 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Image Reconstruction of Static and Dynamic Scenes through Anisoplanatic Turbulence
Aug 31, 2020
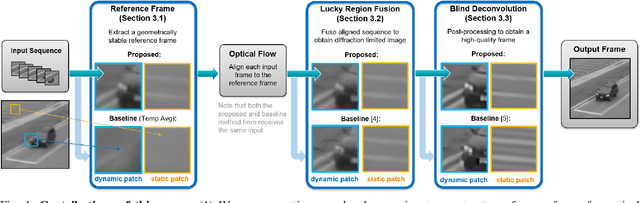
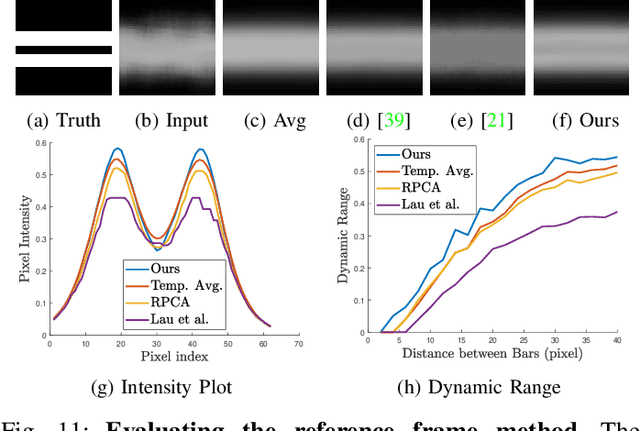

Ground based long-range passive imaging systems often suffer from degraded image quality due to a turbulent atmosphere. While methods exist for removing such turbulent distortions, many are limited to static sequences which cannot be extended to dynamic scenes. In addition, the physics of the turbulence is often not integrated into the image reconstruction algorithms, making the physics foundations of the methods weak. In this paper, we present a unified method for atmospheric turbulence mitigation in both static and dynamic sequences. We are able to achieve better results compared to existing methods by utilizing (i) a novel space-time non-local averaging method to construct a reliable reference frame, (ii) a geometric consistency and a sharpness metric to generate the lucky frame, (iii) a physics-constrained prior model of the point spread function for blind deconvolution. Experimental results based on synthetic and real long-range turbulence sequences validate the performance of the proposed method.
A Survey on Evolutionary Neural Architecture Search
Aug 25, 2020


Deep Neural Networks (DNNs) have achieved great success in many applications, such as image classification, natural language processing and speech recognition. The architectures of DNNs have been proved to play a crucial role in its performance. However, designing architectures for different tasks is a difficult and time-consuming process of trial and error. Neural Architecture Search (NAS), which received great attention in recent years, can design the architecture automatically. Among different kinds of NAS methods, Evolutionary Computation (EC) based NAS methods have recently gained much attention and success. Unfortunately, there is not a comprehensive summary of the EC-based methods. This paper reviews 100+ papers of EC-based NAS methods in light of the common process. Four steps of the process have been covered in this paper including population initialization, population operators, evaluation and selection. Furthermore, current challenges and issues are also discussed to identify future research in this field.
Exploring the potential of transfer learning for metamodels of heterogeneous material deformation
Oct 28, 2020
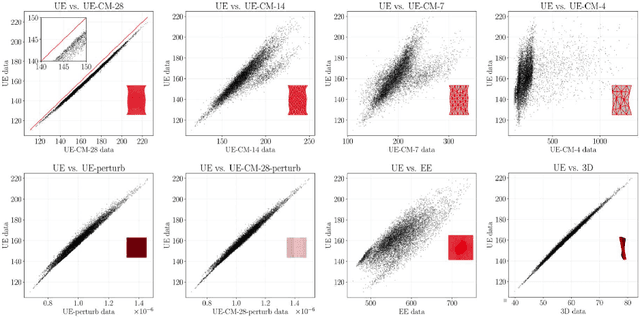
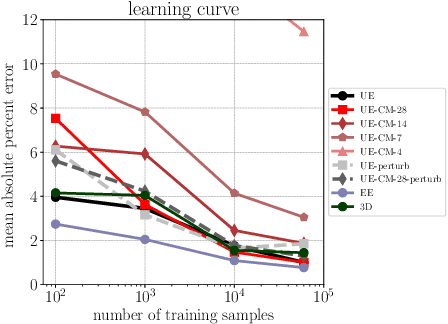
From the nano-scale to the macro-scale, biological tissue is spatially heterogeneous. Even when tissue behavior is well understood, the exact subject specific spatial distribution of material properties is often unknown. And, when developing computational models of biological tissue, it is usually prohibitively computationally expensive to simulate every plausible spatial distribution of material properties for each problem of interest. Therefore, one of the major challenges in developing accurate computational models of biological tissue is capturing the potential effects of this spatial heterogeneity. Recently, machine learning based metamodels have gained popularity as a computationally tractable way to overcome this problem because they can make predictions based on a limited number of direct simulation runs. These metamodels are promising, but they often still require a high number of direct simulations to achieve an acceptable performance. Here we show that transfer learning, a strategy where knowledge gained while solving one problem is transferred to solving a different but related problem, can help overcome this limitation. Critically, transfer learning can be used to leverage both low-fidelity simulation data and simulation data that is the outcome of solving a different but related mechanical problem. In this paper, we extend Mechanical MNIST, our open source benchmark dataset of heterogeneous material undergoing large deformation, to include a selection of low-fidelity simulation results that require 2-4 orders of magnitude less CPU time to run. Then, we show that transferring the knowledge stored in metamodels trained on these low-fidelity simulation results can vastly improve the performance of metamodels used to predict the results of high-fidelity simulations.
STaRFlow: A SpatioTemporal Recurrent Cell for Lightweight Multi-Frame Optical Flow Estimation
Jul 10, 2020
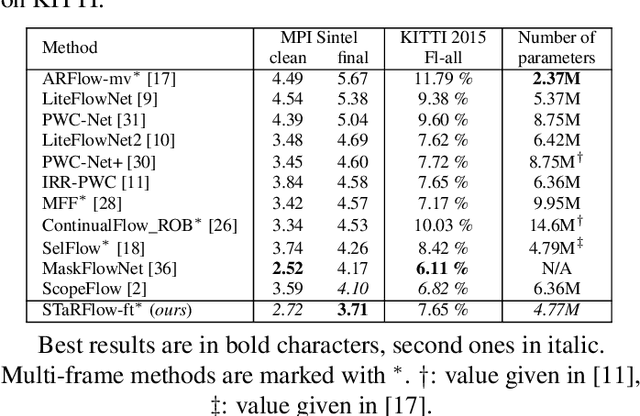
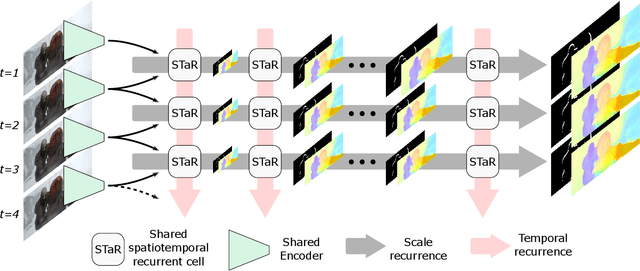
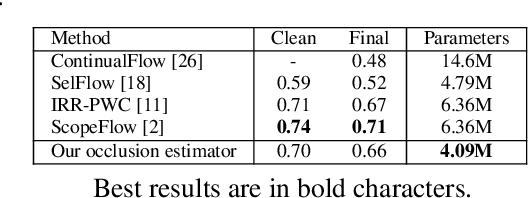
We present a new lightweight CNN-based algorithm for multi-frame optical flow estimation. Our solution introduces a double recurrence over spatial scale and time through repeated use of a generic "STaR" (SpatioTemporal Recurrent) cell. It includes (i) a temporal recurrence based on conveying learned features rather than optical flow estimates; (ii) an occlusion detection process which is coupled with optical flow estimation and therefore uses a very limited number of extra parameters. The resulting STaRFlow algorithm gives state-of-the-art performances on MPI Sintel and Kitti2015 and involves significantly less parameters than all other methods with comparable results.
Transfer Learning for Protein Structure Classification at Low Resolution
Aug 31, 2020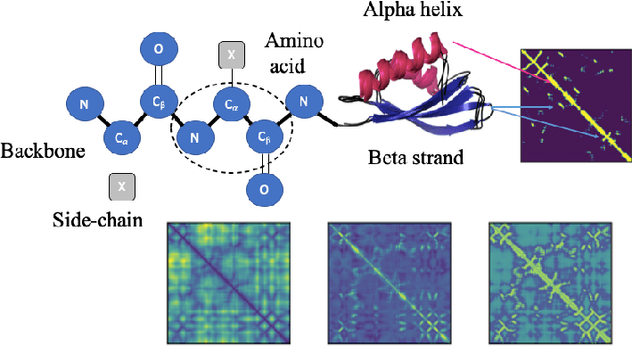
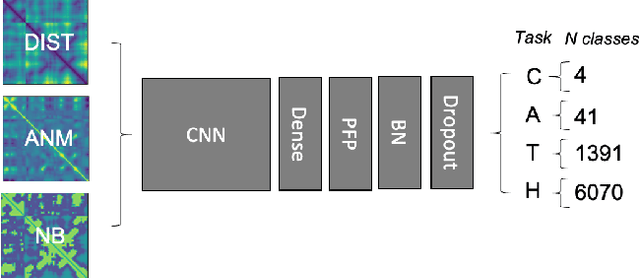
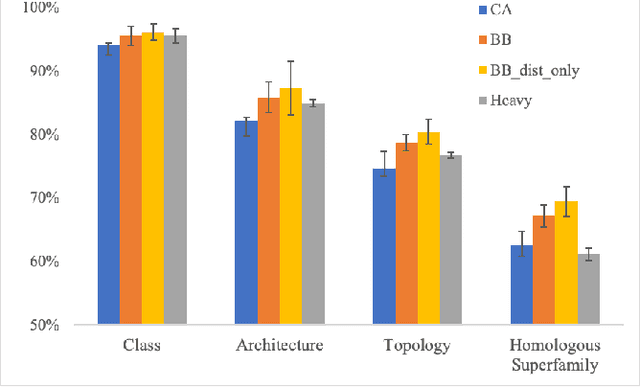

Structure determination is key to understanding protein function at a molecular level. Whilst significant advances have been made in predicting structure and function from amino acid sequence, researchers must still rely on expensive, time-consuming analytical methods to visualise detailed protein conformation. In this study, we demonstrate that it is possible to make accurate ($\geq$80%) predictions of protein class and architecture from structures determined at low ($>$3A) resolution, using a deep convolutional neural network trained on high-resolution ($\leq$3A) structures represented as 2D matrices. Thus, we provide proof of concept for high-speed, low-cost protein structure classification at low resolution, and a basis for extension to prediction of function. We investigate the impact of the input representation on classification performance, showing that side-chain information may not be necessary for fine-grained structure predictions. Finally, we confirm that high-resolution, low-resolution and NMR-determined structures inhabit a common feature space, and thus provide a theoretical foundation for boosting with single-image super-resolution.
Two-Stream Networks for Lane-Change Prediction of Surrounding Vehicles
Aug 25, 2020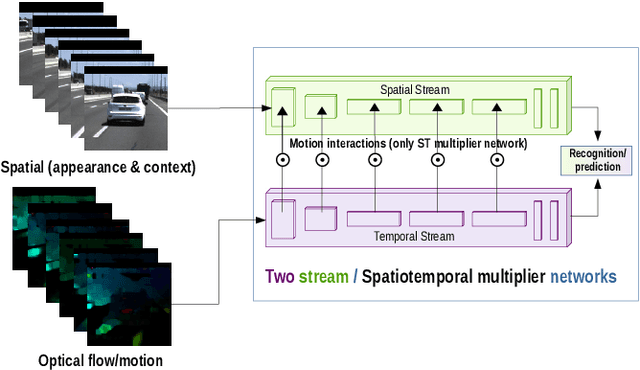


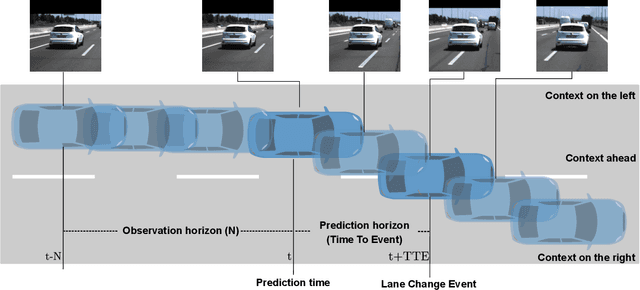
In highway scenarios, an alert human driver will typically anticipate early cut-in and cut-out maneuvers of surrounding vehicles using only visual cues. An automated system must anticipate these situations at an early stage too, to increase the safety and the efficiency of its performance. To deal with lane-change recognition and prediction of surrounding vehicles, we pose the problem as an action recognition/prediction problem by stacking visual cues from video cameras. Two video action recognition approaches are analyzed: two-stream convolutional networks and spatiotemporal multiplier networks. Different sizes of the regions around the vehicles are analyzed, evaluating the importance of the interaction between vehicles and the context information in the performance. In addition, different prediction horizons are evaluated. The obtained results demonstrate the potential of these methodologies to serve as robust predictors of future lane-changes of surrounding vehicles in time horizons between 1 and 2 seconds.
A Distributed Multi-Robot Coordination Algorithm for Navigation in Tight Environments
Jun 20, 2020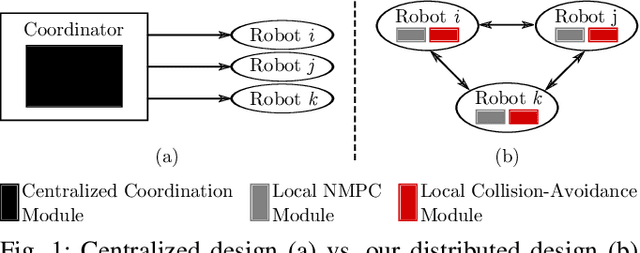
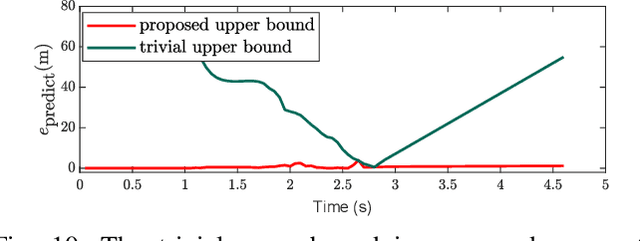
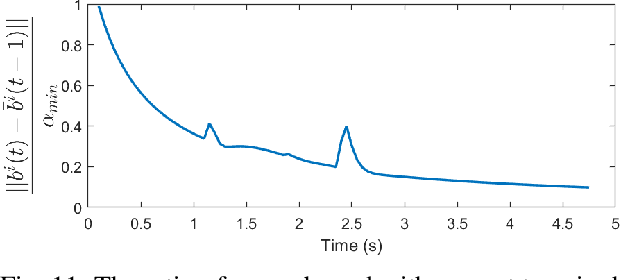
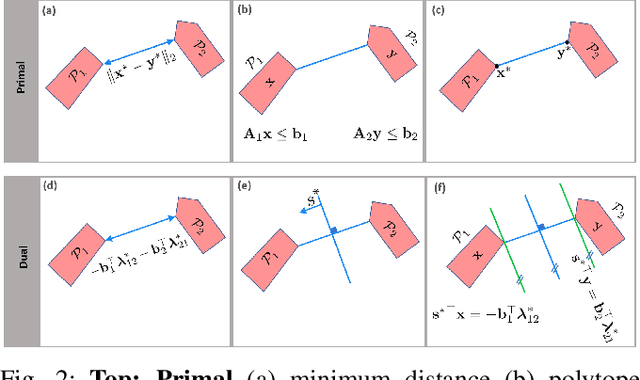
This work presents a distributed method for multi-robot coordination based on nonlinear model predictive control (NMPC) and dual decomposition. Our approach allows the robots to coordinate in tight spaces (e.g., highway lanes, parking lots, warehouses, canals, etc.) by using a polytopic description of each robot's shape and formulating the collision avoidance as a dual optimization problem. Our method accommodates heterogeneous teams of robots (i.e., robots with different polytopic shapes and dynamic models can be part of the same team) and can be used to avoid collisions in $n$-dimensional spaces. Starting from a centralized implementation of the NMPC problem, we show how to exploit the problem structure to allow the robots to cooperate (while communicating their intentions to the neighbors) and compute collision-free paths in a distributed way in real time. By relying on a bi-level optimization scheme, our design decouples the optimization of the robot states and of the collision-avoidance variables to create real time coordination strategies. Finally, we apply our method for the autonomous navigation of a platoon of connected vehicles on a simulation setting. We compare our design with the centralized NMPC design to show the computational benefits of the proposed distributed algorithm. In addition, we demonstrate our method for coordination of a heterogeneous team of robots (with different polytopic shapes).
Deep Echo State Q-Network (DEQN) and Its Application in Dynamic Spectrum Sharing for 5G and Beyond
Oct 12, 2020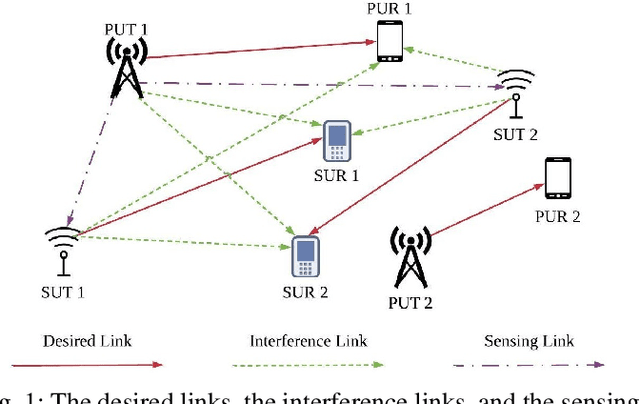

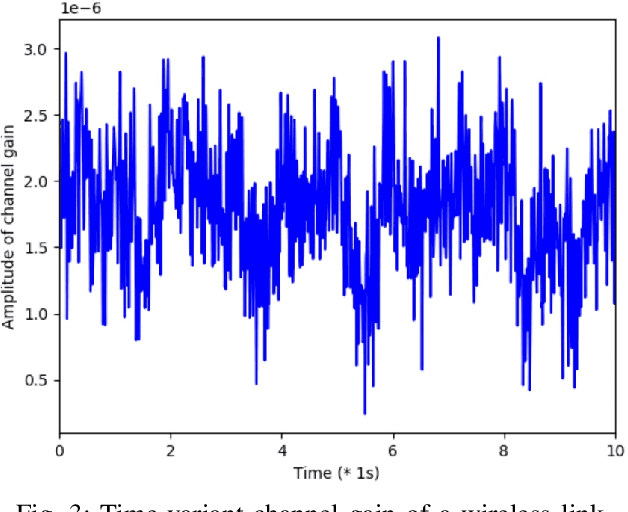
Deep reinforcement learning (DRL) has been shown to be successful in many application domains. Combining recurrent neural networks (RNNs) and DRL further enables DRL to be applicable in non-Markovian environments by capturing temporal information. However, training of both DRL and RNNs is known to be challenging requiring a large amount of training data to achieve convergence. In many targeted applications, such as those used in the fifth generation (5G) cellular communication, the environment is highly dynamic while the available training data is very limited. Therefore, it is extremely important to develop DRL strategies that are capable of capturing the temporal correlation of the dynamic environment requiring limited training overhead. In this paper, we introduce the deep echo state Q-network (DEQN) that can adapt to the highly dynamic environment in a short period of time with limited training data. We evaluate the performance of the introduced DEQN method under the dynamic spectrum sharing (DSS) scenario, which is a promising technology in 5G and future 6G networks to increase the spectrum utilization. Compared to conventional spectrum management policy that grants a fixed spectrum band to a single system for exclusive access, DSS allows the secondary system to share the spectrum with the primary system. Our work sheds light on the application of an efficient DRL framework in highly dynamic environments with limited available training data.
FANG: Leveraging Social Context for Fake News Detection Using Graph Representation
Aug 18, 2020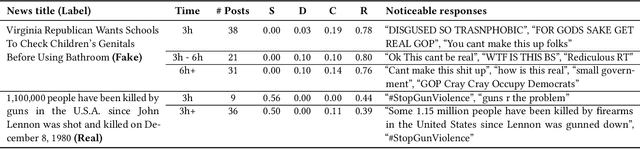
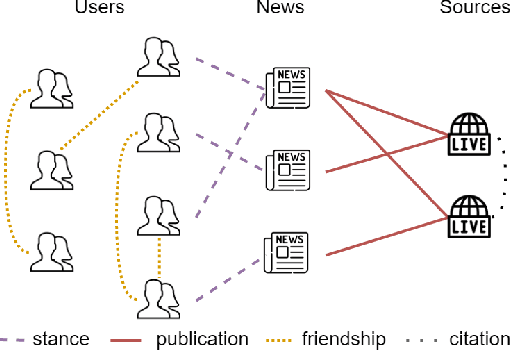
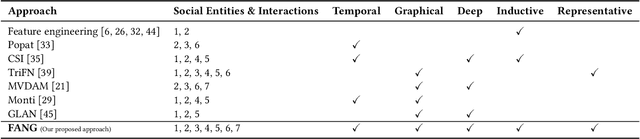
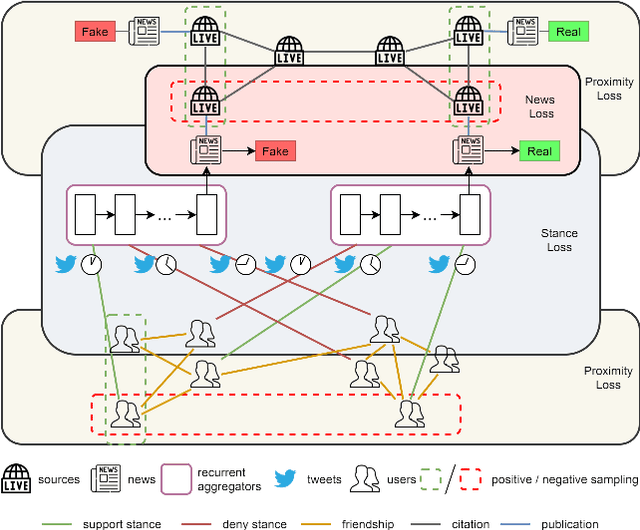
We propose Factual News Graph (FANG), a novel graphical social context representation and learning framework for fake news detection. Unlike previous contextual models that have targeted performance, our focus is on representation learning. Compared to transductive models, FANG is scalable in training as it does not have to maintain all nodes, and it is efficient at inference time, without the need to re-process the entire graph. Our experimental results show that FANG is better at capturing the social context into a high fidelity representation, compared to recent graphical and non-graphical models. In particular, FANG yields significant improvements for the task of fake news detection, and it is robust in the case of limited training data. We further demonstrate that the representations learned by FANG generalize to related tasks, such as predicting the factuality of reporting of a news medium.
Hybrid Attention Networks for Flow and Pressure Forecasting in Water Distribution Systems
Apr 14, 2020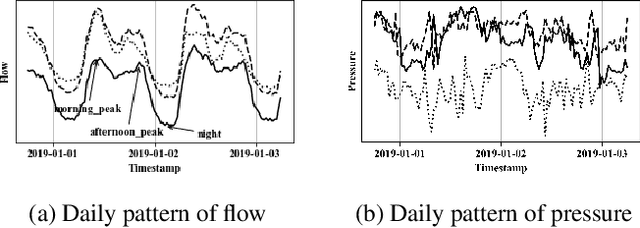
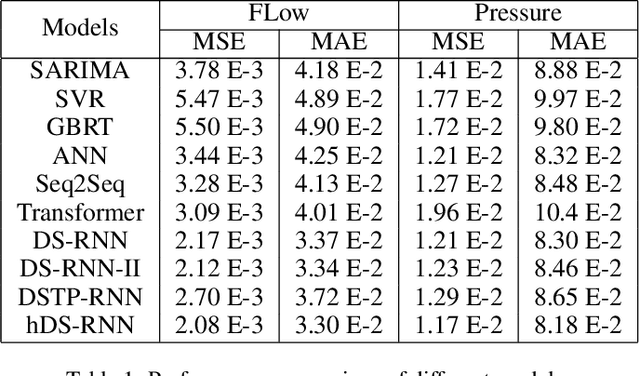
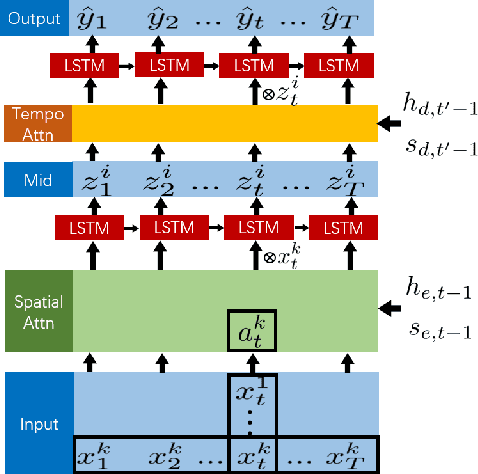
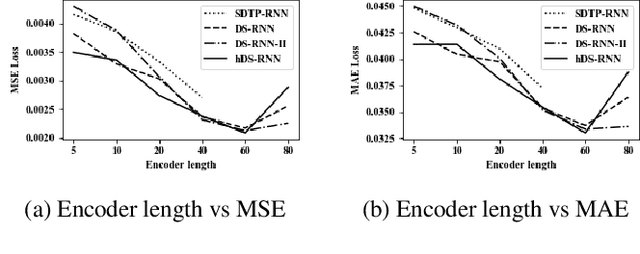
Multivariate geo-sensory time series prediction is challenging because of the complex spatial and temporal correlation. In urban water distribution systems (WDS), numerous spatial-correlated sensors have been deployed to continuously collect hydraulic data. Forecasts of monitored flow and pressure time series are of vital importance for operational decision making, alerts and anomaly detection. To address this issue, we proposed a hybrid dual-stage spatial-temporal attention-based recurrent neural networks (hDS-RNN). Our model consists of two stages: a spatial attention-based encoder and a temporal attention-based decoder. Specifically, a hybrid spatial attention mechanism that employs inputs along temporal and spatial axes is proposed. Experiments on a real-world dataset are conducted and demonstrate that our model outperformed 9 baseline models in flow and pressure series prediction in WDS.