 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Scaling Motion Forecasting Models with Ensemble Distillation
Apr 05, 2024
Motion forecasting has become an increasingly critical component of autonomous robotic systems. Onboard compute budgets typically limit the accuracy of real-time systems. In this work we propose methods of improving motion forecasting systems subject to limited compute budgets by combining model ensemble and distillation techniques. The use of ensembles of deep neural networks has been shown to improve generalization accuracy in many application domains. We first demonstrate significant performance gains by creating a large ensemble of optimized single models. We then develop a generalized framework to distill motion forecasting model ensembles into small student models which retain high performance with a fraction of the computing cost. For this study we focus on the task of motion forecasting using real world data from autonomous driving systems. We develop ensemble models that are very competitive on the Waymo Open Motion Dataset (WOMD) and Argoverse leaderboards. From these ensembles, we train distilled student models which have high performance at a fraction of the compute costs. These experiments demonstrate distillation from ensembles as an effective method for improving accuracy of predictive models for robotic systems with limited compute budgets.
Solving a Real-World Optimization Problem Using Proximal Policy Optimization with Curriculum Learning and Reward Engineering
Apr 03, 2024We present a proximal policy optimization (PPO) agent trained through curriculum learning (CL) principles and meticulous reward engineering to optimize a real-world high-throughput waste sorting facility. Our work addresses the challenge of effectively balancing the competing objectives of operational safety, volume optimization, and minimizing resource usage. A vanilla agent trained from scratch on these multiple criteria fails to solve the problem due to its inherent complexities. This problem is particularly difficult due to the environment's extremely delayed rewards with long time horizons and class (or action) imbalance, with important actions being infrequent in the optimal policy. This forces the agent to anticipate long-term action consequences and prioritize rare but rewarding behaviours, creating a non-trivial reinforcement learning task. Our five-stage CL approach tackles these challenges by gradually increasing the complexity of the environmental dynamics during policy transfer while simultaneously refining the reward mechanism. This iterative and adaptable process enables the agent to learn a desired optimal policy. Results demonstrate that our approach significantly improves inference-time safety, achieving near-zero safety violations in addition to enhancing waste sorting plant efficiency.
Addressing Concept Shift in Online Time Series Forecasting: Detect-then-Adapt
Mar 22, 2024Online updating of time series forecasting models aims to tackle the challenge of concept drifting by adjusting forecasting models based on streaming data. While numerous algorithms have been developed, most of them focus on model design and updating. In practice, many of these methods struggle with continuous performance regression in the face of accumulated concept drifts over time. To address this limitation, we present a novel approach, Concept \textbf{D}rift \textbf{D}etection an\textbf{D} \textbf{A}daptation (D3A), that first detects drifting conception and then aggressively adapts the current model to the drifted concepts after the detection for rapid adaption. To best harness the utility of historical data for model adaptation, we propose a data augmentation strategy introducing Gaussian noise into existing training instances. It helps mitigate the data distribution gap, a critical factor contributing to train-test performance inconsistency. The significance of our data augmentation process is verified by our theoretical analysis. Our empirical studies across six datasets demonstrate the effectiveness of D3A in improving model adaptation capability. Notably, compared to a simple Temporal Convolutional Network (TCN) baseline, D3A reduces the average Mean Squared Error (MSE) by $43.9\%$. For the state-of-the-art (SOTA) model, the MSE is reduced by $33.3\%$.
Reliable Feature Selection for Adversarially Robust Cyber-Attack Detection
Apr 05, 2024The growing cybersecurity threats make it essential to use high-quality data to train Machine Learning (ML) models for network traffic analysis, without noisy or missing data. By selecting the most relevant features for cyber-attack detection, it is possible to improve both the robustness and computational efficiency of the models used in a cybersecurity system. This work presents a feature selection and consensus process that combines multiple methods and applies them to several network datasets. Two different feature sets were selected and were used to train multiple ML models with regular and adversarial training. Finally, an adversarial evasion robustness benchmark was performed to analyze the reliability of the different feature sets and their impact on the susceptibility of the models to adversarial examples. By using an improved dataset with more data diversity, selecting the best time-related features and a more specific feature set, and performing adversarial training, the ML models were able to achieve a better adversarially robust generalization. The robustness of the models was significantly improved without their generalization to regular traffic flows being affected, without increases of false alarms, and without requiring too many computational resources, which enables a reliable detection of suspicious activity and perturbed traffic flows in enterprise computer networks.
Efficient 3D Implicit Head Avatar with Mesh-anchored Hash Table Blendshapes
Apr 02, 20243D head avatars built with neural implicit volumetric representations have achieved unprecedented levels of photorealism. However, the computational cost of these methods remains a significant barrier to their widespread adoption, particularly in real-time applications such as virtual reality and teleconferencing. While attempts have been made to develop fast neural rendering approaches for static scenes, these methods cannot be simply employed to support realistic facial expressions, such as in the case of a dynamic facial performance. To address these challenges, we propose a novel fast 3D neural implicit head avatar model that achieves real-time rendering while maintaining fine-grained controllability and high rendering quality. Our key idea lies in the introduction of local hash table blendshapes, which are learned and attached to the vertices of an underlying face parametric model. These per-vertex hash-tables are linearly merged with weights predicted via a CNN, resulting in expression dependent embeddings. Our novel representation enables efficient density and color predictions using a lightweight MLP, which is further accelerated by a hierarchical nearest neighbor search method. Extensive experiments show that our approach runs in real-time while achieving comparable rendering quality to state-of-the-arts and decent results on challenging expressions.
Sub-Nyquist Sampling OFDM Radar With a Time-Frequency Phase-Coded Waveform
Mar 21, 2024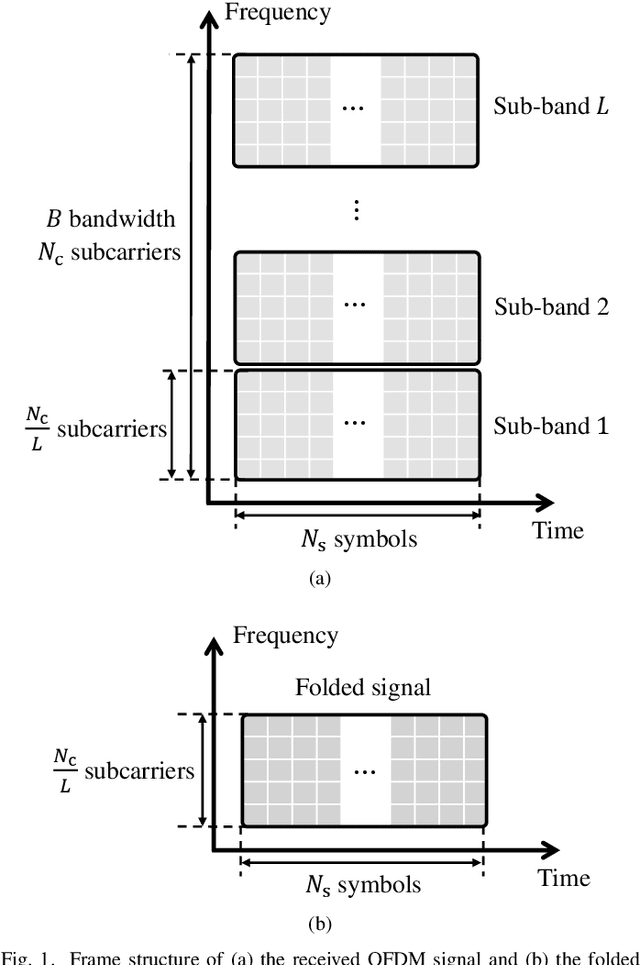
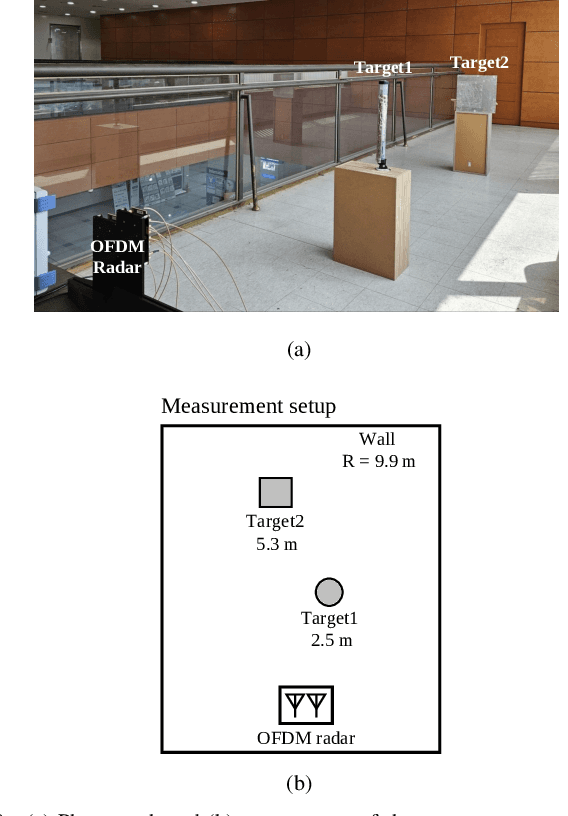
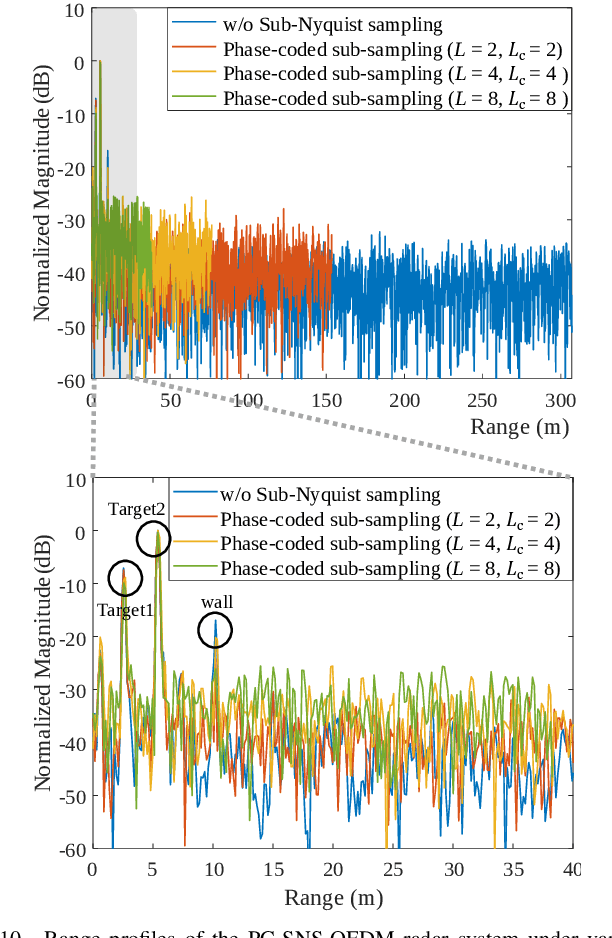
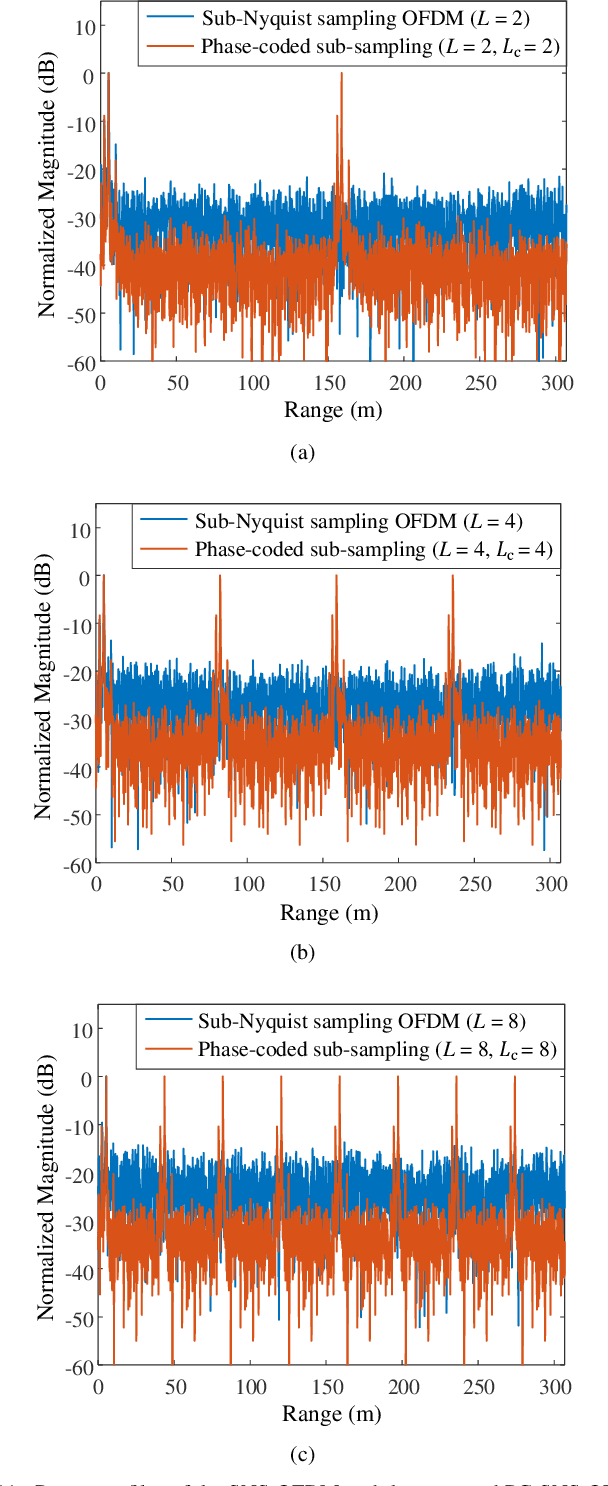
This paper presents a time-frequency phase-coded sub-Nyquist sampling orthogonal frequency division multiplexing (PC-SNS-OFDM) radar system to reduce the analog-to-digital converter (ADC) sampling rate without any additional hardware or signal processing. The proposed radar divides the transmitted OFDM signal into multiple sub-bands along the frequency axis and provides orthogonality to these sub-bands by multiplying phase codes in both the time and frequency domains. Although the sampling rate is reduced by the factor of the number of sub-bands, the sub-bands above the sampling rate are folded into the lowest one due to aliasing. In the process of restoring the signals in folded sub-bands to those in full signal bands, the proposed PC-SNS-OFDM radar effectively eliminates symbol-mismatch noise while introducing trade-offs in the range and Doppler ambiguities. The utilization of phase codes in both the frequency and time domains provides flexible control of the range and Doppler ambiguities. It also improves the signal-to-noise ratio (SNR) of detected targets compared to an earlier sub-Nyquist sampling OFDM radar system. This is validated with simulations and experiments under various sub-Nyquist sampling rates.
PointInfinity: Resolution-Invariant Point Diffusion Models
Apr 04, 2024We present PointInfinity, an efficient family of point cloud diffusion models. Our core idea is to use a transformer-based architecture with a fixed-size, resolution-invariant latent representation. This enables efficient training with low-resolution point clouds, while allowing high-resolution point clouds to be generated during inference. More importantly, we show that scaling the test-time resolution beyond the training resolution improves the fidelity of generated point clouds and surfaces. We analyze this phenomenon and draw a link to classifier-free guidance commonly used in diffusion models, demonstrating that both allow trading off fidelity and variability during inference. Experiments on CO3D show that PointInfinity can efficiently generate high-resolution point clouds (up to 131k points, 31 times more than Point-E) with state-of-the-art quality.
Automated Contrastive Learning Strategy Search for Time Series
Mar 19, 2024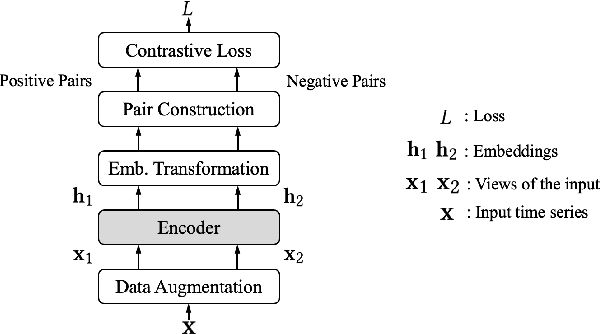
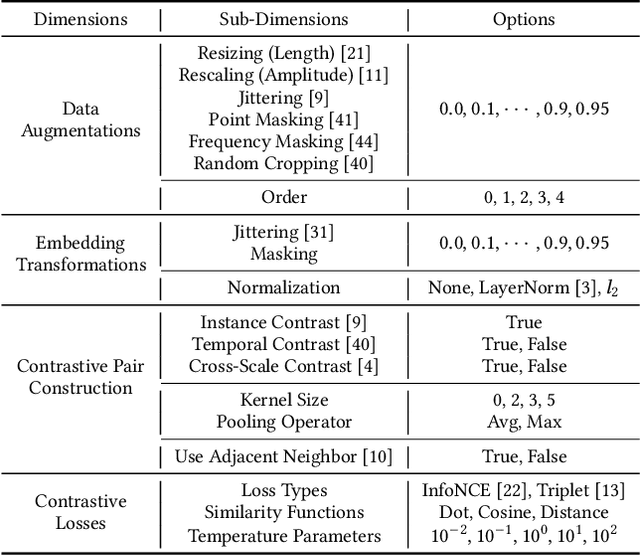
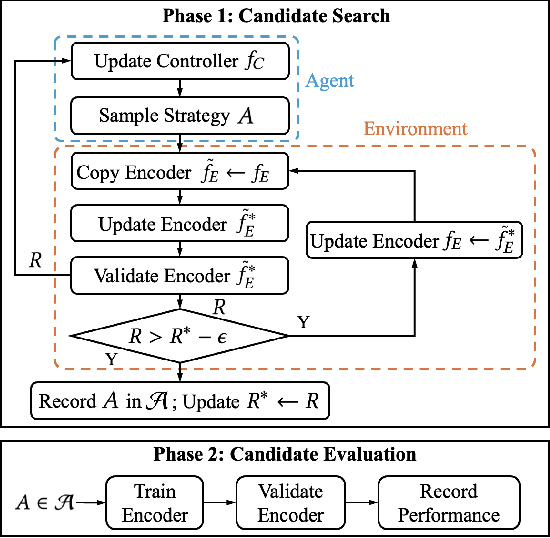
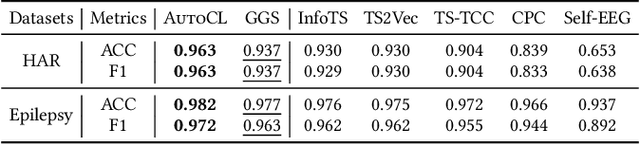
In recent years, Contrastive Learning (CL) has become a predominant representation learning paradigm for time series. Most existing methods in the literature focus on manually building specific Contrastive Learning Strategies (CLS) by human heuristics for certain datasets and tasks. However, manually developing CLS usually require excessive prior knowledge about the datasets and tasks, e.g., professional cognition of the medical time series in healthcare, as well as huge human labor and massive experiments to determine the detailed learning configurations. In this paper, we present an Automated Machine Learning (AutoML) practice at Microsoft, which automatically learns to contrastively learn representations for various time series datasets and tasks, namely Automated Contrastive Learning (AutoCL). We first construct a principled universal search space of size over 3x1012, covering data augmentation, embedding transformation, contrastive pair construction and contrastive losses. Further, we introduce an efficient reinforcement learning algorithm, which optimizes CLS from the performance on the validation tasks, to obtain more effective CLS within the space. Experimental results on various real-world tasks and datasets demonstrate that AutoCL could automatically find the suitable CLS for a given dataset and task. From the candidate CLS found by AutoCL on several public datasets/tasks, we compose a transferable Generally Good Strategy (GGS), which has a strong performance for other datasets. We also provide empirical analysis as a guidance for future design of CLS.
A High Order Solver for Signature Kernels
Apr 01, 2024Signature kernels are at the core of several machine learning algorithms for analysing multivariate time series. The kernel of two bounded variation paths (such as piecewise linear interpolations of time series data) is typically computed by solving a Goursat problem for a hyperbolic partial differential equation (PDE) in two independent time variables. However, this approach becomes considerably less practical for highly oscillatory input paths, as they have to be resolved at a fine enough scale to accurately recover their signature kernel, resulting in significant time and memory complexities. To mitigate this issue, we first show that the signature kernel of a broader class of paths, known as \emph{smooth rough paths}, also satisfies a PDE, albeit in the form of a system of coupled equations. We then use this result to introduce new algorithms for the numerical approximation of signature kernels. As bounded variation paths (and more generally geometric $p$-rough paths) can be approximated by piecewise smooth rough paths, one can replace the PDE with rapidly varying coefficients in the original Goursat problem by an explicit system of coupled equations with piecewise constant coefficients derived from the first few iterated integrals of the original input paths. While this approach requires solving more equations, they do not require looking back at the complex and fine structure of the initial paths, which significantly reduces the computational complexity associated with the analysis of highly oscillatory time series.
TEeVTOL: Balancing Energy and Time Efficiency in eVTOL Aircraft Path Planning Across City-Scale Wind Fields
Mar 21, 2024Electric vertical-takeoff and landing (eVTOL) aircraft, recognized for their maneuverability and flexibility, offer a promising alternative to our transportation system. However, the operational effectiveness of these aircraft faces many challenges, such as the delicate balance between energy and time efficiency, stemming from unpredictable environmental factors, including wind fields. Mathematical modeling-based approaches have been adopted to plan aircraft flight path in urban wind fields with the goal to save energy and time costs. While effective, they are limited in adapting to dynamic and complex environments. To optimize energy and time efficiency in eVTOL's flight through dynamic wind fields, we introduce a novel path planning method leveraging deep reinforcement learning. We assess our method with extensive experiments, comparing it to Dijkstra's algorithm -- the theoretically optimal approach for determining shortest paths in a weighted graph, where weights represent either energy or time cost. The results show that our method achieves a graceful balance between energy and time efficiency, closely resembling the theoretically optimal values for both objectives.