 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Follow-the-Leader Strategy using Hierarchical Deep Neural Networks with Grouped Convolutions
Nov 04, 2020
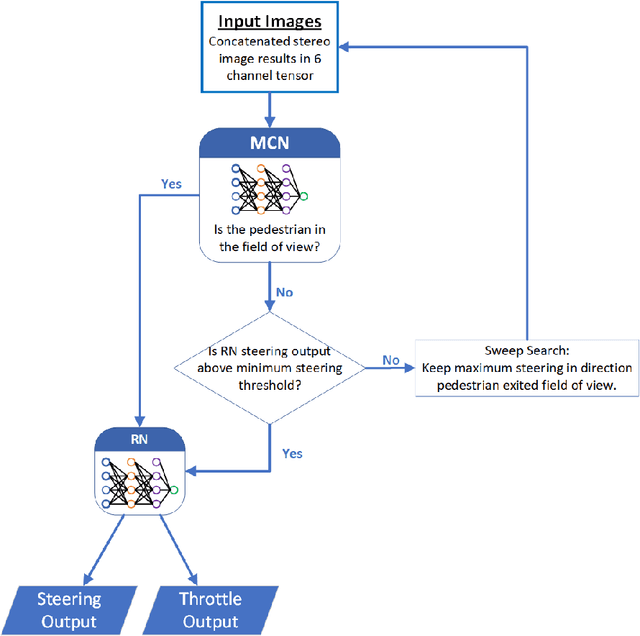
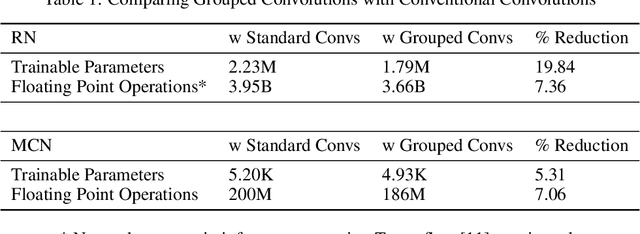
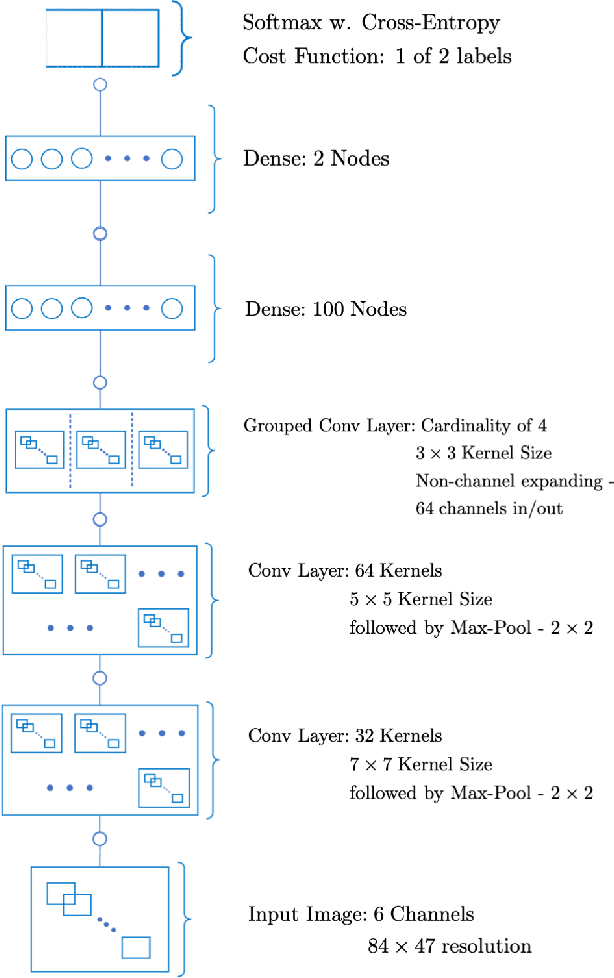

The task of following-the-leader is implemented using a hierarchical Deep Neural Network (DNN) end-to-end driving model to match the direction and speed of a target pedestrian. The model uses a classifier DNN to determine if the pedestrian is within the field of view of the camera sensor. If the pedestrian is present, the image stream from the camera is fed to a regression DNN which simultaneously adjusts the autonomous vehicle's steering and throttle to keep cadence with the pedestrian. If the pedestrian is not visible, the vehicle uses a straightforward exploratory search strategy to reacquire the tracking objective. The classifier and regression DNNs incorporate grouped convolutions to boost model performance as well as to significantly reduce parameter count and compute latency. The models are trained on the Intelligence Processing Unit (IPU) to leverage its fine-grain compute capabilities in order to minimize time-to-train. The results indicate very robust tracking behavior on the part of the autonomous vehicle in terms of its steering and throttle profiles, which required minimal data collection to produce. The throughput in terms of processing training samples has been boosted by the use of the IPU in conjunction with grouped convolutions by a factor ${\sim}3.5$ for training of the classifier and a factor of ${\sim}7$ for the regression network. A recording of the vehicle tracking a pedestrian has been produced and is available on the web.
Towards Efficient Scheduling of Federated Mobile Devices under Computational and Statistical Heterogeneity
May 25, 2020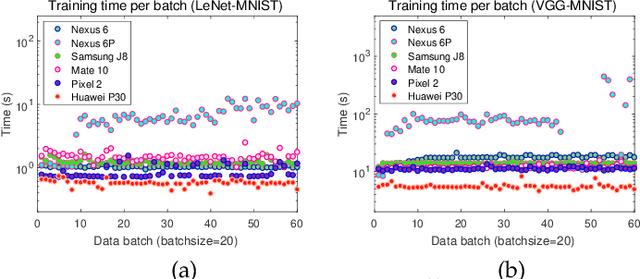
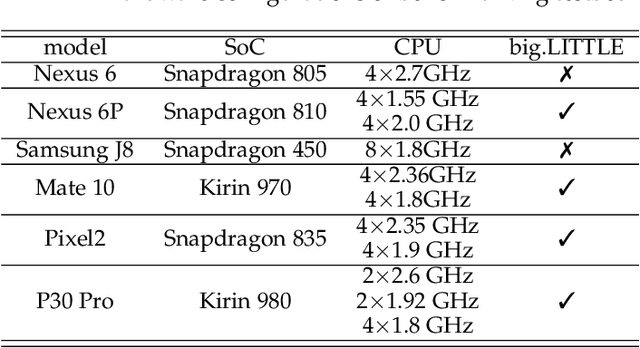
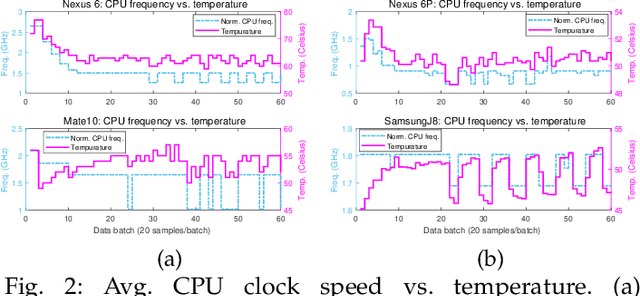

Originated from distributed learning, federated learning enables privacy-preserved collaboration on a new abstracted level by sharing the model parameters only. While the current research mainly focuses on optimizing learning algorithms and minimizing communication overhead left by distributed learning, there is still a considerable gap when it comes to the real implementation on mobile devices. In this paper, we start with an empirical experiment to demonstrate computation heterogeneity is a more pronounced bottleneck than communication on the current generation of battery-powered mobile devices, and the existing methods are haunted by mobile stragglers. Further, non-identically distributed data across the mobile users makes the selection of participants critical to the accuracy and convergence. To tackle the computational and statistical heterogeneity, we utilize data as a tunable knob and propose two efficient polynomial-time algorithms to schedule different workloads on various mobile devices, when data is identically or non-identically distributed. For identically distributed data, we combine partitioning and linear bottleneck assignment to achieve near-optimal training time without accuracy loss. For non-identically distributed data, we convert it into an average cost minimization problem and propose a greedy algorithm to find a reasonable balance between computation time and accuracy. We also establish an offline profiler to quantify the runtime behavior of different devices, which serves as the input to the scheduling algorithms. We conduct extensive experiments on a mobile testbed with two datasets and up to 20 devices. Compared with the common benchmarks, the proposed algorithms achieve 2-100x speedup epoch-wise, 2-7% accuracy gain and boost the convergence rate by more than 100% on CIFAR10.
Extremely Low Bit Transformer Quantization for On-Device Neural Machine Translation
Sep 16, 2020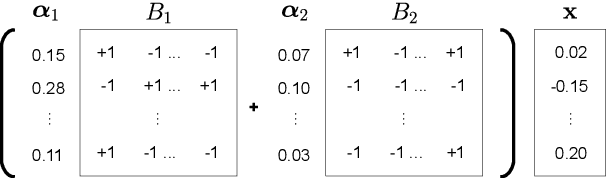
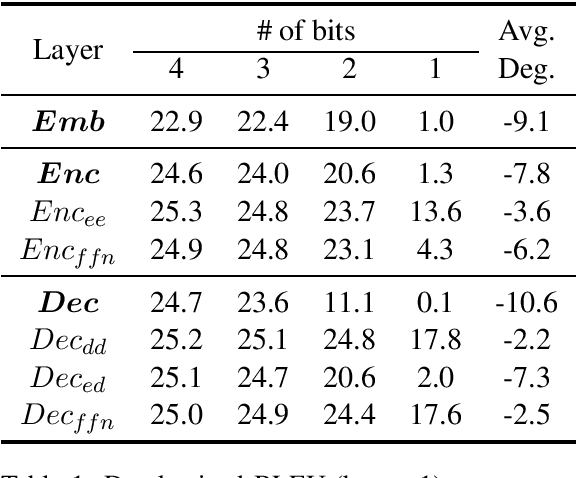
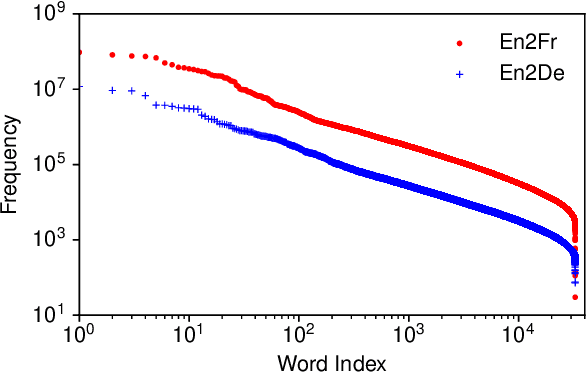
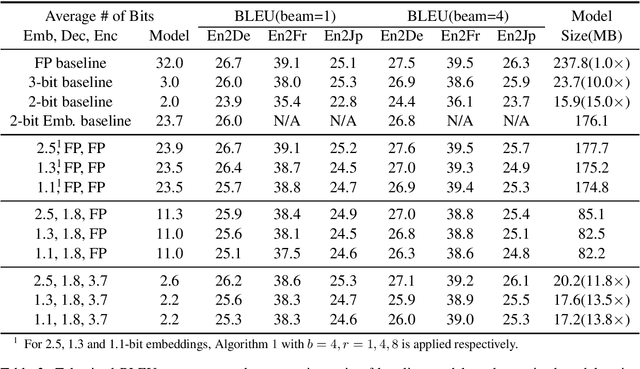
Transformer is being widely used in Neural Machine Translation (NMT). Deploying Transformer models to mobile or edge devices with limited resources is challenging because of heavy computation and memory overhead during inference. Quantization is an effective technique to address such challenges. Our analysis shows that for a given number of quantization bits, each block of Transformer contributes to translation accuracy and inference computations in different manners. Moreover, even inside an embedding block, each word presents vastly different contributions. Correspondingly, we propose a mixed precision quantization strategy to represent Transformer weights with lower bits (e.g. under 3 bits). For example, for each word in an embedding block, we assign different quantization bits based on statistical property. Our quantized Transformer model achieves 11.8x smaller model size than the baseline model, with less than -0.5 BLEU. We achieve 8.3x reduction in run-time memory footprints and 3.5x speed up (Galaxy N10+) such that our proposed compression strategy enables efficient implementation for on-device NMT.
Towards a Fast Steady-State Visual Evoked Potentials (SSVEP) Brain-Computer Interface (BCI)
Feb 04, 2020
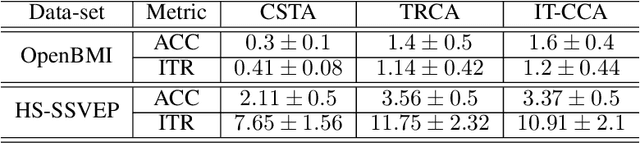
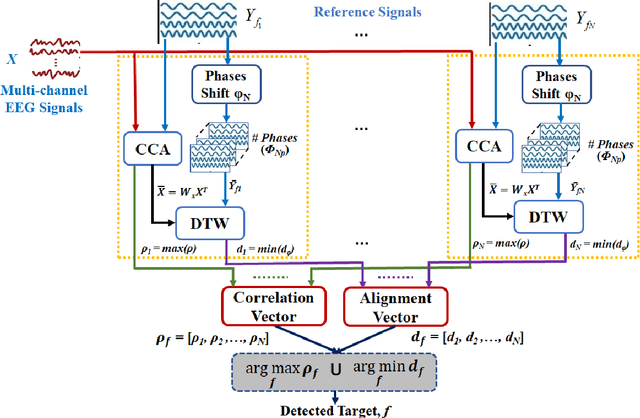
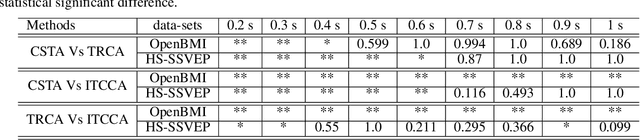
Steady-state visual evoked potentials (SSVEP) brain-computer interface (BCI) provides reliable responses leading to high accuracy and information throughput. But achieving high accuracy typically requires a relatively long time window of one second or more. Various methods were proposed to improve sub-second response accuracy through subject-specific training and calibration. Substantial performance improvements were achieved with tedious calibration and subject-specific training; resulting in the user's discomfort. So, we propose a training-free method by combining spatial-filtering and temporal alignment (CSTA) to recognize SSVEP responses in sub-second response time. CSTA exploits linear correlation and non-linear similarity between steady-state responses and stimulus templates with complementary fusion to achieve desirable performance improvements. We evaluated the performance of CSTA in terms of accuracy and Information Transfer Rate (ITR) in comparison with both training-based and training-free methods using two SSVEP data-sets. We observed that CSTA achieves the maximum mean accuracy of 97.43$\pm$2.26 % and 85.71$\pm$13.41 % with four-class and forty-class SSVEP data-sets respectively in sub-second response time in offline analysis. CSTA yields significantly higher mean performance (p<0.001) than the training-free method on both data-sets. Compared with training-based methods, CSTA shows 29.33$\pm$19.65 % higher mean accuracy with statistically significant differences in time window less than 0.5 s. In longer time windows, CSTA exhibits either better or comparable performance though not statistically significantly better than training-based methods. We show that the proposed method brings advantages of subject-independent SSVEP classification without requiring training while enabling high target recognition performance in sub-second response time.
Self-Supervised Scale Recovery for Monocular Depth and Egomotion Estimation
Sep 09, 2020

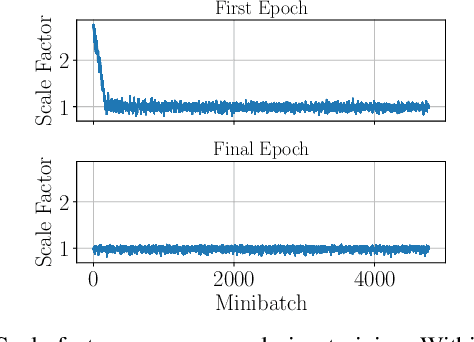
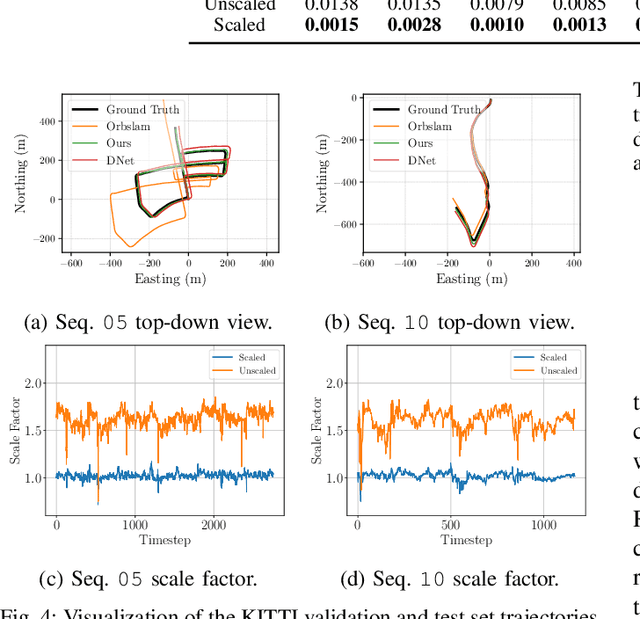
The self-supervised loss formulation for jointly training depth and egomotion neural networks with monocular images is well studied and has demonstrated state-of-the-art accuracy. One of the main limitations of this approach, however, is that the depth and egomotion estimates are only determined up to an unknown scale. In this paper, we present a novel scale recovery loss that enforces consistency between a known camera height and the estimated camera height, generating metric (scaled) depth and egomotion predictions. We show that our proposed method is competitive with other scale recovery techniques (i.e., pose supervision and stereo left/right consistency constraints). Further, we demonstrate how our method facilitates network retraining within new environments, whereas other scale-resolving approaches are incapable of doing so. Notably, our egomotion network is able to produce more accurate estimates than a similar method that only recovers scale at test time.
Multi-span Style Extraction for Generative Reading Comprehension
Sep 15, 2020
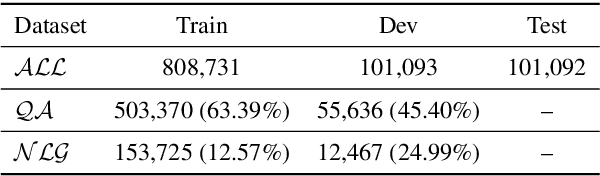
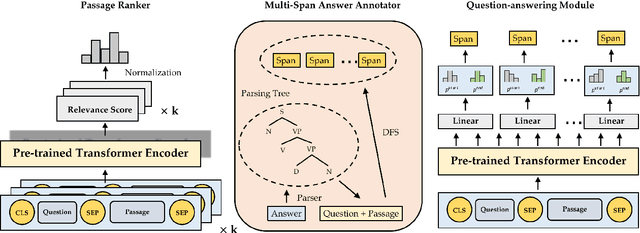
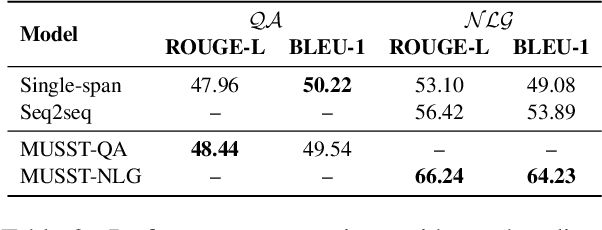
Generative machine reading comprehension (MRC) requires a model to generate well-formed answers. For this type of MRC, answer generation method is crucial to the model performance. However, generative models, which are supposed to be the right model for the task, in generally perform poorly. At the same time, single-span extraction models have been proven effective for extractive MRC, where the answer is constrained to a single span in the passage. Nevertheless, they generally suffer from generating incomplete answers or introducing redundant words when applied to the generative MRC. Thus, we extend the single-span extraction method to multi-span, proposing a new framework which enables generative MRC to be smoothly solved as multi-span extraction. Thorough experiments demonstrate that this novel approach can alleviate the dilemma between generative models and single-span models and produce answers with better-formed syntax and semantics. We will open-source our code for the research community.
A Computationally Efficient Approach to Black-box Optimization using Gaussian Process Models
Oct 27, 2020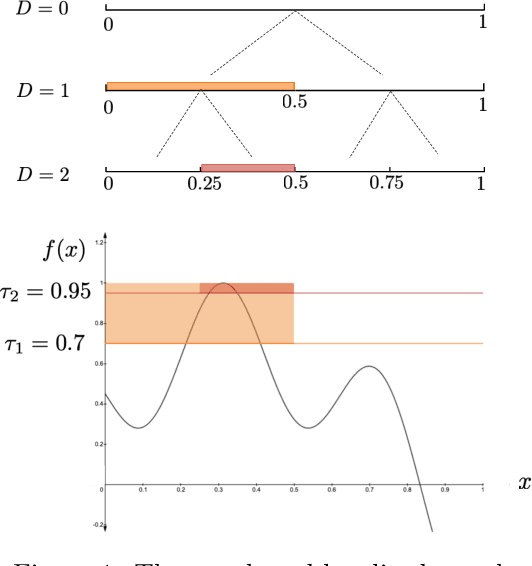
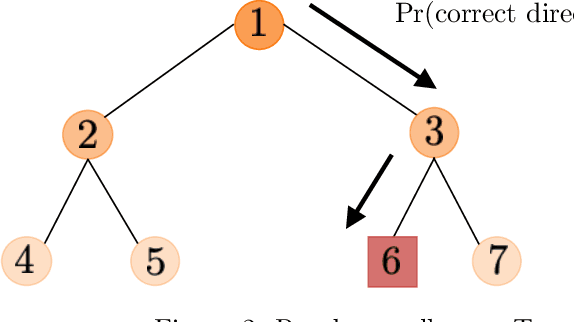
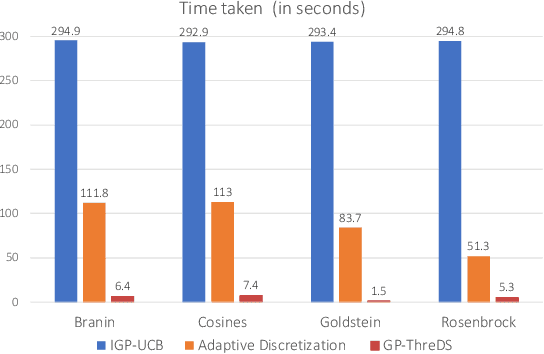
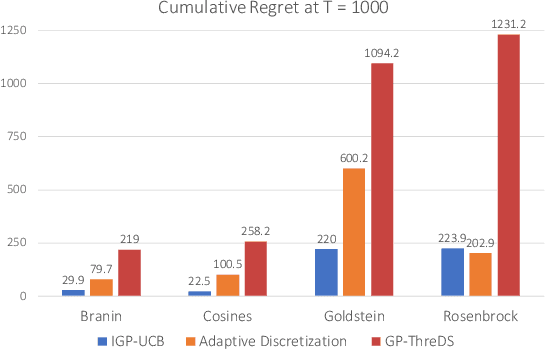
We consider the sequential optimization of an unknown function from noisy feedback using Gaussian process modeling. A prevailing approach to this problem involves choosing query points based on finding the maximum of an upper confidence bound (UCB) score over the entire domain of the function. Due to the multi-modal nature of the UCB, this maximization can only be approximated, usually using an increasingly fine sequence of discretizations of the entire domain, making such methods computationally prohibitive. We propose a general approach that reduces the computational complexity of this class of algorithms by a factor of $O(T^{2d-1})$ (where $T$ is the time horizon and $d$ the dimension of the function domain), while preserving the same regret order. The significant reduction in computational complexity results from two key features of the proposed approach: (i) a tree-based localized search strategy rooted in the methodology of domain shrinking to achieve increasing accuracy with a constant-size discretization; (ii) a localized optimization with the objective relaxed from a global maximizer to any point with value exceeding a given threshold, where the threshold is updated iteratively to approach the maximum as the search deepens. More succinctly, the proposed optimization strategy is a sequence of localized searches in the domain of the function guided by an iterative search in the range of the function to approach the maximum.
WISDoM: a framework for the Analysis of Wishart distributed matrices
Jan 28, 2020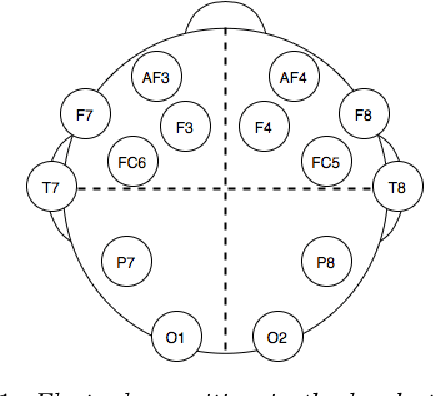
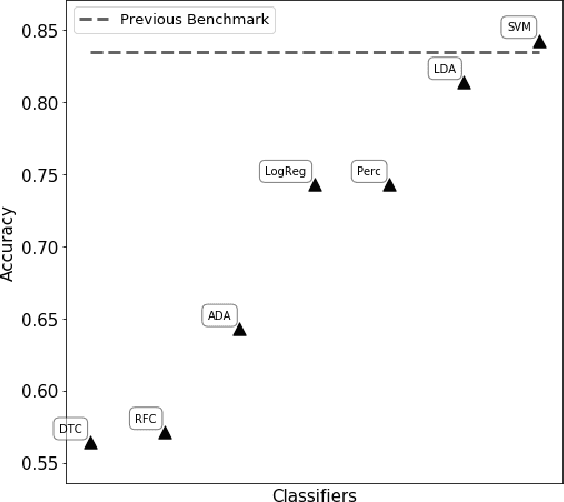
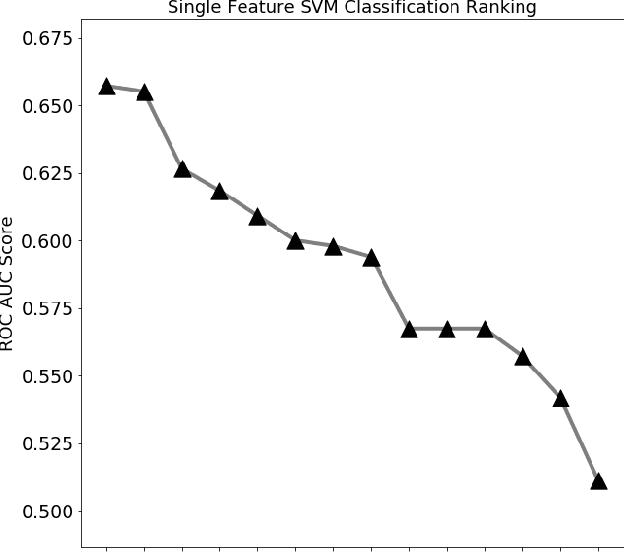
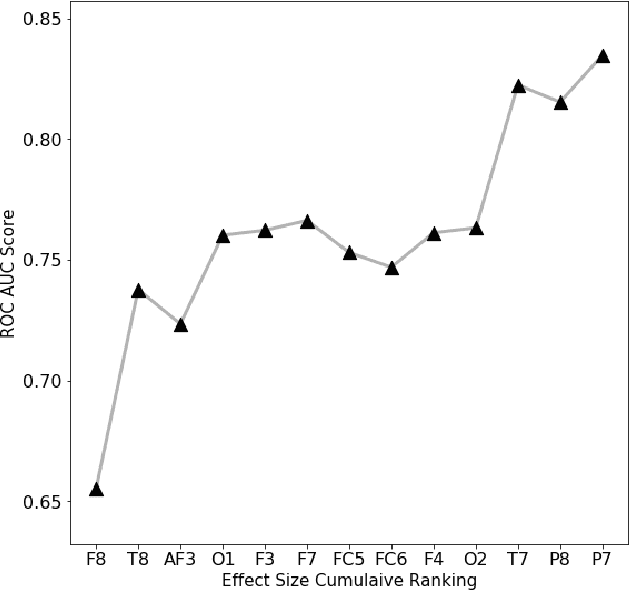
WISDoM (Wishart Distributed Matrices) is a new framework for the characterization of symmetric positive-definite matrices associated to experimental samples, like covariance or correlation matrices, based on the Wishart distribution as a null model. WISDoM can be applied to tasks of supervised learning, like classification, even when such matrices are generated by data of different dimensionality (e.g. time series with same number of variables but different time sampling). In particular, we show the application of the method for the ranking of features associated to electro encephalogram (EEG) data with a time series design, providing a theoretically sound approach for this type of studies.
Classification of Industrial Control Systems screenshots using Transfer Learning
May 21, 2020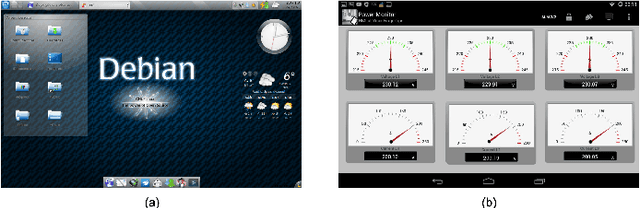
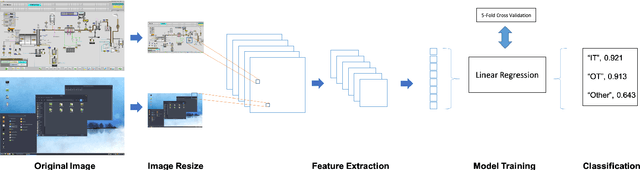

Industrial Control Systems depend heavily on security and monitoring protocols. Several tools are available for this purpose, which scout vulnerabilities and take screenshots from various control panels for later analysis. However, they do not adequately classify images into specific control groups, which can difficult operations performed by manual operators. In order to solve this problem, we use transfer learning with five CNN architectures, pre-trained on Imagenet, to determine which one best classifies screenshots obtained from Industrial Controls Systems. Using 337 manually labeled images, we train these architectures and study their performance both in accuracy and CPU and GPU time. We find out that MobilenetV1 is the best architecture based on its 97,95% of F1-Score, and its speed on CPU with 0.47 seconds per image. In systems where time is critical and GPU is available, VGG16 is preferable because it takes 0.04 seconds to process images, but dropping performance to 87,67%.
Q-NAV: NAV Setting Method based on Reinforcement Learning in Underwater Wireless Networks
May 21, 2020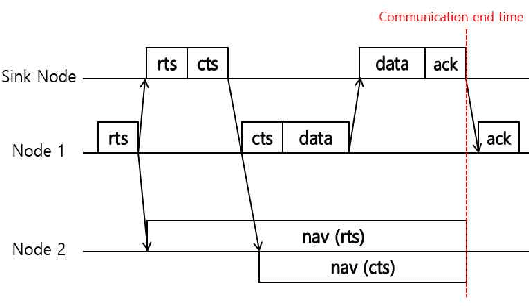
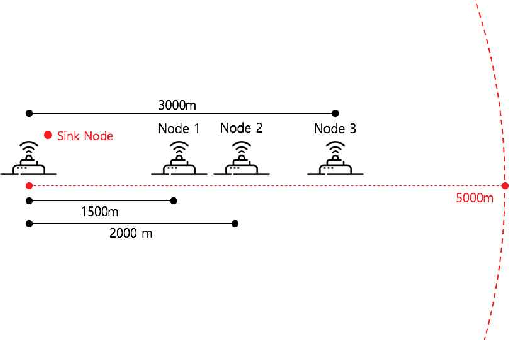


The demand on the underwater communications is extremely increasing in searching for underwater resources, marine expedition, or environmental researches, yet there are many problems with the wireless communications because of the characteristics of the underwater environments. Especially, with the underwater wireless networks, there happen inevitable delay time and spacial inequality due to the distances between the nodes. To solve these problems, this paper suggests a new solution based on ALOHA-Q. The suggested method use random NAV value. and Environments take reward through communications success or fail. After then, The environments setting NAV value from reward. This model minimizes usage of energy and computing resources under the underwater wireless networks, and learns and setting NAV values through intense learning. The results of the simulations show that NAV values can be environmentally adopted and select best value to the circumstances, so the problems which are unnecessary delay times and spacial inequality can be solved. Result of simulations, NAV time decreasing 17.5% compared with original NAV.