 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Provable Acceleration of Neural Net Training via Polyak's Momentum
Oct 04, 2020
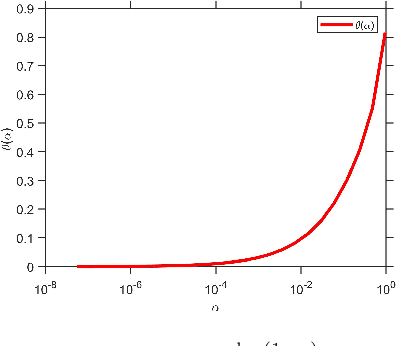
Incorporating a so-called "momentum" dynamic in gradient descent methods is widely used in neural net training as it has been broadly observed that, at least empirically, it often leads to significantly faster convergence. At the same time, there are very few theoretical guarantees in the literature to explain this apparent acceleration effect. In this paper we show that Polyak's momentum, in combination with over-parameterization of the model, helps achieve faster convergence in training a one-layer ReLU network on $n$ examples. We show specifically that gradient descent with Polyak's momentum decreases the initial training error at a rate much faster than that of vanilla gradient descent. We provide a bound for a fixed sample size $n$, and we show that gradient descent with Polyak's momentum converges at an accelerated rate to a small error that is controllable by the number of neurons $m$. Prior work [DZPS19] showed that using vanilla gradient descent, and with a similar method of over-parameterization, the error decays as $(1-\kappa_n)^t$ after $t$ iterations, where $\kappa_n$ is a problem-specific parameter. Our result shows that with the appropriate choice of parameters one has a rate of $(1-\sqrt{\kappa_n})^t$. This work establishes that momentum does indeed speed up neural net training.
Legal Document Classification: An Application to Law Area Prediction of Petitions to Public Prosecution Service
Oct 13, 2020
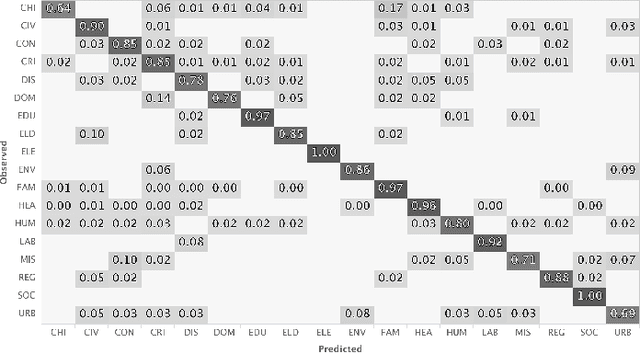
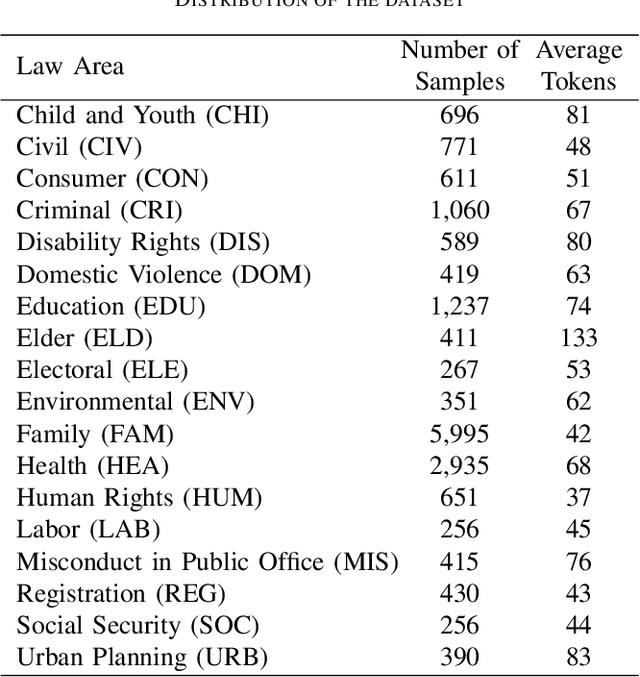
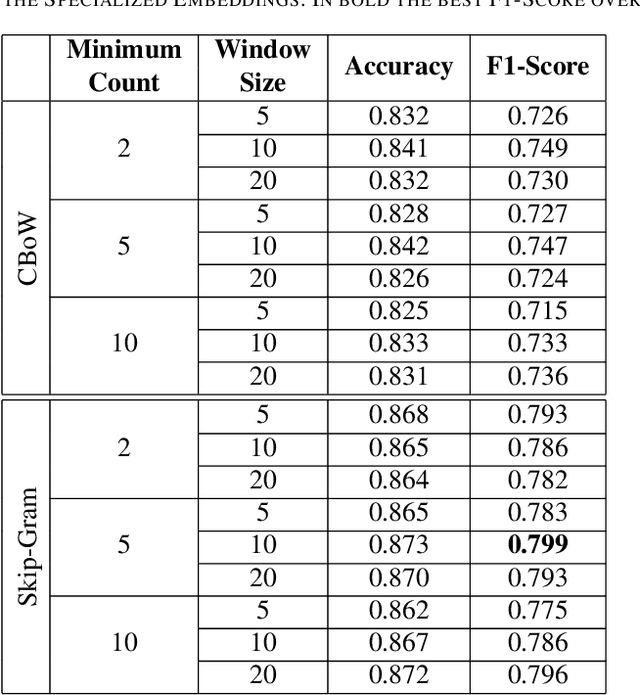
In recent years, there has been an increased interest in the application of Natural Language Processing (NLP) to legal documents. The use of convolutional and recurrent neural networks along with word embedding techniques have presented promising results when applied to textual classification problems, such as sentiment analysis and topic segmentation of documents. This paper proposes the use of NLP techniques for textual classification, with the purpose of categorizing the descriptions of the services provided by the Public Prosecutor's Office of the State of Paran\'a to the population in one of the areas of law covered by the institution. Our main goal is to automate the process of assigning petitions to their respective areas of law, with a consequent reduction in costs and time associated with such process while allowing the allocation of human resources to more complex tasks. In this paper, we compare different approaches to word representations in the aforementioned task: including document-term matrices and a few different word embeddings. With regards to the classification models, we evaluated three different families: linear models, boosted trees and neural networks. The best results were obtained with a combination of Word2Vec trained on a domain-specific corpus and a Recurrent Neural Network (RNN) architecture (more specifically, LSTM), leading to an accuracy of 90\% and F1-Score of 85\% in the classification of eighteen categories (law areas).
Satellite Image Classification with Deep Learning
Oct 13, 2020
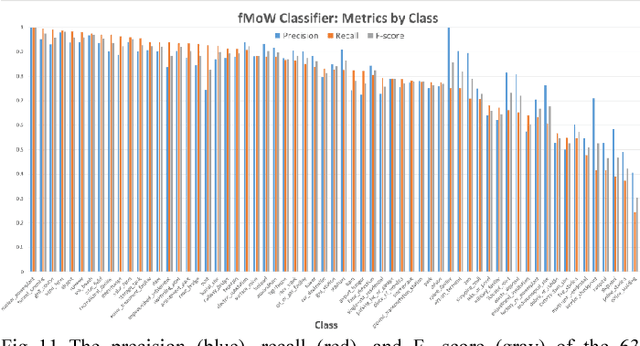
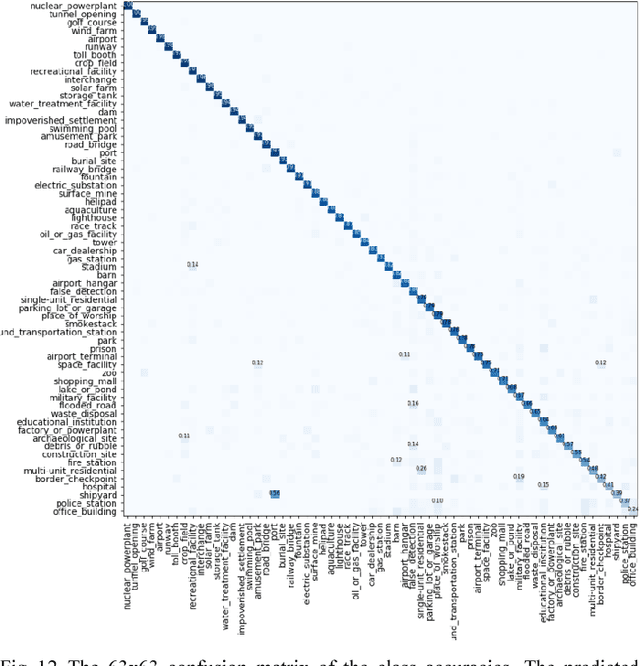

Satellite imagery is important for many applications including disaster response, law enforcement, and environmental monitoring. These applications require the manual identification of objects and facilities in the imagery. Because the geographic expanses to be covered are great and the analysts available to conduct the searches are few, automation is required. Yet traditional object detection and classification algorithms are too inaccurate and unreliable to solve the problem. Deep learning is a family of machine learning algorithms that have shown promise for the automation of such tasks. It has achieved success in image understanding by means of convolutional neural networks. In this paper we apply them to the problem of object and facility recognition in high-resolution, multi-spectral satellite imagery. We describe a deep learning system for classifying objects and facilities from the IARPA Functional Map of the World (fMoW) dataset into 63 different classes. The system consists of an ensemble of convolutional neural networks and additional neural networks that integrate satellite metadata with image features. It is implemented in Python using the Keras and TensorFlow deep learning libraries and runs on a Linux server with an NVIDIA Titan X graphics card. At the time of writing the system is in 2nd place in the fMoW TopCoder competition. Its total accuracy is 83%, the F1 score is 0.797, and it classifies 15 of the classes with accuracies of 95% or better.
* 7 pages, 18 figures, 2017 IEEE Applied Imagery Pattern Recognition Workshop (AIPR)
Gaussianizing the Earth: Multidimensional Information Measures for Earth Data Analysis
Oct 13, 2020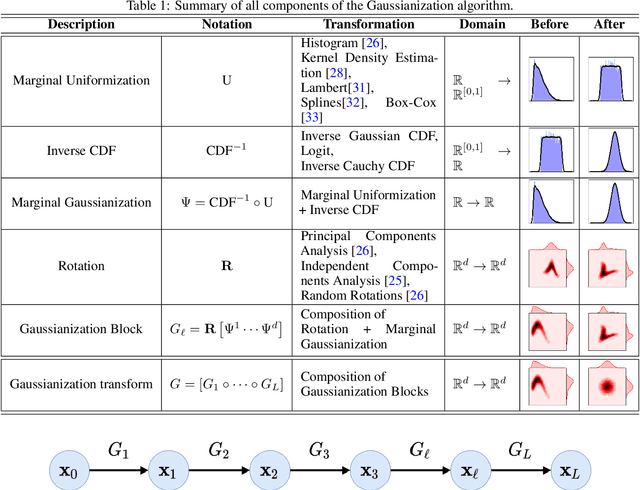
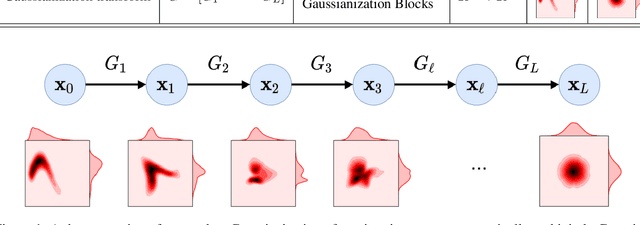
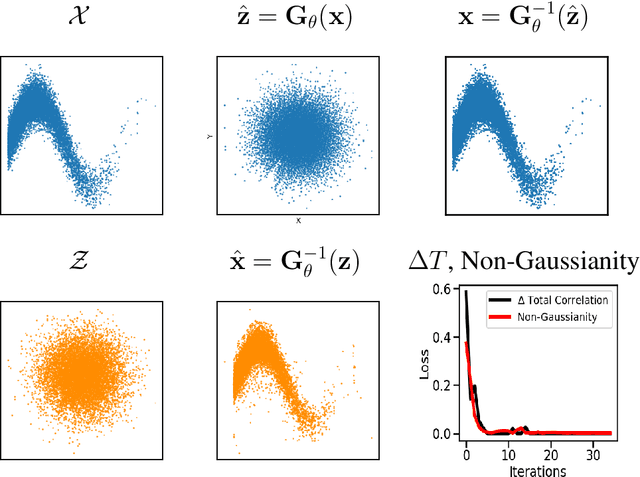
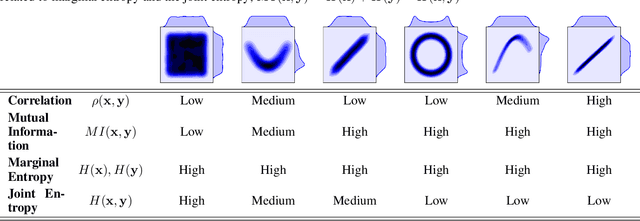
Information theory is an excellent framework for analyzing Earth system data because it allows us to characterize uncertainty and redundancy, and is universally interpretable. However, accurately estimating information content is challenging because spatio-temporal data is high-dimensional, heterogeneous and has non-linear characteristics. In this paper, we apply multivariate Gaussianization for probability density estimation which is robust to dimensionality, comes with statistical guarantees, and is easy to apply. In addition, this methodology allows us to estimate information-theoretic measures to characterize multivariate densities: information, entropy, total correlation, and mutual information. We demonstrate how information theory measures can be applied in various Earth system data analysis problems. First we show how the method can be used to jointly Gaussianize radar backscattering intensities, synthesize hyperspectral data, and quantify of information content in aerial optical images. We also quantify the information content of several variables describing the soil-vegetation status in agro-ecosystems, and investigate the temporal scales that maximize their shared information under extreme events such as droughts. Finally, we measure the relative information content of space and time dimensions in remote sensing products and model simulations involving long records of key variables such as precipitation, sensible heat and evaporation. Results confirm the validity of the method, for which we anticipate a wide use and adoption. Code and demos of the implemented algorithms and information-theory measures are provided.
Visual Memorability for Robotic Interestingness via Unsupervised Online Learning
May 19, 2020
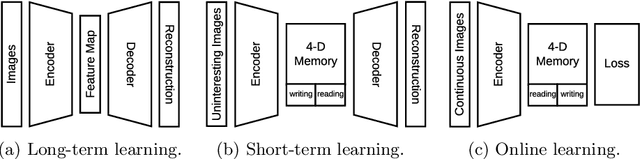
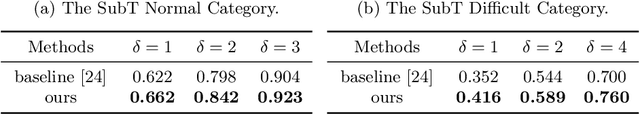
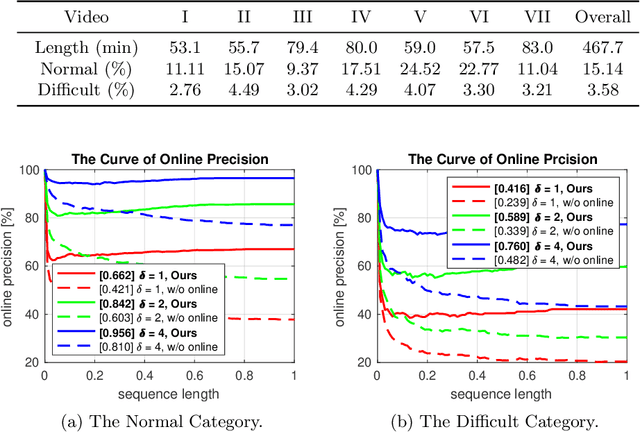
In this paper, we aim to solve the problem of interesting scene prediction for mobile robots. This area is currently under explored but is crucial for many practical applications such as autonomous exploration and decision making. First, we expect a robot to detect novel and interesting scenes in unknown environments and lose interests over time after repeatedly observing similar objects. Second, we expect the robots to learn from unbalanced data in a short time, as the robots normally only know the uninteresting scenes before they are deployed. Inspired by those industrial demands, we first propose a novel translation-invariant visual memory for recalling and identifying interesting scenes, then design a three-stage architecture of long-term, short-term, and online learning for human-like experience, environmental knowledge, and online adaption, respectively. It is demonstrated that our approach is able to learn online and find interesting scenes for practical exploration tasks. It also achieves a much higher accuracy than the state-of-the-art algorithm on very challenging robotic interestingness prediction datasets.
TwinBERT: Distilling Knowledge to Twin-Structured BERT Models for Efficient Retrieval
Feb 14, 2020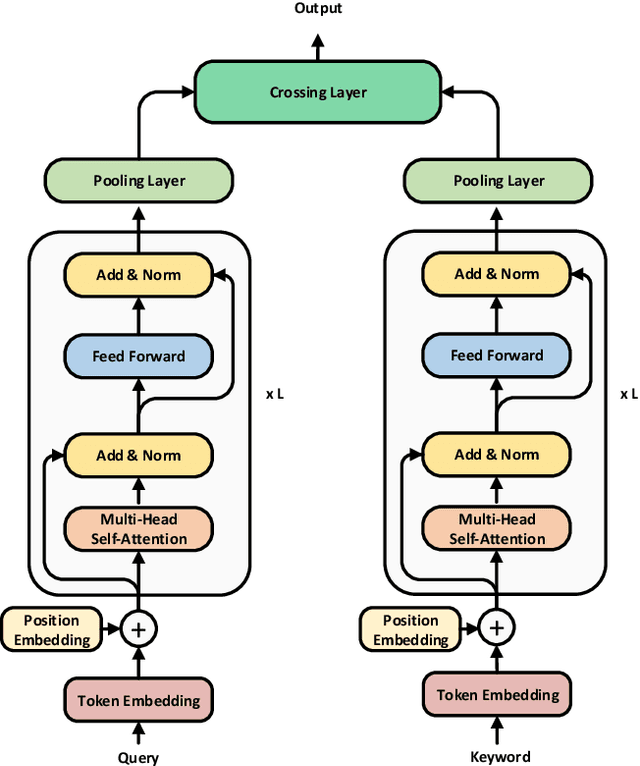
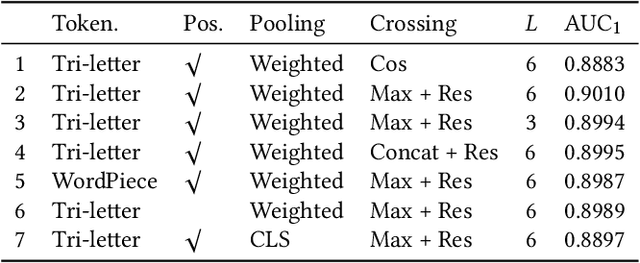
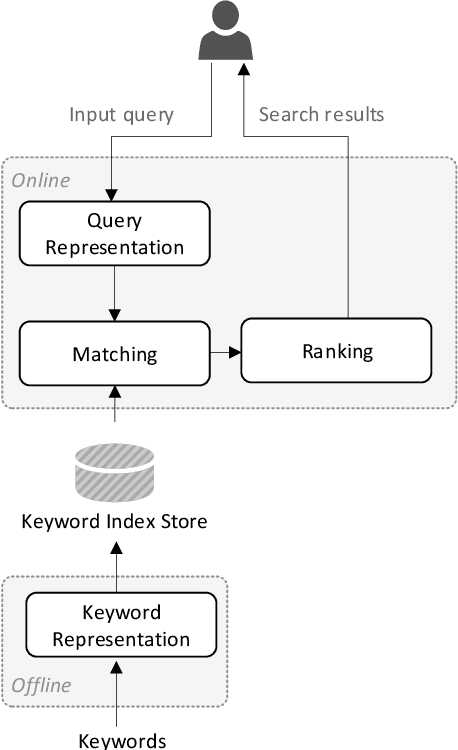
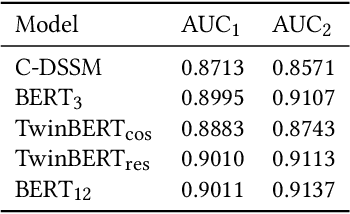
Pre-trained language models like BERT have achieved great success in a wide variety of NLP tasks, while the superior performance comes with high demand in computational resources, which hinders the application in low-latency IR systems. We present TwinBERT model for effective and efficient retrieval, which has twin-structured BERT-like encoders to represent query and document respectively and a crossing layer to combine the embeddings and produce a similarity score. Different from BERT, where the two input sentences are concatenated and encoded together, TwinBERT decouples them during encoding and produces the embeddings for query and document independently, which allows document embeddings to be pre-computed offline and cached in memory. Thereupon, the computation left for run-time is from the query encoding and query-document crossing only. This single change can save large amount of computation time and resources, and therefore significantly improve serving efficiency. Moreover, a few well-designed network layers and training strategies are proposed to further reduce computational cost while at the same time keep the performance as remarkable as BERT model. Lastly, we develop two versions of TwinBERT for retrieval and relevance tasks correspondingly, and both of them achieve close or on-par performance to BERT-Base model. The model was trained following the teacher-student framework and evaluated with data from one of the major search engines. Experimental results showed that the inference time was significantly reduced and was firstly controlled around 20ms on CPUs while at the same time the performance gain from fine-tuned BERT-Base model was mostly retained. Integration of the models into production systems also demonstrated remarkable improvements on relevance metrics with negligible influence on latency.
k-Nearest Neighbour Classifiers: 2nd Edition (with Python examples)
Apr 29, 2020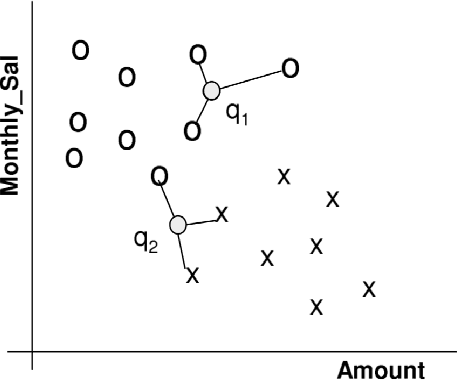
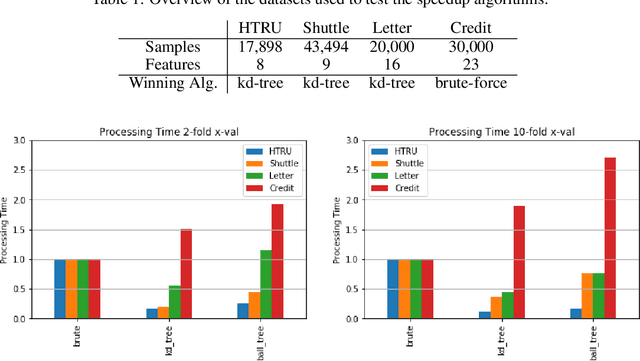
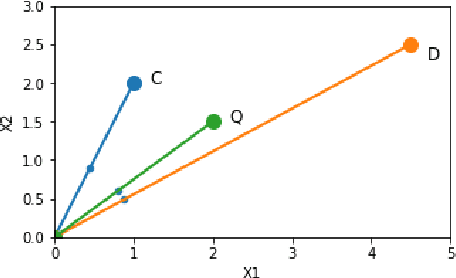
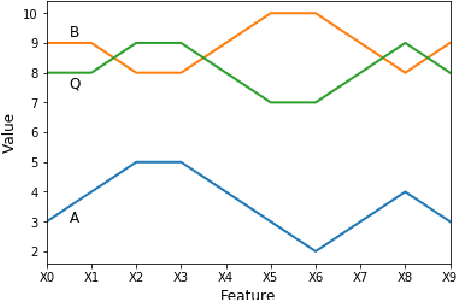
Perhaps the most straightforward classifier in the arsenal or machine learning techniques is the Nearest Neighbour Classifier -- classification is achieved by identifying the nearest neighbours to a query example and using those neighbours to determine the class of the query. This approach to classification is of particular importance because issues of poor run-time performance is not such a problem these days with the computational power that is available. This paper presents an overview of techniques for Nearest Neighbour classification focusing on; mechanisms for assessing similarity (distance), computational issues in identifying nearest neighbours and mechanisms for reducing the dimension of the data. This paper is the second edition of a paper previously published as a technical report. Sections on similarity measures for time-series, retrieval speed-up and intrinsic dimensionality have been added. An Appendix is included providing access to Python code for the key methods.
Real-time Decolorization using Dominant Colors
Apr 22, 2014Decolorization is the process to convert a color image or video to its grayscale version, and it has received great attention in recent years. An ideal decolorization algorithm should preserve the original color contrast as much as possible. Meanwhile, it should provide the final decolorized result as fast as possible. However, most of the current methods are suffering from either unsatisfied color information preservation or high computational cost, limiting their application value. In this paper, a simple but effective technique is proposed for real-time decolorization. Based on the typical rgb2gray() color conversion model, which produces a grayscale image by linearly combining R, G, and B channels, we propose a dominant color hypothesis and a corresponding distance measurement metric to evaluate the quality of grayscale conversion. The local optimum scheme provides several "good" candidates in a confidence interval, from which the "best" result can be extracted. Experimental results demonstrate that remarkable simplicity of the proposed method facilitates the process of high resolution images and videos in real-time using a common CPU.
Automatic Assignment of Radiology Examination Protocols Using Pre-trained Language Models with Knowledge Distillation
Sep 01, 2020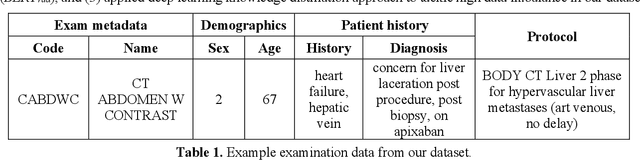
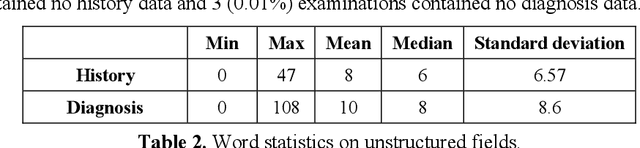
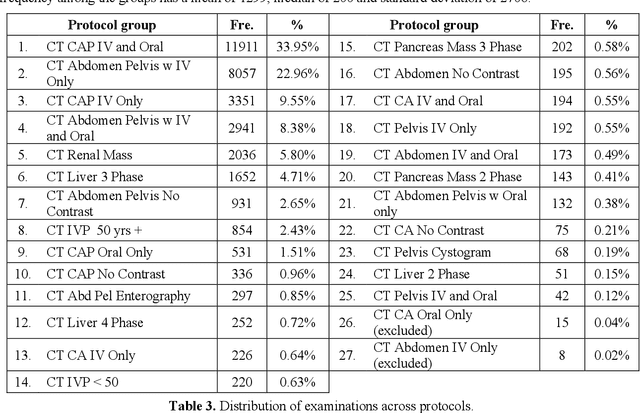
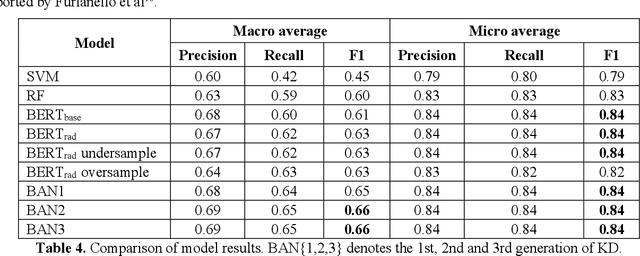
Selecting radiology examination protocol is a repetitive, error-prone, and time-consuming process. In this paper, we present a deep learning approach to automatically assign protocols to computer tomography examinations, by pre-training a domain-specific BERT model ($BERT_{rad}$). To handle the high data imbalance across exam protocols, we used a knowledge distillation approach that up-sampled the minority classes through data augmentation. We compared classification performance of the described approach with the statistical n-gram models using Support Vector Machine (SVM) and Random Forest (RF) classifiers, as well as the Google's $BERT_{base}$ model. SVM and RF achieved macro-averaged F1 scores of 0.45 and 0.6 while $BERT_{base}$ and $BERT_{rad}$ achieved 0.61 and 0.63. Knowledge distillation improved overall performance on the minority classes, achieving a F1 score of 0.66. Additionally, by choosing the optimal threshold, the BERT models could classify over 50% of test samples within 5% error rate and potentially alleviate half of radiologist protocoling workload.
Probabilistic Spatial Transformers for Bayesian Data Augmentation
Apr 07, 2020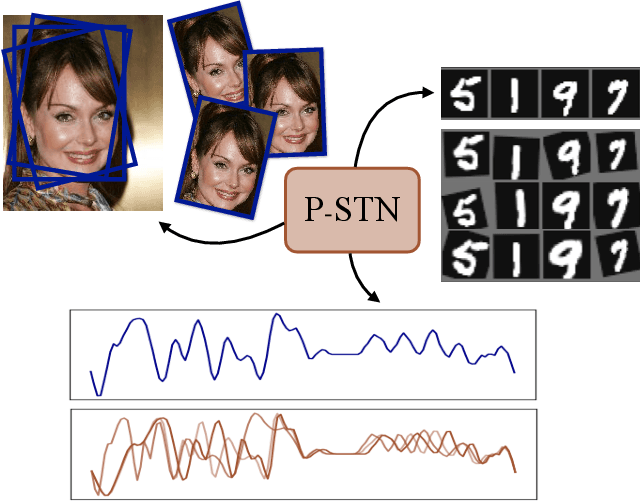
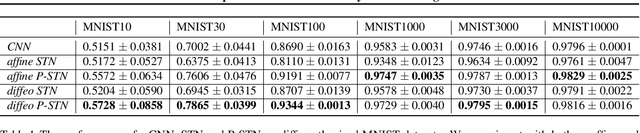
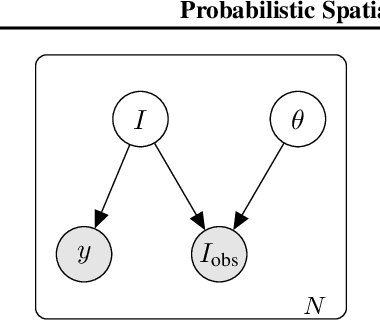

High-capacity models require vast amounts of data, and data augmentation is a common remedy when this resource is limited. Standard augmentation techniques apply small hand-tuned transformations to existing data, which is a brittle process that realistically only allows for simple transformations. We propose a Bayesian interpretation of data augmentation where the transformations are modelled as latent variables to be marginalized, and show how these can be inferred variationally in an end-to-end fashion. This allows for significantly more complex transformations than manual tuning, and the marginalization implies a form of test-time data augmentation. The resulting model can be interpreted as a probabilistic extension of spatial transformer networks. Experimentally, we demonstrate improvements in accuracy and uncertainty quantification in image and time series classification tasks.