 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PMVOS: Pixel-Level Matching-Based Video Object Segmentation
Sep 18, 2020
Semi-supervised video object segmentation (VOS) aims to segment arbitrary target objects in video when the ground truth segmentation mask of the initial frame is provided. Due to this limitation of using prior knowledge about the target object, feature matching, which compares template features representing the target object with input features, is an essential step. Recently, pixel-level matching (PM), which matches every pixel in template features and input features, has been widely used for feature matching because of its high performance. However, despite its effectiveness, the information used to build the template features is limited to the initial and previous frames. We address this issue by proposing a novel method-PM-based video object segmentation (PMVOS)-that constructs strong template features containing the information of all past frames. Furthermore, we apply self-attention to the similarity maps generated from PM to capture global dependencies. On the DAVIS 2016 validation set, we achieve new state-of-the-art performance among real-time methods (> 30 fps), with a J&F score of 85.6%. Performance on the DAVIS 2017 and YouTube-VOS validation sets is also impressive, with J&F scores of 74.0% and 68.2%, respectively.
Compositional Video Synthesis with Action Graphs
Jul 13, 2020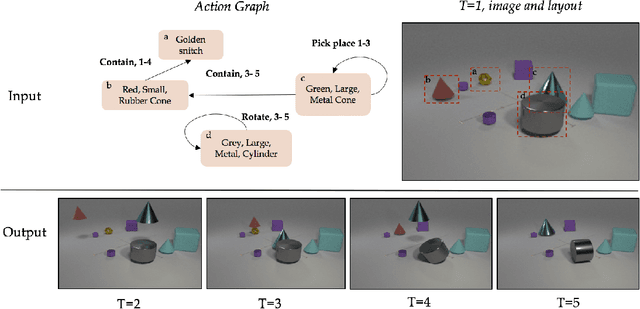
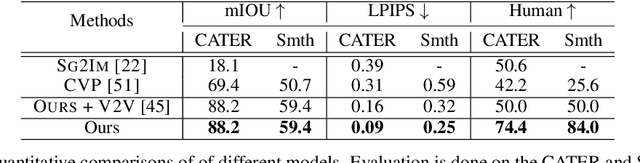
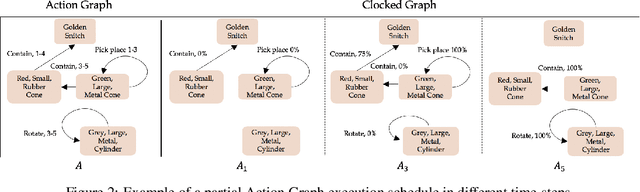
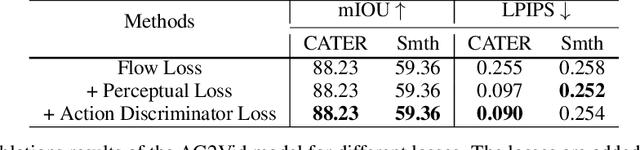
Videos of actions are complex spatio-temporal signals, containing rich compositional structures. Current generative models are limited in their ability to generate examples of object configurations outside the range they were trained on. Towards this end, we introduce a generative model (AG2Vid) based on Action Graphs, a natural and convenient structure that represents the dynamics of actions between objects over time. Our AG2Vid model disentangles appearance and position features, allowing for more accurate generation. AG2Vid is evaluated on the CATER and Something-Something datasets and outperforms other baselines. Finally, we show how Action Graphs can be used for generating novel compositions of unseen actions.
Scaling up Differentially Private Deep Learning with Fast Per-Example Gradient Clipping
Sep 07, 2020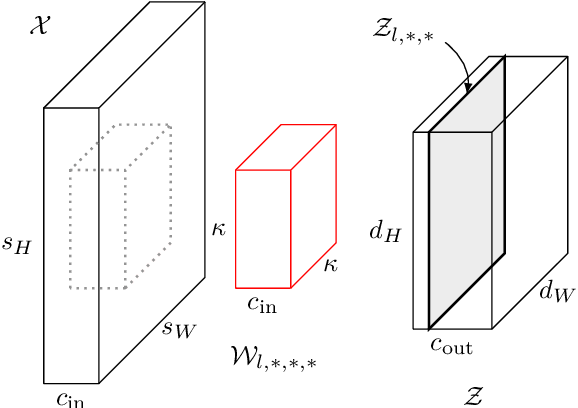
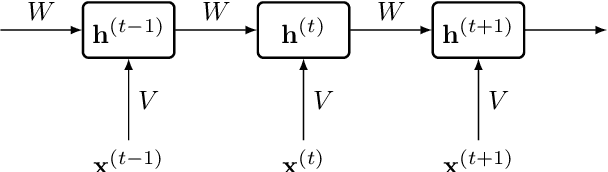
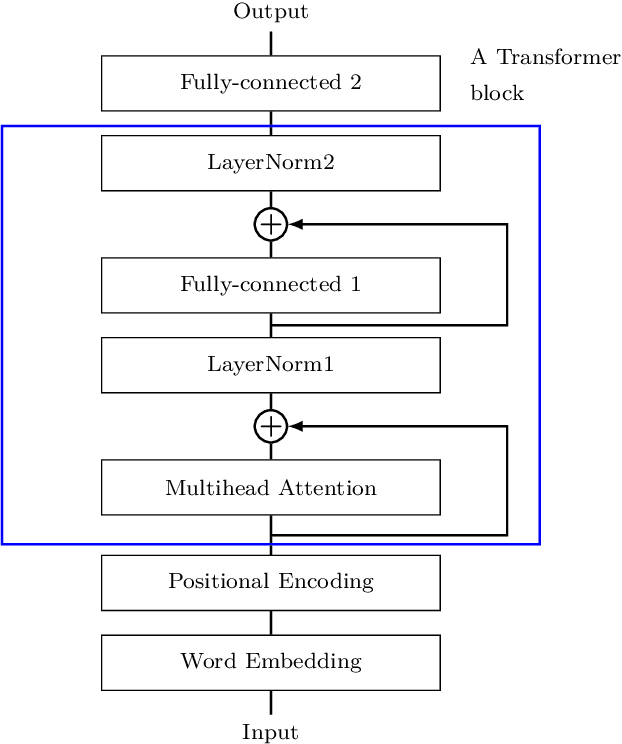
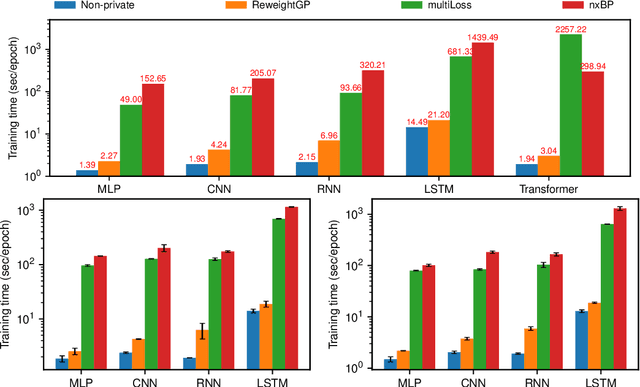
Recent work on Renyi Differential Privacy has shown the feasibility of applying differential privacy to deep learning tasks. Despite their promise, however, differentially private deep networks often lag far behind their non-private counterparts in accuracy, showing the need for more research in model architectures, optimizers, etc. One of the barriers to this expanded research is the training time -- often orders of magnitude larger than training non-private networks. The reason for this slowdown is a crucial privacy-related step called "per-example gradient clipping" whose naive implementation undoes the benefits of batch training with GPUs. By analyzing the back-propagation equations we derive new methods for per-example gradient clipping that are compatible with auto-differentiation (e.g., in PyTorch and TensorFlow) and provide better GPU utilization. Our implementation in PyTorch showed significant training speed-ups (by factors of 54x - 94x for training various models with batch sizes of 128). These techniques work for a variety of architectural choices including convolutional layers, recurrent networks, attention, residual blocks, etc.
Disentangled Representations for Domain-generalized Cardiac Segmentation
Aug 26, 2020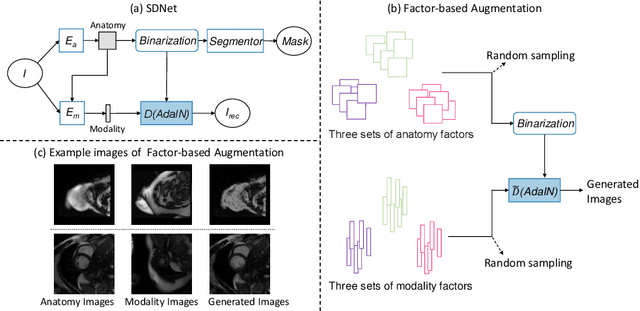
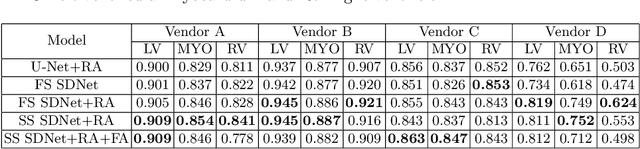
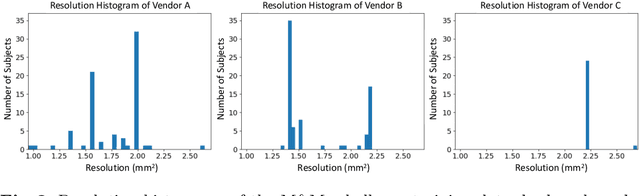
Robust cardiac image segmentation is still an open challenge due to the inability of the existing methods to achieve satisfactory performance on unseen data of different domains. Since the acquisition and annotation of medical data are costly and time-consuming, recent work focuses on domain adaptation and generalization to bridge the gap between data from different populations and scanners. In this paper, we propose two data augmentation methods that focus on improving the domain adaptation and generalization abilities of state-to-the-art cardiac segmentation models. In particular, our "Resolution Augmentation" method generates more diverse data by rescaling images to different resolutions within a range spanning different scanner protocols. Subsequently, our "Factor-based Augmentation" method generates more diverse data by projecting the original samples onto disentangled latent spaces, and combining the learned anatomy and modality factors from different domains. Our extensive experiments demonstrate the importance of efficient adaptation between seen and unseen domains, as well as model generalization ability, to robust cardiac image segmentation.
Implementation of a Natural User Interface to Command a Drone
Mar 05, 2020
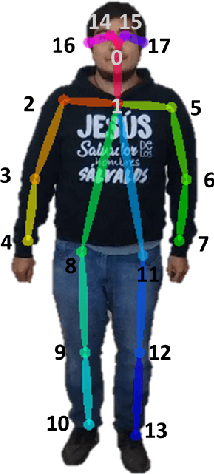
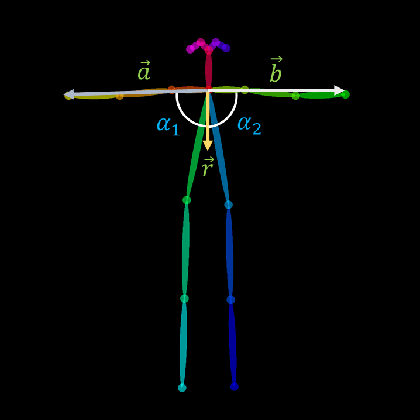
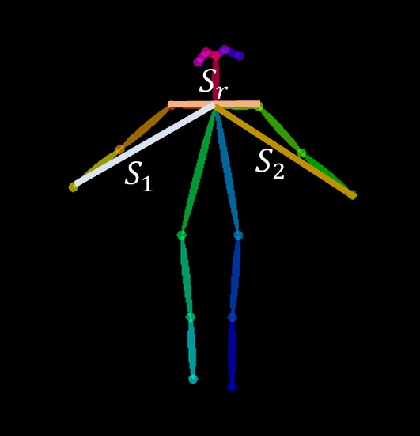
In this work, we propose the use of a Natural User Interface (NUI) through body gestures using the open source library OpenPose, looking for a more dynamic and intuitive way to control a drone. For the implementation, we use the Robotic Operative System (ROS) to control and manage the different components of the project. Wrapped inside ROS, OpenPose (OP) processes the video obtained in real-time by a commercial drone, allowing to obtain the user's pose. Finally, the keypoints from OpenPose are obtained and translated, using geometric constraints, to specify high-level commands to the drone. Real-time experiments validate the full strategy.
Detecting and adapting to crisis pattern with context based Deep Reinforcement Learning
Sep 07, 2020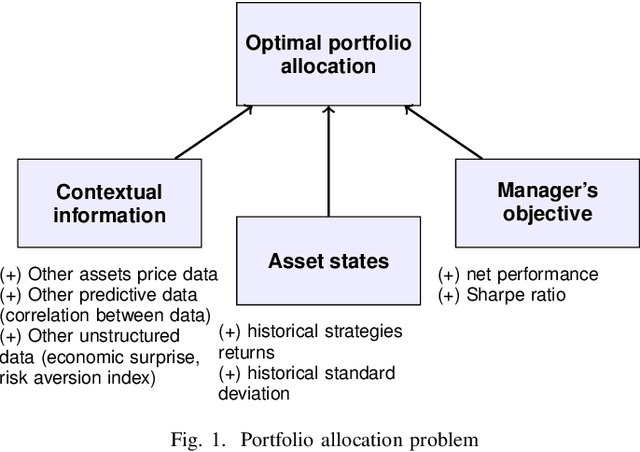

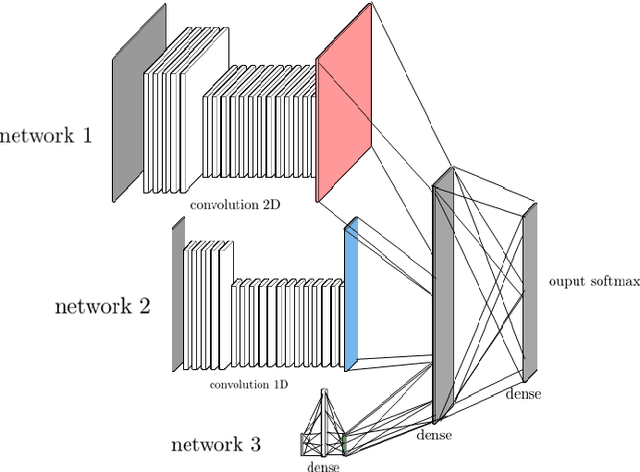
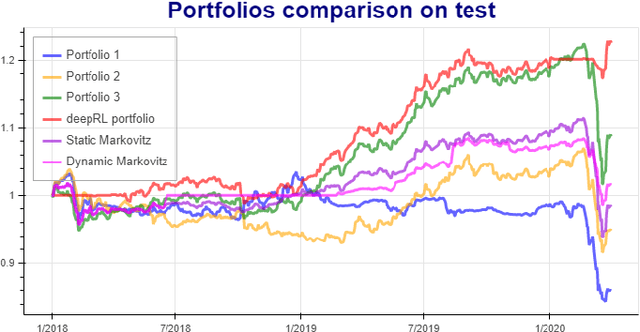
Deep reinforcement learning (DRL) has reached super human levels in complex tasks like game solving (Go and autonomous driving). However, it remains an open question whether DRL can reach human level in applications to financial problems and in particular in detecting pattern crisis and consequently dis-investing. In this paper, we present an innovative DRL framework consisting in two sub-networks fed respectively with portfolio strategies past performances and standard deviations as well as additional contextual features. The second sub network plays an important role as it captures dependencies with common financial indicators features like risk aversion, economic surprise index and correlations between assets that allows taking into account context based information. We compare different network architectures either using layers of convolutions to reduce network's complexity or LSTM block to capture time dependency and whether previous allocations is important in the modeling. We also use adversarial training to make the final model more robust. Results on test set show this approach substantially over-performs traditional portfolio optimization methods like Markowitz and is able to detect and anticipate crisis like the current Covid one.
Moving object detection for visual odometry in a dynamic environment based on occlusion accumulation
Sep 18, 2020



Detection of moving objects is an essential capability in dealing with dynamic environments. Most moving object detection algorithms have been designed for color images without depth. For robotic navigation where real-time RGB-D data is often readily available, utilization of the depth information would be beneficial for obstacle recognition. Here, we propose a simple moving object detection algorithm that uses RGB-D images. The proposed algorithm does not require estimating a background model. Instead, it uses an occlusion model which enables us to estimate the camera pose on a background confused with moving objects that dominate the scene. The proposed algorithm allows to separate the moving object detection and visual odometry (VO) so that an arbitrary robust VO method can be employed in a dynamic situation with a combination of moving object detection, whereas other VO algorithms for a dynamic environment are inseparable. In this paper, we use dense visual odometry (DVO) as a VO method with a bi-square regression weight. Experimental results show the segmentation accuracy and the performance improvement of DVO in the situations. We validate our algorithm in public datasets and our dataset which also publicly accessible.
* 7 pages
Group Activity Prediction with Sequential Relational Anticipation Model
Aug 06, 2020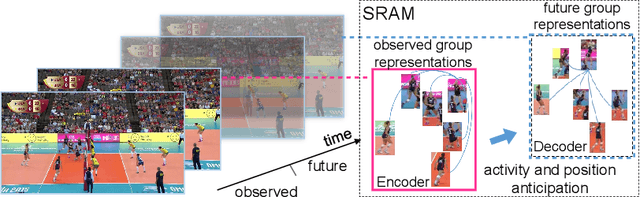
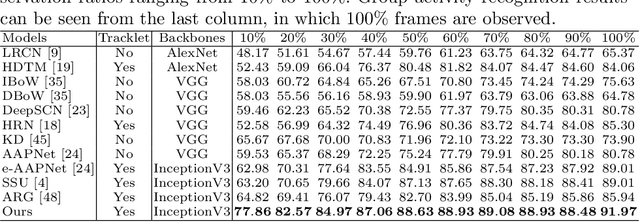

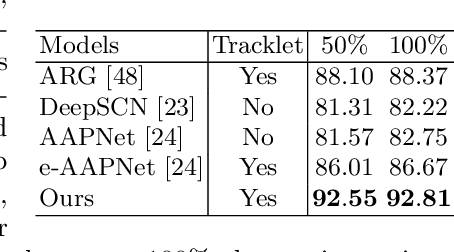
In this paper, we propose a novel approach to predict group activities given the beginning frames with incomplete activity executions. Existing action prediction approaches learn to enhance the representation power of the partial observation. However, for group activity prediction, the relation evolution of people's activity and their positions over time is an important cue for predicting group activity. To this end, we propose a sequential relational anticipation model (SRAM) that summarizes the relational dynamics in the partial observation and progressively anticipates the group representations with rich discriminative information. Our model explicitly anticipates both activity features and positions by two graph auto-encoders, aiming to learn a discriminative group representation for group activity prediction. Experimental results on two popularly used datasets demonstrate that our approach significantly outperforms the state-of-the-art activity prediction methods.
Foundations of Reasoning with Uncertainty via Real-valued Logics
Aug 06, 2020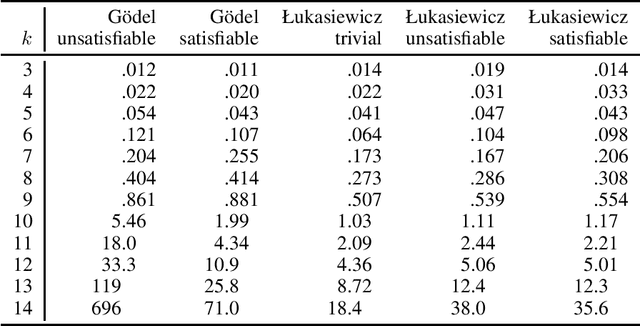
Real-valued logics underlie an increasing number of neuro-symbolic approaches, though typically their logical inference capabilities are characterized only qualitatively. We provide foundations for establishing the correctness and power of such systems. For the first time, we give a sound and complete axiomatization for a broad class containing all the common real-valued logics. This axiomatization allows us to derive exactly what information can be inferred about the combinations of real values of a collection of formulas given information about the combinations of real values of several other collections of formulas. We then extend the axiomatization to deal with weighted subformulas. Finally, we give a decision procedure based on linear programming for deciding, under certain natural assumptions, whether a set of our sentences logically implies another of our sentences.
Approximate Message Passing with Spectral Initialization for Generalized Linear Models
Oct 07, 2020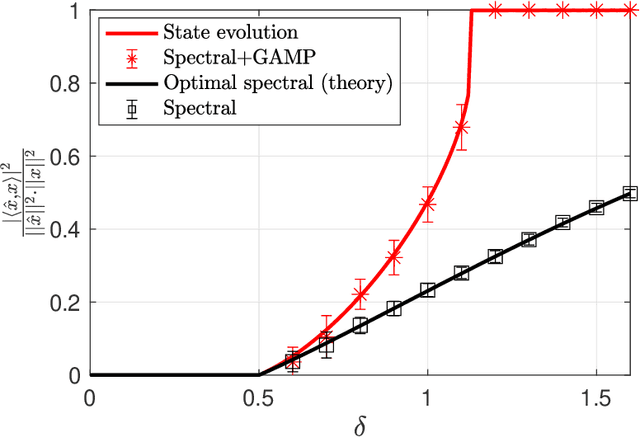
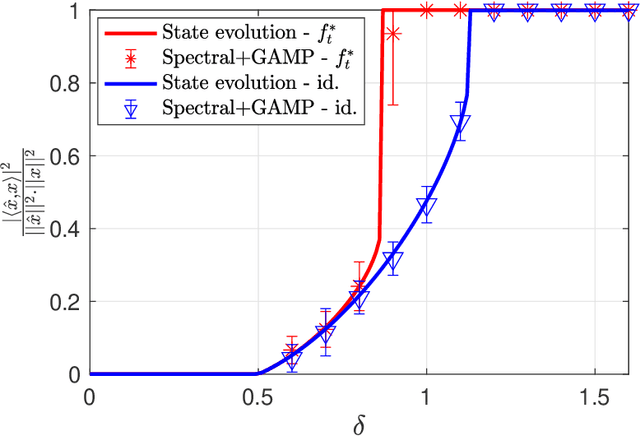

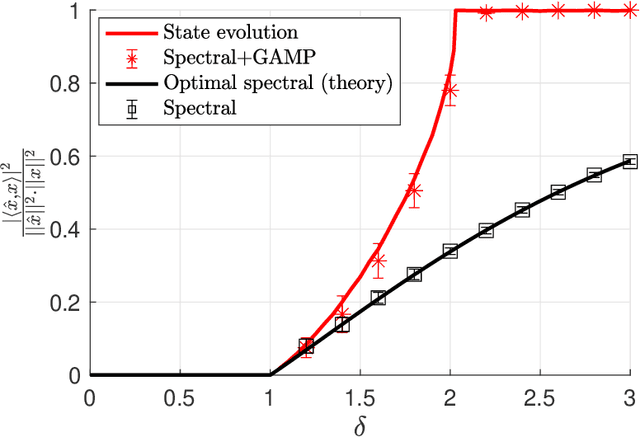
We consider the problem of estimating a signal from measurements obtained via a generalized linear model. We focus on estimators based on approximate message passing (AMP), a family of iterative algorithms with many appealing features: the performance of AMP in the high-dimensional limit can be succinctly characterized under suitable model assumptions; AMP can also be tailored to the empirical distribution of the signal entries, and for a wide class of estimation problems, AMP is conjectured to be optimal among all polynomial-time algorithms. However, a major issue of AMP is that in many models (such as phase retrieval), it requires an initialization correlated with the ground-truth signal and independent from the measurement matrix. Assuming that such an initialization is available is typically not realistic. In this paper, we solve this problem by proposing an AMP algorithm initialized with a spectral estimator. With such an initialization, the standard AMP analysis fails since the spectral estimator depends in a complicated way on the design matrix. Our main technical contribution is the construction and analysis of a two-phase artificial AMP algorithm that first produces the spectral estimator, and then closely approximates the iterates of the true AMP. Our analysis yields a rigorous characterization of the performance of AMP with spectral initialization in the high-dimensional limit. We also provide numerical results that demonstrate the validity of the proposed approach.