 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On Chernoff Lower-Bound of Outage Threshold for Non-Central $χ^2$-Distributed Beamforming Gain in URLLC Systems
Dec 28, 2023
The cumulative distribution function (CDF) of a non-central $\chi^2$-distributed random variable (RV) is often used when measuring the outage probability of communication systems. For ultra-reliable low-latency communication (URLLC), it is important but mathematically challenging to determine the outage threshold for an extremely small outage target. This motivates us to investigate lower bounds of the outage threshold, and it is found that the one derived from the Chernoff inequality (named Cher-LB) is the most effective lower bound. This finding is associated with three rigorously established properties of the Cher-LB with respect to the mean, variance, reliability requirement, and degrees of freedom of the non-central $\chi^2$-distributed RV. The Cher-LB is then employed to predict the beamforming gain in URLLC for both conventional multi-antenna systems (i.e., MIMO) under first-order Markov time-varying channel and reconfigurable intellgent surface (RIS) systems. It is exhibited that, with the proposed Cher-LB, the pessimistic prediction of the beamforming gain is made sufficiently accurate for guaranteed reliability as well as the transmit-energy efficiency.
Timeliness: A New Design Metric and a New Attack Surface
Dec 28, 2023As the landscape of time-sensitive applications gains prominence in 5G/6G communications, timeliness of information updates at network nodes has become crucial, which is popularly quantified in the literature by the age of information metric. However, as we devise policies to improve age of information of our systems, we inadvertently introduce a new vulnerability for adversaries to exploit. In this article, we comprehensively discuss the diverse threats that age-based systems are vulnerable to. We begin with discussion on densely interconnected networks that employ gossiping between nodes to expedite dissemination of dynamic information in the network, and show how the age-based nature of gossiping renders these networks uniquely susceptible to threats such as timestomping attacks, jamming attacks, and the propagation of misinformation. Later, we survey adversarial works within simpler network settings, specifically in one-hop and two-hop configurations, and delve into adversarial robustness concerning challenges posed by jamming, timestomping, and issues related to privacy leakage. We conclude this article with future directions that aim to address challenges posed by more intelligent adversaries and robustness of networks to them.
CARSS: Cooperative Attention-guided Reinforcement Subpath Synthesis for Solving Traveling Salesman Problem
Dec 24, 2023This paper introduces CARSS (Cooperative Attention-guided Reinforcement Subpath Synthesis), a novel approach to address the Traveling Salesman Problem (TSP) by leveraging cooperative Multi-Agent Reinforcement Learning (MARL). CARSS decomposes the TSP solving process into two distinct yet synergistic steps: "subpath generation" and "subpath merging." In the former, a cooperative MARL framework is employed to iteratively generate subpaths using multiple agents. In the latter, these subpaths are progressively merged to form a complete cycle. The algorithm's primary objective is to enhance efficiency in terms of training memory consumption, testing time, and scalability, through the adoption of a multi-agent divide and conquer paradigm. Notably, attention mechanisms play a pivotal role in feature embedding and parameterization strategies within CARSS. The training of the model is facilitated by the independent REINFORCE algorithm. Empirical experiments reveal CARSS's superiority compared to single-agent alternatives: it demonstrates reduced GPU memory utilization, accommodates training graphs nearly 2.5 times larger, and exhibits the potential for scaling to even more extensive problem sizes. Furthermore, CARSS substantially reduces testing time and optimization gaps by approximately 50% for TSP instances of up to 1000 vertices, when compared to standard decoding methods.
AI and Tempo Estimation: A Review
Dec 30, 2023The author's goal in this paper is to explore how artificial intelligence (AI) has been utilised to inform our understanding of and ability to estimate at scale a critical aspect of musical creativity - musical tempo. The central importance of tempo to musical creativity can be seen in how it is used to express specific emotions (Eerola and Vuoskoski 2013), suggest particular musical styles (Li and Chan 2011), influence perception of expression (Webster and Weir 2005) and mediate the urge to move one's body in time to the music (Burger et al. 2014). Traditional tempo estimation methods typically detect signal periodicities that reflect the underlying rhythmic structure of the music, often using some form of autocorrelation of the amplitude envelope (Lartillot and Toiviainen 2007). Recently, AI-based methods utilising convolutional or recurrent neural networks (CNNs, RNNs) on spectral representations of the audio signal have enjoyed significant improvements in accuracy (Aarabi and Peeters 2022). Common AI-based techniques include those based on probability (e.g., Bayesian approaches, hidden Markov models (HMM)), classification and statistical learning (e.g., support vector machines (SVM)), and artificial neural networks (ANNs) (e.g., self-organising maps (SOMs), CNNs, RNNs, deep learning (DL)). The aim here is to provide an overview of some of the more common AI-based tempo estimation algorithms and to shine a light on notable benefits and potential drawbacks of each. Limitations of AI in this field in general are also considered, as is the capacity for such methods to account for idiosyncrasies inherent in tempo perception, i.e., how well AI-based approaches are able to think and act like humans.
A quasi-polynomial time algorithm for Multi-Dimensional Scaling via LP hierarchies
Nov 29, 2023Multi-dimensional Scaling (MDS) is a family of methods for embedding pair-wise dissimilarities between $n$ objects into low-dimensional space. MDS is widely used as a data visualization tool in the social and biological sciences, statistics, and machine learning. We study the Kamada-Kawai formulation of MDS: given a set of non-negative dissimilarities $\{d_{i,j}\}_{i , j \in [n]}$ over $n$ points, the goal is to find an embedding $\{x_1,\dots,x_n\} \subset \mathbb{R}^k$ that minimizes \[ \text{OPT} = \min_{x} \mathbb{E}_{i,j \in [n]} \left[ \left(1-\frac{\|x_i - x_j\|}{d_{i,j}}\right)^2 \right] \] Despite its popularity, our theoretical understanding of MDS is extremely limited. Recently, Demaine, Hesterberg, Koehler, Lynch, and Urschel (arXiv:2109.11505) gave the first approximation algorithm with provable guarantees for Kamada-Kawai, which achieves an embedding with cost $\text{OPT} +\epsilon$ in $n^2 \cdot 2^{\tilde{\mathcal{O}}(k \Delta^4 / \epsilon^2)}$ time, where $\Delta$ is the aspect ratio of the input dissimilarities. In this work, we give the first approximation algorithm for MDS with quasi-polynomial dependency on $\Delta$: for target dimension $k$, we achieve a solution with cost $\mathcal{O}(\text{OPT}^{ \hspace{0.04in}1/k } \cdot \log(\Delta/\epsilon) )+ \epsilon$ in time $n^{ \mathcal{O}(1)} \cdot 2^{\tilde{\mathcal{O}}( k^2 (\log(\Delta)/\epsilon)^{k/2 + 1} ) }$. Our approach is based on a novel analysis of a conditioning-based rounding scheme for the Sherali-Adams LP Hierarchy. Crucially, our analysis exploits the geometry of low-dimensional Euclidean space, allowing us to avoid an exponential dependence on the aspect ratio $\Delta$. We believe our geometry-aware treatment of the Sherali-Adams Hierarchy is an important step towards developing general-purpose techniques for efficient metric optimization algorithms.
Link Streams as a Generalization of Graphs and Time Series
Nov 19, 2023A link stream is a set of possibly weighted triplets (t, u, v) modeling that u and v interacted at time t. Link streams offer an effective model for datasets containing both temporal and relational information, making their proper analysis crucial in many applications. They are commonly regarded as sequences of graphs or collections of time series. Yet, a recent seminal work demonstrated that link streams are more general objects of which graphs are only particular cases. It therefore started the construction of a dedicated formalism for link streams by extending graph theory. In this work, we contribute to the development of this formalism by showing that link streams also generalize time series. In particular, we show that a link stream corresponds to a time-series extended to a relational dimension, which opens the door to also extend the framework of signal processing to link streams. We therefore develop extensions of numerous signal concepts to link streams: from elementary ones like energy, correlation, and differentiation, to more advanced ones like Fourier transform and filters.
Improving performance of heart rate time series classification by grouping subjects
Nov 22, 2023Unlike the more commonly analyzed ECG or PPG data for activity classification, heart rate time series data is less detailed, often noisier and can contain missing data points. Using the BigIdeasLab_STEP dataset, which includes heart rate time series annotated with specific tasks performed by individuals, we sought to determine if general classification was achievable. Our analyses showed that the accuracy is sensitive to the choice of window/stride size. Moreover, we found variable classification performances between subjects due to differences in the physical structure of their hearts. Various techniques were used to minimize this variability. First of all, normalization proved to be a crucial step and significantly improved the performance. Secondly, grouping subjects and performing classification inside a group helped to improve performance and decrease inter-subject variability. Finally, we show that including handcrafted features as input to a deep learning (DL) network improves the classification performance further. Together, these findings indicate that heart rate time series can be utilized for classification tasks like predicting activity. However, normalization or grouping techniques need to be chosen carefully to minimize the issue of subject variability.
Curriculum Learning and Imitation Learning for Model-free Control on Financial Time-series
Nov 22, 2023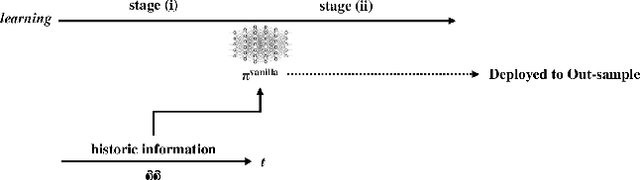

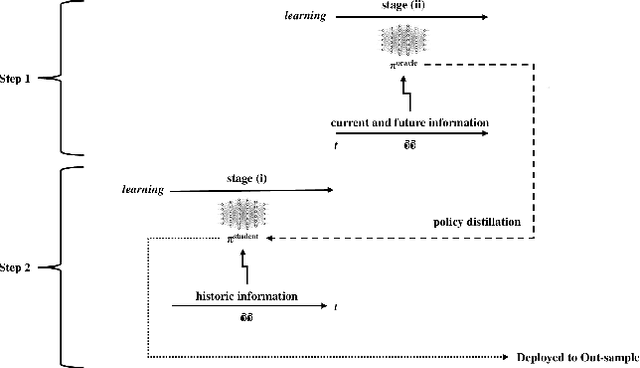
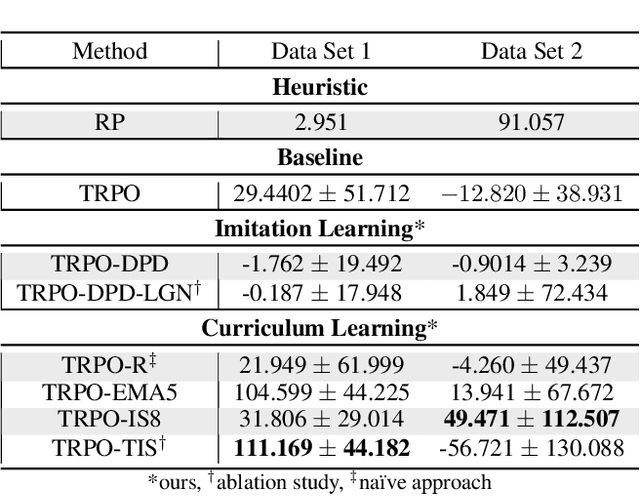
Curriculum learning and imitation learning have been leveraged extensively in the robotics domain. However, minimal research has been done on leveraging these ideas on control tasks over highly stochastic time-series data. Here, we theoretically and empirically explore these approaches in a representative control task over complex time-series data. We implement the fundamental ideas of curriculum learning via data augmentation, while imitation learning is implemented via policy distillation from an oracle. Our findings reveal that curriculum learning should be considered a novel direction in improving control-task performance over complex time-series. Our ample random-seed out-sample empirics and ablation studies are highly encouraging for curriculum learning for time-series control. These findings are especially encouraging as we tune all overlapping hyperparameters on the baseline -- giving an advantage to the baseline. On the other hand, we find that imitation learning should be used with caution.
Energy-Calibrated VAE with Test Time Free Lunch
Nov 21, 2023In this paper, we propose a novel generative model that utilizes a conditional Energy-Based Model (EBM) for enhancing Variational Autoencoder (VAE), termed Energy-Calibrated VAE (EC-VAE). Specifically, VAEs often suffer from blurry generated samples due to the lack of a tailored training on the samples generated in the generative direction. On the other hand, EBMs can generate high-quality samples but require expensive Markov Chain Monte Carlo (MCMC) sampling. To address these issues, we introduce a conditional EBM for calibrating the generative direction of VAE during training, without requiring it for the generation at test time. In particular, we train EC-VAE upon both the input data and the calibrated samples with adaptive weight to enhance efficacy while avoiding MCMC sampling at test time. Furthermore, we extend the calibration idea of EC-VAE to variational learning and normalizing flows, and apply EC-VAE to an additional application of zero-shot image restoration via neural transport prior and range-null theory. We evaluate the proposed method with two applications, including image generation and zero-shot image restoration, and the experimental results show that our method achieves the state-of-the-art performance over single-step non-adversarial generation.
A Quick Response Algorithm for Dynamic Autonomous Mobile Robot Routing Problem with Time Windows
Nov 26, 2023This paper investigates the optimization problem of scheduling autonomous mobile robots (AMRs) in hospital settings, considering dynamic requests with different priorities. The primary objective is to minimize the daily service cost by dynamically planning routes for the limited number of available AMRs. The total cost consists of AMR's purchase cost, transportation cost, delay penalty cost, and loss of denial of service. To address this problem, we have established a two-stage mathematical programming model. In the first stage, a tabu search algorithm is employed to plan prior routes for all known medical requests. The second stage involves planning for real-time received dynamic requests using the efficient insertion algorithm with decision rules, which enables quick response based on the time window and demand constraints of the dynamic requests. One of the main contributions of this study is to make resource allocation decisions based on the present number of service AMRs for dynamic requests with different priorities. Computational experiments using Lackner instances demonstrate the efficient insertion algorithm with decision rules is very fast and robust in solving the dynamic AMR routing problem with time windows and request priority. Additionally, we provide managerial insights concerning the AMR's safety stock settings, which can aid in decision-making processes.