 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Timeliness: A New Design Metric and a New Attack Surface
Dec 28, 2023
As the landscape of time-sensitive applications gains prominence in 5G/6G communications, timeliness of information updates at network nodes has become crucial, which is popularly quantified in the literature by the age of information metric. However, as we devise policies to improve age of information of our systems, we inadvertently introduce a new vulnerability for adversaries to exploit. In this article, we comprehensively discuss the diverse threats that age-based systems are vulnerable to. We begin with discussion on densely interconnected networks that employ gossiping between nodes to expedite dissemination of dynamic information in the network, and show how the age-based nature of gossiping renders these networks uniquely susceptible to threats such as timestomping attacks, jamming attacks, and the propagation of misinformation. Later, we survey adversarial works within simpler network settings, specifically in one-hop and two-hop configurations, and delve into adversarial robustness concerning challenges posed by jamming, timestomping, and issues related to privacy leakage. We conclude this article with future directions that aim to address challenges posed by more intelligent adversaries and robustness of networks to them.
On Chernoff Lower-Bound of Outage Threshold for Non-Central $χ^2$-Distributed Beamforming Gain in URLLC Systems
Dec 28, 2023The cumulative distribution function (CDF) of a non-central $\chi^2$-distributed random variable (RV) is often used when measuring the outage probability of communication systems. For ultra-reliable low-latency communication (URLLC), it is important but mathematically challenging to determine the outage threshold for an extremely small outage target. This motivates us to investigate lower bounds of the outage threshold, and it is found that the one derived from the Chernoff inequality (named Cher-LB) is the most effective lower bound. This finding is associated with three rigorously established properties of the Cher-LB with respect to the mean, variance, reliability requirement, and degrees of freedom of the non-central $\chi^2$-distributed RV. The Cher-LB is then employed to predict the beamforming gain in URLLC for both conventional multi-antenna systems (i.e., MIMO) under first-order Markov time-varying channel and reconfigurable intellgent surface (RIS) systems. It is exhibited that, with the proposed Cher-LB, the pessimistic prediction of the beamforming gain is made sufficiently accurate for guaranteed reliability as well as the transmit-energy efficiency.
Periodic Vibration Gaussian: Dynamic Urban Scene Reconstruction and Real-time Rendering
Nov 30, 2023Modeling dynamic, large-scale urban scenes is challenging due to their highly intricate geometric structures and unconstrained dynamics in both space and time. Prior methods often employ high-level architectural priors, separating static and dynamic elements, resulting in suboptimal capture of their synergistic interactions. To address this challenge, we present a unified representation model, called Periodic Vibration Gaussian (PVG). PVG builds upon the efficient 3D Gaussian splatting technique, originally designed for static scene representation, by introducing periodic vibration-based temporal dynamics. This innovation enables PVG to elegantly and uniformly represent the characteristics of various objects and elements in dynamic urban scenes. To enhance temporally coherent representation learning with sparse training data, we introduce a novel flow-based temporal smoothing mechanism and a position-aware adaptive control strategy. Extensive experiments on Waymo Open Dataset and KITTI benchmarks demonstrate that PVG surpasses state-of-the-art alternatives in both reconstruction and novel view synthesis for both dynamic and static scenes. Notably, PVG achieves this without relying on manually labeled object bounding boxes or expensive optical flow estimation. Moreover, PVG exhibits 50/6000-fold acceleration in training/rendering over the best alternative.
AI and Tempo Estimation: A Review
Dec 30, 2023The author's goal in this paper is to explore how artificial intelligence (AI) has been utilised to inform our understanding of and ability to estimate at scale a critical aspect of musical creativity - musical tempo. The central importance of tempo to musical creativity can be seen in how it is used to express specific emotions (Eerola and Vuoskoski 2013), suggest particular musical styles (Li and Chan 2011), influence perception of expression (Webster and Weir 2005) and mediate the urge to move one's body in time to the music (Burger et al. 2014). Traditional tempo estimation methods typically detect signal periodicities that reflect the underlying rhythmic structure of the music, often using some form of autocorrelation of the amplitude envelope (Lartillot and Toiviainen 2007). Recently, AI-based methods utilising convolutional or recurrent neural networks (CNNs, RNNs) on spectral representations of the audio signal have enjoyed significant improvements in accuracy (Aarabi and Peeters 2022). Common AI-based techniques include those based on probability (e.g., Bayesian approaches, hidden Markov models (HMM)), classification and statistical learning (e.g., support vector machines (SVM)), and artificial neural networks (ANNs) (e.g., self-organising maps (SOMs), CNNs, RNNs, deep learning (DL)). The aim here is to provide an overview of some of the more common AI-based tempo estimation algorithms and to shine a light on notable benefits and potential drawbacks of each. Limitations of AI in this field in general are also considered, as is the capacity for such methods to account for idiosyncrasies inherent in tempo perception, i.e., how well AI-based approaches are able to think and act like humans.
FIKIT: Priority-Based Real-time GPU Multi-tasking Scheduling with Kernel Identification
Nov 24, 2023Highly parallelized workloads like machine learning training, inferences and general HPC tasks are greatly accelerated using GPU devices. In a cloud computing cluster, serving a GPU's computation power through multi-tasks sharing is highly demanded since there are always more task requests than the number of GPU available. Existing GPU sharing solutions focus on reducing task-level waiting time or task-level switching costs when multiple jobs competing for a single GPU. Non-stopped computation requests come with different priorities, having non-symmetric impact on QoS for sharing a GPU device. Existing work missed the kernel-level optimization opportunity brought by this setting. To address this problem, we present a novel kernel-level scheduling strategy called FIKIT: Filling Inter-kernel Idle Time. FIKIT incorporates task-level priority information, fine-grained kernel identification, and kernel measurement, allowing low priorities task's execution during high priority task's inter-kernel idle time. Thereby, filling the GPU's device runtime fully, and reduce overall GPU sharing impact to cloud services. Across a set of ML models, the FIKIT based inference system accelerated high priority tasks by 1.33 to 14.87 times compared to the JCT in GPU sharing mode, and more than half of the cases are accelerated by more than 3.5 times. Alternatively, under preemptive sharing, the low-priority tasks have a comparable to default GPU sharing mode JCT, with a 0.84 to 1 times ratio. We further limit the kernel measurement and runtime fine-grained kernel scheduling overhead to less than 10%.
Structured Estimation of Heterogeneous Time Series
Nov 15, 2023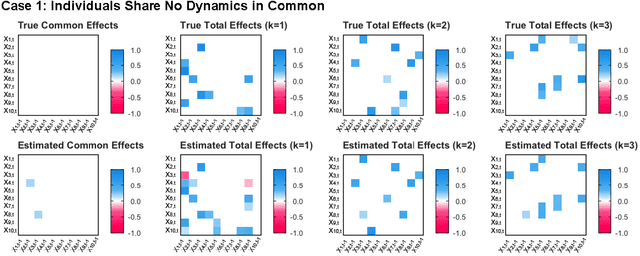
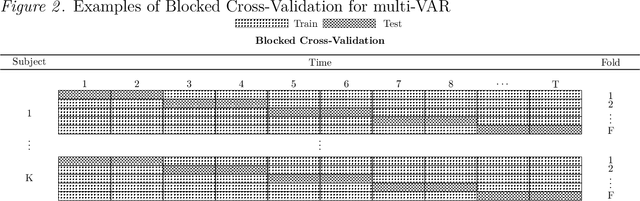
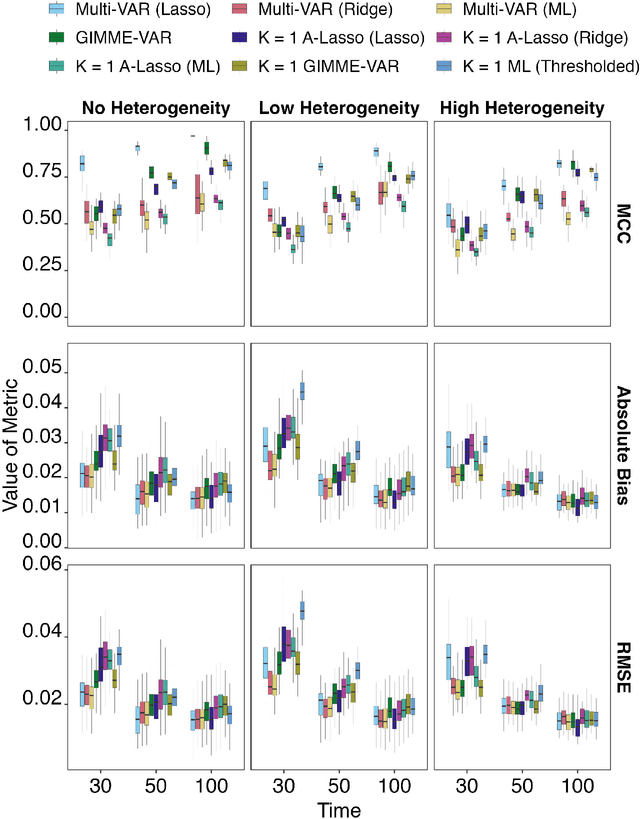
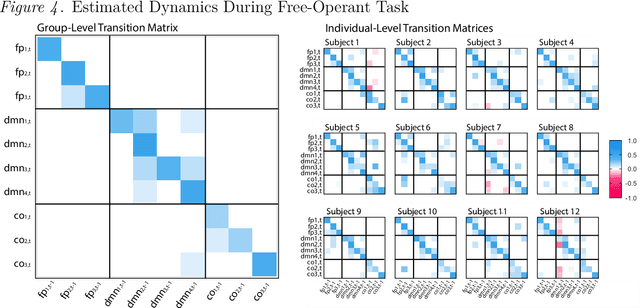
How best to model structurally heterogeneous processes is a foundational question in the social, health and behavioral sciences. Recently, Fisher et al., (2022) introduced the multi-VAR approach for simultaneously estimating multiple-subject multivariate time series characterized by common and individualizing features using penalized estimation. This approach differs from many popular modeling approaches for multiple-subject time series in that qualitative and quantitative differences in a large number of individual dynamics are well-accommodated. The current work extends the multi-VAR framework to include new adaptive weighting schemes that greatly improve estimation performance. In a small set of simulation studies we compare adaptive multi-VAR with these new penalty weights to common alternative estimators in terms of path recovery and bias. Furthermore, we provide toy examples and code demonstrating the utility of multi-VAR under different heterogeneity regimes using the multivar package for R (Fisher, 2022).
How to Efficiently Annotate Images for Best-Performing Deep Learning Based Segmentation Models: An Empirical Study with Weak and Noisy Annotations and Segment Anything Model
Dec 20, 2023Deep neural networks (DNNs) have been deployed for many image segmentation tasks and achieved outstanding performance. However, preparing a dataset for training segmentation DNNs is laborious and costly since typically pixel-level annotations are provided for each object of interest. To alleviate this issue, one can provide only weak labels such as bounding boxes or scribbles, or less accurate (noisy) annotations of the objects. These are significantly faster to generate and thus result in more annotated images given the same time budget. However, the reduction in quality might negatively affect the segmentation performance of the resulting model. In this study, we perform a thorough cost-effectiveness evaluation of several weak and noisy labels. We considered 11 variants of annotation strategies and 4 datasets. We conclude that the common practice of accurately outlining the objects of interest is virtually never the optimal approach when the annotation time is limited, even if notable annotation time is available (10s of hours). Annotation approaches that stood out in such scenarios were (1) contour-based annotation with rough continuous traces, (2) polygon-based annotation with few vertices, and (3) box annotations combined with the Segment Anything Model (SAM). In situations where unlimited annotation time was available, precise annotations still lead to the highest segmentation model performance.
Deep Copula-Based Survival Analysis for Dependent Censoring with Identifiability Guarantees
Dec 24, 2023Censoring is the central problem in survival analysis where either the time-to-event (for instance, death), or the time-tocensoring (such as loss of follow-up) is observed for each sample. The majority of existing machine learning-based survival analysis methods assume that survival is conditionally independent of censoring given a set of covariates; an assumption that cannot be verified since only marginal distributions is available from the data. The existence of dependent censoring, along with the inherent bias in current estimators has been demonstrated in a variety of applications, accentuating the need for a more nuanced approach. However, existing methods that adjust for dependent censoring require practitioners to specify the ground truth copula. This requirement poses a significant challenge for practical applications, as model misspecification can lead to substantial bias. In this work, we propose a flexible deep learning-based survival analysis method that simultaneously accommodate for dependent censoring and eliminates the requirement for specifying the ground truth copula. We theoretically prove the identifiability of our model under a broad family of copulas and survival distributions. Experiments results from a wide range of datasets demonstrate that our approach successfully discerns the underlying dependency structure and significantly reduces survival estimation bias when compared to existing methods.
METER: A Dynamic Concept Adaptation Framework for Online Anomaly Detection
Dec 28, 2023Real-time analytics and decision-making require online anomaly detection (OAD) to handle drifts in data streams efficiently and effectively. Unfortunately, existing approaches are often constrained by their limited detection capacity and slow adaptation to evolving data streams, inhibiting their efficacy and efficiency in handling concept drift, which is a major challenge in evolving data streams. In this paper, we introduce METER, a novel dynamic concept adaptation framework that introduces a new paradigm for OAD. METER addresses concept drift by first training a base detection model on historical data to capture recurring central concepts, and then learning to dynamically adapt to new concepts in data streams upon detecting concept drift. Particularly, METER employs a novel dynamic concept adaptation technique that leverages a hypernetwork to dynamically generate the parameter shift of the base detection model, providing a more effective and efficient solution than conventional retraining or fine-tuning approaches. Further, METER incorporates a lightweight drift detection controller, underpinned by evidential deep learning, to support robust and interpretable concept drift detection. We conduct an extensive experimental evaluation, and the results show that METER significantly outperforms existing OAD approaches in various application scenarios.
SparseProp: Efficient Event-Based Simulation and Training of Sparse Recurrent Spiking Neural Networks
Dec 28, 2023Spiking Neural Networks (SNNs) are biologically-inspired models that are capable of processing information in streams of action potentials. However, simulating and training SNNs is computationally expensive due to the need to solve large systems of coupled differential equations. In this paper, we introduce SparseProp, a novel event-based algorithm for simulating and training sparse SNNs. Our algorithm reduces the computational cost of both the forward and backward pass operations from O(N) to O(log(N)) per network spike, thereby enabling numerically exact simulations of large spiking networks and their efficient training using backpropagation through time. By leveraging the sparsity of the network, SparseProp eliminates the need to iterate through all neurons at each spike, employing efficient state updates instead. We demonstrate the efficacy of SparseProp across several classical integrate-and-fire neuron models, including a simulation of a sparse SNN with one million LIF neurons. This results in a speed-up exceeding four orders of magnitude relative to previous event-based implementations. Our work provides an efficient and exact solution for training large-scale spiking neural networks and opens up new possibilities for building more sophisticated brain-inspired models.