 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Shuffling Recurrent Neural Networks
Jul 14, 2020
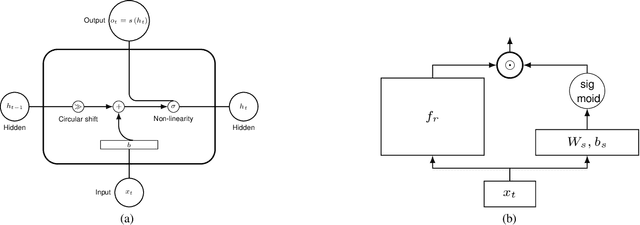

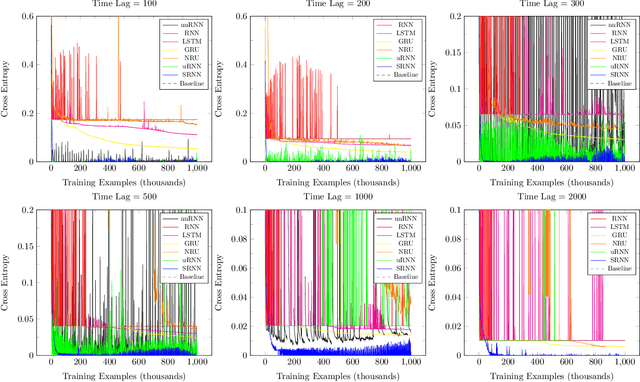
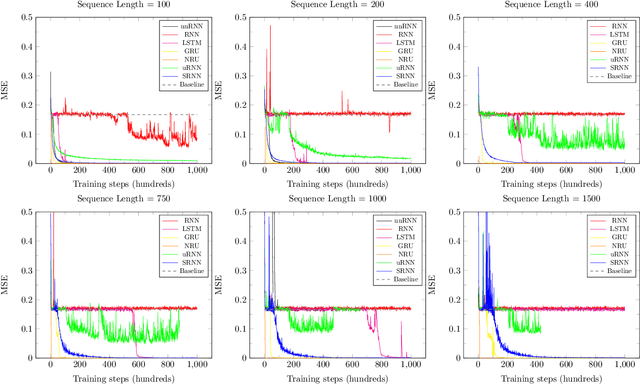
We propose a novel recurrent neural network model, where the hidden state $h_t$ is obtained by permuting the vector elements of the previous hidden state $h_{t-1}$ and adding the output of a learned function $b(x_t)$ of the input $x_t$ at time $t$. In our model, the prediction is given by a second learned function, which is applied to the hidden state $s(h_t)$. The method is easy to implement, extremely efficient, and does not suffer from vanishing nor exploding gradients. In an extensive set of experiments, the method shows competitive results, in comparison to the leading literature baselines.
TorchCraft: a Library for Machine Learning Research on Real-Time Strategy Games
Nov 03, 2016
We present TorchCraft, a library that enables deep learning research on Real-Time Strategy (RTS) games such as StarCraft: Brood War, by making it easier to control these games from a machine learning framework, here Torch. This white paper argues for using RTS games as a benchmark for AI research, and describes the design and components of TorchCraft.
Fastfood: Approximate Kernel Expansions in Loglinear Time
Aug 13, 2014
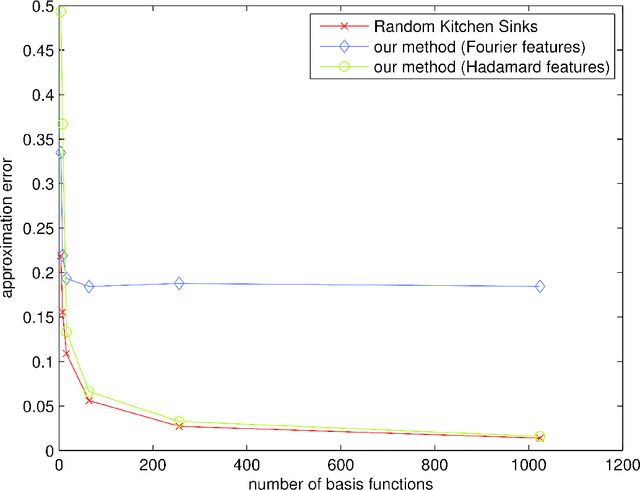
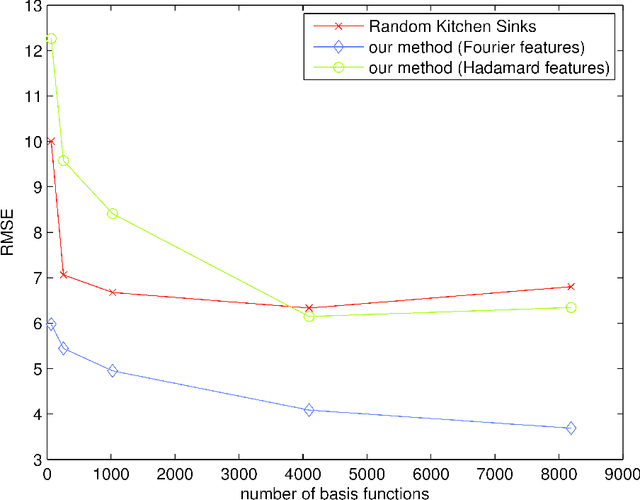
Despite their successes, what makes kernel methods difficult to use in many large scale problems is the fact that storing and computing the decision function is typically expensive, especially at prediction time. In this paper, we overcome this difficulty by proposing Fastfood, an approximation that accelerates such computation significantly. Key to Fastfood is the observation that Hadamard matrices, when combined with diagonal Gaussian matrices, exhibit properties similar to dense Gaussian random matrices. Yet unlike the latter, Hadamard and diagonal matrices are inexpensive to multiply and store. These two matrices can be used in lieu of Gaussian matrices in Random Kitchen Sinks proposed by Rahimi and Recht (2009) and thereby speeding up the computation for a large range of kernel functions. Specifically, Fastfood requires O(n log d) time and O(n) storage to compute n non-linear basis functions in d dimensions, a significant improvement from O(nd) computation and storage, without sacrificing accuracy. Our method applies to any translation invariant and any dot-product kernel, such as the popular RBF kernels and polynomial kernels. We prove that the approximation is unbiased and has low variance. Experiments show that we achieve similar accuracy to full kernel expansions and Random Kitchen Sinks while being 100x faster and using 1000x less memory. These improvements, especially in terms of memory usage, make kernel methods more practical for applications that have large training sets and/or require real-time prediction.
CLEANN: Accelerated Trojan Shield for Embedded Neural Networks
Sep 04, 2020
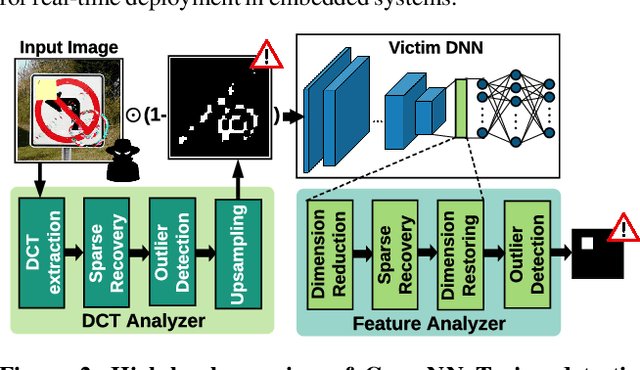

We propose CLEANN, the first end-to-end framework that enables online mitigation of Trojans for embedded Deep Neural Network (DNN) applications. A Trojan attack works by injecting a backdoor in the DNN while training; during inference, the Trojan can be activated by the specific backdoor trigger. What differentiates CLEANN from the prior work is its lightweight methodology which recovers the ground-truth class of Trojan samples without the need for labeled data, model retraining, or prior assumptions on the trigger or the attack. We leverage dictionary learning and sparse approximation to characterize the statistical behavior of benign data and identify Trojan triggers. CLEANN is devised based on algorithm/hardware co-design and is equipped with specialized hardware to enable efficient real-time execution on resource-constrained embedded platforms. Proof of concept evaluations on CLEANN for the state-of-the-art Neural Trojan attacks on visual benchmarks demonstrate its competitive advantage in terms of attack resiliency and execution overhead.
An Autonomous Reactive Architecture for Efficient AUV Mission Time Management in Realistic Severe Ocean Environment
Jun 15, 2016Today AUVs operation still remains restricted to very particular tasks with low real autonomy due to battery restrictions. Efficient motion planning and mission scheduling are principle requirement toward advance autonomy and facilitate the vehicle to handle long-range operations. A single vehicle cannot carry out all tasks in a large scale terrain; hence, it needs a certain degree of autonomy in performing robust decision making and awareness of the mission/environment to trade-off between tasks to be completed, managing the available time, and ensuring safe deployment at all stages of the mission. In this respect, this research introduces a modular control architecture including higher/lower level planners, in which the higher level module is responsible for increasing mission productivity by assigning prioritized tasks while guiding the vehicle toward its final destination in a terrain covered by several waypoints; and the lower level is responsible for vehicle's safe deployment in a smaller scale encountering time-varying ocean current and different uncertain static/moving obstacles similar to actual ocean environment. Synchronization between higher and lower level modules is efficiently configured to manage the mission time and to guarantee on-time termination of the mission. The performance and accuracy of two higher and lower level modules are tested and validated using ant colony and firefly optimization algorithm, respectively. After all, the overall performance of the architecture is investigated in 10 different mission scenarios. The analyze of the captured results from different simulated missions confirm the efficiency and inherent robustness of the introduced architecture in efficient time management, safe deployment, and providing beneficial operation by proper prioritizing the tasks in accordance with mission time.
On the Interplay Between Fine-tuning and Sentence-level Probing for Linguistic Knowledge in Pre-trained Transformers
Oct 06, 2020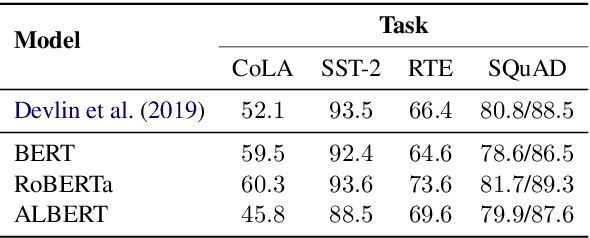
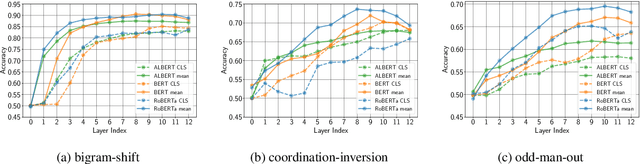
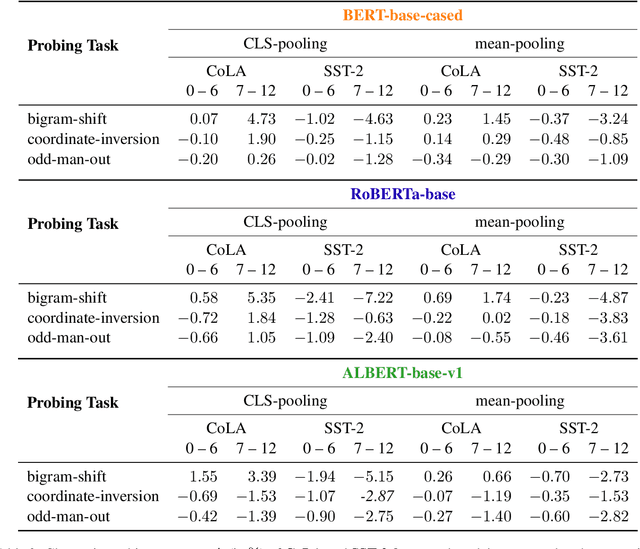
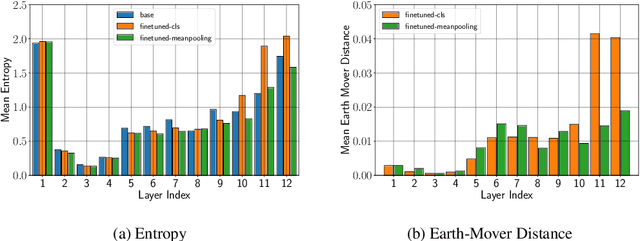
Fine-tuning pre-trained contextualized embedding models has become an integral part of the NLP pipeline. At the same time, probing has emerged as a way to investigate the linguistic knowledge captured by pre-trained models. Very little is, however, understood about how fine-tuning affects the representations of pre-trained models and thereby the linguistic knowledge they encode. This paper contributes towards closing this gap. We study three different pre-trained models: BERT, RoBERTa, and ALBERT, and investigate through sentence-level probing how fine-tuning affects their representations. We find that for some probing tasks fine-tuning leads to substantial changes in accuracy, possibly suggesting that fine-tuning introduces or even removes linguistic knowledge from a pre-trained model. These changes, however, vary greatly across different models, fine-tuning and probing tasks. Our analysis reveals that while fine-tuning indeed changes the representations of a pre-trained model and these changes are typically larger for higher layers, only in very few cases, fine-tuning has a positive effect on probing accuracy that is larger than just using the pre-trained model with a strong pooling method. Based on our findings, we argue that both positive and negative effects of fine-tuning on probing require a careful interpretation.
Classification of Huntington Disease using Acoustic and Lexical Features
Aug 07, 2020
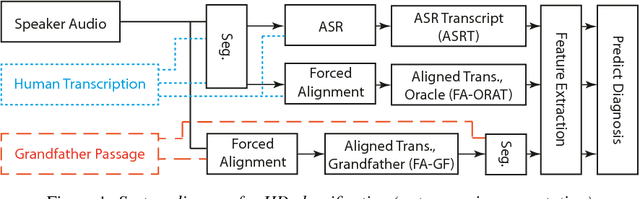

Speech is a critical biomarker for Huntington Disease (HD), with changes in speech increasing in severity as the disease progresses. Speech analyses are currently conducted using either transcriptions created manually by trained professionals or using global rating scales. Manual transcription is both expensive and time-consuming and global rating scales may lack sufficient sensitivity and fidelity. Ultimately, what is needed is an unobtrusive measure that can cheaply and continuously track disease progression. We present first steps towards the development of such a system, demonstrating the ability to automatically differentiate between healthy controls and individuals with HD using speech cues. The results provide evidence that objective analyses can be used to support clinical diagnoses, moving towards the tracking of symptomatology outside of laboratory and clinical environments.
Generative Adversarial Network for Radar Signal Generation
Aug 07, 2020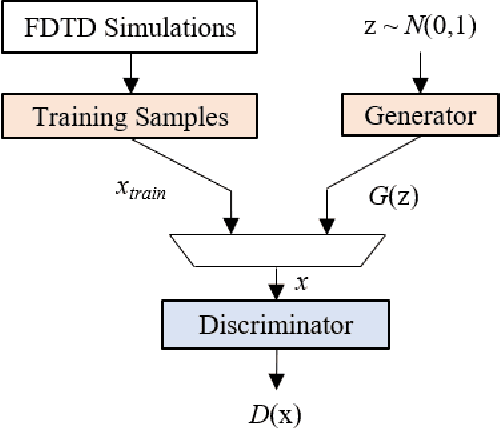
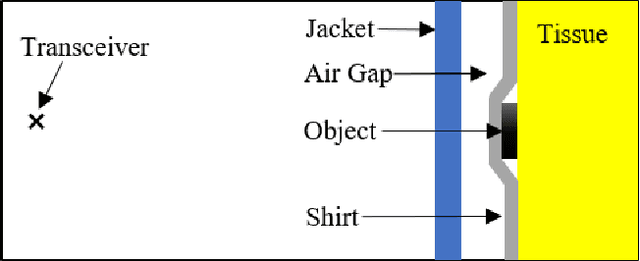
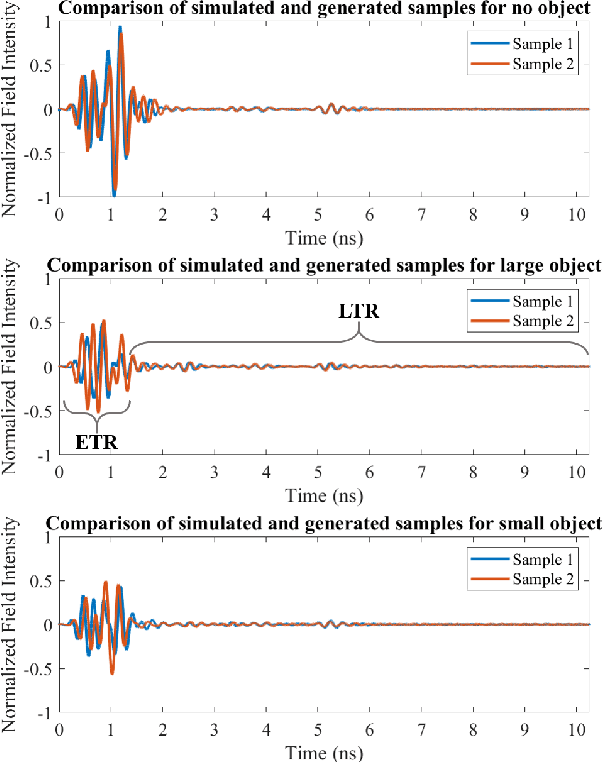
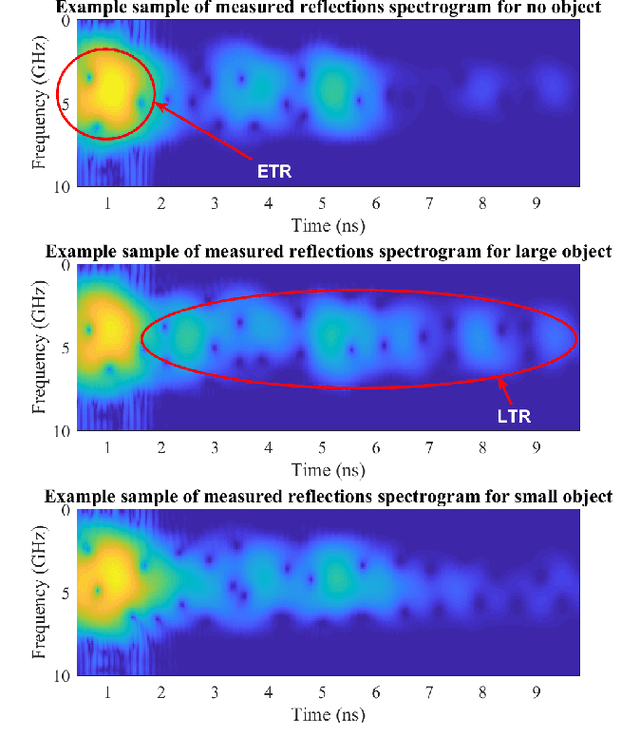
A major obstacle in radar based methods for concealed object detection on humans and seamless integration into security and access control system is the difficulty in collecting high quality radar signal data. Generative adversarial networks (GAN) have shown promise in data generation application in the fields of image and audio processing. As such, this paper proposes the design of a GAN for application in radar signal generation. Data collected using the Finite-Difference Time-Domain (FDTD) method on three concealed object classes (no object, large object, and small object) were used as training data to train a GAN to generate radar signal samples for each class. The proposed GAN generated radar signal data which was indistinguishable from the training data by qualitative human observers.
AE-Netv2: Optimization of Image Fusion Efficiency and Network Architecture
Oct 06, 2020
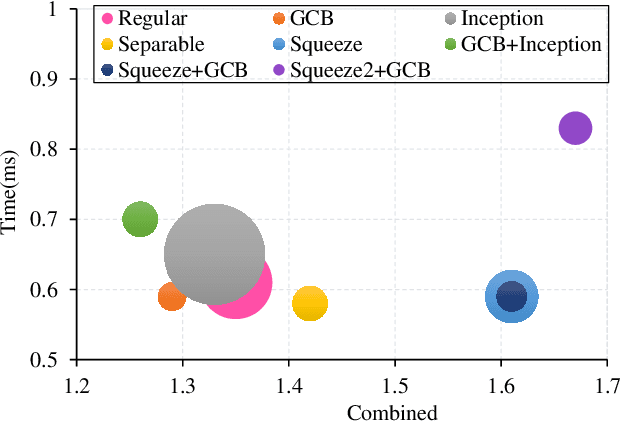

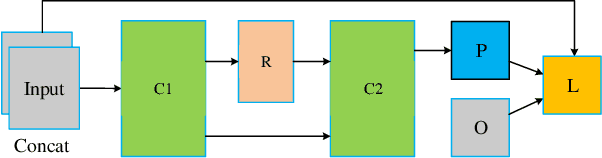
Existing image fusion methods pay few research attention to image fusion efficiency and network architecture. However, the efficiency and accuracy of image fusion has an important impact in practical applications. To solve this problem, we propose an \textit{efficient autonomous evolution image fusion method, dubed by AE-Netv2}. Different from other image fusion methods based on deep learning, AE-Netv2 is inspired by human brain cognitive mechanism. Firstly, we discuss the influence of different network architecture on image fusion quality and fusion efficiency, which provides a reference for the design of image fusion architecture. Secondly, we explore the influence of pooling layer on image fusion task and propose an image fusion method with pooling layer. Finally, we explore the commonness and characteristics of different image fusion tasks, which provides a research basis for further research on the continuous learning characteristics of human brain in the field of image fusion. Comprehensive experiments demonstrate the superiority of AE-Netv2 compared with state-of-the-art methods in different fusion tasks at a real time speed of 100+ FPS on GTX 2070. Among all tested methods based on deep learning, AE-Netv2 has the faster speed, the smaller model size and the better robustness.
Autonomous Navigation in Unknown Environments with Sparse Bayesian Kernel-based Occupancy Mapping
Sep 15, 2020
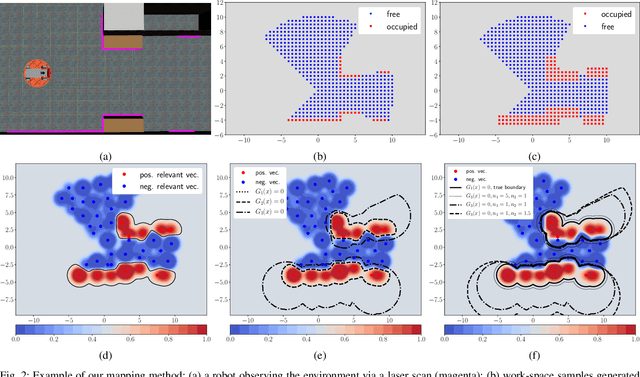
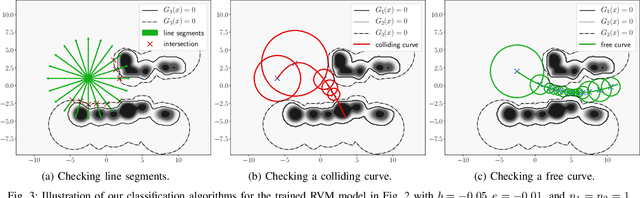

This paper focuses on online occupancy mapping and real-time collision checking onboard an autonomous robot navigating in a large unknown environment. Commonly used voxel and octree map representations can be easily maintained in a small environment but have increasing memory requirements as the environment grows. We propose a fundamentally different approach for occupancy mapping, in which the boundary between occupied and free space is viewed as the decision boundary of a machine learning classifier. This work generalizes a kernel perceptron model which maintains a very sparse set of support vectors to represent the environment boundaries efficiently. We develop a probabilistic formulation based on Relevance Vector Machines, allowing robustness to measurement noise and localization errors as well as probabilistic occupancy classification, supporting autonomous navigation. We provide an online training algorithm, updating the sparse Bayesian map incrementally from streaming range data, and an efficient collision-checking method for general curves, representing potential robot trajectories. The effectiveness of our mapping and collision checking algorithms is evaluated in tasks requiring autonomous robot navigation in unknown environments.