 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time Autonomous Control of a Continuous Macroscopic Process as Demonstrated by Plastic Forming
Dec 14, 2023
To meet the demands for more adaptable and expedient approaches to augment both research and manufacturing, we report an autonomous system using real-time in-situ characterization and an autonomous, decision-making processer based on an active learning algorithm. This system was applied to a plastic film forming system to highlight its efficiency and accuracy in determining the process conditions for specified target film dimensions, importantly, without any human intervention. Application of this system towards nine distinct film dimensions demonstrated the system ability to quickly determine the appropriate and stable process conditions (average 11 characterization-adjustment iterations, 19 minutes) and the ability to avoid traps, such as repetitive over-correction. Furthermore, comparison of the achieved film dimensions to the target values showed a high accuracy (R2 = 0.87, 0.90) for film width and thickness, respectively. In addition, the use of an active learning algorithm afforded our system to proceed optimization with zero initial training data, which was unavailable due to the complex relationships between the control factors (material supply rate, applied force, material viscosity) within the plastic forming process. As our system is intrinsically general and can be applied to any most material processes, these results have significant implications in accelerating both research and industrial processes.
SeqNAS: Neural Architecture Search for Event Sequence Classification
Jan 06, 2024Neural Architecture Search (NAS) methods are widely used in various industries to obtain high quality taskspecific solutions with minimal human intervention. Event Sequences find widespread use in various industrial applications including churn prediction customer segmentation fraud detection and fault diagnosis among others. Such data consist of categorical and real-valued components with irregular timestamps. Despite the usefulness of NAS methods previous approaches only have been applied to other domains images texts or time series. Our work addresses this limitation by introducing a novel NAS algorithm SeqNAS specifically designed for event sequence classification. We develop a simple yet expressive search space that leverages commonly used building blocks for event sequence classification including multihead self attention convolutions and recurrent cells. To perform the search we adopt sequential Bayesian Optimization and utilize previously trained models as an ensemble of teachers to augment knowledge distillation. As a result of our work we demonstrate that our method surpasses state of the art NAS methods and popular architectures suitable for sequence classification and holds great potential for various industrial applications.
Learning Persistent Community Structures in Dynamic Networks via Topological Data Analysis
Jan 06, 2024Dynamic community detection methods often lack effective mechanisms to ensure temporal consistency, hindering the analysis of network evolution. In this paper, we propose a novel deep graph clustering framework with temporal consistency regularization on inter-community structures, inspired by the concept of minimal network topological changes within short intervals. Specifically, to address the representation collapse problem, we first introduce MFC, a matrix factorization-based deep graph clustering algorithm that preserves node embedding. Based on static clustering results, we construct probabilistic community networks and compute their persistence homology, a robust topological measure, to assess structural similarity between them. Moreover, a novel neural network regularization TopoReg is introduced to ensure the preservation of topological similarity between inter-community structures over time intervals. Our approach enhances temporal consistency and clustering accuracy on real-world datasets with both fixed and varying numbers of communities. It is also a pioneer application of TDA in temporally persistent community detection, offering an insightful contribution to field of network analysis. Code and data are available at the public git repository: https://github.com/kundtx/MFC_TopoReg
Spiking Neural Networks with Dynamic Time Steps for Vision Transformers
Nov 28, 2023Spiking Neural Networks (SNNs) have emerged as a popular spatio-temporal computing paradigm for complex vision tasks. Recently proposed SNN training algorithms have significantly reduced the number of time steps (down to 1) for improved latency and energy efficiency, however, they target only convolutional neural networks (CNN). These algorithms, when applied on the recently spotlighted vision transformers (ViT), either require a large number of time steps or fail to converge. Based on analysis of the histograms of the ANN and SNN activation maps, we hypothesize that each ViT block has a different sensitivity to the number of time steps. We propose a novel training framework that dynamically allocates the number of time steps to each ViT module depending on a trainable score assigned to each timestep. In particular, we generate a scalar binary time step mask that filters spikes emitted by each neuron in a leaky-integrate-and-fire (LIF) layer. The resulting SNNs have high activation sparsity and require only accumulate operations (AC), except for the input embedding layer, in contrast to expensive multiply-and-accumulates (MAC) needed in traditional ViTs. This yields significant improvements in energy efficiency. We evaluate our training framework and resulting SNNs on image recognition tasks including CIFAR10, CIFAR100, and ImageNet with different ViT architectures. We obtain a test accuracy of 95.97% with 4.97 time steps with direct encoding on CIFAR10.
Deep learning-based estimation of time-dependent parameters in Markov models with application to nonlinear regression and SDEs
Dec 13, 2023We present a novel deep learning method for estimating time-dependent parameters in Markov processes through discrete sampling. Departing from conventional machine learning, our approach reframes parameter approximation as an optimization problem using the maximum likelihood approach. Experimental validation focuses on parameter estimation in multivariate regression and stochastic differential equations (SDEs). Theoretical results show that the real solution is close to SDE with parameters approximated using our neural network-derived under specific conditions. Our work contributes to SDE-based model parameter estimation, offering a versatile tool for diverse fields.
Evolution of urban areas and land surface temperature
Jan 05, 2024With the global population on the rise, our cities have been expanding to accommodate the growing number of people. The expansion of cities generally leads to the engulfment of peripheral areas. However, such expansion of urban areas is likely to cause increment in areas with increased land surface temperature (LST). By considering each summer as a data point, we form LST multi-year time-series and cluster it to obtain spatio-temporal pattern. We observe several interesting phenomena from these patterns, e.g., some clusters show reasonable similarity to the built-up area, whereas the locations with high temporal variation are seen more in the peripheral areas. Furthermore, the LST center of mass shifts over the years for cities with development activities tilted towards a direction. We conduct the above-mentioned studies for three different cities in three different continents.
FedNS: A Fast Sketching Newton-Type Algorithm for Federated Learning
Jan 05, 2024Recent Newton-type federated learning algorithms have demonstrated linear convergence with respect to the communication rounds. However, communicating Hessian matrices is often unfeasible due to their quadratic communication complexity. In this paper, we introduce a novel approach to tackle this issue while still achieving fast convergence rates. Our proposed method, named as Federated Newton Sketch methods (FedNS), approximates the centralized Newton's method by communicating the sketched square-root Hessian instead of the exact Hessian. To enhance communication efficiency, we reduce the sketch size to match the effective dimension of the Hessian matrix. We provide convergence analysis based on statistical learning for the federated Newton sketch approaches. Specifically, our approaches reach super-linear convergence rates w.r.t. the communication rounds for the first time. We validate the effectiveness of our algorithms through various experiments, which coincide with our theoretical findings.
Message Feedback Interference Cancellation Aided UAMP Iterative Detector for OTFS Systems
Jan 05, 2024The designing of efficient signal detectors is important and yet challenge for orthogonal time frequency space (OTFS) systems in high-mobility scenarios. In this letter, we develop an efficient message feedback interference cancellation aided unitary approximate message passing (denoted as UAMPMFIC) iterative detector, where the latest feedback messages from variable nodes are utilized for more reliable interference cancellation and performance improvement. A fast recursive scheme is leveraged in the proposed UAMP-MFIC detector to prevent complexity increasing. To further alleviate the error-propagation and improve the receiver performance, we also develop the bidirectional symbol detection structures, where Turbo UAMP-MFIC detector and iterative weight UAMP-MFIC detector are proposed to efficiently fuse the estimation results of forward and backward UAMP-MFIC detectors. The simulation results are finally provided to demonstrate performance improvement of our proposed detectors over existing detectors.
Underwater Acoustic Signal Recognition Based on Salient Feature
Jan 05, 2024With the rapid advancement of technology, the recognition of underwater acoustic signals in complex environments has become increasingly crucial. Currently, mainstream underwater acoustic signal recognition relies primarily on time-frequency analysis to extract spectral features, finding widespread applications in the field. However, existing recognition methods heavily depend on expert systems, facing limitations such as restricted knowledge bases and challenges in handling complex relationships. These limitations stem from the complexity and maintenance difficulties associated with rules or inference engines. Recognizing the potential advantages of deep learning in handling intricate relationships, this paper proposes a method utilizing neural networks for underwater acoustic signal recognition. The proposed approach involves continual learning of features extracted from spectra for the classification of underwater acoustic signals. Deep learning models can automatically learn abstract features from data and continually adjust weights during training to enhance classification performance.
FlopPITy: Enabling self-consistent exoplanet atmospheric retrievals with machine learning
Jan 08, 2024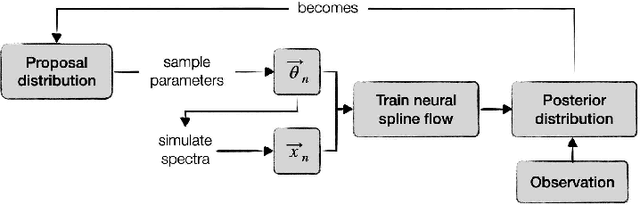
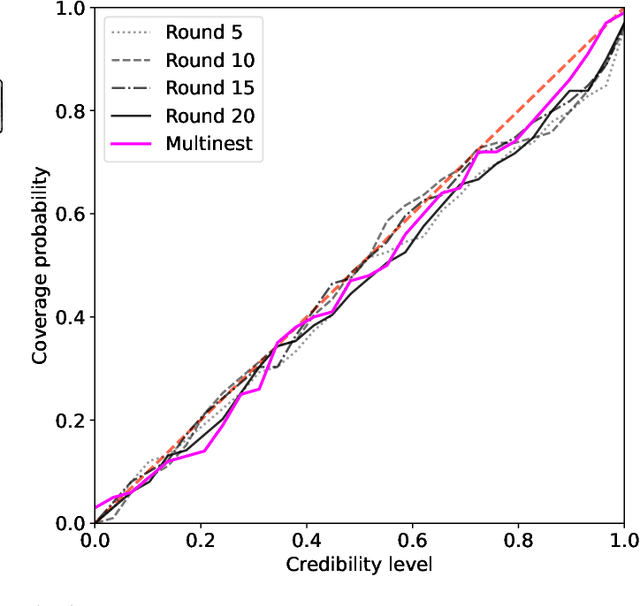
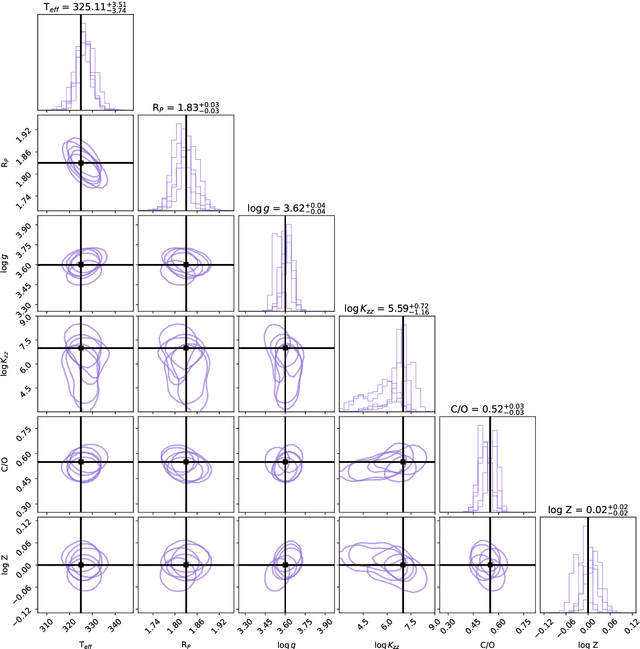
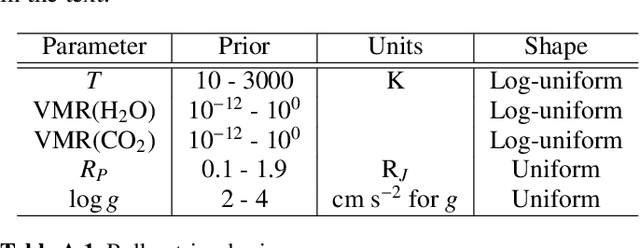
Interpreting the observations of exoplanet atmospheres to constrain physical and chemical properties is typically done using Bayesian retrieval techniques. Because these methods require many model computations, a compromise is made between model complexity and run time. Reaching this compromise leads to the simplification of many physical and chemical processes (e.g. parameterised temperature structure). Here we implement and test sequential neural posterior estimation (SNPE), a machine learning inference algorithm, for exoplanet atmospheric retrievals. The goal is to speed up retrievals so they can be run with more computationally expensive atmospheric models, such as those computing the temperature structure using radiative transfer. We generate 100 synthetic observations using ARCiS (ARtful Modeling Code for exoplanet Science, an atmospheric modelling code with the flexibility to compute models in varying degrees of complexity) and perform retrievals on them to test the faithfulness of the SNPE posteriors. The faithfulness quantifies whether the posteriors contain the ground truth as often as we expect. We also generate a synthetic observation of a cool brown dwarf using the self-consistent capabilities of ARCiS and run a retrieval with self-consistent models to showcase the possibilities that SNPE opens. We find that SNPE provides faithful posteriors and is therefore a reliable tool for exoplanet atmospheric retrievals. We are able to run a self-consistent retrieval of a synthetic brown dwarf spectrum using only 50,000 forward model evaluations. We find that SNPE can speed up retrievals between $\sim2\times$ and $\geq10\times$ depending on the computational load of the forward model, the dimensionality of the observation, and the signal-to-noise ratio of the observation. We make the code publicly available for the community on Github.