 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On Fair Virtual Conference Scheduling: Achieving Equitable Participant and Speaker Satisfaction
Oct 24, 2020
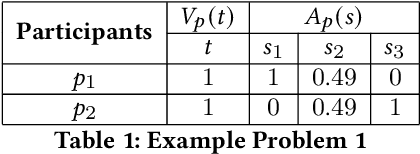
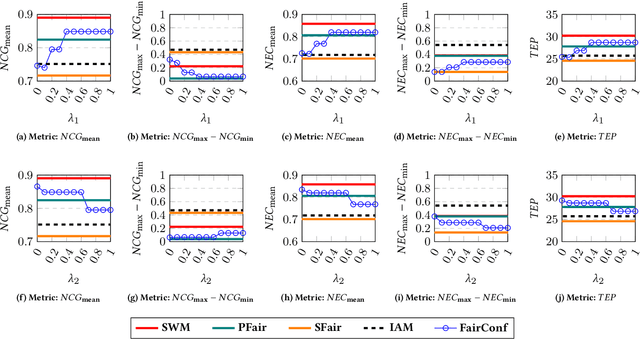
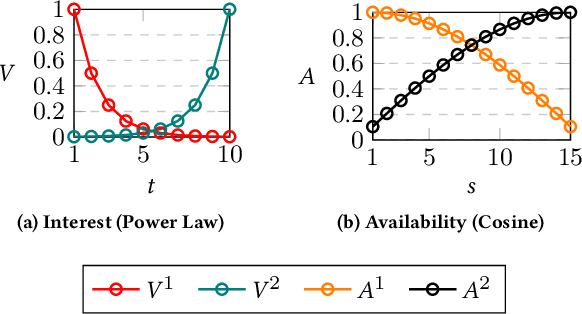
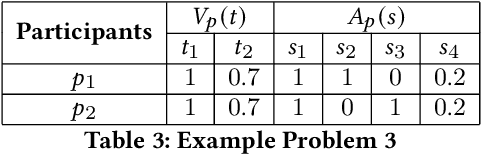
The (COVID-19) pandemic-induced restrictions on travel and social gatherings have prompted most conference organizers to move their events online. However, in contrast to physical conferences, virtual conferences face a challenge in efficiently scheduling talks, accounting for the availability of participants from different time-zones as well as their interests in attending different talks. In such settings, a natural objective for the conference organizers would be to maximize some global welfare measure, such as the total expected audience participation across all talks. However, we show that optimizing for global welfare could result in a schedule that is unfair to the stakeholders, i.e., the individual utilities for participants and speakers can be highly unequal. To address the fairness concerns, we formally define fairness notions for participants and speakers, and subsequently derive suitable fairness objectives for them. We show that the welfare and fairness objectives can be in conflict with each other, and there is a need to maintain a balance between these objective while caring for them simultaneously. Thus, we propose a joint optimization framework that allows conference organizers to design talk schedules that balance (i.e., allow trade-offs) between global welfare, participant fairness and the speaker fairness objectives. We show that the optimization problem can be solved using integer linear programming, and empirically evaluate the necessity and benefits of such joint optimization approach in virtual conference scheduling.
Efficient, Simple and Automated Negative Sampling for Knowledge Graph Embedding
Oct 24, 2020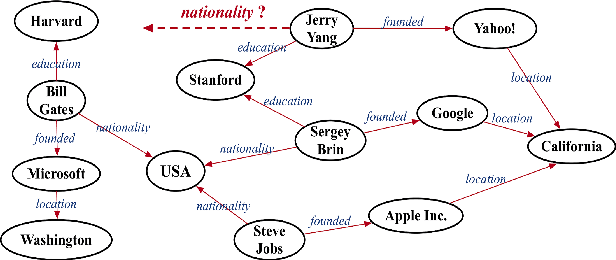
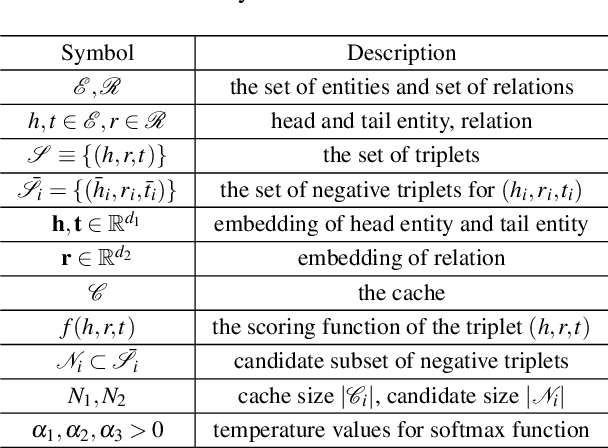

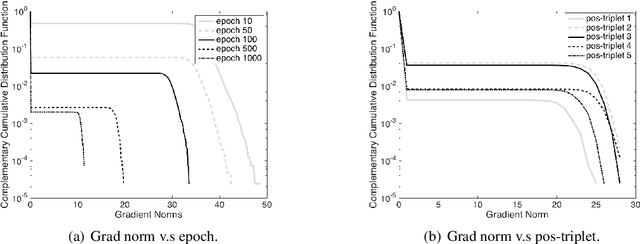
Negative sampling, which samples negative triplets from non-observed ones in knowledge graph (KG), is an essential step in KG embedding. Recently, generative adversarial network (GAN), has been introduced in negative sampling. By sampling negative triplets with large gradients, these methods avoid the problem of vanishing gradient and thus obtain better performance. However, they make the original model more complex and harder to train. In this paper, motivated by the observation that negative triplets with large gradients are important but rare, we propose to directly keep track of them with the cache. In this way, our method acts as a "distilled" version of previous GAN-based methods, which does not waste training time on additional parameters to fit the full distribution of negative triplets. However, how to sample from and update the cache are two critical questions. We propose to solve these issues by automated machine learning techniques. The automated version also covers GAN-based methods as special cases. Theoretical explanation of NSCaching is also provided, justifying the superior over fixed sampling scheme. Besides, we further extend NSCaching with skip-gram model for graph embedding. Finally, extensive experiments show that our method can gain significant improvements on various KG embedding models and the skip-gram model, and outperforms the state-of-the-art negative sampling methods.
Optimal target assignment for massive spectroscopic surveys
May 18, 2020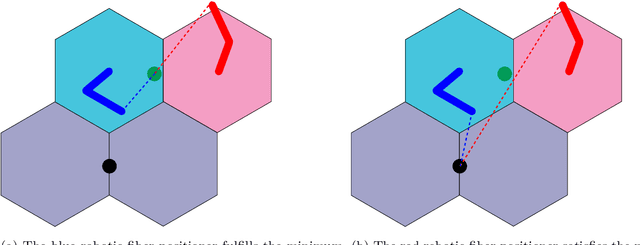

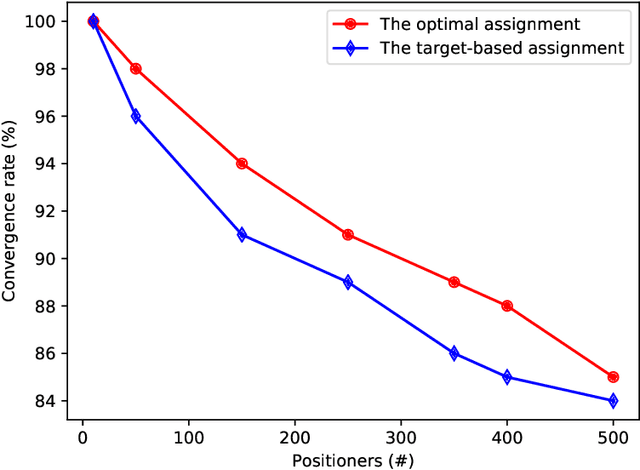
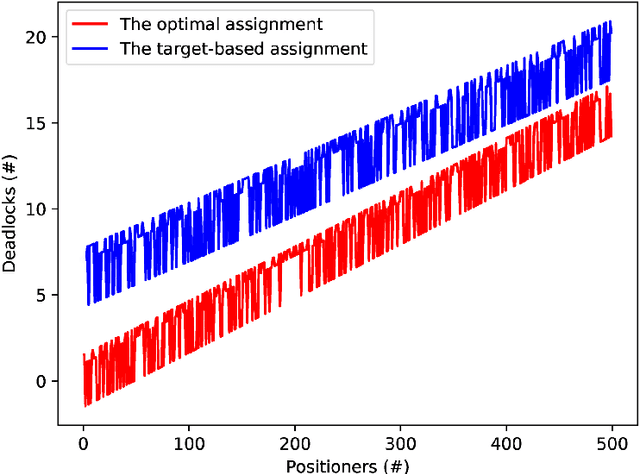
Robotics have recently contributed to cosmological spectroscopy to automatically obtain the map of the observable universe using robotic fiber positioners. For this purpose, an assignment algorithm is required to assign each robotic fiber positioner to a target associated with a particular observation. The assignment process directly impacts on the coordination of robotic fiber positioners to reach their assigned targets. In this paper, we establish an optimal target assignment scheme which simultaneously provides the fastest coordination accompanied with the minimum of colliding scenarios between robotic fiber positioners. In particular, we propose a cost function by whose minimization both of the cited requirements are taken into account in the course of a target assignment process. The applied simulations manifest the improvement of convergence rates using our optimal approach. We show that our algorithm scales the solution in quadratic time in the case of full observations. Additionally, the convergence time and the percentage of the colliding scenarios are also decreased in both supervisory and hybrid coordination strategies.
Application of Facial Recognition using Convolutional Neural Networks for Entry Access Control
Nov 23, 2020
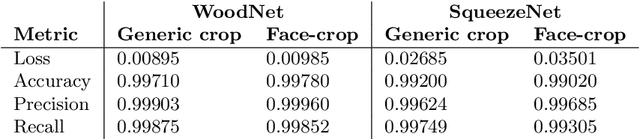
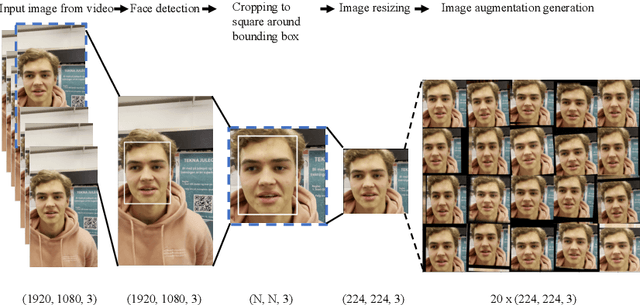
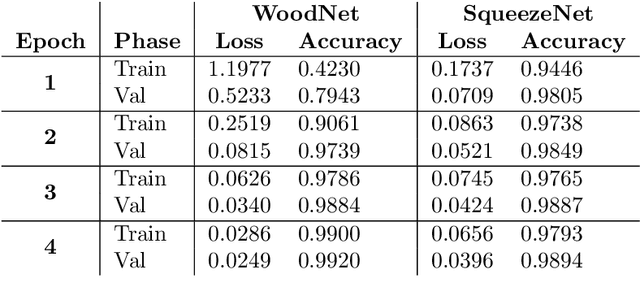
The purpose of this paper is to design a solution to the problem of facial recognition by use of convolutional neural networks, with the intention of applying the solution in a camera-based home-entry access control system. More specifically, the paper focuses on solving the supervised classification problem of taking images of people as input and classifying the person in the image as one of the authors or not. Two approaches are proposed: (1) building and training a neural network called WoodNet from scratch and (2) leveraging transfer learning by utilizing a network pre-trained on the ImageNet database and adapting it to this project's data and classes. In order to train the models to recognize the authors, a dataset containing more than 150 000 images has been created, balanced over the authors and others. Image extraction from videos and image augmentation techniques were instrumental for dataset creation. The results are two models classifying the individuals in the dataset with high accuracy, achieving over 99% accuracy on held-out test data. The pre-trained model fitted significantly faster than WoodNet, and seems to generalize better. However, these results come with a few caveats. Because of the way the dataset was compiled, as well as the high accuracy, one has reason to believe the models over-fitted to the data to some degree. An added consequence of the data compilation method is that the test dataset may not be sufficiently different from the training data, limiting its ability to validate generalization of the models. However, utilizing the models in a web-cam based system, classifying faces in real-time, shows promising results and indicates that the models generalized fairly well for at least some of the classes (see the accompanying video).
PowerPlanningDL: Reliability-Aware Framework for On-Chip Power Grid Design using Deep Learning
May 04, 2020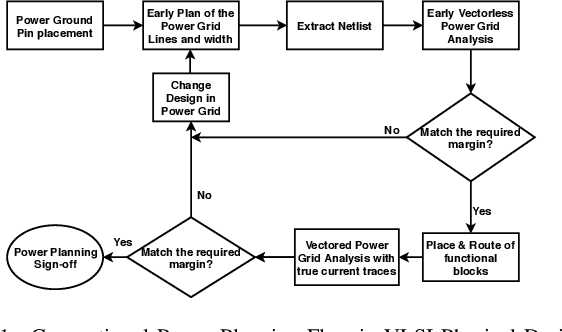
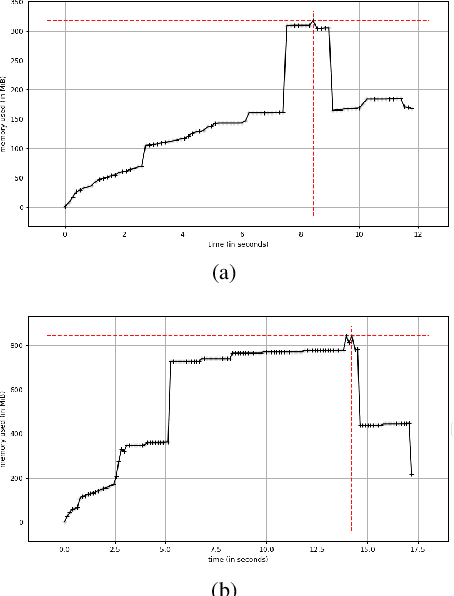
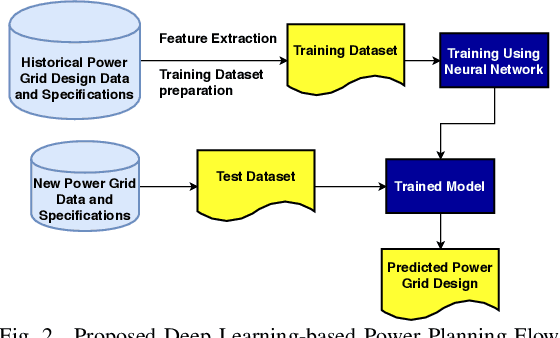
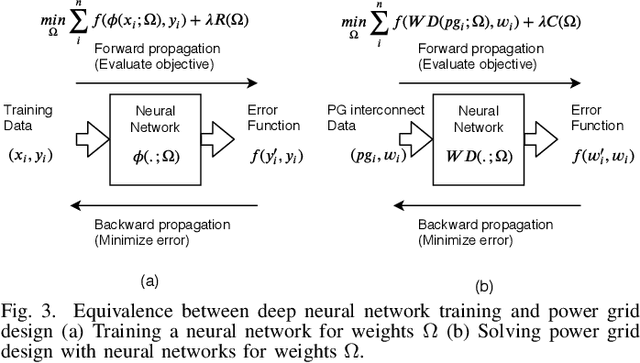
With the increase in the complexity of chip designs, VLSI physical design has become a time-consuming task, which is an iterative design process. Power planning is that part of the floorplanning in VLSI physical design where power grid networks are designed in order to provide adequate power to all the underlying functional blocks. Power planning also requires multiple iterative steps to create the power grid network while satisfying the allowed worst-case IR drop and Electromigration (EM) margin. For the first time, this paper introduces Deep learning (DL)-based framework to approximately predict the initial design of the power grid network, considering different reliability constraints. The proposed framework reduces many iterative design steps and speeds up the total design cycle. Neural Network-based multi-target regression technique is used to create the DL model. Feature extraction is done, and the training dataset is generated from the floorplans of some of the power grid designs extracted from the IBM processor. The DL model is trained using the generated dataset. The proposed DL-based framework is validated using a new set of power grid specifications (obtained by perturbing the designs used in the training phase). The results show that the predicted power grid design is closer to the original design with minimal prediction error (~2%). The proposed DL-based approach also improves the design cycle time with a speedup of ~6X for standard power grid benchmarks.
Combining Scatter Transform and Deep Neural Networks for Multilabel Electrocardiogram Signal Classification
Oct 15, 2020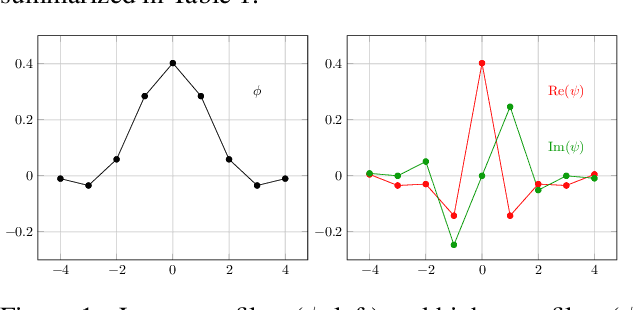
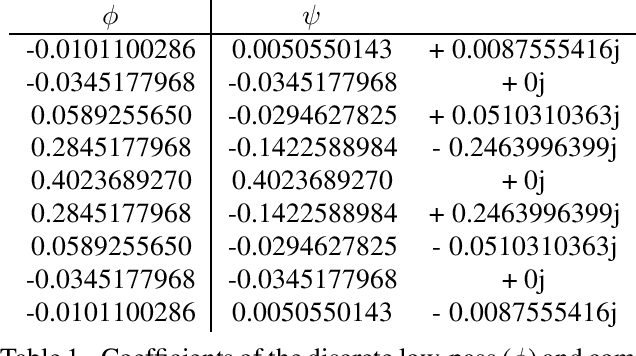

An essential part for the accurate classification of electrocardiogram (ECG) signals is the extraction of informative yet general features, which are able to discriminate diseases. Cardiovascular abnormalities manifest themselves in features on different time scales: small scale morphological features, such as missing P-waves, as well as rhythmical features apparent on heart rate scales. For this reason we incorporate a variant of the complex wavelet transform, called a scatter transform, in a deep residual neural network (ResNet). The former has the advantage of being derived from theory, making it well behaved under certain transformations of the input. The latter has proven useful in ECG classification, allowing feature extraction and classification to be learned in an end-to-end manner. Through the incorporation of trainable layers in between scatter transforms, the model gains the ability to combine information from different channels, yielding more informative features for the classification task and adapting them to the specific domain. For evaluation, we submitted our model in the official phase in the PhysioNet/Computing in Cardiology Challenge 2020. Our (Team Triage) approach achieved a challenge validation score of 0.640, and full test score of 0.485, placing us 4th out of 41 in the official ranking.
Probabilistic 3D surface reconstruction from sparse MRI information
Oct 05, 2020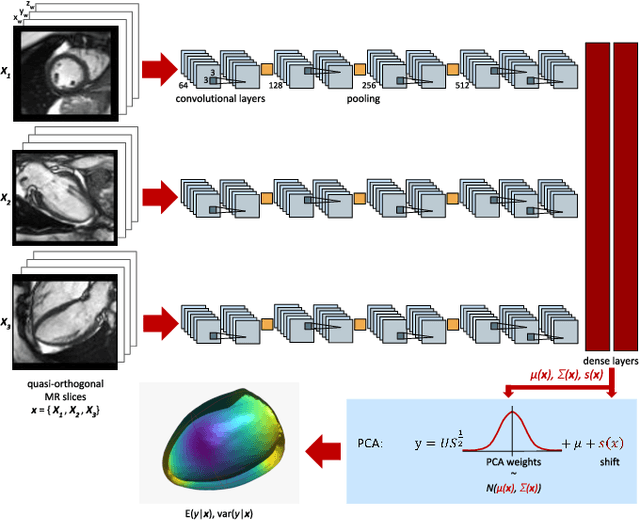
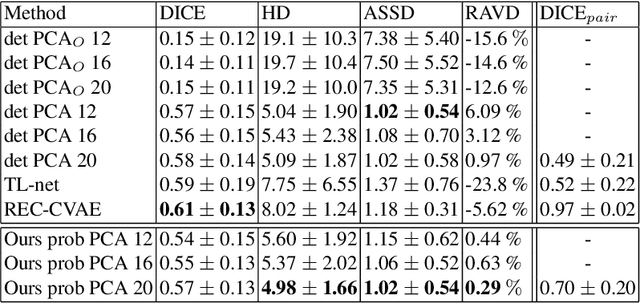

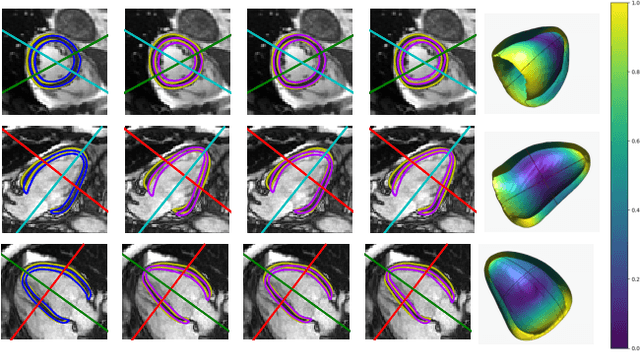
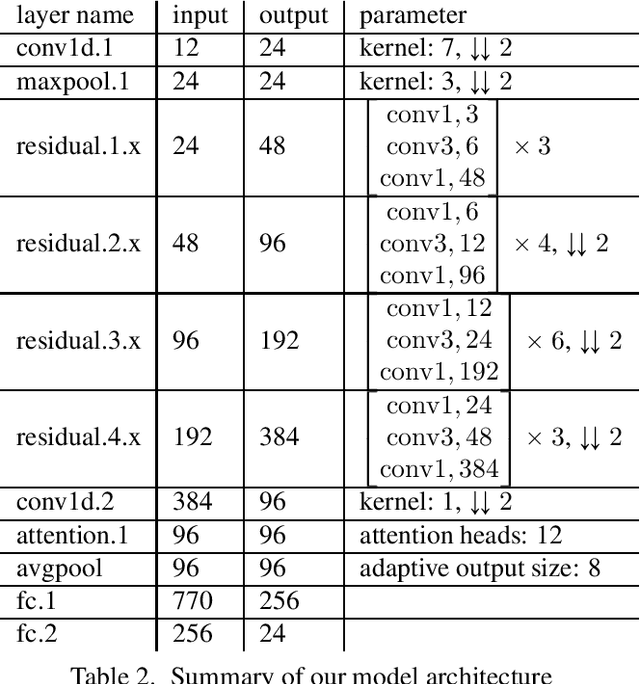
Surface reconstruction from magnetic resonance (MR) imaging data is indispensable in medical image analysis and clinical research. A reliable and effective reconstruction tool should: be fast in prediction of accurate well localised and high resolution models, evaluate prediction uncertainty, work with as little input data as possible. Current deep learning state of the art (SOTA) 3D reconstruction methods, however, often only produce shapes of limited variability positioned in a canonical position or lack uncertainty evaluation. In this paper, we present a novel probabilistic deep learning approach for concurrent 3D surface reconstruction from sparse 2D MR image data and aleatoric uncertainty prediction. Our method is capable of reconstructing large surface meshes from three quasi-orthogonal MR imaging slices from limited training sets whilst modelling the location of each mesh vertex through a Gaussian distribution. Prior shape information is encoded using a built-in linear principal component analysis (PCA) model. Extensive experiments on cardiac MR data show that our probabilistic approach successfully assesses prediction uncertainty while at the same time qualitatively and quantitatively outperforms SOTA methods in shape prediction. Compared to SOTA, we are capable of properly localising and orientating the prediction via the use of a spatially aware neural network.
Motion-Encoded Particle Swarm Optimization for Moving Target Search Using UAVs
Oct 05, 2020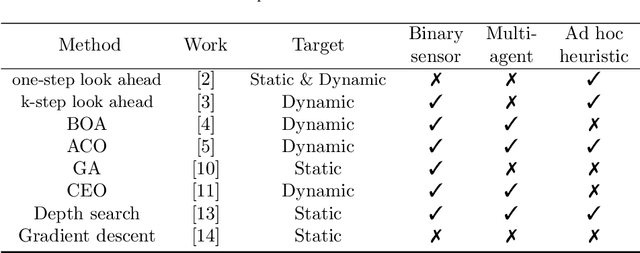
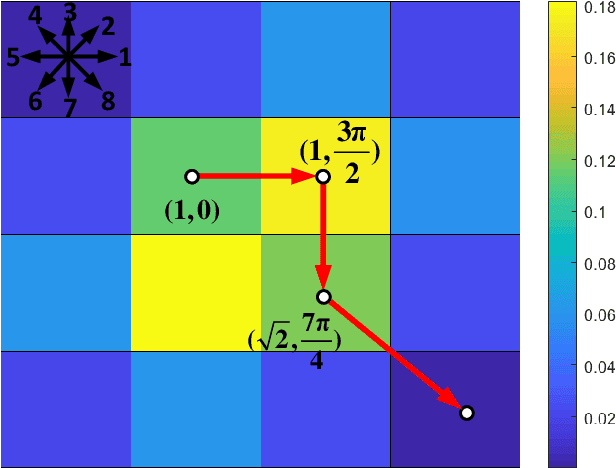
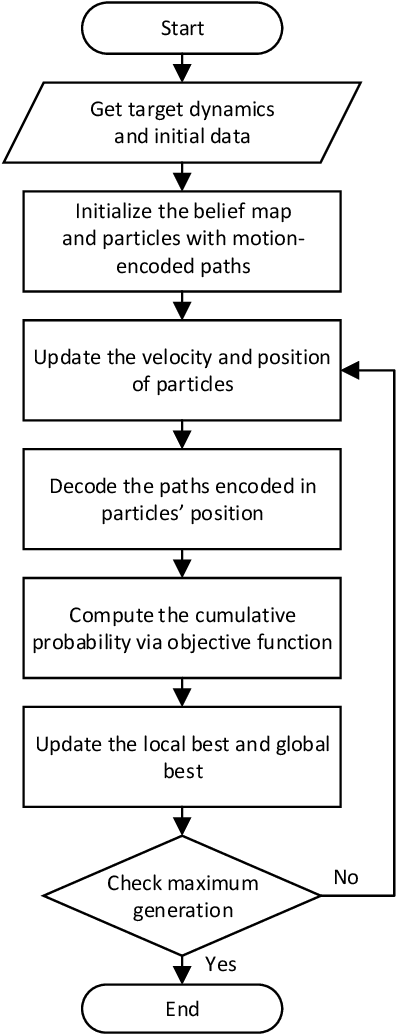
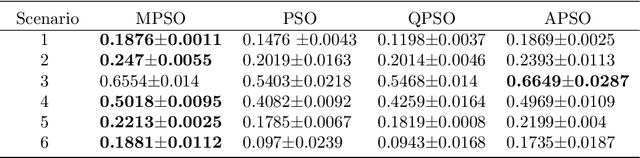
This paper presents a novel algorithm named the motion-encoded particle swarm optimization (MPSO) for finding a moving target with unmanned aerial vehicles (UAVs). From the Bayesian theory, the search problem can be converted to the optimization of a cost function that represents the probability of detecting the target. Here, the proposed MPSO is developed to solve that problem by encoding the search trajectory as a series of UAV motion paths evolving over the generation of particles in a PSO algorithm. This motion-encoded approach allows for preserving important properties of the swarm including the cognitive and social coherence, and thus resulting in better solutions. Results from extensive simulations with existing methods show that the proposed MPSO improves the detection performance by 24\% and time performance by 4.71 times compared to the original PSO, and moreover, also outperforms other state-of-the-art metaheuristic optimization algorithms including the artificial bee colony (ABC), ant colony optimization (ACO), genetic algorithm (GA), differential evolution (DE), and tree-seed algorithm (TSA) in most search scenarios. Experiments have been conducted with real UAVs in searching for a dynamic target in different scenarios to demonstrate MPSO merits in a practical application.
LG-GAN: Label Guided Adversarial Network for Flexible Targeted Attack of Point Cloud-based Deep Networks
Nov 01, 2020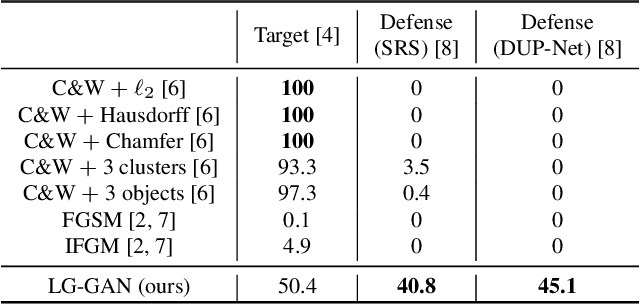
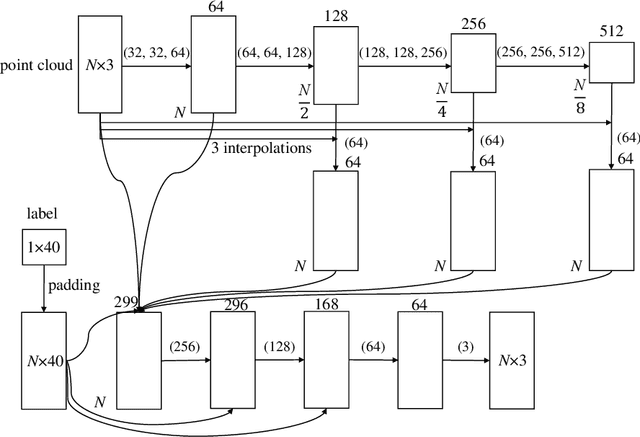
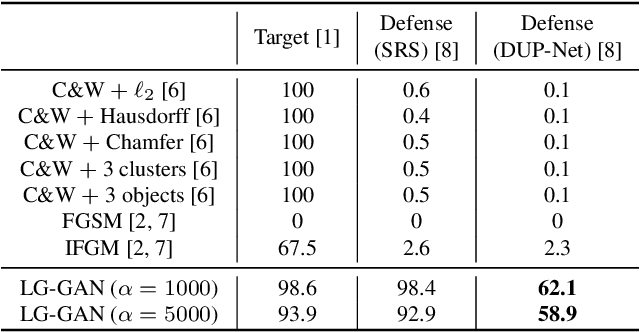

Deep neural networks have made tremendous progress in 3D point-cloud recognition. Recent works have shown that these 3D recognition networks are also vulnerable to adversarial samples produced from various attack methods, including optimization-based 3D Carlini-Wagner attack, gradient-based iterative fast gradient method, and skeleton-detach based point-dropping. However, after a careful analysis, these methods are either extremely slow because of the optimization/iterative scheme, or not flexible to support targeted attack of a specific category. To overcome these shortcomings, this paper proposes a novel label guided adversarial network (LG-GAN) for real-time flexible targeted point cloud attack. To the best of our knowledge, this is the first generation based 3D point cloud attack method. By feeding the original point clouds and target attack label into LG-GAN, it can learn how to deform the point clouds to mislead the recognition network into the specific label only with a single forward pass. In detail, LGGAN first leverages one multi-branch adversarial network to extract hierarchical features of the input point clouds, then incorporates the specified label information into multiple intermediate features using the label encoder. Finally, the encoded features will be fed into the coordinate reconstruction decoder to generate the target adversarial sample. By evaluating different point-cloud recognition models (e.g., PointNet, PointNet++ and DGCNN), we demonstrate that the proposed LG-GAN can support flexible targeted attack on the fly while guaranteeing good attack performance and higher efficiency simultaneously.
Can a Robot Trust You? A DRL-Based Approach to Trust-Driven Human-Guided Navigation
Nov 01, 2020

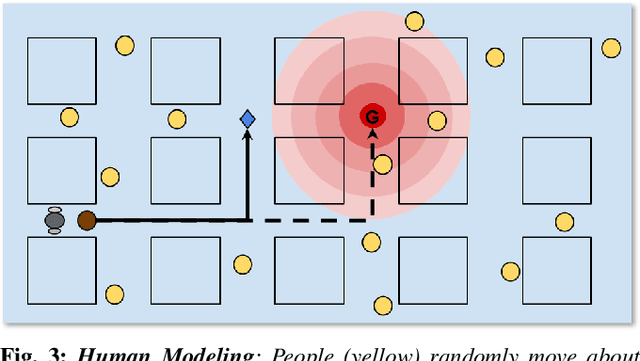
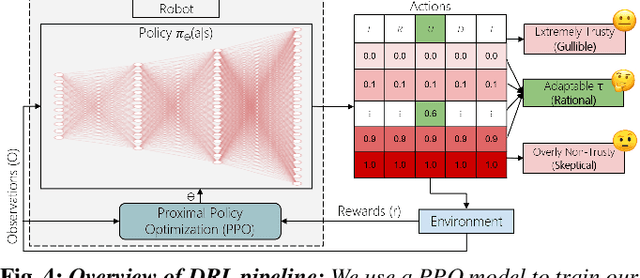
Humans are known to construct cognitive maps of their everyday surroundings using a variety of perceptual inputs. As such, when a human is asked for directions to a particular location, their wayfinding capability in converting this cognitive map into directional instructions is challenged. Owing to spatial anxiety, the language used in the spoken instructions can be vague and often unclear. To account for this unreliability in navigational guidance, we propose a novel Deep Reinforcement Learning (DRL) based trust-driven robot navigation algorithm that learns humans' trustworthiness to perform a language guided navigation task. Our approach seeks to answer the question as to whether a robot can trust a human's navigational guidance or not. To this end, we look at training a policy that learns to navigate towards a goal location using only trustworthy human guidance, driven by its own robot trust metric. We look at quantifying various affective features from language-based instructions and incorporate them into our policy's observation space in the form of a human trust metric. We utilize both these trust metrics into an optimal cognitive reasoning scheme that decides when and when not to trust the given guidance. Our results show that the learned policy can navigate the environment in an optimal, time-efficient manner as opposed to an explorative approach that performs the same task. We showcase the efficacy of our results both in simulation and a real-world environment.