 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Exploratory Analysis of Covid-19 Tweets using Topic Modeling, UMAP, and DiGraphs
May 06, 2020
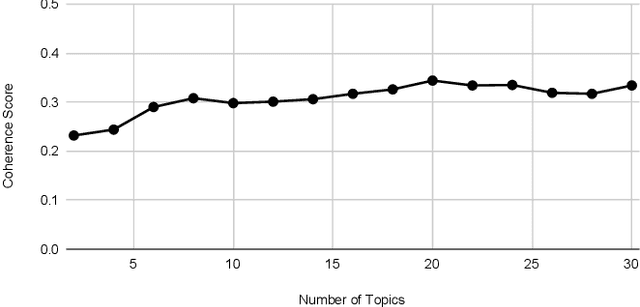
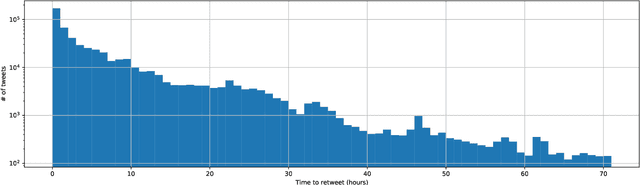
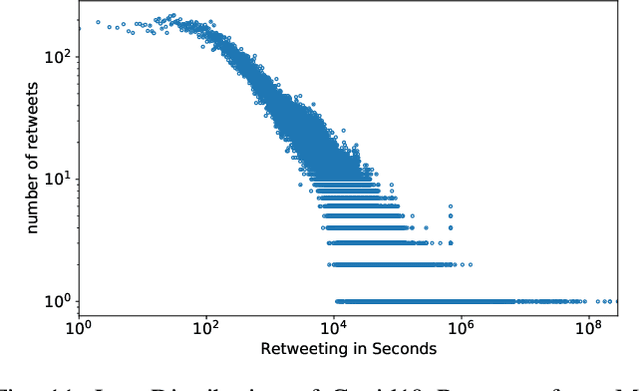
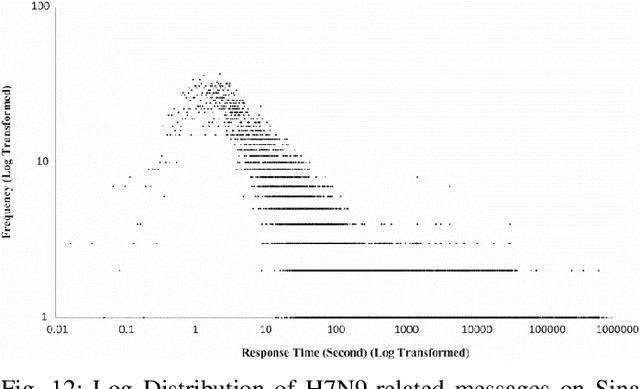
This paper illustrates five different techniques to assess the distinctiveness of topics, key terms and features, speed of information dissemination, and network behaviors for Covid19 tweets. First, we use pattern matching and second, topic modeling through Latent Dirichlet Allocation (LDA) to generate twenty different topics that discuss case spread, healthcare workers, and personal protective equipment (PPE). One topic specific to U.S. cases would start to uptick immediately after live White House Coronavirus Task Force briefings, implying that many Twitter users are paying attention to government announcements. We contribute machine learning methods not previously reported in the Covid19 Twitter literature. This includes our third method, Uniform Manifold Approximation and Projection (UMAP), that identifies unique clustering-behavior of distinct topics to improve our understanding of important themes in the corpus and help assess the quality of generated topics. Fourth, we calculated retweeting times to understand how fast information about Covid19 propagates on Twitter. Our analysis indicates that the median retweeting time of Covid19 for a sample corpus in March 2020 was 2.87 hours, approximately 50 minutes faster than repostings from Chinese social media about H7N9 in March 2013. Lastly, we sought to understand retweet cascades, by visualizing the connections of users over time from fast to slow retweeting. As the time to retweet increases, the density of connections also increase where in our sample, we found distinct users dominating the attention of Covid19 retweeters. One of the simplest highlights of this analysis is that early-stage descriptive methods like regular expressions can successfully identify high-level themes which were consistently verified as important through every subsequent analysis.
Approximately Optimal Continuous-Time Motion Planning and Control via Probabilistic Inference
Feb 27, 2017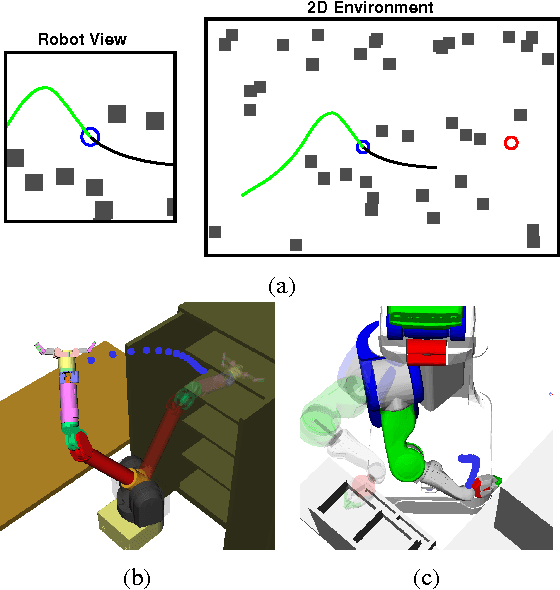
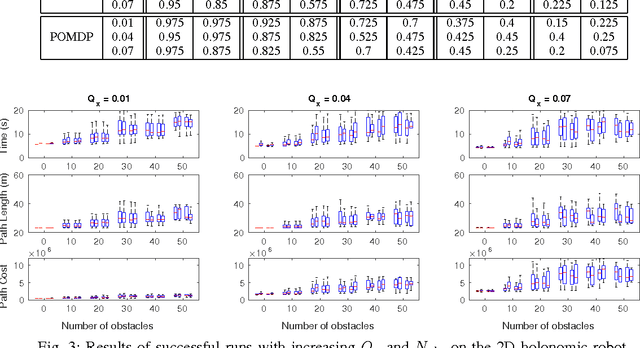
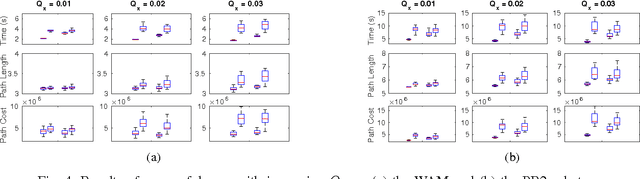
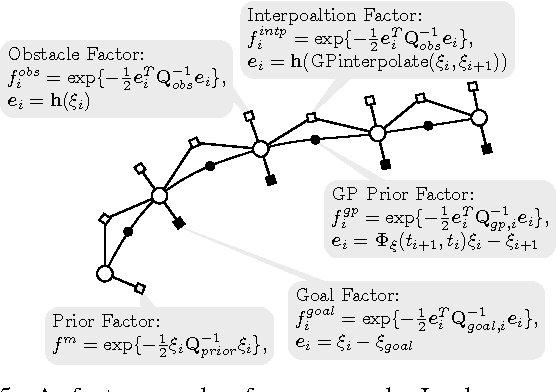
The problem of optimal motion planing and control is fundamental in robotics. However, this problem is intractable for continuous-time stochastic systems in general and the solution is difficult to approximate if non-instantaneous nonlinear performance indices are present. In this work, we provide an efficient algorithm, PIPC (Probabilistic Inference for Planning and Control), that yields approximately optimal policies with arbitrary higher-order nonlinear performance indices. Using probabilistic inference and a Gaussian process representation of trajectories, PIPC exploits the underlying sparsity of the problem such that its complexity scales linearly in the number of nonlinear factors. We demonstrate the capabilities of our algorithm in a receding horizon setting with multiple systems in simulation.
TrueImage: A Machine Learning Algorithm to Improve the Quality of Telehealth Photos
Oct 01, 2020

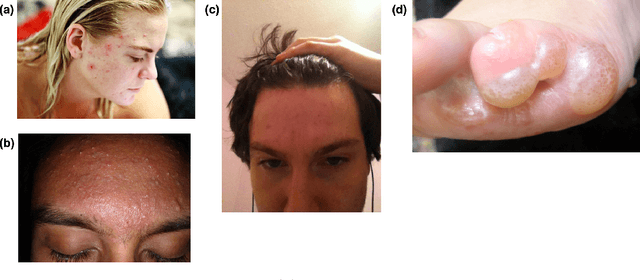

Telehealth is an increasingly critical component of the health care ecosystem, especially due to the COVID-19 pandemic. Rapid adoption of telehealth has exposed limitations in the existing infrastructure. In this paper, we study and highlight photo quality as a major challenge in the telehealth workflow. We focus on teledermatology, where photo quality is particularly important; the framework proposed here can be generalized to other health domains. For telemedicine, dermatologists request that patients submit images of their lesions for assessment. However, these images are often of insufficient quality to make a clinical diagnosis since patients do not have experience taking clinical photos. A clinician has to manually triage poor quality images and request new images to be submitted, leading to wasted time for both the clinician and the patient. We propose an automated image assessment machine learning pipeline, TrueImage, to detect poor quality dermatology photos and to guide patients in taking better photos. Our experiments indicate that TrueImage can reject 50% of the sub-par quality images, while retaining 80% of good quality images patients send in, despite heterogeneity and limitations in the training data. These promising results suggest that our solution is feasible and can improve the quality of teledermatology care.
Combining Label Propagation and Simple Models Out-performs Graph Neural Networks
Oct 27, 2020



Graph Neural Networks (GNNs) are the predominant technique for learning over graphs. However, there is relatively little understanding of why GNNs are successful in practice and whether they are necessary for good performance. Here, we show that for many standard transductive node classification benchmarks, we can exceed or match the performance of state-of-the-art GNNs by combining shallow models that ignore the graph structure with two simple post-processing steps that exploit correlation in the label structure: (i) an "error correlation" that spreads residual errors in training data to correct errors in test data and (ii) a "prediction correlation" that smooths the predictions on the test data. We call this overall procedure Correct and Smooth (C&S), and the post-processing steps are implemented via simple modifications to standard label propagation techniques from early graph-based semi-supervised learning methods. Our approach exceeds or nearly matches the performance of state-of-the-art GNNs on a wide variety of benchmarks, with just a small fraction of the parameters and orders of magnitude faster runtime. For instance, we exceed the best known GNN performance on the OGB-Products dataset with 137 times fewer parameters and greater than 100 times less training time. The performance of our methods highlights how directly incorporating label information into the learning algorithm (as was done in traditional techniques) yields easy and substantial performance gains. We can also incorporate our techniques into big GNN models, providing modest gains. Our code for the OGB results is at https://github.com/Chillee/CorrectAndSmooth.
Robustness Analysis of Neural Networks via Efficient Partitioning: Theory and Applications in Control Systems
Oct 01, 2020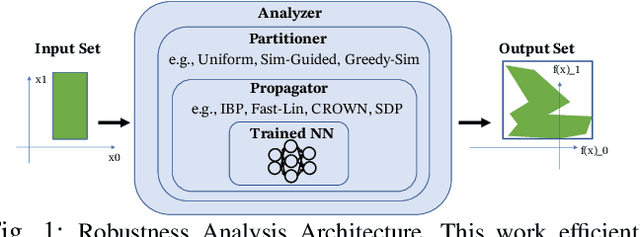
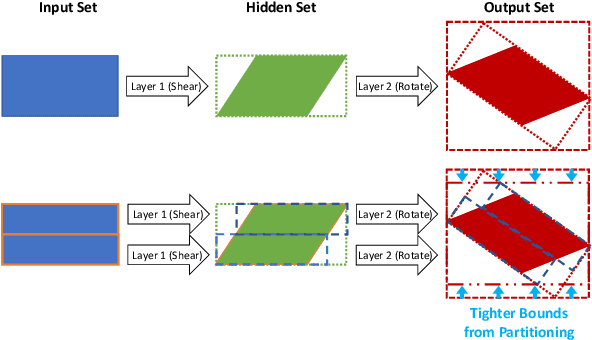
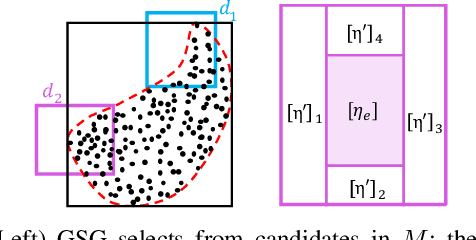
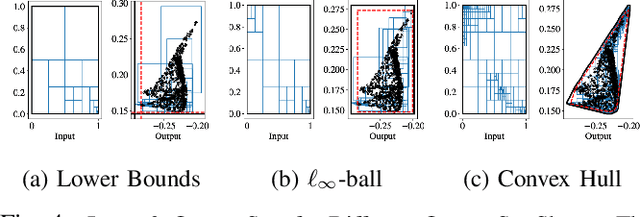
Neural networks (NNs) are now routinely implemented on systems that must operate in uncertain environments, but the tools for formally analyzing how this uncertainty propagates to NN outputs are not yet commonplace. Computing tight bounds on NN output sets (given an input set) provides a measure of confidence associated with the NN decisions and is essential to deploy NNs on safety-critical systems. Recent works approximate the propagation of sets through nonlinear activations or partition the uncertainty set to provide a guaranteed outer bound on the set of possible NN outputs. However, the bound looseness causes excessive conservatism and/or the computation is too slow for online analysis. This paper unifies propagation and partition approaches to provide a family of robustness analysis algorithms that give tighter bounds than existing works for the same amount of computation time (or reduced computational effort for a desired accuracy level). Moreover, we provide new partitioning techniques that are aware of their current bound estimates and desired boundary shape (e.g., lower bounds, weighted $\ell_\infty$-ball, convex hull), leading to further improvements in the computation-tightness tradeoff. The paper demonstrates the tighter bounds and reduced conservatism of the proposed robustness analysis framework with examples from model-free RL and forward kinematics learning.
Training Production Language Models without Memorizing User Data
Sep 21, 2020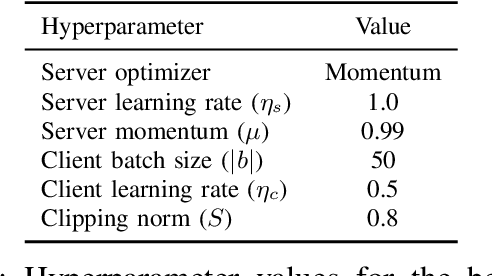
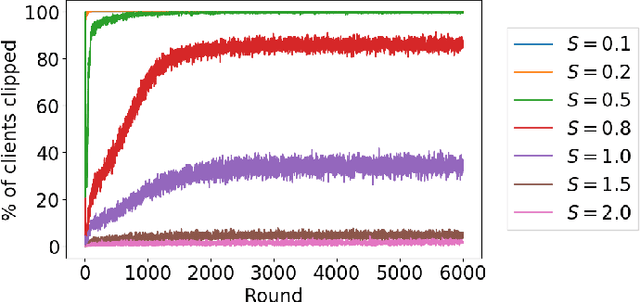
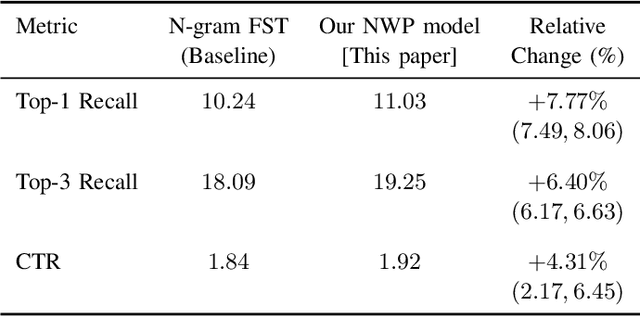
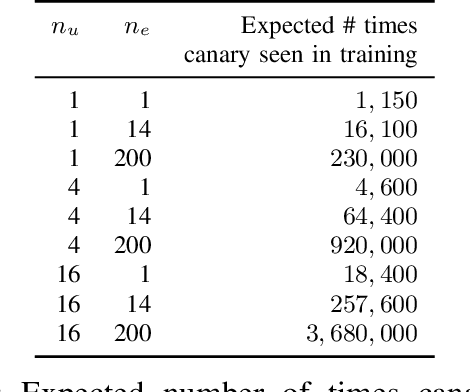
This paper presents the first consumer-scale next-word prediction (NWP) model trained with Federated Learning (FL) while leveraging the Differentially Private Federated Averaging (DP-FedAvg) technique. There has been prior work on building practical FL infrastructure, including work demonstrating the feasibility of training language models on mobile devices using such infrastructure. It has also been shown (in simulations on a public corpus) that it is possible to train NWP models with user-level differential privacy using the DP-FedAvg algorithm. Nevertheless, training production-quality NWP models with DP-FedAvg in a real-world production environment on a heterogeneous fleet of mobile phones requires addressing numerous challenges. For instance, the coordinating central server has to keep track of the devices available at the start of each round and sample devices uniformly at random from them, while ensuring \emph{secrecy of the sample}, etc. Unlike all prior privacy-focused FL work of which we are aware, for the first time we demonstrate the deployment of a differentially private mechanism for the training of a production neural network in FL, as well as the instrumentation of the production training infrastructure to perform an end-to-end empirical measurement of unintended memorization.
Intelligent Reference Curation for Visual Place Recognition via Bayesian Selective Fusion
Oct 19, 2020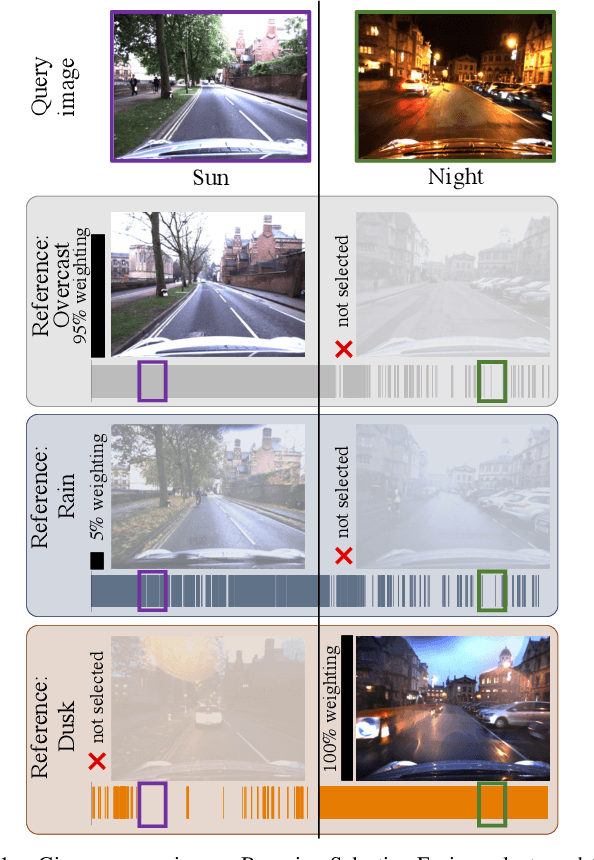
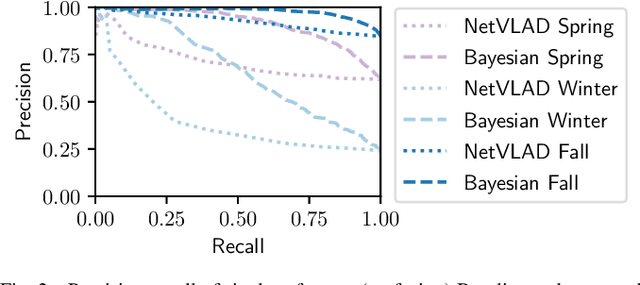
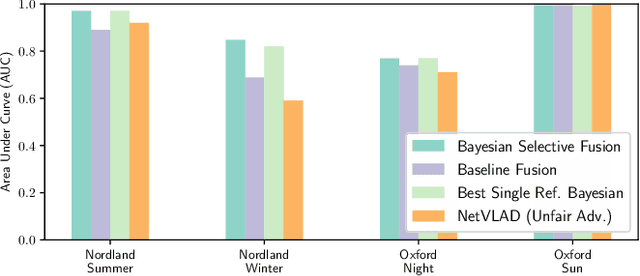
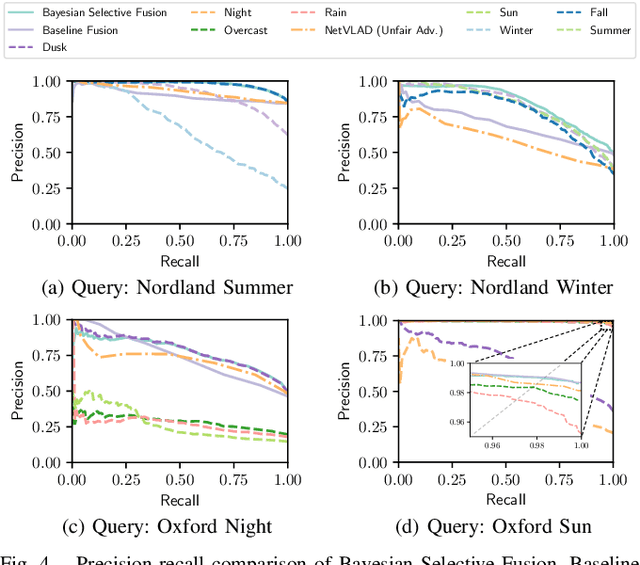
The key challenge of visual place recognition (VPR) lies in recognizing places despite drastic visual appearance changes due to factors such as time of day, season, or weather or lighting conditions. Numerous approaches based on deep-learnt image descriptors, sequence matching, domain translation, and probabilistic localization have had success in addressing this challenge, but most rely on the availability of carefully curated representative reference images of the possible places. In this paper, we propose a novel approach, dubbed Bayesian Selective Fusion, for actively selecting and fusing informative reference images to determine the best place match for a given query image. The selective element of our approach avoids the counterproductive fusion of every reference image and enables the dynamic selection of informative reference images in environments with changing visual conditions (such as indoors with flickering lights, outdoors during sunshowers or over the day-night cycle). The probabilistic element of our approach provides a means of fusing multiple reference images that accounts for their varying uncertainty via a novel training-free likelihood function for VPR. On difficult query images from two benchmark datasets, we demonstrate that our approach matches and exceeds the performance of several alternative fusion approaches along with state-of-the-art techniques that are provided with a priori (unfair) knowledge of the best reference images. Our approach is well suited for long-term robot autonomy where dynamic visual environments are commonplace since it is training-free, descriptor-agnostic, and complements existing techniques such as sequence matching.
A fully end-to-end deep learning approach for real-time simultaneous 3D reconstruction and material recognition
Mar 14, 2017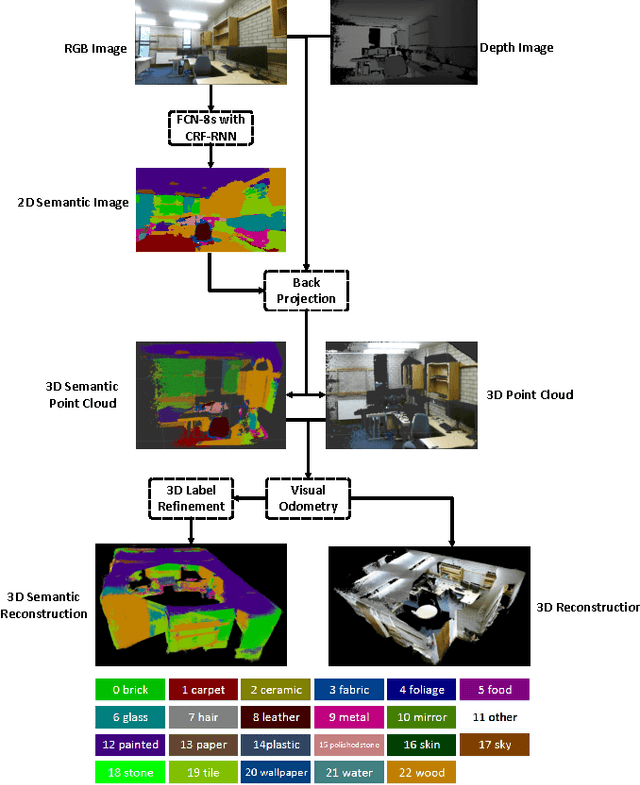
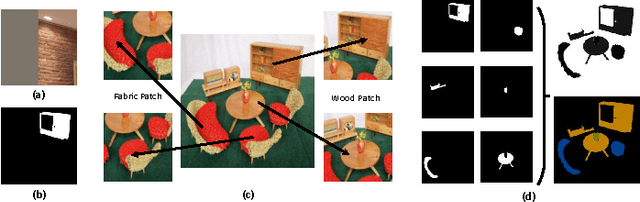

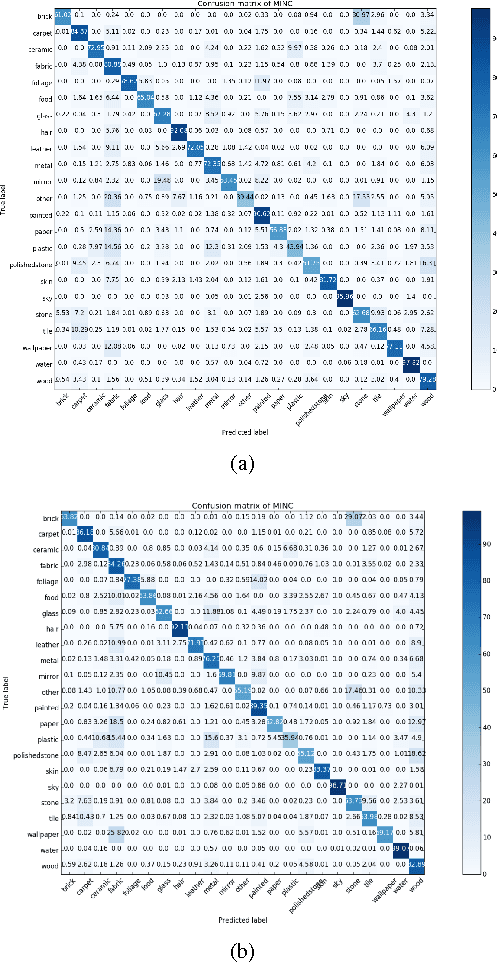
This paper addresses the problem of simultaneous 3D reconstruction and material recognition and segmentation. Enabling robots to recognise different materials (concrete, metal etc.) in a scene is important for many tasks, e.g. robotic interventions in nuclear decommissioning. Previous work on 3D semantic reconstruction has predominantly focused on recognition of everyday domestic objects (tables, chairs etc.), whereas previous work on material recognition has largely been confined to single 2D images without any 3D reconstruction. Meanwhile, most 3D semantic reconstruction methods rely on computationally expensive post-processing, using Fully-Connected Conditional Random Fields (CRFs), to achieve consistent segmentations. In contrast, we propose a deep learning method which performs 3D reconstruction while simultaneously recognising different types of materials and labelling them at the pixel level. Unlike previous methods, we propose a fully end-to-end approach, which does not require hand-crafted features or CRF post-processing. Instead, we use only learned features, and the CRF segmentation constraints are incorporated inside the fully end-to-end learned system. We present the results of experiments, in which we trained our system to perform real-time 3D semantic reconstruction for 23 different materials in a real-world application. The run-time performance of the system can be boosted to around 10Hz, using a conventional GPU, which is enough to achieve real-time semantic reconstruction using a 30fps RGB-D camera. To the best of our knowledge, this work is the first real-time end-to-end system for simultaneous 3D reconstruction and material recognition.
An Adversarial Domain Separation Framework for Septic Shock Early Prediction Across EHR Systems
Oct 26, 2020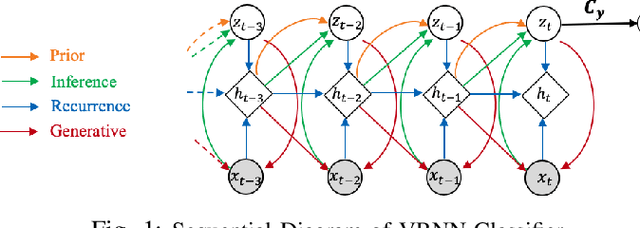
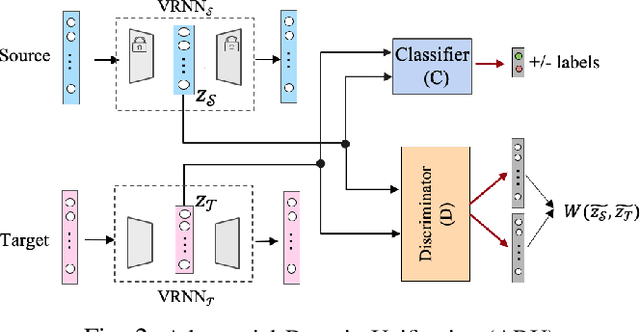
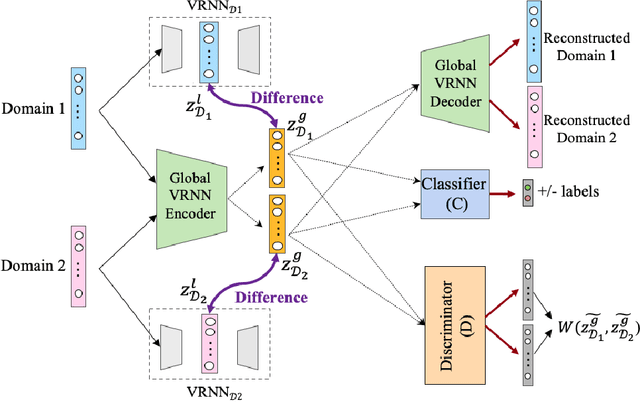
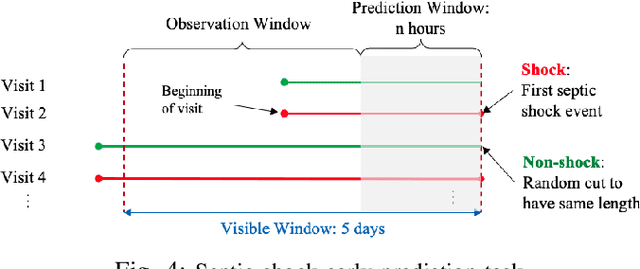
Modeling patient disease progression using Electronic Health Records (EHRs) is critical to assist clinical decision making. While most of prior work has mainly focused on developing effective disease progression models using EHRs collected from an individual medical system, relatively little work has investigated building robust yet generalizable diagnosis models across different systems. In this work, we propose a general domain adaptation (DA) framework that tackles two categories of discrepancies in EHRs collected from different medical systems: one is caused by heterogeneous patient populations (covariate shift) and the other is caused by variations in data collection procedures (systematic bias). Prior research in DA has mainly focused on addressing covariate shift but not systematic bias. In this work, we propose an adversarial domain separation framework that addresses both categories of discrepancies by maintaining one globally-shared invariant latent representation across all systems} through an adversarial learning process, while also allocating a domain-specific model for each system to extract local latent representations that cannot and should not be unified across systems. Moreover, our proposed framework is based on variational recurrent neural network (VRNN) because of its ability to capture complex temporal dependencies and handling missing values in time-series data. We evaluate our framework for early diagnosis of an extremely challenging condition, septic shock, using two real-world EHRs from distinct medical systems in the U.S. The results show that by separating globally-shared from domain-specific representations, our framework significantly improves septic shock early prediction performance in both EHRs and outperforms the current state-of-the-art DA models.
Congestion-aware Evacuation Routing using Augmented Reality Devices
Apr 25, 2020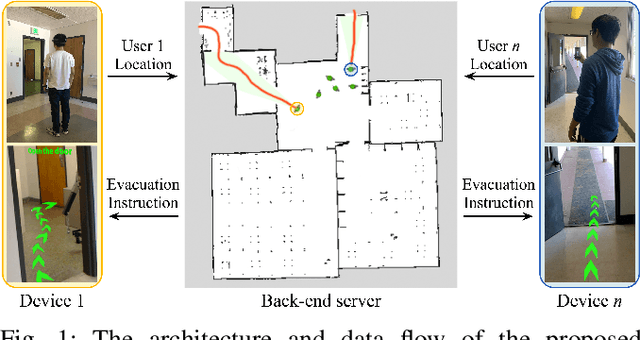
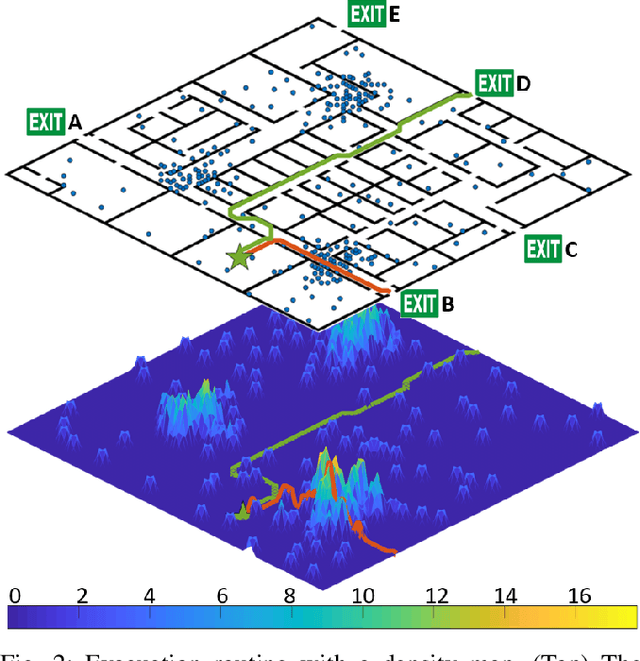
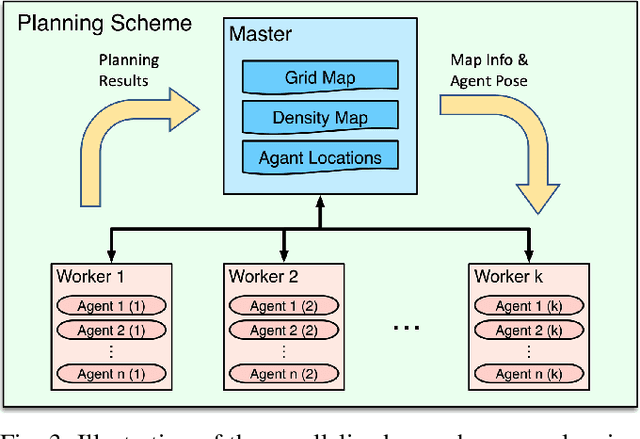
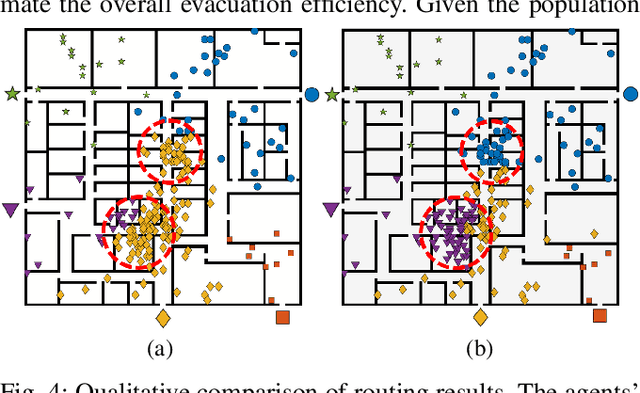
We present a congestion-aware routing solution for indoor evacuation, which produces real-time individual-customized evacuation routes among multiple destinations while keeping tracks of all evacuees' locations. A population density map, obtained on-the-fly by aggregating locations of evacuees from user-end Augmented Reality (AR) devices, is used to model the congestion distribution inside a building. To efficiently search the evacuation route among all destinations, a variant of A* algorithm is devised to obtain the optimal solution in a single pass. In a series of simulated studies, we show that the proposed algorithm is more computationally optimized compared to classic path planning algorithms; it generates a more time-efficient evacuation route for each individual that minimizes the overall congestion. A complete system using AR devices is implemented for a pilot study in real-world environments, demonstrating the efficacy of the proposed approach.