 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
AE-Netv2: Optimization of Image Fusion Efficiency and Network Architecture
Oct 05, 2020
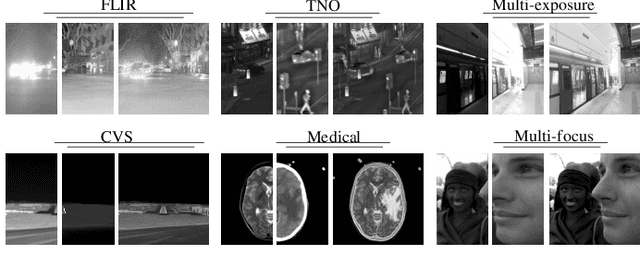
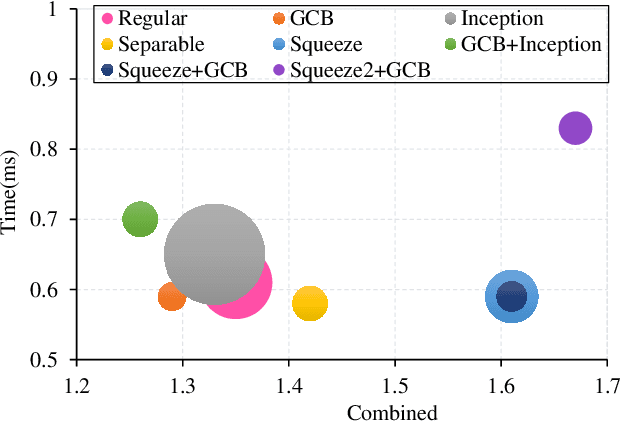

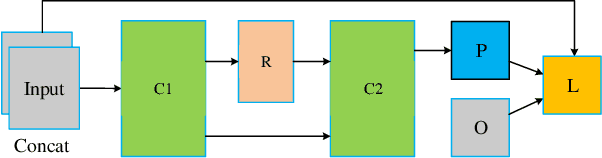
Existing image fusion methods pay few research attention to image fusion efficiency and network architecture. However, the efficiency and accuracy of image fusion has an important impact in practical applications. To solve this problem, we propose an \textit{efficient autonomous evolution image fusion method, dubed by AE-Netv2}. Different from other image fusion methods based on deep learning, AE-Netv2 is inspired by human brain cognitive mechanism. Firstly, we discuss the influence of different network architecture on image fusion quality and fusion efficiency, which provides a reference for the design of image fusion architecture. Secondly, we explore the influence of pooling layer on image fusion task and propose an image fusion method with pooling layer. Finally, we explore the commonness and characteristics of different image fusion tasks, which provides a research basis for further research on the continuous learning characteristics of human brain in the field of image fusion. Comprehensive experiments demonstrate the superiority of AE-Netv2 compared with state-of-the-art methods in different fusion tasks at a real time speed of 100+ FPS on GTX 2070. Among all tested methods based on deep learning, AE-Netv2 has the faster speed, the smaller model size and the better robustness.
Assessment of COVID-19 hospitalization forecasts from a simplified SIR model
Jul 20, 2020
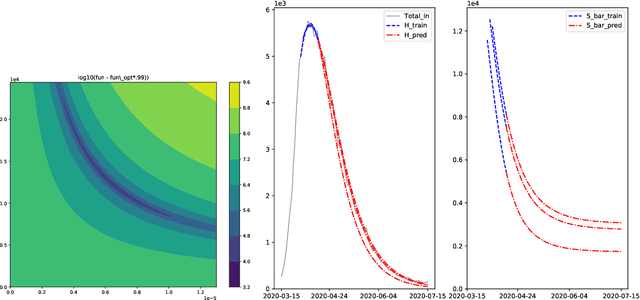
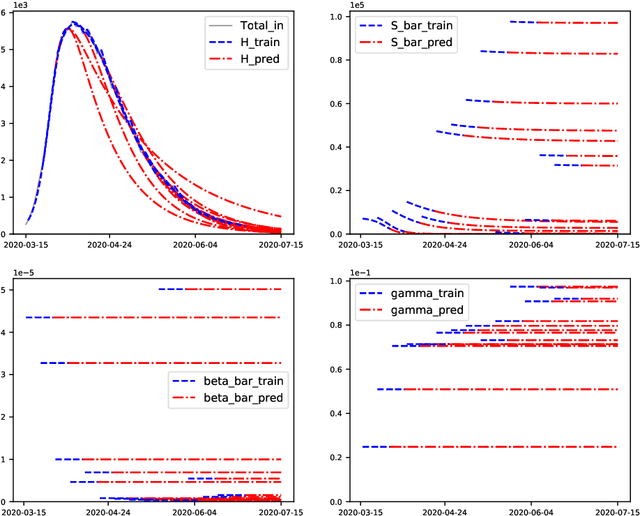

We propose the SH model, a simplified version of the well-known SIR compartmental model of infectious diseases. With optimized parameters and initial conditions, this time-invariant two-parameter two-dimensional model is able to fit COVID-19 hospitalization data over several months with high accuracy (mean absolute percentage error below 15%). Moreover, we observed that, when the model is trained on a suitable two-week period around the hospitalization peak for Belgium, it forecasts the subsequent three-month decrease with mean absolute percentage error below 10%. However, when it is trained in the increase phase, it is less successful at forecasting the subsequent evolution.
Development and Evaluation of a Deep Neural Network for Histologic Classification of Renal Cell Carcinoma on Biopsy and Surgical Resection Slides
Oct 30, 2020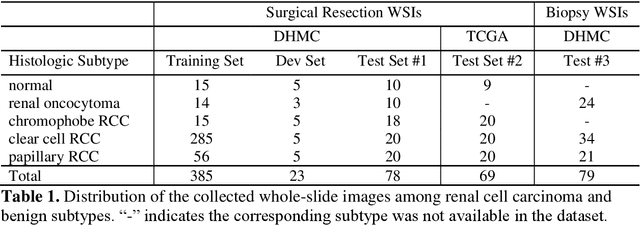
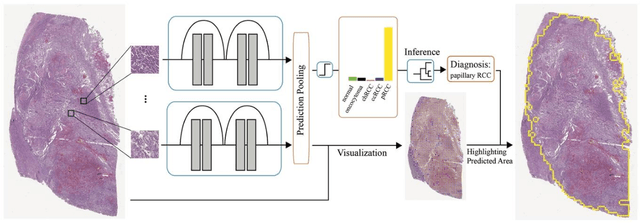
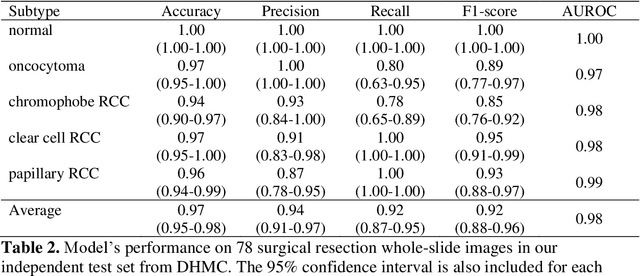
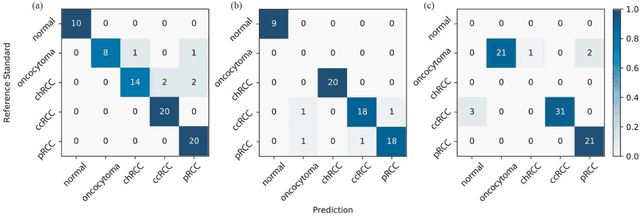
Renal cell carcinoma (RCC) is the most common renal cancer in adults. The histopathologic classification of RCC is essential for diagnosis, prognosis, and management of patients. Reorganization and classification of complex histologic patterns of RCC on biopsy and surgical resection slides under a microscope remains a heavily specialized, error-prone, and time-consuming task for pathologists. In this study, we developed a deep neural network model that can accurately classify digitized surgical resection slides and biopsy slides into five related classes: clear cell RCC, papillary RCC, chromophobe RCC, renal oncocytoma, and normal. In addition to the whole-slide classification pipeline, we visualized the identified indicative regions and features on slides for classification by reprocessing patch-level classification results to ensure the explainability of our diagnostic model. We evaluated our model on independent test sets of 78 surgical resection whole slides and 79 biopsy slides from our tertiary medical institution, and 69 randomly selected surgical resection slides from The Cancer Genome Atlas (TCGA) database. The average area under the curve (AUC) of our classifier on the internal resection slides, internal biopsy slides, and external TCGA slides is 0.98, 0.98 and 0.99, respectively. Our results suggest that the high generalizability of our approach across different data sources and specimen types. More importantly, our model has the potential to assist pathologists by (1) automatically pre-screening slides to reduce false-negative cases, (2) highlighting regions of importance on digitized slides to accelerate diagnosis, and (3) providing objective and accurate diagnosis as the second opinion.
FC-DCNN: A densely connected neural network for stereo estimation
Oct 14, 2020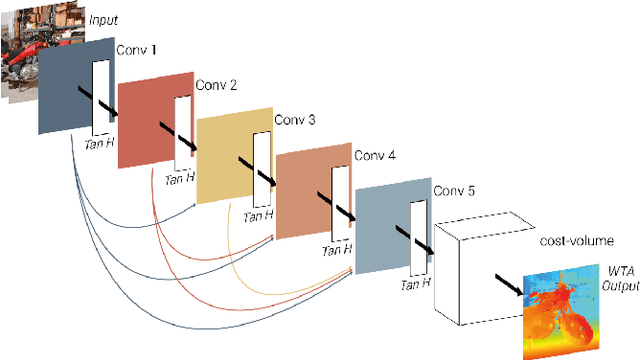


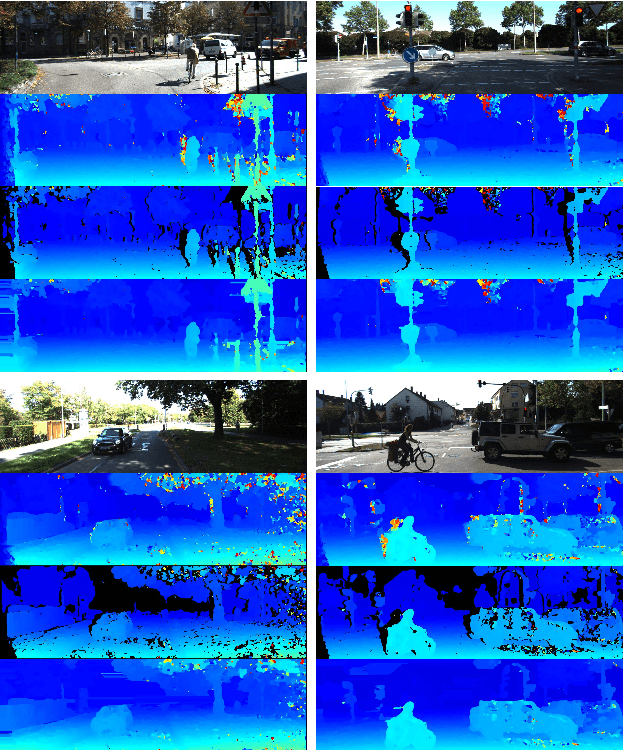
We propose a novel lightweight network for stereo estimation. Our network consists of a fully-convolutional densely connected neural network (FC-DCNN) that computes matching costs between rectified image pairs. Our FC-DCNN method learns expressive features and performs some simple but effective post-processing steps. The densely connected layer structure connects the output of each layer to the input of each subsequent layer. This network structure and the fact that we do not use any fully-connected layers or 3D convolutions leads to a very lightweight network. The output of this network is used in order to calculate matching costs and create a cost-volume. Instead of using time and memory-inefficient cost-aggregation methods such as semi-global matching or conditional random fields in order to improve the result, we rely on filtering techniques, namely median filter and guided filter. By computing a left-right consistency check we get rid of inconsistent values. Afterwards we use a watershed foreground-background segmentation on the disparity image with removed inconsistencies. This mask is then used to refine the final prediction. We show that our method works well for both challenging indoor and outdoor scenes by evaluating it on the Middlebury, KITTI and ETH3D benchmarks respectively. Our full framework is available at https://github.com/thedodo/FC-DCNN
Pair the Dots: Jointly Examining Training History and Test Stimuli for Model Interpretability
Oct 14, 2020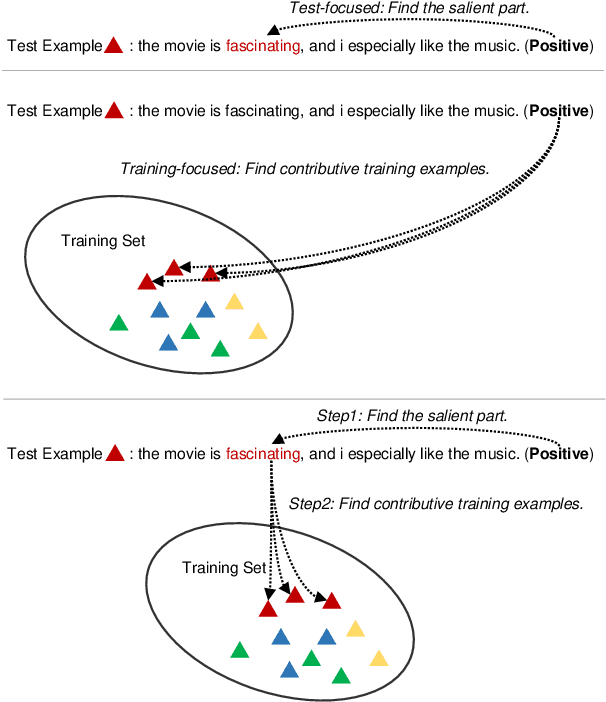
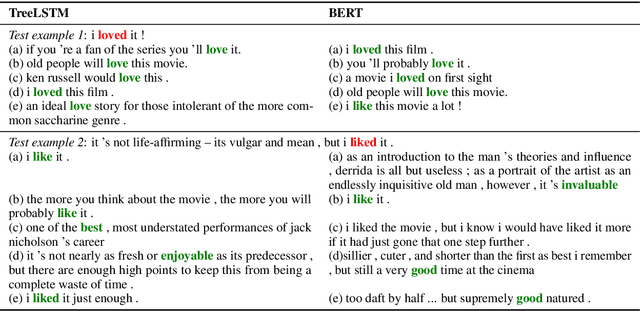

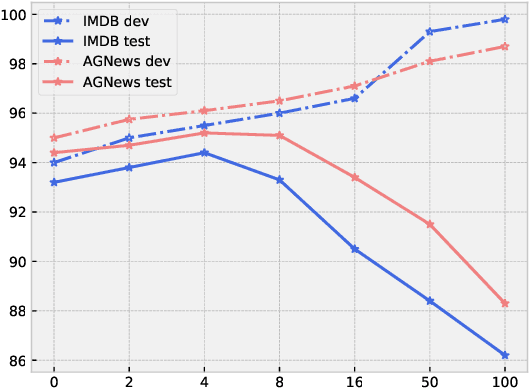
Any prediction from a model is made by a combination of learning history and test stimuli. This provides significant insights for improving model interpretability: {\it because of which part(s) of which training example(s), the model attends to which part(s) of a test example}. Unfortunately, existing methods to interpret a model's predictions are only able to capture a single aspect of either test stimuli or learning history, and evidences from both are never combined or integrated. In this paper, we propose an efficient and differentiable approach to make it feasible to interpret a model's prediction by jointly examining training history and test stimuli. Test stimuli is first identified by gradient-based methods, signifying {\it the part of a test example that the model attends to}. The gradient-based saliency scores are then propagated to training examples using influence functions to identify {\it which part(s) of which training example(s)} make the model attends to the test stimuli. The system is differentiable and time efficient: the adoption of saliency scores from gradient-based methods allows us to efficiently trace a model's prediction through test stimuli, and then back to training examples through influence functions. We demonstrate that the proposed methodology offers clear explanations about neural model decisions, along with being useful for performing error analysis, crafting adversarial examples and fixing erroneously classified examples.
e-SNLI-VE-2.0: Corrected Visual-Textual Entailment with Natural Language Explanations
Apr 22, 2020

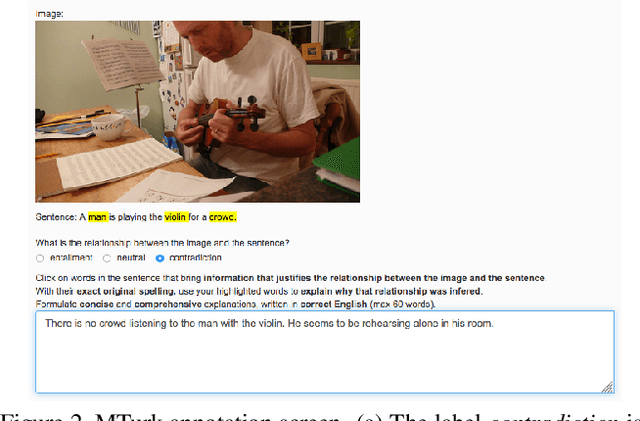
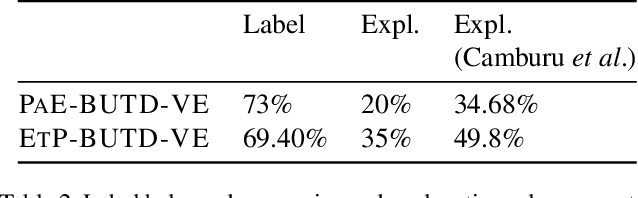
The recently proposed SNLI-VE corpus for recognising visual-textual entailment is a large, real-world dataset for fine-grained multimodal reasoning. However, the automatic way in which SNLI-VE has been assembled (via combining parts of two related datasets) gives rise to a large number of errors in the labels of this corpus. In this paper, we first present a data collection effort to correct the class with the highest error rate in SNLI-VE. Secondly, we re-evaluate an existing model on the corrected corpus, which we call SNLI-VE-2.0, and provide a quantitative comparison with its performance on the non-corrected corpus. Thirdly, we introduce e-SNLI-VE-2.0, which appends human-written natural language explanations to SNLI-VE-2.0. Finally, we train models that learn from these explanations at training time, and output such explanations at testing time.
Understanding Catastrophic Overfitting in Single-step Adversarial Training
Oct 05, 2020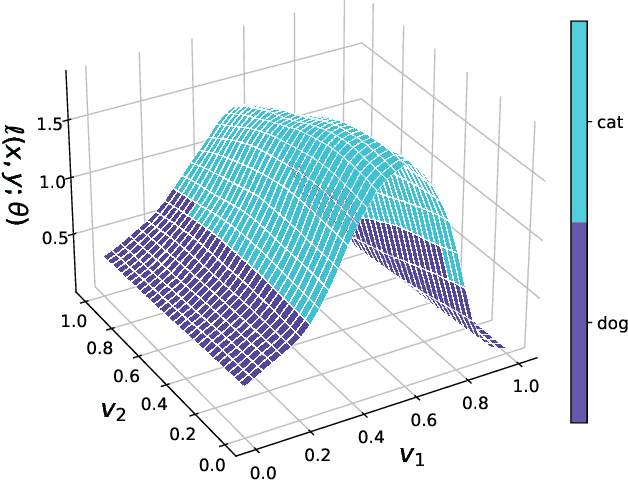
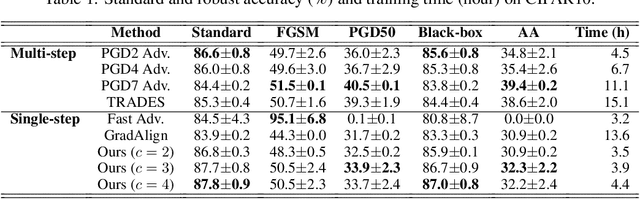
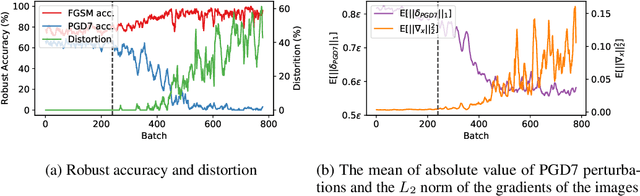
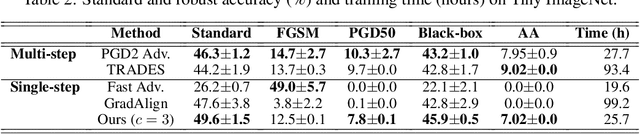
Adversarial examples are perturbed inputs that are designed to deceive machine-learning classifiers by adding adversarial perturbations to the original data. Although fast adversarial training have demonstrated both robustness and efficiency, the problem of "catastrophic overfitting" has been observed. It is a phenomenon that, during single-step adversarial training, the robust accuracy against projected gradient descent (PGD) suddenly decreases to 0% after few epochs, whereas the robustness against fast gradient sign method (FGSM) increases to 100%. In this paper, we address three main topics. (i) We demonstrate that catastrophic overfitting occurs in single-step adversarial training because it trains adversarial images with maximum perturbation only, not all adversarial examples in the adversarial direction, which leads to a distorted decision boundary and a highly curved loss surface. (ii) We experimentally prove this phenomenon by proposing a simple method using checkpoints. This method not only prevents catastrophic overfitting, but also overrides the belief that single-step adversarial training is hard to prevent multi-step attacks. (iii) We compare the performance of the proposed method to that obtained in recent works and demonstrate that it provides sufficient robustness to different attacks even after hundreds of training epochs in less time. All code for reproducing the experiments in this paper are at https://github.com/Harry24k/catastrophic-overfitting.
Physics-informed Neural Networks for Solving Inverse Problems of Nonlinear Biot's Equations: Batch Training
May 18, 2020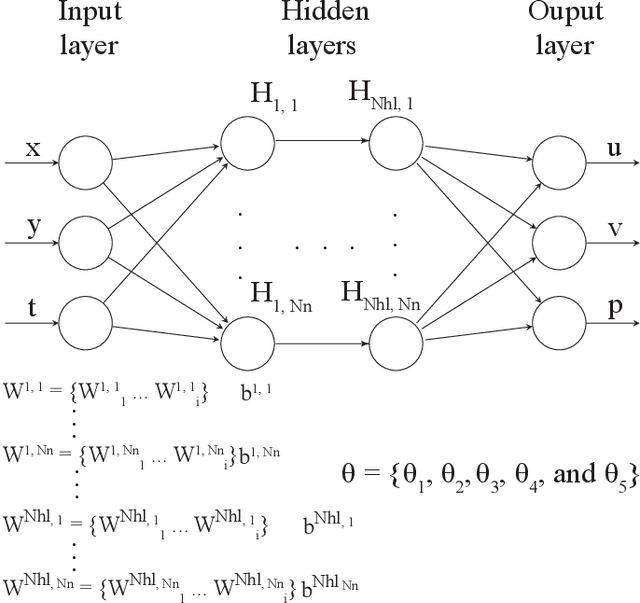
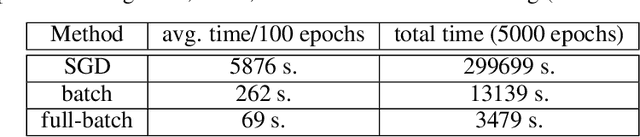
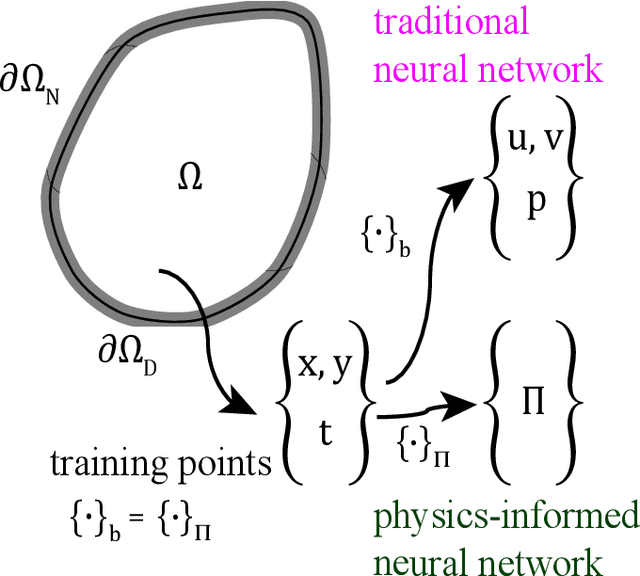

In biomedical engineering, earthquake prediction, and underground energy harvesting, it is crucial to indirectly estimate the physical properties of porous media since the direct measurement of those are usually impractical/prohibitive. Here we apply the physics-informed neural networks to solve the inverse problem with regard to the nonlinear Biot's equations. Specifically, we consider batch training and explore the effect of different batch sizes. The results show that training with small batch sizes, i.e., a few examples per batch, provides better approximations (lower percentage error) of the physical parameters than using large batches or the full batch. The increased accuracy of the physical parameters, comes at the cost of longer training time. Specifically, we find the size should not be too small since a very small batch size requires a very long training time without a corresponding improvement in estimation accuracy. We find that a batch size of 8 or 32 is a good compromise, which is also robust to additive noise in the data. The learning rate also plays an important role and should be used as a hyperparameter.
DANCE: Differentiable Accelerator/Network Co-Exploration
Sep 14, 2020
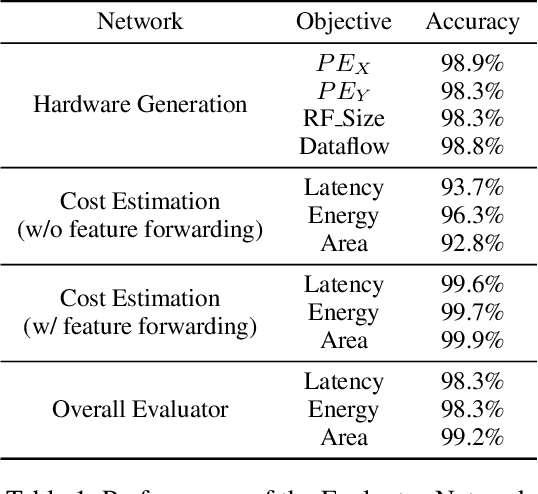
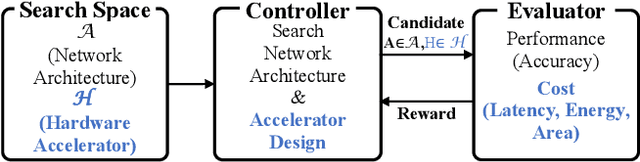
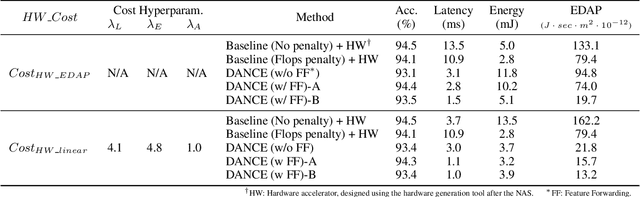
To cope with the ever-increasing computational demand of the DNN execution, recent neural architecture search (NAS) algorithms consider hardware cost metrics into account, such as GPU latency. To further pursue a fast, efficient execution, DNN-specialized hardware accelerators are being designed for multiple purposes, which far-exceeds the efficiency of the GPUs. However, those hardware-related metrics have been proven to exhibit non-linear relationships with the network architectures. Therefore it became a chicken-and-egg problem to optimize the network against the accelerator, or to optimize the accelerator against the network. In such circumstances, this work presents DANCE, a differentiable approach towards the co-exploration of the hardware accelerator and network architecture design. At the heart of DANCE is a differentiable evaluator network. By modeling the hardware evaluation software with a neural network, the relation between the accelerator architecture and the hardware metrics becomes differentiable, allowing the search to be performed with backpropagation. Compared to the naive existing approaches, our method performs co-exploration in a significantly shorter time, while achieving superior accuracy and hardware cost metrics.
Fast Bayesian Force Fields from Active Learning: Study of Inter-Dimensional Transformation of Stanene
Aug 26, 2020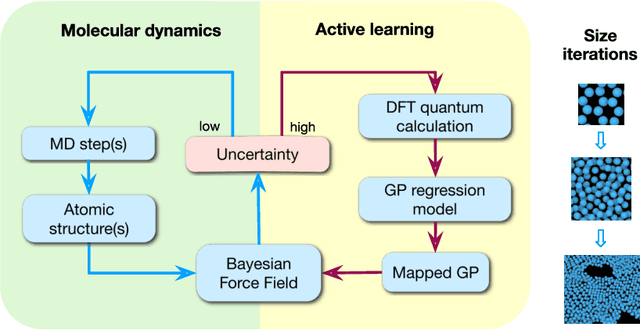
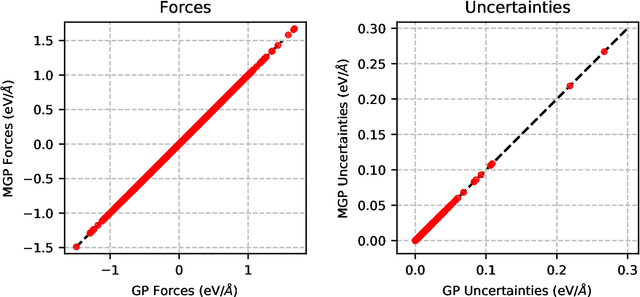
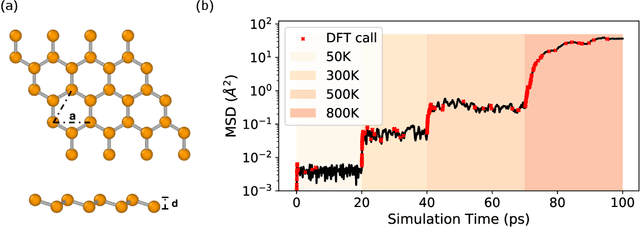
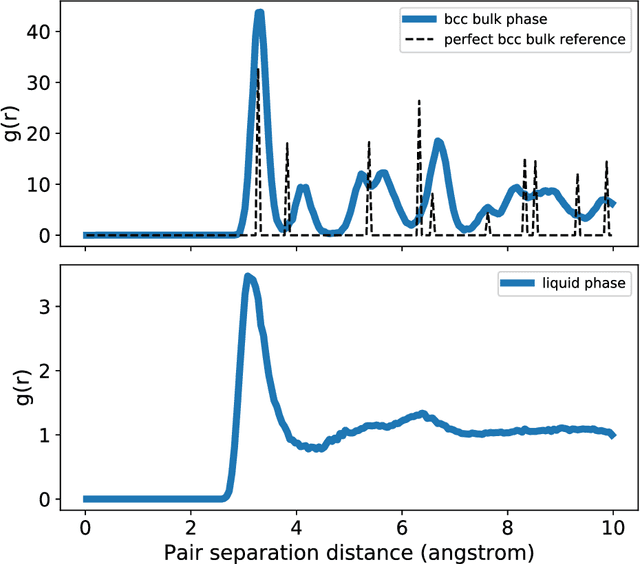
We present a way to dramatically accelerate Gaussian process models for interatomic force fields based on many-body kernels by mapping both forces and uncertainties onto functions of low-dimensional features. This allows for automated active learning of models combining near-quantum accuracy, built-in uncertainty, and constant cost of evaluation that is comparable to classical analytical models, capable of simulating millions of atoms. Using this approach, we perform large scale molecular dynamics simulations of the stability of the stanene monolayer. We discover an unusual phase transformation mechanism of 2D stanene, where ripples lead to nucleation of bilayer defects, densification into a disordered multilayer structure, followed by formation of bulk liquid at high temperature or nucleation and growth of the 3D bcc crystal at low temperature. The presented method opens possibilities for rapid development of fast accurate uncertainty-aware models for simulating long-time large-scale dynamics of complex materials.