 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CA-GAN: Weakly Supervised Color Aware GAN for Controllable Makeup Transfer
Aug 24, 2020




While existing makeup style transfer models perform an image synthesis whose results cannot be explicitly controlled, the ability to modify makeup color continuously is a desirable property for virtual try-on applications. We propose a new formulation for the makeup style transfer task, with the objective to learn a color controllable makeup style synthesis. We introduce CA-GAN, a generative model that learns to modify the color of specific objects (e.g. lips or eyes) in the image to an arbitrary target color while preserving background. Since color labels are rare and costly to acquire, our method leverages weakly supervised learning for conditional GANs. This enables to learn a controllable synthesis of complex objects, and only requires a weak proxy of the image attribute that we desire to modify. Finally, we present for the first time a quantitative analysis of makeup style transfer and color control performance.
Partially Observable Online Change Detection via Smooth-Sparse Decomposition
Sep 22, 2020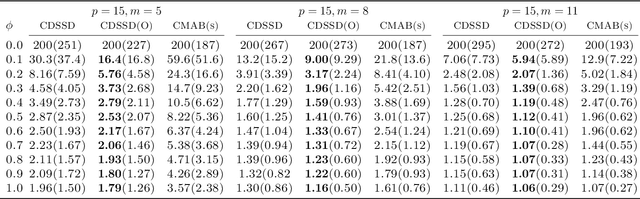
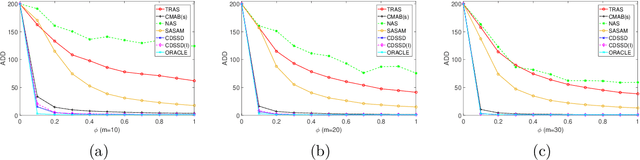
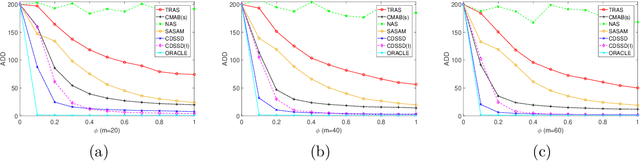
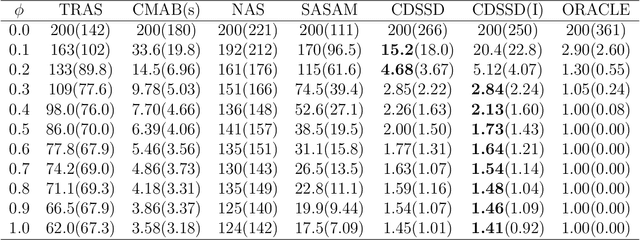
We consider online change detection of high dimensional data streams with sparse changes, where only a subset of data streams can be observed at each sensing time point due to limited sensing capacities. On the one hand, the detection scheme should be able to deal with partially observable data and meanwhile have efficient detection power for sparse changes. On the other, the scheme should be able to adaptively and actively select the most important variables to observe to maximize the detection power. To address these two points, in this paper, we propose a novel detection scheme called CDSSD. In particular, it describes the structure of high dimensional data with sparse changes by smooth-sparse decomposition, whose parameters can be learned via spike-slab variational Bayesian inference. Then the posterior Bayes factor, which incorporates the learned parameters and sparse change information, is formulated as a detection statistic. Finally, by formulating the statistic as the reward of a combinatorial multi-armed bandit problem, an adaptive sampling strategy based on Thompson sampling is proposed. The efficacy and applicability of our method in practice are demonstrated with numerical studies and a real case study.
"I have vxxx bxx connexxxn!": Facing Packet Loss in Deep Speech Emotion Recognition
May 15, 2020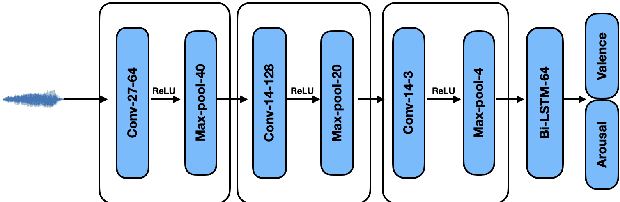

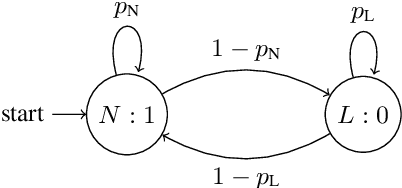
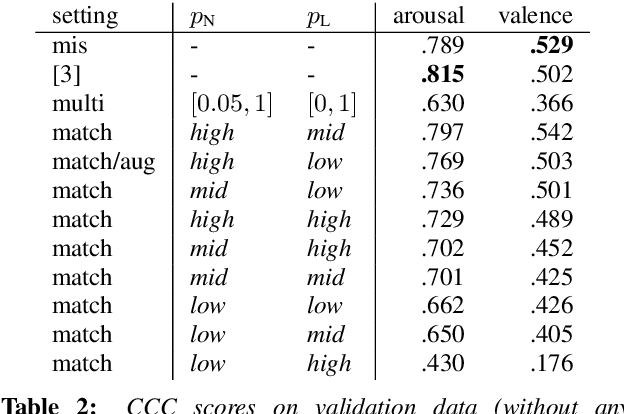
In applications that use emotion recognition via speech, frame-loss can be a severe issue given manifold applications, where the audio stream loses some data frames, for a variety of reasons like low bandwidth. In this contribution, we investigate for the first time the effects of frame-loss on the performance of emotion recognition via speech. Reproducible extensive experiments are reported on the popular RECOLA corpus using a state-of-the-art end-to-end deep neural network, which mainly consists of convolution blocks and recurrent layers. A simple environment based on a Markov Chain model is used to model the loss mechanism based on two main parameters. We explore matched, mismatched, and multi-condition training settings. As one expects, the matched setting yields the best performance, while the mismatched yields the lowest. Furthermore, frame-loss as a data augmentation technique is introduced as a general-purpose strategy to overcome the effects of frame-loss. It can be used during training, and we observed it to produce models that are more robust against frame-loss in run-time environments.
Exploratory Analysis of Covid-19 Tweets using Topic Modeling, UMAP, and DiGraphs
May 06, 2020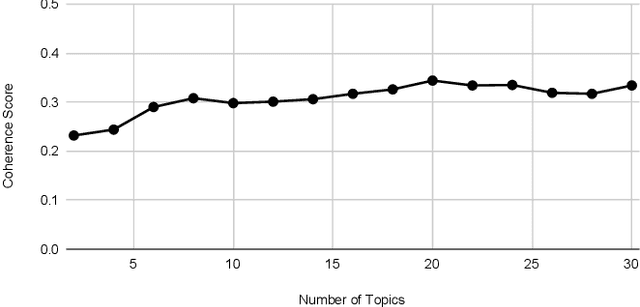
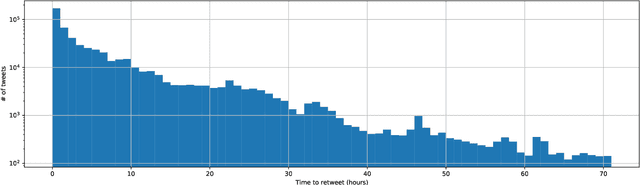
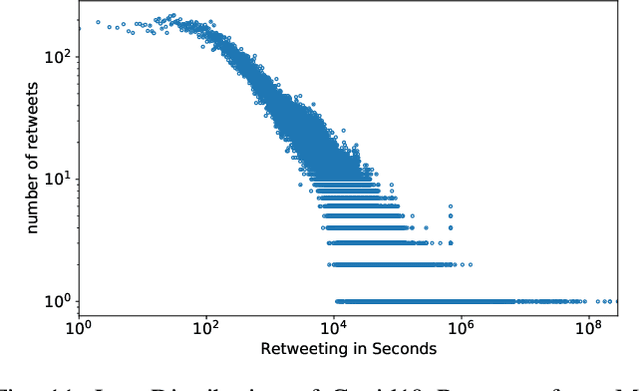
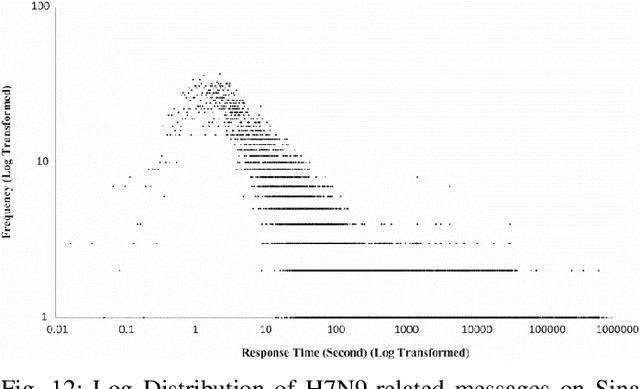
This paper illustrates five different techniques to assess the distinctiveness of topics, key terms and features, speed of information dissemination, and network behaviors for Covid19 tweets. First, we use pattern matching and second, topic modeling through Latent Dirichlet Allocation (LDA) to generate twenty different topics that discuss case spread, healthcare workers, and personal protective equipment (PPE). One topic specific to U.S. cases would start to uptick immediately after live White House Coronavirus Task Force briefings, implying that many Twitter users are paying attention to government announcements. We contribute machine learning methods not previously reported in the Covid19 Twitter literature. This includes our third method, Uniform Manifold Approximation and Projection (UMAP), that identifies unique clustering-behavior of distinct topics to improve our understanding of important themes in the corpus and help assess the quality of generated topics. Fourth, we calculated retweeting times to understand how fast information about Covid19 propagates on Twitter. Our analysis indicates that the median retweeting time of Covid19 for a sample corpus in March 2020 was 2.87 hours, approximately 50 minutes faster than repostings from Chinese social media about H7N9 in March 2013. Lastly, we sought to understand retweet cascades, by visualizing the connections of users over time from fast to slow retweeting. As the time to retweet increases, the density of connections also increase where in our sample, we found distinct users dominating the attention of Covid19 retweeters. One of the simplest highlights of this analysis is that early-stage descriptive methods like regular expressions can successfully identify high-level themes which were consistently verified as important through every subsequent analysis.
Robust quantum minimum finding with an application to hypothesis selection
Mar 26, 2020
We consider the problem of finding the minimum element in a list of length $N$ using a noisy comparator. The noise is modelled as follows: given two elements to compare, if the values of the elements differ by at least $\alpha$ by some metric defined on the elements, then the comparison will be made correctly; if the values of the elements are closer than $\alpha$, the outcome of the comparison is not subject to any guarantees. We demonstrate a quantum algorithm for noisy quantum minimum-finding that preserves the quadratic speedup of the noiseless case: our algorithm runs in time $\tilde O(\sqrt{N (1+\Delta)})$, where $\Delta$ is an upper-bound on the number of elements within the interval $\alpha$, and outputs a good approximation of the true minimum with high probability. Our noisy comparator model is motivated by the problem of hypothesis selection, where given a set of $N$ known candidate probability distributions and samples from an unknown target distribution, one seeks to output some candidate distribution $O(\varepsilon)$-close to the unknown target. Much work on the classical front has been devoted to speeding up the run time of classical hypothesis selection from $O(N^2)$ to $O(N)$, in part by using statistical primitives such as the Scheff\'{e} test. Assuming a quantum oracle generalization of the classical data access and applying our noisy quantum minimum-finding algorithm, we take this run time into the sublinear regime. The final expected run time is $\tilde O( \sqrt{N(1+\Delta)})$, with the same $O(\log N)$ sample complexity from the unknown distribution as the classical algorithm. We expect robust quantum minimum-finding to be a useful building block for algorithms in situations where the comparator (which may be another quantum or classical algorithm) is resolution-limited or subject to some uncertainty.
Multi-label Learning with Missing Values using Combined Facial Action Unit Datasets
Aug 17, 2020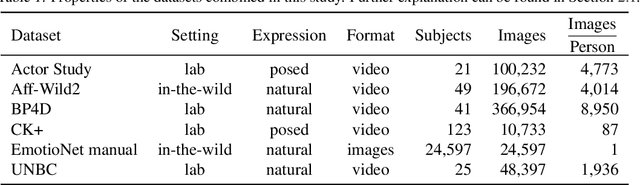

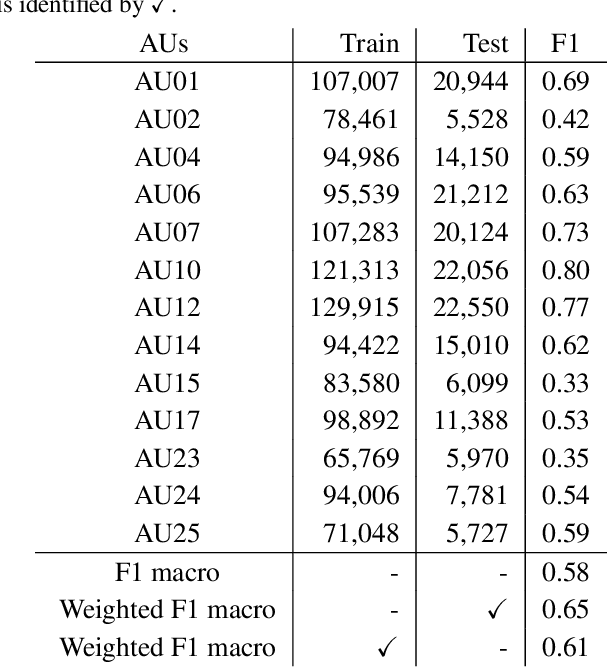
Facial action units allow an objective, standardized description of facial micro movements which can be used to describe emotions in human faces. Annotating data for action units is an expensive and time-consuming task, which leads to a scarce data situation. By combining multiple datasets from different studies, the amount of training data for a machine learning algorithm can be increased in order to create robust models for automated, multi-label action unit detection. However, every study annotates different action units, leading to a tremendous amount of missing labels in a combined database. In this work, we examine this challenge and present our approach to create a combined database and an algorithm capable of learning under the presence of missing labels without inferring their values. Our approach shows competitive performance compared to recent competitions in action unit detection.
Congestion-aware Evacuation Routing using Augmented Reality Devices
Apr 25, 2020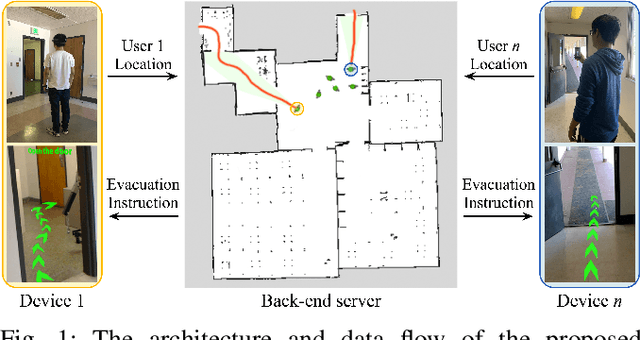
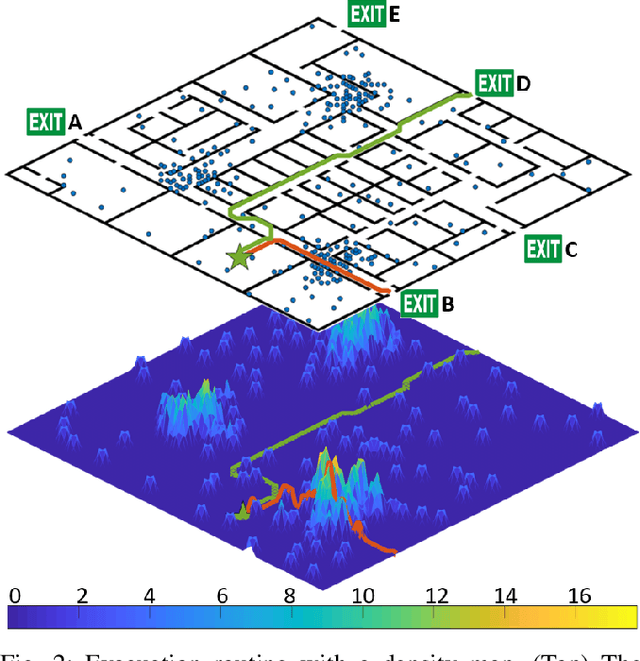
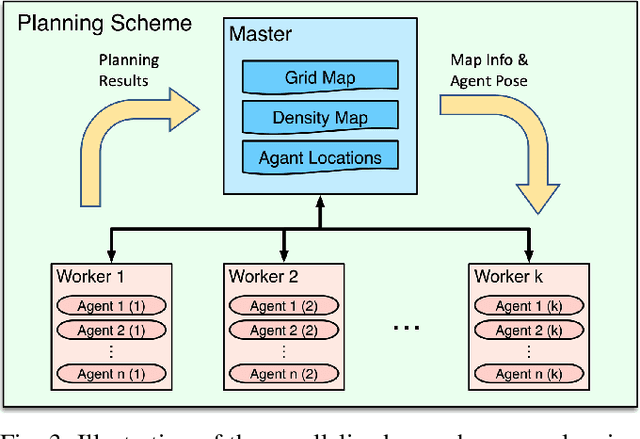
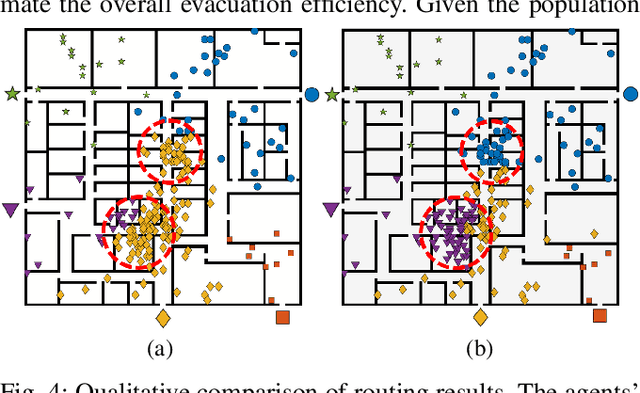
We present a congestion-aware routing solution for indoor evacuation, which produces real-time individual-customized evacuation routes among multiple destinations while keeping tracks of all evacuees' locations. A population density map, obtained on-the-fly by aggregating locations of evacuees from user-end Augmented Reality (AR) devices, is used to model the congestion distribution inside a building. To efficiently search the evacuation route among all destinations, a variant of A* algorithm is devised to obtain the optimal solution in a single pass. In a series of simulated studies, we show that the proposed algorithm is more computationally optimized compared to classic path planning algorithms; it generates a more time-efficient evacuation route for each individual that minimizes the overall congestion. A complete system using AR devices is implemented for a pilot study in real-world environments, demonstrating the efficacy of the proposed approach.
Towards Building a Real Time Mobile Device Bird Counting System Through Synthetic Data Training and Model Compression
Dec 15, 2019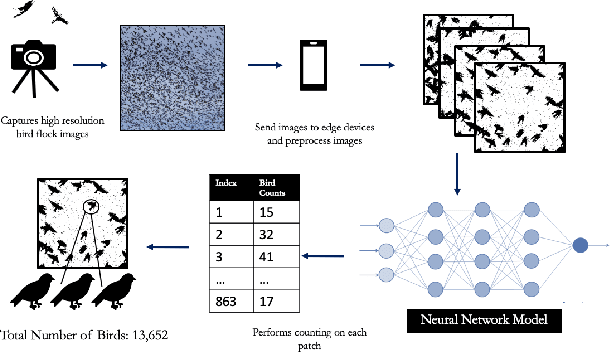

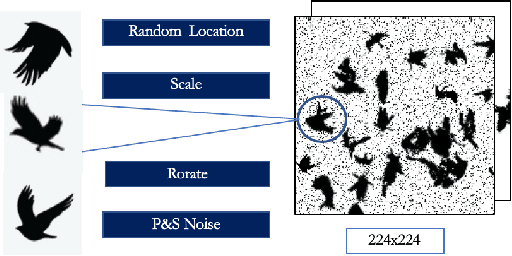
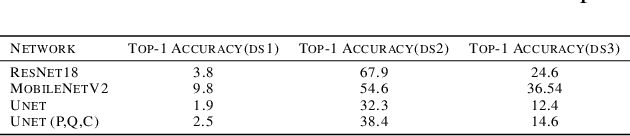
Counting the number of birds in an open sky setting has been an challenging problem due to the large number of bird flocks and the birds can overlap. Another difficulty is the lack of accurate training samples since the cost of labeling images of bird flocks can be extremely high and each sample picture can contain thousands of birds in a high resolution image. Inspired by recent work on training with synthetic data to perform crowd counting, we design a mechanism to generate synthetic bird dataset with precise bird count and the corresponding density maps. We then train a Unet model on the synthetic dataset to perform density map estimation that produces the count for each input. Our method is able to achieve MSE of approximately 12.4 on real dataset. In order to build a scalable system for fast bird counting under storage and computational constraints, we use model compression techniques and efficient model structures to increase the inference speed and save storage cost. We are able to reduce storage cost from 55MB to less than 5MB for the model with minimum loss of accuracy. This paper describes the pipelines of building an efficient bird counting system.
A continuous-time analysis of distributed stochastic gradient
Dec 28, 2018Synchronization in distributed networks of nonlinear dynamical systems plays a critical role in improving robustness of the individual systems to independent stochastic perturbations. Through analogy with dynamical models of biological quorum sensing, where synchronization between systems is induced through interaction with a common signal, we analyze the effect of synchronization on distributed stochastic gradient algorithms. We demonstrate that synchronization can significantly reduce the magnitude of the noise felt by the individual distributed agents and by their spatial mean. This noise reduction property is connected with a reduction in smoothing of the loss function imposed by the stochastic gradient approximation. Using similar techniques, we provide a convergence analysis, and derive a bound on the expected deviation of the spatial mean of the agents from the global minimizer of a strictly convex function. By considering additional dynamics for the quorum variable, we derive an analogous bound, and obtain new convergence results for the elastic averaging SGD algorithm. We conclude with a local analysis around a minimum of a nonconvex loss function, and show that the distributed setting leads to lower expected loss values and wider minima.
Distributed Value Function Approximation for Collaborative Multi-Agent Reinforcement Learning
Jun 18, 2020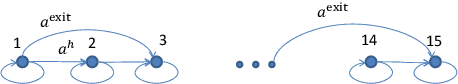
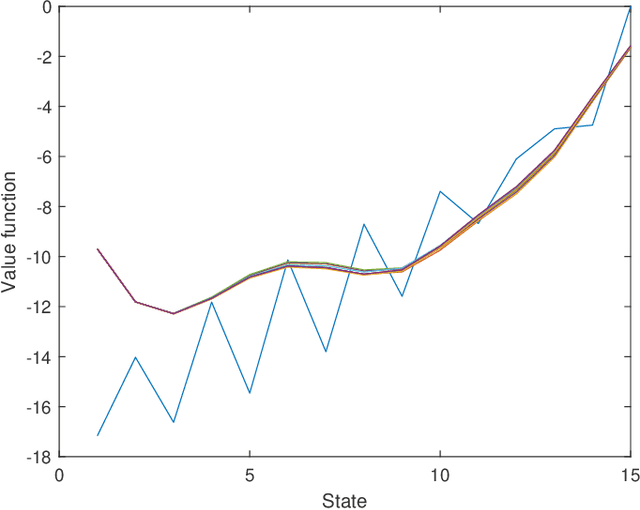
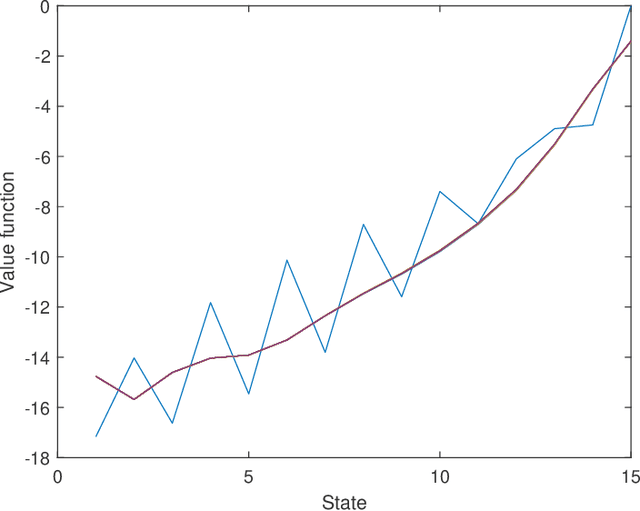
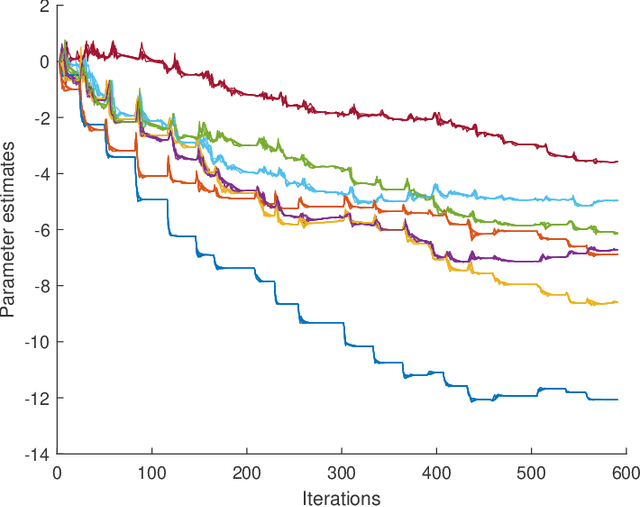
In this paper we propose novel distributed gradient-based temporal difference algorithms for multi-agent off-policy learning of linear approximation of the value function in Markov decision processes. The algorithms are composed of: 1) local parameter updates based on the single-agent off-policy gradient temporal difference learning algorithms, including eligibility traces with state dependent parameters, and 2) linear dynamic consensus scheme over the underlying, typically sparsely connected, inter-agent communication network. The proposed algorithms differ in the way of how the time-scales are selected, how local recursions are performed and how consensus iterations are incorporated. The algorithms are completely decentralized, allowing applications in which all the agents may have completely different behavior policies while evaluating a single target policy. In this sense, the algorithms may be considered as a tool for either parallelization or multi-agent collaborative learning under given constraints. We provide weak convergence results, taking rigorously into account properties of the underlying Feller-Markov processes. We prove that, under nonrestrictive assumptions on the time-varying network topology and the individual state-visiting distributions of the agents, the parameter estimates of the algorithms weakly converge to a consensus point. The variance reduction effect of the proposed algorithms is demonstrated by analyzing a limiting stochastic differential equation. Specific guidelines for network design, providing the desired convergence points, are given. The algorithms' properties are illustrated by characteristic simulation results.