 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Machine Learning Approach for Optimizing the Timing Resolution of a High Purity Germanium Detector
Mar 31, 2020
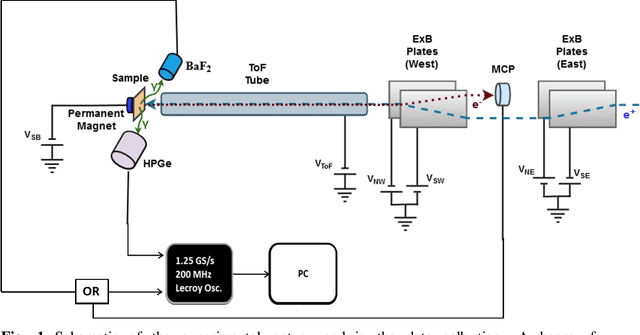
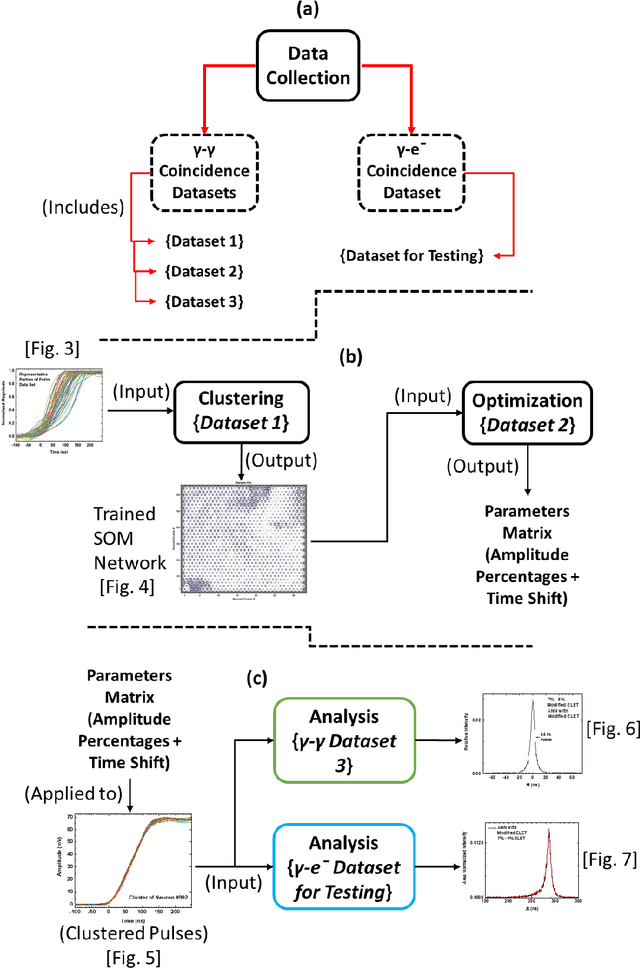
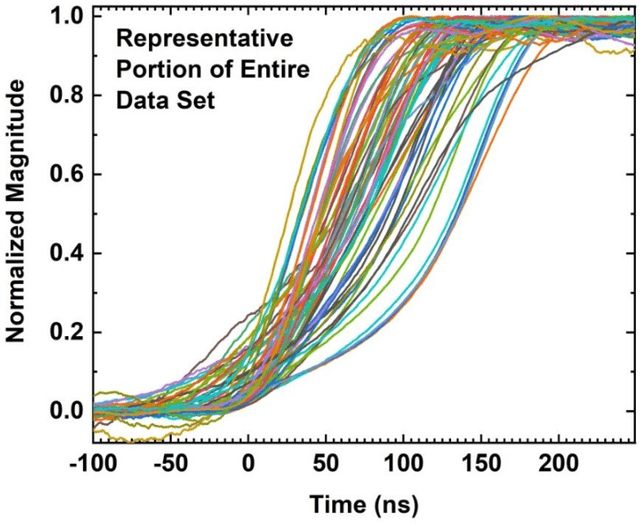
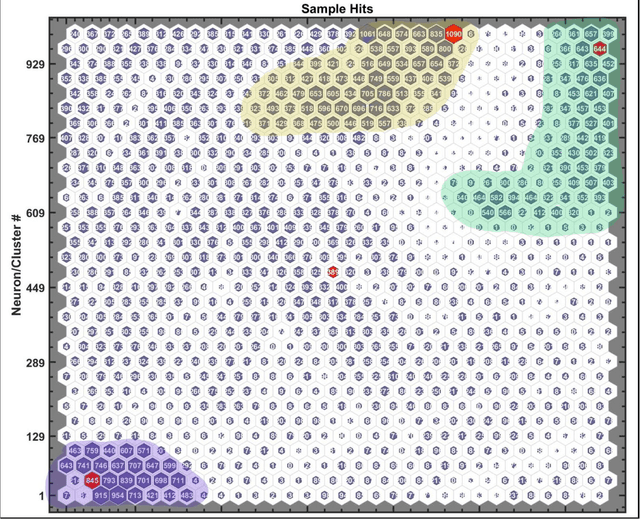
We describe here an efficient machine-learning based approach for the optimization of parameters used for extracting the arrival time of waveforms, in particular those generated by the detection of 511 keV annihilation gamma-rays by a 60 cm3 coaxial high purity germanium detector (HPGe). The method utilizes a type of artificial neural network (ANN) called a self-organizing map (SOM) to cluster the HPGe waveforms based on the shape of their rising edges. The optimal timing parameters for HPGe waveforms belonging to a particular cluster are found by minimizing the time difference between the HPGe signal and a signal produced by a BaF2 scintillation detector. Applying these variable timing parameters to the HPGe signals achieved a gamma-coincidence timing resolution of ~ 4.3 ns at the 511 keV photo peak (defined as 511 +- 50 keV) and a timing resolution of ~ 6.5 ns for the entire gamma spectrum--without rejecting any valid pulses. This timing resolution approaches the best obtained by analog nuclear electronics, without the corresponding complexities of analog optimization procedures. We further demonstrate the universality and efficacy of the machine learning approach by applying the method to the generation of secondary electron time-of-flight spectra following the implantation of energetic positrons on a sample.
AGVNet: Attention Guided Velocity Learning for 3D Human Motion Prediction
Jun 09, 2020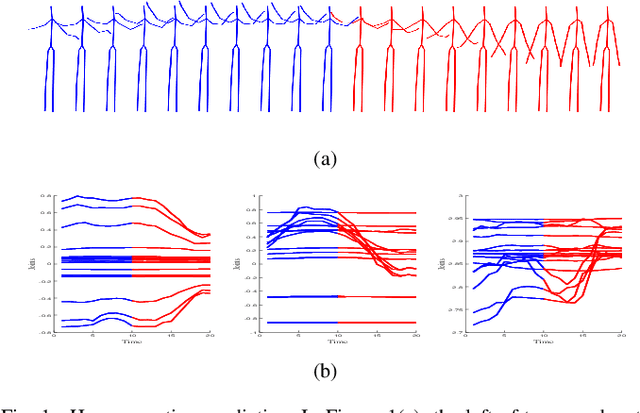
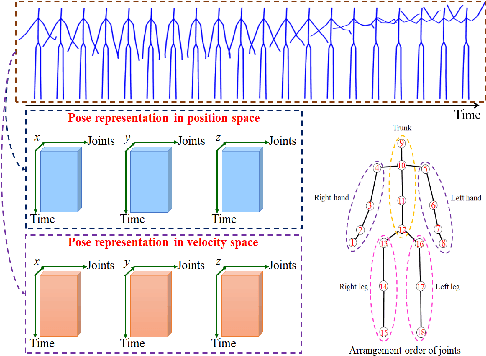
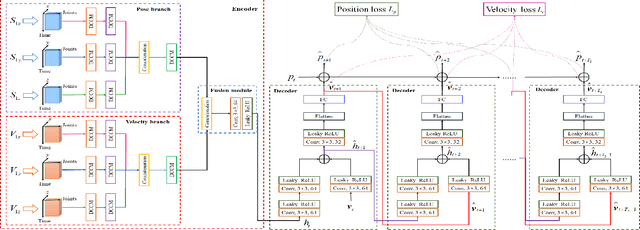
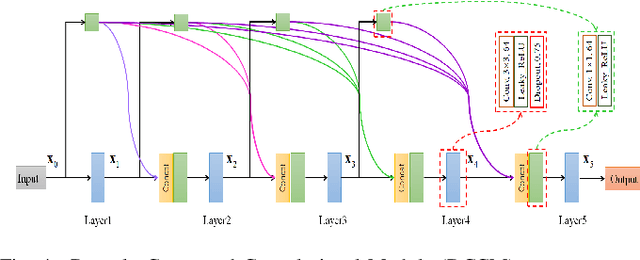
Prediction of human motion plays a significant role in human-machine interactions for a variety of real-life applications. In this paper, we propose a novel attention-guided velocity learning network, AGVNet, that utilizes multi-order information such as positions and velocities derived from the dynamic states of the human body for predicting human motion. Unlike existing methods, our network formulates the human motion system as a dynamic system and predicts human motion using the position and velocity of poses. Specifically, a multi-level Encoder is proposed to model the dynamics of moving joints at the axis level and joint level. A recursive feedforward Decoder generates future poses recursively by reusing the predictions at the previous time-steps and fusing multiple order information from both the velocity and position space. To avoid the error accumulation, a unique loss function, ATPL (Attention Temporal Prediction Loss), is designed with decreasing attention to the later predictions, making the network more accurate for predictions at the early time-steps. The experiments on two benchmark datasets (i.e., Human$3.6$M and $3$DPW) confirm that our method achieves state-of-the-art performance with improved effectiveness. The code will be made public once the paper is accepted.
Learning unbiased registration and joint segmentation: evaluation on longitudinal diffusion MRI
Nov 03, 2020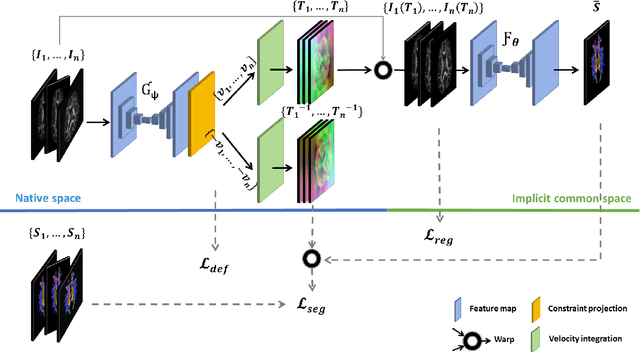
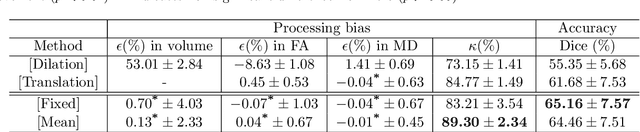
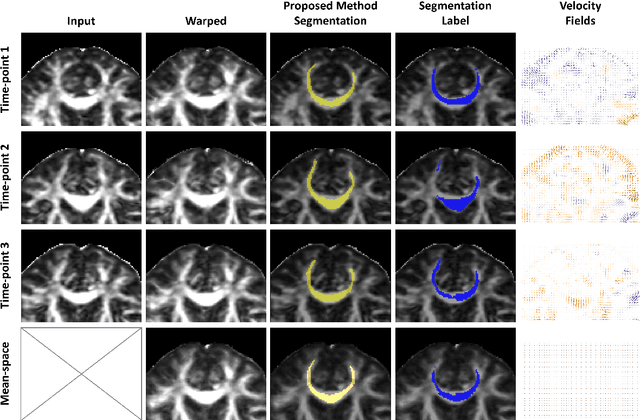
Analysis of longitudinal changes in imaging studies often involves both segmentation of structures of interest and registration of multiple timeframes. The accuracy of such analysis could benefit from a tailored framework that jointly optimizes both tasks to fully exploit the information available in the longitudinal data. Most learning-based registration algorithms, including joint optimization approaches, currently suffer from bias due to selection of a fixed reference frame and only support pairwise transformations. We here propose an analytical framework based on an unbiased learning strategy for group-wise registration that simultaneously registers images to the mean space of a group to obtain consistent segmentations. We evaluate the proposed method on longitudinal analysis of a white matter tract in a brain MRI dataset with 2-3 time-points for 3249 individuals, i.e., 8045 images in total. The reproducibility of the method is evaluated on test-retest data from 97 individuals. The results confirm that the implicit reference image is an average of the input image. In addition, the proposed framework leads to consistent segmentations and significantly lower processing bias than that of a pair-wise fixed-reference approach. This processing bias is even smaller than those obtained when translating segmentations by only one voxel, which can be attributed to subtle numerical instabilities and interpolation. Therefore, we postulate that the proposed mean-space learning strategy could be widely applied to learning-based registration tasks. In addition, this group-wise framework introduces a novel way for learning-based longitudinal studies by direct construction of an unbiased within-subject template and allowing reliable and efficient analysis of spatio-temporal imaging biomarkers.
Continuous close-range 3D object pose estimation
Oct 02, 2020
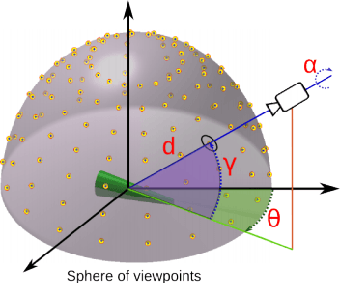
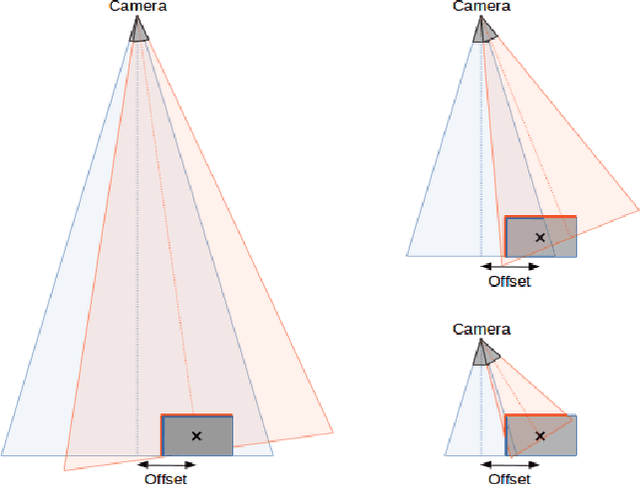

In the context of future manufacturing lines, removing fixtures will be a fundamental step to increase the flexibility of autonomous systems in assembly and logistic operations. Vision-based 3D pose estimation is a necessity to accurately handle objects that might not be placed at fixed positions during the robot task execution. Industrial tasks bring multiple challenges for the robust pose estimation of objects such as difficult object properties, tight cycle times and constraints on camera views. In particular, when interacting with objects, we have to work with close-range partial views of objects that pose a new challenge for typical view-based pose estimation methods. In this paper, we present a 3D pose estimation method based on a gradient-ascend particle filter that integrates new observations on-the-fly to improve the pose estimate. Thereby, we can apply this method online during task execution to save valuable cycle time. In contrast to other view-based pose estimation methods, we model potential views in full 6- dimensional space that allows us to cope with close-range partial objects views. We demonstrate the approach on a real assembly task, in which the algorithm usually converges to the correct pose within 10-15 iterations with an average accuracy of less than 8mm.
AFP-SRC: Identification of Antifreeze Proteins Using Sparse Representation Classifier
Oct 02, 2020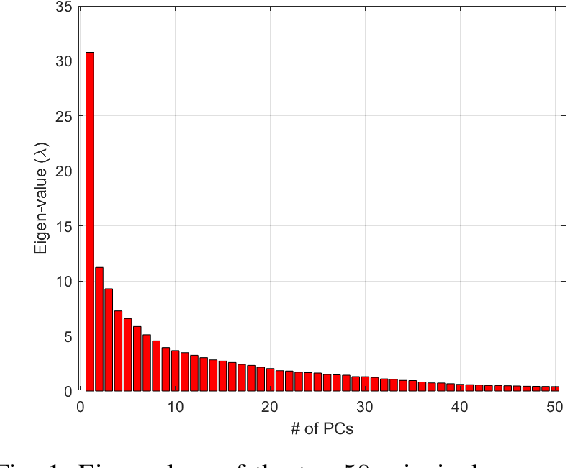
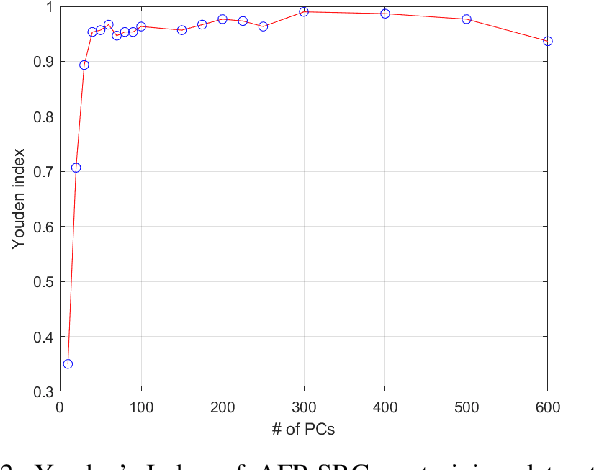
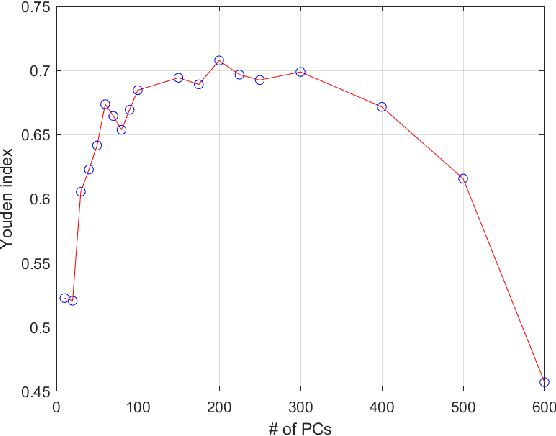
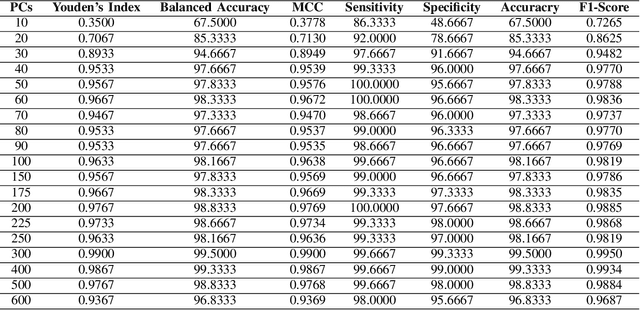
Species living in the extreme cold environment fight against the harsh conditions using antifreeze proteins (AFPs), that manipulates the freezing mechanism of water in more than one way. This amazing nature of AFP turns out to be extremely useful in several industrial and medical applications. The lack of similarity in their structure and sequence makes their prediction an arduous task and identifying them experimentally in the wet-lab is time-consuming and expensive. In this research, we propose a computational framework for the prediction of AFPs which is essentially based on a sample-specific classification method using the sparse reconstruction. A linear model and an over-complete dictionary matrix of known AFPs are used to predict a sparse class-label vector that provides a sample-association score. Delta-rule is applied for the reconstruction of two pseudo-samples using lower and upper parts of the sample-association vector and based on the minimum recovery score, class labels are assigned. We compare our approach with contemporary methods on a standard dataset and the proposed method is found to outperform in terms of Balanced accuracy and Youden's index. The MATLAB implementation of the proposed method is available at the author's GitHub page (\{https://github.com/Shujaat123/AFP-SRC}{https://github.com/Shujaat123/AFP-SRC}).
Detection of Gravitational Waves Using Bayesian Neural Networks
Jul 08, 2020
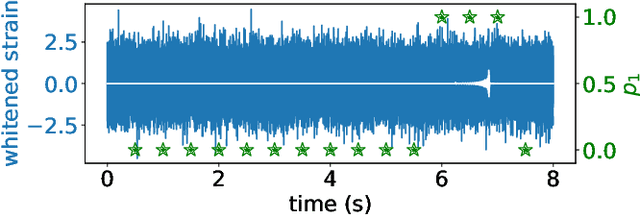
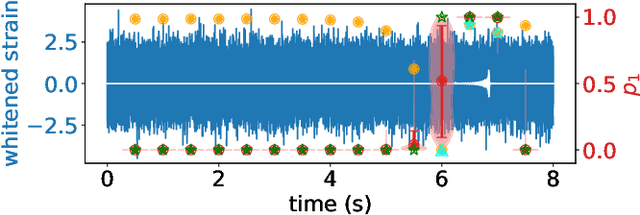
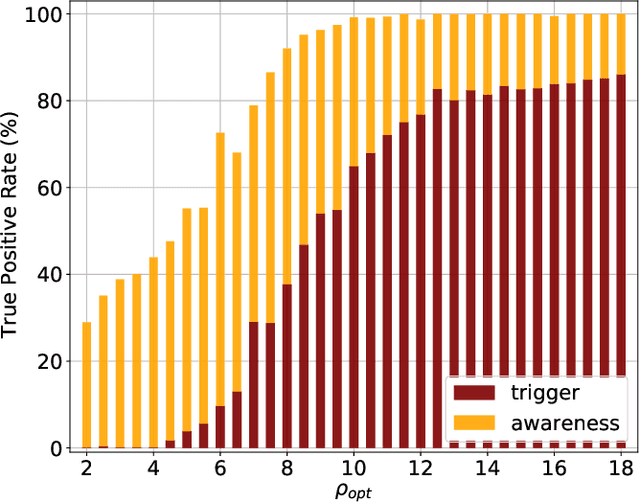
We propose a new model of Bayesian Neural Networks to not only detect the events of compact binary coalescence in the observational data of gravitational waves (GW) but also identify the time periods of the associated GW waveforms before the events. This is achieved by incorporating the Bayesian approach into the CLDNN classifier, which integrates together the Convolutional Neural Network (CNN) and the Long Short-Term Memory Recurrent Neural Network (LSTM). Our model successfully detect all seven BBH events in the LIGO Livingston O2 data, with the periods of their GW waveforms correctly labeled. The ability of a Bayesian approach for uncertainty estimation enables a newly defined `awareness' state for recognizing the possible presence of signals of unknown types, which is otherwise rejected in a non-Bayesian model. Such data chunks labeled with the awareness state can then be further investigated rather than overlooked. Performance tests show that our model recognizes 90% of the events when the optimal signal-to-noise ratio $\rho_\text{opt} >7$ (100% when $\rho_\text{opt} >8.5$) and successfully labels more than 95% of the waveform periods when $\rho_\text{opt} >8$. The latency between the arrival of peak signal and generating an alert with the associated waveform period labeled is only about 20 seconds for an unoptimized code on a moderate GPU-equipped personal computer. This makes our model possible for nearly real-time detection and for forecasting the coalescence events when assisted with deeper training on a larger dataset using the state-of-art HPCs.
Real-time Decolorization using Dominant Colors
Apr 22, 2014Decolorization is the process to convert a color image or video to its grayscale version, and it has received great attention in recent years. An ideal decolorization algorithm should preserve the original color contrast as much as possible. Meanwhile, it should provide the final decolorized result as fast as possible. However, most of the current methods are suffering from either unsatisfied color information preservation or high computational cost, limiting their application value. In this paper, a simple but effective technique is proposed for real-time decolorization. Based on the typical rgb2gray() color conversion model, which produces a grayscale image by linearly combining R, G, and B channels, we propose a dominant color hypothesis and a corresponding distance measurement metric to evaluate the quality of grayscale conversion. The local optimum scheme provides several "good" candidates in a confidence interval, from which the "best" result can be extracted. Experimental results demonstrate that remarkable simplicity of the proposed method facilitates the process of high resolution images and videos in real-time using a common CPU.
SWIPENET: Object detection in noisy underwater images
Oct 19, 2020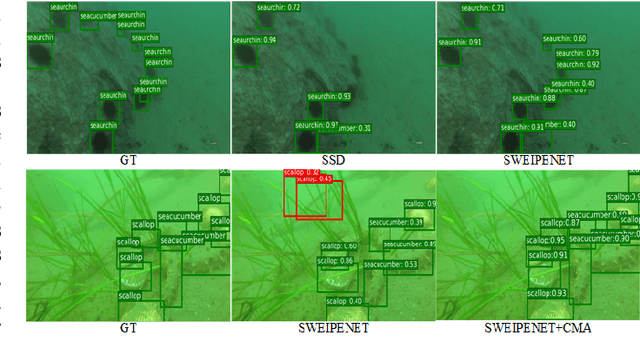


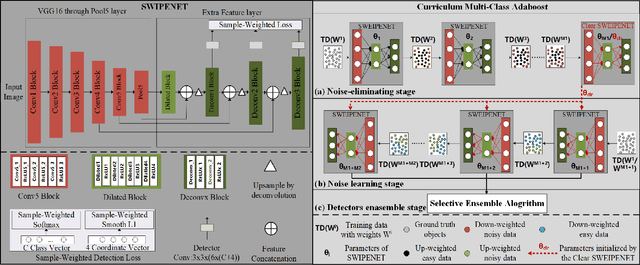
In recent years, deep learning based object detection methods have achieved promising performance in controlled environments. However, these methods lack sufficient capabilities to handle underwater object detection due to these challenges: (1) images in the underwater datasets and real applications are blurry whilst accompanying severe noise that confuses the detectors and (2) objects in real applications are usually small. In this paper, we propose a novel Sample-WeIghted hyPEr Network (SWIPENET), and a robust training paradigm named Curriculum Multi-Class Adaboost (CMA), to address these two problems at the same time. Firstly, the backbone of SWIPENET produces multiple high resolution and semantic-rich Hyper Feature Maps, which significantly improve small object detection. Secondly, a novel sample-weighted detection loss function is designed for SWIPENET, which focuses on learning high weight samples and ignore learning low weight samples. Moreover, inspired by the human education process that drives the learning from easy to hard concepts, we here propose the CMA training paradigm that first trains a clean detector which is free from the influence of noisy data. Then, based on the clean detector, multiple detectors focusing on learning diverse noisy data are trained and incorporated into a unified deep ensemble of strong noise immunity. Experiments on two underwater robot picking contest datasets (URPC2017 and URPC2018) show that the proposed SWIPENET+CMA framework achieves better accuracy in object detection against several state-of-the-art approaches.
Analyzing the Real-World Applicability of DGA Classifiers
Jun 19, 2020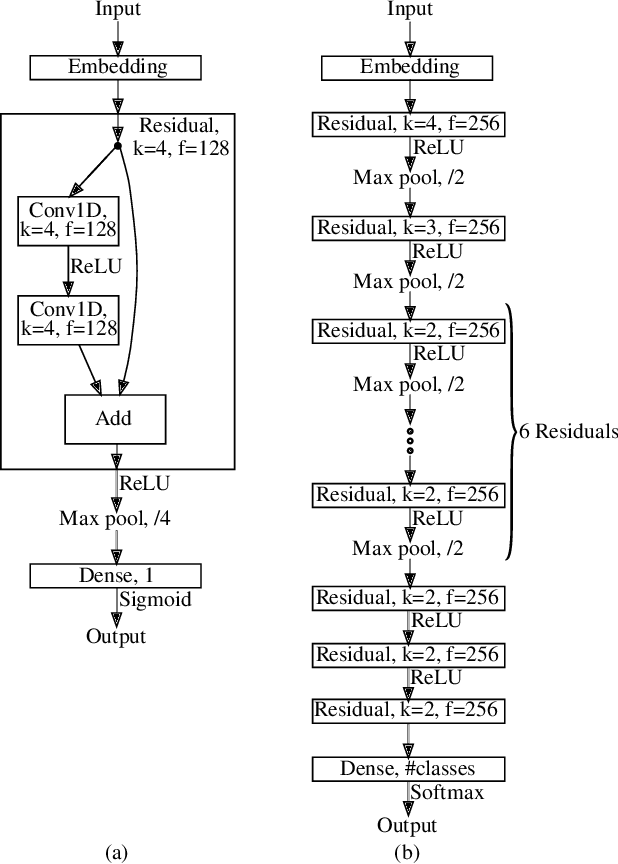

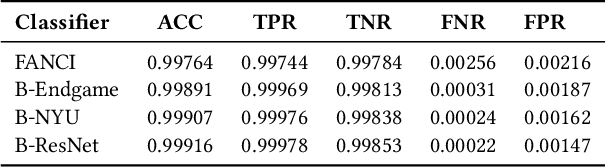
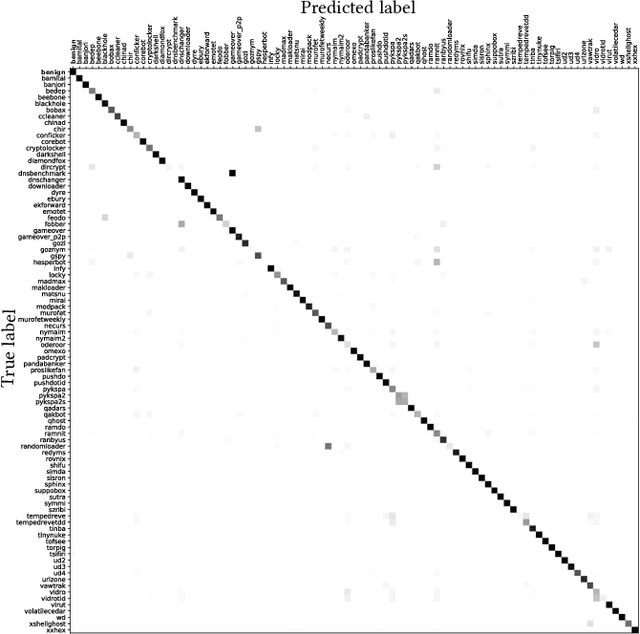
Separating benign domains from domains generated by DGAs with the help of a binary classifier is a well-studied problem for which promising performance results have been published. The corresponding multiclass task of determining the exact DGA that generated a domain enabling targeted remediation measures is less well studied. Selecting the most promising classifier for these tasks in practice raises a number of questions that have not been addressed in prior work so far. These include the questions on which traffic to train in which network and when, just as well as how to assess robustness against adversarial attacks. Moreover, it is unclear which features lead a classifier to a decision and whether the classifiers are real-time capable. In this paper, we address these issues and thus contribute to bringing DGA detection classifiers closer to practical use. In this context, we propose one novel classifier based on residual neural networks for each of the two tasks and extensively evaluate them as well as previously proposed classifiers in a unified setting. We not only evaluate their classification performance but also compare them with respect to explainability, robustness, and training and classification speed. Finally, we show that our newly proposed binary classifier generalizes well to other networks, is time-robust, and able to identify previously unknown DGAs.
* Accepted at The 15th International Conference on Availability, Reliability and Security (ARES 2020)
CA-GAN: Weakly Supervised Color Aware GAN for Controllable Makeup Transfer
Aug 24, 2020



While existing makeup style transfer models perform an image synthesis whose results cannot be explicitly controlled, the ability to modify makeup color continuously is a desirable property for virtual try-on applications. We propose a new formulation for the makeup style transfer task, with the objective to learn a color controllable makeup style synthesis. We introduce CA-GAN, a generative model that learns to modify the color of specific objects (e.g. lips or eyes) in the image to an arbitrary target color while preserving background. Since color labels are rare and costly to acquire, our method leverages weakly supervised learning for conditional GANs. This enables to learn a controllable synthesis of complex objects, and only requires a weak proxy of the image attribute that we desire to modify. Finally, we present for the first time a quantitative analysis of makeup style transfer and color control performance.