 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-Time Depth Refinement for Specular Objects
Mar 30, 2016
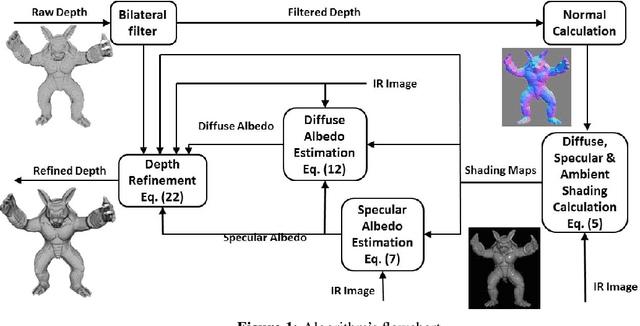
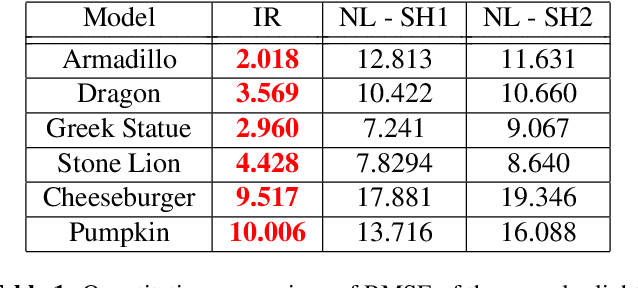
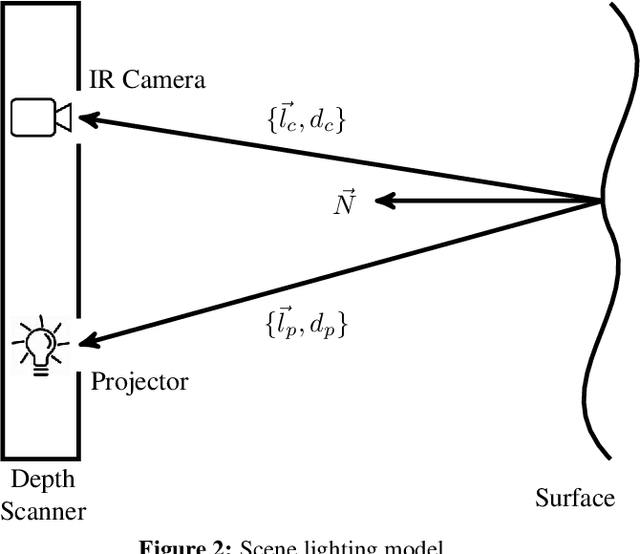
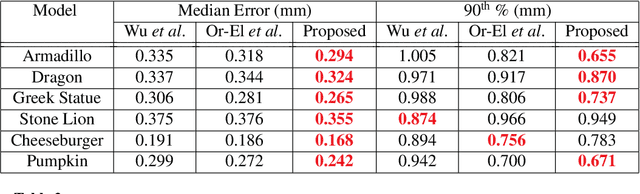
The introduction of consumer RGB-D scanners set off a major boost in 3D computer vision research. Yet, the precision of existing depth scanners is not accurate enough to recover fine details of a scanned object. While modern shading based depth refinement methods have been proven to work well with Lambertian objects, they break down in the presence of specularities. We present a novel shape from shading framework that addresses this issue and enhances both diffuse and specular objects' depth profiles. We take advantage of the built-in monochromatic IR projector and IR images of the RGB-D scanners and present a lighting model that accounts for the specular regions in the input image. Using this model, we reconstruct the depth map in real-time. Both quantitative tests and visual evaluations prove that the proposed method produces state of the art depth reconstruction results.
Few shot clustering for indoor occupancy detection with extremely low-quality images from battery free cameras
Aug 13, 2020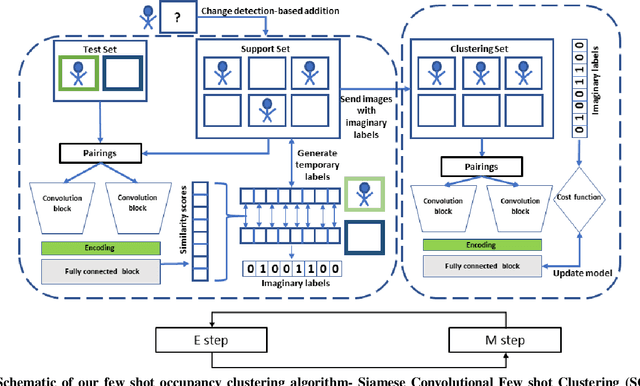
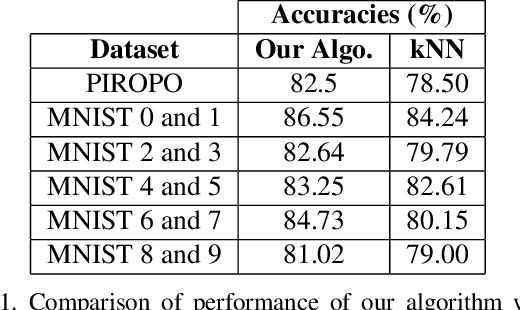
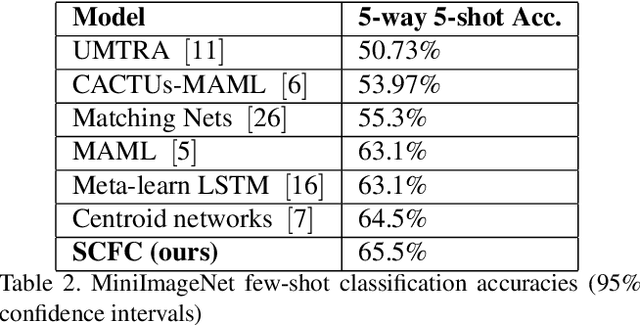
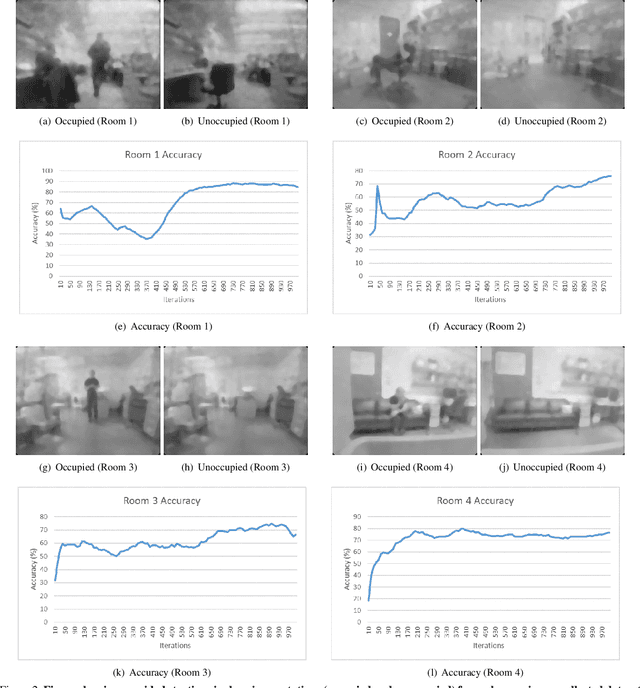
Reliable detection of human occupancy in indoor environments is critical for various energy efficiency, security, and safety applications. We consider this challenge of occupancy detection using extremely low-quality, privacy-preserving images from low power image sensors. We propose a combined few shot learning and clustering algorithm to address this challenge that has very low commissioning and maintenance cost. While the few shot learning concept enables us to commission our system with a few labeled examples, the clustering step serves the purpose of online adaptation to changing imaging environment over time. Apart from validating and comparing our algorithm on benchmark datasets, we also demonstrate performance of our algorithm on streaming images collected from real homes using our novel battery free camera hardware.
What Can We Learn From Almost a Decade of Food Tweets
Jul 10, 2020

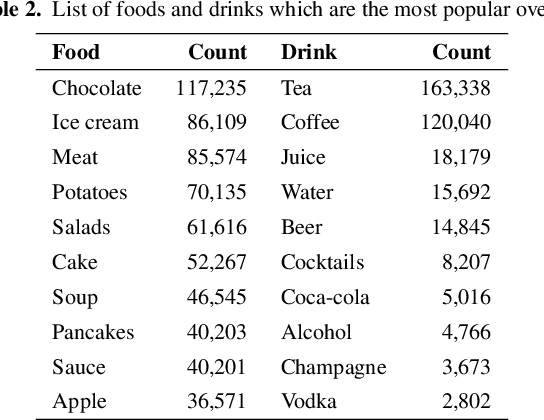
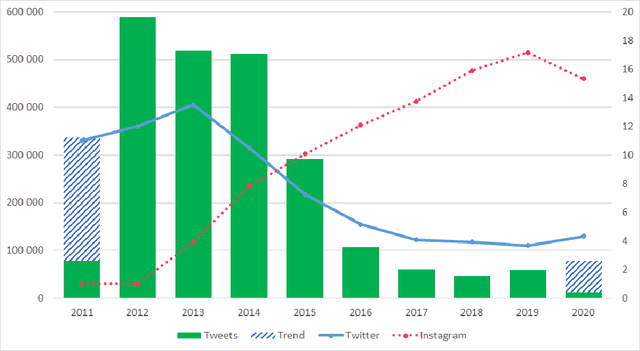
We present the Latvian Twitter Eater Corpus - a set of tweets in the narrow domain related to food, drinks, eating and drinking. The corpus has been collected over time-span of over 8 years and includes over 2 million tweets entailed with additional useful data. We also separate two sub-corpora of question and answer tweets and sentiment annotated tweets. We analyse contents of the corpus and demonstrate use-cases for the sub-corpora by training domain-specific question-answering and sentiment-analysis models using data from the corpus.
Non-Convex Exact Community Recovery in Stochastic Block Model
Jun 29, 2020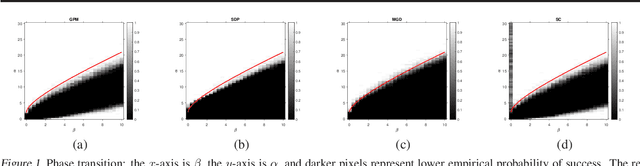

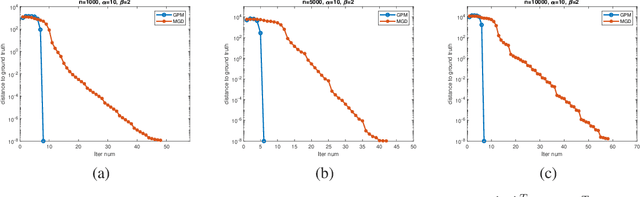
Learning community structures in graphs that are randomly generated by stochastic block models (SBMs) has received much attention lately. In this paper, we focus on the problem of exactly recovering the communities in a binary symmetric SBM, where a graph of $n$ vertices is partitioned into two equal-sized communities and the vertices are connected with probability $p = \alpha\log(n)/n$ within communities and $q = \beta\log(n)/n$ across communities for some $\alpha>\beta>0$. We propose a two-stage iterative algorithm for solving this problem, which employs the power method with a random starting point in the first-stage and turns to a generalized power method that can identify the communities in a finite number of iterations in the second-stage. It is shown that for any fixed $\alpha$ and $\beta$ such that $\sqrt{\alpha} - \sqrt{\beta} > \sqrt{2}$, which is known to be the information-theoretic limit for exact recovery, the proposed algorithm exactly identifies the underlying communities in $\tilde{O}(n)$ running time with probability tending to one as $n\rightarrow\infty$. As far as we know, this is the first algorithm with nearly-linear running time that achieves exact recovery at the information-theoretic limit. We also present numerical results of the proposed algorithm to support and complement our theoretical development.
H2O-Net: Self-Supervised Flood Segmentation via Adversarial Domain Adaptation and Label Refinement
Oct 11, 2020
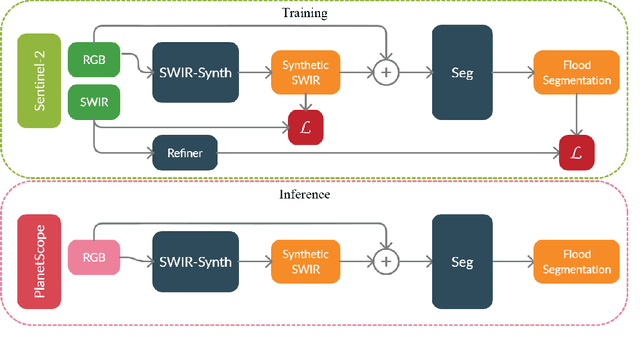
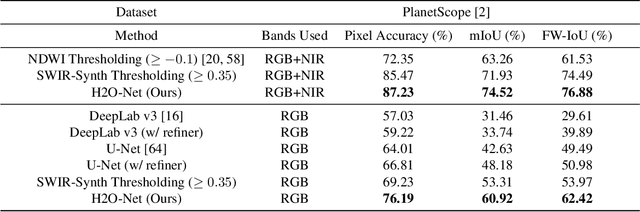
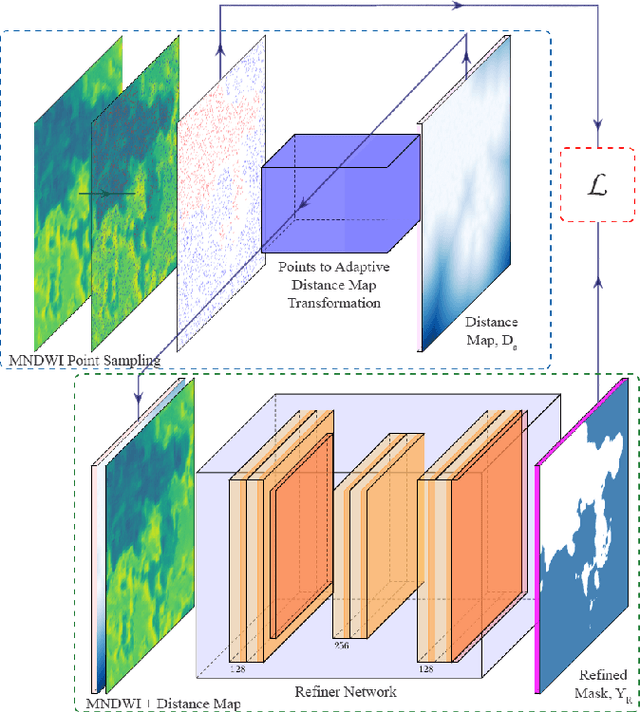
Accurate flood detection in near real time via high resolution, high latency satellite imagery is essential to prevent loss of lives by providing quick and actionable information. Instruments and sensors useful for flood detection are only available in low resolution, low latency satellites with region re-visit periods of up to 16 days, making flood alerting systems that use such satellites unreliable. This work presents H2O-Network, a self supervised deep learning method to segment floods from satellites and aerial imagery by bridging domain gap between low and high latency satellite and coarse-to-fine label refinement. H2O-Net learns to synthesize signals highly correlative with water presence as a domain adaptation step for semantic segmentation in high resolution satellite imagery. Our work also proposes a self-supervision mechanism, which does not require any hand annotation, used during training to generate high quality ground truth data. We demonstrate that H2O-Net outperforms the state-of-the-art semantic segmentation methods on satellite imagery by 10% and 12% pixel accuracy and mIoU respectively for the task of flood segmentation. We emphasize the generalizability of our model by transferring model weights trained on satellite imagery to drone imagery, a highly different sensor and domain.
MixML: A Unified Analysis of Weakly Consistent Parallel Learning
May 14, 2020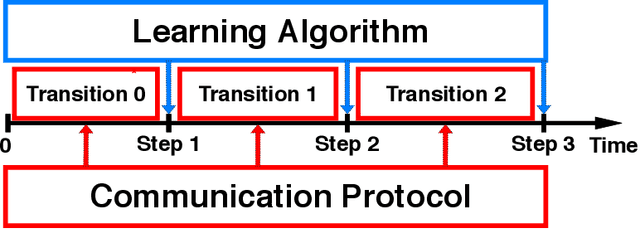
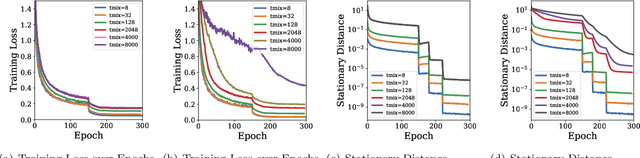
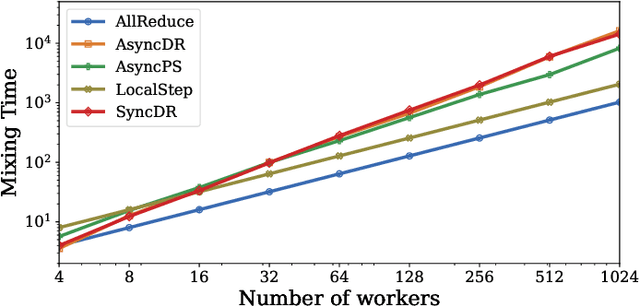
Parallelism is a ubiquitous method for accelerating machine learning algorithms. However, theoretical analysis of parallel learning is usually done in an algorithm- and protocol-specific setting, giving little insight about how changes in the structure of communication could affect convergence. In this paper we propose MixML, a general framework for analyzing convergence of weakly consistent parallel machine learning. Our framework includes: (1) a unified way of modeling the communication process among parallel workers; (2) a new parameter, the mixing time tmix, that quantifies how the communication process affects convergence; and (3) a principled way of converting a convergence proof for a sequential algorithm into one for a parallel version that depends only on tmix. We show MixML recovers and improves on known convergence bounds for asynchronous and/or decentralized versions of many algorithms, includingSGD and AMSGrad. Our experiments substantiate the theory and show the dependency of convergence on the underlying mixing time.
Robotic Motion Planning using Learned Critical Sources and Local Sampling
Jun 07, 2020
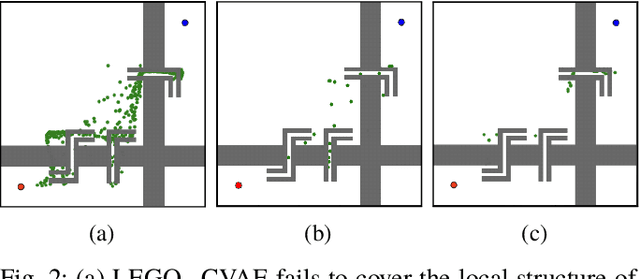
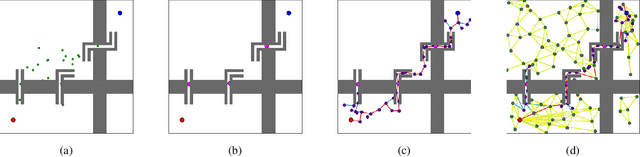
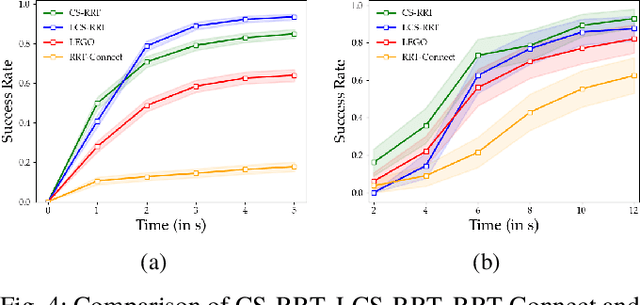
Sampling based methods are widely used for robotic motion planning. Traditionally, these samples are drawn from probabilistic ( or deterministic ) distributions to cover the state space uniformly. Despite being probabilistically complete, they fail to find a feasible path in a reasonable amount of time in constrained environments where it is essential to go through narrow passages (bottleneck regions). Current state of the art techniques train a learning model (learner) to predict samples selectively on these bottleneck regions. However, these algorithms depend completely on samples generated by this learner to navigate through the bottleneck regions. As the complexity of the planning problem increases, the amount of data and time required to make this learner robust to fine variations in the structure of the workspace becomes computationally intractable. In this work, we present (1) an efficient and robust method to use a learner to locate the bottleneck regions and (2) two algorithms that use local sampling methods to leverage the location of these bottleneck regions for efficient motion planning while maintaining probabilistic completeness. We test our algorithms on 2 dimensional planning problems and 7 dimensional robotic arm planning, and report significant gains over heuristics as well as learned baselines.
W-Cell-Net: Multi-frame Interpolation of Cellular Microscopy Videos
May 14, 2020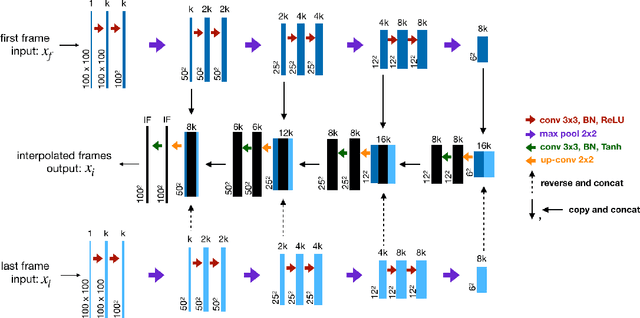
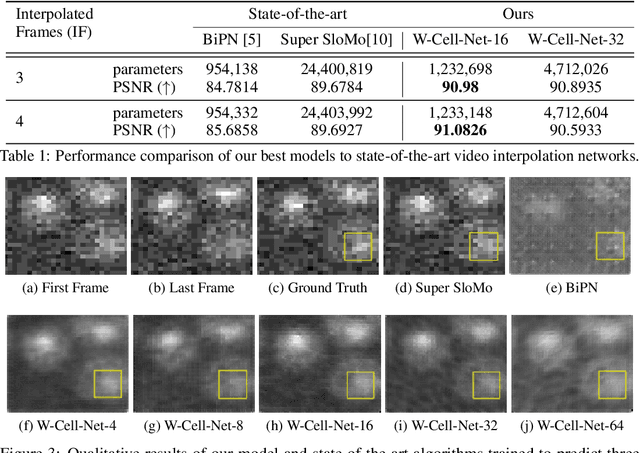
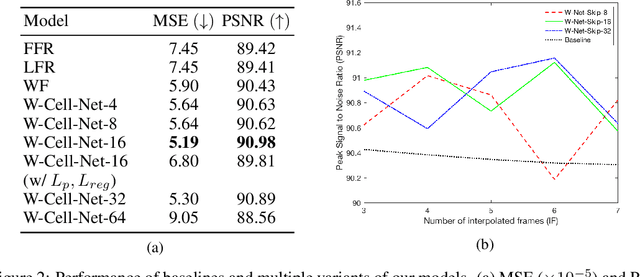
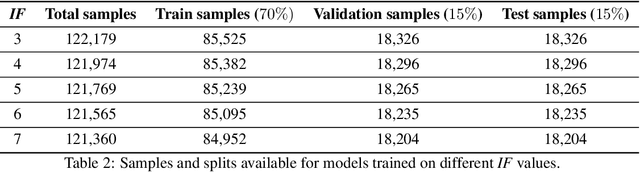
Deep Neural Networks are increasingly used in video frame interpolation tasks such as frame rate changes as well as generating fake face videos. Our project aims to apply recent advances in Deep video interpolation to increase the temporal resolution of fluorescent microscopy time-lapse movies. To our knowledge, there is no previous work that uses Convolutional Neural Networks (CNN) to generate frames between two consecutive microscopy images. We propose a fully convolutional autoencoder network that takes as input two images and generates upto seven intermediate images. Our architecture has two encoders each with a skip connection to a single decoder. We evaluate the performance of several variants of our model that differ in network architecture and loss function. Our best model out-performs state of the art video frame interpolation algorithms. We also show qualitative and quantitative comparisons with state-of-the-art video frame interpolation algorithms. We believe deep video interpolation represents a new approach to improve the time-resolution of fluorescent microscopy.
Any Time Probabilistic Reasoning for Sensor Validation
Jan 30, 2013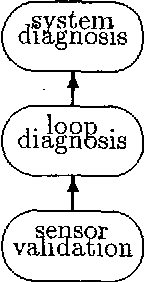
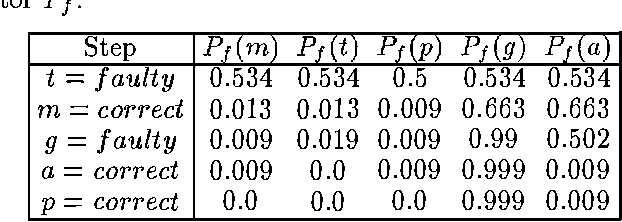

For many real time applications, it is important to validate the information received from the sensors before entering higher levels of reasoning. This paper presents an any time probabilistic algorithm for validating the information provided by sensors. The system consists of two Bayesian network models. The first one is a model of the dependencies between sensors and it is used to validate each sensor. It provides a list of potentially faulty sensors. To isolate the real faults, a second Bayesian network is used, which relates the potential faults with the real faults. This second model is also used to make the validation algorithm any time, by validating first the sensors that provide more information. To select the next sensor to validate, and measure the quality of the results at each stage, an entropy function is used. This function captures in a single quantity both the certainty and specificity measures of any time algorithms. Together, both models constitute a mechanism for validating sensors in an any time fashion, providing at each step the probability of correct/faulty for each sensor, and the total quality of the results. The algorithm has been tested in the validation of temperature sensors of a power plant.
Survival Cluster Analysis
Feb 29, 2020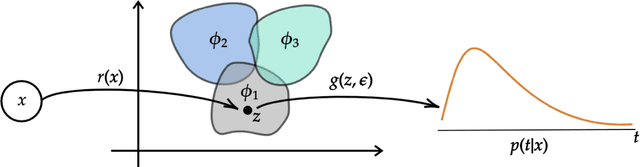
Conventional survival analysis approaches estimate risk scores or individualized time-to-event distributions conditioned on covariates. In practice, there is often great population-level phenotypic heterogeneity, resulting from (unknown) subpopulations with diverse risk profiles or survival distributions. As a result, there is an unmet need in survival analysis for identifying subpopulations with distinct risk profiles, while jointly accounting for accurate individualized time-to-event predictions. An approach that addresses this need is likely to improve characterization of individual outcomes by leveraging regularities in subpopulations, thus accounting for population-level heterogeneity. In this paper, we propose a Bayesian nonparametrics approach that represents observations (subjects) in a clustered latent space, and encourages accurate time-to-event predictions and clusters (subpopulations) with distinct risk profiles. Experiments on real-world datasets show consistent improvements in predictive performance and interpretability relative to existing state-of-the-art survival analysis models.