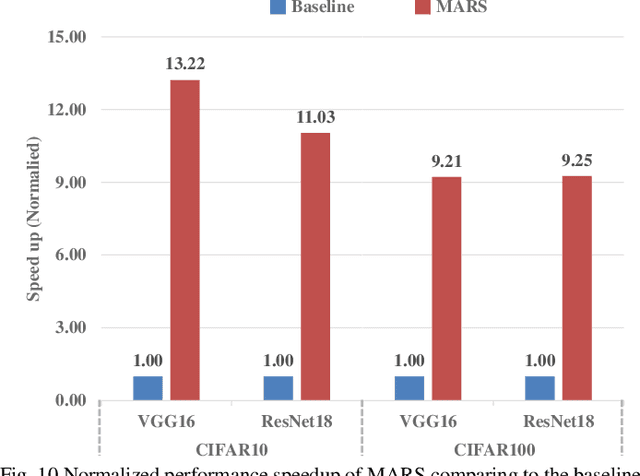
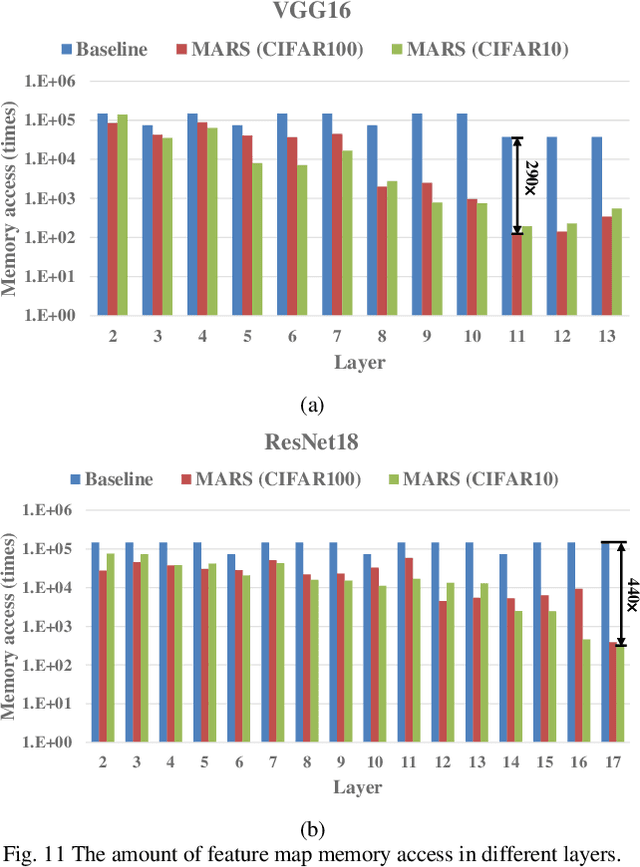
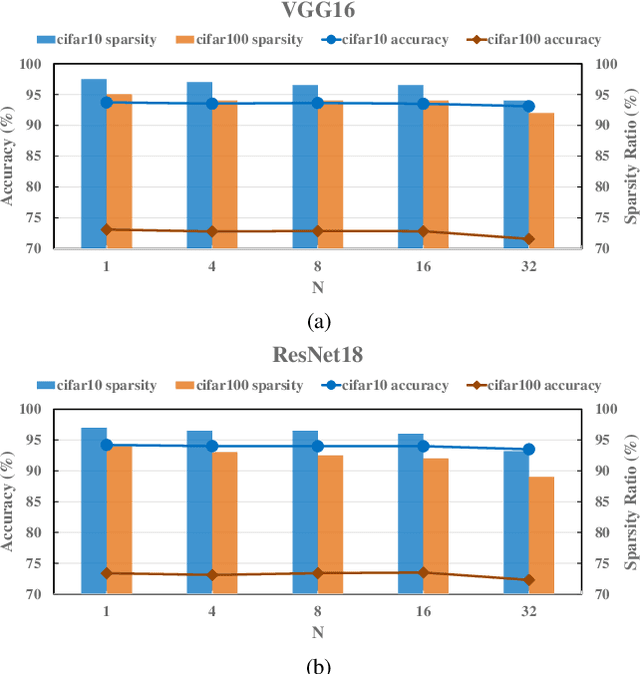
Convolutional neural networks (CNNs) play a key role in deep learning applications. However, the large storage overheads and the substantial computation cost of CNNs are problematic in hardware accelerators. Computing-in-memory (CIM) architecture has demonstrated great potential to effectively compute large-scale matrix-vector multiplication. However, the intensive multiply and accumulation (MAC) operations executed at the crossbar array and the limited capacity of CIM macros remain bottlenecks for further improvement of energy efficiency and throughput. To reduce computation costs, network pruning and quantization are two widely studied compression methods to shrink the model size. However, most of the model compression algorithms can only be implemented in digital-based CNN accelerators. For implementation in a static random access memory (SRAM) CIM-based accelerator, the model compression algorithm must consider the hardware limitations of CIM macros, such as the number of word lines and bit lines that can be turned on at the same time, as well as how to map the weight to the SRAM CIM macro. In this study, a software and hardware co-design approach is proposed to design an SRAM CIM-based CNN accelerator and an SRAM CIM-aware model compression algorithm. To lessen the high-precision MAC required by batch normalization (BN), a quantization algorithm that can fuse BN into the weights is proposed. Furthermore, to reduce the number of network parameters, a sparsity algorithm that considers a CIM architecture is proposed. Last, MARS, a CIM-based CNN accelerator that can utilize multiple SRAM CIM macros as processing units and support a sparsity neural network, is proposed.
Implementation of a Natural User Interface to Command a Drone
Mar 05, 2020
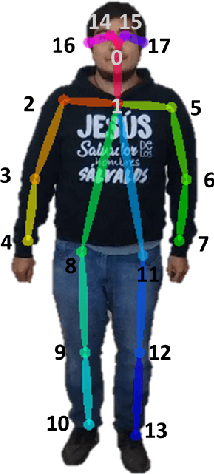
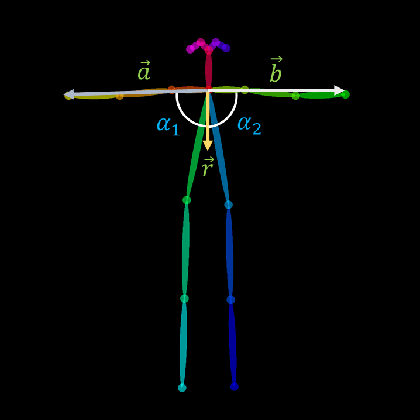
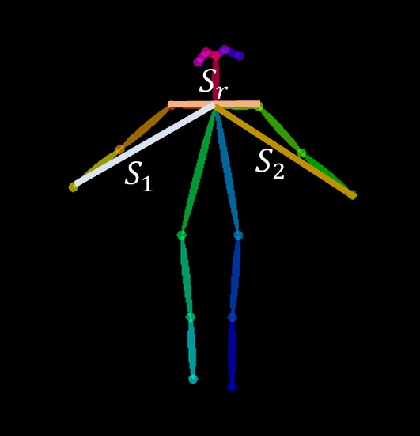
In this work, we propose the use of a Natural User Interface (NUI) through body gestures using the open source library OpenPose, looking for a more dynamic and intuitive way to control a drone. For the implementation, we use the Robotic Operative System (ROS) to control and manage the different components of the project. Wrapped inside ROS, OpenPose (OP) processes the video obtained in real-time by a commercial drone, allowing to obtain the user's pose. Finally, the keypoints from OpenPose are obtained and translated, using geometric constraints, to specify high-level commands to the drone. Real-time experiments validate the full strategy.
Compositional Video Synthesis with Action Graphs
Jul 13, 2020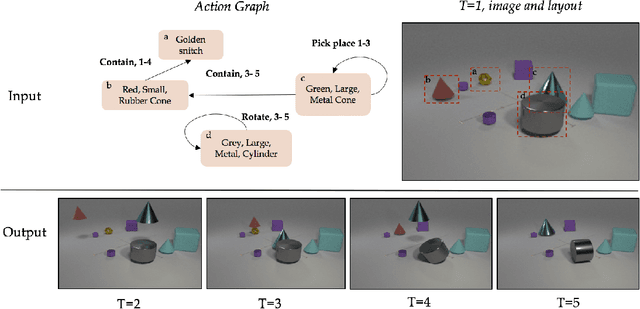
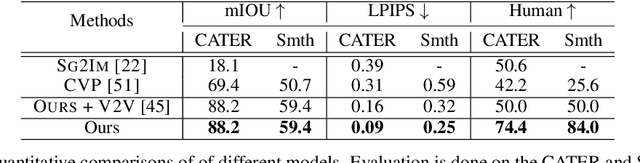
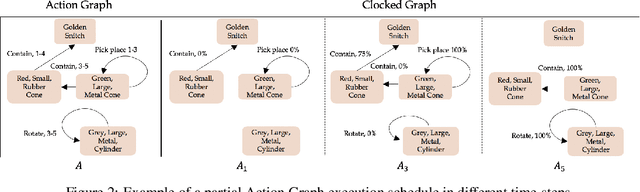
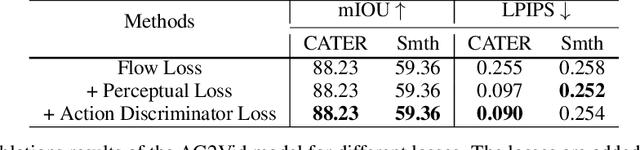
Videos of actions are complex spatio-temporal signals, containing rich compositional structures. Current generative models are limited in their ability to generate examples of object configurations outside the range they were trained on. Towards this end, we introduce a generative model (AG2Vid) based on Action Graphs, a natural and convenient structure that represents the dynamics of actions between objects over time. Our AG2Vid model disentangles appearance and position features, allowing for more accurate generation. AG2Vid is evaluated on the CATER and Something-Something datasets and outperforms other baselines. Finally, we show how Action Graphs can be used for generating novel compositions of unseen actions.
LACO: A Latency-Driven Network Slicing Orchestration in Beyond-5G Networks
Sep 07, 2020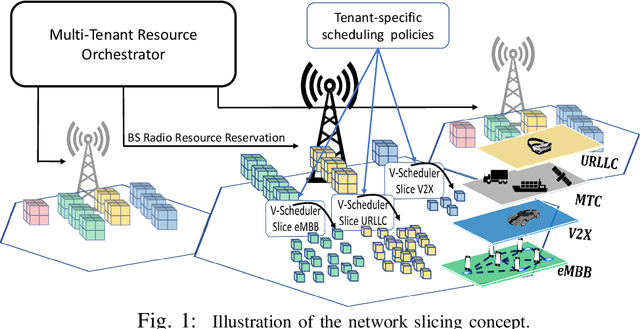
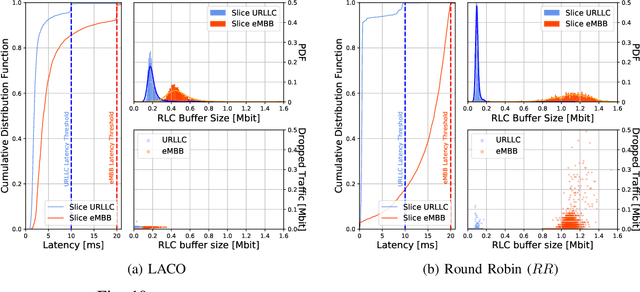
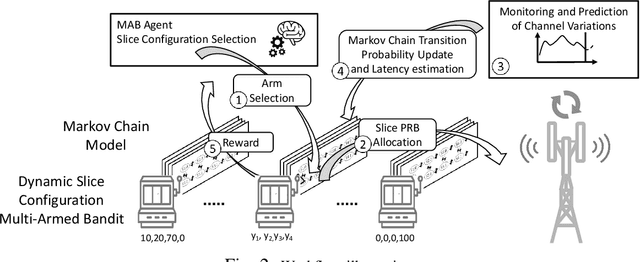
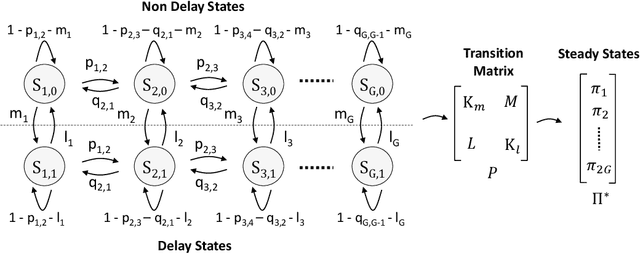
Network Slicing is expected to become a game changer in the upcoming 5G networks and beyond, enlarging the telecom business ecosystem through still-unexplored vertical industry profits. This implies that heterogeneous service level agreements (SLAs) must be guaranteed per slice given the multitude of predefined requirements. In this paper, we pioneer a novel radio slicing orchestration solution that simultaneously provides-latency and throughput guarantees in a multi-tenancy environment. Leveraging on a solid mathematical framework, we exploit the exploration-vs-exploitation paradigm by means of a multi-armed-bandit-based(MAB) orchestrator, LACO, that makes adaptive resource slicing decisions with no prior knowledge on the traffic demand or channel quality statistics. As opposed to traditional MAB methods that are blind to the underlying system, LACO relies on system structure information to expedite decisions. After a preliminary simulations campaign empirically proving the validness of our solution, we provide a robust implementation of LACO using off-the-shelf equipment to fully emulate realistic network conditions:near-optimal results within affordable computational time are measured when LACO is in place.
PMVOS: Pixel-Level Matching-Based Video Object Segmentation
Sep 18, 2020Semi-supervised video object segmentation (VOS) aims to segment arbitrary target objects in video when the ground truth segmentation mask of the initial frame is provided. Due to this limitation of using prior knowledge about the target object, feature matching, which compares template features representing the target object with input features, is an essential step. Recently, pixel-level matching (PM), which matches every pixel in template features and input features, has been widely used for feature matching because of its high performance. However, despite its effectiveness, the information used to build the template features is limited to the initial and previous frames. We address this issue by proposing a novel method-PM-based video object segmentation (PMVOS)-that constructs strong template features containing the information of all past frames. Furthermore, we apply self-attention to the similarity maps generated from PM to capture global dependencies. On the DAVIS 2016 validation set, we achieve new state-of-the-art performance among real-time methods (> 30 fps), with a J&F score of 85.6%. Performance on the DAVIS 2017 and YouTube-VOS validation sets is also impressive, with J&F scores of 74.0% and 68.2%, respectively.
Robust Model Predictive Longitudinal Position Tracking Control for an Autonomous Vehicle Based on Multiple Models
Sep 28, 2020
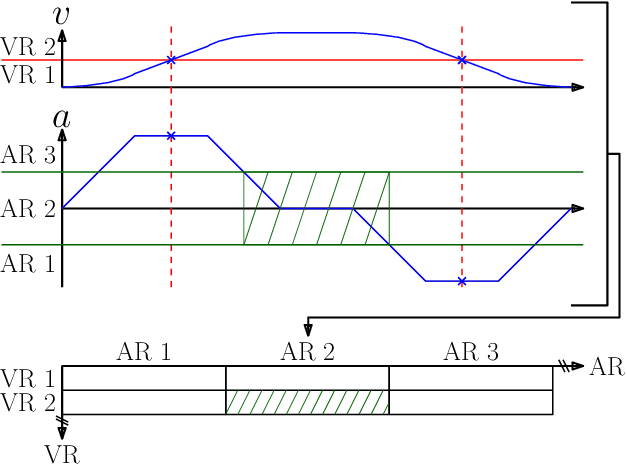
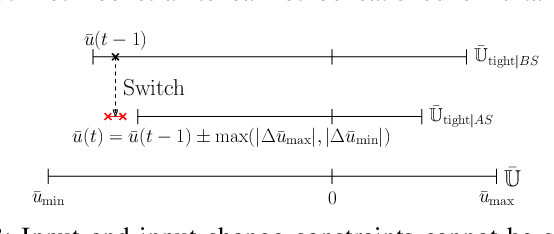
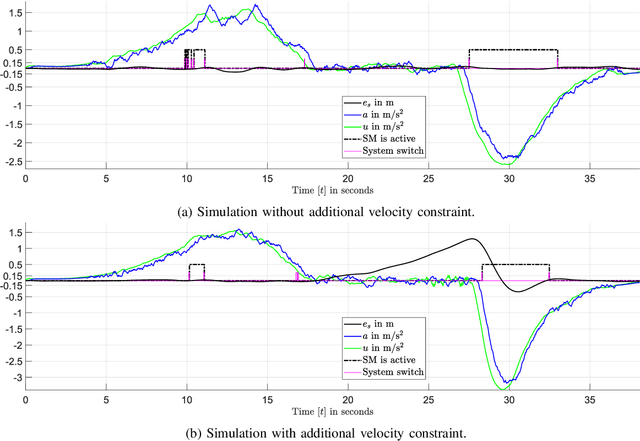
The aim of this work is to control the longitudinal position of an autonomous vehicle with an internal combustion engine. The powertrain has an inherent dead-time characteristic and constraints on physical states apply since the vehicle is neither able to accelerate arbitrarily strong, nor to drive arbitrarily fast. A model predictive controller (MPC) is able to cope with both of the aforementioned system properties. MPC heavily relies on a model and therefore a strategy on how to obtain multiple linear state space prediction models of the nonlinear system via input/output data system identification from acceleration data is given. The models are identified in different regions of the vehicle dynamics in order to obtain more accurate predictions. The still remaining plant-model mismatch can be expressed as an additive disturbance which can be handled through robust control theory. Therefore modifications to the models for applying robust MPC tracking control theory are described. Then a controller which guarantees robust constraint satisfaction and recursive feasibility is designed. As a next step, modifications to apply the controller on multiple models are discussed. In this context, a model switching strategy is provided and theoretical and computational limitations are pointed out. Lastly, simulation results are presented and discussed, including computational load when switching between systems.
Scaling up Differentially Private Deep Learning with Fast Per-Example Gradient Clipping
Sep 07, 2020
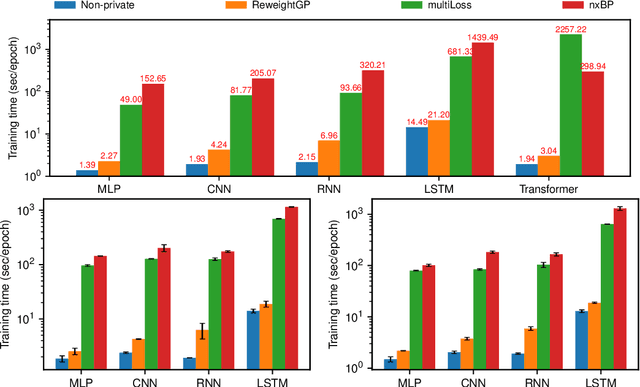
Recent work on Renyi Differential Privacy has shown the feasibility of applying differential privacy to deep learning tasks. Despite their promise, however, differentially private deep networks often lag far behind their non-private counterparts in accuracy, showing the need for more research in model architectures, optimizers, etc. One of the barriers to this expanded research is the training time -- often orders of magnitude larger than training non-private networks. The reason for this slowdown is a crucial privacy-related step called "per-example gradient clipping" whose naive implementation undoes the benefits of batch training with GPUs. By analyzing the back-propagation equations we derive new methods for per-example gradient clipping that are compatible with auto-differentiation (e.g., in PyTorch and TensorFlow) and provide better GPU utilization. Our implementation in PyTorch showed significant training speed-ups (by factors of 54x - 94x for training various models with batch sizes of 128). These techniques work for a variety of architectural choices including convolutional layers, recurrent networks, attention, residual blocks, etc.
Disentangled Representations for Domain-generalized Cardiac Segmentation
Aug 26, 2020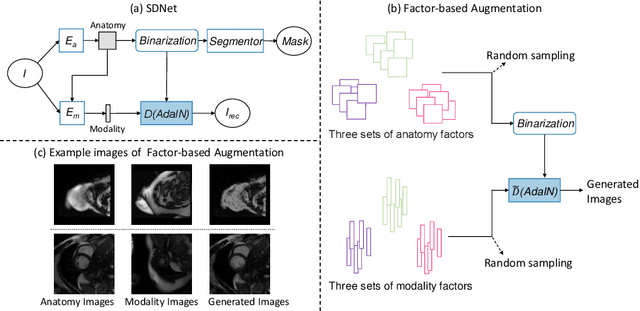
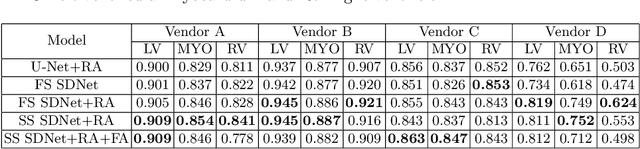
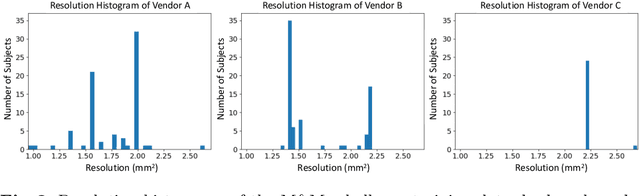
Robust cardiac image segmentation is still an open challenge due to the inability of the existing methods to achieve satisfactory performance on unseen data of different domains. Since the acquisition and annotation of medical data are costly and time-consuming, recent work focuses on domain adaptation and generalization to bridge the gap between data from different populations and scanners. In this paper, we propose two data augmentation methods that focus on improving the domain adaptation and generalization abilities of state-to-the-art cardiac segmentation models. In particular, our "Resolution Augmentation" method generates more diverse data by rescaling images to different resolutions within a range spanning different scanner protocols. Subsequently, our "Factor-based Augmentation" method generates more diverse data by projecting the original samples onto disentangled latent spaces, and combining the learned anatomy and modality factors from different domains. Our extensive experiments demonstrate the importance of efficient adaptation between seen and unseen domains, as well as model generalization ability, to robust cardiac image segmentation.