 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robust Reinforcement Learning: A Case Study in Linear Quadratic Regulation
Aug 25, 2020
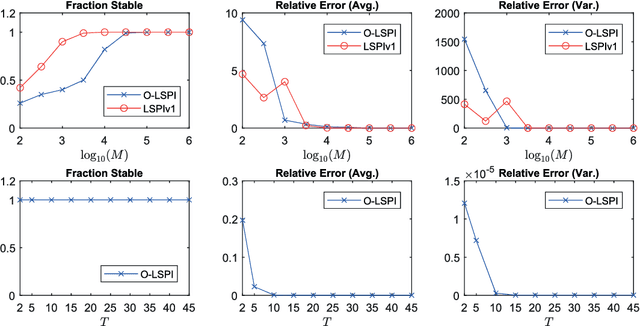
This paper studies the robustness aspect of reinforcement learning algorithms in the presence of errors. Specifically, we revisit the benchmark problem of discrete-time linear quadratic regulation (LQR) and study the long-standing open question: Under what conditions is the policy iteration method robustly stable for dynamical systems with unbounded, continuous state and action spaces? Using advanced stability results in control theory, it is shown that policy iteration for LQR is inherently robust to small errors and enjoys local input-to-state stability: whenever the error in each iteration is bounded and small, the solutions of the policy iteration algorithm are also bounded, and, moreover, enter and stay in a small neighborhood of the optimal LQR solution. As an application, a novel off-policy optimistic least-squares policy iteration for the LQR problem is proposed, when the system dynamics are subjected to additive stochastic disturbances. The proposed new results in robust reinforcement learning are validated by a numerical example.
A Comparison of Few-Shot Learning Methods for Underwater Optical and Sonar Image Classification
May 10, 2020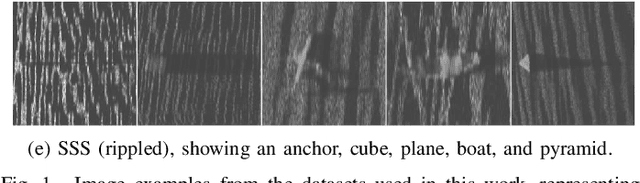
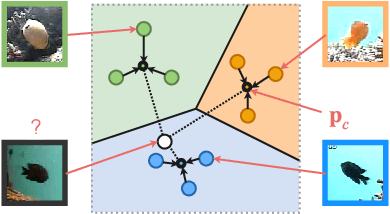
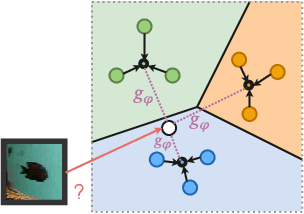
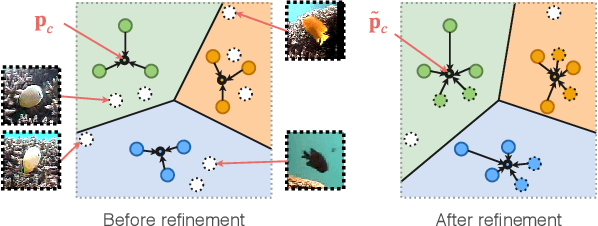
Deep convolutional neural networks have shown to perform well in underwater object recognition tasks, on both optical and sonar images. However, many such methods require hundreds, if not thousands, of images per class to generalize well to unseen examples. This is restricting in situations where obtaining and labeling larger volumes of data is impractical, such as observing a rare object, performing real-time operations, or operating in new underwater environments. Finding an algorithm capable of learning from only a few samples could reduce the time spent obtaining and labeling datasets, and accelerate the training of deep-learning models. To the best of our knowledge, this is the first paper to evaluate and compare several Few-Shot Learning (FSL) methods using underwater optical and side-scan sonar imagery. Our results show that FSL methods offer a significant advantage over the traditional transfer learning methods that employ fine-tuning of pre-trained models. Our findings show that FSL methods are not too far from being used on real-world robotics scenarios and expanding the capabilities of autonomous underwater systems.
Distributional Generalization: A New Kind of Generalization
Sep 17, 2020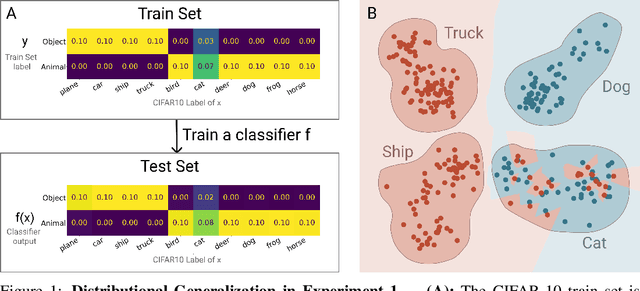

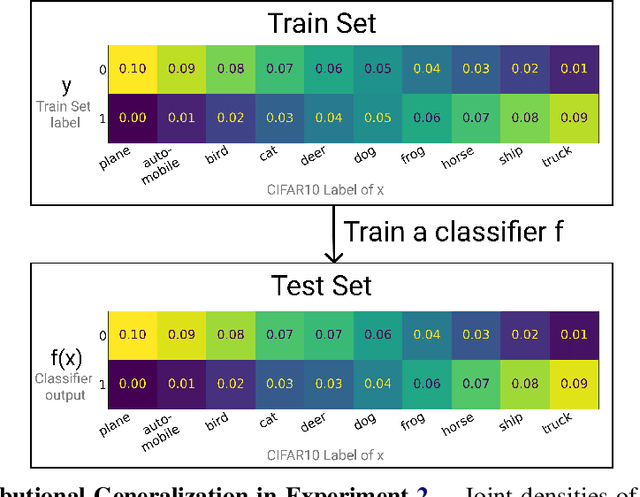

We introduce a new notion of generalization-- Distributional Generalization-- which roughly states that outputs of a classifier at train and test time are close *as distributions*, as opposed to close in just their average error. For example, if we mislabel 30% of dogs as cats in the train set of CIFAR-10, then a ResNet trained to interpolation will in fact mislabel roughly 30% of dogs as cats on the *test set* as well, while leaving other classes unaffected. This behavior is not captured by classical generalization, which would only consider the average error and not the distribution of errors over the input domain. This example is a specific instance of our much more general conjectures which apply even on distributions where the Bayes risk is zero. Our conjectures characterize the form of distributional generalization that can be expected, in terms of problem parameters (model architecture, training procedure, number of samples, data distribution). We verify the quantitative predictions of these conjectures across a variety of domains in machine learning, including neural networks, kernel machines, and decision trees. These empirical observations are independently interesting, and form a more fine-grained characterization of interpolating classifiers beyond just their test error.
Neuromorphic Nearest-Neighbor Search Using Intel's Pohoiki Springs
Apr 27, 2020



Neuromorphic computing applies insights from neuroscience to uncover innovations in computing technology. In the brain, billions of interconnected neurons perform rapid computations at extremely low energy levels by leveraging properties that are foreign to conventional computing systems, such as temporal spiking codes and finely parallelized processing units integrating both memory and computation. Here, we showcase the Pohoiki Springs neuromorphic system, a mesh of 768 interconnected Loihi chips that collectively implement 100 million spiking neurons in silicon. We demonstrate a scalable approximate k-nearest neighbor (k-NN) algorithm for searching large databases that exploits neuromorphic principles. Compared to state-of-the-art conventional CPU-based implementations, we achieve superior latency, index build time, and energy efficiency when evaluated on several standard datasets containing over 1 million high-dimensional patterns. Further, the system supports adding new data points to the indexed database online in O(1) time unlike all but brute force conventional k-NN implementations.
Uncertainty-aware Self-supervised 3D Data Association
Aug 18, 2020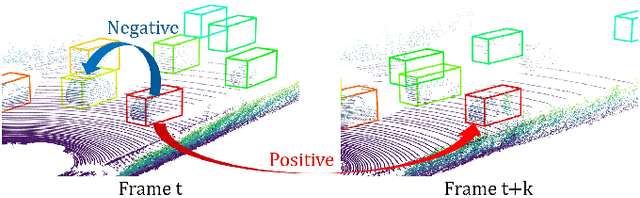

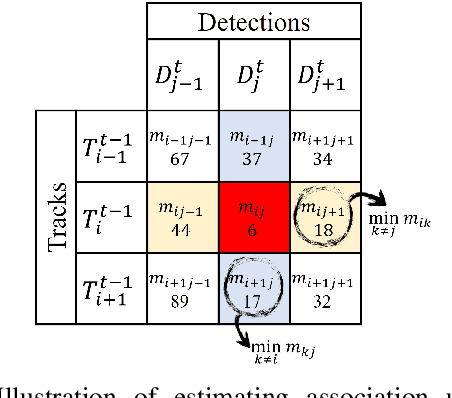
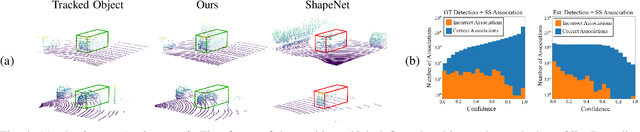
3D object trackers usually require training on large amounts of annotated data that is expensive and time-consuming to collect. Instead, we propose leveraging vast unlabeled datasets by self-supervised metric learning of 3D object trackers, with a focus on data association. Large scale annotations for unlabeled data are cheaply obtained by automatic object detection and association across frames. We show how these self-supervised annotations can be used in a principled manner to learn point-cloud embeddings that are effective for 3D tracking. We estimate and incorporate uncertainty in self-supervised tracking to learn more robust embeddings, without needing any labeled data. We design embeddings to differentiate objects across frames, and learn them using uncertainty-aware self-supervised training. Finally, we demonstrate their ability to perform accurate data association across frames, towards effective and accurate 3D tracking. Project videos and code are at https://jianrenw.github.io/Self-Supervised-3D-Data-Association.
A High Probability Analysis of Adaptive SGD with Momentum
Jul 28, 2020Stochastic Gradient Descent (SGD) and its variants are the most used algorithms in machine learning applications. In particular, SGD with adaptive learning rates and momentum is the industry standard to train deep networks. Despite the enormous success of these methods, our theoretical understanding of these variants in the nonconvex setting is not complete, with most of the results only proving convergence in expectation and with strong assumptions on the stochastic gradients. In this paper, we present a high probability analysis for adaptive and momentum algorithms, under weak assumptions on the function, stochastic gradients, and learning rates. We use it to prove for the first time the convergence of the gradients to zero in high probability in the smooth nonconvex setting for Delayed AdaGrad with momentum.
Learning an Adaptive Model for Extreme Low-light Raw Image Processing
Apr 22, 2020
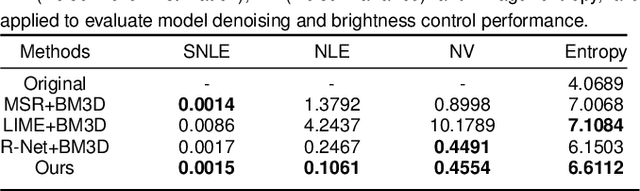
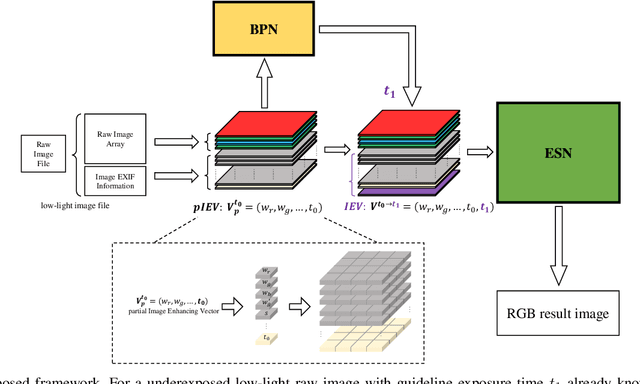
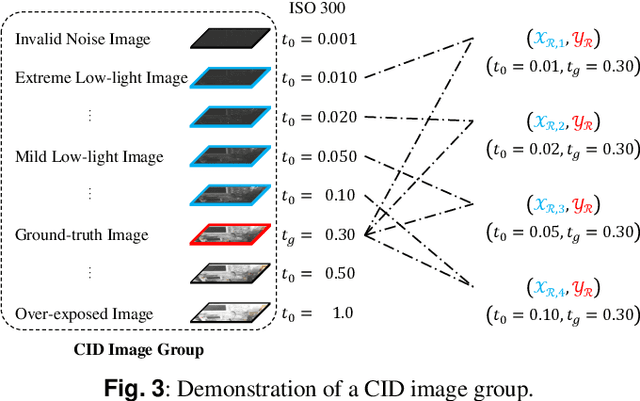
Low-light images suffer from severe noise and low illumination. Current deep learning models that are trained with real-world images have excellent noise reduction, but a ratio parameter must be chosen manually to complete the enhancement pipeline. In this work, we propose an adaptive low-light raw image enhancement network to avoid parameter-handcrafting and to improve image quality. The proposed method can be divided into two sub-models: Brightness Prediction (BP) and Exposure Shifting (ES). The former is designed to control the brightness of the resulting image by estimating a guideline exposure time $t_1$. The latter learns to approximate an exposure-shifting operator $ES$, converting a low-light image with real exposure time $t_0$ to a noise-free image with guideline exposure time $t_1$. Additionally, structural similarity (SSIM) loss and Image Enhancement Vector (IEV) are introduced to promote image quality, and a new Campus Image Dataset (CID) is proposed to overcome the limitations of the existing datasets and to supervise the training of the proposed model. Using the proposed model, we can achieve high-quality low-light image enhancement from a single raw image. In quantitative tests, it is shown that the proposed method has the lowest Noise Level Estimation (NLE) score compared with the state-of-the-art low-light algorithms, suggesting a superior denoising performance. Furthermore, those tests illustrate that the proposed method is able to adaptively control the global image brightness according to the content of the image scene. Lastly, the potential application in video processing is briefly discussed.
On the Structure of the Time-Optimal Path Parameterization Problem with Third-Order Constraints
Sep 19, 2017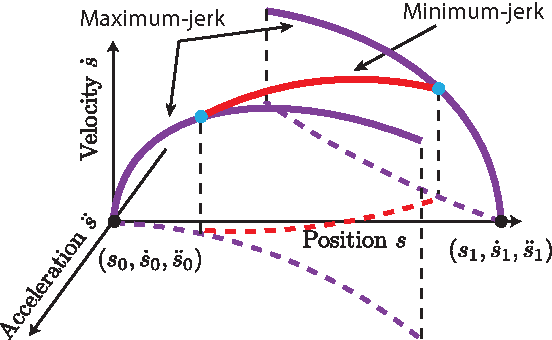
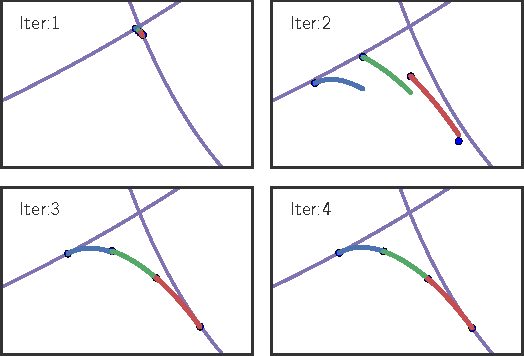
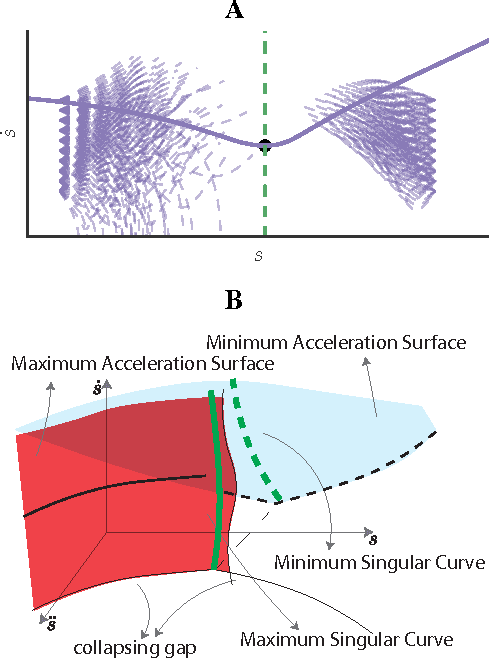
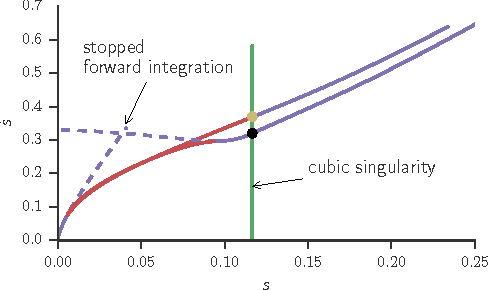
Finding the Time-Optimal Parameterization of a Path (TOPP) subject to second-order constraints (e.g. acceleration, torque, contact stability, etc.) is an important and well-studied problem in robotics. In comparison, TOPP subject to third-order constraints (e.g. jerk, torque rate, etc.) has received far less attention and remains largely open. In this paper, we investigate the structure of the TOPP problem with third-order constraints. In particular, we identify two major difficulties: (i) how to smoothly connect optimal profiles, and (ii) how to address singularities, which stop profile integration prematurely. We propose a new algorithm, TOPP3, which addresses these two difficulties and thereby constitutes an important milestone towards an efficient computational solution to TOPP with third-order constraints.
The Annotation Guideline of LST20 Corpus
Aug 12, 2020
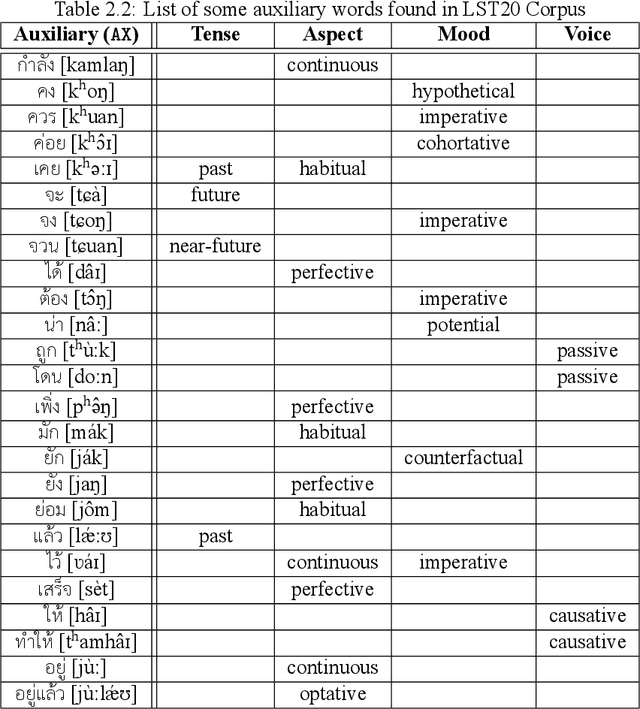
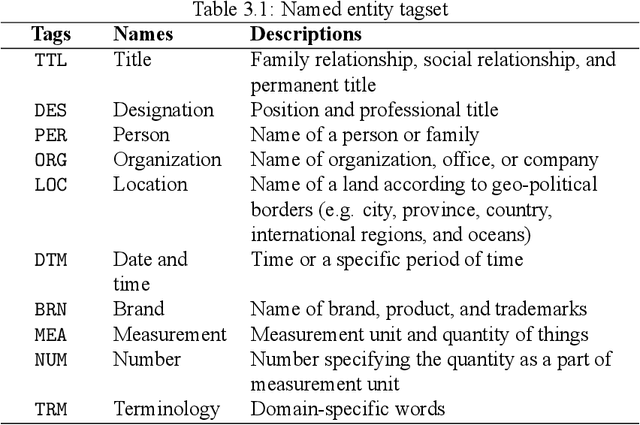

This report presents the annotation guideline for LST20, a large-scale corpus with multiple layers of linguistic annotation for Thai language processing. Our guideline consists of five layers of linguistic annotation: word segmentation, POS tagging, named entities, clause boundaries, and sentence boundaries. The dataset complies to the CoNLL-2003-style format for ease of use. LST20 Corpus offers five layers of linguistic annotation as aforementioned. At a large scale, it consists of 3,164,864 words, 288,020 named entities, 248,962 clauses, and 74,180 sentences, while it is annotated with 16 distinct POS tags. All 3,745 documents are also annotated with 15 news genres. Regarding its sheer size, this dataset is considered large enough for developing joint neural models for NLP. With the existence of this publicly available corpus, Thai has become a linguistically rich language for the first time.
Picking Winning Tickets Before Training by Preserving Gradient Flow
Feb 18, 2020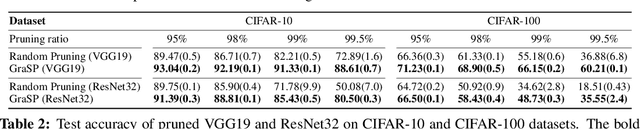
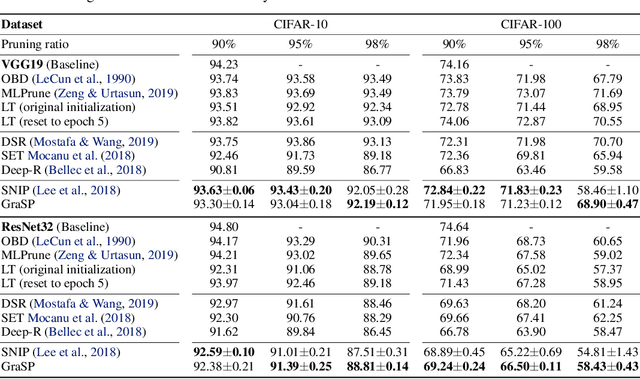
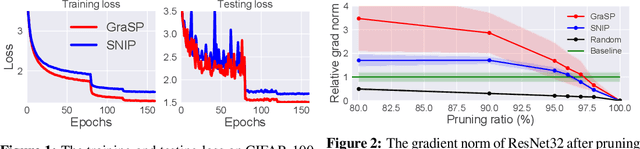
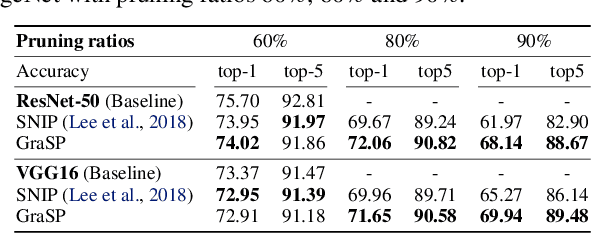
Overparameterization has been shown to benefit both the optimization and generalization of neural networks, but large networks are resource hungry at both training and test time. Network pruning can reduce test-time resource requirements, but is typically applied to trained networks and therefore cannot avoid the expensive training process. We aim to prune networks at initialization, thereby saving resources at training time as well. Specifically, we argue that efficient training requires preserving the gradient flow through the network. This leads to a simple but effective pruning criterion we term Gradient Signal Preservation (GraSP). We empirically investigate the effectiveness of the proposed method with extensive experiments on CIFAR-10, CIFAR-100, Tiny-ImageNet and ImageNet, using VGGNet and ResNet architectures. Our method can prune 80% of the weights of a VGG-16 network on ImageNet at initialization, with only a 1.6% drop in top-1 accuracy. Moreover, our method achieves significantly better performance than the baseline at extreme sparsity levels.
* Accepted at ICLR 2020