 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Advancing from Predictive Maintenance to Intelligent Maintenance with AI and IIoT
Sep 01, 2020
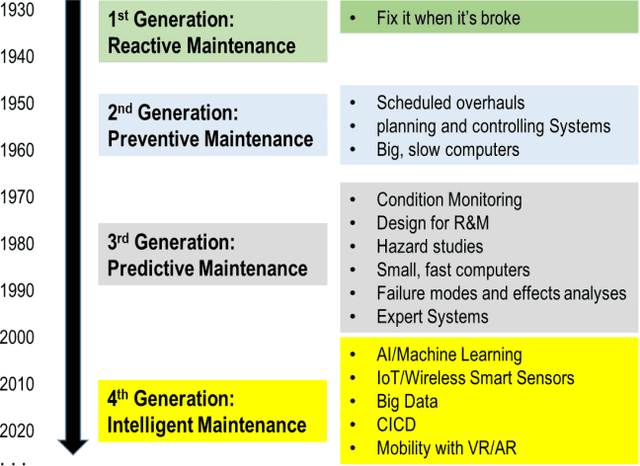
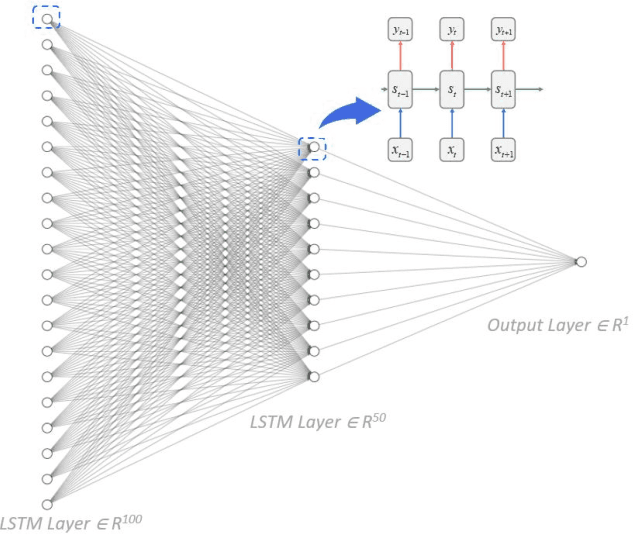
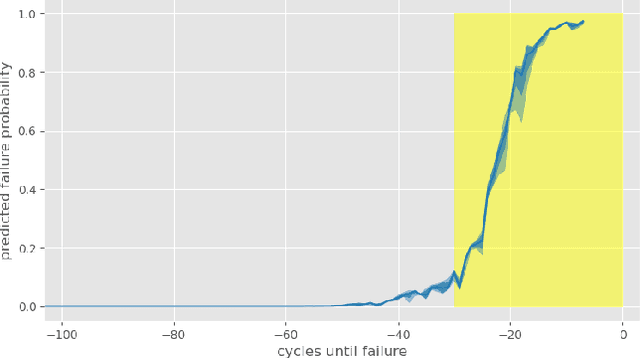
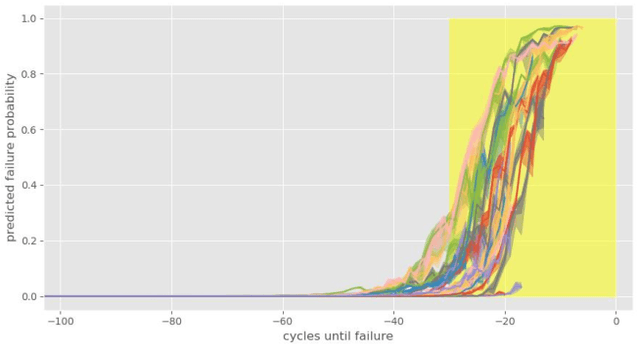
As Artificial Intelligent (AI) technology advances and increasingly large amounts of data become readily available via various Industrial Internet of Things (IIoT) projects, we evaluate the state of the art of predictive maintenance approaches and propose our innovative framework to improve the current practice. The paper first reviews the evolution of reliability modelling technology in the past 90 years and discusses major technologies developed in industry and academia. We then introduce the next generation maintenance framework - Intelligent Maintenance, and discuss its key components. This AI and IIoT based Intelligent Maintenance framework is composed of (1) latest machine learning algorithms including probabilistic reliability modelling with deep learning, (2) real-time data collection, transfer, and storage through wireless smart sensors, (3) Big Data technologies, (4) continuously integration and deployment of machine learning models, (5) mobile device and AR/VR applications for fast and better decision-making in the field. Particularly, we proposed a novel probabilistic deep learning reliability modelling approach and demonstrate it in the Turbofan Engine Degradation Dataset.
k-Nearest Neighbour Classifiers: 2nd Edition (with Python examples)
Apr 29, 2020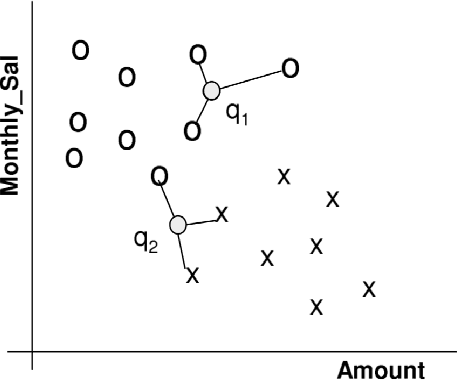
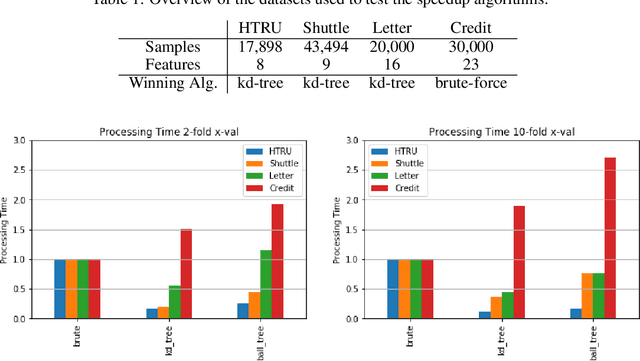
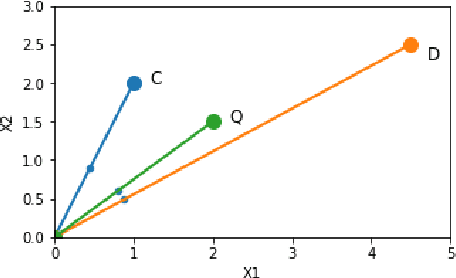
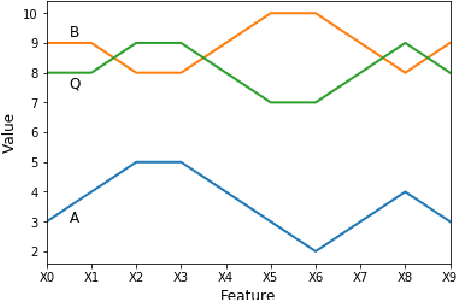
Perhaps the most straightforward classifier in the arsenal or machine learning techniques is the Nearest Neighbour Classifier -- classification is achieved by identifying the nearest neighbours to a query example and using those neighbours to determine the class of the query. This approach to classification is of particular importance because issues of poor run-time performance is not such a problem these days with the computational power that is available. This paper presents an overview of techniques for Nearest Neighbour classification focusing on; mechanisms for assessing similarity (distance), computational issues in identifying nearest neighbours and mechanisms for reducing the dimension of the data. This paper is the second edition of a paper previously published as a technical report. Sections on similarity measures for time-series, retrieval speed-up and intrinsic dimensionality have been added. An Appendix is included providing access to Python code for the key methods.
Learning to Learn from Mistakes: Robust Optimization for Adversarial Noise
Aug 12, 2020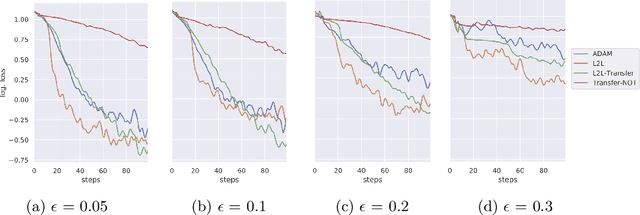
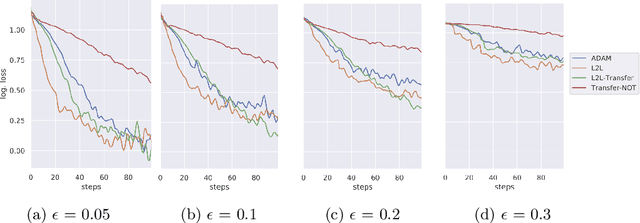
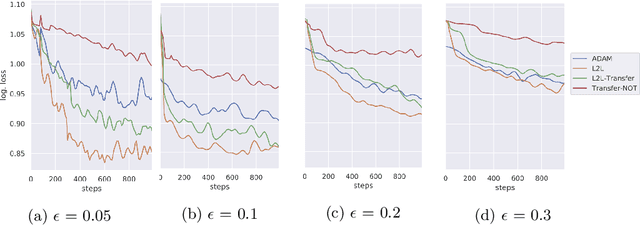
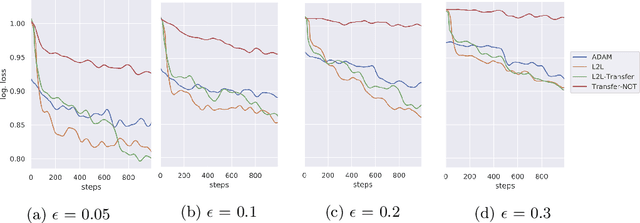
Sensitivity to adversarial noise hinders deployment of machine learning algorithms in security-critical applications. Although many adversarial defenses have been proposed, robustness to adversarial noise remains an open problem. The most compelling defense, adversarial training, requires a substantial increase in processing time and it has been shown to overfit on the training data. In this paper, we aim to overcome these limitations by training robust models in low data regimes and transfer adversarial knowledge between different models. We train a meta-optimizer which learns to robustly optimize a model using adversarial examples and is able to transfer the knowledge learned to new models, without the need to generate new adversarial examples. Experimental results show the meta-optimizer is consistent across different architectures and data sets, suggesting it is possible to automatically patch adversarial vulnerabilities.
Physics-informed Neural Networks for Solving Inverse Problems of Nonlinear Biot's Equations: Batch Training
May 18, 2020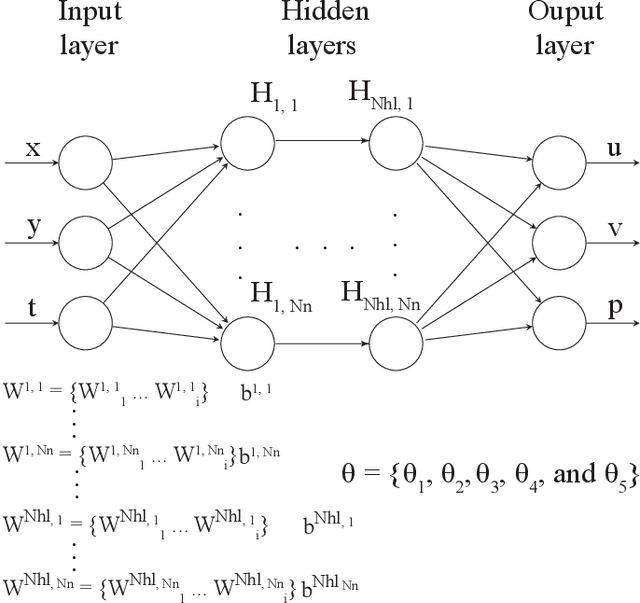
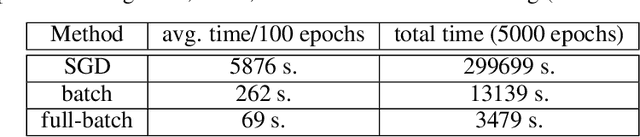
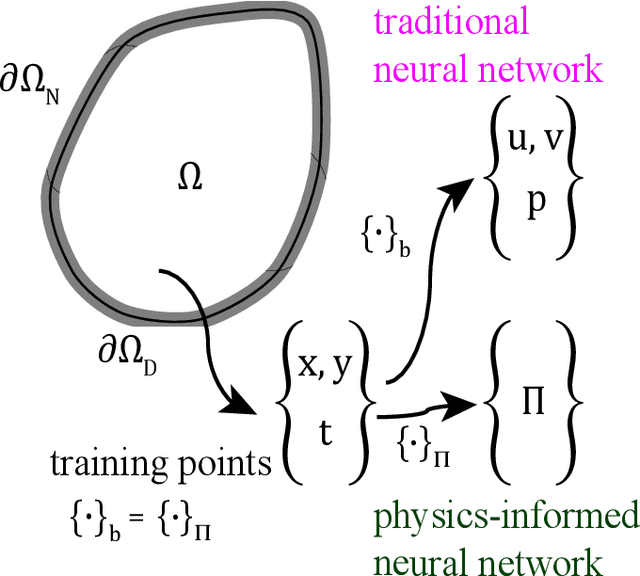

In biomedical engineering, earthquake prediction, and underground energy harvesting, it is crucial to indirectly estimate the physical properties of porous media since the direct measurement of those are usually impractical/prohibitive. Here we apply the physics-informed neural networks to solve the inverse problem with regard to the nonlinear Biot's equations. Specifically, we consider batch training and explore the effect of different batch sizes. The results show that training with small batch sizes, i.e., a few examples per batch, provides better approximations (lower percentage error) of the physical parameters than using large batches or the full batch. The increased accuracy of the physical parameters, comes at the cost of longer training time. Specifically, we find the size should not be too small since a very small batch size requires a very long training time without a corresponding improvement in estimation accuracy. We find that a batch size of 8 or 32 is a good compromise, which is also robust to additive noise in the data. The learning rate also plays an important role and should be used as a hyperparameter.
TwinBERT: Distilling Knowledge to Twin-Structured BERT Models for Efficient Retrieval
Feb 14, 2020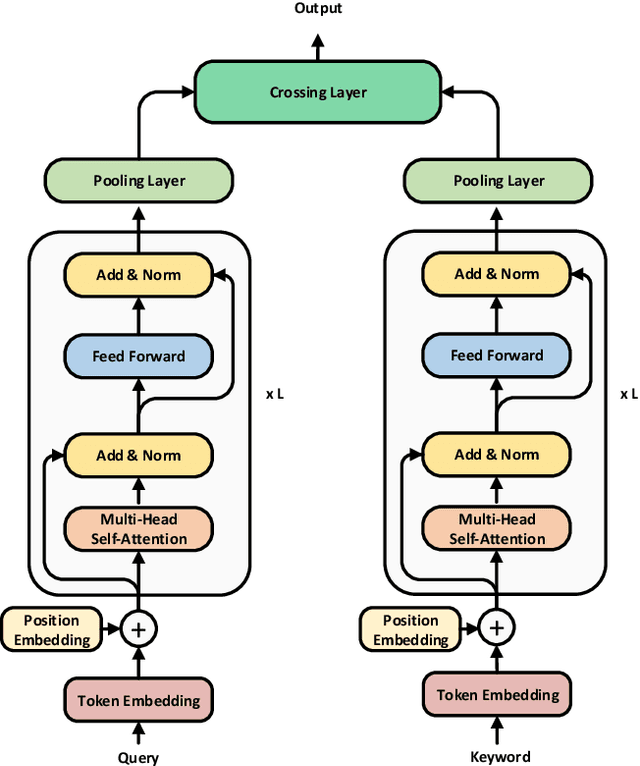
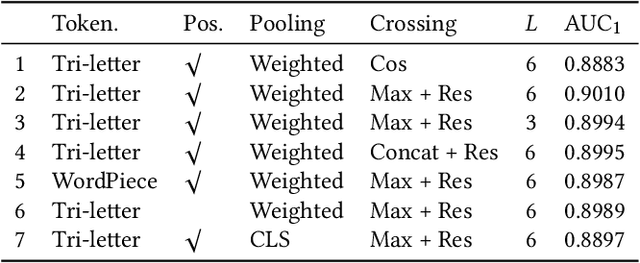
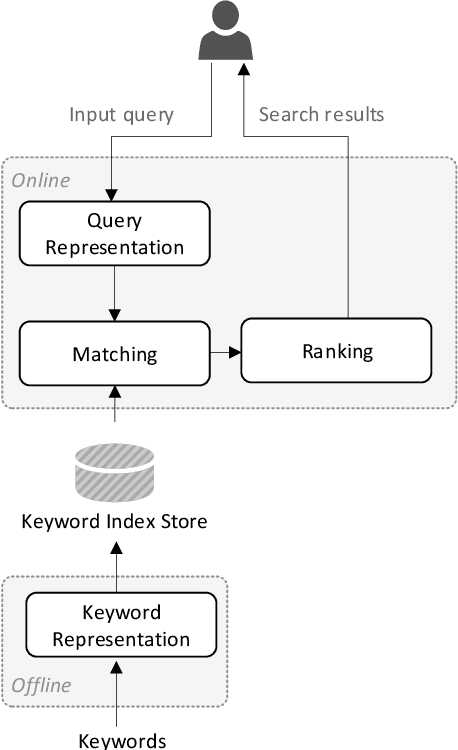
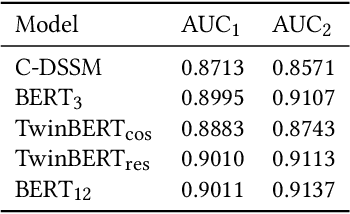
Pre-trained language models like BERT have achieved great success in a wide variety of NLP tasks, while the superior performance comes with high demand in computational resources, which hinders the application in low-latency IR systems. We present TwinBERT model for effective and efficient retrieval, which has twin-structured BERT-like encoders to represent query and document respectively and a crossing layer to combine the embeddings and produce a similarity score. Different from BERT, where the two input sentences are concatenated and encoded together, TwinBERT decouples them during encoding and produces the embeddings for query and document independently, which allows document embeddings to be pre-computed offline and cached in memory. Thereupon, the computation left for run-time is from the query encoding and query-document crossing only. This single change can save large amount of computation time and resources, and therefore significantly improve serving efficiency. Moreover, a few well-designed network layers and training strategies are proposed to further reduce computational cost while at the same time keep the performance as remarkable as BERT model. Lastly, we develop two versions of TwinBERT for retrieval and relevance tasks correspondingly, and both of them achieve close or on-par performance to BERT-Base model. The model was trained following the teacher-student framework and evaluated with data from one of the major search engines. Experimental results showed that the inference time was significantly reduced and was firstly controlled around 20ms on CPUs while at the same time the performance gain from fine-tuned BERT-Base model was mostly retained. Integration of the models into production systems also demonstrated remarkable improvements on relevance metrics with negligible influence on latency.
Probabilistic Spatial Transformers for Bayesian Data Augmentation
Apr 07, 2020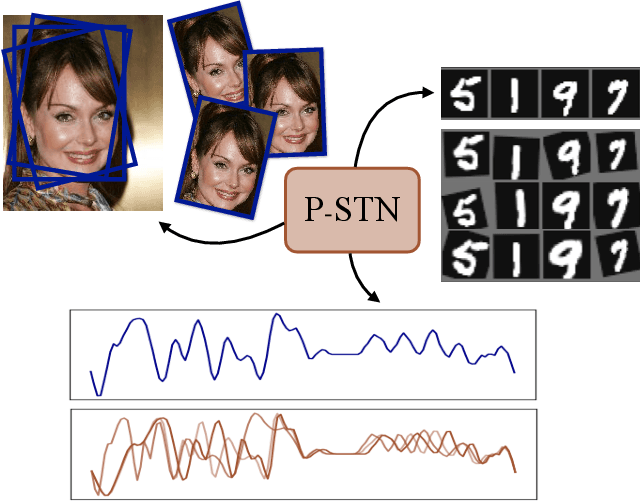
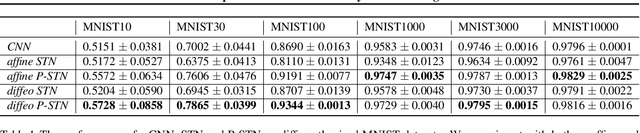
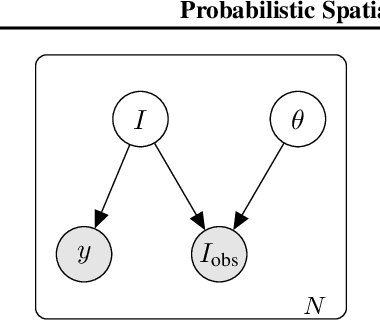

High-capacity models require vast amounts of data, and data augmentation is a common remedy when this resource is limited. Standard augmentation techniques apply small hand-tuned transformations to existing data, which is a brittle process that realistically only allows for simple transformations. We propose a Bayesian interpretation of data augmentation where the transformations are modelled as latent variables to be marginalized, and show how these can be inferred variationally in an end-to-end fashion. This allows for significantly more complex transformations than manual tuning, and the marginalization implies a form of test-time data augmentation. The resulting model can be interpreted as a probabilistic extension of spatial transformer networks. Experimentally, we demonstrate improvements in accuracy and uncertainty quantification in image and time series classification tasks.
e-SNLI-VE-2.0: Corrected Visual-Textual Entailment with Natural Language Explanations
Apr 22, 2020

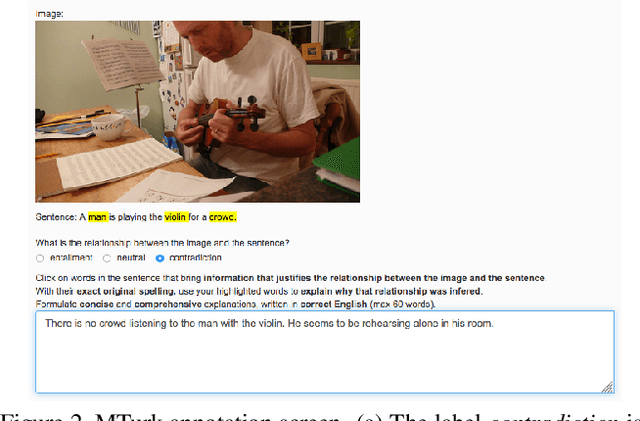
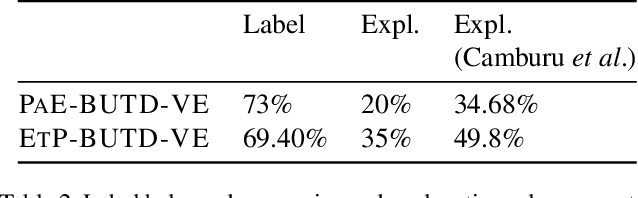
The recently proposed SNLI-VE corpus for recognising visual-textual entailment is a large, real-world dataset for fine-grained multimodal reasoning. However, the automatic way in which SNLI-VE has been assembled (via combining parts of two related datasets) gives rise to a large number of errors in the labels of this corpus. In this paper, we first present a data collection effort to correct the class with the highest error rate in SNLI-VE. Secondly, we re-evaluate an existing model on the corrected corpus, which we call SNLI-VE-2.0, and provide a quantitative comparison with its performance on the non-corrected corpus. Thirdly, we introduce e-SNLI-VE-2.0, which appends human-written natural language explanations to SNLI-VE-2.0. Finally, we train models that learn from these explanations at training time, and output such explanations at testing time.
Development and Validation of a Novel Prognostic Model for Predicting AMD Progression Using Longitudinal Fundus Images
Jul 10, 2020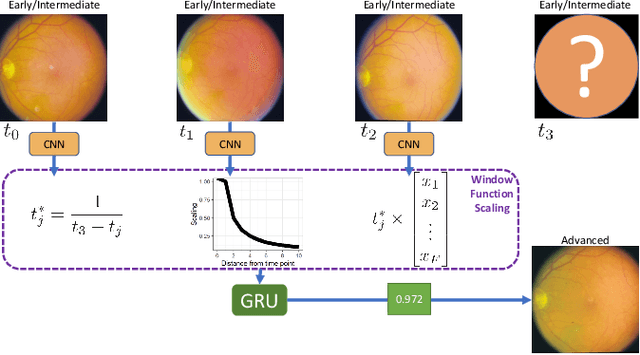
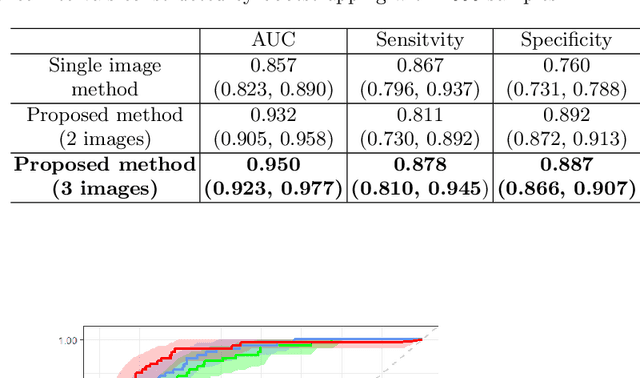
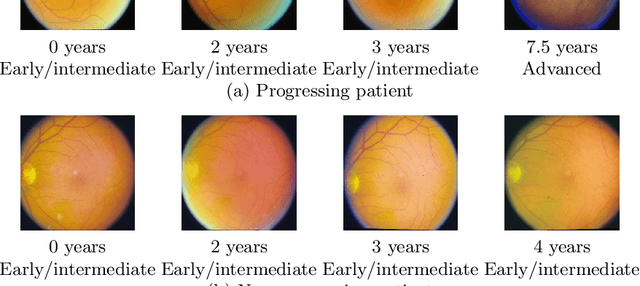
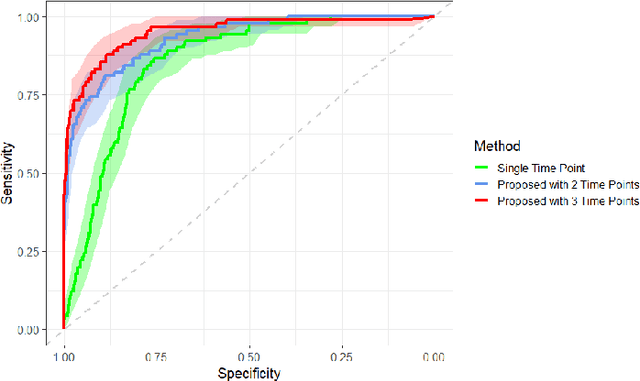
Prognostic models aim to predict the future course of a disease or condition and are a vital component of personalized medicine. Statistical models make use of longitudinal data to capture the temporal aspect of disease progression; however, these models require prior feature extraction. Deep learning avoids explicit feature extraction, meaning we can develop models for images where features are either unknown or impossible to quantify accurately. Previous prognostic models using deep learning with imaging data require annotation during training or only utilize a single time point. We propose a novel deep learning method to predict the progression of diseases using longitudinal imaging data with uneven time intervals, which requires no prior feature extraction. Given previous images from a patient, our method aims to predict whether the patient will progress onto the next stage of the disease. The proposed method uses InceptionV3 to produce feature vectors for each image. In order to account for uneven intervals, a novel interval scaling is proposed. Finally, a Recurrent Neural Network is used to prognosticate the disease. We demonstrate our method on a longitudinal dataset of color fundus images from 4903 eyes with age-related macular degeneration (AMD), taken from the Age-Related Eye Disease Study, to predict progression to late AMD. Our method attains a testing sensitivity of 0.878, a specificity of 0.887, and an area under the receiver operating characteristic of 0.950. We compare our method to previous methods, displaying superior performance in our model. Class activation maps display how the network reaches the final decision.
SeDMiD for Confusion Detection: Uncovering Mind State from Time Series Brain Wave Data
Nov 29, 2016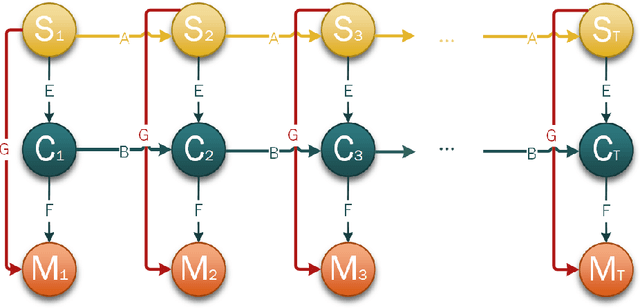

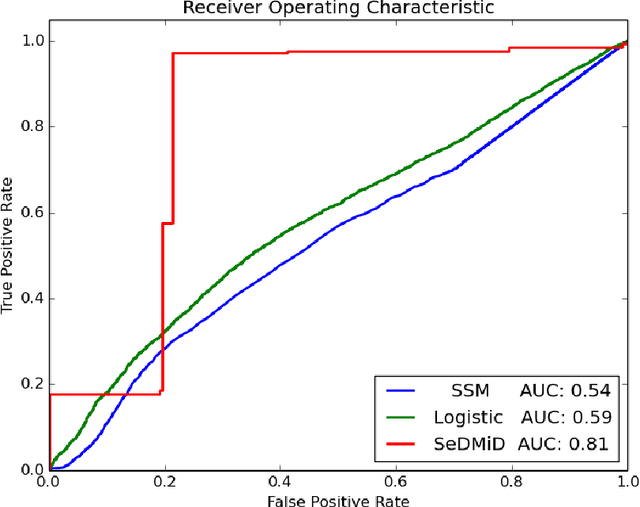
Understanding how brain functions has been an intriguing topic for years. With the recent progress on collecting massive data and developing advanced technology, people have become interested in addressing the challenge of decoding brain wave data into meaningful mind states, with many machine learning models and algorithms being revisited and developed, especially the ones that handle time series data because of the nature of brain waves. However, many of these time series models, like HMM with hidden state in discrete space or State Space Model with hidden state in continuous space, only work with one source of data and cannot handle different sources of information simultaneously. In this paper, we propose an extension of State Space Model to work with different sources of information together with its learning and inference algorithms. We apply this model to decode the mind state of students during lectures based on their brain waves and reach a significant better results compared to traditional methods.
Reliably Learning the ReLU in Polynomial Time
Nov 30, 2016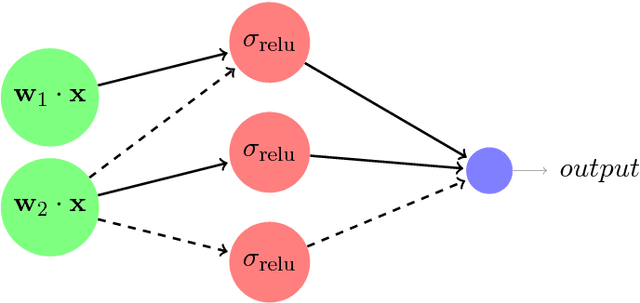
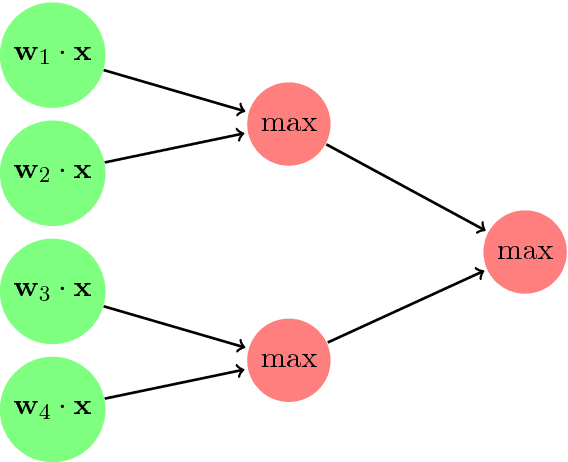
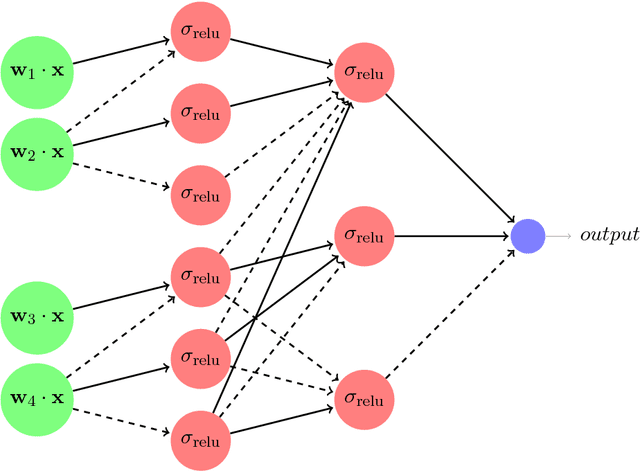
We give the first dimension-efficient algorithms for learning Rectified Linear Units (ReLUs), which are functions of the form $\mathbf{x} \mapsto \max(0, \mathbf{w} \cdot \mathbf{x})$ with $\mathbf{w} \in \mathbb{S}^{n-1}$. Our algorithm works in the challenging Reliable Agnostic learning model of Kalai, Kanade, and Mansour (2009) where the learner is given access to a distribution $\cal{D}$ on labeled examples but the labeling may be arbitrary. We construct a hypothesis that simultaneously minimizes the false-positive rate and the loss on inputs given positive labels by $\cal{D}$, for any convex, bounded, and Lipschitz loss function. The algorithm runs in polynomial-time (in $n$) with respect to any distribution on $\mathbb{S}^{n-1}$ (the unit sphere in $n$ dimensions) and for any error parameter $\epsilon = \Omega(1/\log n)$ (this yields a PTAS for a question raised by F. Bach on the complexity of maximizing ReLUs). These results are in contrast to known efficient algorithms for reliably learning linear threshold functions, where $\epsilon$ must be $\Omega(1)$ and strong assumptions are required on the marginal distribution. We can compose our results to obtain the first set of efficient algorithms for learning constant-depth networks of ReLUs. Our techniques combine kernel methods and polynomial approximations with a "dual-loss" approach to convex programming. As a byproduct we obtain a number of applications including the first set of efficient algorithms for "convex piecewise-linear fitting" and the first efficient algorithms for noisy polynomial reconstruction of low-weight polynomials on the unit sphere.