 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RTFE: A Recursive Temporal Fact Embedding Framework for Temporal Knowledge Graph Completion
Sep 30, 2020
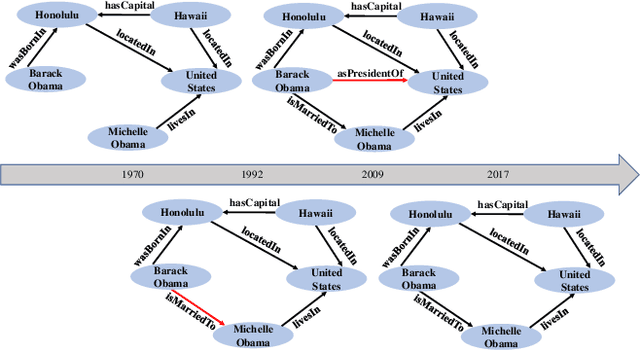
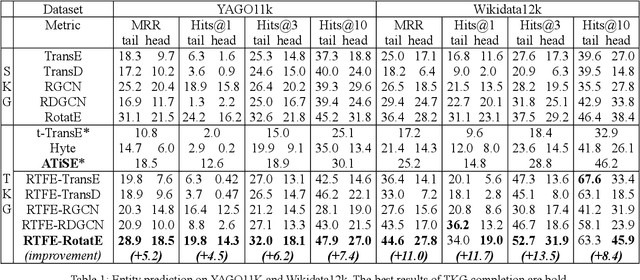
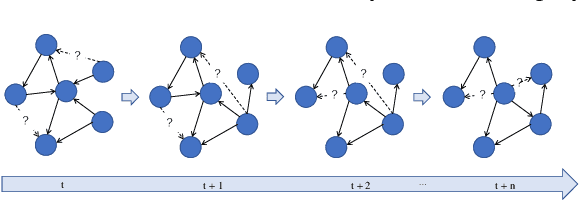

In recent years, many efforts have been made to complete knowledge graphs (KGs) by various graph embedding methods, most of which only focus on static KGs (SKGs) without considering the time dependency of facts. However, KGs in reality are dynamic and there exists correlations between facts with different timestamps. Due to the sparsity of temporal KGs (TKGs), SKG embedding methods cannot be directly applied to TKGs. And existing methods of TKG embedding suffer from two issues: (1) they follow the pattern of SKG embedding where all facts need to be retrained when a new timestamp appears; (2) they don't provide a general way to transplant SKG embedding methods to TKGs and therefore lack extensibility. In this paper, we propose a novel Recursive Temporal Fact Embedding Framework (RTFE) to transplant translation-based or graph neural network-based SKG embedding methods to TKGs. In the recursive way, timestamp parameters provide a good starting point for the next future timestamp. And existing SKG embedding models can be used as components. Experiments on TKGs show that our proposed framework (1) outperforms the state-of-the-art baseline model in the entity prediction task on fact datasets; (2) achieves similar performance compared with the state-of-the-art baseline model in relation prediction task on fact datasets; and (3) shows performance in the entity prediction task on event datasets.
A Experimental Study of Weight Initialization and Weight Inheritance Effects on Neuroevolution
Sep 21, 2020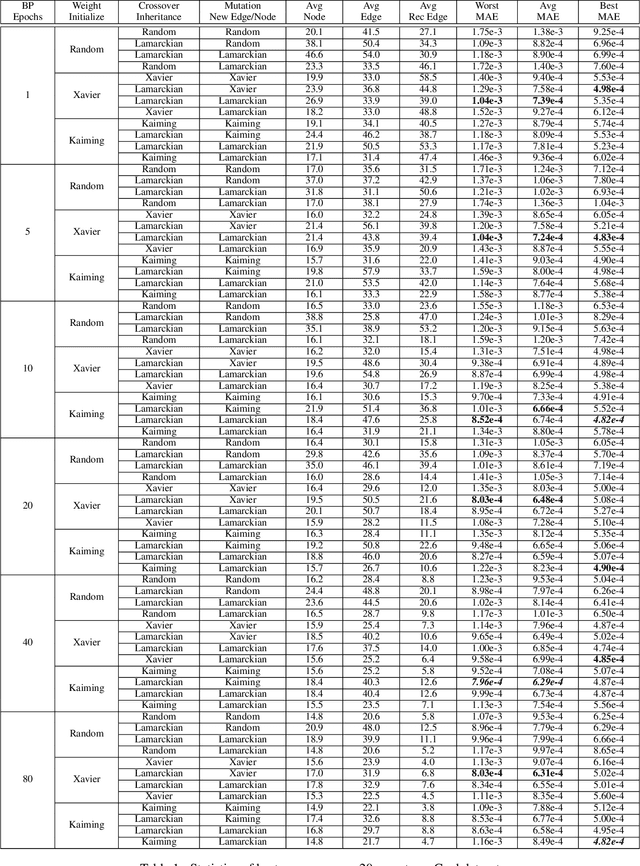
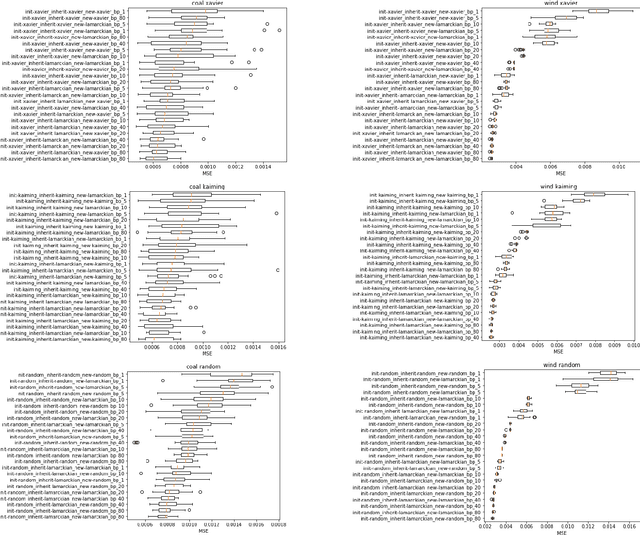
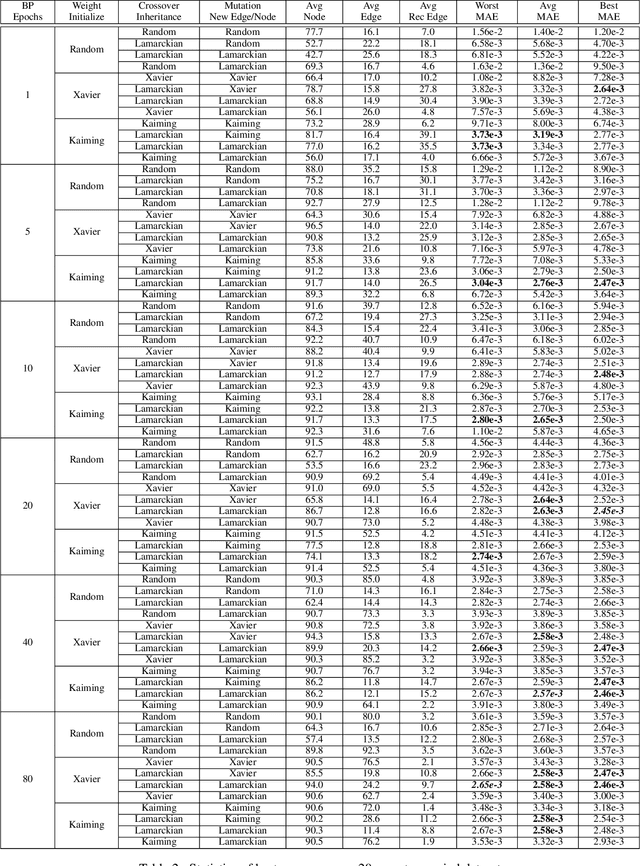
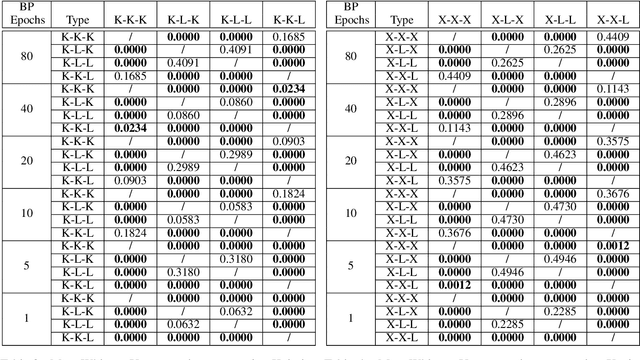
Weight initialization is critical in being able to successfully train artificial neural networks (ANNs), and even more so for recurrent neural networks (RNNs) which can easily suffer from vanishing and exploding gradients. In neuroevolution, where evolutionary algorithms are applied to neural architecture search, weights typically need to be initialized at three different times: when initial genomes (ANN architectures) are created at the beginning of the search, when offspring genomes are generated by crossover, and when new nodes or edges are created during mutation. This work explores the difference between using Xavier, Kaiming, and uniform random weight initialization methods, as well as novel Lamarckian weight inheritance methods for initializing new weights during crossover and mutation operations. These are examined using the Evolutionary eXploration of Augmenting Memory Models (EXAMM) neuroevolution algorithm, which is capable of evolving RNNs with a variety of modern memory cells (e.g., LSTM, GRU, MGU, UGRNN and Delta-RNN cells) as well recurrent connections with varying time skips through a high performance island based distributed evolutionary algorithm. Results show that with statistical significance, utilizing the Lamarckian strategies outperforms Kaiming, Xavier and uniform random weight initialization, and can speed neuroevolution by requiring less backpropagation epochs to be evaluated for each generated RNN.
Bayesian geoacoustic inversion using mixture density network
Aug 19, 2020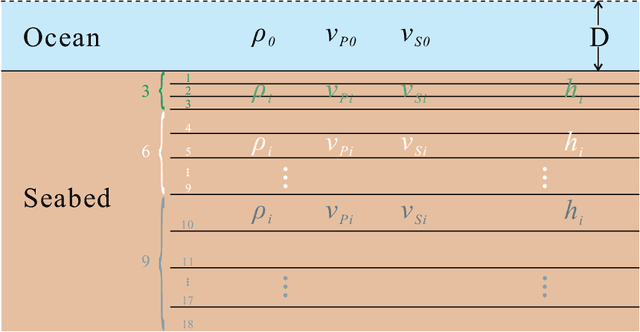
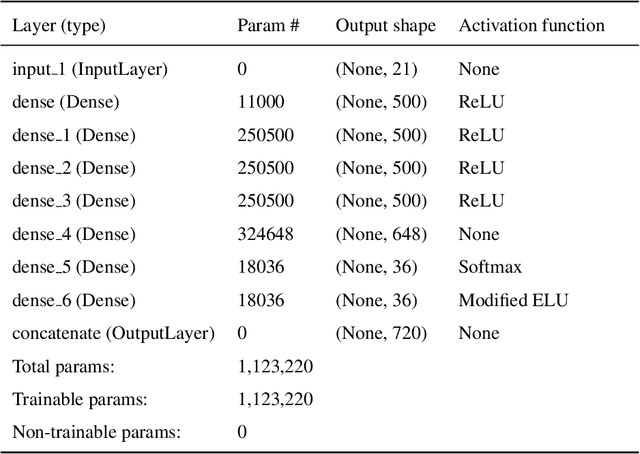
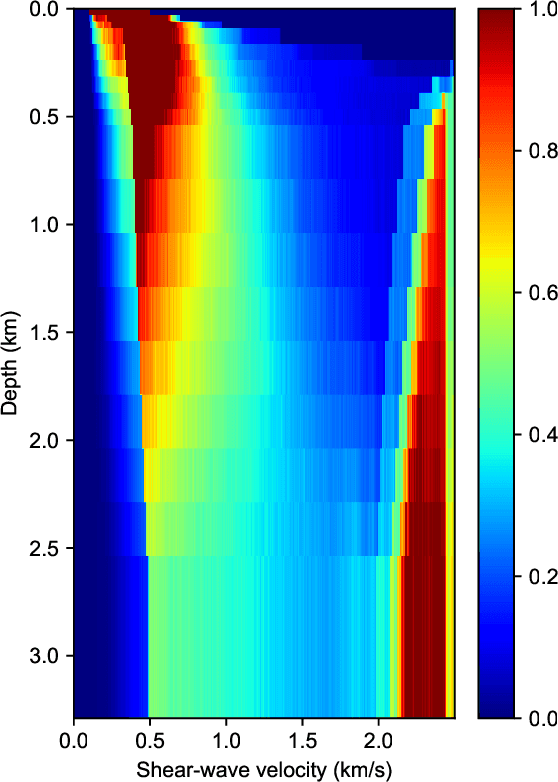
Bayesian geoacoustic inversion problems are conventionally solved by Markov chain Monte Carlo methods or its variants, which are computationally expensive. This paper extends the classic Bayesian geoacoustic inversion framework using the mixture density network (MDN), which provides a much more efficient way to solve geoacoustic inversion problems in Bayesian inference framework. Some important geoacoustic statistics of Bayesian geoacoustic inversion are derived from the multidimensional posterior probability density (PPD) using the MDN theory. These statistics make it convenient to train the network directly on the whole parameter space and get the multidimensional PPD of model parameters. The network is trained on a simulated dataset of surface-wave dispersion curves with shear-wave velocities as labels. The results show that the network gives reliable predictions and has good generalization performance on unseen data. Once trained, the network can rapidly (within seconds) give a fully probabilistic solution which is comparable to Monte Carlo methods. It provides an promissing approach for real-time inversion.
Rethinking Recurrent Neural Networks and other Improvements for Image Classification
Jul 30, 2020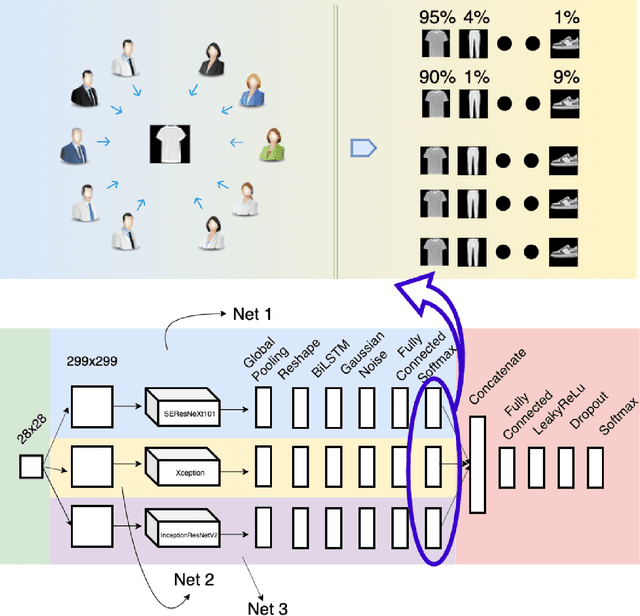
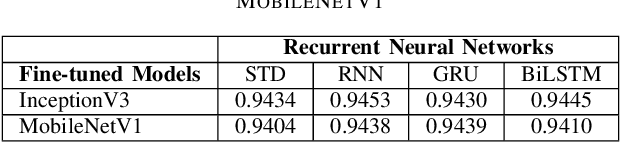
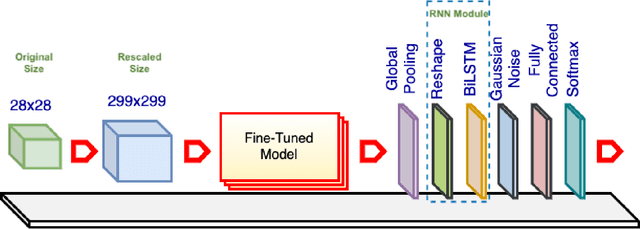
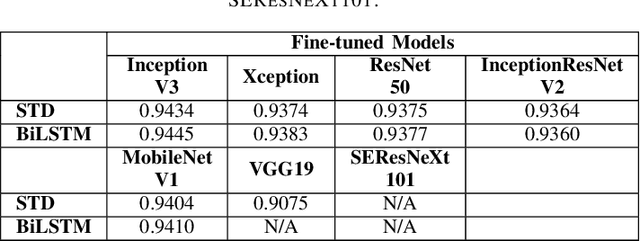
For a long history of Machine Learning which dates back to several decades, Recurrent Neural Networks (RNNs) have been mainly used for sequential data and time series or generally 1D information. Even in some rare researches on 2D images, the networks merely learn and generate data sequentially rather than for recognition of images. In this research, we propose to integrate RNN as an additional layer in designing image recognition's models. Moreover, we develop End-to-End Ensemble Multi-models that are able to learn experts' predictions from several models. Besides, we extend training strategy and softmax pruning which overall leads our designs to perform comparably to top models on several datasets. The source code of the methods provided in this article is available in https://github.com/leonlha/e2e-3m and http://nguyenhuuphong.me.
Fast, Structured Clinical Documentation via Contextual Autocomplete
Jul 29, 2020

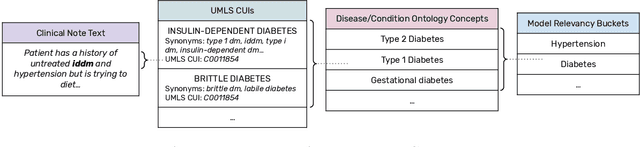

We present a system that uses a learned autocompletion mechanism to facilitate rapid creation of semi-structured clinical documentation. We dynamically suggest relevant clinical concepts as a doctor drafts a note by leveraging features from both unstructured and structured medical data. By constraining our architecture to shallow neural networks, we are able to make these suggestions in real time. Furthermore, as our algorithm is used to write a note, we can automatically annotate the documentation with clean labels of clinical concepts drawn from medical vocabularies, making notes more structured and readable for physicians, patients, and future algorithms. To our knowledge, this system is the only machine learning-based documentation utility for clinical notes deployed in a live hospital setting, and it reduces keystroke burden of clinical concepts by 67% in real environments.
Spectral Analysis Network for Deep Representation Learning and Image Clustering
Sep 11, 2020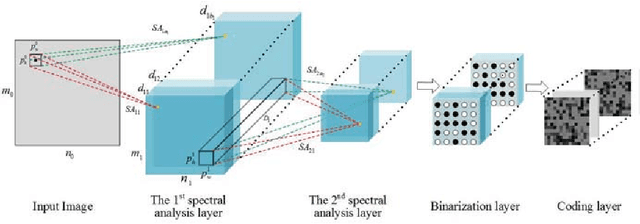
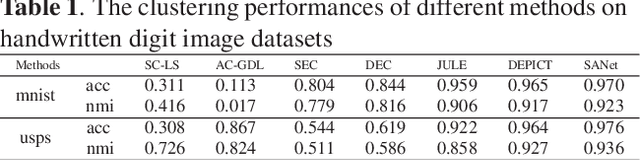

Deep representation learning is a crucial procedure in multimedia analysis and attracts increasing attention. Most of the popular techniques rely on convolutional neural network and require a large amount of labeled data in the training procedure. However, it is time consuming or even impossible to obtain the label information in some tasks due to cost limitation. Thus, it is necessary to develop unsupervised deep representation learning techniques. This paper proposes a new network structure for unsupervised deep representation learning based on spectral analysis, which is a popular technique with solid theory foundations. Compared with the existing spectral analysis methods, the proposed network structure has at least three advantages. Firstly, it can identify the local similarities among images in patch level and thus more robust against occlusion. Secondly, through multiple consecutive spectral analysis procedures, the proposed network can learn more clustering-friendly representations and is capable to reveal the deep correlations among data samples. Thirdly, it can elegantly integrate different spectral analysis procedures, so that each spectral analysis procedure can have their individual strengths in dealing with different data sample distributions. Extensive experimental results show the effectiveness of the proposed methods on various image clustering tasks.
Monitoring and Diagnosability of Perception Systems
May 27, 2020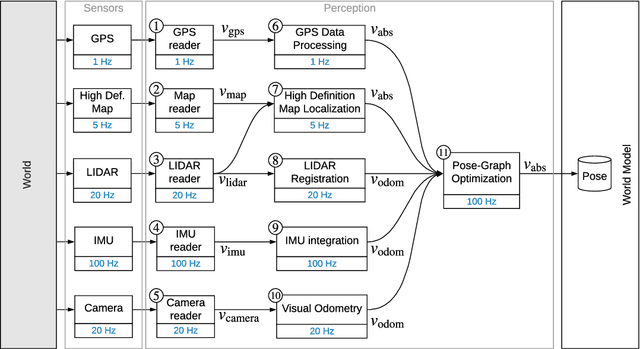
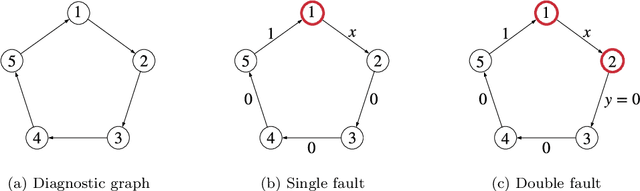
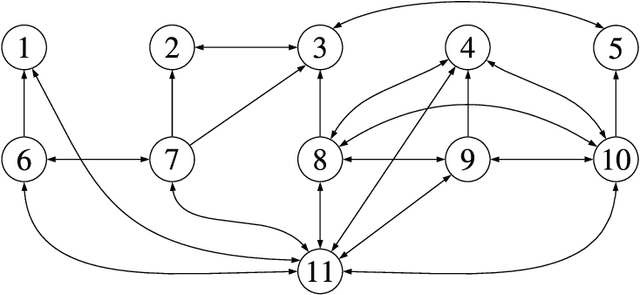
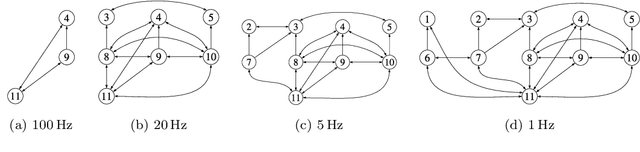
Perception is a critical component of high-integrity applications of robotics and autonomous systems, such as self-driving cars. In these applications, failure of perception systems may put human life at risk, and a broad adoption of these technologies relies on the development of methodologies to guarantee and monitor safe operation as well as detect and mitigate failures. Despite the paramount importance of perception systems, currently there is no formal approach for system-level monitoring. In this work, we propose a mathematical model for runtime monitoring and fault detection of perception systems. Towards this goal, we draw connections with the literature on self-diagnosability for multiprocessor systems, and generalize it to (i) account for modules with heterogeneous outputs, and (ii) add a temporal dimension to the problem, which is crucial to model realistic perception systems where modules interact over time. This contribution results in a graph-theoretic approach that, given a perception system, is able to detect faults at runtime and allows computing an upper-bound on the number of faulty modules that can be detected. Our second contribution is to show that the proposed monitoring approach can be elegantly described with the language of topos theory, which allows formulating diagnosability over arbitrary time intervals.
Towards Deep Clustering of Human Activities from Wearables
Aug 19, 2020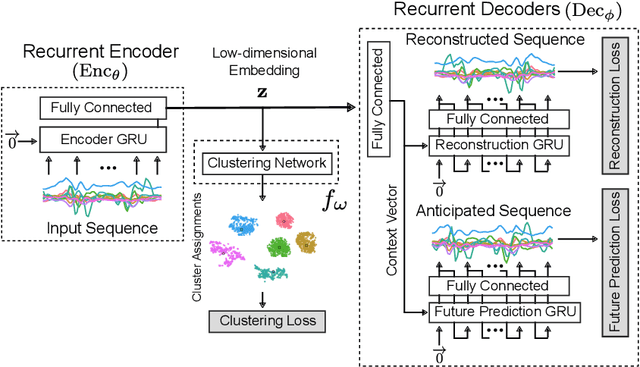
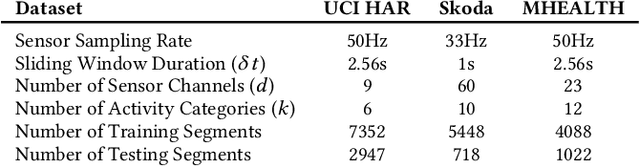
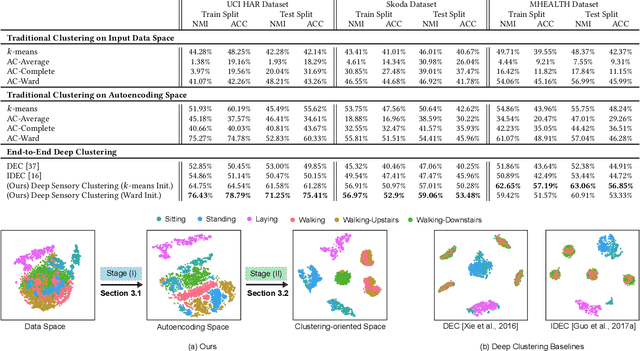
Our ability to exploit low-cost wearable sensing modalities for critical human behaviour and activity monitoring applications in health and wellness is reliant on supervised learning regimes; here, deep learning paradigms have proven extremely successful in learning activity representations from annotated data. However, the costly work of gathering and annotating sensory activity datasets is labor-intensive, time consuming and not scalable to large volumes of data. While existing unsupervised remedies of deep clustering leverage network architectures and optimization objectives that are tailored for static image datasets, deep architectures to uncover cluster structures from raw sequence data captured by on-body sensors remains largely unexplored. In this paper, we develop an unsupervised end-to-end learning strategy for the fundamental problem of human activity recognition (HAR) from wearables. Through extensive experiments, including comparisons with existing methods, we show the effectiveness of our approach to jointly learn unsupervised representations for sensory data and generate cluster assignments with strong semantic correspondence to distinct human activities.
On Box-Cox Transformation for Image Normality and Pattern Classification
Apr 15, 2020
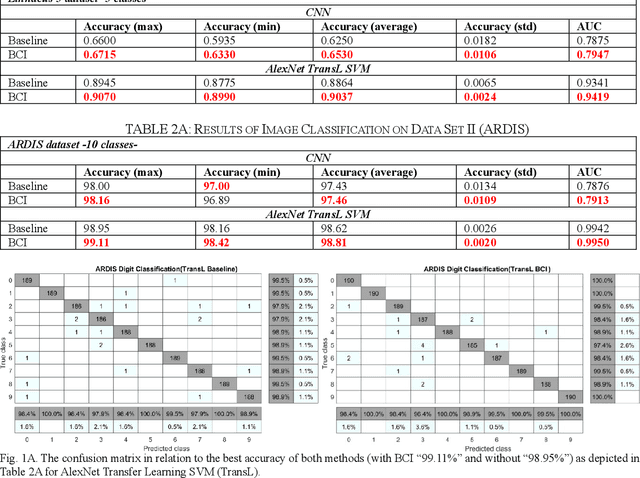
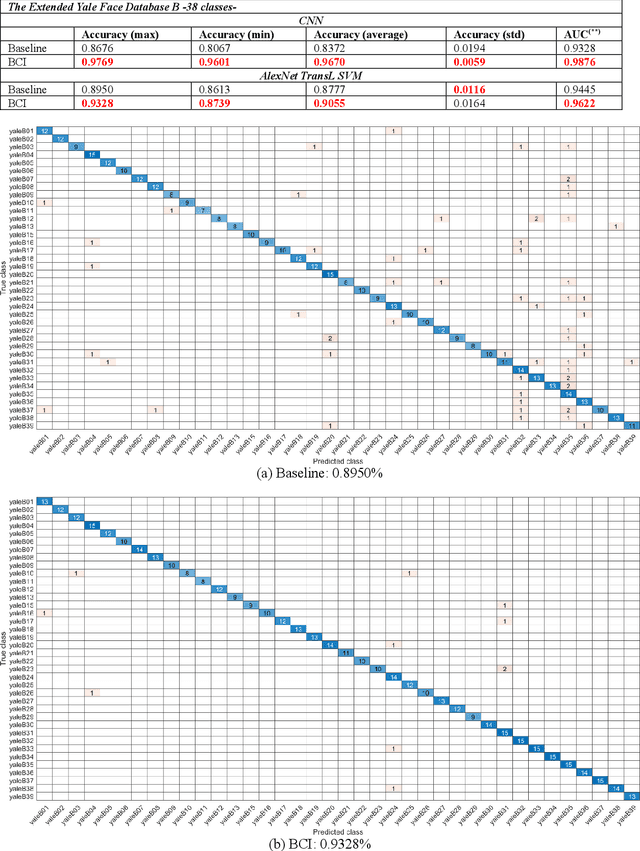
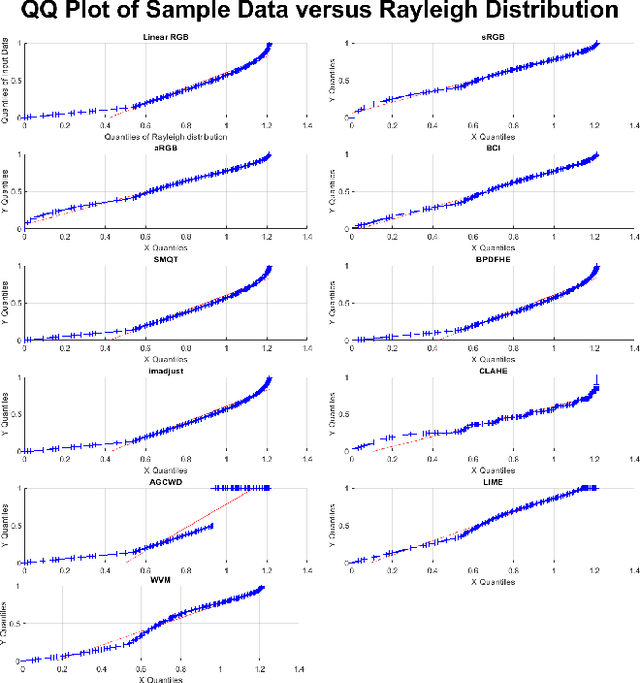
A unique member of the power transformation family is known as the Box-Cox transformation. The latter can be seen as a mathematical operation that leads to finding the optimum lambda ({\lambda}) value that maximizes the log-likelihood function to transform a data to a normal distribution and to reduce heteroscedasticity. In data analytics, a normality assumption underlies a variety of statistical test models. This technique, however, is best known in statistical analysis to handle one-dimensional data. Herein, this paper revolves around the utility of such a tool as a pre-processing step to transform two-dimensional data, namely, digital images and to study its effect. Moreover, to reduce time complexity, it suffices to estimate the parameter lambda in real-time for large two-dimensional matrices by merely considering their probability density function as a statistical inference of the underlying data distribution. We compare the effect of this light-weight Box-Cox transformation with well-established state-of-the-art low light image enhancement techniques. We also demonstrate the effectiveness of our approach through several test-bed data sets for generic improvement of visual appearance of images and for ameliorating the performance of a colour pattern classification algorithm as an example application. Results with and without the proposed approach, are compared using the state-of-the art transfer/deep learning which are discussed in the Appendix. To the best of our knowledge, this is the first time that the Box-Cox transformation is extended to digital images by exploiting histogram transformation.
Solving Stochastic Compositional Optimization is Nearly as Easy as Solving Stochastic Optimization
Aug 31, 2020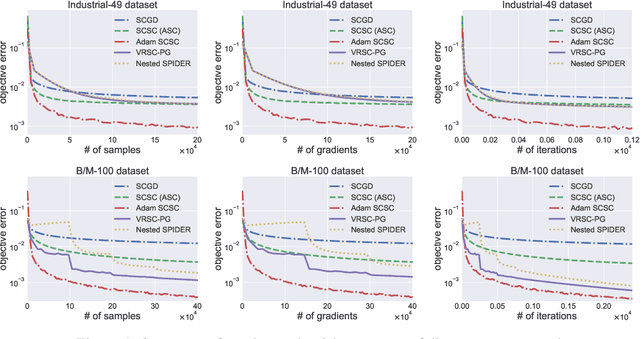
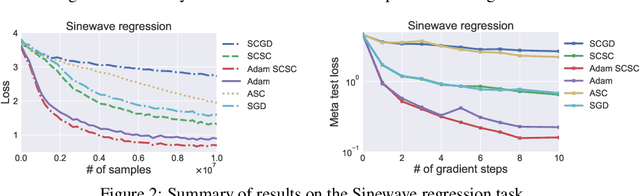
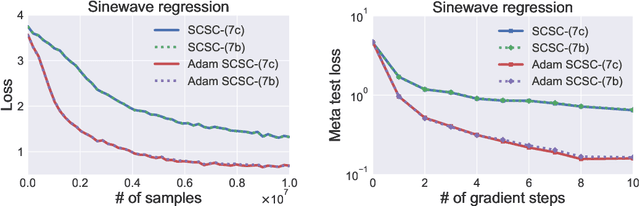
Stochastic compositional optimization generalizes classic (non-compositional) stochastic optimization to the minimization of compositions of functions. Each composition may introduce an additional expectation. The series of expectations may be nested. Stochastic compositional optimization is gaining popularity in applications such as reinforcement learning and meta learning. This paper presents a new Stochastically Corrected Stochastic Compositional gradient method (SCSC). SCSC runs in a single-time scale with a single loop, uses a fixed batch size, and guarantees to converge at the same rate as the stochastic gradient descent (SGD) method for non-compositional stochastic optimization. This is achieved by making a careful improvement to a popular stochastic compositional gradient method. It is easy to apply SGD-improvement techniques to accelerate SCSC. This helps SCSC achieve state-of-the-art performance for stochastic compositional optimization. In particular, we apply Adam to SCSC, and the exhibited rate of convergence matches that of the original Adam on non-compositional stochastic optimization. We test SCSC using the portfolio management and model-agnostic meta-learning tasks.