 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Finding Action Tubes with a Sparse-to-Dense Framework
Aug 30, 2020
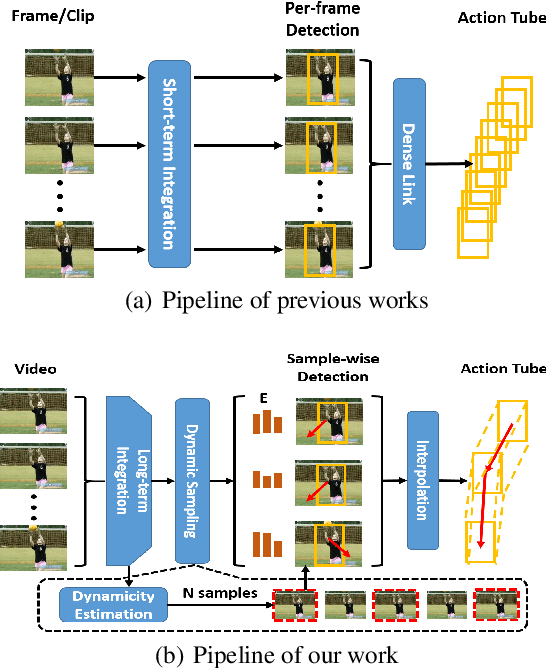

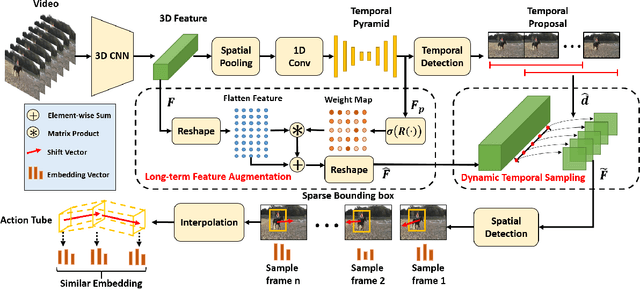
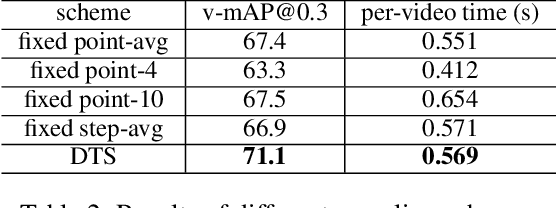
The task of spatial-temporal action detection has attracted increasing attention among researchers. Existing dominant methods solve this problem by relying on short-term information and dense serial-wise detection on each individual frames or clips. Despite their effectiveness, these methods showed inadequate use of long-term information and are prone to inefficiency. In this paper, we propose for the first time, an efficient framework that generates action tube proposals from video streams with a single forward pass in a sparse-to-dense manner. There are two key characteristics in this framework: (1) Both long-term and short-term sampled information are explicitly utilized in our spatiotemporal network, (2) A new dynamic feature sampling module (DTS) is designed to effectively approximate the tube output while keeping the system tractable. We evaluate the efficacy of our model on the UCF101-24, JHMDB-21 and UCFSports benchmark datasets, achieving promising results that are competitive to state-of-the-art methods. The proposed sparse-to-dense strategy rendered our framework about 7.6 times more efficient than the nearest competitor.
Bayesian geoacoustic inversion using mixture density network
Aug 18, 2020
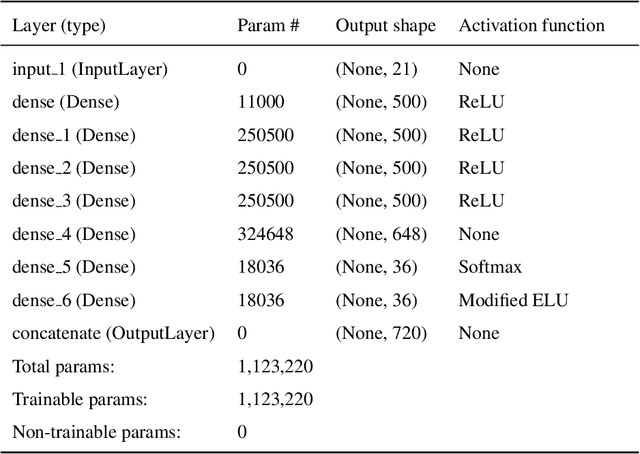
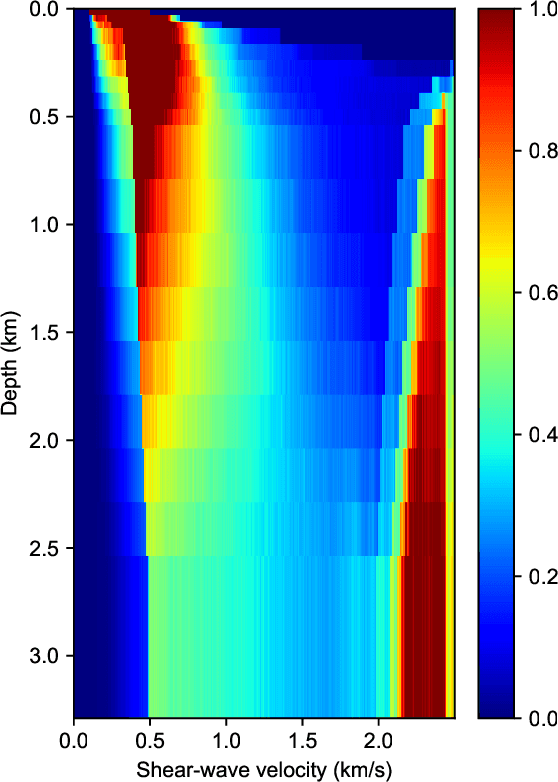
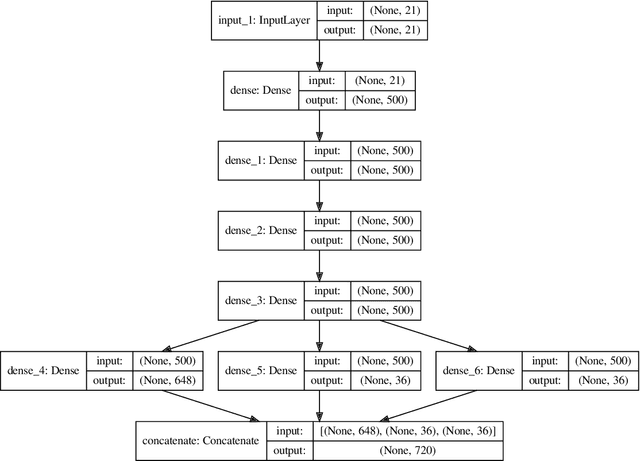
Bayesian geoacoustic inversion problems are conventionally solved by Markov chain Monte Carlo methods or its variants, which are computationally expensive. This paper extends the classic Bayesian geoacoustic inversion framework using the mixture density network (MDN), which provides a much more efficient way to solve geoacoustic inversion problems in Bayesian inference framework. Some important geoacoustic statistics of Bayesian geoacoustic inversion are derived from the multidimensional posterior probability density (PPD) using the MDN theory. These statistics make it convenient to train the network directly on the whole parameter space and get the multidimensional PPD of model parameters. The network is trained on a simulated dataset of surface-wave dispersion curves with shear-wave velocities as labels. The results show that the network gives reliable predictions and has good generalization performance on unseen data. Once trained, the network can rapidly (within seconds) give a fully probabilistic solution which is comparable to Monte Carlo methods. It provides an promissing approach for real-time inversion.
A novel control mode of bionic morphing tail based on deep reinforcement learning
Oct 08, 2020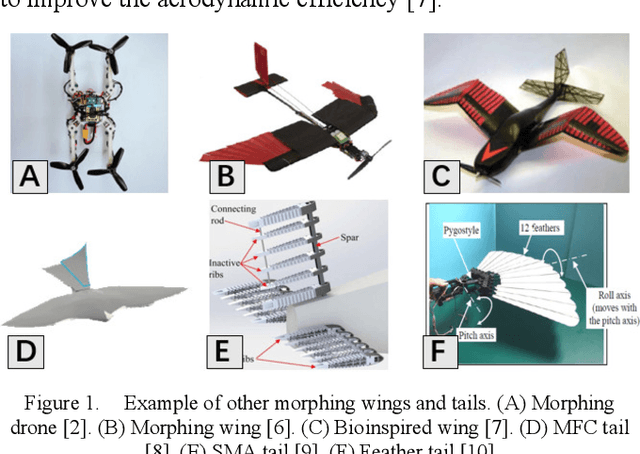
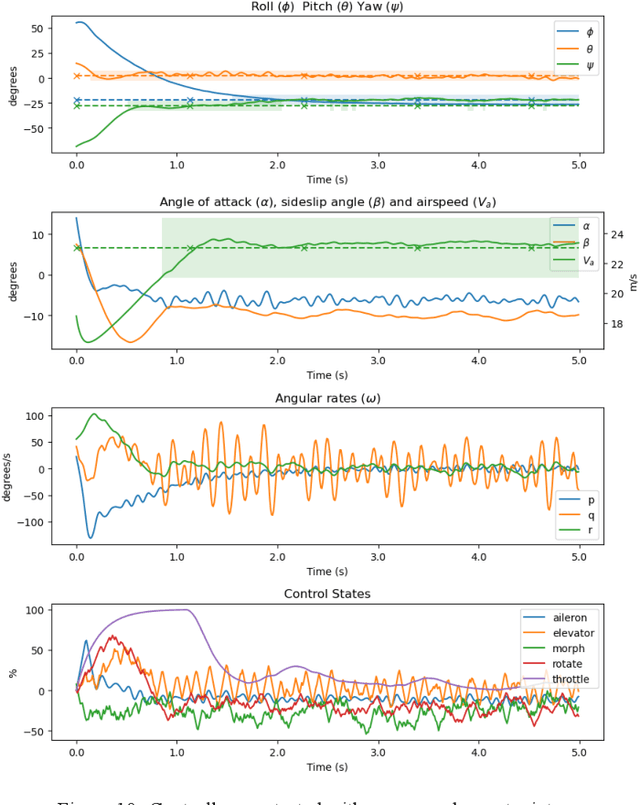
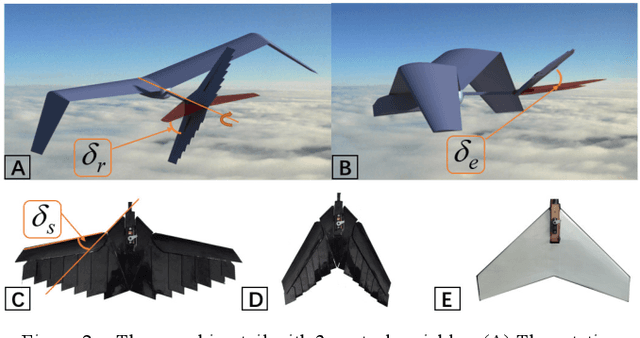
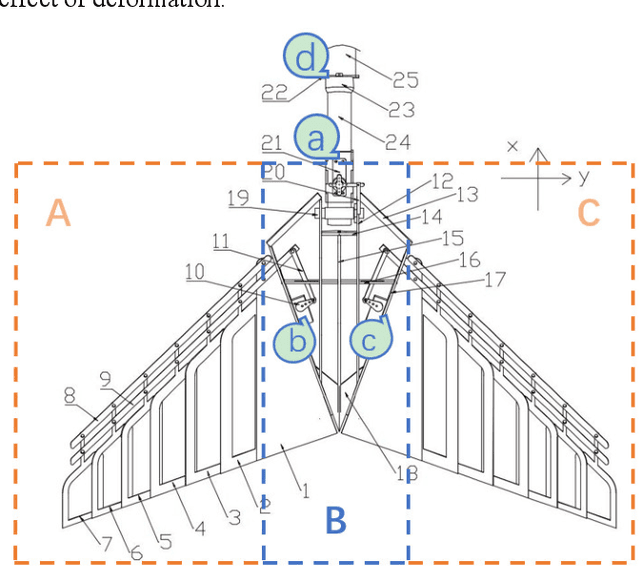
In the field of fixed wing aircraft, many morphing technologies have been applied to the wing, such as adaptive airfoil, variable span aircraft, variable swept angle aircraft, etc., but few are aimed at the tail. The traditional fixed wing tail includes horizontal and vertical tail. Inspired by the bird tail, this paper will introduce a new bionic tail. The tail has a novel control mode, which has multiple control variables. Compared with the traditional fixed wing tail, it adds the area control and rotation control around the longitudinal symmetry axis, so it can control the pitch and yaw of the aircraft at the same time. When the area of the tail changes, the maneuverability and stability of the aircraft can be changed, and the aerodynamic efficiency of the aircraft can also be improved. The aircraft with morphing ability is often difficult to establish accurate mathematical model, because the model has a strong nonlinear, model-based control method is difficult to deal with the strong nonlinear aircraft. In recent years, with the rapid development of artificial intelligence technology, learning based control methods are also brilliant, in which the deep reinforcement learning algorithm can be a good solution to the control object which is difficult to establish model. In this paper, the model-free control algorithm PPO is used to control the tail, and the traditional PID is used to control the aileron and throttle. After training in simulation, the tail shows excellent attitude control ability.
State Action Separable Reinforcement Learning
Jun 05, 2020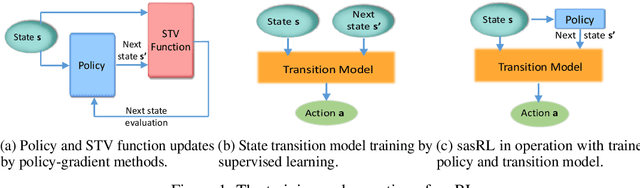
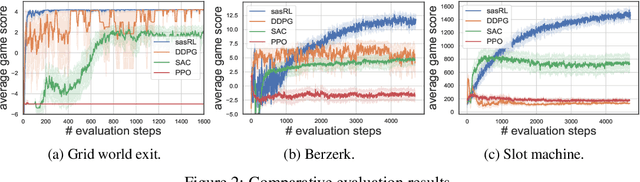
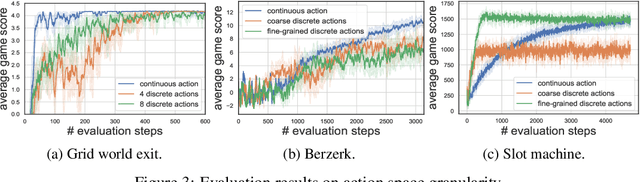
Reinforcement Learning (RL) based methods have seen their paramount successes in solving serial decision-making and control problems in recent years. For conventional RL formulations, Markov Decision Process (MDP) and state-action-value function are the basis for the problem modeling and policy evaluation. However, several challenging issues still remain. Among most cited issues, the enormity of state/action space is an important factor that causes inefficiency in accurately approximating the state-action-value function. We observe that although actions directly define the agents' behaviors, for many problems the next state after a state transition matters more than the action taken, in determining the return of such a state transition. In this regard, we propose a new learning paradigm, State Action Separable Reinforcement Learning (sasRL), wherein the action space is decoupled from the value function learning process for higher efficiency. Then, a light-weight transition model is learned to assist the agent to determine the action that triggers the associated state transition. In addition, our convergence analysis reveals that under certain conditions, the convergence time of sasRL is $O(T^{1/k})$, where $T$ is the convergence time for updating the value function in the MDP-based formulation and $k$ is a weighting factor. Experiments on several gaming scenarios show that sasRL outperforms state-of-the-art MDP-based RL algorithms by up to $75\%$.
Self-supervised Sparse to Dense Motion Segmentation
Aug 18, 2020



Observable motion in videos can give rise to the definition of objects moving with respect to the scene. The task of segmenting such moving objects is referred to as motion segmentation and is usually tackled either by aggregating motion information in long, sparse point trajectories, or by directly producing per frame dense segmentations relying on large amounts of training data. In this paper, we propose a self supervised method to learn the densification of sparse motion segmentations from single video frames. While previous approaches towards motion segmentation build upon pre-training on large surrogate datasets and use dense motion information as an essential cue for the pixelwise segmentation, our model does not require pre-training and operates at test time on single frames. It can be trained in a sequence specific way to produce high quality dense segmentations from sparse and noisy input. We evaluate our method on the well-known motion segmentation datasets FBMS59 and DAVIS16.
Data-Driven Open Set Fault Classification and Fault Size Estimation Using Quantitative Fault Diagnosis Analysis
Sep 10, 2020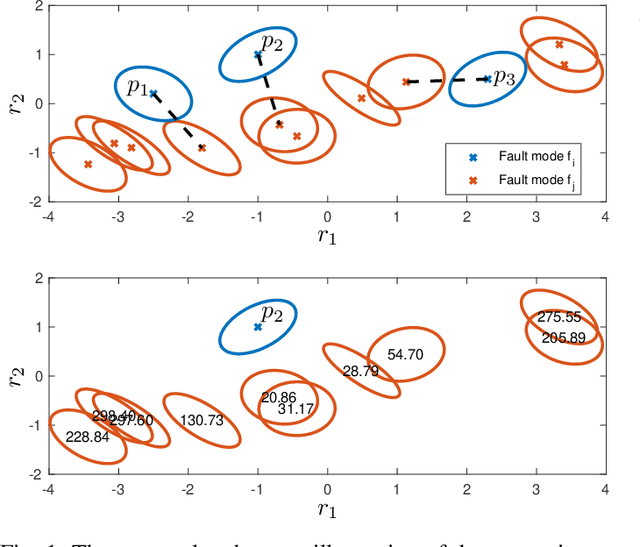
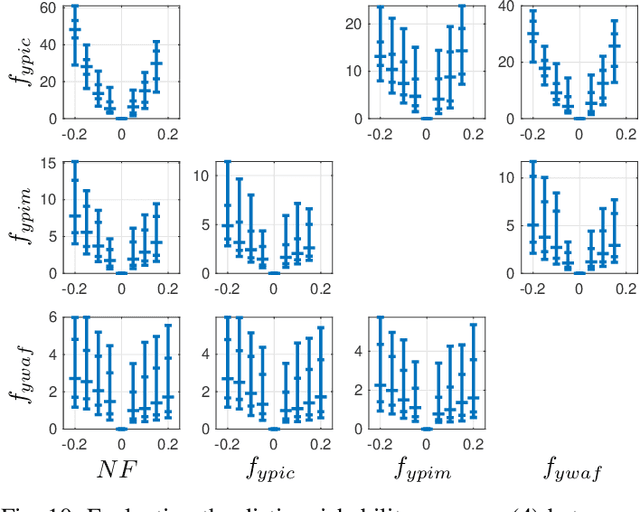
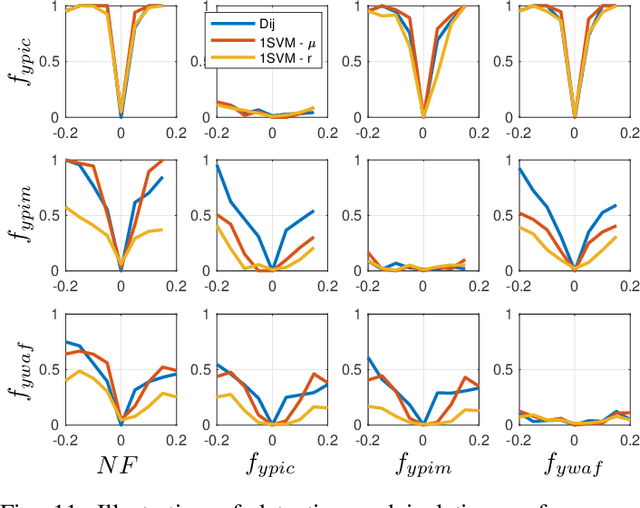
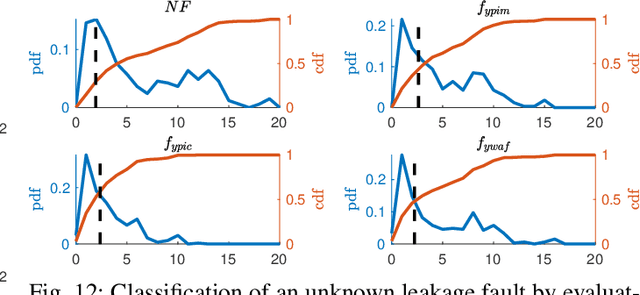
Data-driven fault classification is complicated by imbalanced training data and unknown fault classes. Fault diagnosis of dynamic systems is done by detecting changes in time-series data, for example residuals, caused by faults or system degradation. Different fault classes can result in similar residual outputs, especially for small faults which can be difficult to distinguish from nominal system operation. Analyzing how easy it is to distinguish data from different fault classes is crucial during the design process of a diagnosis system to evaluate if classification performance requirements can be met. Here, a data-driven model of different fault classes is used based on the Kullback-Leibler divergence. This is used to develop a framework for quantitative fault diagnosis performance analysis and open set fault classification. A data-driven fault classification algorithm is proposed which can handle unknown faults and also estimate the fault size using training data from known fault scenarios. To illustrate the usefulness of the proposed methods, data have been collected from an engine test bench to illustrate the design process of a data-driven diagnosis system, including quantitative fault diagnosis analysis and evaluation of the developed open set fault classification algorithm.
Asymmetric Loss For Multi-Label Classification
Sep 29, 2020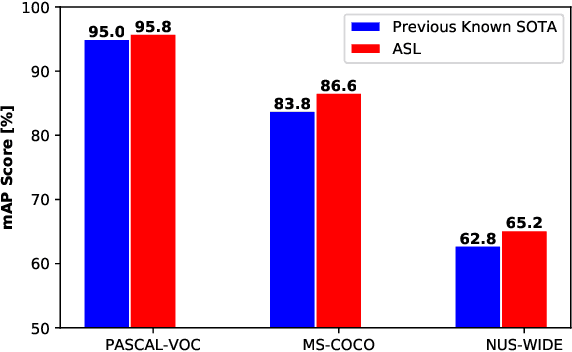
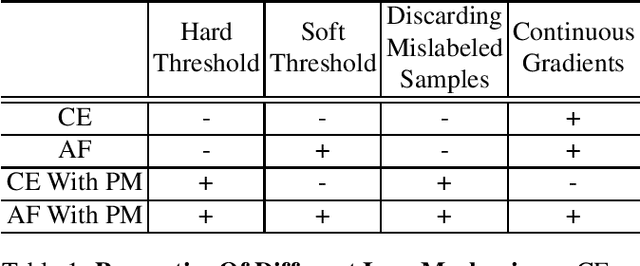
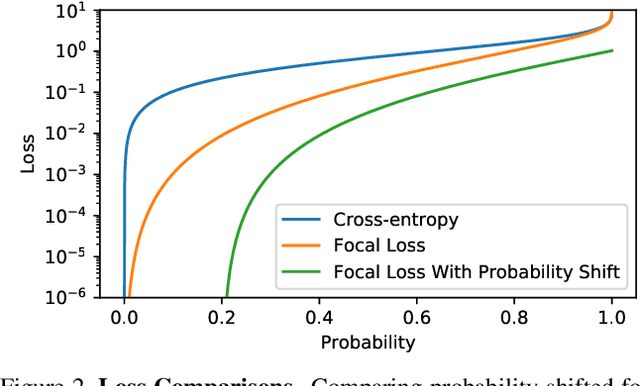
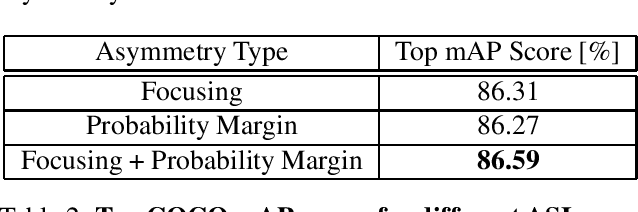
Pictures of everyday life are inherently multi-label in nature. Hence, multi-label classification is commonly used to analyze their content. In typical multi-label datasets, each picture contains only a few positive labels, and many negative ones. This positive-negative imbalance can result in under-emphasizing gradients from positive labels during training, leading to poor accuracy. In this paper, we introduce a novel asymmetric loss ("ASL"), that operates differently on positive and negative samples. The loss dynamically down-weights the importance of easy negative samples, causing the optimization process to focus more on the positive samples, and also enables to discard mislabeled negative samples. We demonstrate how ASL leads to a more "balanced" network, with increased average probabilities for positive samples, and show how this balanced network is translated to better mAP scores, compared to commonly used losses. Furthermore, we offer a method that can dynamically adjust the level of asymmetry throughout the training. With ASL, we reach new state-of-the-art results on three common multi-label datasets, including achieving 86.6% on MS-COCO. We also demonstrate ASL applicability for other tasks such as fine-grain single-label classification and object detection. ASL is effective, easy to implement, and does not increase the training time or complexity. Implementation is available at: https://github.com/Alibaba-MIIL/ASL.
Rotated Binary Neural Network
Sep 29, 2020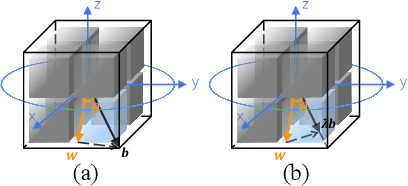
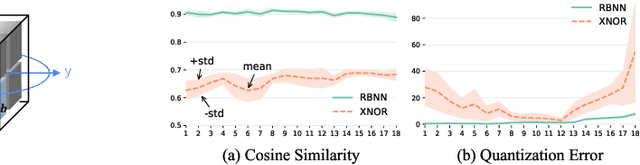
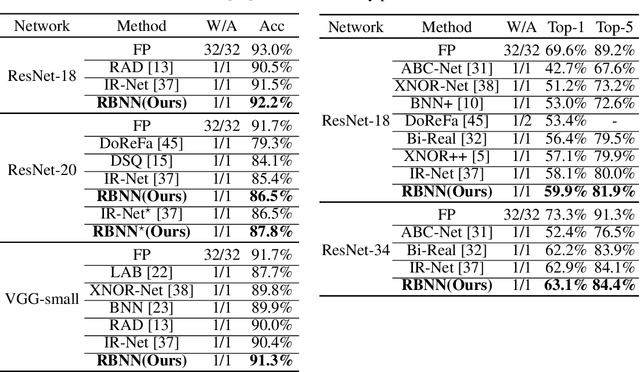
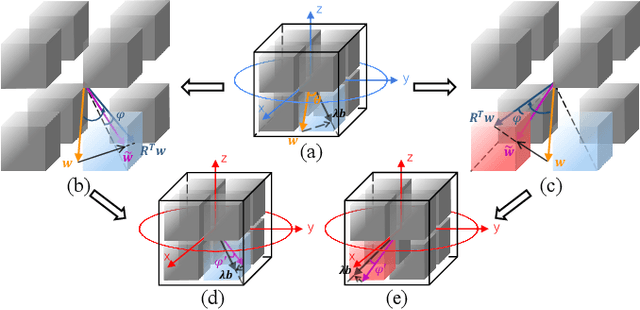
Binary Neural Network (BNN) shows its predominance in reducing the complexity of deep neural networks. However, it suffers severe performance degradation. One of the major impediments is the large quantization error between the full-precision weight vector and its binary vector. Previous works focus on compensating for the norm gap while leaving the angular bias hardly touched. In this paper, for the first time, we explore the influence of angular bias on the quantization error and then introduce a Rotated Binary Neural Network (RBNN), which considers the angle alignment between the full-precision weight vector and its binarized version. At the beginning of each training epoch, we propose to rotate the full-precision weight vector to its binary vector to reduce the angular bias. To avoid the high complexity of learning a large rotation matrix, we further introduce a bi-rotation formulation that learns two smaller rotation matrices. In the training stage, we devise an adjustable rotated weight vector for binarization to escape the potential local optimum. Our rotation leads to around 50% weight flips which maximize the information gain. Finally, we propose a training-aware approximation of the sign function for the gradient backward. Experiments on CIFAR-10 and ImageNet demonstrate the superiorities of RBNN over many state-of-the-arts. Our source code, experimental settings, training logs and binary models are available at https://github.com/lmbxmu/RBNN.
The Greedy Miser: Learning under Test-time Budgets
Jun 27, 2012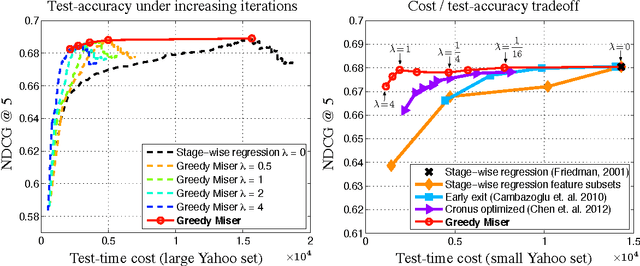
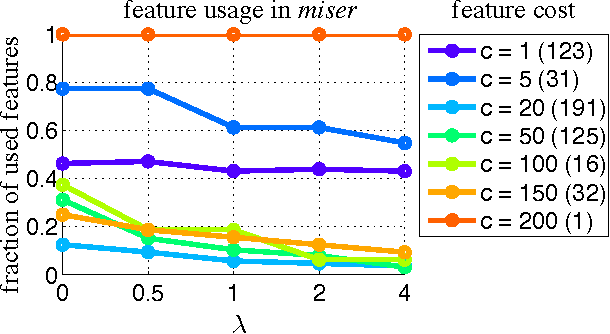
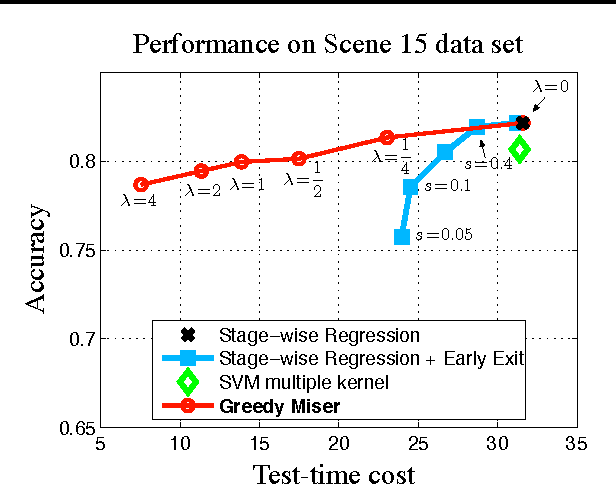

As machine learning algorithms enter applications in industrial settings, there is increased interest in controlling their cpu-time during testing. The cpu-time consists of the running time of the algorithm and the extraction time of the features. The latter can vary drastically when the feature set is diverse. In this paper, we propose an algorithm, the Greedy Miser, that incorporates the feature extraction cost during training to explicitly minimize the cpu-time during testing. The algorithm is a straightforward extension of stage-wise regression and is equally suitable for regression or multi-class classification. Compared to prior work, it is significantly more cost-effective and scales to larger data sets.
Optimal HDR and Depth from Dual Cameras
Mar 12, 2020
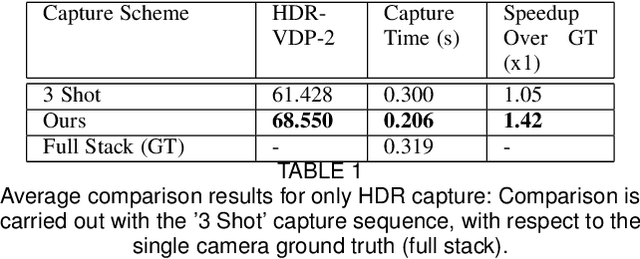
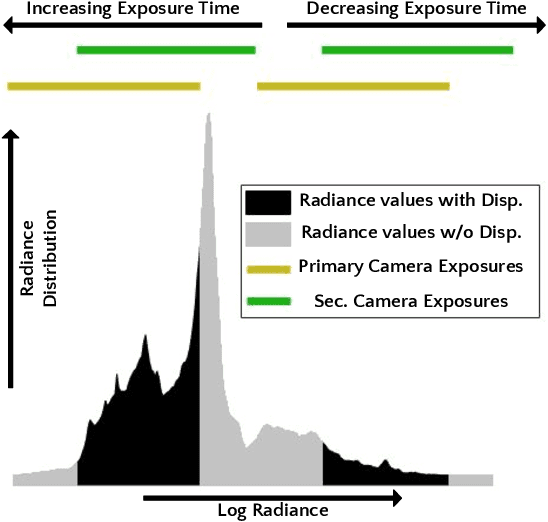
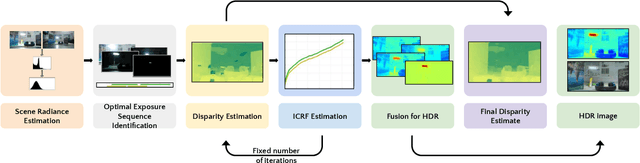
Dual camera systems have assisted in the proliferation of various applications, such as optical zoom, low-light imaging and High Dynamic Range (HDR) imaging. In this work, we explore an optimal method for capturing the scene HDR and disparity map using dual camera setups. Hasinoff et al. (2010) have developed a noise optimal framework for HDR capture from a single camera. We generalize this to the dual camera set-up for estimating both HDR and disparity map. It may seem that dual camera systems can capture HDR in a shorter time. However, disparity estimation is a necessary step, which requires overlap among the images captured by the two cameras. This may lead to an increase in the capture time. To address this conflicting requirement, we propose a novel framework to find the optimal exposure and ISO sequence by minimizing the capture time under the constraints of an upper bound on the disparity error and a lower bound on the per-exposure SNR. We show that the resulting optimization problem is non-convex in general and propose an appropriate initialization technique. To obtain the HDR and disparity map from the optimal capture sequence, we propose a pipeline which alternates between estimating the camera ICRFs and the scene disparity map. We demonstrate that our optimal capture sequence leads to better results than other possible capture sequences. Our results are also close to those obtained by capturing the full stereo stack spanning the entire dynamic range. Finally, we present for the first time a stereo HDR dataset consisting of dense ISO and exposure stack captured from a smartphone dual camera. The dataset consists of 6 scenes, with an average of 142 exposure-ISO image sequence per scene.