 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Human-centric Dialog Training via Offline Reinforcement Learning
Oct 12, 2020
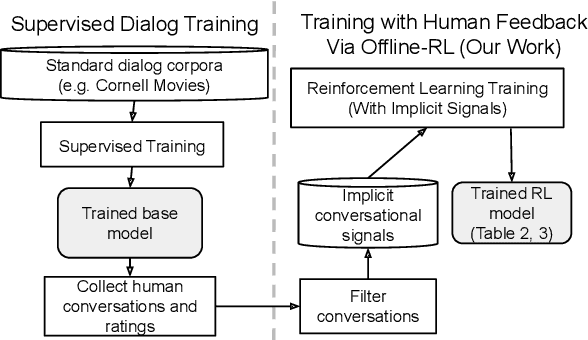
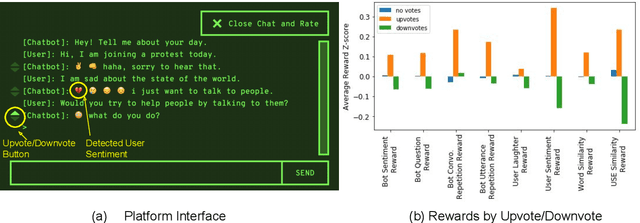
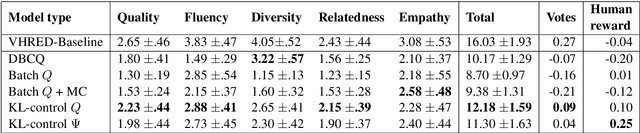
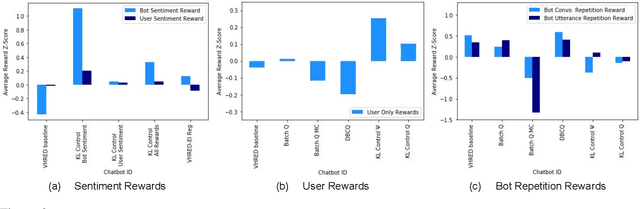
How can we train a dialog model to produce better conversations by learning from human feedback, without the risk of humans teaching it harmful chat behaviors? We start by hosting models online, and gather human feedback from real-time, open-ended conversations, which we then use to train and improve the models using offline reinforcement learning (RL). We identify implicit conversational cues including language similarity, elicitation of laughter, sentiment, and more, which indicate positive human feedback, and embed these in multiple reward functions. A well-known challenge is that learning an RL policy in an offline setting usually fails due to the lack of ability to explore and the tendency to make over-optimistic estimates of future reward. These problems become even harder when using RL for language models, which can easily have a 20,000 action vocabulary and many possible reward functions. We solve the challenge by developing a novel class of offline RL algorithms. These algorithms use KL-control to penalize divergence from a pre-trained prior language model, and use a new strategy to make the algorithm pessimistic, instead of optimistic, in the face of uncertainty. We test the resulting dialog model with ratings from 80 users in an open-domain setting and find it achieves significant improvements over existing deep offline RL approaches. The novel offline RL method is viable for improving any existing generative dialog model using a static dataset of human feedback.
Competing AI: How competition feedback affects machine learning
Sep 15, 2020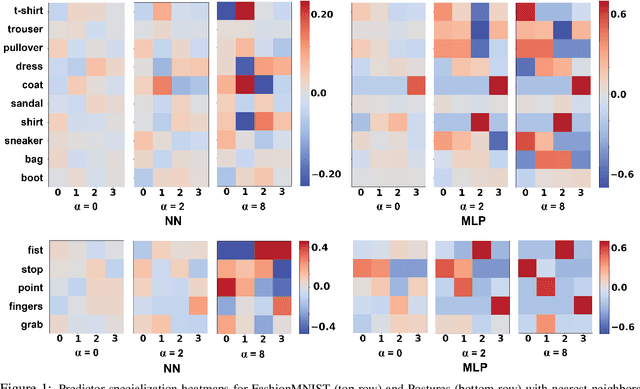
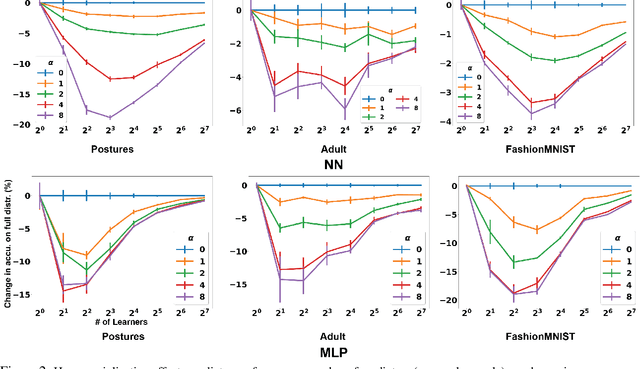
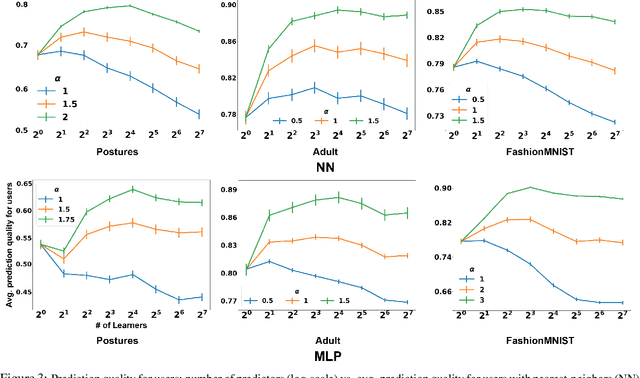
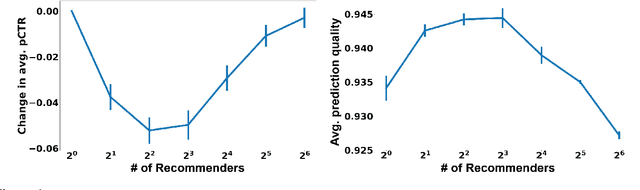
This papers studies how competition affects machine learning (ML) predictors. As ML becomes more ubiquitous, it is often deployed by companies to compete over customers. For example, digital platforms like Yelp use ML to predict user preference and make recommendations. A service that is more often queried by users, perhaps because it more accurately anticipates user preferences, is also more likely to obtain additional user data (e.g. in the form of a Yelp review). Thus, competing predictors cause feedback loops whereby a predictor's performance impacts what training data it receives and biases its predictions over time. We introduce a flexible model of competing ML predictors that enables both rapid experimentation and theoretical tractability. We show with empirical and mathematical analysis that competition causes predictors to specialize for specific sub-populations at the cost of worse performance over the general population. We further analyze the impact of predictor specialization on the overall prediction quality experienced by users. We show that having too few or too many competing predictors in a market can hurt the overall prediction quality. Our theory is complemented by experiments on several real datasets using popular learning algorithms, such as neural networks and nearest neighbor methods.
Quantum Boosting
Feb 12, 2020Suppose we have a weak learning algorithm $\mathcal{A}$ for a Boolean-valued problem: $\mathcal{A}$ produces hypotheses whose bias $\gamma$ is small, only slightly better than random guessing (this could, for instance, be due to implementing $\mathcal{A}$ on a noisy device), can we boost the performance of $\mathcal{A}$ so that $\mathcal{A}$'s output is correct on $2/3$ of the inputs? Boosting is a technique that converts a weak and inaccurate machine learning algorithm into a strong accurate learning algorithm. The AdaBoost algorithm by Freund and Schapire (for which they were awarded the G\"odel prize in 2003) is one of the widely used boosting algorithms, with many applications in theory and practice. Suppose we have a $\gamma$-weak learner for a Boolean concept class $C$ that takes time $R(C)$, then the time complexity of AdaBoost scales as $VC(C)\cdot poly(R(C), 1/\gamma)$, where $VC(C)$ is the $VC$-dimension of $C$. In this paper, we show how quantum techniques can improve the time complexity of classical AdaBoost. To this end, suppose we have a $\gamma$-weak quantum learner for a Boolean concept class $C$ that takes time $Q(C)$, we introduce a quantum boosting algorithm whose complexity scales as $\sqrt{VC(C)}\cdot poly(Q(C),1/\gamma);$ thereby achieving a quadratic quantum improvement over classical AdaBoost in terms of $VC(C)$.
Decoupling Representation Learning from Reinforcement Learning
Sep 14, 2020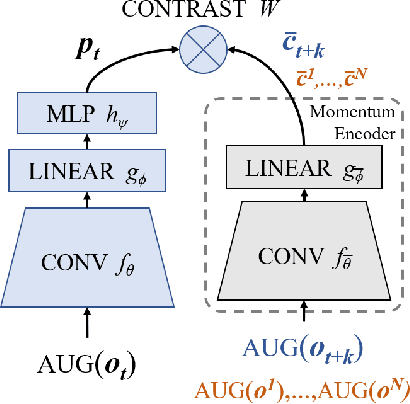

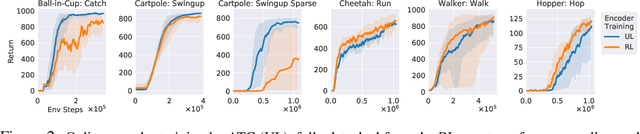
In an effort to overcome limitations of reward-driven feature learning in deep reinforcement learning (RL) from images, we propose decoupling representation learning from policy learning. To this end, we introduce a new unsupervised learning (UL) task, called Augmented Temporal Contrast (ATC), which trains a convolutional encoder to associate pairs of observations separated by a short time difference, under image augmentations and using a contrastive loss. In online RL experiments, we show that training the encoder exclusively using ATC matches or outperforms end-to-end RL in most environments. Additionally, we benchmark several leading UL algorithms by pre-training encoders on expert demonstrations and using them, with weights frozen, in RL agents; we find that agents using ATC-trained encoders outperform all others. We also train multi-task encoders on data from multiple environments and show generalization to different downstream RL tasks. Finally, we ablate components of ATC, and introduce a new data augmentation to enable replay of (compressed) latent images from pre-trained encoders when RL requires augmentation. Our experiments span visually diverse RL benchmarks in DeepMind Control, DeepMind Lab, and Atari, and our complete code is available at https://github.com/astooke/rlpyt/rlpyt/ul.
A Gradient Flow Framework For Analyzing Network Pruning
Sep 24, 2020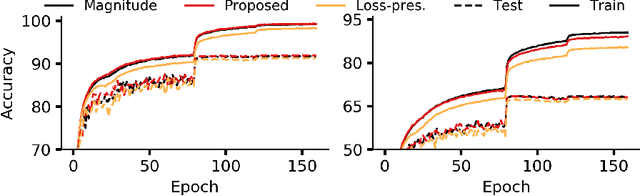
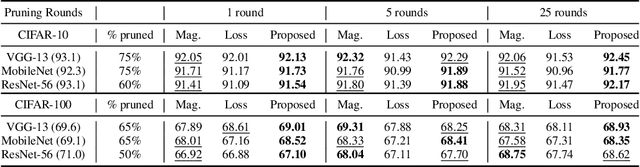
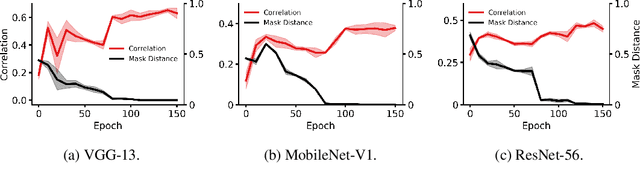
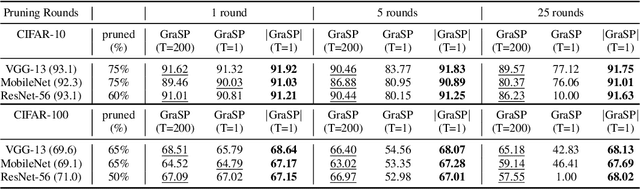
Recent network pruning methods focus on pruning models early-on in training. To estimate the impact of removing a parameter, these methods use importance measures that were originally designed for pruning trained models. Despite lacking justification for their use early-on in training, models pruned using such measures result in surprisingly minimal accuracy loss. To better explain this behavior, we develop a general, gradient-flow based framework that relates state-of-the-art importance measures through an order of time-derivative of the norm of model parameters. We use this framework to determine the relationship between pruning measures and evolution of model parameters, establishing several findings related to pruning models early-on in training: (i) magnitude-based pruning removes parameters that contribute least to reduction in loss, resulting in models that converge faster than magnitude-agnostic methods; (ii) loss-preservation based pruning preserves first-order model evolution dynamics and is well-motivated for pruning minimally trained models; and (iii) gradient-norm based pruning affects second-order model evolution dynamics, and increasing gradient norm via pruning can produce poorly performing models. We validate our claims on several VGG-13, MobileNet-V1, and ResNet-56 models trained on CIFAR-10 and CIFAR-100. Code available at https://github.com/EkdeepSLubana/flowandprune.
Dual-Mandate Patrols: Multi-Armed Bandits for Green Security
Sep 14, 2020


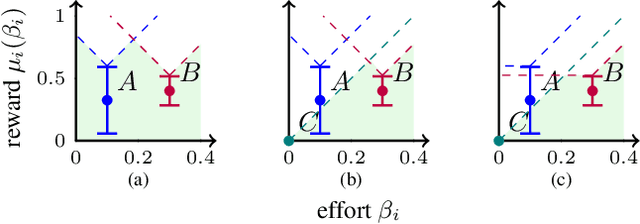
Conservation efforts in green security domains to protect wildlife and forests are constrained by the limited availability of defenders (i.e., patrollers), who must patrol vast areas to protect from attackers (e.g., poachers or illegal loggers). Defenders must choose how much time to spend in each region of the protected area, balancing exploration of infrequently visited regions and exploitation of known hotspots. We formulate the problem as a stochastic multi-armed bandit, where each action represents a patrol strategy, enabling us to guarantee the rate of convergence of the patrolling policy. However, a naive bandit approach would compromise short-term performance for long-term optimality, resulting in animals poached and forests destroyed. To speed up performance, we leverage smoothness in the reward function and decomposability of actions. We show a synergy between Lipschitz-continuity and decomposition as each aids the convergence of the other. In doing so, we bridge the gap between combinatorial and Lipschitz bandits, presenting a no-regret approach that tightens existing guarantees while optimizing for short-term performance. We demonstrate that our algorithm, LIZARD, improves performance on real-world poaching data from Cambodia.
Temporal Answer Set Programming
Sep 14, 2020
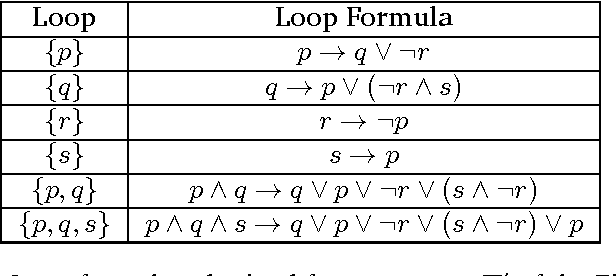
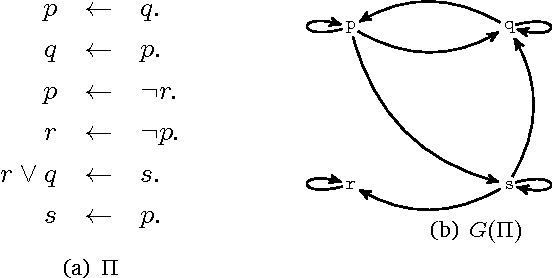
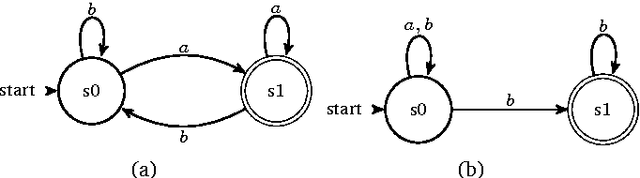
We present an overview on Temporal Logic Programming under the perspective of its application for Knowledge Representation and declarative problem solving. Such programs are the result of combining usual rules with temporal modal operators, as in Linear-time Temporal Logic (LTL). We focus on recent results of the non-monotonic formalism called Temporal Equilibrium Logic (TEL) that is defined for the full syntax of LTL, but performs a model selection criterion based on Equilibrium Logic, a well known logical characterization of Answer Set Programming (ASP). We obtain a proper extension of the stable models semantics for the general case of arbitrary temporal formulas. We recall the basic definitions for TEL and its monotonic basis, the temporal logic of Here-and-There (THT), and study the differences between infinite and finite traces. We also provide other useful results, such as the translation into other formalisms like Quantified Equilibrium Logic or Second-order LTL, and some techniques for computing temporal stable models based on automata. In a second part, we focus on practical aspects, defining a syntactic fragment called temporal logic programs closer to ASP, and explain how this has been exploited in the construction of the solver TELINGO.
Explaining Neural Matrix Factorization with Gradient Rollback
Oct 12, 2020



Explaining the predictions of neural black-box models is an important problem, especially when such models are used in applications where user trust is crucial. Estimating the influence of training examples on a learned neural model's behavior allows us to identify training examples most responsible for a given prediction and, therefore, to faithfully explain the output of a black-box model. The most generally applicable existing method is based on influence functions, which scale poorly for larger sample sizes and models. We propose gradient rollback, a general approach for influence estimation, applicable to neural models where each parameter update step during gradient descent touches a smaller number of parameters, even if the overall number of parameters is large. Neural matrix factorization models trained with gradient descent are part of this model class. These models are popular and have found a wide range of applications in industry. Especially knowledge graph embedding methods, which belong to this class, are used extensively. We show that gradient rollback is highly efficient at both training and test time. Moreover, we show theoretically that the difference between gradient rollback's influence approximation and the true influence on a model's behavior is smaller than known bounds on the stability of stochastic gradient descent. This establishes that gradient rollback is robustly estimating example influence. We also conduct experiments which show that gradient rollback provides faithful explanations for knowledge base completion and recommender datasets. An implementation is available in the submission system.
Joint Modeling of Event Sequence and Time Series with Attentional Twin Recurrent Neural Networks
Mar 24, 2017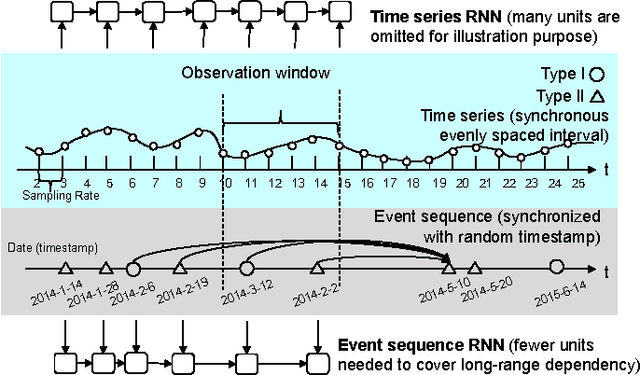
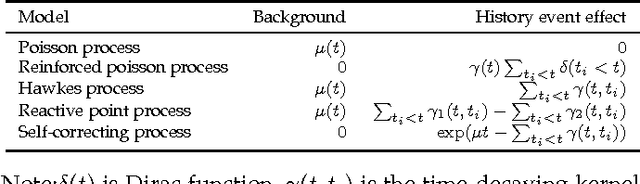
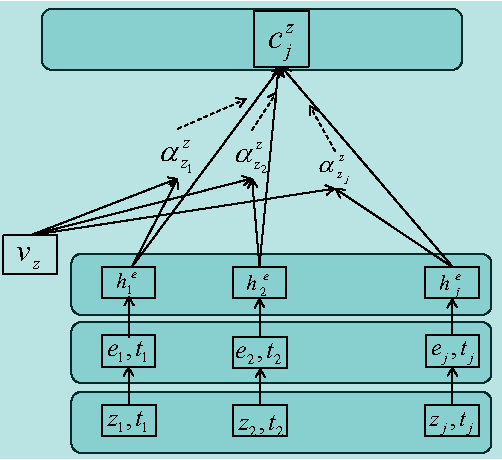
A variety of real-world processes (over networks) produce sequences of data whose complex temporal dynamics need to be studied. More especially, the event timestamps can carry important information about the underlying network dynamics, which otherwise are not available from the time-series evenly sampled from continuous signals. Moreover, in most complex processes, event sequences and evenly-sampled times series data can interact with each other, which renders joint modeling of those two sources of data necessary. To tackle the above problems, in this paper, we utilize the rich framework of (temporal) point processes to model event data and timely update its intensity function by the synergic twin Recurrent Neural Networks (RNNs). In the proposed architecture, the intensity function is synergistically modulated by one RNN with asynchronous events as input and another RNN with time series as input. Furthermore, to enhance the interpretability of the model, the attention mechanism for the neural point process is introduced. The whole model with event type and timestamp prediction output layers can be trained end-to-end and allows a black-box treatment for modeling the intensity. We substantiate the superiority of our model in synthetic data and three real-world benchmark datasets.
Early Bird: Loop Closures from Opposing Viewpoints for Perceptually-Aliased Indoor Environments
Oct 03, 2020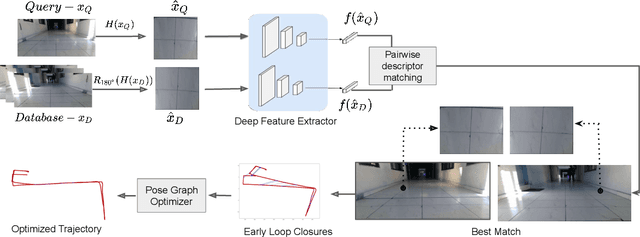


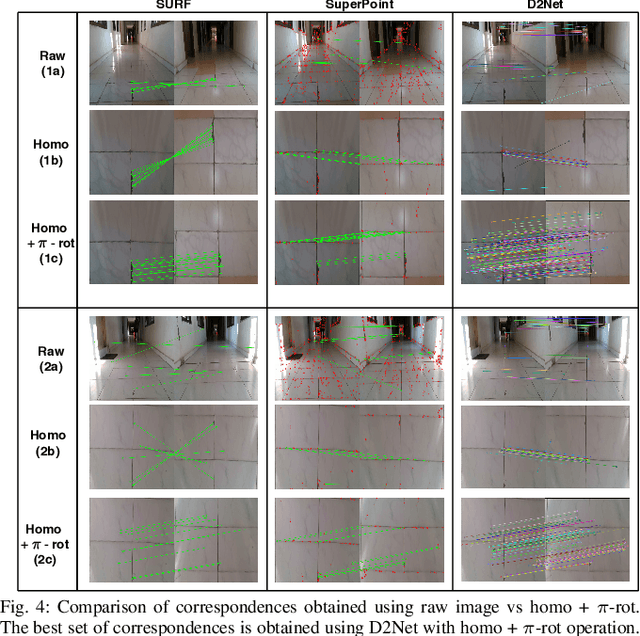
Significant advances have been made recently in Visual Place Recognition (VPR), feature correspondence, and localization due to the proliferation of deep-learning-based methods. However, existing approaches tend to address, partially or fully, only one of two key challenges: viewpoint change and perceptual aliasing. In this paper, we present novel research that simultaneously addresses both challenges by combining deep-learned features with geometric transformations based on reasonable domain assumptions about navigation on a ground-plane, whilst also removing the requirement for specialized hardware setup (e.g. lighting, downwards facing cameras). In particular, our integration of VPR with SLAM by leveraging the robustness of deep-learned features and our homography-based extreme viewpoint invariance significantly boosts the performance of VPR, feature correspondence, and pose graph submodules of the SLAM pipeline. For the first time, we demonstrate a localization system capable of state-of-the-art performance despite perceptual aliasing and extreme 180-degree-rotated viewpoint change in a range of real-world and simulated experiments. Our system is able to achieve early loop closures that prevent significant drifts in SLAM trajectories. We also compare extensively several deep architectures for VPR and descriptor matching. We also show that superior place recognition and descriptor matching across opposite views results in a similar performance gain in back-end pose graph optimization.