 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robustness and Overcoming Brittleness of AI-Enabled Legal Micro-Directives: The Role of Autonomous Levels of AI Legal Reasoning
Aug 31, 2020
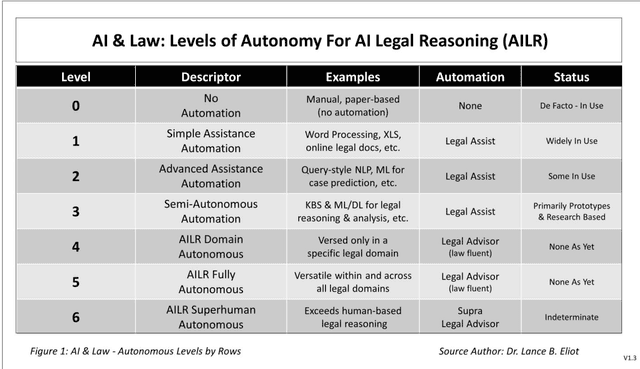
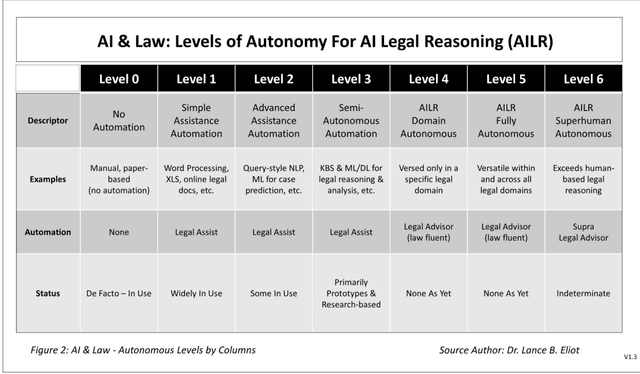
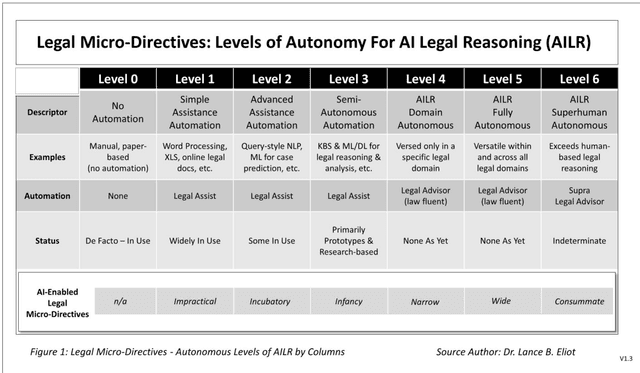

Recent research by legal scholars suggests that the law might inevitably be transformed into legal micro-directives consisting of legal rules that are derived from legal standards or that are otherwise produced automatically or via the consequent derivations of legal goals and then propagated via automation for everyday use as readily accessible lawful directives throughout society. This paper examines and extends the legal micro-directives theories in three crucial respects: (1) By indicating that legal micro-directives are likely to be AI-enabled and evolve over time in scope and velocity across the autonomous levels of AI Legal Reasoning, (2) By exploring the trade-offs between legal standards and legal rules as the imprinters of the micro-directives, and (3) By illuminating a set of brittleness exposures that can undermine legal micro-directives and proffering potential mitigating remedies to seek greater robustness in the instantiation and promulgation of such AI-powered lawful directives.
Deep Echo State Q-Network (DEQN) and Its Application in Dynamic Spectrum Sharing for 5G and Beyond
Oct 12, 2020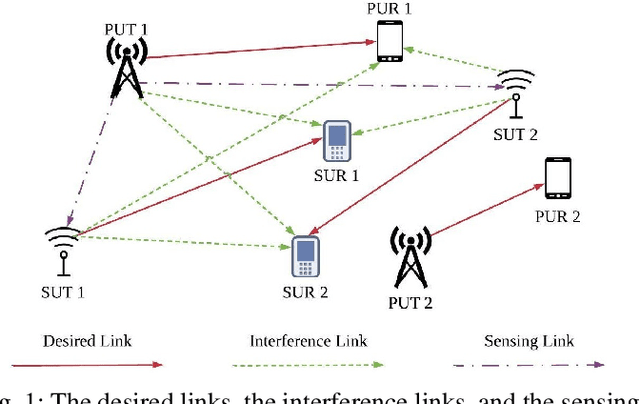

Deep reinforcement learning (DRL) has been shown to be successful in many application domains. Combining recurrent neural networks (RNNs) and DRL further enables DRL to be applicable in non-Markovian environments by capturing temporal information. However, training of both DRL and RNNs is known to be challenging requiring a large amount of training data to achieve convergence. In many targeted applications, such as those used in the fifth generation (5G) cellular communication, the environment is highly dynamic while the available training data is very limited. Therefore, it is extremely important to develop DRL strategies that are capable of capturing the temporal correlation of the dynamic environment requiring limited training overhead. In this paper, we introduce the deep echo state Q-network (DEQN) that can adapt to the highly dynamic environment in a short period of time with limited training data. We evaluate the performance of the introduced DEQN method under the dynamic spectrum sharing (DSS) scenario, which is a promising technology in 5G and future 6G networks to increase the spectrum utilization. Compared to conventional spectrum management policy that grants a fixed spectrum band to a single system for exclusive access, DSS allows the secondary system to share the spectrum with the primary system. Our work sheds light on the application of an efficient DRL framework in highly dynamic environments with limited available training data.
Top-DB-Net: Top DropBlock for Activation Enhancement in Person Re-Identification
Oct 12, 2020



Person Re-Identification is a challenging task that aims to retrieve all instances of a query image across a system of non-overlapping cameras. Due to the various extreme changes of view, it is common that local regions that could be used to match people are suppressed, which leads to a scenario where approaches have to evaluate the similarity of images based on less informative regions. In this work, we introduce the Top-DB-Net, a method based on Top DropBlock that pushes the network to learn to focus on the scene foreground, with special emphasis on the most task-relevant regions and, at the same time, encodes low informative regions to provide high discriminability. The Top-DB-Net is composed of three streams: (i) a global stream encodes rich image information from a backbone, (ii) the Top DropBlock stream encourages the backbone to encode low informative regions with high discriminative features, and (iii) a regularization stream helps to deal with the noise created by the dropping process of the second stream, when testing the first two streams are used. Vast experiments on three challenging datasets show the capabilities of our approach against state-of-the-art methods. Qualitative results demonstrate that our method exhibits better activation maps focusing on reliable parts of the input images.
* Accepted on 25th International Conference on Pattern Recognition (ICPR2020)
Detection and Description of Change in Visual Streams
Mar 27, 2020

This paper presents a framework for the analysis of changes in visual streams: ordered sequences of images, possibly separated by significant time gaps. We propose a new approach to incorporating unlabeled data into training to generate natural language descriptions of change. We also develop a framework for estimating the time of change in visual stream. We use learned representations for change evidence and consistency of perceived change, and combine these in a regularized graph cut based change detector. Experimental evaluation on visual stream datasets, which we release as part of our contribution, shows that representation learning driven by natural language descriptions significantly improves change detection accuracy, compared to methods that do not rely on language.
Machine-Learning the Sato--Tate Conjecture
Oct 02, 2020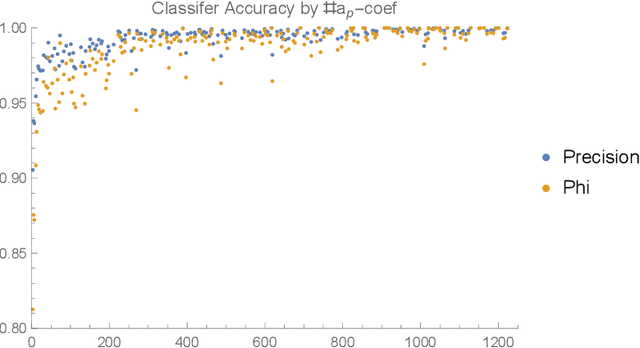
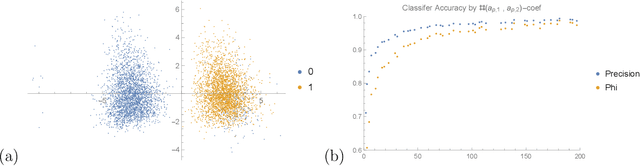
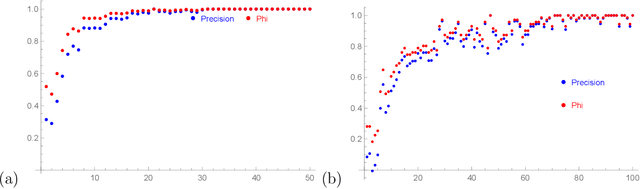
We apply some of the latest techniques from machine-learning to the arithmetic of hyperelliptic curves. More precisely we show that, with impressive accuracy and confidence (between 99 and 100 percent precision), and in very short time (matter of seconds on an ordinary laptop), a Bayesian classifier can distinguish between Sato--Tate groups given a small number of Euler factors for the L-function. Our observations are in keeping with the Sato-Tate conjecture for curves of low genus. For elliptic curves, this amounts to distinguishing generic curves (with Sato--Tate group SU(2)) from those with complex multiplication. In genus 2, a principal component analysis is observed to separate the generic Sato--Tate group USp(4) from the non-generic groups. Furthermore in this case, for which there are many more non-generic possibilities than in the case of elliptic curves, we demonstrate an accurate characterisation of several Sato--Tate groups with the same identity component. Throughout, our observations are verified using known results from the literature and the data available in the LMFDB. The results in this paper suggest that a machine can be trained to learn the Sato--Tate distributions and may be able to classify curves much more efficiently than the methods available in the literature.
Learn to Earn: Enabling Coordination within a Ride Hailing Fleet
Jun 19, 2020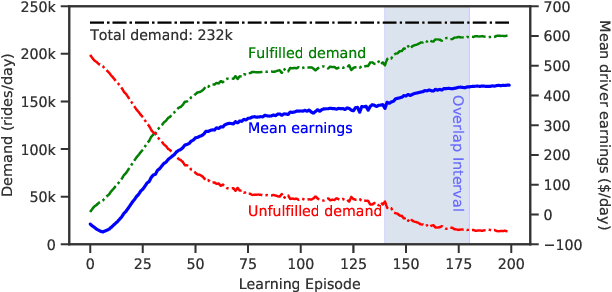
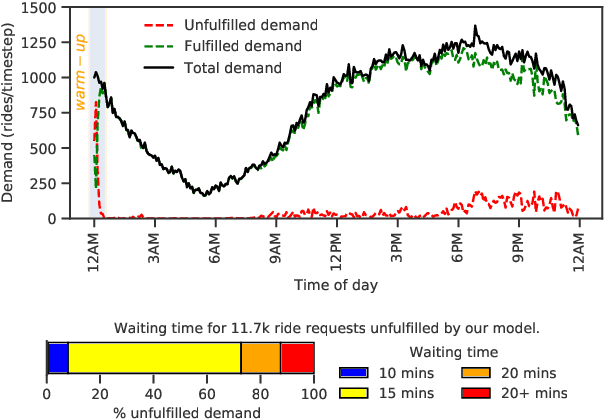
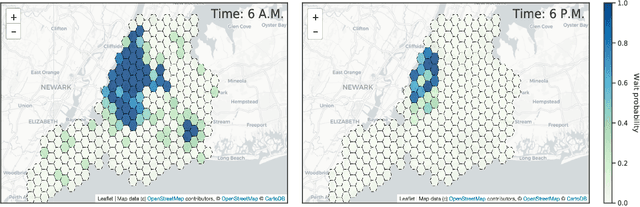
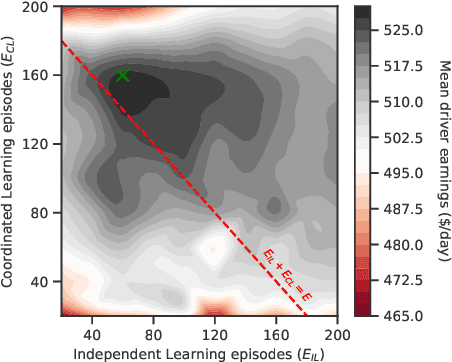
The problem of optimizing social welfare objectives on multi sided ride hailing platforms such as Uber, Lyft, etc., is challenging, due to misalignment of objectives between drivers, passengers, and the platform itself. An ideal solution aims to minimize the response time for each hyper local passenger ride request, while simultaneously maintaining high demand satisfaction and supply utilization across the entire city. Economists tend to rely on dynamic pricing mechanisms that stifle price sensitive excess demand and resolve the supply demand imbalances emerging in specific neighborhoods. In contrast, computer scientists primarily view it as a demand prediction problem with the goal of preemptively repositioning supply to such neighborhoods using black box coordinated multi agent deep reinforcement learning based approaches. Here, we introduce explainability in the existing supply repositioning approaches by establishing the need for coordination between the drivers at specific locations and times. Explicit need based coordination allows our framework to use a simpler non deep reinforcement learning based approach, thereby enabling it to explain its recommendations ex post. Moreover, it provides envy free recommendations i.e., drivers at the same location and time do not envy one another's future earnings. Our experimental evaluation demonstrates the effectiveness, the robustness, and the generalizability of our framework. Finally, in contrast to previous works, we make available a reinforcement learning environment for end to end reproducibility of our work and to encourage future comparative studies.
Training Deep Spiking Neural Networks
Jun 08, 2020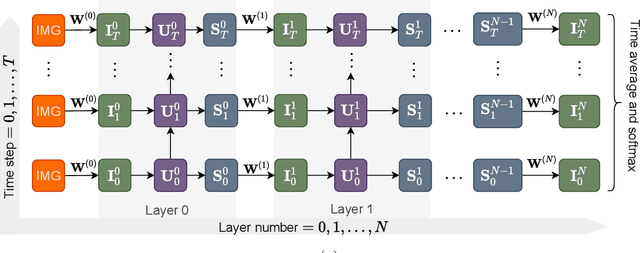



Computation using brain-inspired spiking neural networks (SNNs) with neuromorphic hardware may offer orders of magnitude higher energy efficiency compared to the current analog neural networks (ANNs). Unfortunately, training SNNs with the same number of layers as state of the art ANNs remains a challenge. To our knowledge the only method which is successful in this regard is supervised training of ANN and then converting it to SNN. In this work we directly train deep SNNs using backpropagation with surrogate gradient and find that due to implicitly recurrent nature of feed forward SNN's the exploding or vanishing gradient problem severely hinders their training. We show that this problem can be solved by tuning the surrogate gradient function. We also propose using batch normalization from ANN literature on input currents of SNN neurons. Using these improvements we show that is is possible to train SNN with ResNet50 architecture on CIFAR100 and Imagenette object recognition datasets. The trained SNN falls behind in accuracy compared to analogous ANN but requires several orders of magnitude less inference time steps (as low as 10) to reach good accuracy compared to SNNs obtained by conversion from ANN which require on the order of 1000 time steps.
DNA: Differentiable Network-Accelerator Co-Search
Oct 28, 2020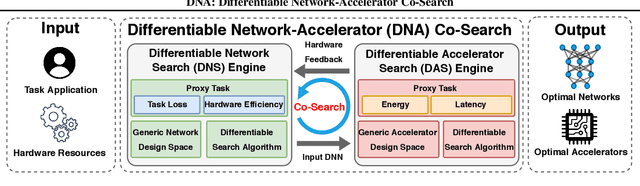

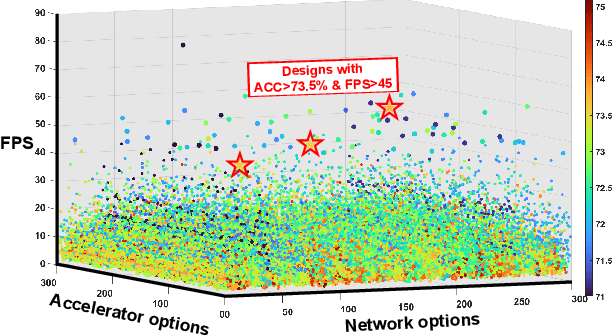
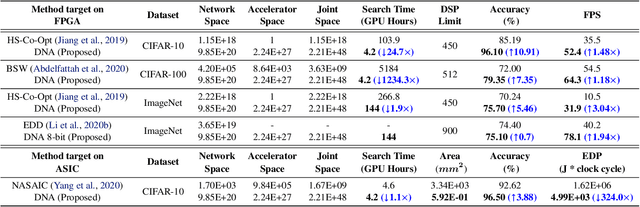
Powerful yet complex deep neural networks (DNNs) have fueled a booming demand for efficient DNN solutions to bring DNN-powered intelligence into numerous applications. Jointly optimizing the networks and their accelerators are promising in providing optimal performance. However, the great potential of such solutions have yet to be unleashed due to the challenge of simultaneously exploring the vast and entangled, yet different design spaces of the networks and their accelerators. To this end, we propose DNA, a Differentiable Network-Accelerator co-search framework for automatically searching for matched networks and accelerators to maximize both the task accuracy and acceleration efficiency. Specifically, DNA integrates two enablers: (1) a generic design space for DNN accelerators that is applicable to both FPGA- and ASIC-based DNN accelerators and compatible with DNN frameworks such as PyTorch to enable algorithmic exploration for more efficient DNNs and their accelerators; and (2) a joint DNN network and accelerator co-search algorithm that enables simultaneously searching for optimal DNN structures and their accelerators' micro-architectures and mapping methods to maximize both the task accuracy and acceleration efficiency. Experiments and ablation studies based on FPGA measurements and ASIC synthesis show that the matched networks and accelerators generated by DNA consistently outperform state-of-the-art (SOTA) DNNs and DNN accelerators (e.g., 3.04x better FPS with a 5.46% higher accuracy on ImageNet), while requiring notably reduced search time (up to 1234.3x) over SOTA co-exploration methods, when evaluated over ten SOTA baselines on three datasets. All codes will be released upon acceptance.
Attention-Driven Body Pose Encoding for Human Activity Recognition
Oct 02, 2020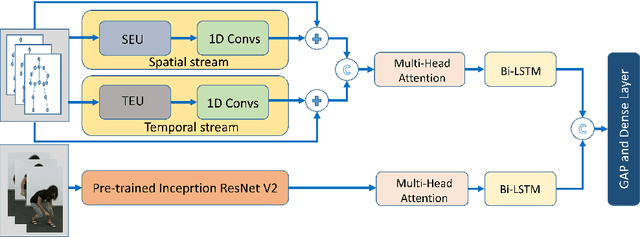
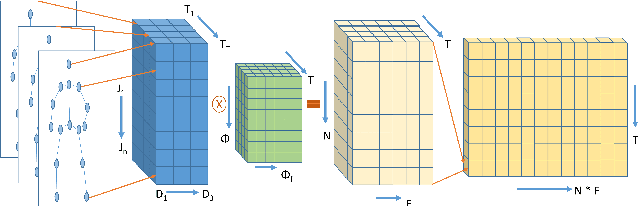
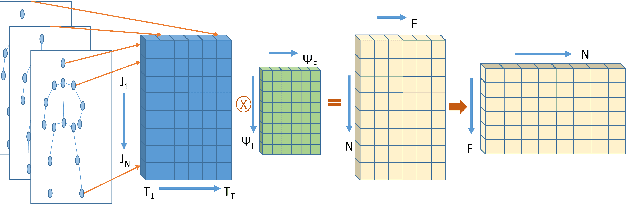
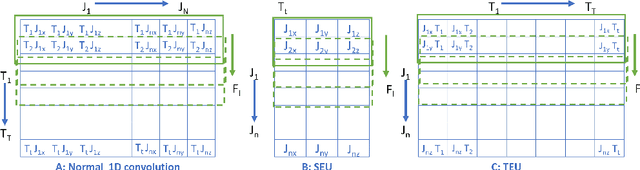
This article proposes a novel attention-based body pose encoding for human activity recognition that presents a enriched representation of body-pose that is learned. The enriched data complements the 3D body joint position data and improves model performance. In this paper, we propose a novel approach that learns enhanced feature representations from a given sequence of 3D body joints. To achieve this encoding, the approach exploits 1) a spatial stream which encodes the spatial relationship between various body joints at each time point to learn spatial structure involving the spatial distribution of different body joints 2) a temporal stream that learns the temporal variation of individual body joints over the entire sequence duration to present a temporally enhanced representation. Afterwards, these two pose streams are fused with a multi-head attention mechanism. % adapted from neural machine translation. We also capture the contextual information from the RGB video stream using a Inception-ResNet-V2 model combined with a multi-head attention and a bidirectional Long Short-Term Memory (LSTM) network. %Moreover, we whose performance is enhanced through the multi-head attention mechanism. Finally, the RGB video stream is combined with the fused body pose stream to give a novel end-to-end deep model for effective human activity recognition.
* This paper has been accepted for publication at the IAPR IEEE/Computer Society International Conference on Pattern Recognition (ICPR), Milan, 2021
Pan-artifact Removing with Deep Learning, on ISEs
May 28, 2020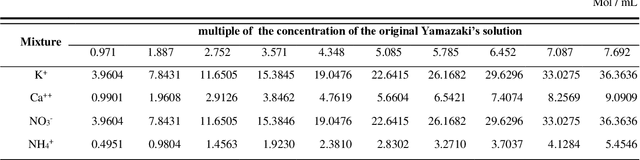
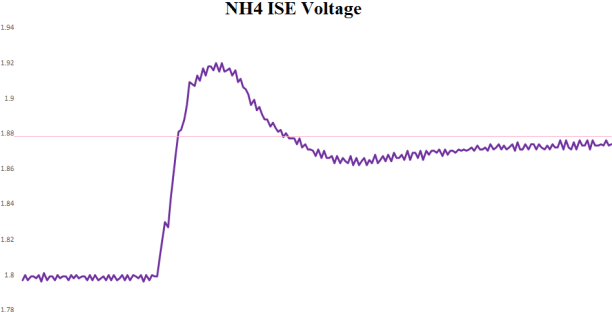
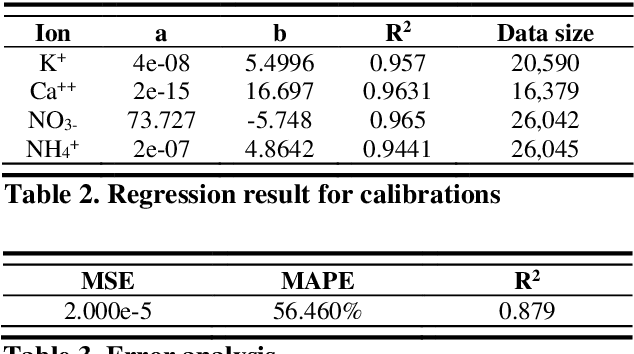
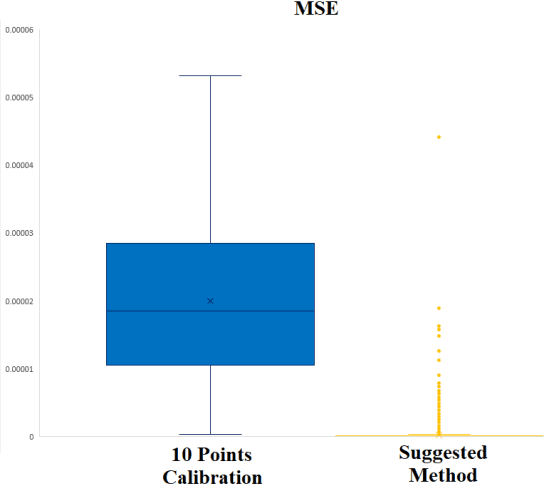
This paper presents a signal-processing method to remove pan-artifact on ISEs with artificial neural networks. An Ion Selective Electrode is used to investigate the concentration of a specific ion from aqueous solution, by measuring the Nernst potential along the glass membrane. However, Application of ISE on a multi-ion solution has problem. First problem is a chemicophysical artifact which is called ion interference effect. Electrically charged particles interact with each other and flows through the glass membrane of different ISEs. Second problem is that movement of liquid directly interfere the glass membrane, causing inaccurate voltage measurement. When multiple ISEs are dipped into same solution, a sensor's signal emission interference voltage measurement of other sensors. Therefore, an ISE is recommended to applied on single-ion solution, without any other sensors applied at the same time. Deep learning approach can remove both artifacts at the same time. The proposed method is designed to remove complex artifacts with one-shot calculation, with MAPE less than 1.8%, and R2 as 0.997. A randomly chosen value of AI-predicted value has MAPE less than 5% (p-value 0.016).