 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Puzzle-AE: Novelty Detection in Images through Solving Puzzles
Aug 29, 2020
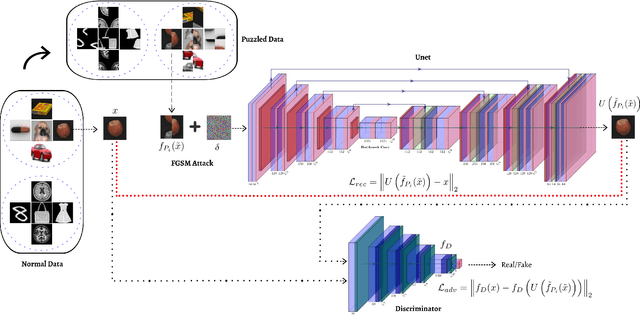
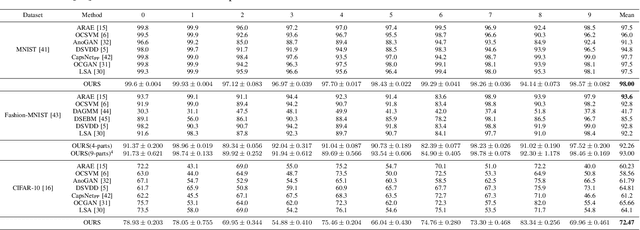
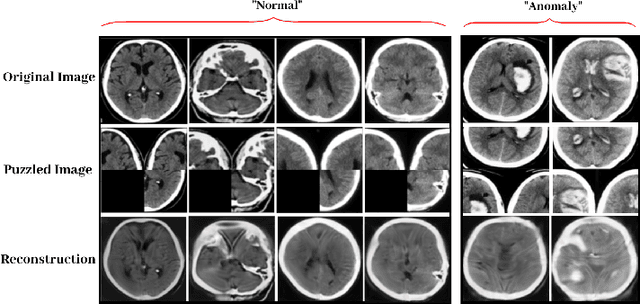

Autoencoder (AE) has proved to be an effective framework for novelty detection. However, they do not typically show promising results on other kinds of real-world datasets, which are exhibiting high intra-class variations, such as CIFAR-10. AEs are not generally able to learn a latent space that solely captures common features of the normal class, resulting in both high false positive and false negative rates due to modeling features that are irrelevant to the normal class. Recently, self-supervised learning has shown great promise in representation learning. To this end, we propose a new AE framework that is trained based on solving puzzles on randomly permuted image patches. Based on this framework, we achieve competitive or superior results compared to SOTA anomaly detection methods on various toy and real-world datasets. Unlike many competitors in this field, the proposed framework is stable, has real-time performance, more general and agnostic to choices of the model hyper-parameters, can work effectively under small sample size settings, and does not require unprincipled early stopping.
Multifunctionality in a Reservoir Computer
Aug 10, 2020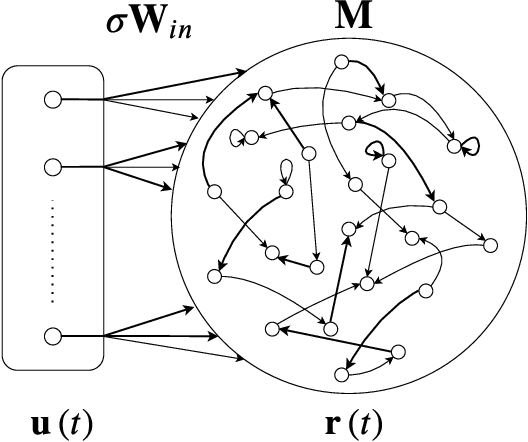
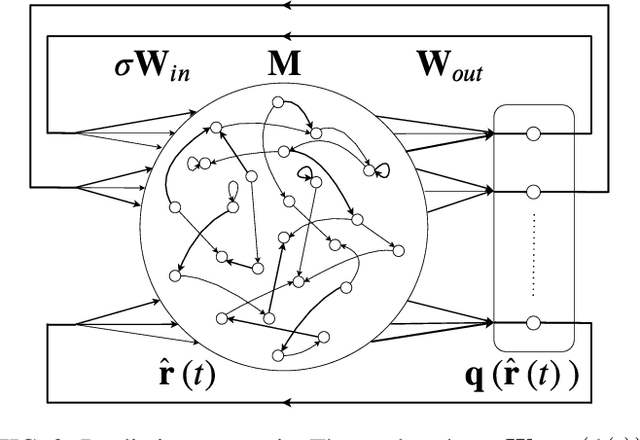
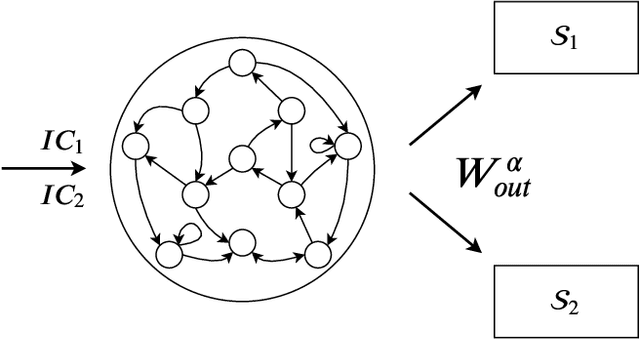
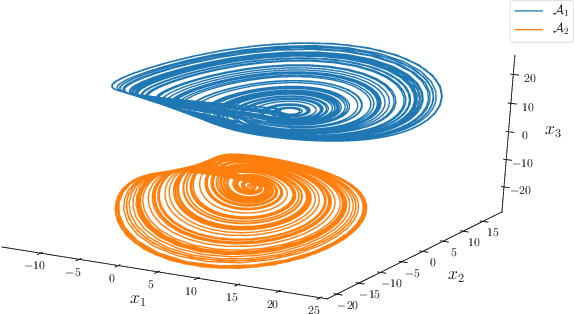
Multifunctionality is a well observed phenomenological feature of biological neural networks and considered to be of fundamental importance to the survival of certain species over time. These multifunctional neural networks are capable of performing more than one task without changing any network connections. In this paper we investigate how this neurological idiosyncrasy can be achieved in an artificial setting with a modern machine learning paradigm known as `Reservoir Computing'. A training technique is designed to enable a Reservoir Computer to perform tasks of a multifunctional nature. We explore the critical effects that changes in certain parameters can have on the Reservoir Computers' ability to express multifunctionality. We also expose the existence of several `untrained attractors'; attractors which dwell within the prediction state space of the Reservoir Computer that were not part of the training. We conduct a bifurcation analysis of these untrained attractors and discuss the implications of our results.
Anomaly Detection and Sampling Cost Control via Hierarchical GANs
Sep 28, 2020
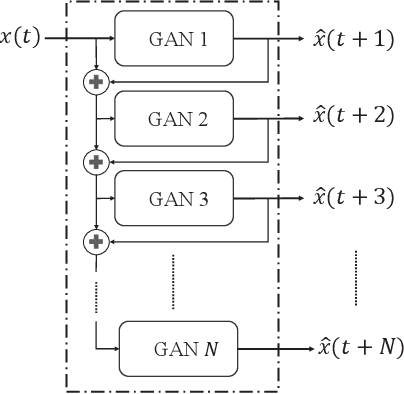
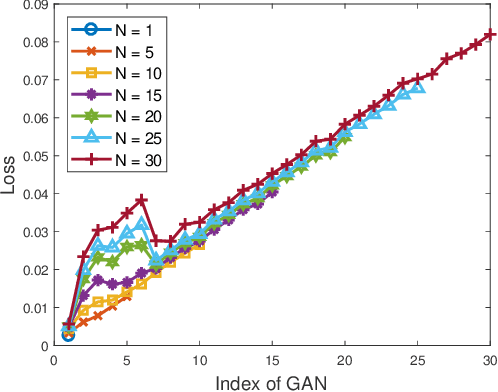
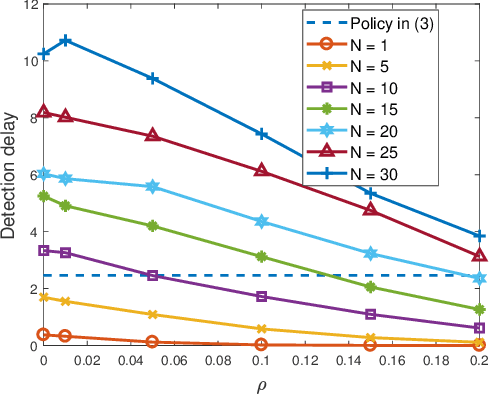
Anomaly detection incurs certain sampling and sensing costs and therefore it is of great importance to strike a balance between the detection accuracy and these costs. In this work, we study anomaly detection by considering the detection of threshold crossings in a stochastic time series without the knowledge of its statistics. To reduce the sampling cost in this detection process, we propose the use of hierarchical generative adversarial networks (GANs) to perform nonuniform sampling. In order to improve the detection accuracy and reduce the delay in detection, we introduce a buffer zone in the operation of the proposed GAN-based detector. In the experiments, we analyze the performance of the proposed hierarchical GAN detector considering the metrics of detection delay, miss rates, average cost of error, and sampling ratio. We identify the tradeoffs in the performance as the buffer zone sizes and the number of GAN levels in the hierarchy vary. We also compare the performance with that of a sampling policy that approximately minimizes the sum of average costs of sampling and error given the parameters of the stochastic process. We demonstrate that the proposed GAN-based detector can have significant performance improvements in terms of detection delay and average cost of error with a larger buffer zone but at the cost of increased sampling rates.
MLPnP - A Real-Time Maximum Likelihood Solution to the Perspective-n-Point Problem
Jul 27, 2016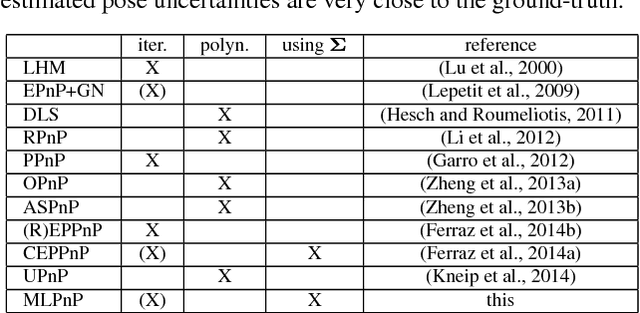
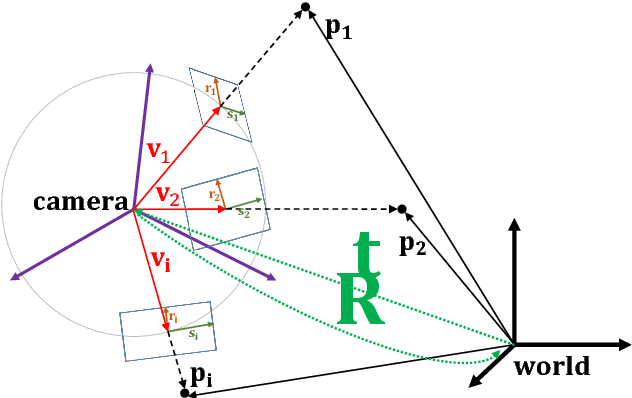
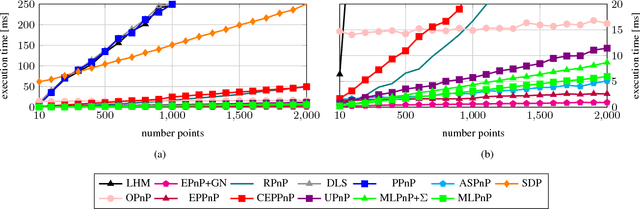

In this paper, a statistically optimal solution to the Perspective-n-Point (PnP) problem is presented. Many solutions to the PnP problem are geometrically optimal, but do not consider the uncertainties of the observations. In addition, it would be desirable to have an internal estimation of the accuracy of the estimated rotation and translation parameters of the camera pose. Thus, we propose a novel maximum likelihood solution to the PnP problem, that incorporates image observation uncertainties and remains real-time capable at the same time. Further, the presented method is general, as is works with 3D direction vectors instead of 2D image points and is thus able to cope with arbitrary central camera models. This is achieved by projecting (and thus reducing) the covariance matrices of the observations to the corresponding vector tangent space.
Self-Supervised Learning of Audio-Visual Objects from Video
Aug 10, 2020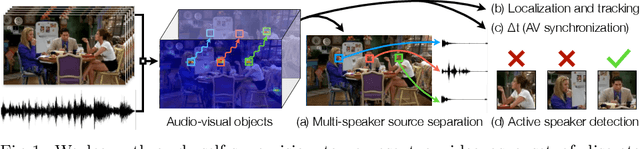
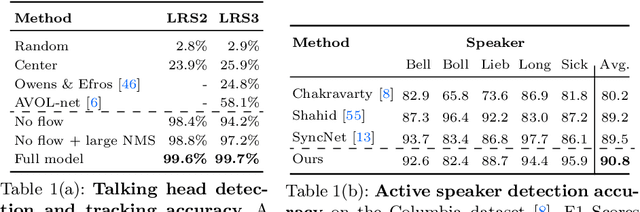
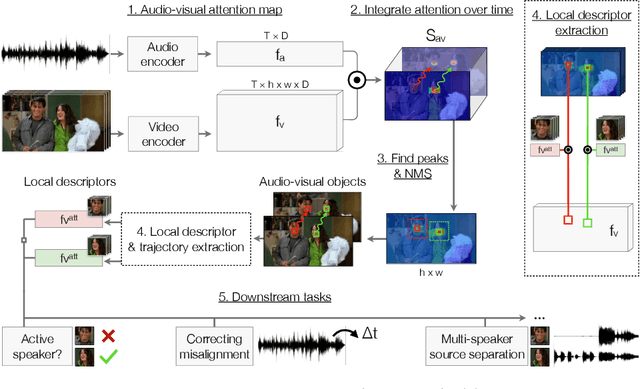
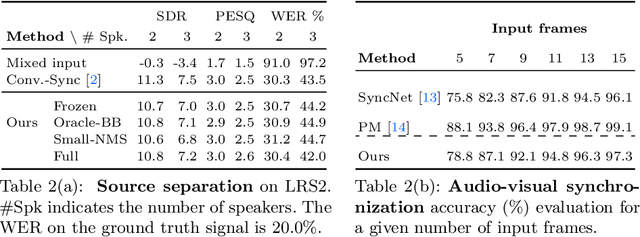
Our objective is to transform a video into a set of discrete audio-visual objects using self-supervised learning. To this end, we introduce a model that uses attention to localize and group sound sources, and optical flow to aggregate information over time. We demonstrate the effectiveness of the audio-visual object embeddings that our model learns by using them for four downstream speech-oriented tasks: (a) multi-speaker sound source separation, (b) localizing and tracking speakers, (c) correcting misaligned audio-visual data, and (d) active speaker detection. Using our representation, these tasks can be solved entirely by training on unlabeled video, without the aid of object detectors. We also demonstrate the generality of our method by applying it to non-human speakers, including cartoons and puppets.Our model significantly outperforms other self-supervised approaches, and obtains performance competitive with methods that use supervised face detection.
MedDG: A Large-scale Medical Consultation Dataset for Building Medical Dialogue System
Oct 15, 2020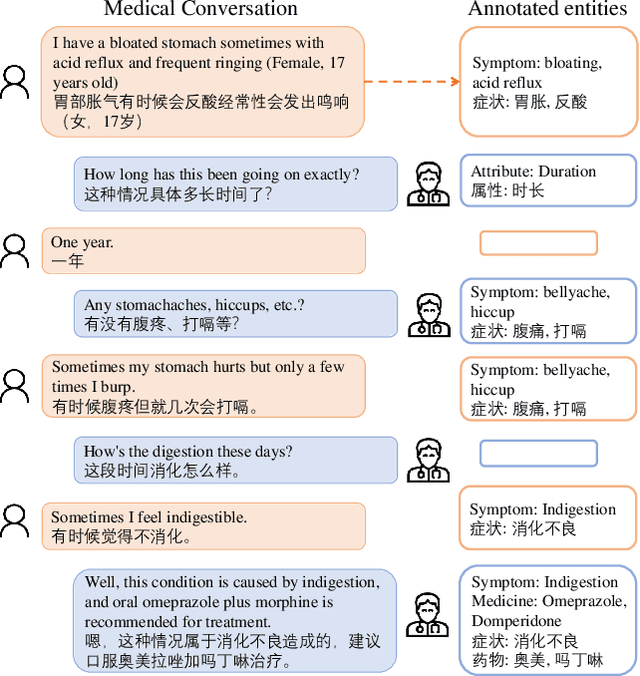

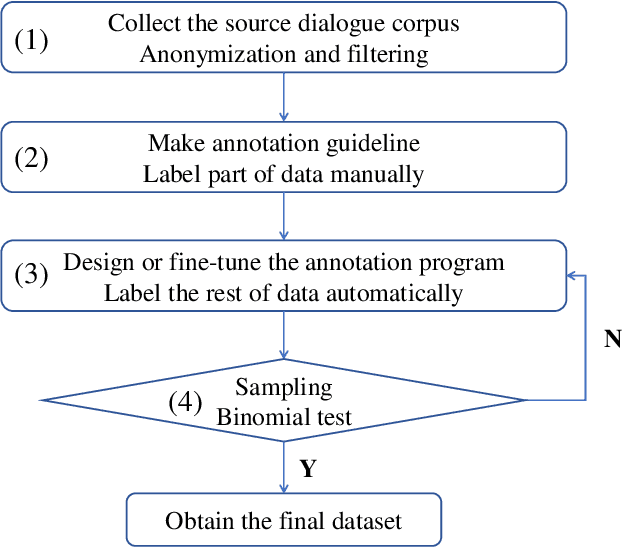
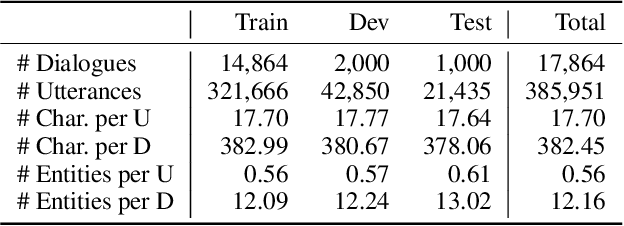
Developing conversational agents to interact with patients and provide primary clinical advice has attracted increasing attention due to its huge application potential, especially in the time of COVID-19 Pandemic. However, the training of end-to-end neural-based medical dialogue system is restricted by an insufficient quantity of medical dialogue corpus. In this work, we make the first attempt to build and release a large-scale high-quality Medical Dialogue dataset related to 12 types of common Gastrointestinal diseases named MedDG, with more than 17K conversations collected from the online health consultation community. Five different categories of entities, including diseases, symptoms, attributes, tests, and medicines, are annotated in each conversation of MedDG as additional labels. To push forward the future research on building expert-sensitive medical dialogue system, we proposes two kinds of medical dialogue tasks based on MedDG dataset. One is the next entity prediction and the other is the doctor response generation. To acquire a clear comprehension on these two medical dialogue tasks, we implement several state-of-the-art benchmarks, as well as design two dialogue models with a further consideration on the predicted entities. Experimental results show that the pre-train language models and other baselines struggle on both tasks with poor performance in our dataset, and the response quality can be enhanced with the help of auxiliary entity information. From human evaluation, the simple retrieval model outperforms several state-of-the-art generative models, indicating that there still remains a large room for improvement on generating medically meaningful responses.
Comparison of ARIMA, ETS, NNAR and hybrid models to forecast the second wave of COVID-19 hospitalizations in Italy
Oct 22, 2020
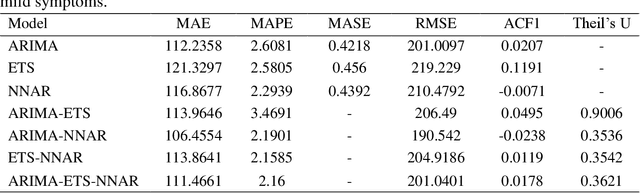
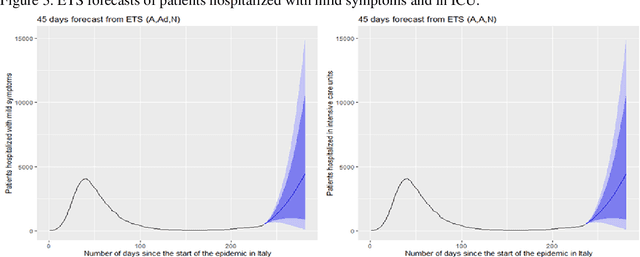
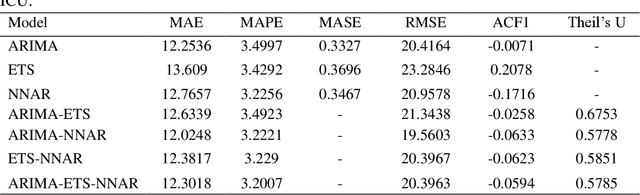
Coronavirus disease (COVID-19) is a severe ongoing novel pandemic that has emerged in Wuhan, China, in December 2019. As of October 13, the outbreak has spread rapidly across the world, affecting over 38 million people, and causing over 1 million deaths. In this article, I analysed several time series forecasting methods to predict the spread of COVID-19 second wave in Italy, over the period after October 13, 2020. I used an autoregressive model (ARIMA), an exponential smoothing state space model (ETS), a neural network autoregression model (NNAR), and the following hybrid combinations of them: ARIMA-ETS, ARIMA-NNAR, ETS-NNAR, and ARIMA-ETS-NNAR. About the data, I forecasted the number of patients hospitalized with mild symptoms, and in intensive care units (ICU). The data refer to the period February 21, 2020-October 13, 2020 and are extracted from the website of the Italian Ministry of Health (www.salute.gov.it). The results show that i) the hybrid models, except for ARIMA-ETS, are better at capturing the linear and non-linear epidemic patterns, by outperforming the respective single models; and ii) the number of COVID-19-related hospitalized with mild symptoms and in ICU will rapidly increase in the next weeks, by reaching the peak in about 50-60 days, i.e. in mid-December 2020, at least. To tackle the upcoming COVID-19 second wave, on one hand, it is necessary to hire healthcare workers and implement sufficient hospital facilities, protective equipment, and ordinary and intensive care beds; and on the other hand, it may be useful to enhance social distancing by improving public transport and adopting the double-shifts schooling system, for example.
Learning Dual Semantic Relations with Graph Attention for Image-Text Matching
Oct 22, 2020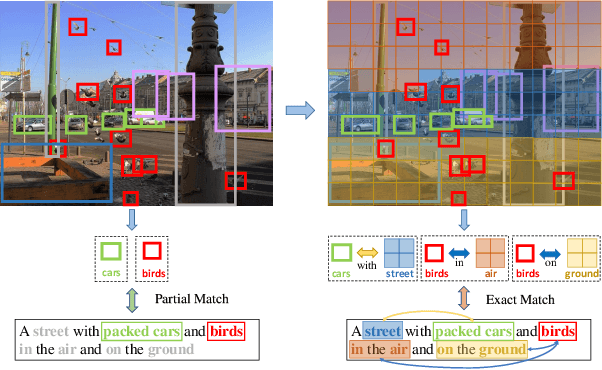
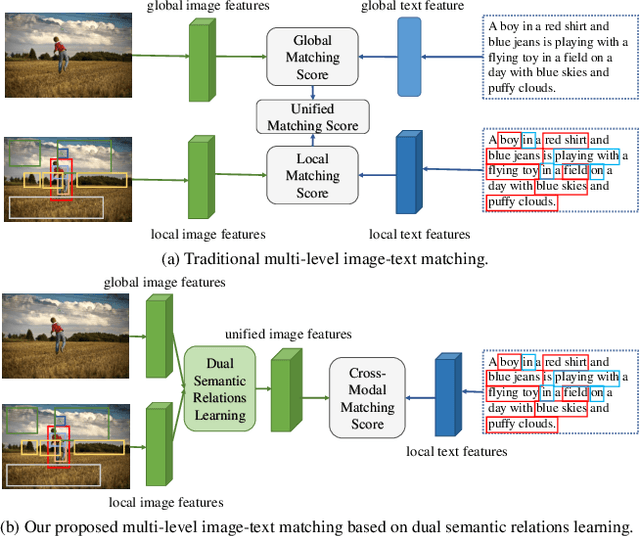
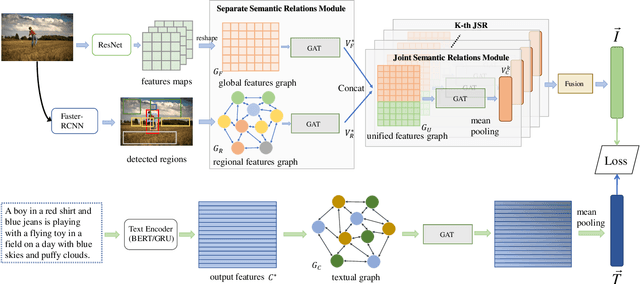
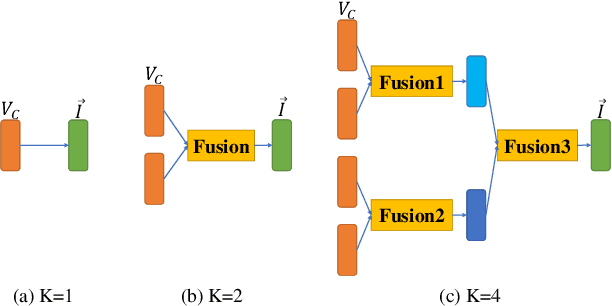
Image-Text Matching is one major task in cross-modal information processing. The main challenge is to learn the unified visual and textual representations. Previous methods that perform well on this task primarily focus on not only the alignment between region features in images and the corresponding words in sentences, but also the alignment between relations of regions and relational words. However, the lack of joint learning of regional features and global features will cause the regional features to lose contact with the global context, leading to the mismatch with those non-object words which have global meanings in some sentences. In this work, in order to alleviate this issue, it is necessary to enhance the relations between regions and the relations between regional and global concepts to obtain a more accurate visual representation so as to be better correlated to the corresponding text. Thus, a novel multi-level semantic relations enhancement approach named Dual Semantic Relations Attention Network(DSRAN) is proposed which mainly consists of two modules, separate semantic relations module and the joint semantic relations module. DSRAN performs graph attention in both modules respectively for region-level relations enhancement and regional-global relations enhancement at the same time. With these two modules, different hierarchies of semantic relations are learned simultaneously, thus promoting the image-text matching process by providing more information for the final visual representation. Quantitative experimental results have been performed on MS-COCO and Flickr30K and our method outperforms previous approaches by a large margin due to the effectiveness of the dual semantic relations learning scheme. Codes are available at https://github.com/kywen1119/DSRAN.
Exploiting Multi-Modal Features From Pre-trained Networks for Alzheimer's Dementia Recognition
Sep 09, 2020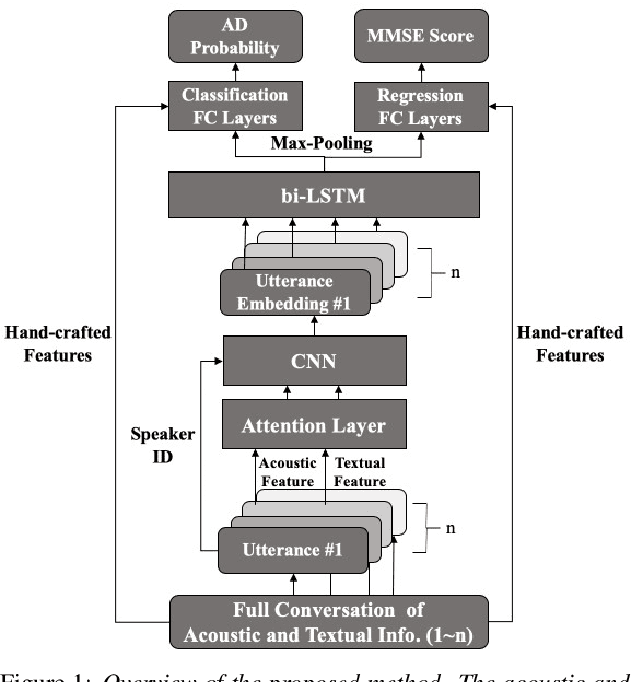

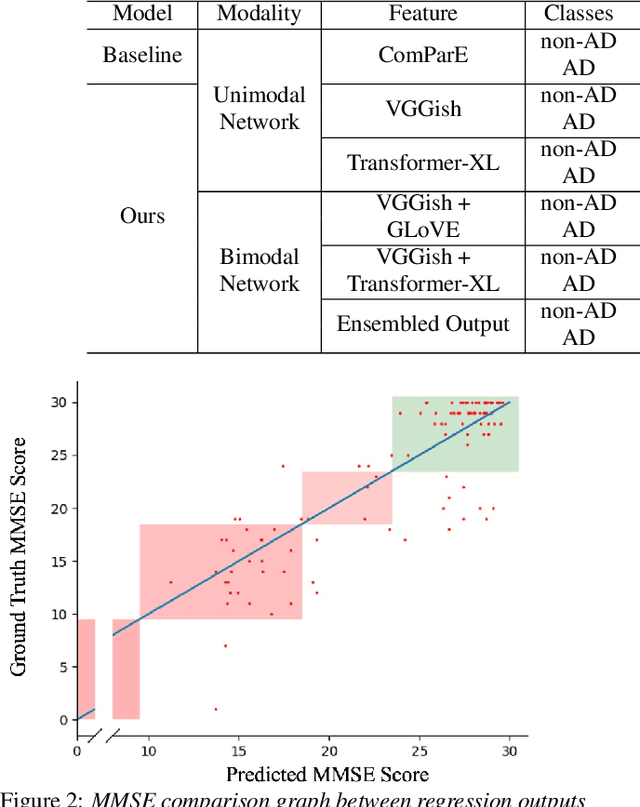
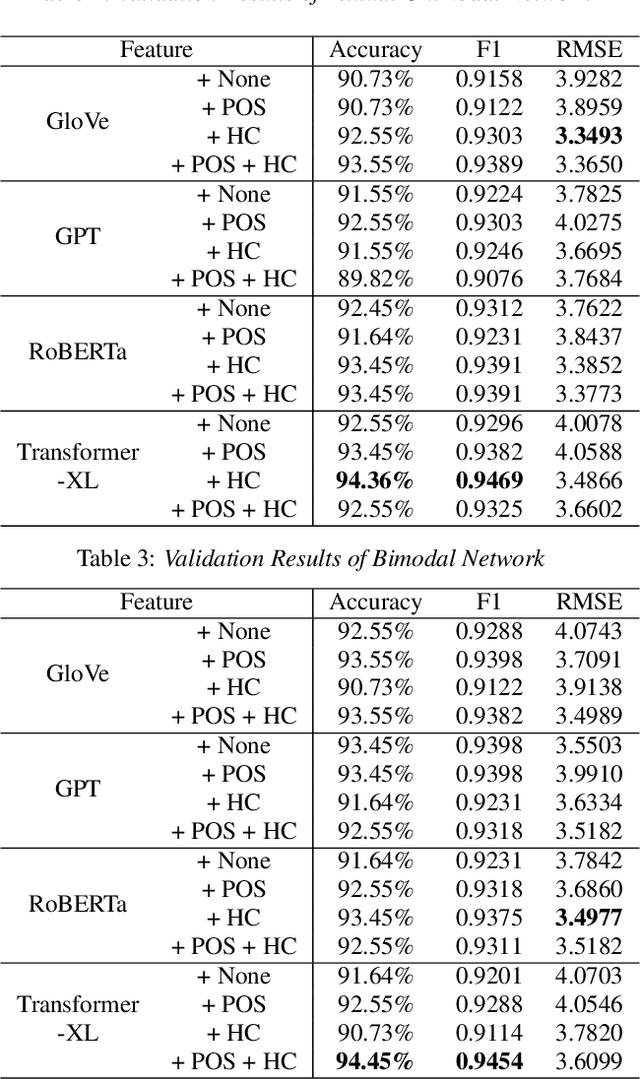
Collecting and accessing a large amount of medical data is very time-consuming and laborious, not only because it is difficult to find specific patients but also because it is required to resolve the confidentiality of a patient's medical records. On the other hand, there are deep learning models, trained on easily collectible, large scale datasets such as Youtube or Wikipedia, offering useful representations. It could therefore be very advantageous to utilize the features from these pre-trained networks for handling a small amount of data at hand. In this work, we exploit various multi-modal features extracted from pre-trained networks to recognize Alzheimer's Dementia using a neural network, with a small dataset provided by the ADReSS Challenge at INTERSPEECH 2020. The challenge regards to discern patients suspicious of Alzheimer's Dementia by providing acoustic and textual data. With the multi-modal features, we modify a Convolutional Recurrent Neural Network based structure to perform classification and regression tasks simultaneously and is capable of computing conversations with variable lengths. Our test results surpass baseline's accuracy by 18.75%, and our validation result for the regression task shows the possibility of classifying 4 classes of cognitive impairment with an accuracy of 78.70%.
A Novel Machine Learning Method for Preference Identification
Oct 22, 2020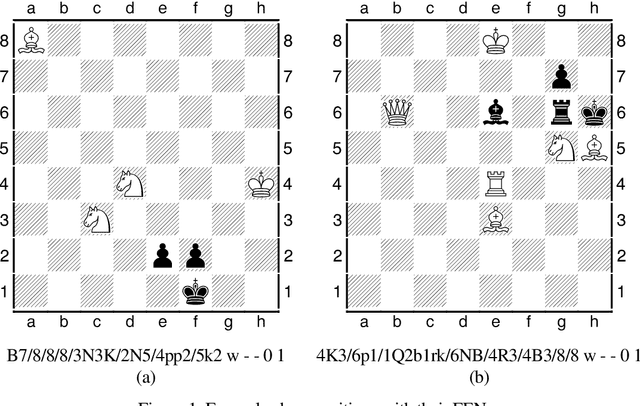
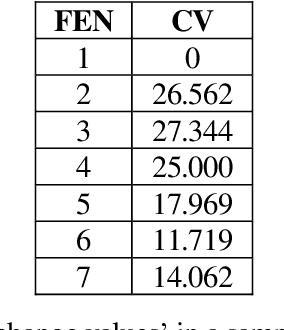
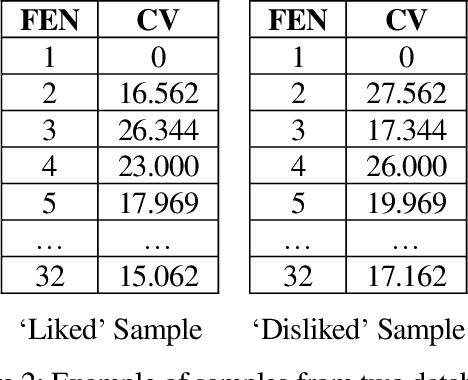
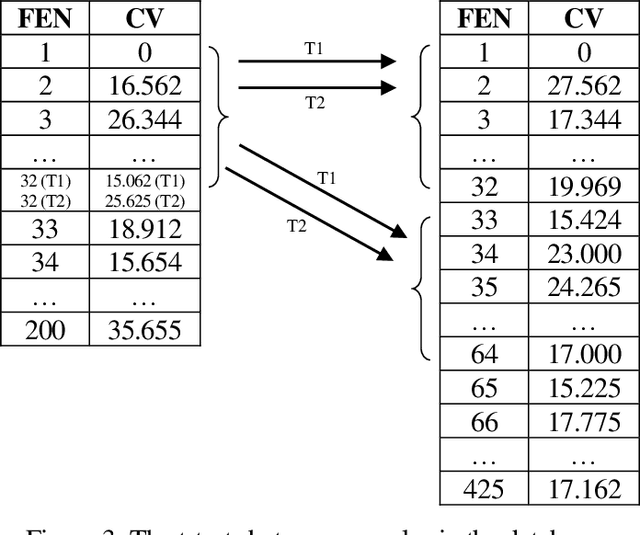
Human preference or taste within any domain is usually a difficult thing to identify or predict with high probability. In the domain of chess problem composition, the same is true. Traditional machine learning approaches tend to focus on the ability of computers to process massive amounts of data and continuously adjust 'weights' within an artificial neural network to better distinguish between say, two groups of objects. Contrasted with chess compositions, there is no clear distinction between what constitutes one and what does not; even less so between a good one and a poor one. We propose a computational method that is able to learn from existing databases of 'liked' and 'disliked' compositions such that a new and unseen collection can be sorted with increased probability of matching a solver's preferences. The method uses a simple 'change factor' relating to the Forsyth-Edwards Notation (FEN) of each composition's starting position, coupled with repeated statistical analysis of sample pairs from both databases. Tested using the author's own collections of computer-generated chess problems, the experimental results showed that the method was able to sort a new and unseen collection of compositions such that, on average, over 70% of the preferred compositions were in the top half of the collection. This saves significant time and energy on the part of solvers as they are likely to find more of what they like sooner. The method may even be applicable to other domains such as image processing because it does not rely on any chess-specific rules but rather just a sufficient and quantifiable 'change' in representation from one object to the next.