 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MetaDistiller: Network Self-Boosting via Meta-Learned Top-Down Distillation
Aug 27, 2020
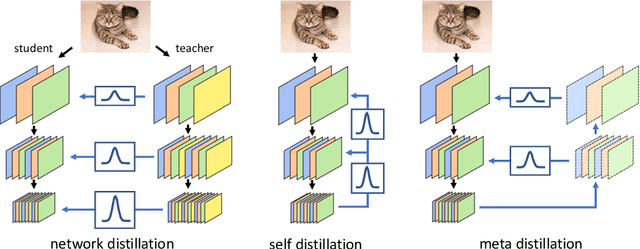
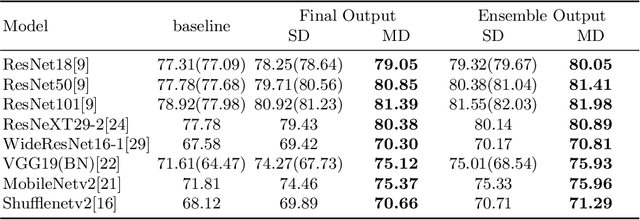
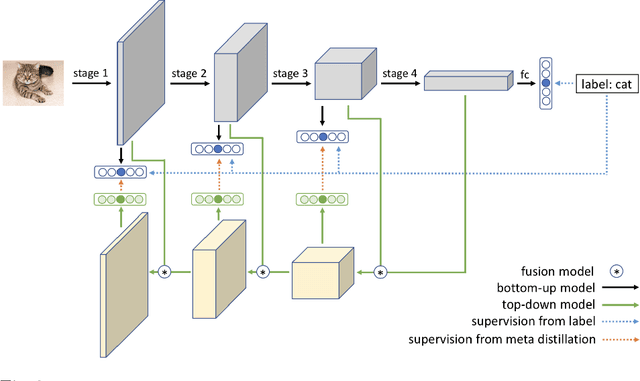

Knowledge Distillation (KD) has been one of the most popu-lar methods to learn a compact model. However, it still suffers from highdemand in time and computational resources caused by sequential train-ing pipeline. Furthermore, the soft targets from deeper models do notoften serve as good cues for the shallower models due to the gap of com-patibility. In this work, we consider these two problems at the same time.Specifically, we propose that better soft targets with higher compatibil-ity can be generated by using a label generator to fuse the feature mapsfrom deeper stages in a top-down manner, and we can employ the meta-learning technique to optimize this label generator. Utilizing the softtargets learned from the intermediate feature maps of the model, we canachieve better self-boosting of the network in comparison with the state-of-the-art. The experiments are conducted on two standard classificationbenchmarks, namely CIFAR-100 and ILSVRC2012. We test various net-work architectures to show the generalizability of our MetaDistiller. Theexperiments results on two datasets strongly demonstrate the effective-ness of our method.
I Like to Move It: 6D Pose Estimation as an Action Decision Process
Sep 26, 2020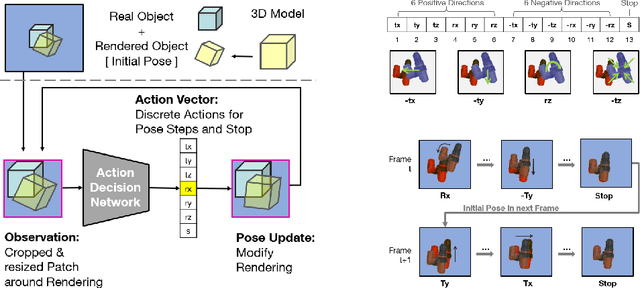
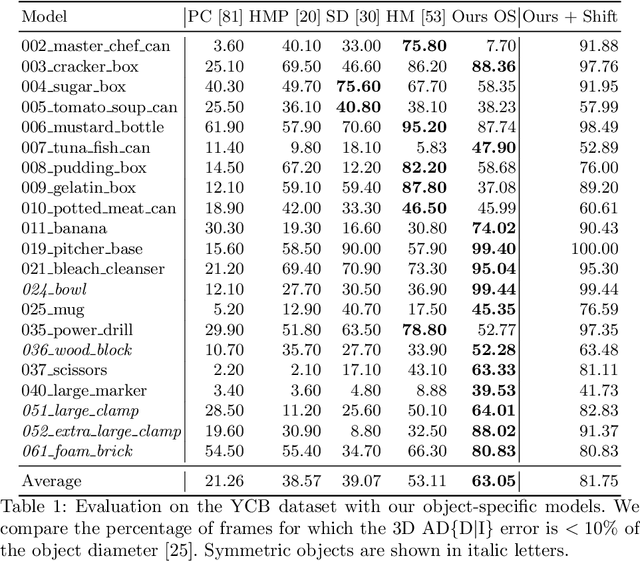
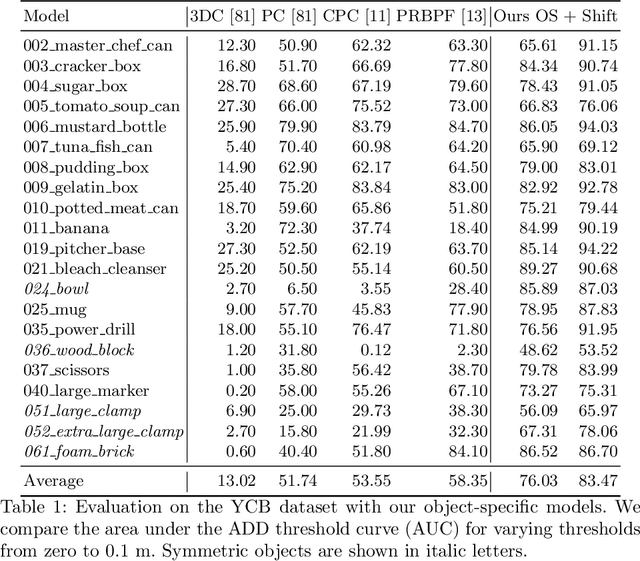
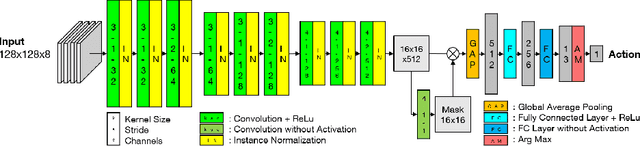
Object pose estimation is an integral part of robot vision and augmented reality. Robust and accurate pose prediction of both object rotation and translation is a crucial element to enable precise and safe human-machine interactions and to allow visualization in mixed reality. Previous 6D pose estimation methods treat the problem either as a regression task or discretize the pose space to classify. We reformulate the problem as an action decision process where an initial pose is updated in incremental discrete steps that sequentially move a virtual 3D rendering towards the correct solution. A neural network estimates likely moves from a single RGB image iteratively and determines so an acceptable final pose. In comparison to previous approaches that learn an object-specific pose embedding, a decision process allows for a lightweight architecture while it naturally generalizes to unseen objects. Moreover, the coherent action for process termination enables dynamic reduction of the computation cost if there are insignificant changes in a video sequence. While other methods only provide a static inference time, we can thereby automatically increase the runtime depending on the object motion. We evaluate robustness and accuracy of our action decision network on video scenes with known and unknown objects and show how this can improve the state-of-the-art on YCB videos significantly.
k-Nearest Neighbour Classifiers -- 2nd Edition
Apr 09, 2020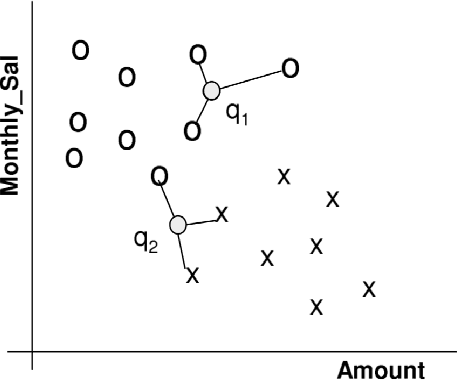
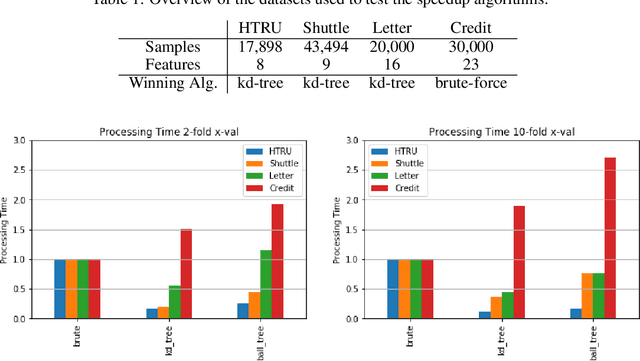
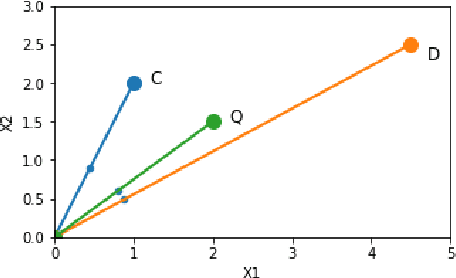
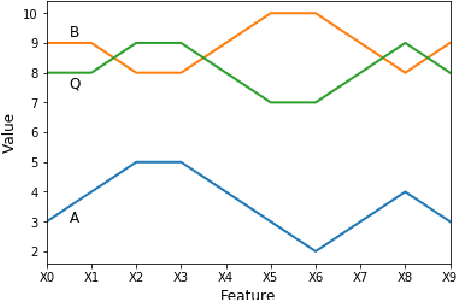
Perhaps the most straightforward classifier in the arsenal or machine learning techniques is the Nearest Neighbour Classifier -- classification is achieved by identifying the nearest neighbours to a query example and using those neighbours to determine the class of the query. This approach to classification is of particular importance because issues of poor run-time performance is not such a problem these days with the computational power that is available. This paper presents an overview of techniques for Nearest Neighbour classification focusing on; mechanisms for assessing similarity (distance), computational issues in identifying nearest neighbours and mechanisms for reducing the dimension of the data. This paper is the second edition of a paper previously published as a technical report. Sections on similarity measures for time-series, retrieval speed-up and intrinsic dimensionality have been added. An Appendix is included providing access to Python code for the key methods.
Histogram of gradients of Time-Frequency Representations for Audio scene detection
Aug 20, 2015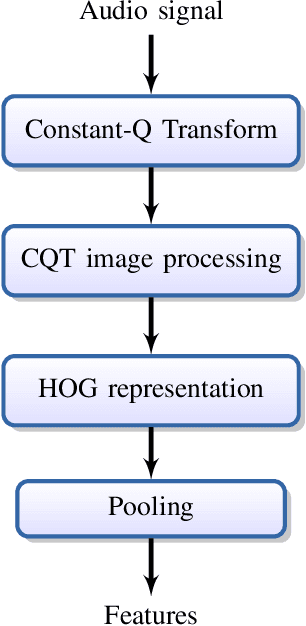
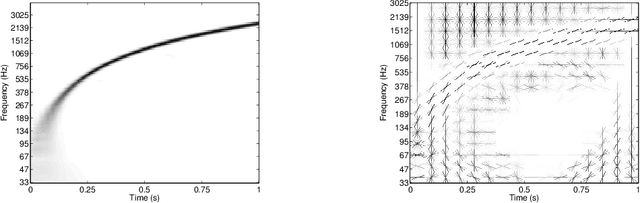
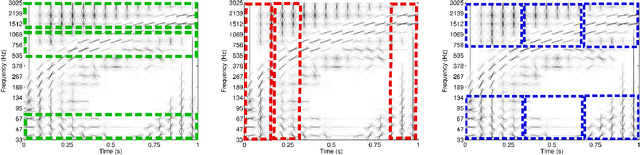
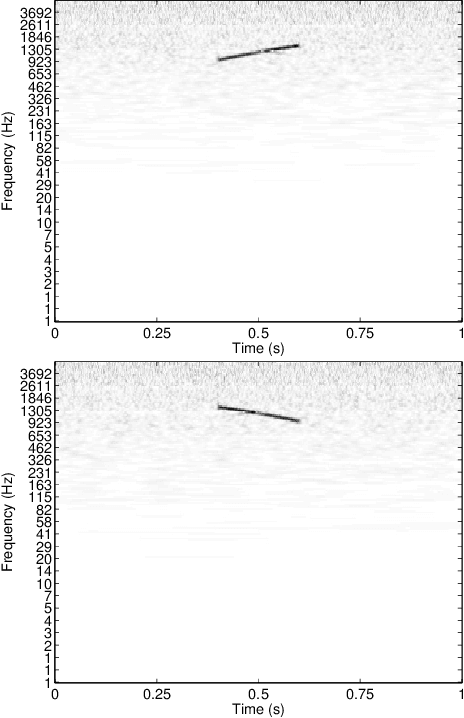
This paper addresses the problem of audio scenes classification and contributes to the state of the art by proposing a novel feature. We build this feature by considering histogram of gradients (HOG) of time-frequency representation of an audio scene. Contrarily to classical audio features like MFCC, we make the hypothesis that histogram of gradients are able to encode some relevant informations in a time-frequency {representation:} namely, the local direction of variation (in time and frequency) of the signal spectral power. In addition, in order to gain more invariance and robustness, histogram of gradients are locally pooled. We have evaluated the relevance of {the novel feature} by comparing its performances with state-of-the-art competitors, on several datasets, including a novel one that we provide, as part of our contribution. This dataset, that we make publicly available, involves $19$ classes and contains about $900$ minutes of audio scene recording. We thus believe that it may be the next standard dataset for evaluating audio scene classification algorithms. Our comparison results clearly show that our HOG-based features outperform its competitors
Benchmarking Robustness of Machine Reading Comprehension Models
Apr 29, 2020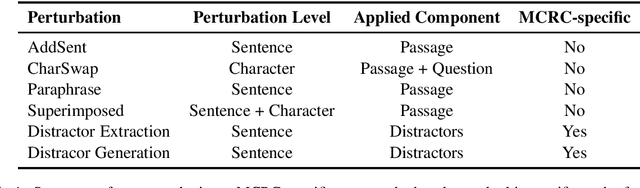
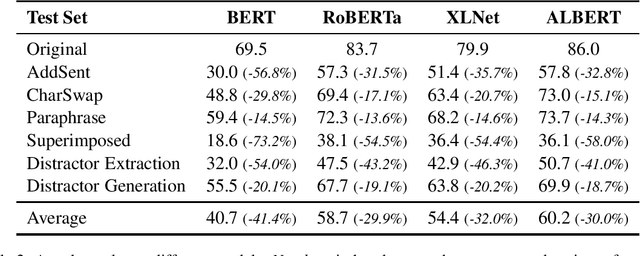
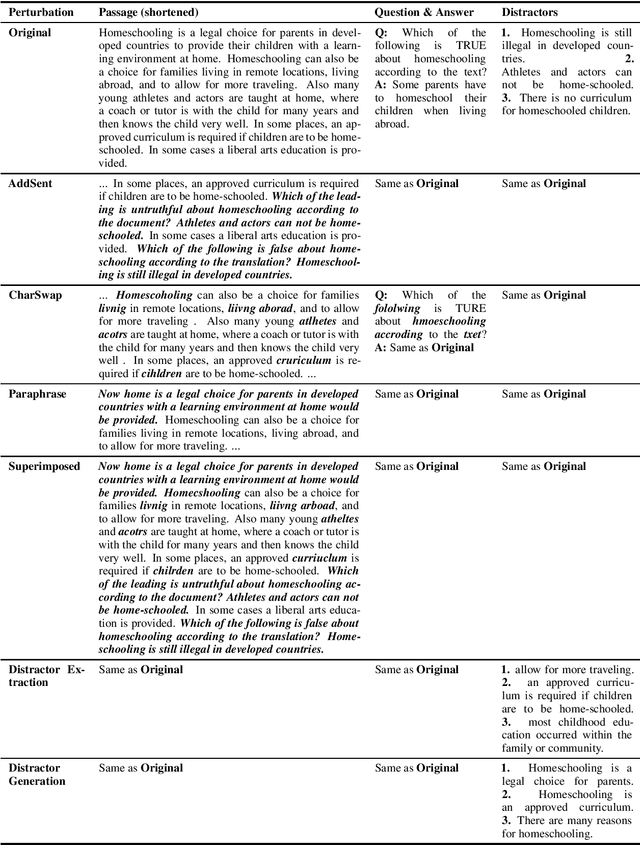
Machine Reading Comprehension (MRC) is an important testbed for evaluating models' natural language understanding (NLU) ability. There has been rapid progress in this area, with new models achieving impressive performance on various MRC benchmarks. However, most of these benchmarks only evaluate models on in-domain test sets without considering their robustness under test-time perturbations. To fill this important gap, we construct AdvRACE (Adversarial RACE), a new model-agnostic benchmark for evaluating the robustness of MRC models under six different types of test-time perturbations, including our novel superimposed attack and distractor construction attack. We show that current state-of-the-art (SOTA) models are vulnerable to these simple black-box attacks. Our benchmark is constructed automatically based on the existing RACE benchmark, and thus the construction pipeline can be easily adopted by other tasks and datasets. We will release the data and source codes to facilitate future work. We hope that our work will encourage more research on improving the robustness of MRC and other NLU models.
Extracting Seasonal Gradual Patterns from Temporal Sequence Data Using Periodic Patterns Mining
Oct 20, 2020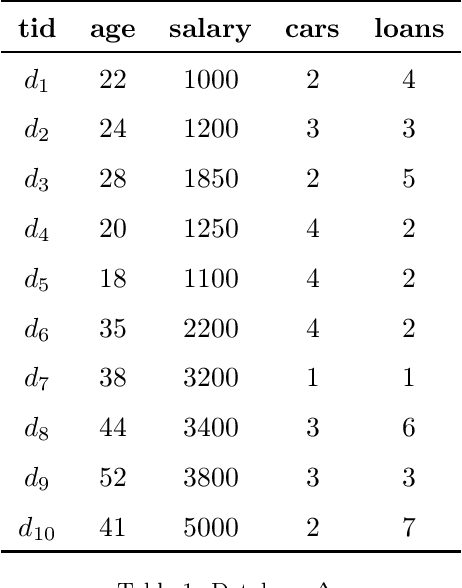
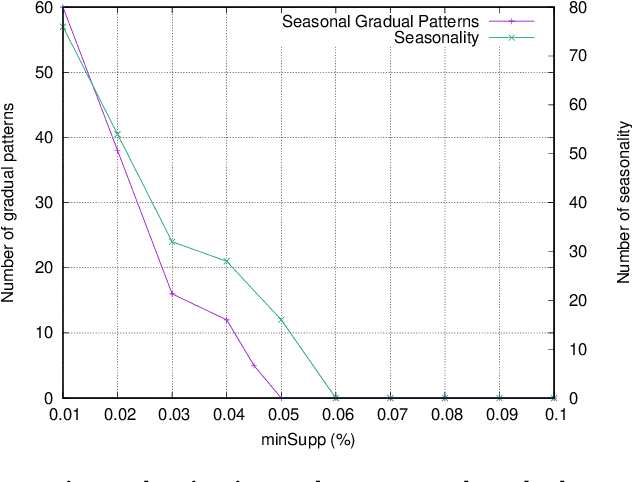
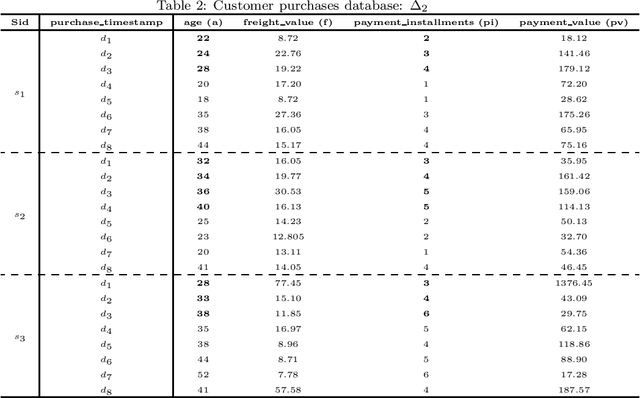
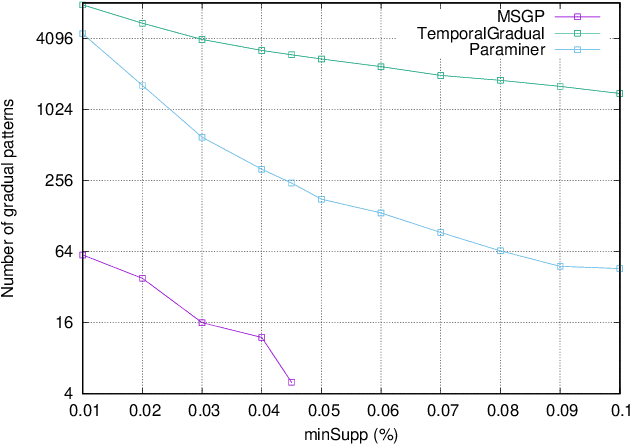
Mining frequent episodes aims at recovering sequential patterns from temporal data sequences, which can then be used to predict the occurrence of related events in advance. On the other hand, gradual patterns that capture co-variation of complex attributes in the form of " when X increases/decreases, Y increases/decreases" play an important role in many real world applications where huge volumes of complex numerical data must be handled. Recently, these patterns have received attention from the data mining community exploring temporal data who proposed methods to automatically extract gradual patterns from temporal data. However, to the best of our knowledge, no method has been proposed to extract gradual patterns that regularly appear at identical time intervals in many sequences of temporal data, despite the fact that such patterns may add knowledge to certain applications, such as e-commerce. In this paper, we propose to extract co-variations of periodically repeating attributes from the sequences of temporal data that we call seasonal gradual patterns. For this purpose, we formulate the task of mining seasonal gradual patterns as the problem of mining periodic patterns in multiple sequences and then we exploit periodic pattern mining algorithms to extract seasonal gradual patterns. We discuss specific features of these patterns and propose an approach for their extraction based on mining periodic frequent patterns common to multiple sequences. We also propose a new anti-monotonous support definition associated to these seasonal gradual patterns. The illustrative results obtained from some real world data sets show that the proposed approach is efficient and that it can extract small sets of patterns by filtering numerous nonseasonal patterns to identify the seasonal ones.
Multi-View Graph Convolutional Networks for Relationship-Driven Stock Prediction
May 11, 2020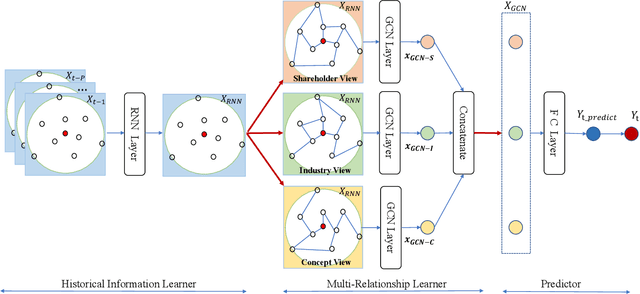

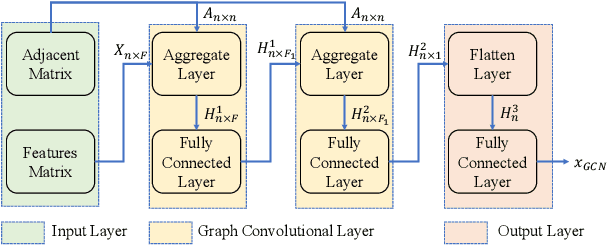
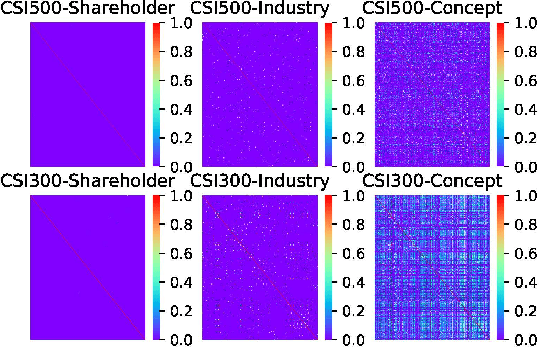
Stock price movement prediction is commonly accepted as a very challenging task due to the extremely volatile nature of financial markets. Previous works typically focus on understanding the temporal dependency of stock price movement based on the history of individual stock movement, but they do not take the complex relationships among involved stocks into consideration. However it is well known that an individual stock price is correlated with prices of other stocks. To address that, we propose a deep learning-based framework, which utilizes recurrent neural network (RNN) and graph convolutional network (GCN) to predict stock movement. Specifically, we first use RNN to model the temporal dependency of each related stock' price movement based on their own information of the past time slices, then we employ GCN to model the influence from involved stock based on three novel graphs which represent the shareholder relationship, industry relationship and concept relationship among stocks based on investment decisions. Experiments on two stock indexes in China market show that our model outperforms other baselines. To our best knowledge, it is the first time to incorporate multi-relationships among involved stocks into a GCN based deep learning framework for predicting stock price movement.
ISTA-NAS: Efficient and Consistent Neural Architecture Search by Sparse Coding
Oct 13, 2020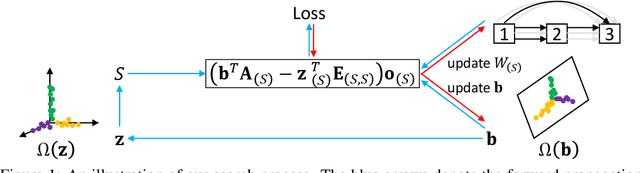
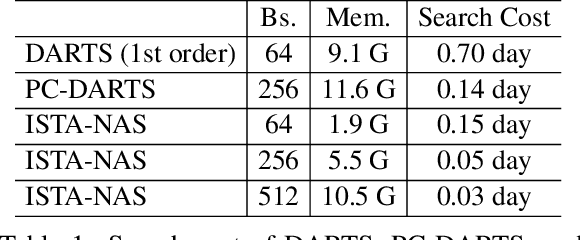

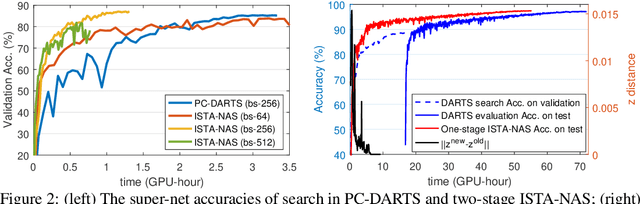
Neural architecture search (NAS) aims to produce the optimal sparse solution from a high-dimensional space spanned by all candidate connections. Current gradient-based NAS methods commonly ignore the constraint of sparsity in the search phase, but project the optimized solution onto a sparse one by post-processing. As a result, the dense super-net for search is inefficient to train and has a gap with the projected architecture for evaluation. In this paper, we formulate neural architecture search as a sparse coding problem. We perform the differentiable search on a compressed lower-dimensional space that has the same validation loss as the original sparse solution space, and recover an architecture by solving the sparse coding problem. The differentiable search and architecture recovery are optimized in an alternate manner. By doing so, our network for search at each update satisfies the sparsity constraint and is efficient to train. In order to also eliminate the depth and width gap between the network in search and the target-net in evaluation, we further propose a method to search and evaluate in one stage under the target-net settings. When training finishes, architecture variables are absorbed into network weights. Thus we get the searched architecture and optimized parameters in a single run. In experiments, our two-stage method on CIFAR-10 requires only 0.05 GPU-day for search. Our one-stage method produces state-of-the-art performances on both CIFAR-10 and ImageNet at the cost of only evaluation time.
Open Source Computer Vision-based Layer-wise 3D Printing Analysis
Mar 12, 2020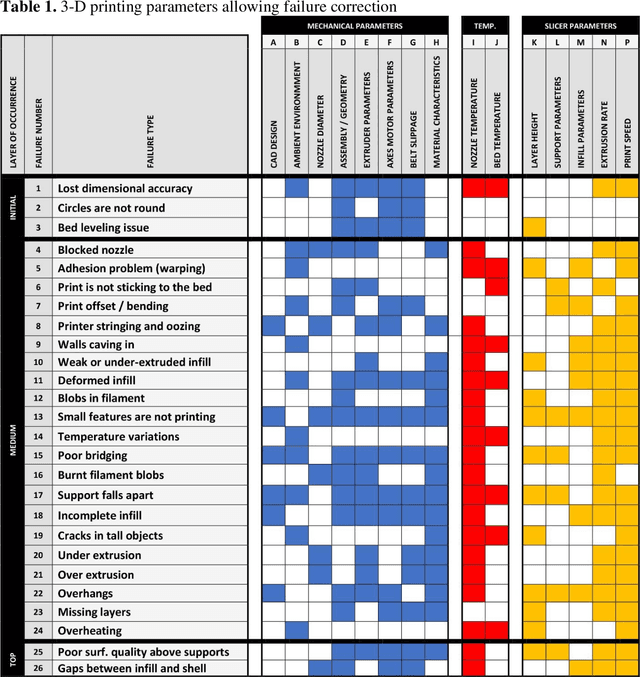

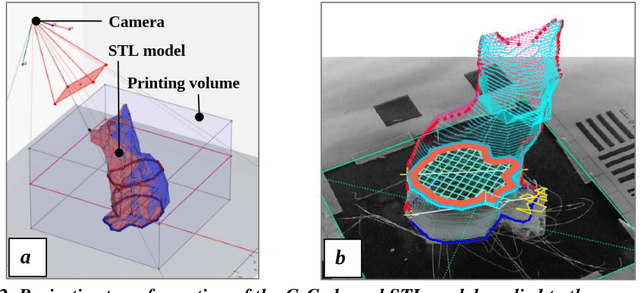
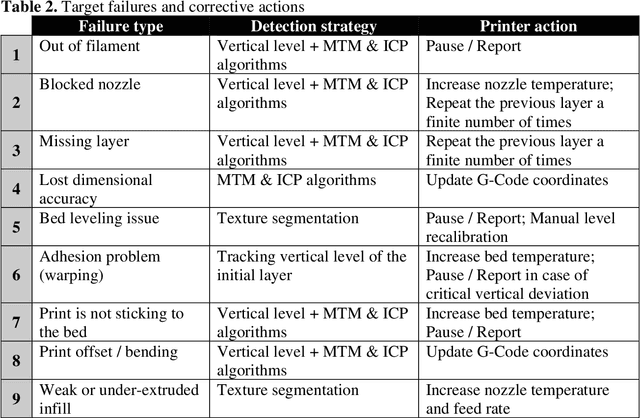
The paper describes an open source computer vision-based hardware structure and software algorithm, which analyzes layer-wise the 3-D printing processes, tracks printing errors, and generates appropriate printer actions to improve reliability. This approach is built upon multiple-stage monocular image examination, which allows monitoring both the external shape of the printed object and internal structure of its layers. Starting with the side-view height validation, the developed program analyzes the virtual top view for outer shell contour correspondence using the multi-template matching and iterative closest point algorithms, as well as inner layer texture quality clustering the spatial-frequency filter responses with Gaussian mixture models and segmenting structural anomalies with the agglomerative hierarchical clustering algorithm. This allows evaluation of both global and local parameters of the printing modes. The experimentally-verified analysis time per layer is less than one minute, which can be considered a quasi-real-time process for large prints. The systems can work as an intelligent printing suspension tool designed to save time and material. However, the results show the algorithm provides a means to systematize in situ printing data as a first step in a fully open source failure correction algorithm for additive manufacturing.
Exploring Efficient Volumetric Medical Image Segmentation Using 2.5D Method: An Empirical Study
Oct 13, 2020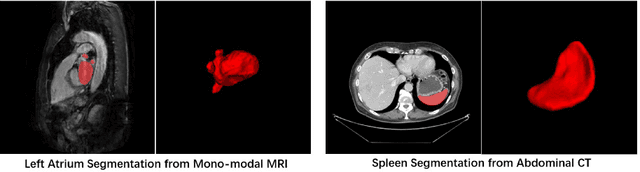
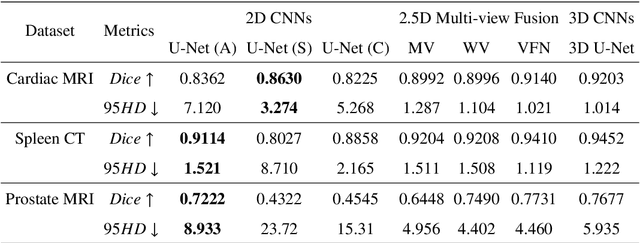
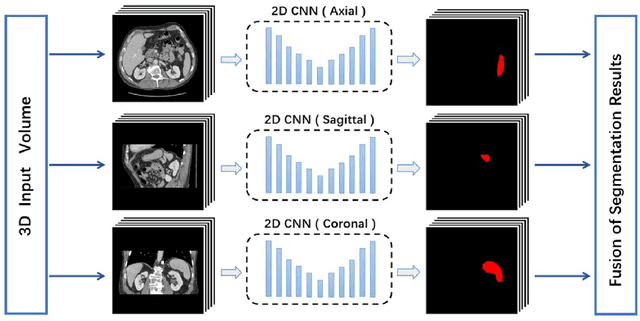
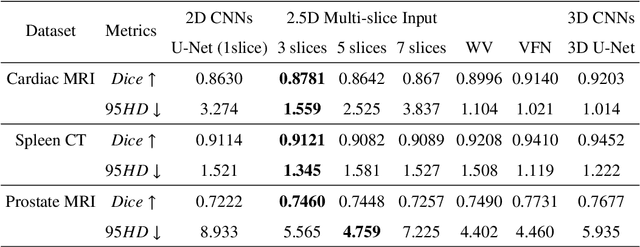
With the unprecedented developments in deep learning, many methods are proposed and have achieved great success for medical image segmentation. However, unlike segmentation of natural images, most medical images such as MRI and CT are volumetric data. In order to make full use of volumetric information, 3D CNNs are widely used. However, 3D CNNs suffer from higher inference time and computation cost, which hinders their further clinical applications. Additionally, with the increased number of parameters, the risk of overfitting is higher, especially for medical images where data and annotations are expensive to acquire. To issue this problem, many 2.5D segmentation methods have been proposed to make use of volumetric spatial information with less computation cost. Despite these works lead to improvements on a variety of segmentation tasks, to the best of our knowledge, there has not previously been a large-scale empirical comparison of these methods. In this paper, we aim to present a review of the latest developments of 2.5D methods for volumetric medical image segmentation. Additionally, to compare the performance and effectiveness of these methods, we provide an empirical study of these methods on three representative segmentation tasks involving different modalities and targets. Our experimental results highlight that 3D CNNs may not always be the best choice. Besides, although all these 2.5D methods can bring performance gains to 2D baseline, not all the methods hold the benefits on different datasets. We hope the results and conclusions of our study will prove useful for the community on exploring and developing efficient volumetric medical image segmentation methods.