 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Experimental Study of Weight Initialization and Weight Inheritance Effects on Neuroevolution
Sep 21, 2020
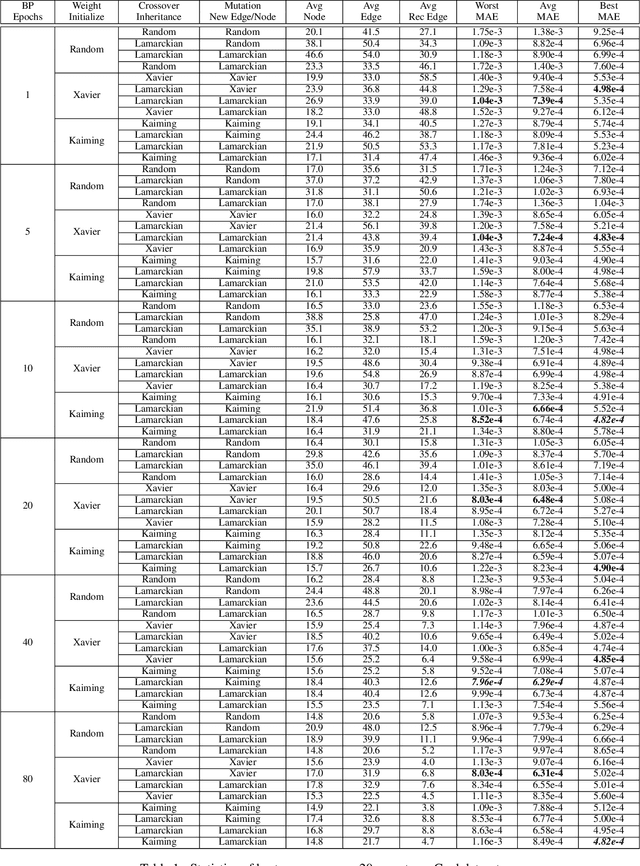
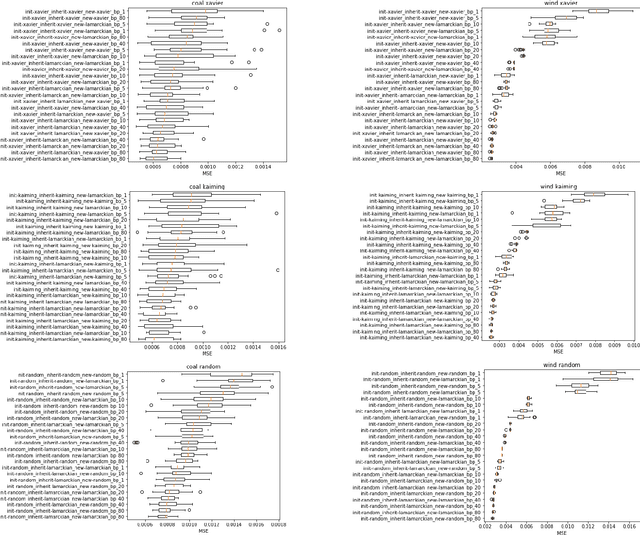
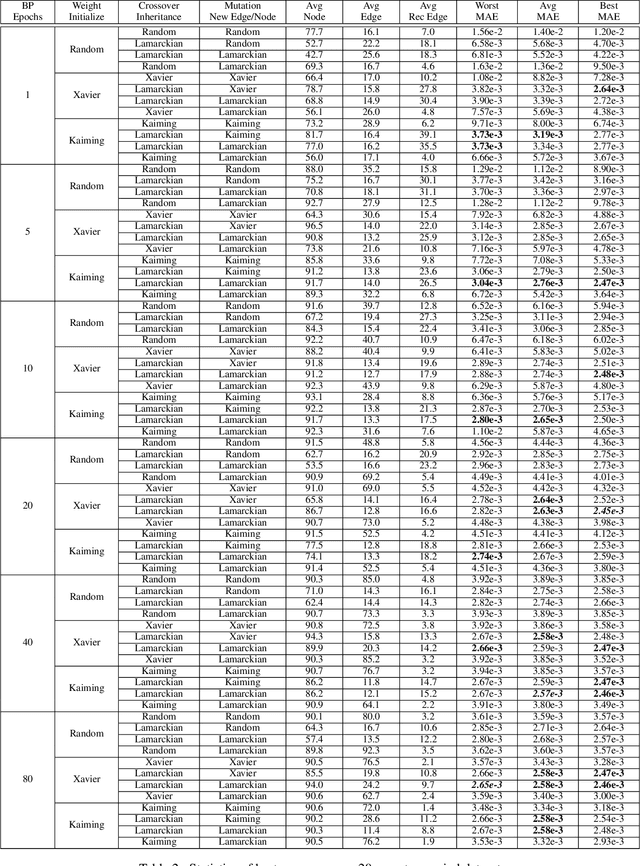
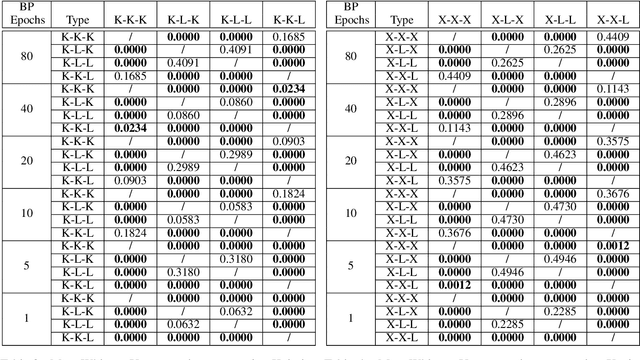
Weight initialization is critical in being able to successfully train artificial neural networks (ANNs), and even more so for recurrent neural networks (RNNs) which can easily suffer from vanishing and exploding gradients. In neuroevolution, where evolutionary algorithms are applied to neural architecture search, weights typically need to be initialized at three different times: when initial genomes (ANN architectures) are created at the beginning of the search, when offspring genomes are generated by crossover, and when new nodes or edges are created during mutation. This work explores the difference between using Xavier, Kaiming, and uniform random weight initialization methods, as well as novel Lamarckian weight inheritance methods for initializing new weights during crossover and mutation operations. These are examined using the Evolutionary eXploration of Augmenting Memory Models (EXAMM) neuroevolution algorithm, which is capable of evolving RNNs with a variety of modern memory cells (e.g., LSTM, GRU, MGU, UGRNN and Delta-RNN cells) as well recurrent connections with varying time skips through a high performance island based distributed evolutionary algorithm. Results show that with statistical significance, utilizing the Lamarckian strategies outperforms Kaiming, Xavier and uniform random weight initialization, and can speed neuroevolution by requiring less backpropagation epochs to be evaluated for each generated RNN.
RTFE: A Recursive Temporal Fact Embedding Framework for Temporal Knowledge Graph Completion
Sep 30, 2020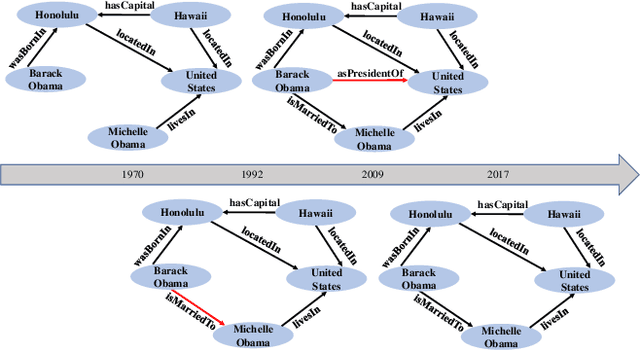
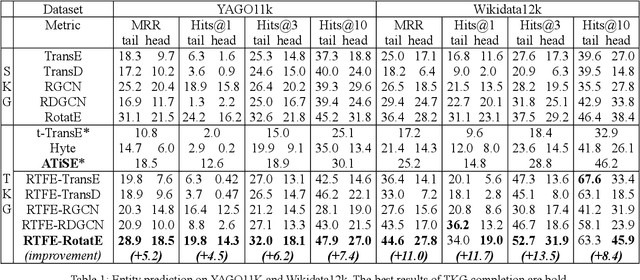

In recent years, many efforts have been made to complete knowledge graphs (KGs) by various graph embedding methods, most of which only focus on static KGs (SKGs) without considering the time dependency of facts. However, KGs in reality are dynamic and there exists correlations between facts with different timestamps. Due to the sparsity of temporal KGs (TKGs), SKG embedding methods cannot be directly applied to TKGs. And existing methods of TKG embedding suffer from two issues: (1) they follow the pattern of SKG embedding where all facts need to be retrained when a new timestamp appears; (2) they don't provide a general way to transplant SKG embedding methods to TKGs and therefore lack extensibility. In this paper, we propose a novel Recursive Temporal Fact Embedding Framework (RTFE) to transplant translation-based or graph neural network-based SKG embedding methods to TKGs. In the recursive way, timestamp parameters provide a good starting point for the next future timestamp. And existing SKG embedding models can be used as components. Experiments on TKGs show that our proposed framework (1) outperforms the state-of-the-art baseline model in the entity prediction task on fact datasets; (2) achieves similar performance compared with the state-of-the-art baseline model in relation prediction task on fact datasets; and (3) shows performance in the entity prediction task on event datasets.
Spectral Analysis Network for Deep Representation Learning and Image Clustering
Sep 11, 2020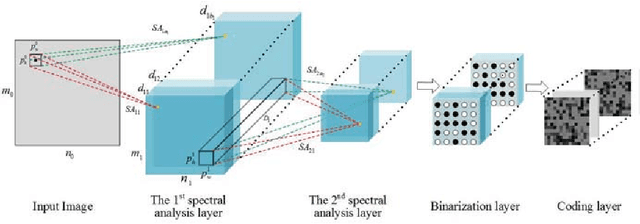
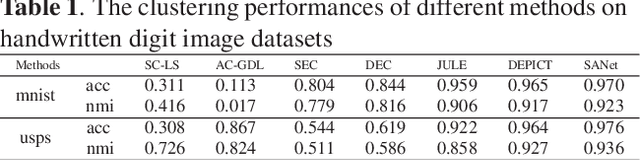

Deep representation learning is a crucial procedure in multimedia analysis and attracts increasing attention. Most of the popular techniques rely on convolutional neural network and require a large amount of labeled data in the training procedure. However, it is time consuming or even impossible to obtain the label information in some tasks due to cost limitation. Thus, it is necessary to develop unsupervised deep representation learning techniques. This paper proposes a new network structure for unsupervised deep representation learning based on spectral analysis, which is a popular technique with solid theory foundations. Compared with the existing spectral analysis methods, the proposed network structure has at least three advantages. Firstly, it can identify the local similarities among images in patch level and thus more robust against occlusion. Secondly, through multiple consecutive spectral analysis procedures, the proposed network can learn more clustering-friendly representations and is capable to reveal the deep correlations among data samples. Thirdly, it can elegantly integrate different spectral analysis procedures, so that each spectral analysis procedure can have their individual strengths in dealing with different data sample distributions. Extensive experimental results show the effectiveness of the proposed methods on various image clustering tasks.
Solving Stochastic Compositional Optimization is Nearly as Easy as Solving Stochastic Optimization
Aug 31, 2020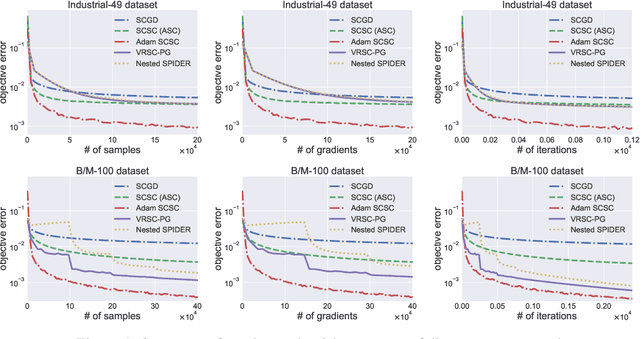
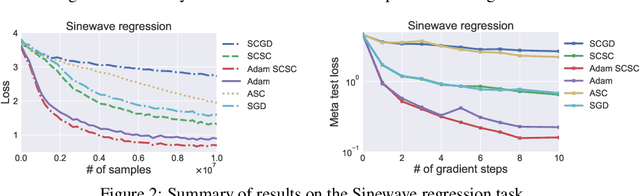
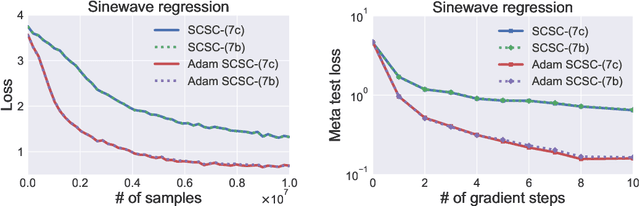
Stochastic compositional optimization generalizes classic (non-compositional) stochastic optimization to the minimization of compositions of functions. Each composition may introduce an additional expectation. The series of expectations may be nested. Stochastic compositional optimization is gaining popularity in applications such as reinforcement learning and meta learning. This paper presents a new Stochastically Corrected Stochastic Compositional gradient method (SCSC). SCSC runs in a single-time scale with a single loop, uses a fixed batch size, and guarantees to converge at the same rate as the stochastic gradient descent (SGD) method for non-compositional stochastic optimization. This is achieved by making a careful improvement to a popular stochastic compositional gradient method. It is easy to apply SGD-improvement techniques to accelerate SCSC. This helps SCSC achieve state-of-the-art performance for stochastic compositional optimization. In particular, we apply Adam to SCSC, and the exhibited rate of convergence matches that of the original Adam on non-compositional stochastic optimization. We test SCSC using the portfolio management and model-agnostic meta-learning tasks.
GraphTCN: Spatio-Temporal Interaction Modeling for Human Trajectory Prediction
Mar 16, 2020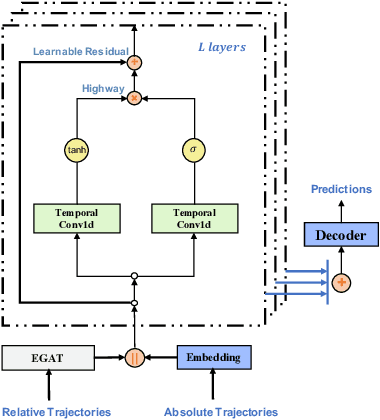
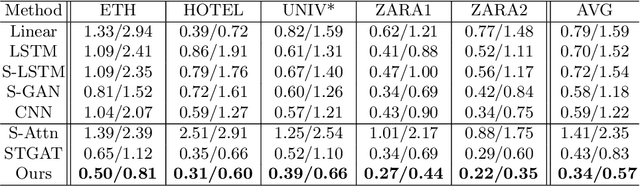

Trajectory prediction is a fundamental and challenging task to forecast the future path of the agents in autonomous applications with multi-agent interaction, where the agents need to predict the future movements of their neighbors to avoid collisions. To respond timely and precisely to the environment, high efficiency and accuracy are required in the prediction. Conventional approaches, e.g., LSTM-based models, take considerable computation costs in the prediction, especially for the long sequence prediction. To support a more efficient and accurate trajectory prediction, we instead propose a novel CNN-based spatial-temporal graph framework GraphTCN, which captures the spatial and temporal interactions in an input-aware manner. The spatial interaction between agents at each time step is captured with an edge graph attention network (EGAT), and the temporal interaction across time step is modeled with a modified gated convolutional network (CNN). In contrast to conventional models, both the spatial and temporal modeling in GraphTCN are computed within each local time window. Therefore, GraphTCN can be executed in parallel for much higher efficiency, and meanwhile with accuracy comparable to best-performing approaches. Experimental results confirm that GraphTCN achieves noticeably better performance in terms of both efficiency and accuracy compared with state-of-the-art methods on various trajectory prediction benchmark datasets.
Direct Adversarial Training for GANs
Aug 19, 2020
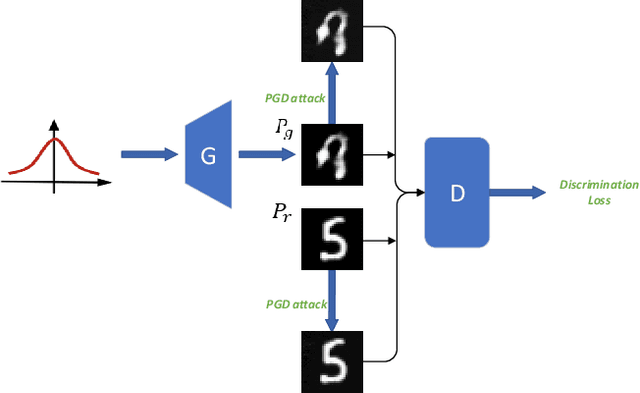
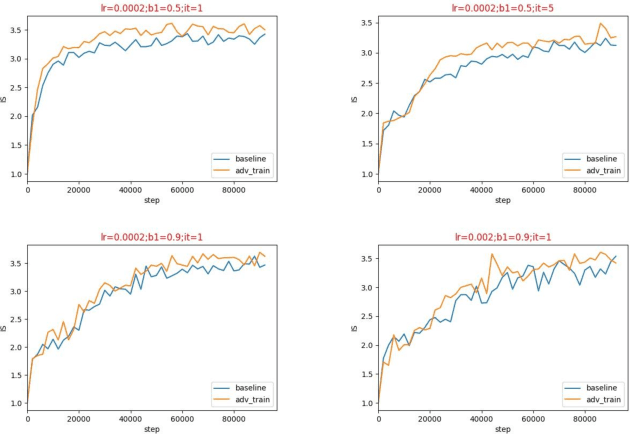
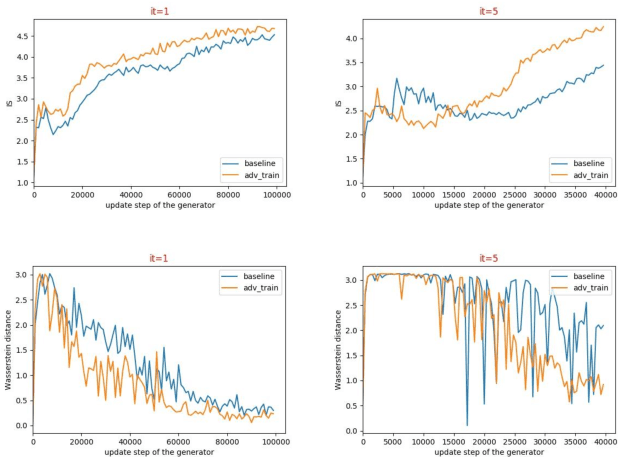
There is an interesting discovery that several neural networks are vulnerable to adversarial examples. That is, many machines learning models misclassify the samples with only a little change which will not be noticed by human eyes. Generative adversarial networks (GANs) are the most popular models for image generation by jointly optimizing discriminator and generator. With stability train, some regularization and normalization have been used to let the discriminator satisfy Lipschitz consistency. In this paper, we have analyzed that the generator may produce adversarial examples for discriminator during the training process, which may cause the unstable training of GANs. For this reason, we propose a direct adversarial training method for GANs. At the same time, we prove that this direct adversarial training can limit the lipschitz constant of the discriminator and accelerate the convergence of the generator. We have verified the advanced performs of the method on multiple baseline networks, such as DCGAN, WGAN, WGAN-GP, and WGAN-LP.
CounteRGAN: Generating Realistic Counterfactuals with Residual Generative Adversarial Nets
Sep 11, 2020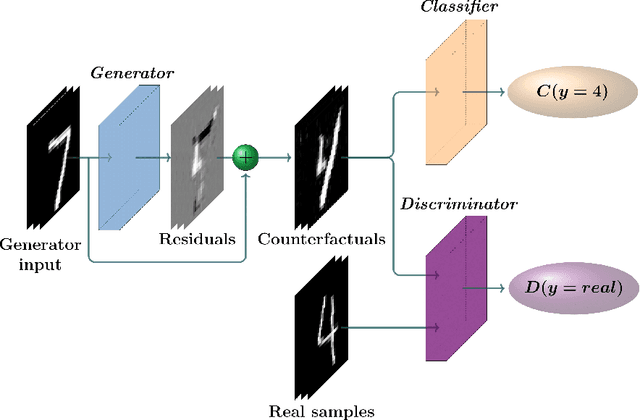
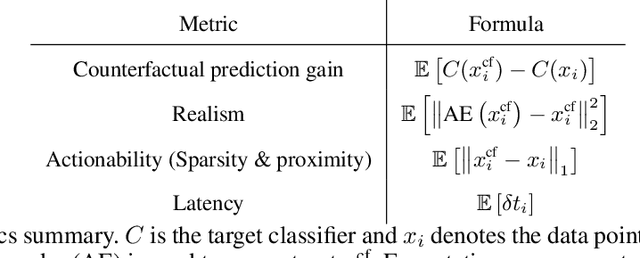
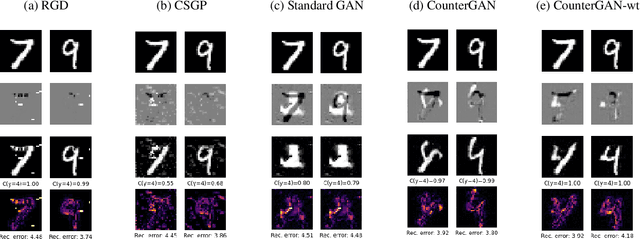
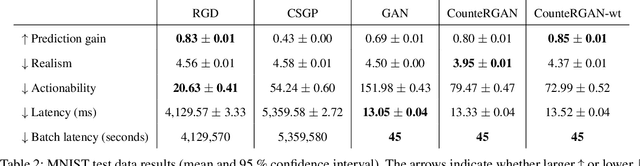
The prevalence of machine learning models in various industries has led to growing demands for model interpretability and for the ability to provide meaningful recourse to users. For example, patients hoping to improve their diagnoses or loan applicants seeking to increase their chances of approval. Counterfactuals can help in this regard by identifying input perturbations that would result in more desirable prediction outcomes. Meaningful counterfactuals should be able to achieve the desired outcome, but also be realistic, actionable, and efficient to compute. Current approaches achieve desired outcomes with moderate actionability but are severely limited in terms of realism and latency. To tackle these limitations, we apply Generative Adversarial Nets (GANs) toward counterfactual search. We also introduce a novel Residual GAN (RGAN) that helps to improve counterfactual realism and actionability compared to regular GANs. The proposed CounteRGAN method utilizes an RGAN and a target classifier to produce counterfactuals capable of providing meaningful recourse. Evaluations on two popular datasets highlight how the CounteRGAN is able to overcome the limitations of existing methods, including latency improvements of >50x to >90,000x, making meaningful recourse available in real-time and applicable to a wide range of domains.
Recurrent Neural Network Control of a Hybrid Dynamic Transfemoral Prosthesis with EdgeDRNN Accelerator
Mar 05, 2020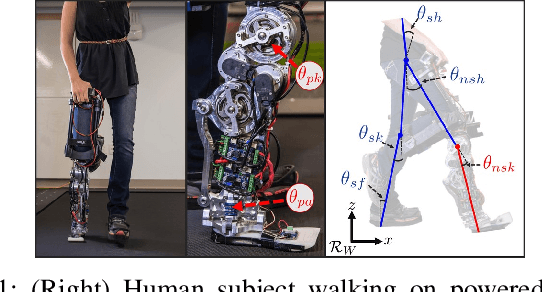
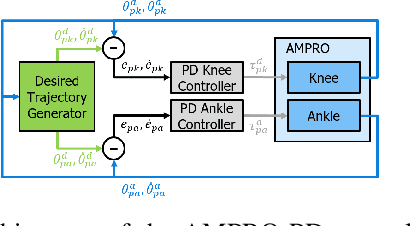
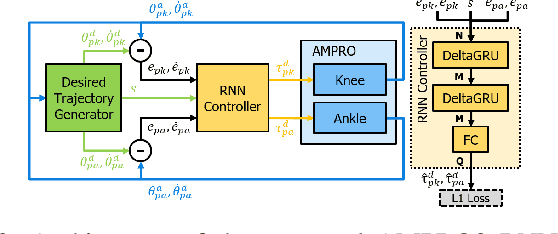
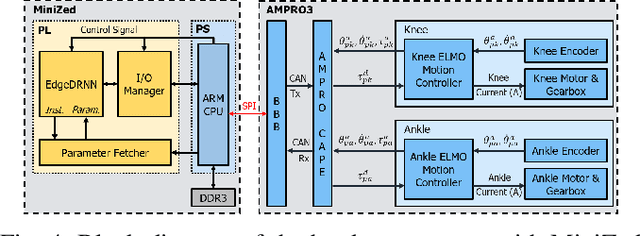
Lower leg prostheses could improve the life quality of amputees by increasing comfort and reducing energy to locomote, but currently control methods are limited in modulating behaviors based upon the human's experience. This paper describes the first steps toward learning complex controllers for dynamical robotic assistive devices. We provide the first example of behavioral cloning to control a powered transfemoral prostheses using a Gated Recurrent Unit (GRU) based recurrent neural network (RNN) running on a custom hardware accelerator that exploits temporal sparsity. The RNN is trained on data collected from the original prosthesis controller. The RNN inference is realized by a novel EdgeDRNN accelerator in real-time. Experimental results show that the RNN can replace the nominal PD controller to realize end-to-end control of the AMPRO3 prosthetic leg walking on flat ground and unforeseen slopes with comparable tracking accuracy. EdgeDRNN computes the RNN about 240 times faster than real time, opening the possibility of running larger networks for more complex tasks in the future. Implementing an RNN on this real-time dynamical system with impacts sets the ground work to incorporate other learned elements of the human-prosthesis system into prosthesis control.
Fully Convolutional Open Set Segmentation
Jun 25, 2020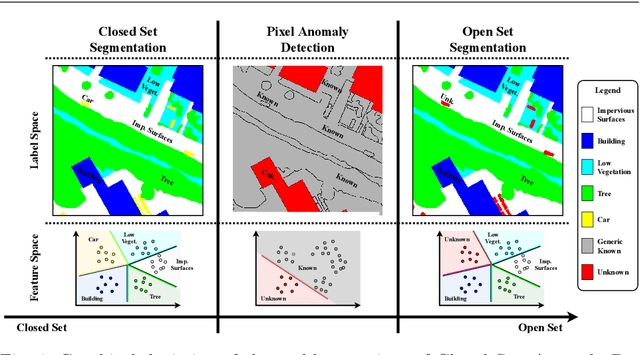
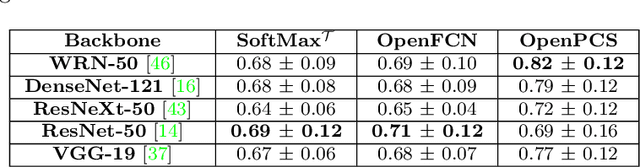
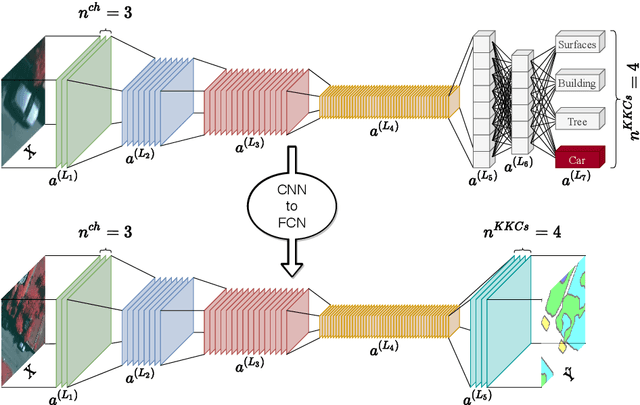
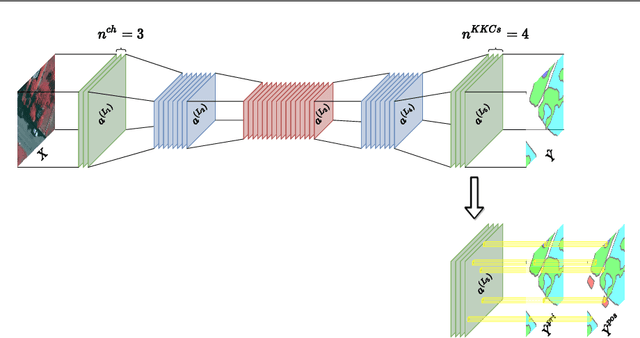
In semantic segmentation knowing about all existing classes is essential to yield effective results with the majority of existing approaches. However, these methods trained in a Closed Set of classes fail when new classes are found in the test phase. It means that they are not suitable for Open Set scenarios, which are very common in real-world computer vision and remote sensing applications. In this paper, we discuss the limitations of Closed Set segmentation and propose two fully convolutional approaches to effectively address Open Set semantic segmentation: OpenFCN and OpenPCS. OpenFCN is based on the well-known OpenMax algorithm, configuring a new application of this approach in segmentation settings. OpenPCS is a fully novel approach based on feature-space from DNN activations that serve as features for computing PCA and multi-variate gaussian likelihood in a lower dimensional space. Experiments were conducted on the well-known Vaihingen and Potsdam segmentation datasets. OpenFCN showed little-to-no improvement when compared to the simpler and much more time efficient SoftMax thresholding, while being between some orders of magnitude slower. OpenPCS achieved promising results in almost all experiments by overcoming both OpenFCN and SoftMax thresholding. OpenPCS is also a reasonable compromise between the runtime performances of the extremely fast SoftMax thresholding and the extremely slow OpenFCN, being close able to run close to real-time. Experiments also indicate that OpenPCS is effective, robust and suitable for Open Set segmentation, being able to improve the recognition of unknown class pixels without reducing the accuracy on the known class pixels.
Semi-supervised Semantic Segmentation of Organs at Risk on 3D Pelvic CT Images
Sep 21, 2020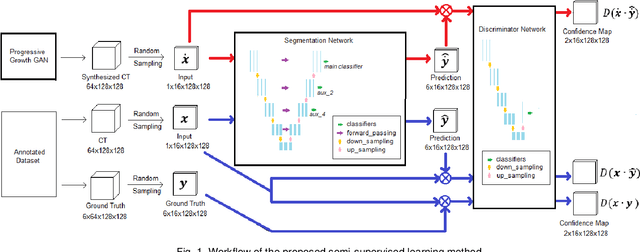

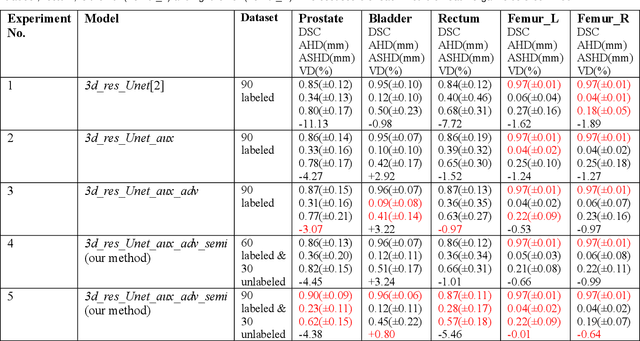
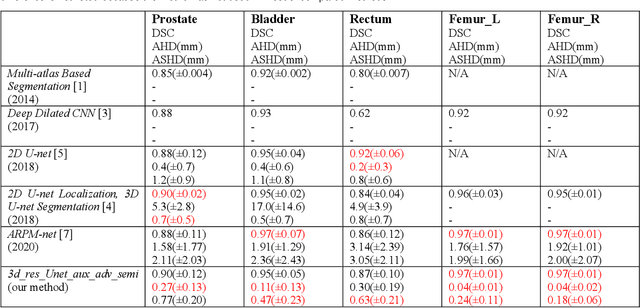
Automated segmentation of organs-at-risk in pelvic computed tomography (CT) images can assist the radiotherapy treatment planning by saving time and effort of manual contouring and reducing intra-observer and inter-observer variation. However, training high-performance deep-learning segmentation models usually requires broad labeled data, which are labor-intensive to collect. Lack of annotated data presents a significant challenge for many medical imaging-related deep learning solutions. This paper proposes a novel end-to-end convolutional neural network-based semi-supervised adversarial method that can segment multiple organs-at-risk, including prostate, bladder, rectum, left femur, and right femur. New design schemes are introduced to enhance the baseline residual U-net architecture to improve performance. Importantly, new unlabeled CT images are synthesized by a generative adversarial network (GAN) that is trained on given images to overcome the inherent problem of insufficient annotated data in practice. A semi-supervised adversarial strategy is then introduced to utilize labeled and unlabeled 3D CT images. The new method is evaluated on a dataset of 100 training cases and 20 testing cases. Experimental results, including four metrics (dice similarity coefficient, average Hausdorff distance, average surface Hausdorff distance, and relative volume difference), show that the new method outperforms several state-of-the-art segmentation approaches.