 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Eating Habits Discovery in Egocentric Photo-streams
Sep 16, 2020


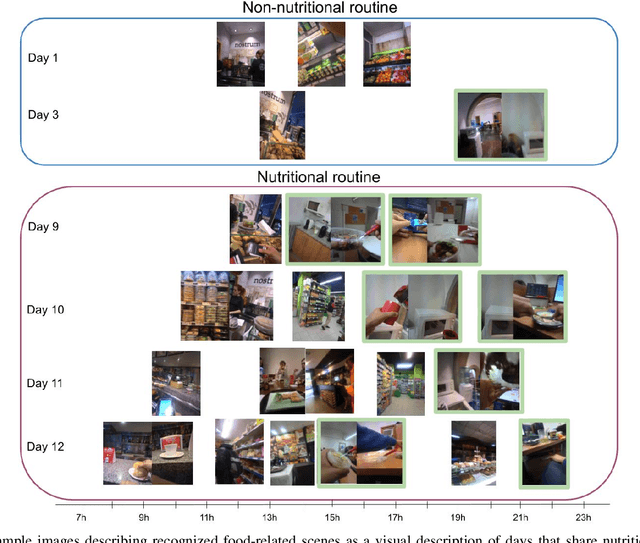
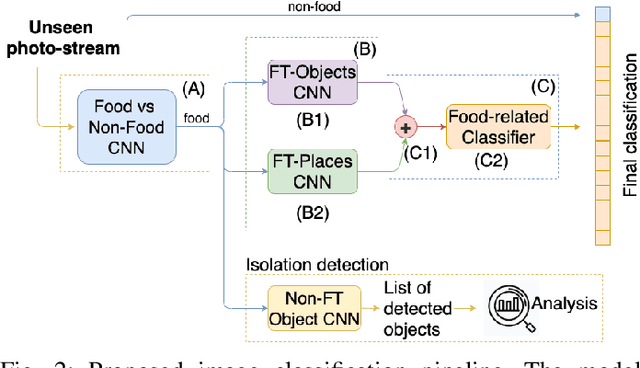
Eating habits are learned throughout the early stages of our lives. However, it is not easy to be aware of how our food-related routine affects our healthy living. In this work, we address the unsupervised discovery of nutritional habits from egocentric photo-streams. We build a food-related behavioural pattern discovery model, which discloses nutritional routines from the activities performed throughout the days. To do so, we rely on Dynamic-Time-Warping for the evaluation of similarity among the collected days. Within this framework, we present a simple, but robust and fast novel classification pipeline that outperforms the state-of-the-art on food-related image classification with a weighted accuracy and F-score of 70% and 63%, respectively. Later, we identify days composed of nutritional activities that do not describe the habits of the person as anomalies in the daily life of the user with the Isolation Forest method. Furthermore, we show an application for the identification of food-related scenes when the camera wearer eats in isolation. Results have shown the good performance of the proposed model and its relevance to visualize the nutritional habits of individuals.
COVID-19 in CXR: from Detection and Severity Scoring to Patient Disease Monitoring
Aug 04, 2020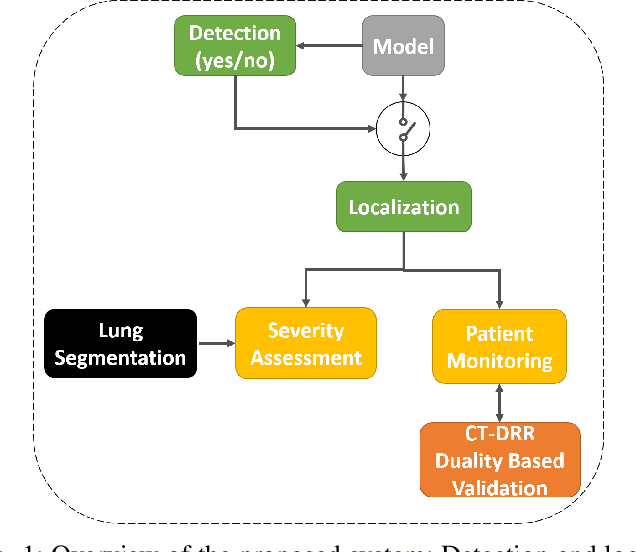
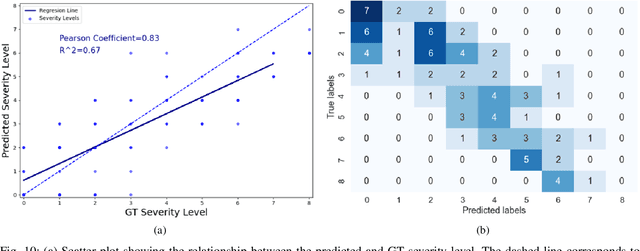
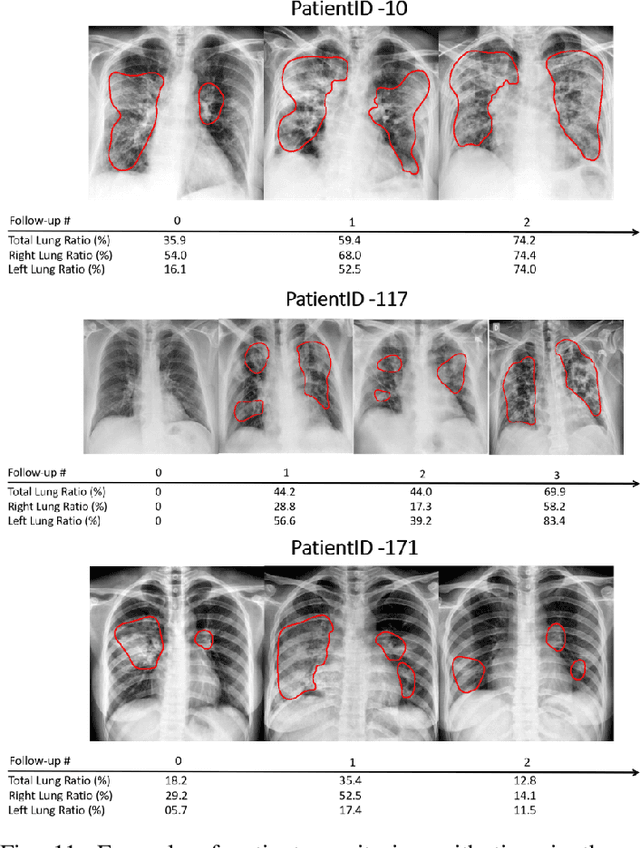
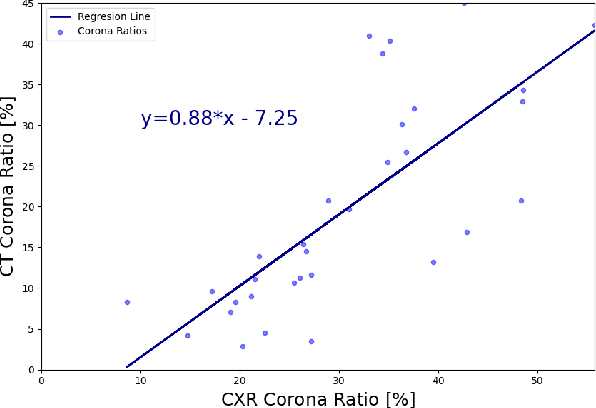
In this work, we estimate the severity of pneumonia in COVID-19 patients and conduct a longitudinal study of disease progression. To achieve this goal, we developed a deep learning model for simultaneous detection and segmentation of pneumonia in chest Xray (CXR) images and generalized to COVID-19 pneumonia. The segmentations were utilized to calculate a "Pneumonia Ratio" which indicates the disease severity. The measurement of disease severity enables to build a disease extent profile over time for hospitalized patients. To validate the model relevance to the patient monitoring task, we developed a validation strategy which involves a synthesis of Digital Reconstructed Radiographs (DRRs - synthetic Xray) from serial CT scans; we then compared the disease progression profiles that were generated from the DRRs to those that were generated from CT volumes.
The Umbrella software suite for automated asteroid detection
Aug 11, 2020
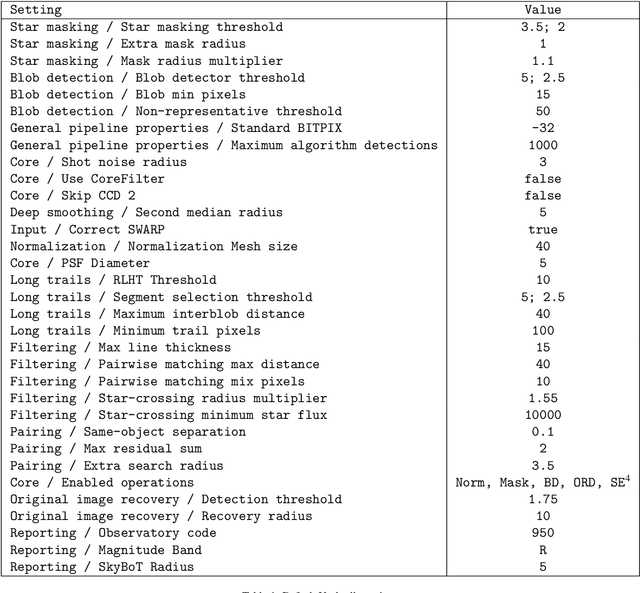

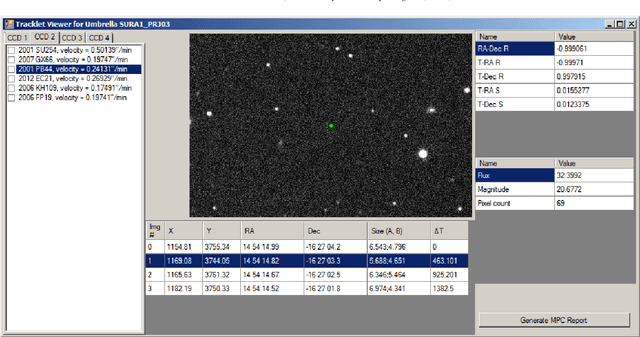
We present the Umbrella software suite for asteroid detection, validation, identification and reporting. The current core of Umbrella is an open-source modular library, called Umbrella2, that includes algorithms and interfaces for all steps of the processing pipeline, including a novel detection algorithm for faint trails. Building on the library, we have also implemented a detection pipeline accessible both as a desktop program (ViaNearby) and via a web server (Webrella), which we have successfully used in near real-time data reduction of a few asteroid surveys on the Wide Field Camera of the Isaac Newton Telescope. In this paper we describe the library, focusing on the interfaces and algorithms available, and we present the results obtained with the desktop version on a set of well-curated fields used by the EURONEAR project as an asteroid detection benchmark.
Efficient Design of Neural Networks with Random Weights
Aug 24, 2020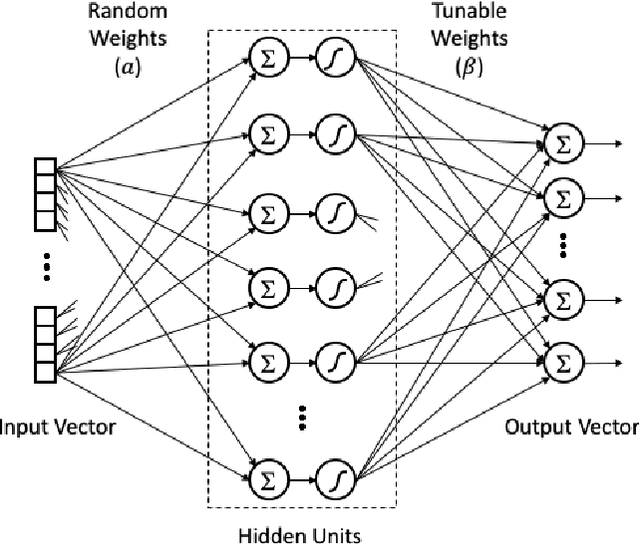
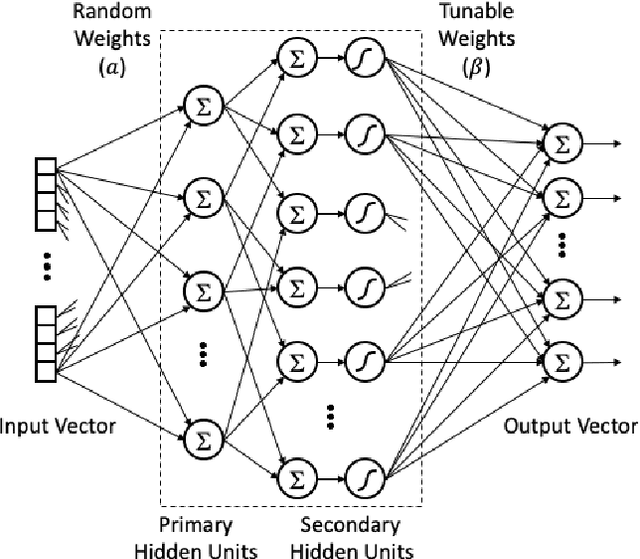
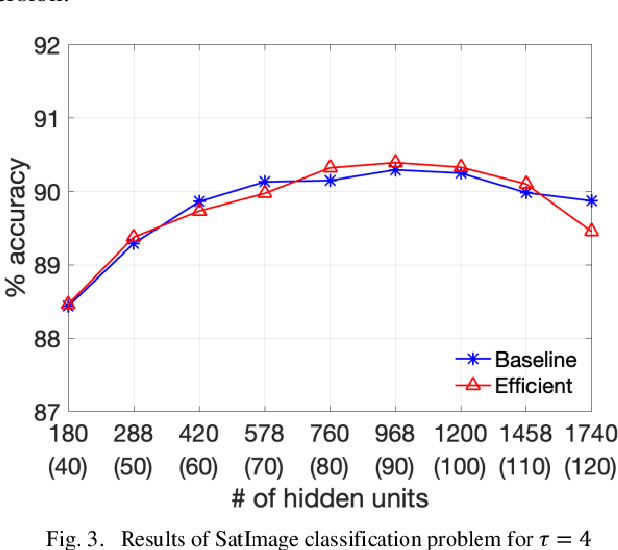
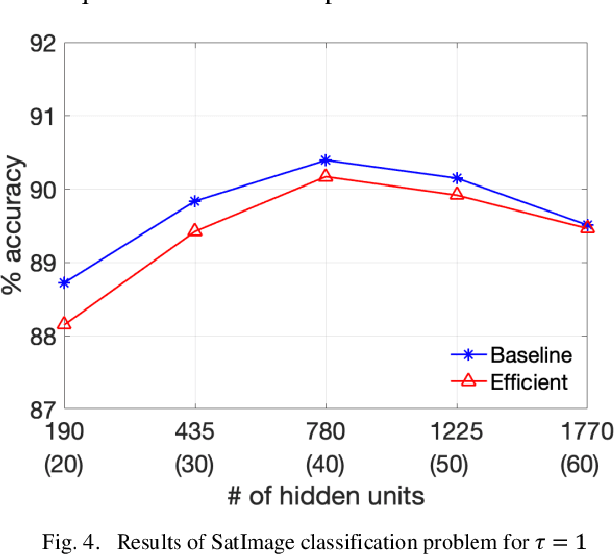
Single layer feedforward networks with random weights are known for their non-iterative and fast training algorithms and are successful in a variety of classification and regression problems. A major drawback of these networks is that they require a large number of hidden units. In this paper, we propose a technique to reduce the number of hidden units substantially without affecting the accuracy of the networks significantly. We introduce the concept of primary and secondary hidden units. The weights for the primary hidden units are chosen randomly while the secondary hidden units are derived using pairwise combinations of the primary hidden units. Using this technique, we show that the number of hidden units can be reduced by at least one order of magnitude. We experimentally show that this technique leads to significant drop in computations at inference time and has only a minor impact on network accuracy. A huge reduction in computations is possible if slightly lower accuracy is acceptable.
Tramp Ship Scheduling Problem with Berth Allocation Considerations and Time-dependent Constraints
May 04, 2017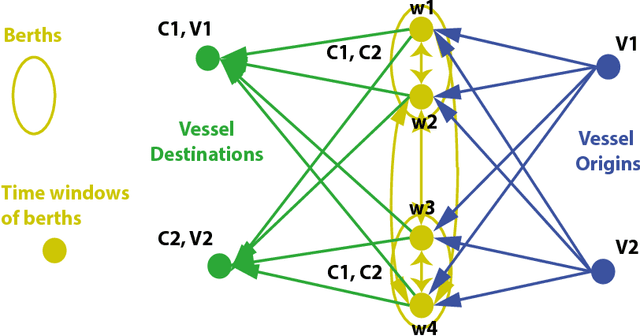


This work presents a model for the Tramp Ship Scheduling problem including berth allocation considerations, motivated by a real case of a shipping company. The aim is to determine the travel schedule for each vessel considering multiple docking and multiple time windows at the berths. This work is innovative due to the consideration of both spatial and temporal attributes during the scheduling process. The resulting model is formulated as a mixed-integer linear programming problem, and a heuristic method to deal with multiple vessel schedules is also presented. Numerical experimentation is performed to highlight the benefits of the proposed approach and the applicability of the heuristic. Conclusions and recommendations for further research are provided.
Monocular Rotational Odometry with Incremental Rotation Averaging and Loop Closure
Oct 05, 2020
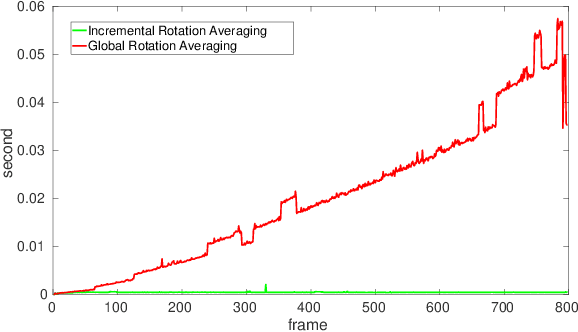
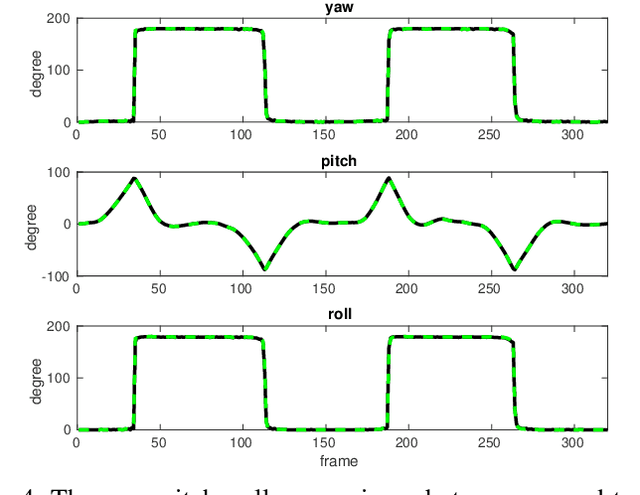
Estimating absolute camera orientations is essential for attitude estimation tasks. An established approach is to first carry out visual odometry (VO) or visual SLAM (V-SLAM), and retrieve the camera orientations (3 DOF) from the camera poses (6 DOF) estimated by VO or V-SLAM. One drawback of this approach, besides the redundancy in estimating full 6 DOF camera poses, is the dependency on estimating a map (3D scene points) jointly with the 6 DOF poses due to the basic constraint on structure-and-motion. To simplify the task of absolute orientation estimation, we formulate the monocular rotational odometry problem and devise a fast algorithm to accurately estimate camera orientations with 2D-2D feature matches alone. Underpinning our system is a new incremental rotation averaging method for fast and constant time iterative updating. Furthermore, our system maintains a view-graph that 1) allows solving loop closure to remove camera orientation drift, and 2) can be used to warm start a V-SLAM system. We conduct extensive quantitative experiments on real-world datasets to demonstrate the accuracy of our incremental camera orientation solver. Finally, we showcase the benefit of our algorithm to V-SLAM: 1) solving the known rotation problem to estimate the trajectory of the camera and the surrounding map, and 2)enabling V-SLAM systems to track pure rotational motions.
Dense-View GEIs Set: View Space Covering for Gait Recognition based on Dense-View GAN
Sep 26, 2020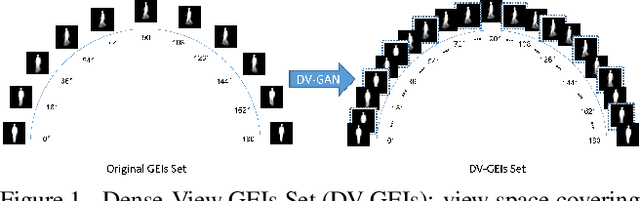
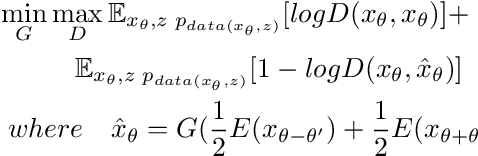
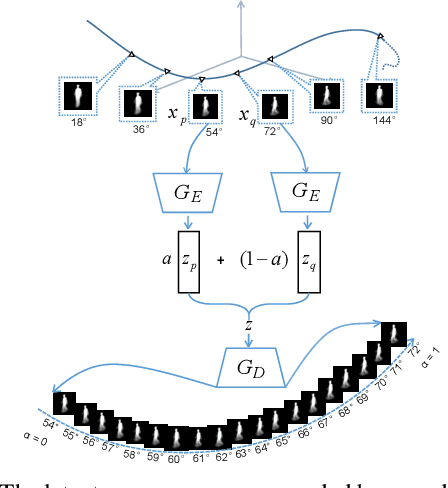

Gait recognition has proven to be effective for long-distance human recognition. But view variance of gait features would change human appearance greatly and reduce its performance. Most existing gait datasets usually collect data with a dozen different angles, or even more few. Limited view angles would prevent learning better view invariant feature. It can further improve robustness of gait recognition if we collect data with various angles at 1 degree interval. But it is time consuming and labor consuming to collect this kind of dataset. In this paper, we, therefore, introduce a Dense-View GEIs Set (DV-GEIs) to deal with the challenge of limited view angles. This set can cover the whole view space, view angle from 0 degree to 180 degree with 1 degree interval. In addition, Dense-View GAN (DV-GAN) is proposed to synthesize this dense view set. DV-GAN consists of Generator, Discriminator and Monitor, where Monitor is designed to preserve human identification and view information. The proposed method is evaluated on the CASIA-B and OU-ISIR dataset. The experimental results show that DV-GEIs synthesized by DV-GAN is an effective way to learn better view invariant feature. We believe the idea of dense view generated samples will further improve the development of gait recognition.
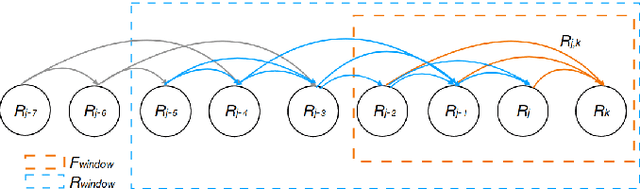
Efficient Derivative Computation for Cumulative B-Splines on Lie Groups
Nov 20, 2019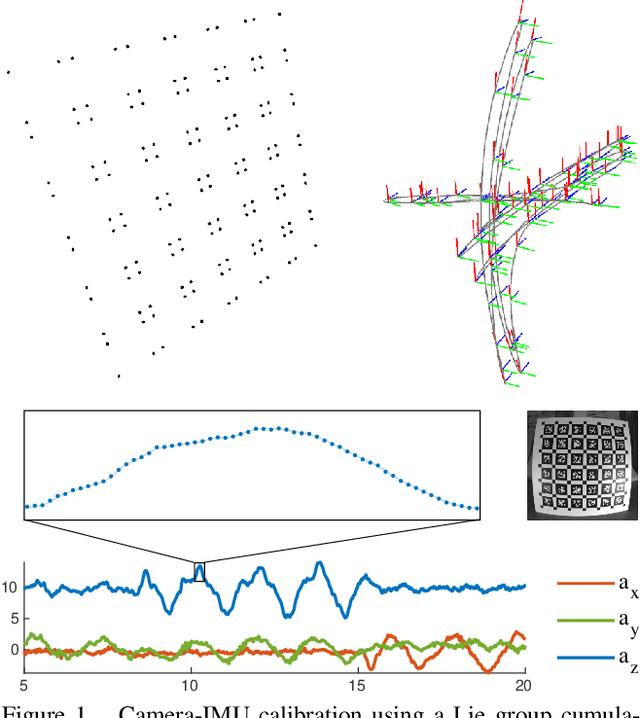
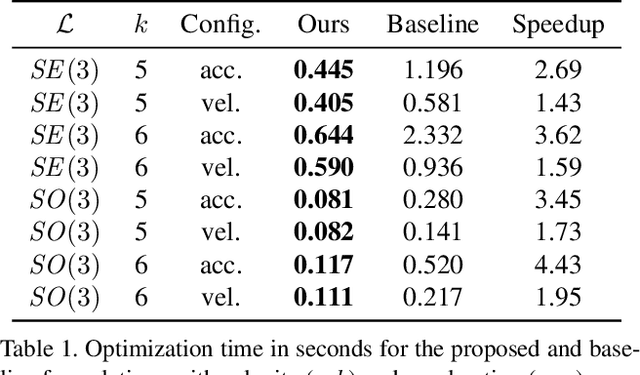


Continuous-time trajectory representation has recently gained popularity for tasks where the fusion of high-frame-rate sensors and multiple unsynchronized devices is required. Lie group cumulative B-splines are a popular way of representing continuous trajectories without singularities. They have been used in near real-time SLAM and odometry systems with IMU, LiDAR, regular, RGB-D and event cameras, as well as for offline calibration. These applications require efficient computation of time derivatives (velocity, acceleration), but all prior works rely on a computationally suboptimal formulation. In this work we present an alternative derivation of time derivatives based on recurrence relations that needs $\mathcal{O}(k)$ instead of $\mathcal{O}(k^2)$ matrix operations (for a spline of order $k$) and results in simple and elegant expressions. While producing the same result, the proposed approach significantly speeds up the trajectory optimization and allows for computing simple analytic derivatives with respect to spline knots. The results presented in this paper pave the way for incorporating continuous-time trajectory representations into more applications where real-time performance is required.
HEX and Neurodynamic Programming
Aug 11, 2020
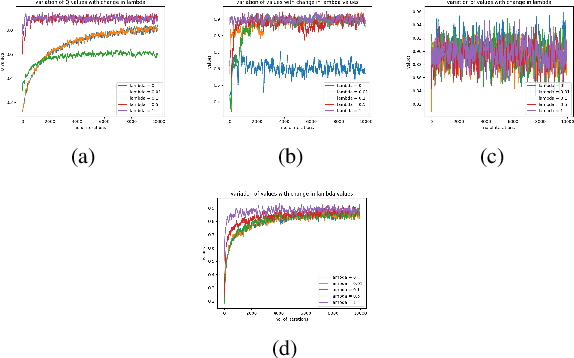
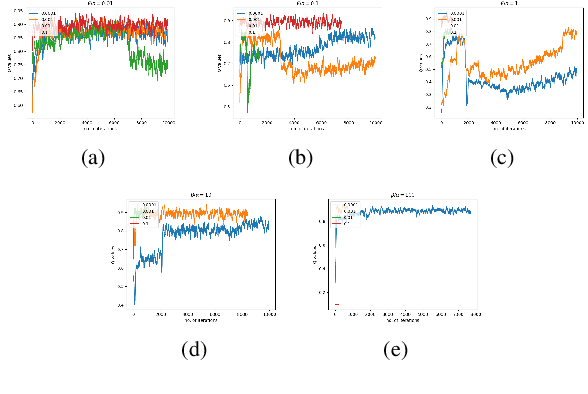
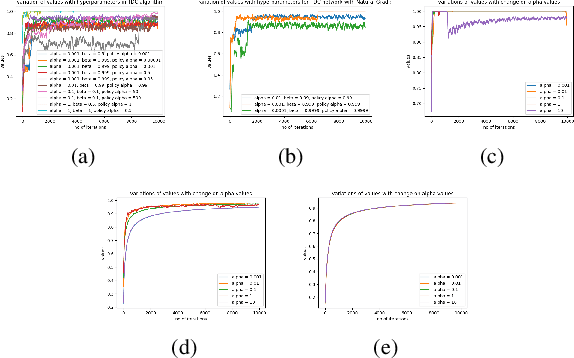
Hex is a complex game with a high branching factor. For the first time Hex is being attempted to be solved without the use of game tree structures and associated methods of pruning. We also are abstaining from any heuristic information about Virtual Connections or Semi Virtual Connections which were previously used in all previous known computer versions of the game. The H-search algorithm which was the basis of finding such connections and had been used with success in previous Hex playing agents has been forgone. Instead what we use is reinforcement learning through self play and approximations through neural networks to by pass the problem of high branching factor and maintaining large tables for state-action evaluations. Our code is based primarily on NeuroHex. The inspiration is drawn from the recent success of AlphaGo Zero.
What is SemEval evaluating? A Systematic Analysis of Evaluation Campaigns in NLP
May 28, 2020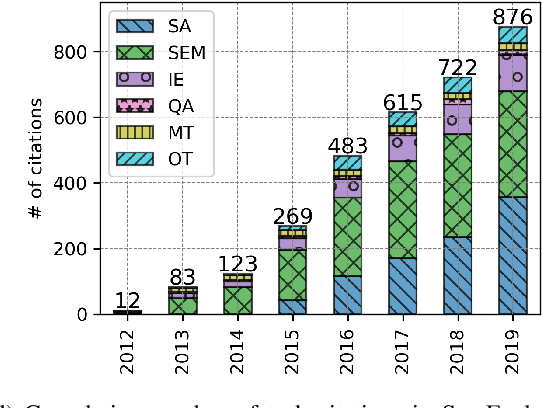
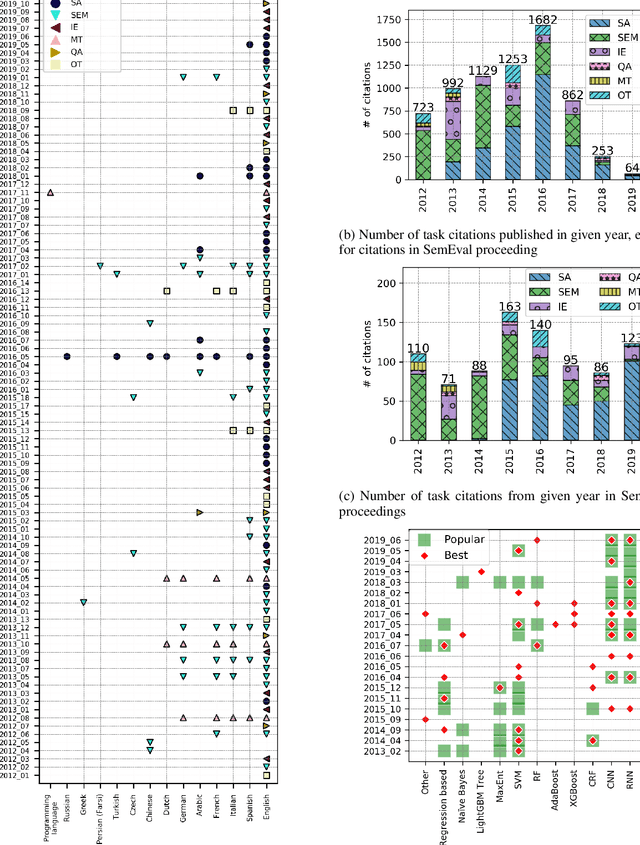
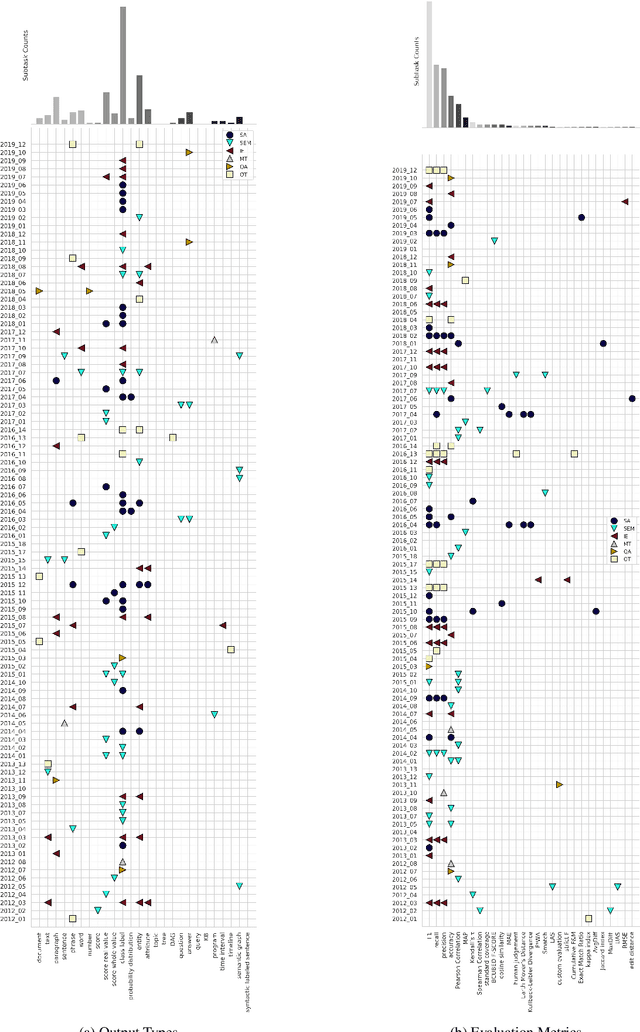
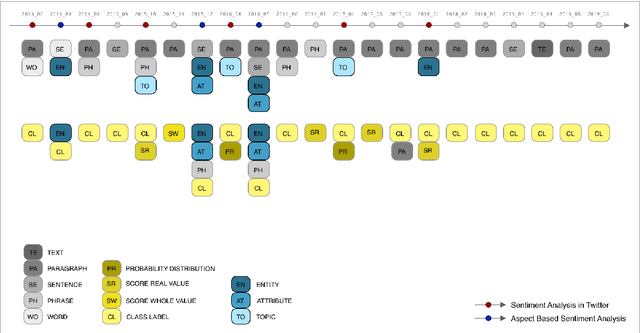
SemEval is the primary venue in the NLP community for the proposal of new challenges and for the systematic empirical evaluation of NLP systems. This paper provides a systematic quantitative analysis of SemEval aiming to evidence the patterns of the contributions behind SemEval. By understanding the distribution of task types, metrics, architectures, participation and citations over time we aim to answer the question on what is being evaluated by SemEval.