 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Classification and Recognition of Encrypted EEG Data Neural Network
Jun 15, 2020
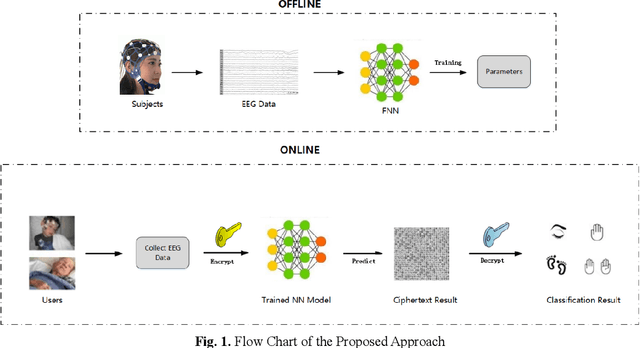

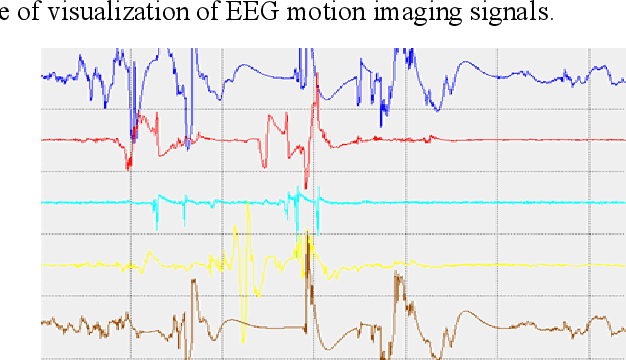
With the rapid development of Machine Learning technology applied in electroencephalography (EEG) signals, Brain-Computer Interface (BCI) has emerged as a novel and convenient human-computer interaction for smart home, intelligent medical and other Internet of Things (IoT) scenarios. However, security issues such as sensitive information disclosure and unauthorized operations have not received sufficient concerns. There are still some defects with the existing solutions to encrypted EEG data such as low accuracy, high time complexity or slow processing speed. For this reason, a classification and recognition method of encrypted EEG data based on neural network is proposed, which adopts Paillier encryption algorithm to encrypt EEG data and meanwhile resolves the problem of floating point operations. In addition, it improves traditional feed-forward neural network (FNN) by using the approximate function instead of activation function and realizes multi-classification of encrypted EEG data. Extensive experiments are conducted to explore the effect of several metrics (such as the hidden neuron size and the learning rate updated by improved simulated annealing algorithm) on the recognition results. Followed by security and time cost analysis, the proposed model and approach are validated and evaluated on public EEG datasets provided by PhysioNet, BCI Competition IV and EPILEPSIAE. The experimental results show that our proposal has the satisfactory accuracy, efficiency and feasibility compared with other solutions.
Stochastic Optimization Forests
Aug 27, 2020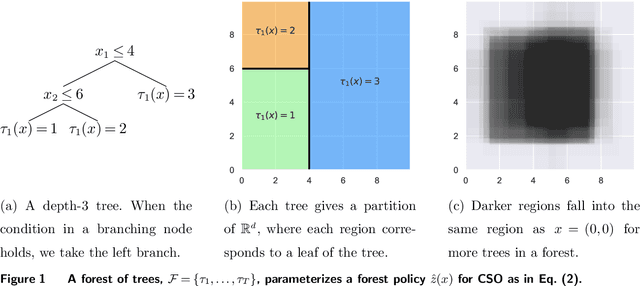

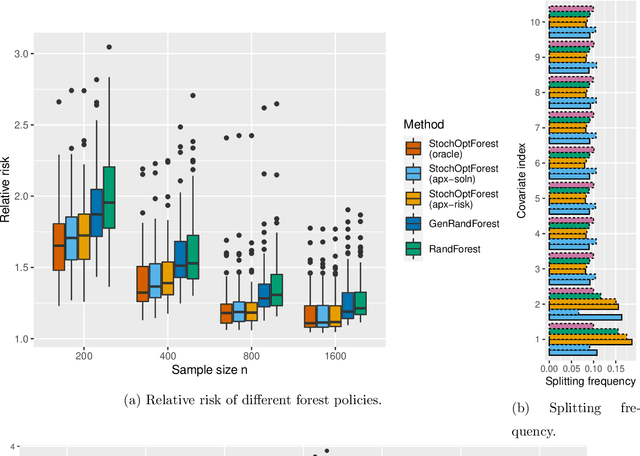
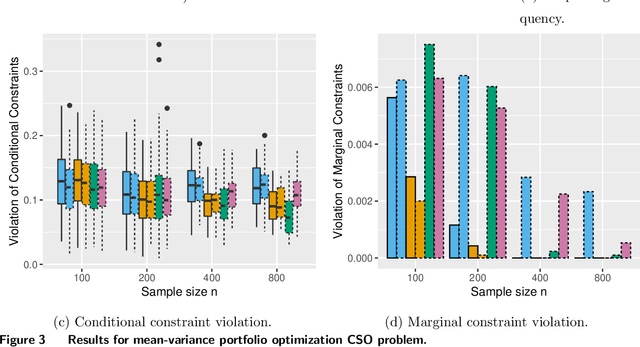
We study conditional stochastic optimization problems, where we leverage rich auxiliary observations (e.g., customer characteristics) to improve decision-making with uncertain variables (e.g., demand). We show how to train forest decision policies for this problem by growing trees that choose splits to directly optimize the downstream decision quality, rather than splitting to improve prediction accuracy as in the standard random forest algorithm. We realize this seemingly computationally intractable problem by developing approximate splitting criteria that utilize optimization perturbation analysis to eschew burdensome re-optimization for every candidate split, so that our method scales to large-scale problems. Our method can accommodate both deterministic and stochastic constraints. We prove that our splitting criteria consistently approximate the true risk. We extensively validate its efficacy empirically, demonstrating the value of optimization-aware construction of forests and the success of our efficient approximations. We show that our approximate splitting criteria can reduce running time hundredfold, while achieving performance close to forest algorithms that exactly re-optimize for every candidate split.
Psoriasis Severity Assessment with a Similarity-Clustering Machine Learning Approach Reduces Intra- and Inter-observation variation
Sep 18, 2020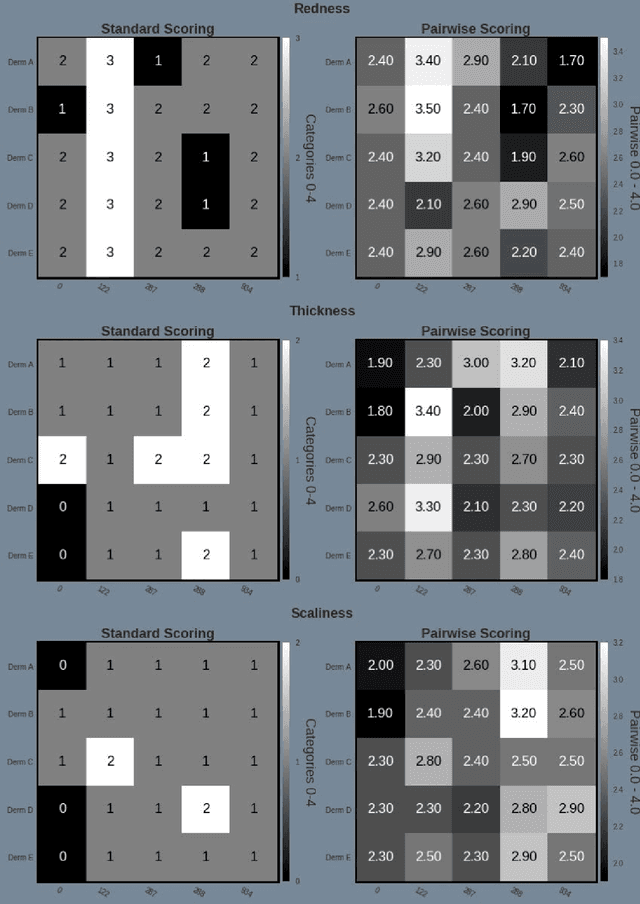
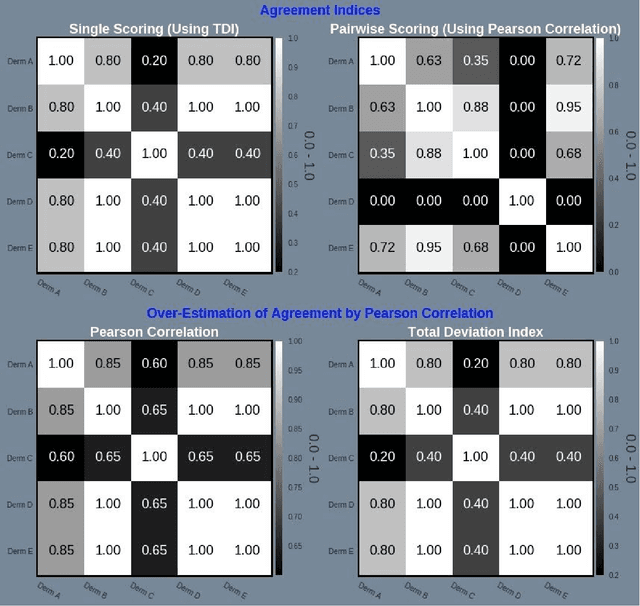
Psoriasis is a complex disease with many variations in genotype and phenotype. General advancements in medicine has further complicated both assessments and treatment for both physicians and dermatologist alike. Even with all of our technological progress we still primarily use the assessment tool Psoriasis Area and Severity Index (PASI) for severity assessments which was developed in the 1970s. In this study we evaluate a method involving digital images, a comparison web application and similarity clustering, developed to improve the assessment tool in terms of intra- and inter-observer variation. Images of patients was collected from a mobile device. Images were captured of the same lesion area taken approximately 1 week apart. Five dermatologists evaluated the severity of psoriasis by modified-PASI, absolute scoring and a relative pairwise PASI scoring using similarity-clustering and conducted using a web-program displaying two images at a time. mPASI scoring of single photos by the same or different dermatologist showed mPASI ratings of 50% to 80%, respectively. Repeated mPASI comparison using similarity clustering showed consistent mPASI ratings > 95%. Pearson correlation between absolute scoring and pairwise scoring progression was 0.72.
Traces of Class/Cross-Class Structure Pervade Deep Learning Spectra
Aug 27, 2020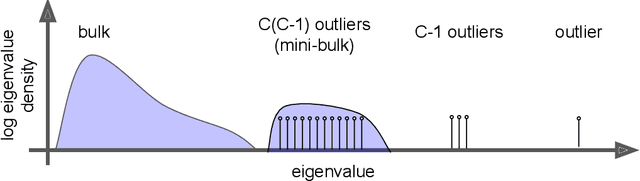
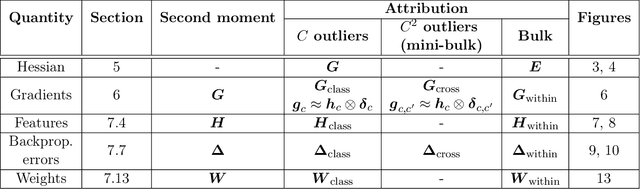
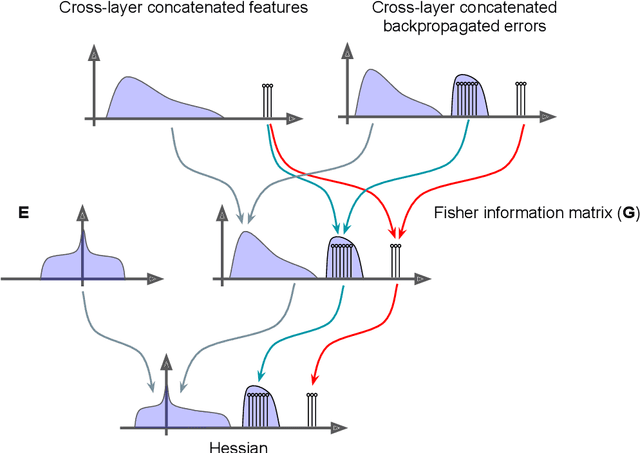
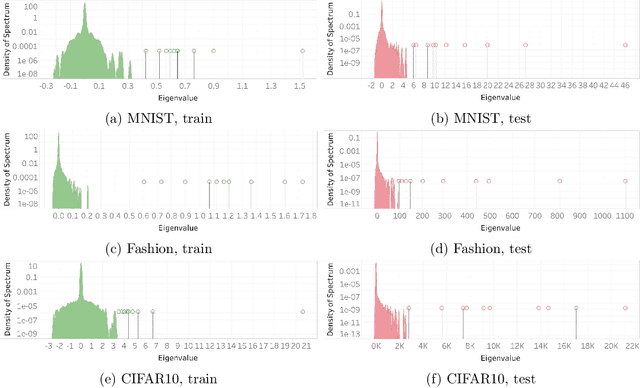
Numerous researchers recently applied empirical spectral analysis to the study of modern deep learning classifiers. We identify and discuss an important formal class/cross-class structure and show how it lies at the origin of the many visually striking features observed in deepnet spectra, some of which were reported in recent articles, others are unveiled here for the first time. These include spectral outliers, "spikes", and small but distinct continuous distributions, "bumps", often seen beyond the edge of a "main bulk". The significance of the cross-class structure is illustrated in three ways: (i) we prove the ratio of outliers to bulk in the spectrum of the Fisher information matrix is predictive of misclassification, in the context of multinomial logistic regression; (ii) we demonstrate how, gradually with depth, a network is able to separate class-distinctive information from class variability, all while orthogonalizing the class-distinctive information; and (iii) we propose a correction to KFAC, a well-known second-order optimization algorithm for training deepnets.
Radial Velocity Retrieval for Multichannel SAR Moving Targets with Time-Space Doppler De-ambiguity
Jun 09, 2017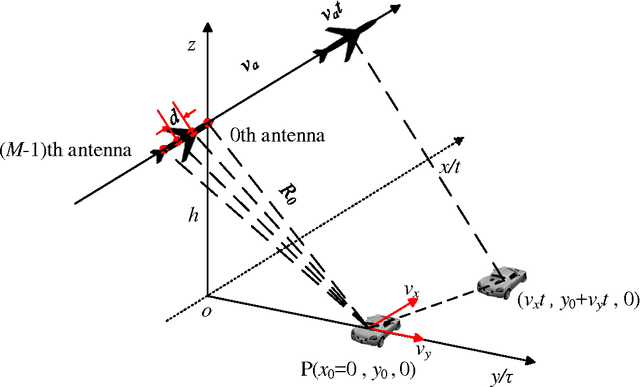
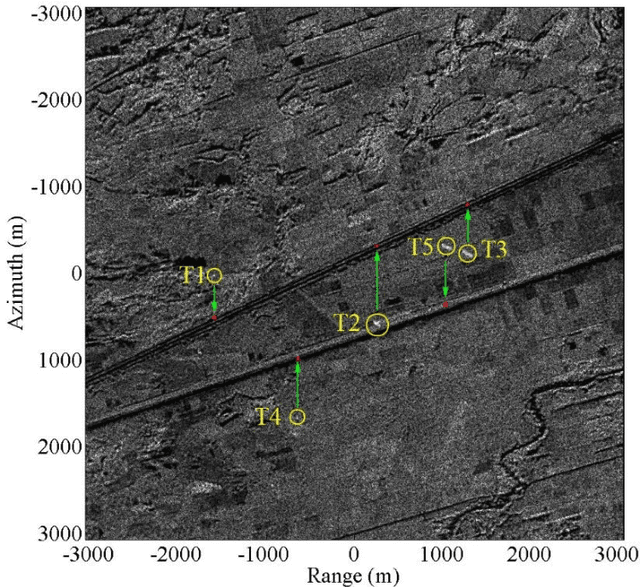
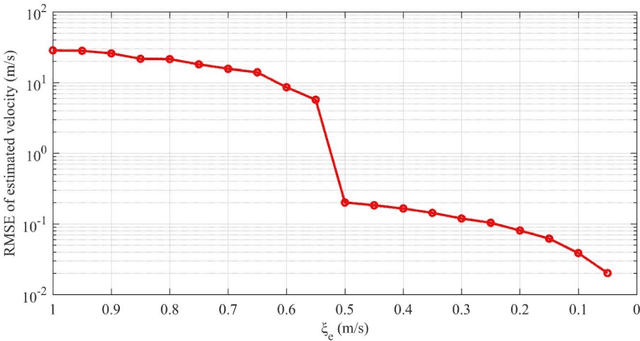
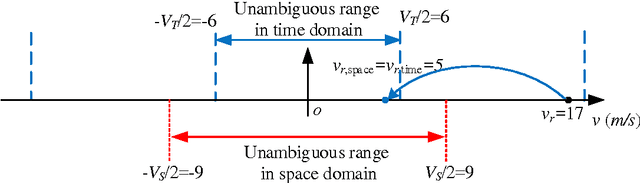
In this paper, with respect to multichannel synthetic aperture radars (SAR), we first formulate the problems of Doppler ambiguities on the radial velocity (RV) estimation of a ground moving target in range-compressed domain, range-Doppler domain and image domain, respectively. It is revealed that in these problems, a cascaded time-space Doppler ambiguity (CTSDA) may encounter, i.e., time domain Doppler ambiguity (TDDA) in each channel arises first and then spatial domain Doppler ambiguity (SDDA) among multi-channels arises second. Accordingly, the multichannel SAR systems with different parameters are investigated in three different cases with diverse Doppler ambiguity properties, and a multi-frequency SAR is then proposed to obtain the RV estimation by solving the ambiguity problem based on Chinese remainder theorem (CRT). In the first two cases, the ambiguity problem can be solved by the existing closed-form robust CRT. In the third case, it is found that the problem is different from the conventional CRT problems and we call it a double remaindering problem in this paper. We then propose a sufficient condition under which the double remaindering problem, i.e., the CTSDA, can also be solved by the closed-form robust CRT. When the sufficient condition is not satisfied for a multi-channel SAR, a searching based method is proposed. Finally, some results of numerical experiments are provided to demonstrate the effectiveness of the proposed methods.
Robust Model Predictive Longitudinal Position Tracking Control for an Autonomous Vehicle Based on Multiple Models
Sep 28, 2020
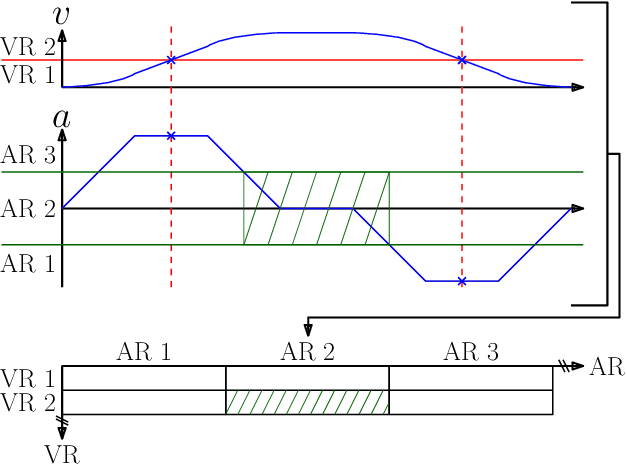
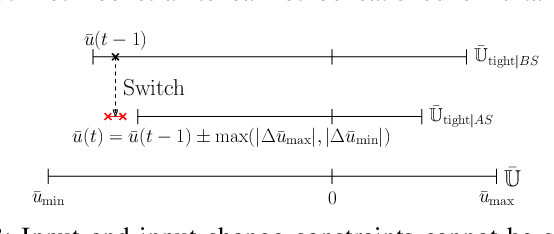
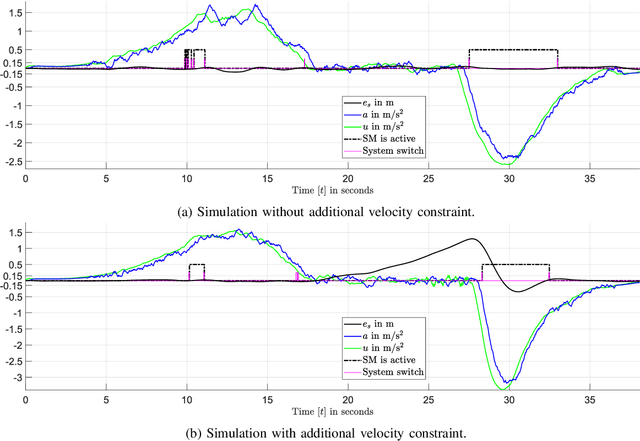
The aim of this work is to control the longitudinal position of an autonomous vehicle with an internal combustion engine. The powertrain has an inherent dead-time characteristic and constraints on physical states apply since the vehicle is neither able to accelerate arbitrarily strong, nor to drive arbitrarily fast. A model predictive controller (MPC) is able to cope with both of the aforementioned system properties. MPC heavily relies on a model and therefore a strategy on how to obtain multiple linear state space prediction models of the nonlinear system via input/output data system identification from acceleration data is given. The models are identified in different regions of the vehicle dynamics in order to obtain more accurate predictions. The still remaining plant-model mismatch can be expressed as an additive disturbance which can be handled through robust control theory. Therefore modifications to the models for applying robust MPC tracking control theory are described. Then a controller which guarantees robust constraint satisfaction and recursive feasibility is designed. As a next step, modifications to apply the controller on multiple models are discussed. In this context, a model switching strategy is provided and theoretical and computational limitations are pointed out. Lastly, simulation results are presented and discussed, including computational load when switching between systems.
Adaptive Neural Network-Based Approximation to Accelerate Eulerian Fluid Simulation
Aug 26, 2020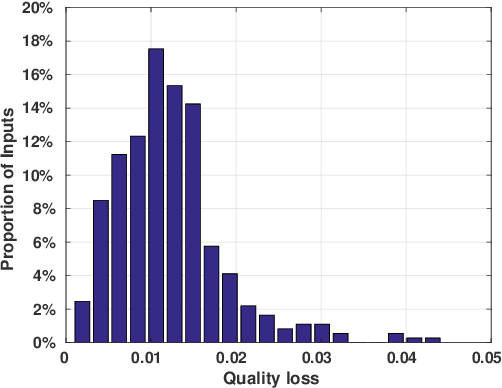
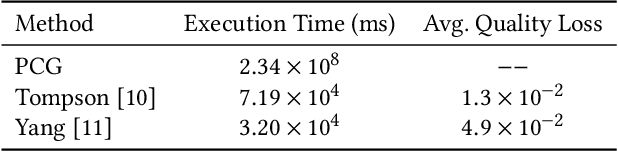
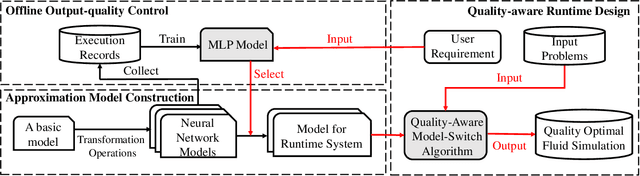
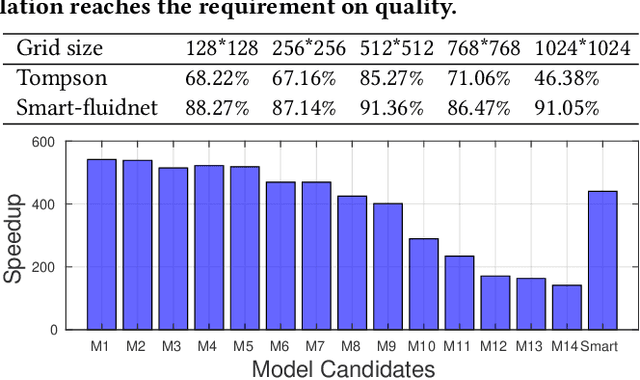
The Eulerian fluid simulation is an important HPC application. The neural network has been applied to accelerate it. The current methods that accelerate the fluid simulation with neural networks lack flexibility and generalization. In this paper, we tackle the above limitation and aim to enhance the applicability of neural networks in the Eulerian fluid simulation. We introduce Smartfluidnet, a framework that automates model generation and application. Given an existing neural network as input, Smartfluidnet generates multiple neural networks before the simulation to meet the execution time and simulation quality requirement. During the simulation, Smartfluidnet dynamically switches the neural networks to make the best efforts to reach the user requirement on simulation quality. Evaluating with 20,480 input problems, we show that Smartfluidnet achieves 1.46x and 590x speedup comparing with a state-of-the-art neural network model and the original fluid simulation respectively on an NVIDIA Titan X Pascal GPU, while providing better simulation quality than the state-of-the-art model.
Phonological Features for 0-shot Multilingual Speech Synthesis
Aug 06, 2020


Code-switching---the intra-utterance use of multiple languages---is prevalent across the world. Within text-to-speech (TTS), multilingual models have been found to enable code-switching. By modifying the linguistic input to sequence-to-sequence TTS, we show that code-switching is possible for languages unseen during training, even within monolingual models. We use a small set of phonological features derived from the International Phonetic Alphabet (IPA), such as vowel height and frontness, consonant place and manner. This allows the model topology to stay unchanged for different languages, and enables new, previously unseen feature combinations to be interpreted by the model. We show that this allows us to generate intelligible, code-switched speech in a new language at test time, including the approximation of sounds never seen in training.
Multiple Video Frame Interpolation via Enhanced Deformable Separable Convolution
Jun 15, 2020
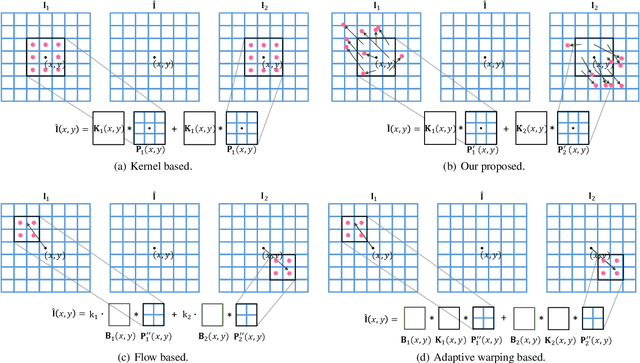

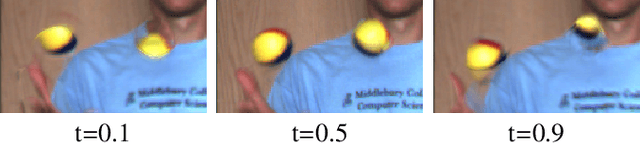
Generating non-existing frames from a consecutive video sequence has been an interesting and challenging problem in the video processing field. Recent kernel-based interpolation methods predict pixels with a single convolution process that convolves source frames with spatially adaptive local kernels. However, when scene motion is larger than the pre-defined kernel size, these methods are prone to yield less plausible results and they cannot directly generate a frame at an arbitrary temporal position because the learned kernels are tied to the midpoint in time between the input frames. In this paper, we try to solve these problems and propose a novel approach that we refer to as enhanced deformable separable convolution (EDSC) to estimate not only adaptive kernels, but also offsets, masks and biases to make the network obtain information from non-local neighborhood. During the learning process, different intermediate time step can be involved as a control variable by means of the coord-conv trick, allowing the estimated components to vary with different input temporal information. This makes our method capable to produce multiple in-between frames. Furthermore, we investigate the relationships between our method and other typical kernel- and flow-based methods. Experimental results show that our method performs favorably against the state-of-the-art methods across a broad range of datasets. Code will be publicly available on URL: \url{https://github.com/Xianhang/EDSC-pytorch}.
Learning to Factorize and Relight a City
Aug 06, 2020
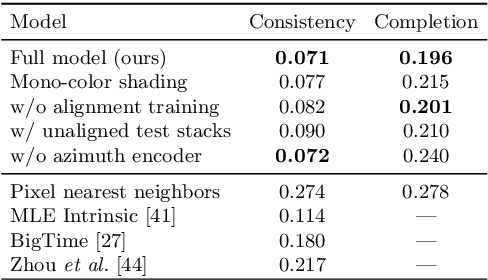


We propose a learning-based framework for disentangling outdoor scenes into temporally-varying illumination and permanent scene factors. Inspired by the classic intrinsic image decomposition, our learning signal builds upon two insights: 1) combining the disentangled factors should reconstruct the original image, and 2) the permanent factors should stay constant across multiple temporal samples of the same scene. To facilitate training, we assemble a city-scale dataset of outdoor timelapse imagery from Google Street View, where the same locations are captured repeatedly through time. This data represents an unprecedented scale of spatio-temporal outdoor imagery. We show that our learned disentangled factors can be used to manipulate novel images in realistic ways, such as changing lighting effects and scene geometry. Please visit factorize-a-city.github.io for animated results.