 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sublinear-Time Approximate MCMC Transitions for Probabilistic Programs
Mar 09, 2015
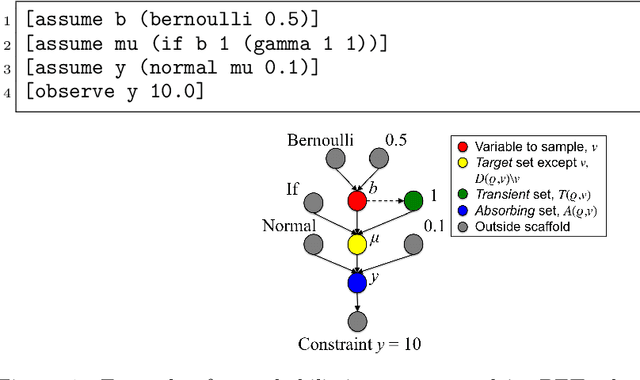

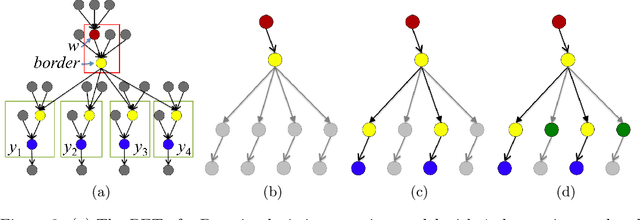
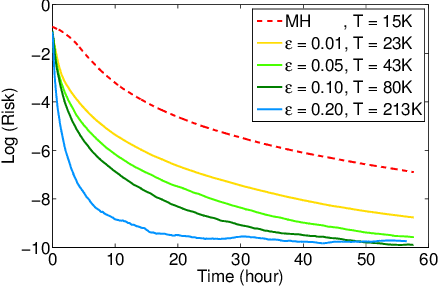
Probabilistic programming languages can simplify the development of machine learning techniques, but only if inference is sufficiently scalable. Unfortunately, Bayesian parameter estimation for highly coupled models such as regressions and state-space models still scales poorly; each MCMC transition takes linear time in the number of observations. This paper describes a sublinear-time algorithm for making Metropolis-Hastings (MH) updates to latent variables in probabilistic programs. The approach generalizes recently introduced approximate MH techniques: instead of subsampling data items assumed to be independent, it subsamples edges in a dynamically constructed graphical model. It thus applies to a broader class of problems and interoperates with other general-purpose inference techniques. Empirical results, including confirmation of sublinear per-transition scaling, are presented for Bayesian logistic regression, nonlinear classification via joint Dirichlet process mixtures, and parameter estimation for stochastic volatility models (with state estimation via particle MCMC). All three applications use the same implementation, and each requires under 20 lines of probabilistic code.
Temporally Folded Convolutional Neural Networks for Sequence Forecasting
Jan 10, 2020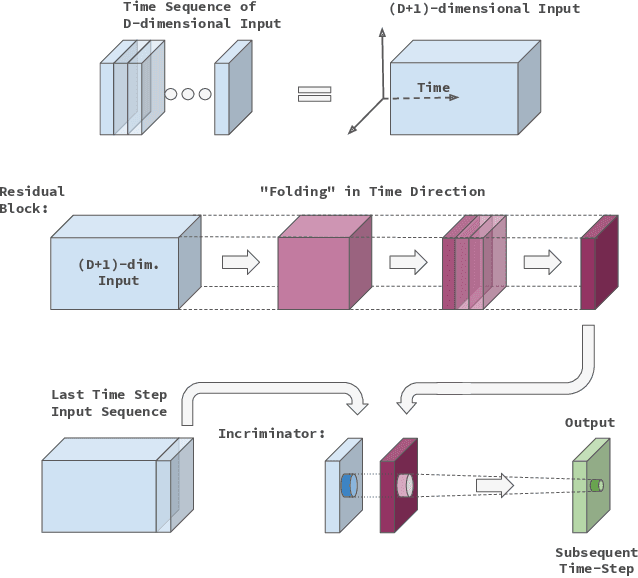
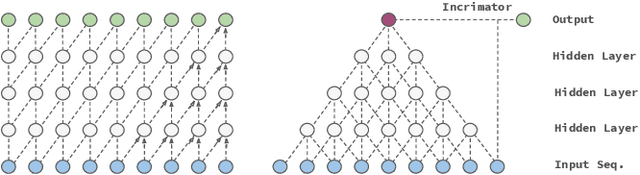
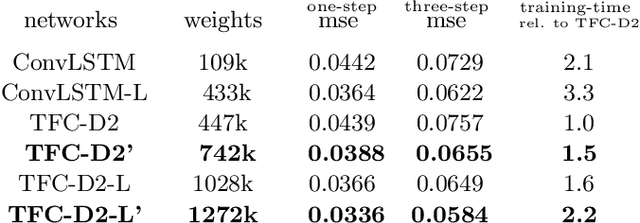

In this work we propose a novel approach to utilize convolutional neural networks for time series forecasting. The time direction of the sequential data with spatial dimensions $D=1,2$ is considered democratically as the input of a spatiotemporal $(D+1)$-dimensional convolutional neural network. Latter then reduces the data stream from $D +1 \to D$ dimensions followed by an incriminator cell which uses this information to forecast the subsequent time step. We empirically compare this strategy to convolutional LSTM's and LSTM's on their performance on the sequential MNIST and the JSB chorals dataset, respectively. We conclude that temporally folded convolutional neural networks (TFC's) may outperform the conventional recurrent strategies.
Learning to Reconstruct Confocal Microscopy Stacks from Single Light Field Images
Mar 24, 2020We present a novel deep learning approach to reconstruct confocal microscopy stacks from single light field images. To perform the reconstruction, we introduce the LFMNet, a novel neural network architecture inspired by the U-Net design. It is able to reconstruct with high-accuracy a 112x112x57.6$\mu m^3$ volume (1287x1287x64 voxels) in 50ms given a single light field image of 1287x1287 pixels, thus dramatically reducing 720-fold the time for confocal scanning of assays at the same volumetric resolution and 64-fold the required storage. To prove the applicability in life sciences, our approach is evaluated both quantitatively and qualitatively on mouse brain slices with fluorescently labelled blood vessels. Because of the drastic reduction in scan time and storage space, our setup and method are directly applicable to real-time in vivo 3D microscopy. We provide analysis of the optical design, of the network architecture and of our training procedure to optimally reconstruct volumes for a given target depth range. To train our network, we built a data set of 362 light field images of mouse brain blood vessels and the corresponding aligned set of 3D confocal scans, which we use as ground truth. The data set will be made available for research purposes.
On the Structure of the Time-Optimal Path Parameterization Problem with Third-Order Constraints
Sep 19, 2017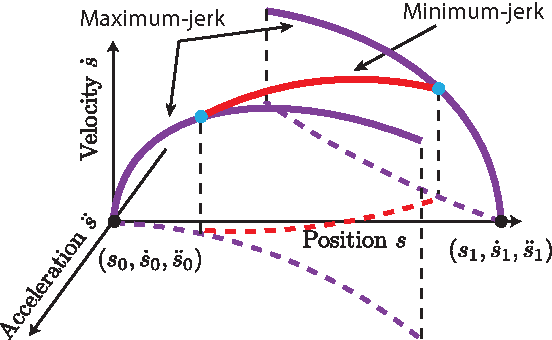
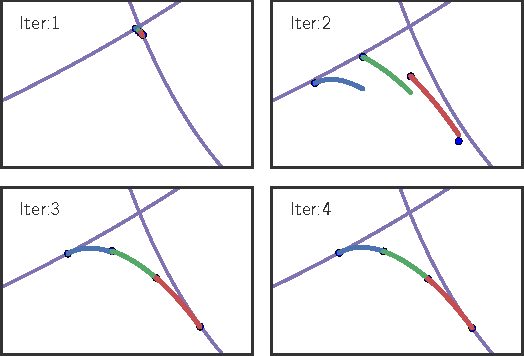
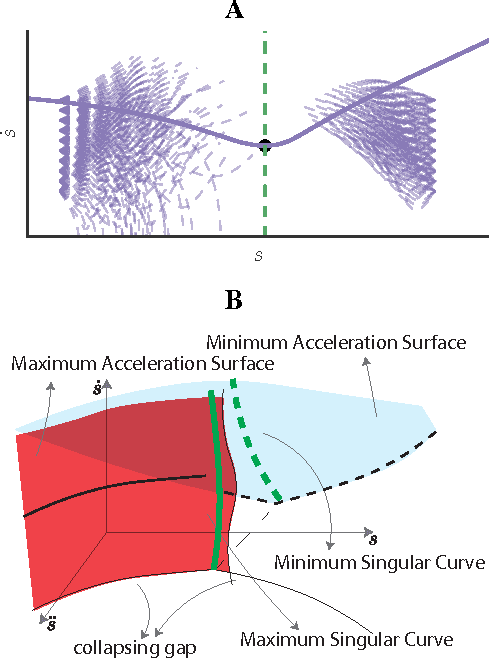
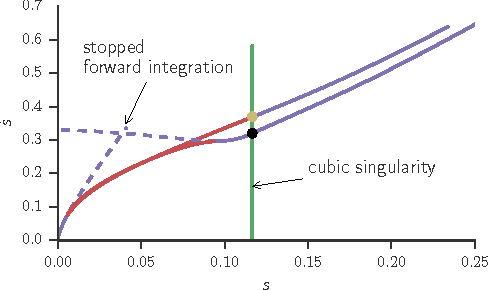
Finding the Time-Optimal Parameterization of a Path (TOPP) subject to second-order constraints (e.g. acceleration, torque, contact stability, etc.) is an important and well-studied problem in robotics. In comparison, TOPP subject to third-order constraints (e.g. jerk, torque rate, etc.) has received far less attention and remains largely open. In this paper, we investigate the structure of the TOPP problem with third-order constraints. In particular, we identify two major difficulties: (i) how to smoothly connect optimal profiles, and (ii) how to address singularities, which stop profile integration prematurely. We propose a new algorithm, TOPP3, which addresses these two difficulties and thereby constitutes an important milestone towards an efficient computational solution to TOPP with third-order constraints.
Matched Queues with Matching Batch Pair (m, n)
Sep 06, 2020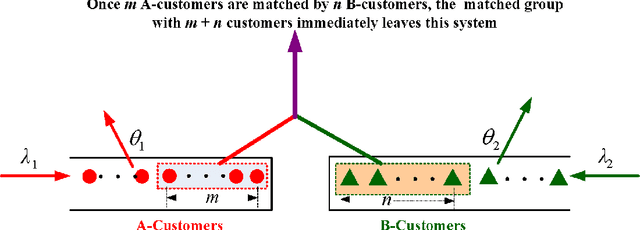
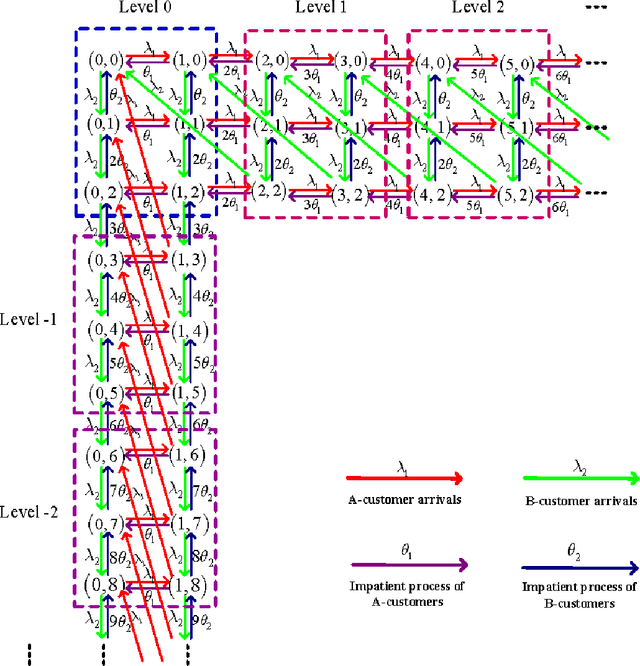
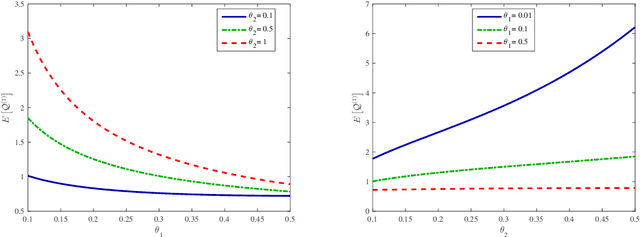
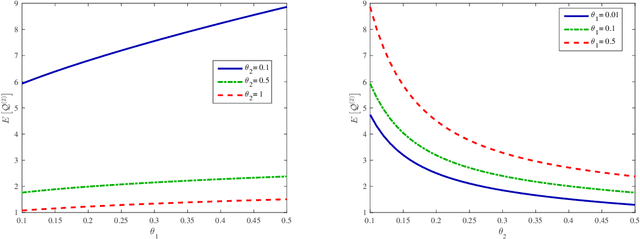
In this paper, we discuss an interesting but challenging bilateral stochastically matching problem: A more general matched queue with matching batch pair (m, n) and two types (i.e., types A and B) of impatient customers, where the arrivals of A- and B-customers are both Poisson processes, m A-customers and n B-customers are matched as a group which leaves the system immediately, and the customers' impatient behavior is to guarantee the stability of the system. We show that this matched queue can be expressed as a novel bidirectional level-dependent quasi-birth-and-death (QBD) process. Based on this, we provide a detailed analysis for this matched queue, including the system stability, the average stationary queue lengthes, and the average sojourn time of any A-customer or B-customer. We believe that the methodology and results developed in this paper can be applicable to dealing with more general matched queueing systems, which are widely encountered in various practical areas, for example, sharing economy, ridesharing platform, bilateral market, organ transplantation, taxi services, assembly systems, and so on.
Efficient Framework for Learning Code Representations through Semantic-Preserving Program Transformations
Sep 06, 2020
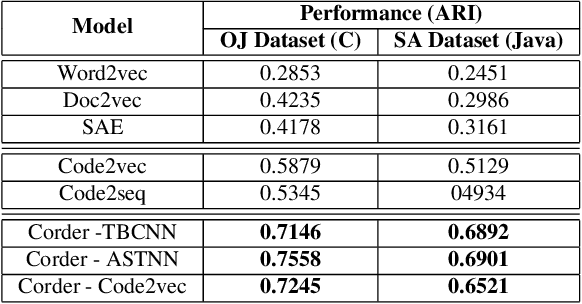
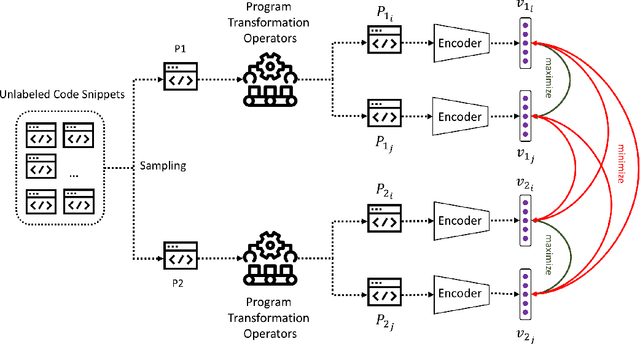
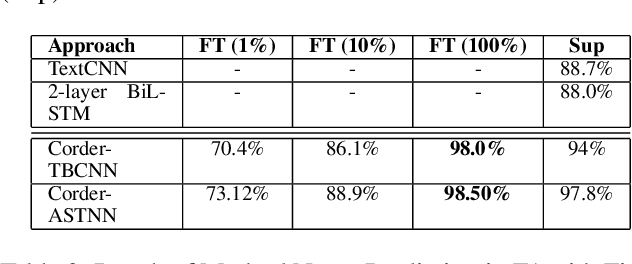
Recent learning techniques for the representation of code depend mostly on human-annotated (labeled) data. In this work, we are proposing Corder, a self-supervised learning system that can learn to represent code without having to label data. The key innovation is that we train the source code model by asking it to recognize similar and dissimilar code snippets through a contrastive learning paradigm. We use a set of semantic-preserving transformation operators to generate snippets that are syntactically diverse but semantically equivalent. The contrastive learning objective, at the same time, maximizes agreement between different views of the same snippets and minimizes agreement between transformed views of different snippets. We train different instances of Corder on 3 neural network encoders, which are Tree-based CNN, ASTNN, and Code2vec over 2.5 million unannotated Java methods mined from GitHub. Our result shows that the Corder pre-training improves code classification and method name prediction with large margins. Furthermore, the code vectors generated by Corder are adapted to code clustering which has been shown to significantly beat the other baselines.
Unsupervised seismic facies classification using deep convolutional autoencoder
Aug 05, 2020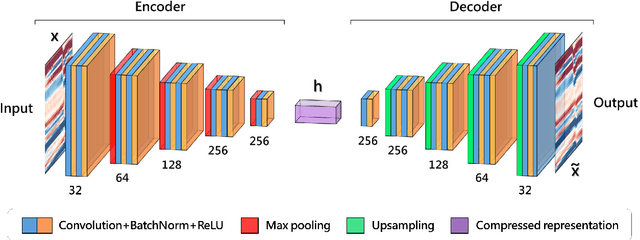
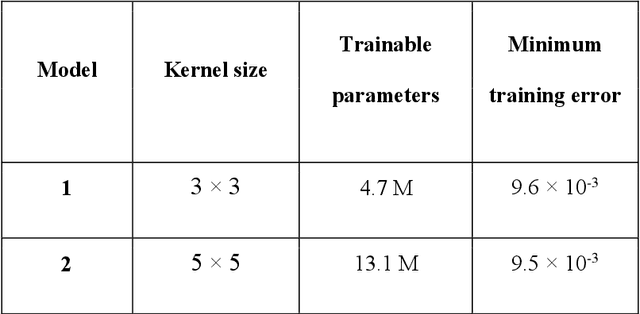

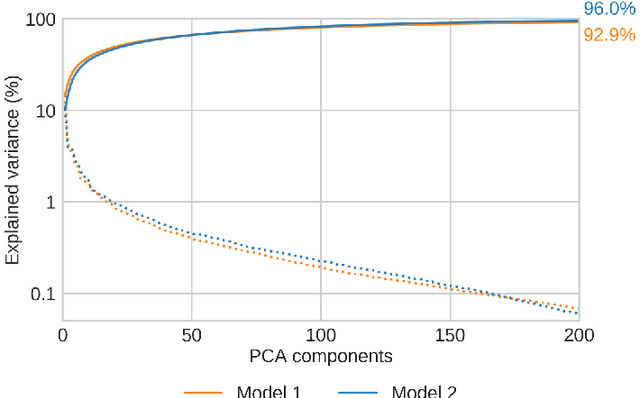
With the increased size and complexity of seismic surveys, manual labeling of seismic facies has become a significant challenge. Application of automatic methods for seismic facies interpretation could significantly reduce the manual labor and subjectivity of a particular interpreter present in conventional methods. A recently emerged group of methods is based on deep neural networks. These approaches are data-driven and require large labeled datasets for network training. We apply a deep convolutional autoencoder for unsupervised seismic facies classification, which does not require manually labeled examples. The facies maps are generated by clustering the deep-feature vectors obtained from the input data. Our method yields accurate results on real data and provides them instantaneously. The proposed approach opens up possibilities to analyze geological patterns in real time without human intervention.
Distributional Generalization: A New Kind of Generalization
Sep 17, 2020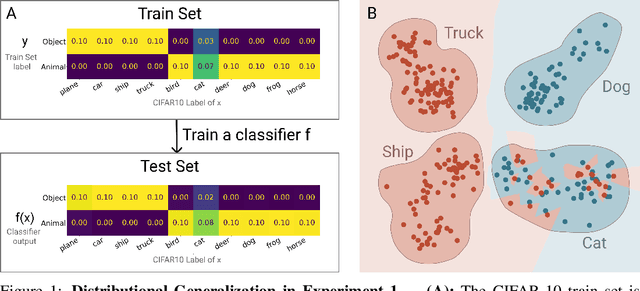

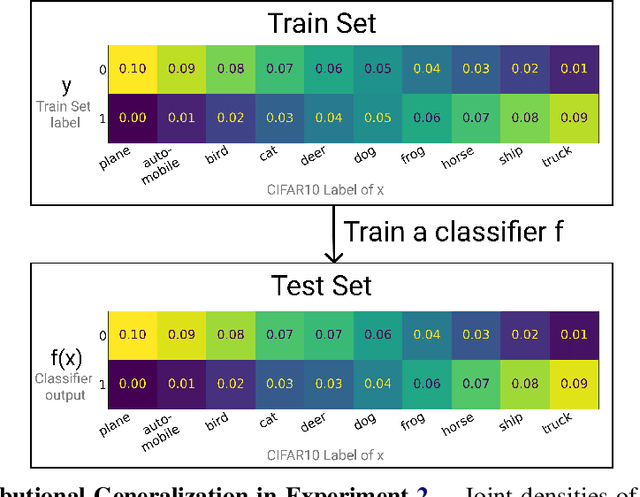

We introduce a new notion of generalization-- Distributional Generalization-- which roughly states that outputs of a classifier at train and test time are close *as distributions*, as opposed to close in just their average error. For example, if we mislabel 30% of dogs as cats in the train set of CIFAR-10, then a ResNet trained to interpolation will in fact mislabel roughly 30% of dogs as cats on the *test set* as well, while leaving other classes unaffected. This behavior is not captured by classical generalization, which would only consider the average error and not the distribution of errors over the input domain. This example is a specific instance of our much more general conjectures which apply even on distributions where the Bayes risk is zero. Our conjectures characterize the form of distributional generalization that can be expected, in terms of problem parameters (model architecture, training procedure, number of samples, data distribution). We verify the quantitative predictions of these conjectures across a variety of domains in machine learning, including neural networks, kernel machines, and decision trees. These empirical observations are independently interesting, and form a more fine-grained characterization of interpolating classifiers beyond just their test error.
Robust Reinforcement Learning: A Case Study in Linear Quadratic Regulation
Aug 25, 2020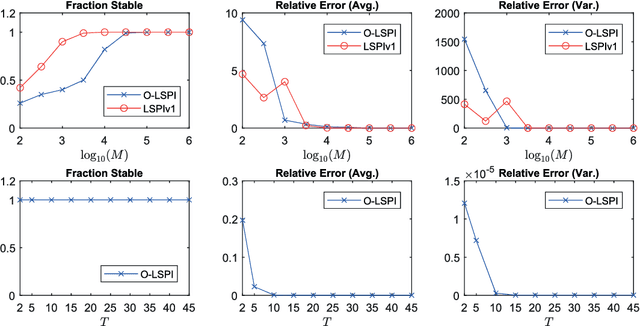
This paper studies the robustness aspect of reinforcement learning algorithms in the presence of errors. Specifically, we revisit the benchmark problem of discrete-time linear quadratic regulation (LQR) and study the long-standing open question: Under what conditions is the policy iteration method robustly stable for dynamical systems with unbounded, continuous state and action spaces? Using advanced stability results in control theory, it is shown that policy iteration for LQR is inherently robust to small errors and enjoys local input-to-state stability: whenever the error in each iteration is bounded and small, the solutions of the policy iteration algorithm are also bounded, and, moreover, enter and stay in a small neighborhood of the optimal LQR solution. As an application, a novel off-policy optimistic least-squares policy iteration for the LQR problem is proposed, when the system dynamics are subjected to additive stochastic disturbances. The proposed new results in robust reinforcement learning are validated by a numerical example.
Capturing Evolution in Word Usage: Just Add More Clusters?
Jan 24, 2020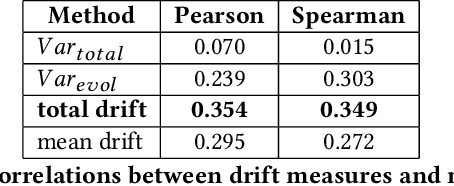
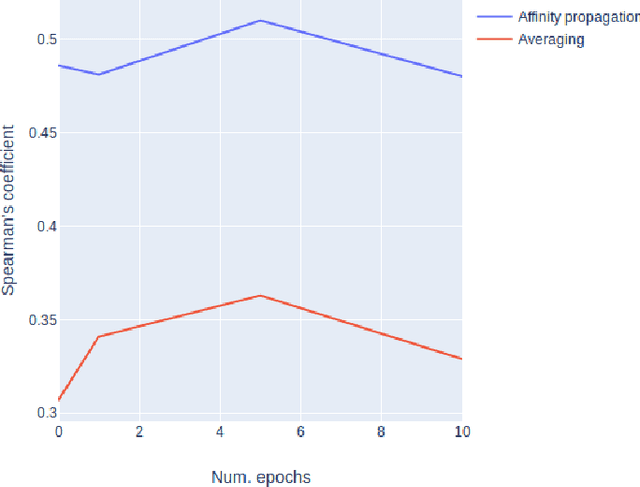
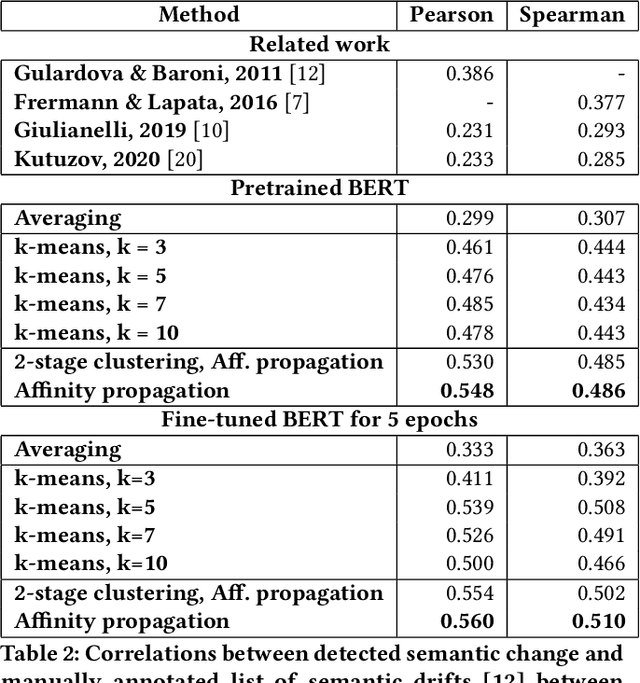
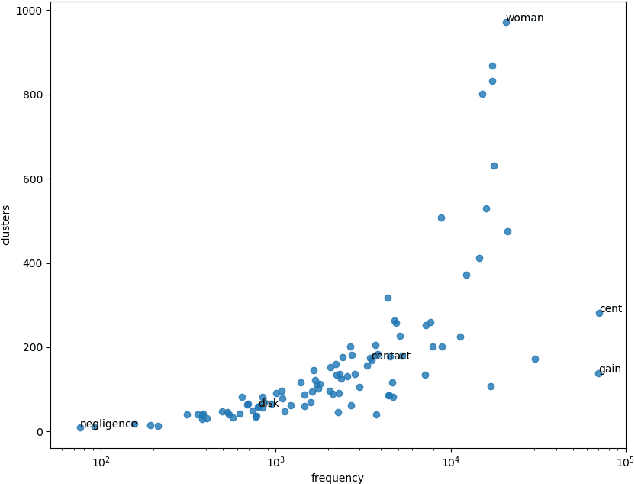
The way the words are used evolves through time, mirroring cultural or technological evolution of society. Semantic change detection is the task of detecting and analysing word evolution in textual data, even in short periods of time. In this paper we focus on a new set of methods relying on contextualised embeddings, a type of semantic modelling that revolutionised the NLP field recently. We leverage the ability of the transformer-based BERT model to generate contextualised embeddings capable of detecting semantic change of words across time. Several approaches are compared in a common setting in order to establish strengths and weaknesses for each of them. We also propose several ideas for improvements, managing to drastically improve the performance of existing approaches.