 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Implementation of a Natural User Interface to Command a Drone
Mar 05, 2020

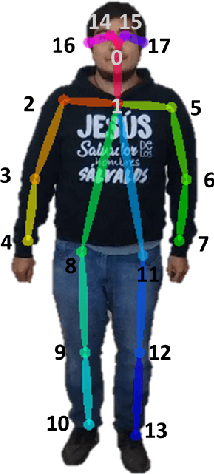
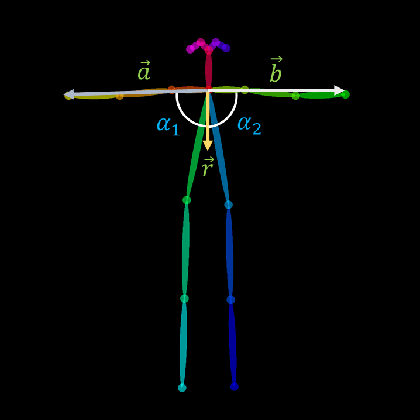
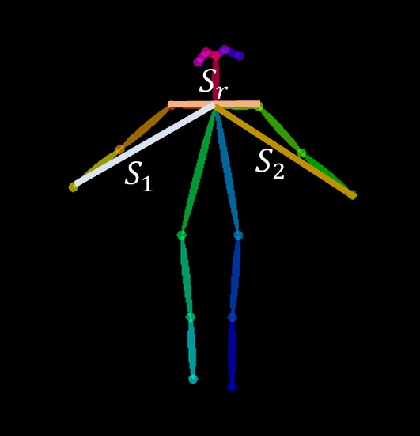
In this work, we propose the use of a Natural User Interface (NUI) through body gestures using the open source library OpenPose, looking for a more dynamic and intuitive way to control a drone. For the implementation, we use the Robotic Operative System (ROS) to control and manage the different components of the project. Wrapped inside ROS, OpenPose (OP) processes the video obtained in real-time by a commercial drone, allowing to obtain the user's pose. Finally, the keypoints from OpenPose are obtained and translated, using geometric constraints, to specify high-level commands to the drone. Real-time experiments validate the full strategy.
Learning an Adaptive Model for Extreme Low-light Raw Image Processing
Apr 22, 2020
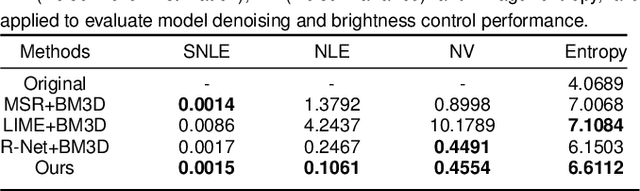
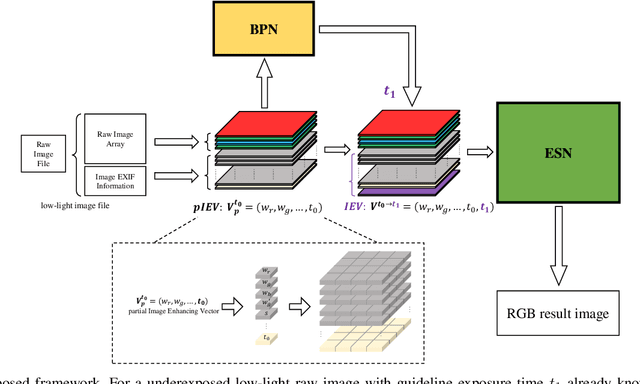
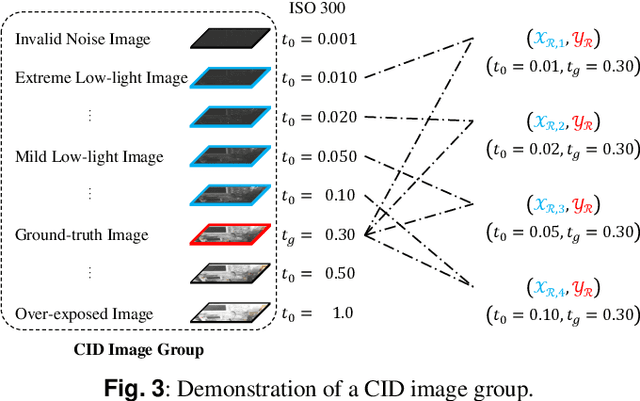
Low-light images suffer from severe noise and low illumination. Current deep learning models that are trained with real-world images have excellent noise reduction, but a ratio parameter must be chosen manually to complete the enhancement pipeline. In this work, we propose an adaptive low-light raw image enhancement network to avoid parameter-handcrafting and to improve image quality. The proposed method can be divided into two sub-models: Brightness Prediction (BP) and Exposure Shifting (ES). The former is designed to control the brightness of the resulting image by estimating a guideline exposure time $t_1$. The latter learns to approximate an exposure-shifting operator $ES$, converting a low-light image with real exposure time $t_0$ to a noise-free image with guideline exposure time $t_1$. Additionally, structural similarity (SSIM) loss and Image Enhancement Vector (IEV) are introduced to promote image quality, and a new Campus Image Dataset (CID) is proposed to overcome the limitations of the existing datasets and to supervise the training of the proposed model. Using the proposed model, we can achieve high-quality low-light image enhancement from a single raw image. In quantitative tests, it is shown that the proposed method has the lowest Noise Level Estimation (NLE) score compared with the state-of-the-art low-light algorithms, suggesting a superior denoising performance. Furthermore, those tests illustrate that the proposed method is able to adaptively control the global image brightness according to the content of the image scene. Lastly, the potential application in video processing is briefly discussed.
Neuromorphic Nearest-Neighbor Search Using Intel's Pohoiki Springs
Apr 27, 2020



Neuromorphic computing applies insights from neuroscience to uncover innovations in computing technology. In the brain, billions of interconnected neurons perform rapid computations at extremely low energy levels by leveraging properties that are foreign to conventional computing systems, such as temporal spiking codes and finely parallelized processing units integrating both memory and computation. Here, we showcase the Pohoiki Springs neuromorphic system, a mesh of 768 interconnected Loihi chips that collectively implement 100 million spiking neurons in silicon. We demonstrate a scalable approximate k-nearest neighbor (k-NN) algorithm for searching large databases that exploits neuromorphic principles. Compared to state-of-the-art conventional CPU-based implementations, we achieve superior latency, index build time, and energy efficiency when evaluated on several standard datasets containing over 1 million high-dimensional patterns. Further, the system supports adding new data points to the indexed database online in O(1) time unlike all but brute force conventional k-NN implementations.
FlipOut: Uncovering Redundant Weights via Sign Flipping
Sep 05, 2020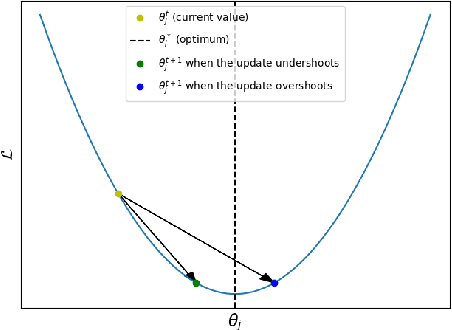

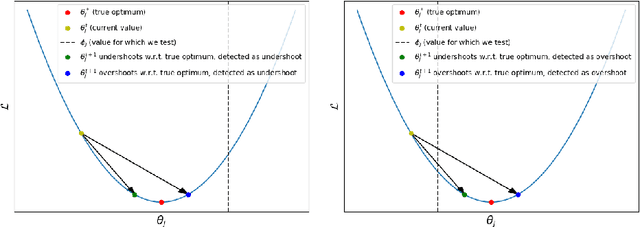
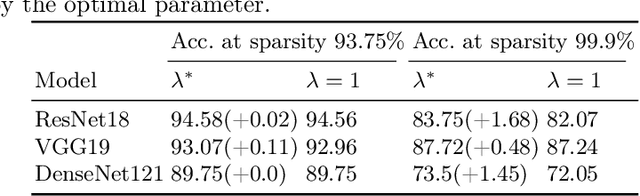
Modern neural networks, although achieving state-of-the-art results on many tasks, tend to have a large number of parameters, which increases training time and resource usage. This problem can be alleviated by pruning. Existing methods, however, often require extensive parameter tuning or multiple cycles of pruning and retraining to convergence in order to obtain a favorable accuracy-sparsity trade-off. To address these issues, we propose a novel pruning method which uses the oscillations around $0$ (i.e. sign flips) that a weight has undergone during training in order to determine its saliency. Our method can perform pruning before the network has converged, requires little tuning effort due to having good default values for its hyperparameters, and can directly target the level of sparsity desired by the user. Our experiments, performed on a variety of object classification architectures, show that it is competitive with existing methods and achieves state-of-the-art performance for levels of sparsity of $99.6\%$ and above for most of the architectures tested. For reproducibility, we release our code publicly at https://github.com/AndreiXYZ/flipout.
Explaining Neural Matrix Factorization with Gradient Rollback
Oct 14, 2020



Explaining the predictions of neural black-box models is an important problem, especially when such models are used in applications where user trust is crucial. Estimating the influence of training examples on a learned neural model's behavior allows us to identify training examples most responsible for a given prediction and, therefore, to faithfully explain the output of a black-box model. The most generally applicable existing method is based on influence functions, which scale poorly for larger sample sizes and models. We propose gradient rollback, a general approach for influence estimation, applicable to neural models where each parameter update step during gradient descent touches a smaller number of parameters, even if the overall number of parameters is large. Neural matrix factorization models trained with gradient descent are part of this model class. These models are popular and have found a wide range of applications in industry. Especially knowledge graph embedding methods, which belong to this class, are used extensively. We show that gradient rollback is highly efficient at both training and test time. Moreover, we show theoretically that the difference between gradient rollback's influence approximation and the true influence on a model's behavior is smaller than known bounds on the stability of stochastic gradient descent. This establishes that gradient rollback is robustly estimating example influence. We also conduct experiments which show that gradient rollback provides faithful explanations for knowledge base completion and recommender datasets.
On the Curse of Memory in Recurrent Neural Networks: Approximation and Optimization Analysis
Sep 16, 2020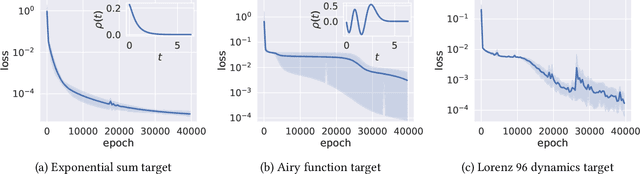
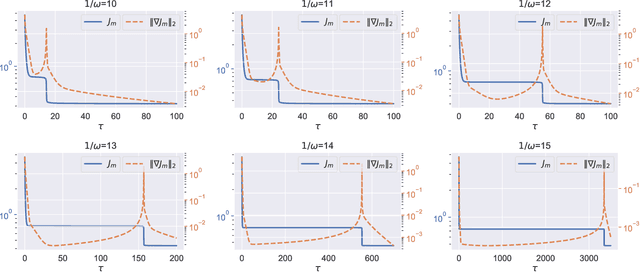
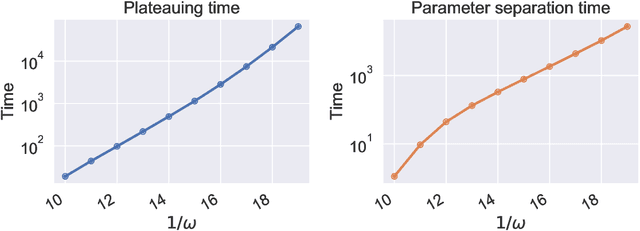
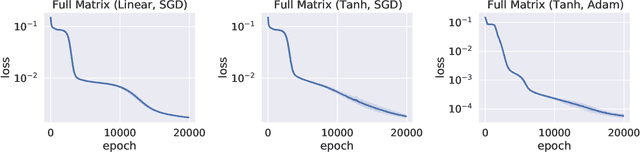
We study the approximation properties and optimization dynamics of recurrent neural networks (RNNs) when applied to learn input-output relationships in temporal data. We consider the simple but representative setting of using continuous-time linear RNNs to learn from data generated by linear relationships. Mathematically, the latter can be understood as a sequence of linear functionals. We prove a universal approximation theorem of such linear functionals, and characterize the approximation rate and its relation with memory. Moreover, we perform a fine-grained dynamical analysis of training linear RNNs, which further reveal the intricate interactions between memory and learning. A unifying theme uncovered is the non-trivial effect of memory, a notion that can be made precise in our framework, on approximation and optimization: when there is long term memory in the target, it takes a large number of neurons to approximate it. Moreover, the training process will suffer from slow downs. In particular, both of these effects become exponentially more pronounced with memory - a phenomenon we call the "curse of memory". These analyses represent a basic step towards a concrete mathematical understanding of new phenomenon that may arise in learning temporal relationships using recurrent architectures.
BREEDS: Benchmarks for Subpopulation Shift
Aug 11, 2020


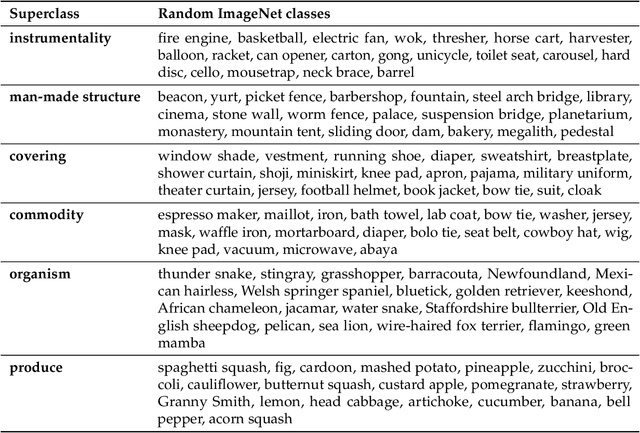
We develop a methodology for assessing the robustness of models to subpopulation shift---specifically, their ability to generalize to novel data subpopulations that were not observed during training. Our approach leverages the class structure underlying existing datasets to control the data subpopulations that comprise the training and test distributions. This enables us to synthesize realistic distribution shifts whose sources can be precisely controlled and characterized, within existing large-scale datasets. Applying this methodology to the ImageNet dataset, we create a suite of subpopulation shift benchmarks of varying granularity. We then validate that the corresponding shifts are tractable by obtaining human baselines for them. Finally, we utilize these benchmarks to measure the sensitivity of standard model architectures as well as the effectiveness of off-the-shelf train-time robustness interventions. Code and data available at https://github.com/MadryLab/BREEDS-Benchmarks .
Modeling and Prediction of Rigid Body Motion with Planar Non-Convex Contact
Oct 05, 2020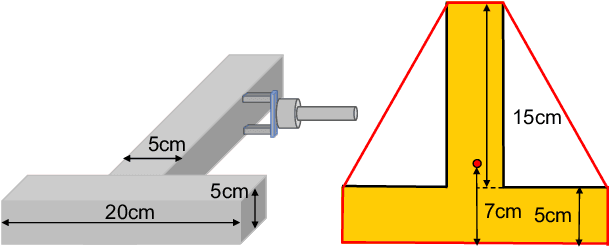
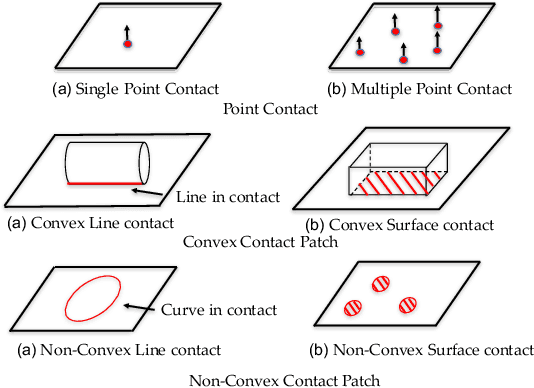
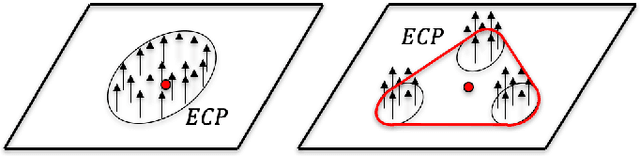
We present a principled method for motion prediction via dynamic simulation for rigid bodies in intermittent contact with each other where the contact region is a planar non-convex contact patch. Such methods are useful in planning and control for robotic manipulation. The planar non-convex contact patch can either be a topologically connected set or disconnected set. Most work in rigid body dynamic simulation assume that the contact between objects is a point contact, which may not be valid in many applications. In this paper, by using the convex hull of the contact patch, we build on our recent work on simulating rigid bodies with convex contact patches for simulating motion of objects with planar non-convex contact patches. We formulate a discrete-time mixed complementarity problem where we solve the contact detection and integration of the equations of motion simultaneously. We solve for the equivalent contact point (ECP) and contact impulse of each contact patch simultaneously along with the state, i.e., configuration and velocity of the objects. We prove that although we are representing a patch contact by an equivalent point, our model for enforcing non-penetration constraints ensure that there is no artificial penetration between the contacting rigid bodies. We provide empirical evidence to show that our method can seamlessly capture transition among different contact modes like patch contact, multiple or single point contact.
Going Deeper With Directly-Trained Larger Spiking Neural Networks
Oct 29, 2020
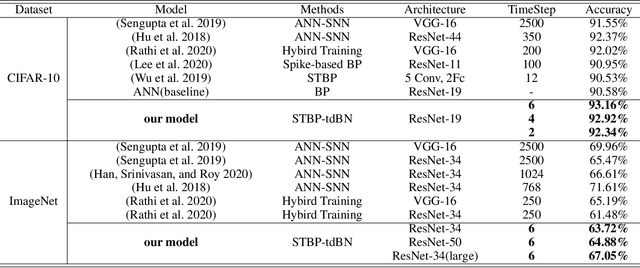
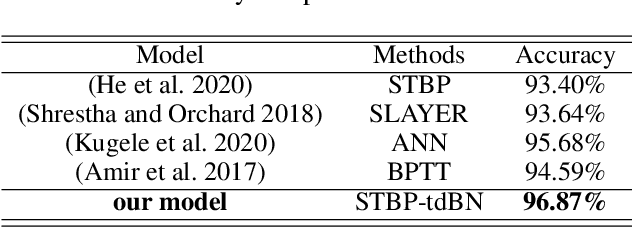
Spiking neural networks (SNNs) are promising in a bio-plausible coding for spatio-temporal information and event-driven signal processing, which is very suited for energy-efficient implementation in neuromorphic hardware. However, the unique working mode of SNNs makes them more difficult to train than traditional networks. Currently, there are two main routes to explore the training of deep SNNs with high performance. The first is to convert a pre-trained ANN model to its SNN version, which usually requires a long coding window for convergence and cannot exploit the spatio-temporal features during training for solving temporal tasks. The other is to directly train SNNs in the spatio-temporal domain. But due to the binary spike activity of the firing function and the problem of gradient vanishing or explosion, current methods are restricted to shallow architectures and thereby difficult in harnessing large-scale datasets (e.g. ImageNet). To this end, we propose a threshold-dependent batch normalization (tdBN) method based on the emerging spatio-temporal backpropagation, termed "STBP-tdBN", enabling direct training of a very deep SNN and the efficient implementation of its inference on neuromorphic hardware. With the proposed method and elaborated shortcut connection, we significantly extend directly-trained SNNs from a shallow structure ( < 10 layer) to a very deep structure (50 layers). Furthermore, we theoretically analyze the effectiveness of our method based on "Block Dynamical Isometry" theory. Finally, we report superior accuracy results including 93.15 % on CIFAR-10, 67.8 % on DVS-CIFAR10, and 67.05% on ImageNet with very few timesteps. To our best knowledge, it's the first time to explore the directly-trained deep SNNs with high performance on ImageNet.
Mastering Large Scale Multi-label Image Recognition with high efficiency overCamera trap images
Aug 18, 2020

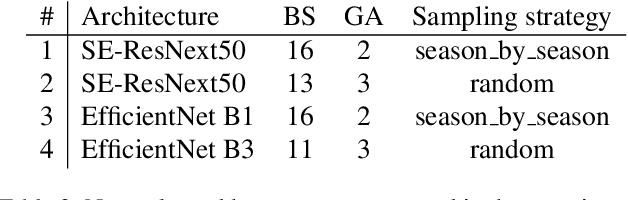
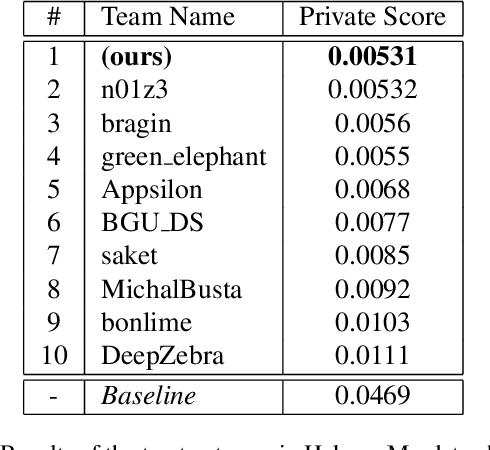
Camera traps are crucial in biodiversity motivated studies, however dealing with large number of images while annotating these data sets is a tedious and time consuming task. To speed up this process, Machine Learning approaches are a reasonable asset. In this article we are proposing an easy, accessible, light-weight, fast and efficient approach based on our winning submission to the "Hakuna Ma-data - Serengeti Wildlife Identification challenge". Our system achieved an Accuracy of 97% and outperformed the human level performance. We show that, given relatively large data sets, it is effective to look at each image only once with little or no augmentation. By utilizing such a simple, yet effective baseline we were able to avoid over-fitting without extensive regularization techniques and to train a top scoring system on a very limited hardware featuring single GPU (1080Ti) despite the large training set (6.7M images and 6TB).