 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Neighbourhood Consensus Networks via Submanifold Sparse Convolutions
Apr 22, 2020

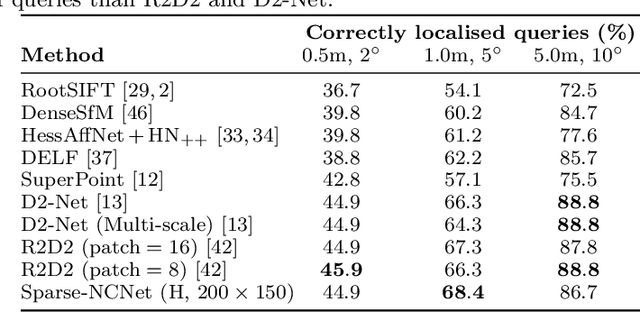
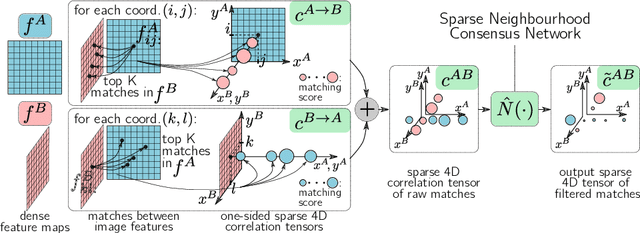
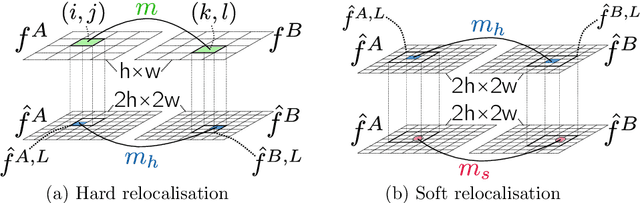
In this work we target the problem of estimating accurately localised correspondences between a pair of images. We adopt the recent Neighbourhood Consensus Networks that have demonstrated promising performance for difficult correspondence problems and propose modifications to overcome their main limitations: large memory consumption, large inference time and poorly localised correspondences. Our proposed modifications can reduce the memory footprint and execution time more than $10\times$, with equivalent results. This is achieved by sparsifying the correlation tensor containing tentative matches, and its subsequent processing with a 4D CNN using submanifold sparse convolutions. Localisation accuracy is significantly improved by processing the input images in higher resolution, which is possible due to the reduced memory footprint, and by a novel two-stage correspondence relocalisation module. The proposed Sparse-NCNet method obtains state-of-the-art results on the HPatches Sequences and InLoc visual localisation benchmarks, and competitive results in the Aachen Day-Night benchmark.
Incremental Text to Speech for Neural Sequence-to-Sequence Models using Reinforcement Learning
Aug 07, 2020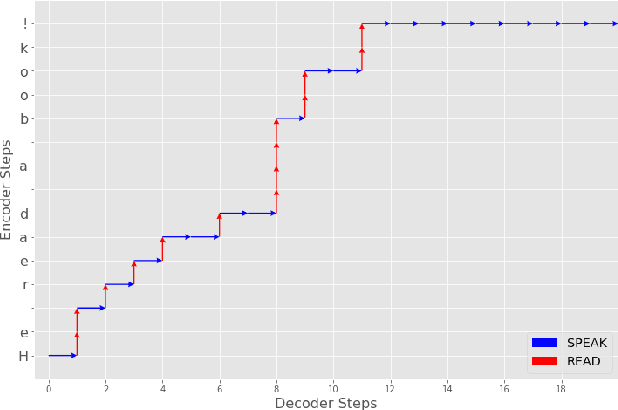

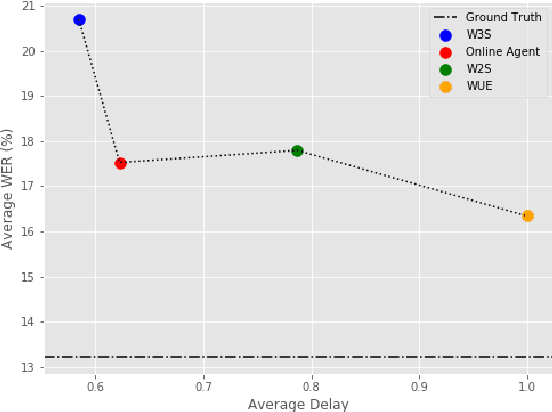
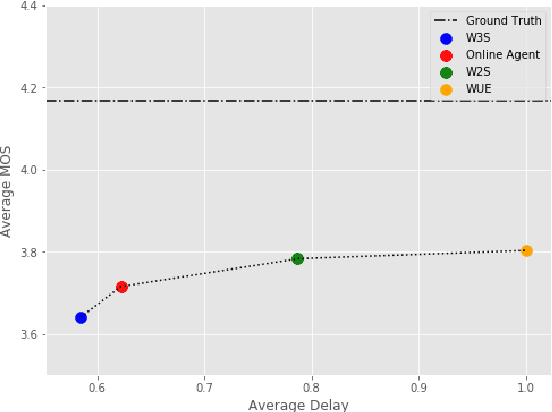
Modern approaches to text to speech require the entire input character sequence to be processed before any audio is synthesised. This latency limits the suitability of such models for time-sensitive tasks like simultaneous interpretation. Interleaving the action of reading a character with that of synthesising audio reduces this latency. However, the order of this sequence of interleaved actions varies across sentences, which raises the question of how the actions should be chosen. We propose a reinforcement learning based framework to train an agent to make this decision. We compare our performance against that of deterministic, rule-based systems. Our results demonstrate that our agent successfully balances the trade-off between the latency of audio generation and the quality of synthesised audio. More broadly, we show that neural sequence-to-sequence models can be adapted to run in an incremental manner.
Fast nonparametric clustering of structured time-series
Apr 14, 2014
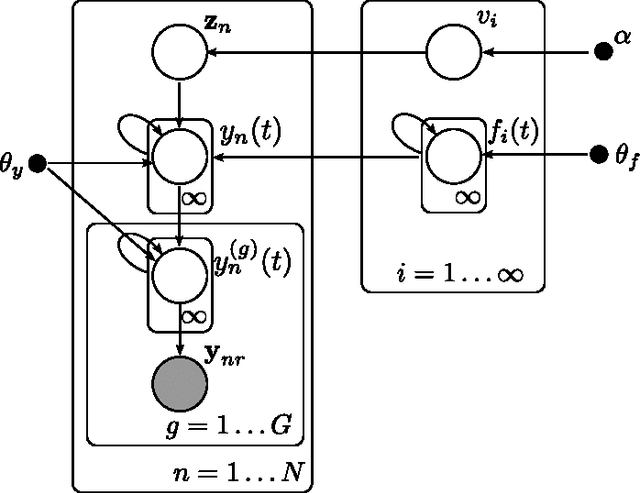
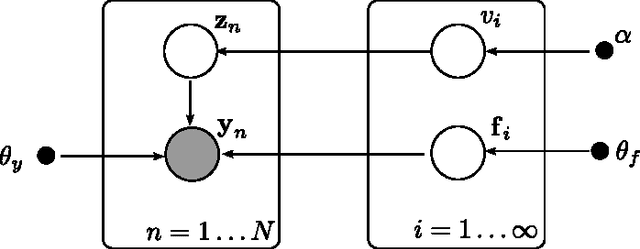
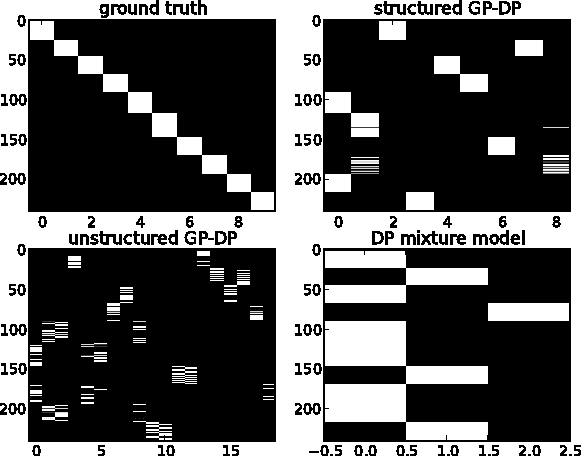
In this publication, we combine two Bayesian non-parametric models: the Gaussian Process (GP) and the Dirichlet Process (DP). Our innovation in the GP model is to introduce a variation on the GP prior which enables us to model structured time-series data, i.e. data containing groups where we wish to model inter- and intra-group variability. Our innovation in the DP model is an implementation of a new fast collapsed variational inference procedure which enables us to optimize our variationala pproximation significantly faster than standard VB approaches. In a biological time series application we show how our model better captures salient features of the data, leading to better consistency with existing biological classifications, while the associated inference algorithm provides a twofold speed-up over EM-based variational inference.
Skyline: Interactive In-Editor Computational Performance Profiling for Deep Neural Network Training
Aug 20, 2020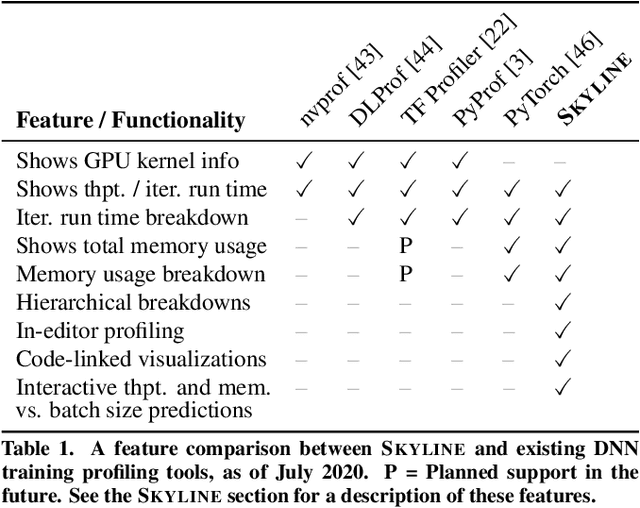
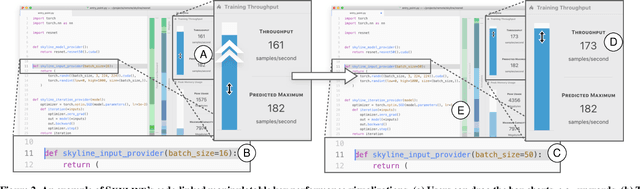
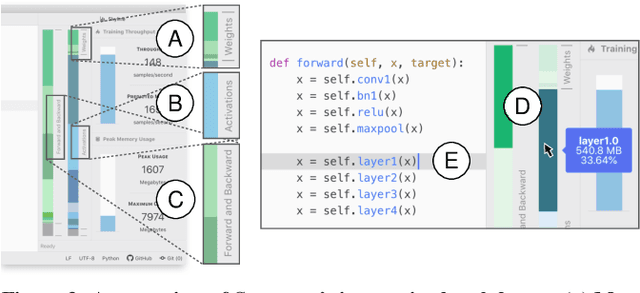
Training a state-of-the-art deep neural network (DNN) is a computationally-expensive and time-consuming process, which incentivizes deep learning developers to debug their DNNs for computational performance. However, effectively performing this debugging requires intimate knowledge about the underlying software and hardware systems---something that the typical deep learning developer may not have. To help bridge this gap, we present Skyline: a new interactive tool for DNN training that supports in-editor computational performance profiling, visualization, and debugging. Skyline's key contribution is that it leverages special computational properties of DNN training to provide (i) interactive performance predictions and visualizations, and (ii) directly manipulatable visualizations that, when dragged, mutate the batch size in the code. As an in-editor tool, Skyline allows users to leverage these diagnostic features to debug the performance of their DNNs during development. An exploratory qualitative user study of Skyline produced promising results; all the participants found Skyline to be useful and easy to use.
Constructing a Knowledge Graph from Unstructured Documents without External Alignment
Aug 20, 2020
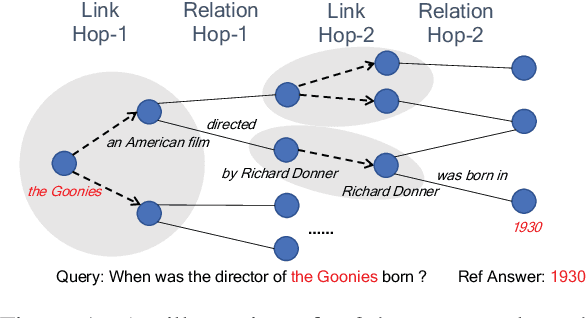
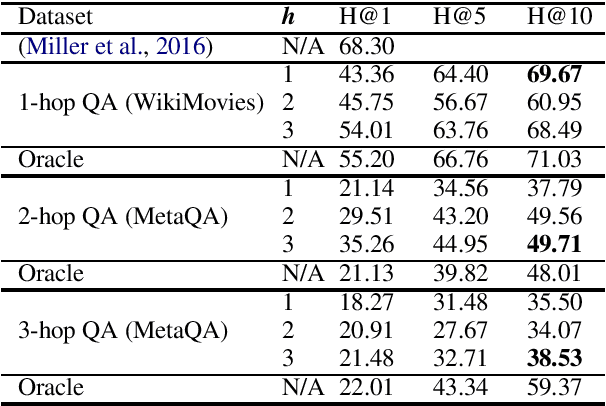

Knowledge graphs (KGs) are relevant to many NLP tasks, but building a reliable domain-specific KG is time-consuming and expensive. A number of methods for constructing KGs with minimized human intervention have been proposed, but still require a process to align into the human-annotated knowledge base. To overcome this issue, we propose a novel method to automatically construct a KG from unstructured documents that does not require external alignment and explore its use to extract desired information. To summarize our approach, we first extract knowledge tuples in their surface form from unstructured documents, encode them using a pre-trained language model, and link the surface-entities via the encoding to form the graph structure. We perform experiments with benchmark datasets such as WikiMovies and MetaQA. The experimental results show that our method can successfully create and search a KG with 18K documents and achieve 69.7% hits@10 (close to an oracle model) on a query retrieval task.
Benchmarking in Optimization: Best Practice and Open Issues
Jul 07, 2020
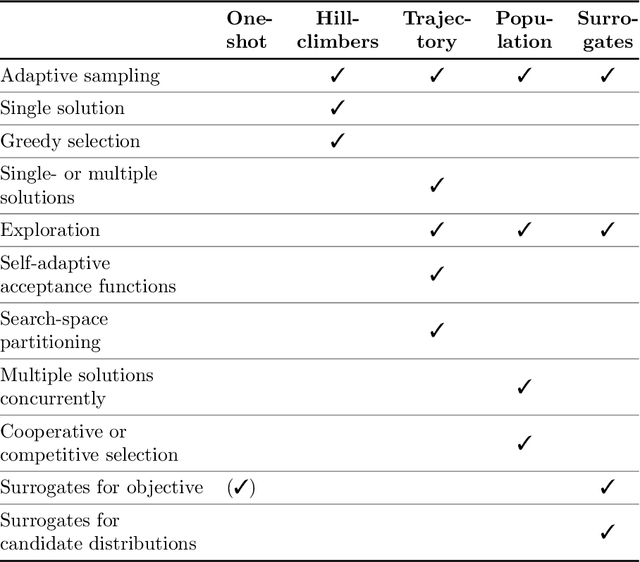
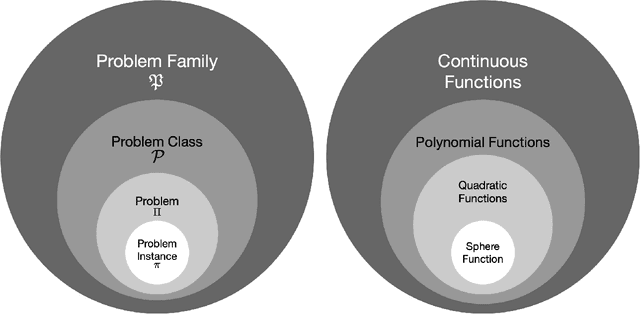

This survey compiles ideas and recommendations from more than a dozen researchers with different backgrounds and from different institutes around the world. Promoting best practice in benchmarking is its main goal. The article discusses eight essential topics in benchmarking: clearly stated goals, well-specified problems, suitable algorithms, adequate performance measures, thoughtful analysis, effective and efficient designs, comprehensible presentations, and guaranteed reproducibility. The final goal is to provide well-accepted guidelines (rules) that might be useful for authors and reviewers. As benchmarking in optimization is an active and evolving field of research this manuscript is meant to co-evolve over time by means of periodic updates.
WaveCycleGAN2: Time-domain Neural Post-filter for Speech Waveform Generation
Apr 09, 2019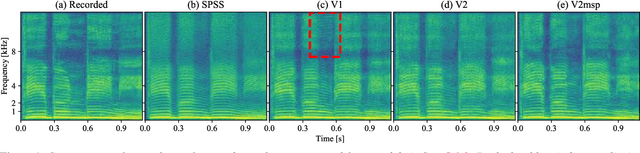
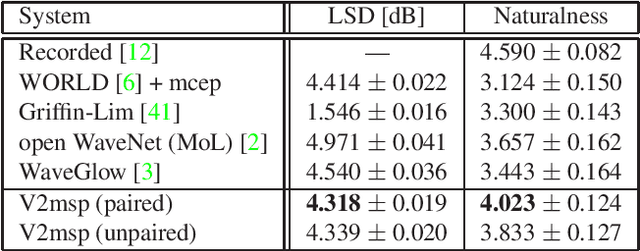
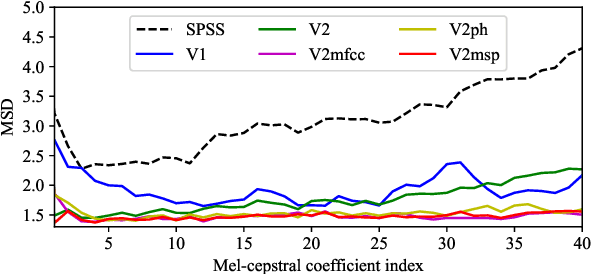
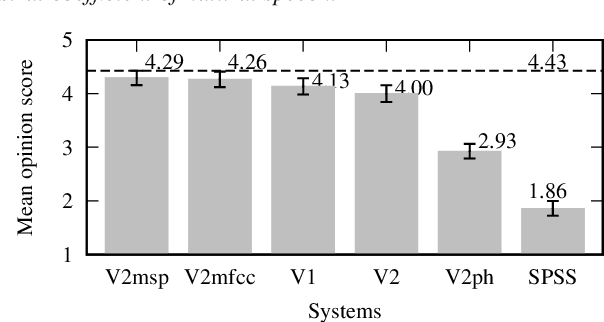
WaveCycleGAN has recently been proposed to bridge the gap between natural and synthesized speech waveforms in statistical parametric speech synthesis and provides fast inference with a moving average model rather than an autoregressive model and high-quality speech synthesis with the adversarial training. However, the human ear can still distinguish the processed speech waveforms from natural ones. One possible cause of this distinguishability is the aliasing observed in the processed speech waveform via down/up-sampling modules. To solve the aliasing and provide higher quality speech synthesis, we propose WaveCycleGAN2, which 1) uses generators without down/up-sampling modules and 2) combines discriminators of the waveform domain and acoustic parameter domain. The results show that the proposed method 1) alleviates the aliasing well, 2) is useful for both speech waveforms generated by analysis-and-synthesis and statistical parametric speech synthesis, and 3) achieves a mean opinion score comparable to those of natural speech and speech synthesized by WaveNet (open WaveNet) and WaveGlow while processing speech samples at a rate of more than 150 kHz on an NVIDIA Tesla P100.
Using Monte Carlo dropout and bootstrap aggregation for uncertainty estimation in radiation therapy dose prediction with deep learning neural networks
Nov 01, 2020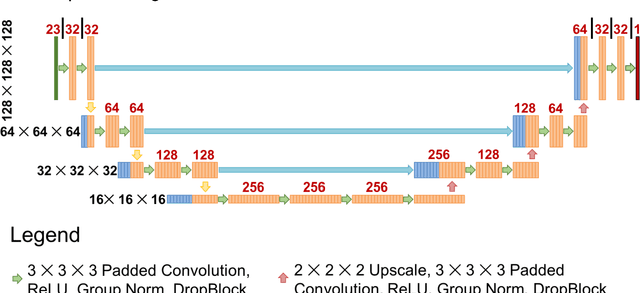
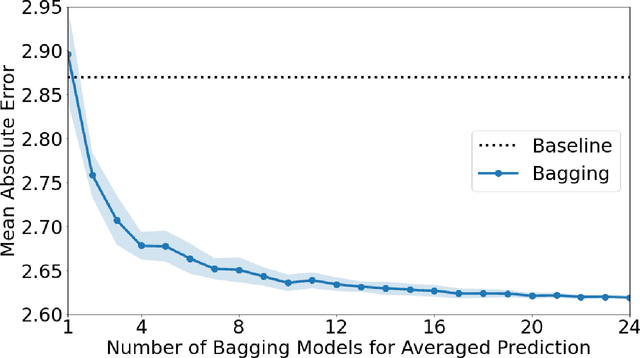
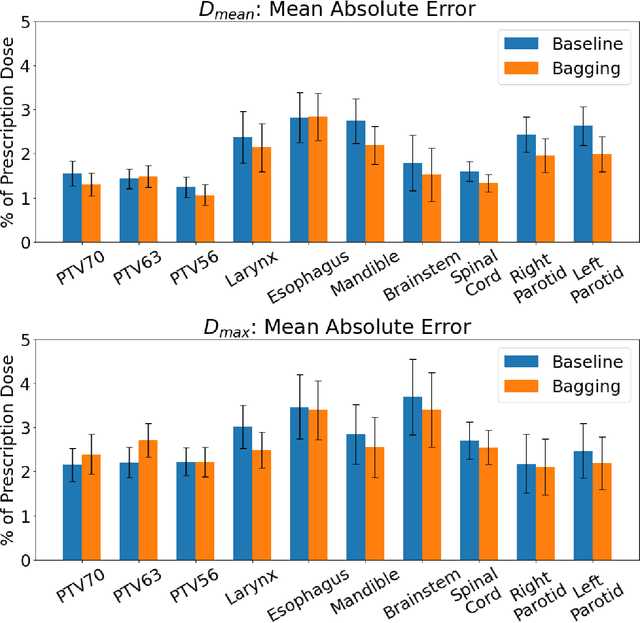
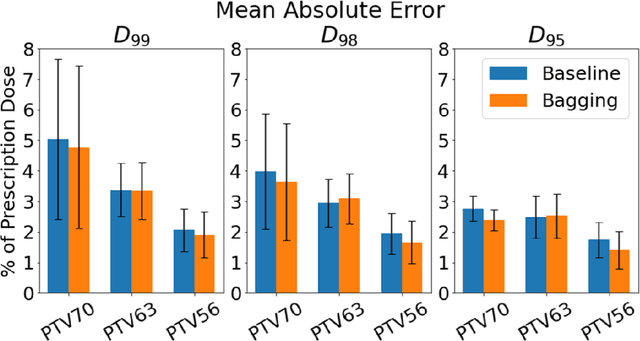
Recently, artificial intelligence technologies and algorithms have become a major focus for advancements in treatment planning for radiation therapy. As these are starting to become incorporated into the clinical workflow, a major concern from clinicians is not whether the model is accurate, but whether the model can express to a human operator when it does not know if its answer is correct. We propose to use Monte Carlo dropout (MCDO) and the bootstrap aggregation (bagging) technique on deep learning models to produce uncertainty estimations for radiation therapy dose prediction. We show that both models are capable of generating a reasonable uncertainty map, and, with our proposed scaling technique, creating interpretable uncertainties and bounds on the prediction and any relevant metrics. Performance-wise, bagging provides statistically significant reduced loss value and errors in most of the metrics investigated in this study. The addition of bagging was able to further reduce errors by another 0.34% for Dmean and 0.19% for Dmax, on average, when compared to the baseline framework. Overall, the bagging framework provided significantly lower MAE of 2.62, as opposed to the baseline framework's MAE of 2.87. The usefulness of bagging, from solely a performance standpoint, does highly depend on the problem and the acceptable predictive error, and its high upfront computational cost during training should be factored in to deciding whether it is advantageous to use it. In terms of deployment with uncertainty estimations turned on, both frameworks offer the same performance time of about 12 seconds. As an ensemble-based metaheuristic, bagging can be used with existing machine learning architectures to improve stability and performance, and MCDO can be applied to any deep learning models that have dropout as part of their architecture.
Disentanglement Then Reconstruction: Learning Compact Features for Unsupervised Domain Adaptation
May 28, 2020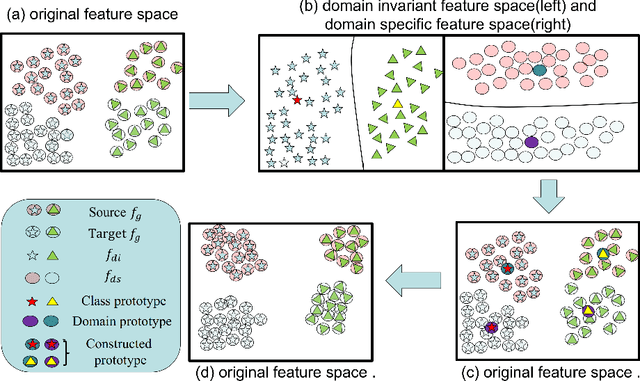
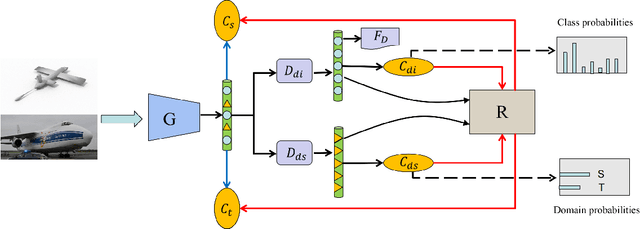
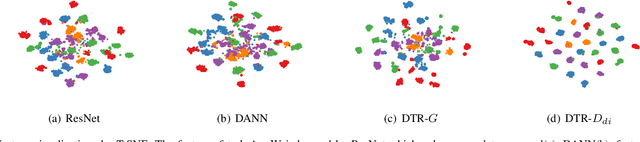
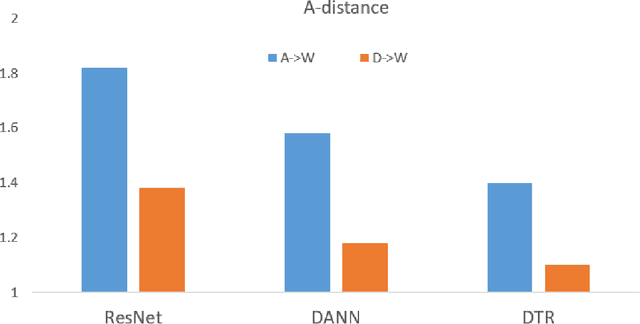
Recent works in domain adaptation always learn domain invariant features to mitigate the gap between the source and target domains by adversarial methods. The category information are not sufficiently used which causes the learned domain invariant features are not enough discriminative. We propose a new domain adaptation method based on prototype construction which likes capturing data cluster centers. Specifically, it consists of two parts: disentanglement and reconstruction. First, the domain specific features and domain invariant features are disentangled from the original features. At the same time, the domain prototypes and class prototypes of both domains are estimated. Then, a reconstructor is trained by reconstructing the original features from the disentangled domain invariant features and domain specific features. By this reconstructor, we can construct prototypes for the original features using class prototypes and domain prototypes correspondingly. In the end, the feature extraction network is forced to extract features close to these prototypes. Our contribution lies in the technical use of the reconstructor to obtain the original feature prototypes which helps to learn compact and discriminant features. As far as we know, this idea is proposed for the first time. Experiment results on several public datasets confirm the state-of-the-art performance of our method.
Strategy for Boosting Pair Comparison and Improving Quality Assessment Accuracy
Oct 01, 2020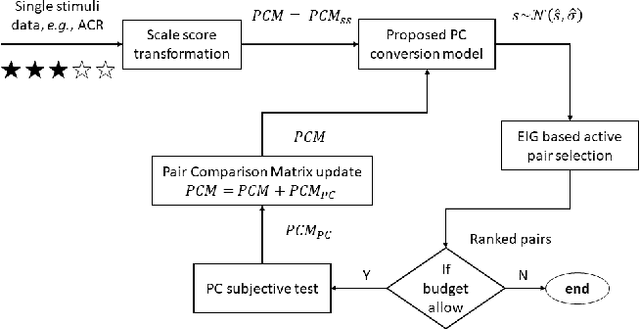
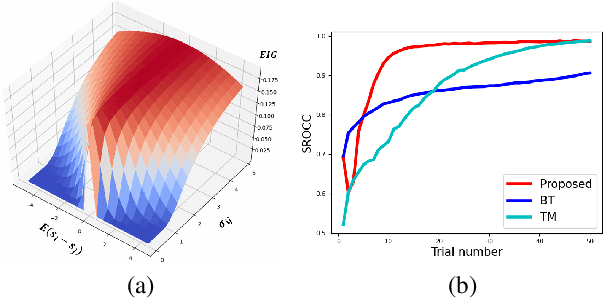
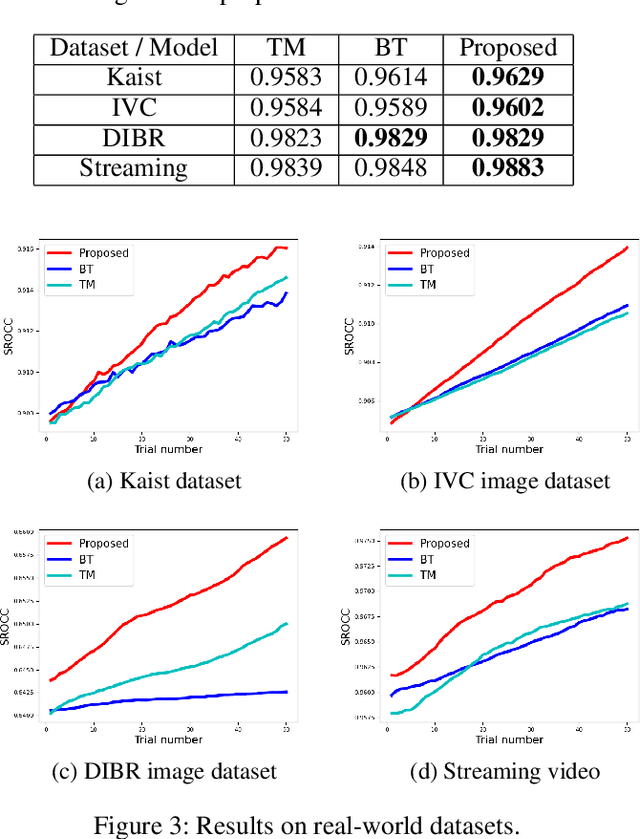
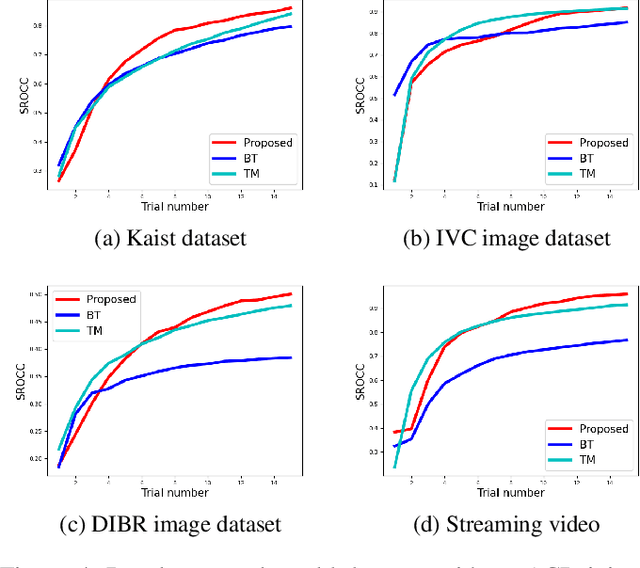
The development of rigorous quality assessment model relies on the collection of reliable subjective data, where the perceived quality of visual multimedia is rated by the human observers. Different subjective assessment protocols can be used according to the objectives, which determine the discriminability and accuracy of the subjective data. Single stimulus methodology, e.g., the Absolute Category Rating (ACR) has been widely adopted due to its simplicity and efficiency. However, Pair Comparison (PC) is of significant advantage over ACR in terms of discriminability. In addition, PC avoids the influence of observers' bias regarding their understanding of the quality scale. Nevertheless, full pair comparison is much more time-consuming. In this study, we therefore 1) employ a generic model to bridge the pair comparison data and ACR data, where the variance term could be recovered and the obtained information is more complete; 2) propose a fusion strategy to boost pair comparisons by utilizing the ACR results as initialization information; 3) develop a novel active batch sampling strategy based on Minimum Spanning Tree (MST) for PC. In such a way, the proposed methodology could achieve the same accuracy of pair comparison but with the compelxity as low as ACR. Extensive experimental results demonstrate the efficiency and accuracy of the proposed approach, which outperforms the state of the art approaches.