 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DTGAN: Dual Attention Generative Adversarial Networks for Text-to-Image Generation
Nov 05, 2020
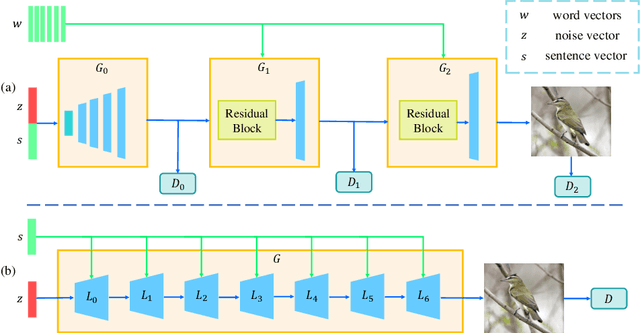
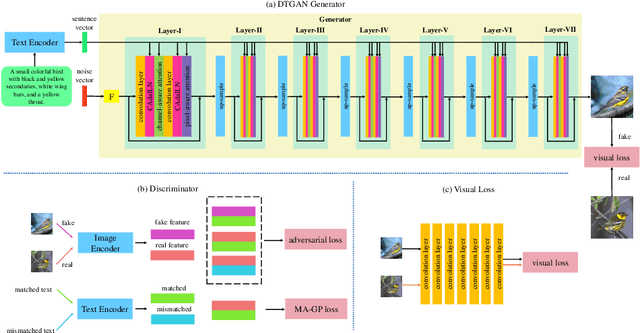
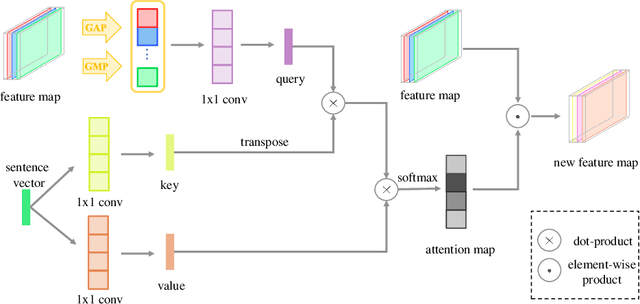
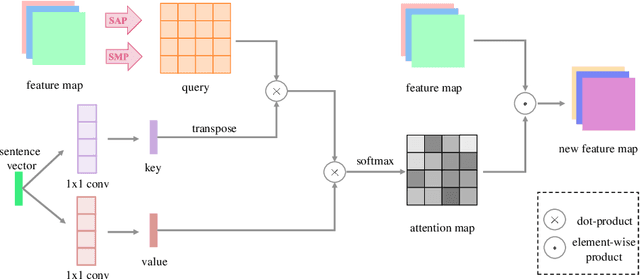
Most existing text-to-image generation methods adopt a multi-stage modular architecture which has three significant problems: (1) Training multiple networks can increase the run time and affect the convergence and stability of the generative model; (2) These approaches ignore the quality of early-stage generator images; (3) Many discriminators need to be trained. To this end, we propose the Dual Attention Generative Adversarial Network (DTGAN) which can synthesize high quality and visually realistic images only employing a single generator/discriminator pair. The proposed model introduces channel-aware and pixel-aware attention modules that can guide the generator to focus on text-relevant channels and pixels based on the global sentence vector and to fine-tune original feature maps using attention weights. Also, Conditional Adaptive Instance-Layer Normalization (CAdaILN) is presented to help our attention modules flexibly control the amount of change in shape and texture by the input natural-language description. Furthermore, a new type of visual loss is utilized to enhance the image quality by ensuring the vivid shape and the perceptually uniform color distributions of generated images. Experimental results on benchmark datasets demonstrate the superiority of our proposed method compared to the state-of-the-art models with a multi-stage framework. Visualization of the attention maps shows that the channel-aware attention module is able to localize the discriminative regions, while the pixel-aware attention module has the ability to capture the globally visual contents for the generation of an image.
Bidirectional Sampling Based Search Without Two Point Boundary Value Solution
Oct 28, 2020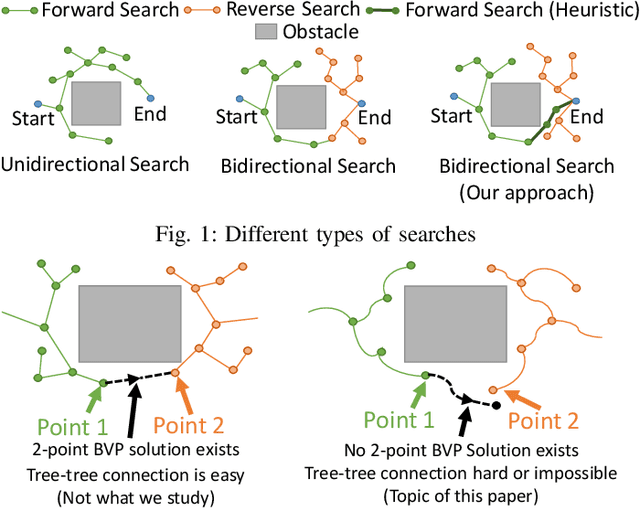
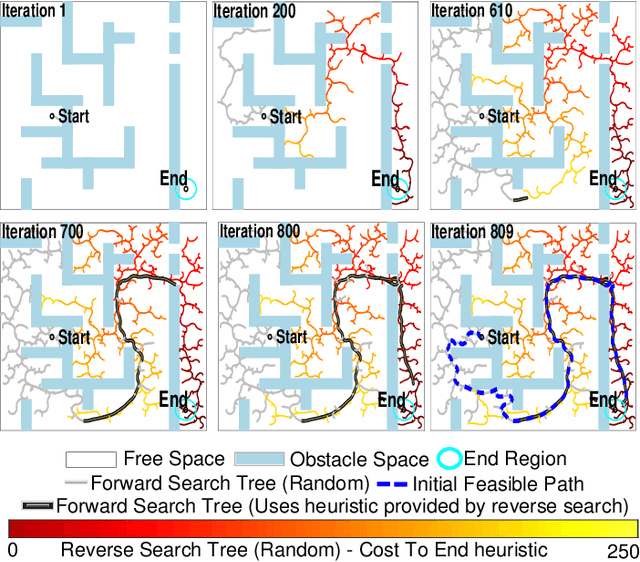

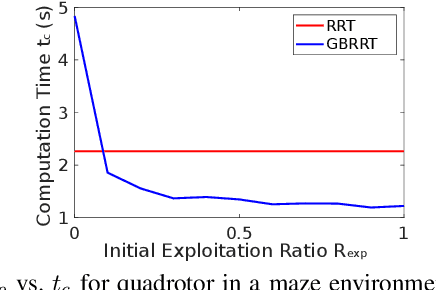
Bidirectional path and motion planning approaches decrease planning time, on average, compared to their unidirectional counterparts. In the context of single-query feasible motion planning, using bidirectional search to find a continuous motion plan requires an explicit connection between the forward search tree and the reverse search tree. Such a tree-tree connection requires solving a two-point Boundary Value Problem (BVP). However, two-point BVP solution can be difficult or impossible to calculate for many types of vehicles (using numerical methods to find a solution, such as shooting approaches may be computationally expensive and is sometimes numerically unstable). To overcome this challenge, we present a generalized bidirectional search algorithm that does not require solving two-point BVP. Instead of connecting the two trees directly, our algorithm uses the cost information of the reverse tree as a guiding heuristic for forward search. This enables the forward search to quickly converge to a full feasible solution without an explicit tree-tree connection and without the solution to a two-point BVP. We run multiple software simulations in different environments and using dynamics of different vehicles along with real-world hardware experiments to show that our approach performs very close or better than existing state of the art approaches in terms of quickly converging to an initial feasible solution.
The Slow Deterioration of the Generalization Error of the Random Feature Model
Aug 13, 2020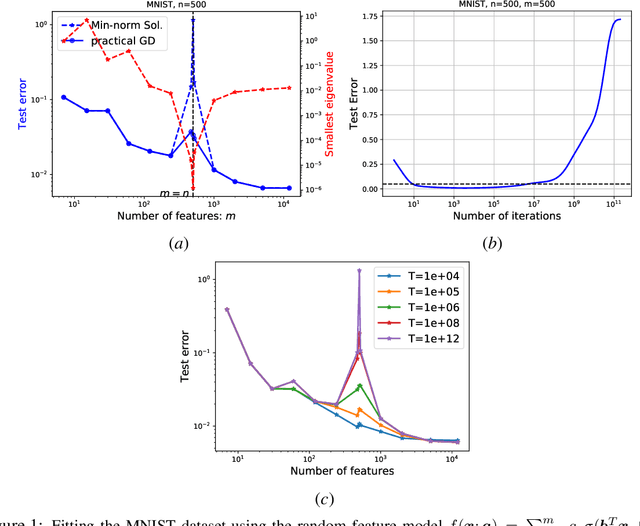
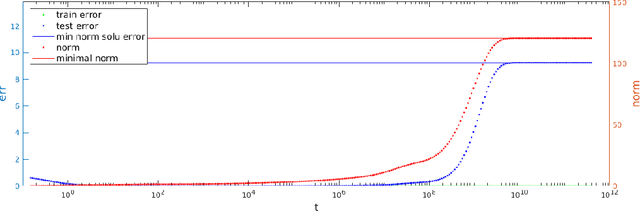
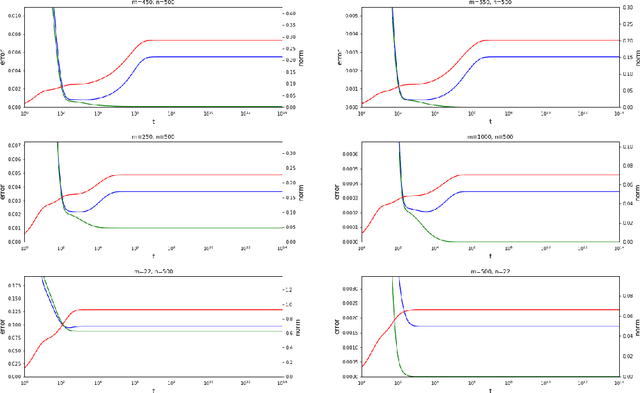
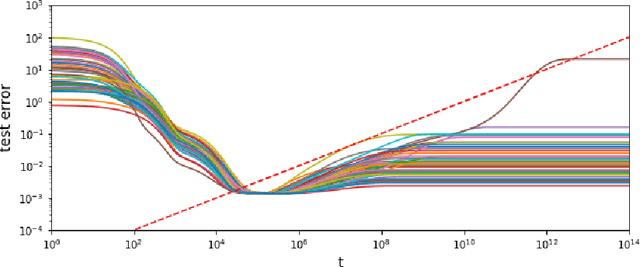
The random feature model exhibits a kind of resonance behavior when the number of parameters is close to the training sample size. This behavior is characterized by the appearance of large generalization gap, and is due to the occurrence of very small eigenvalues for the associated Gram matrix. In this paper, we examine the dynamic behavior of the gradient descent algorithm in this regime. We show, both theoretically and experimentally, that there is a dynamic self-correction mechanism at work: The larger the eventual generalization gap, the slower it develops, both because of the small eigenvalues. This gives us ample time to stop the training process and obtain solutions with good generalization property.
Robust Learning under Strong Noise via SQs
Oct 18, 2020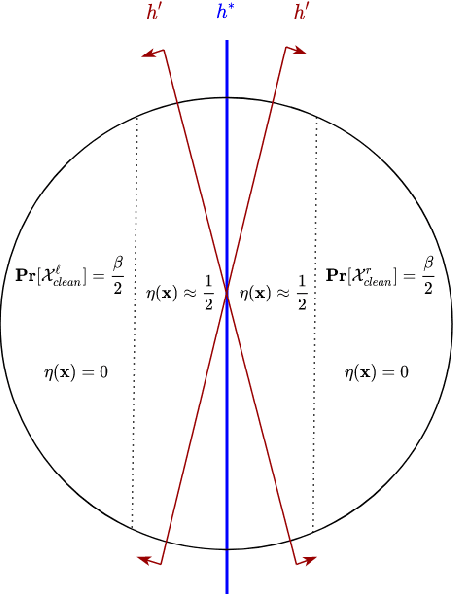
This work provides several new insights on the robustness of Kearns' statistical query framework against challenging label-noise models. First, we build on a recent result by \cite{DBLP:journals/corr/abs-2006-04787} that showed noise tolerance of distribution-independently evolvable concept classes under Massart noise. Specifically, we extend their characterization to more general noise models, including the Tsybakov model which considerably generalizes the Massart condition by allowing the flipping probability to be arbitrarily close to $\frac{1}{2}$ for a subset of the domain. As a corollary, we employ an evolutionary algorithm by \cite{DBLP:conf/colt/KanadeVV10} to obtain the first polynomial time algorithm with arbitrarily small excess error for learning linear threshold functions over any spherically symmetric distribution in the presence of spherically symmetric Tsybakov noise. Moreover, we posit access to a stronger oracle, in which for every labeled example we additionally obtain its flipping probability. In this model, we show that every SQ learnable class admits an efficient learning algorithm with OPT + $\epsilon$ misclassification error for a broad class of noise models. This setting substantially generalizes the widely-studied problem of classification under RCN with known noise rate, and corresponds to a non-convex optimization problem even when the noise function -- i.e. the flipping probabilities of all points -- is known in advance.
HydroDeep -- A Knowledge Guided Deep Neural Network for Geo-Spatiotemporal Data Analysis
Oct 09, 2020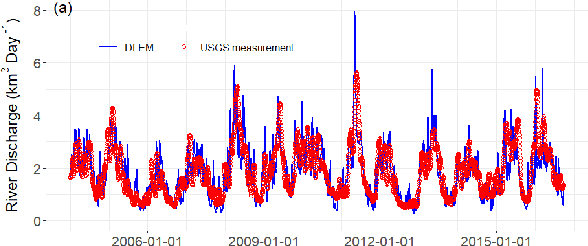

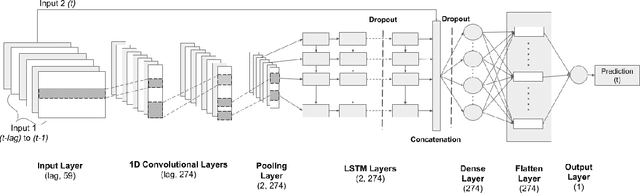
Floods are one of the major climate-related disasters, leading to substantial economic loss and social safety issue. However, the confidence in predicting changes in fluvial floods remains low due to limited evidence and complex causes of regional climate change. The recent development in machine learning techniques has the potential to improve traditional hydrological models by using monitoring data. Although Recurrent Neural Networks (RNN) perform remarkably with multivariate time series data, these models are blinded to the underlying mechanisms represented in a process-based model for flood prediction. While both process-based models and deep learning networks have their strength, understanding the fundamental mechanisms intrinsic to geo-spatiotemporal information is crucial to improve the prediction accuracy of flood occurrence. This paper demonstrates a neural network architecture (HydroDeep) that couples a process-based hydro-ecological model with a combination of Deep Convolutional Neural Network (CNN) and Long Short-Term Memory (LSTM) Network to build a hybrid baseline model. HydroDeep outperforms the performance of both the independent networks by 4.8% and 31.8% respectively in Nash-Sutcliffe efficiency. A trained HydroDeep can transfer its knowledge and can learn the Geo-spatiotemporal features of any new region in minimal training iterations.
Perception-Prediction-Reaction Agents for Deep Reinforcement Learning
Jun 26, 2020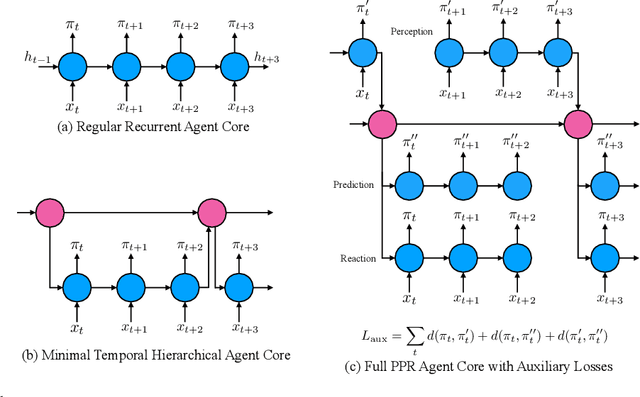

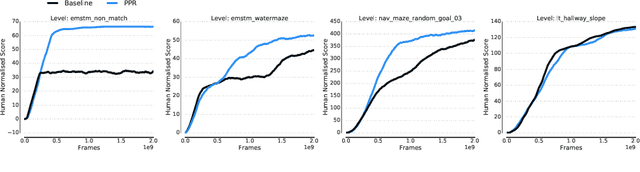
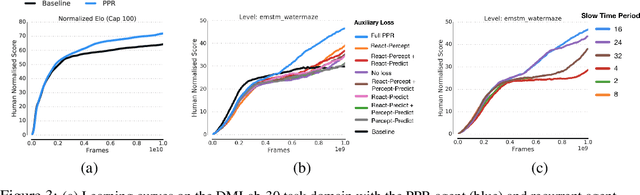
We introduce a new recurrent agent architecture and associated auxiliary losses which improve reinforcement learning in partially observable tasks requiring long-term memory. We employ a temporal hierarchy, using a slow-ticking recurrent core to allow information to flow more easily over long time spans, and three fast-ticking recurrent cores with connections designed to create an information asymmetry. The \emph{reaction} core incorporates new observations with input from the slow core to produce the agent's policy; the \emph{perception} core accesses only short-term observations and informs the slow core; lastly, the \emph{prediction} core accesses only long-term memory. An auxiliary loss regularizes policies drawn from all three cores against each other, enacting the prior that the policy should be expressible from either recent or long-term memory. We present the resulting \emph{Perception-Prediction-Reaction} (PPR) agent and demonstrate its improved performance over a strong LSTM-agent baseline in DMLab-30, particularly in tasks requiring long-term memory. We further show significant improvements in Capture the Flag, an environment requiring agents to acquire a complicated mixture of skills over long time scales. In a series of ablation experiments, we probe the importance of each component of the PPR agent, establishing that the entire, novel combination is necessary for this intriguing result.
A Spatial-Temporal Graph Based Hybrid Infectious Disease Model with Application to COVID-19
Oct 18, 2020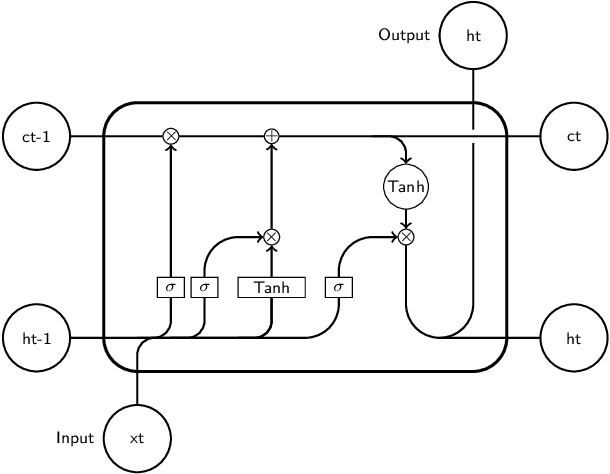
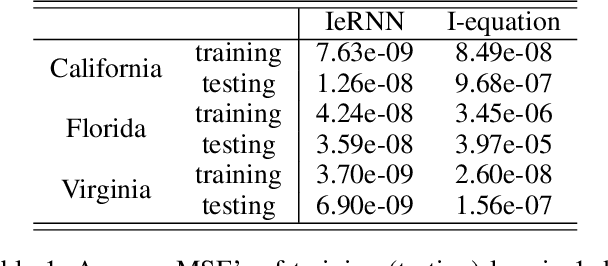
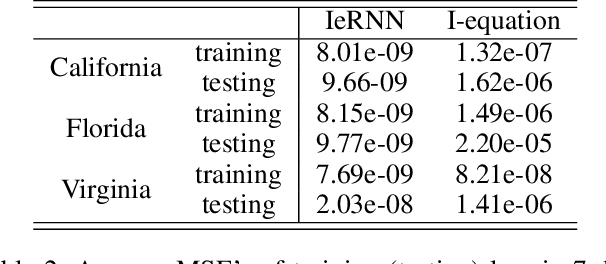
As the COVID-19 pandemic evolves, reliable prediction plays an important role for policy making. The classical infectious disease model SEIR (susceptible-exposed-infectious-recovered) is a compact yet simplistic temporal model. The data-driven machine learning models such as RNN (recurrent neural networks) can suffer in case of limited time series data such as COVID-19. In this paper, we combine SEIR and RNN on a graph structure to develop a hybrid spatio-temporal model to achieve both accuracy and efficiency in training and forecasting. We introduce two features on the graph structure: node feature (local temporal infection trend) and edge feature (geographic neighbor effect). For node feature, we derive a discrete recursion (called I-equation) from SEIR so that gradient descend method applies readily to its optimization. For edge feature, we design an RNN model to capture the neighboring effect and regularize the landscape of loss function so that local minima are effective and robust for prediction. The resulting hybrid model (called IeRNN) improves the prediction accuracy on state-level COVID-19 new case data from the US, out-performing standard temporal models (RNN, SEIR, and ARIMA) in 1-day and 7-day ahead forecasting. Our model accommodates various degrees of reopening and provides potential outcomes for policymakers.
Denmark's Participation in the Search Engine TREC COVID-19 Challenge: Lessons Learned about Searching for Precise Biomedical Scientific Information on COVID-19
Nov 26, 2020
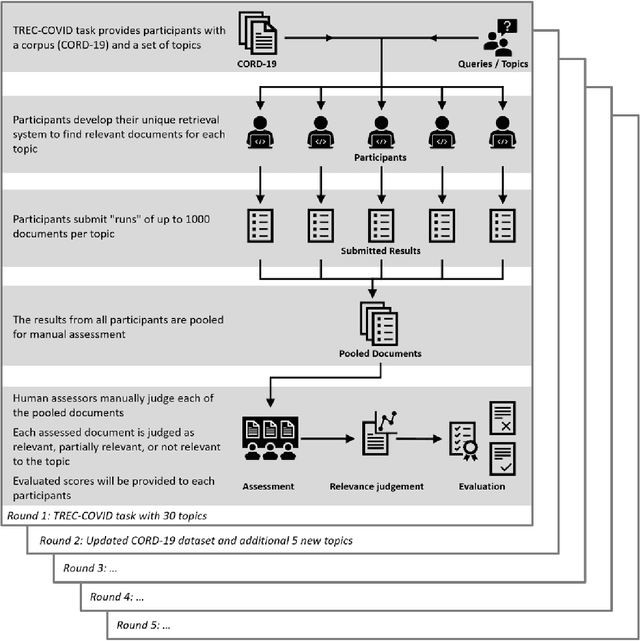
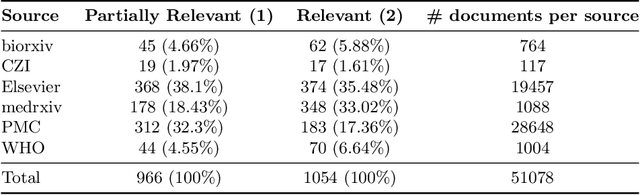
This report describes the participation of two Danish universities, University of Copenhagen and Aalborg University, in the international search engine competition on COVID-19 (the 2020 TREC-COVID Challenge) organised by the U.S. National Institute of Standards and Technology (NIST) and its Text Retrieval Conference (TREC) division. The aim of the competition was to find the best search engine strategy for retrieving precise biomedical scientific information on COVID-19 from the largest, at that point in time, dataset of curated scientific literature on COVID-19 -- the COVID-19 Open Research Dataset (CORD-19). CORD-19 was the result of a call to action to the tech community by the U.S. White House in March 2020, and was shortly thereafter posted on Kaggle as an AI competition by the Allen Institute for AI, the Chan Zuckerberg Initiative, Georgetown University's Center for Security and Emerging Technology, Microsoft, and the National Library of Medicine at the US National Institutes of Health. CORD-19 contained over 200,000 scholarly articles (of which more than 100,000 were with full text) about COVID-19, SARS-CoV-2, and related coronaviruses, gathered from curated biomedical sources. The TREC-COVID challenge asked for the best way to (a) retrieve accurate and precise scientific information, in response to some queries formulated by biomedical experts, and (b) rank this information decreasingly by its relevance to the query. In this document, we describe the TREC-COVID competition setup, our participation to it, and our resulting reflections and lessons learned about the state-of-art technology when faced with the acute task of retrieving precise scientific information from a rapidly growing corpus of literature, in response to highly specialised queries, in the middle of a pandemic.
Multi-scale Transformer Language Models
May 01, 2020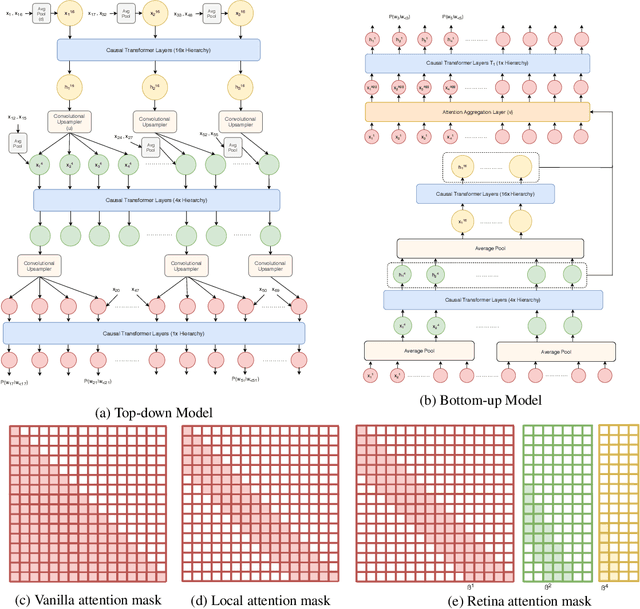
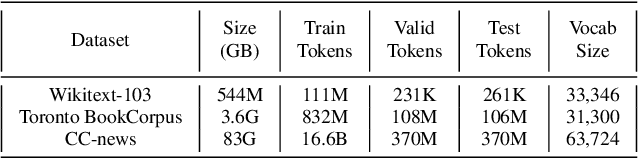
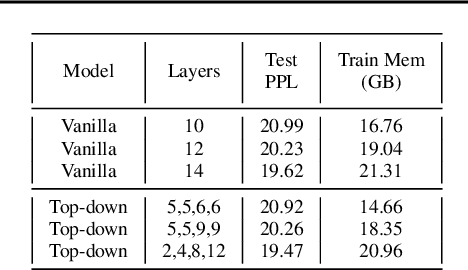
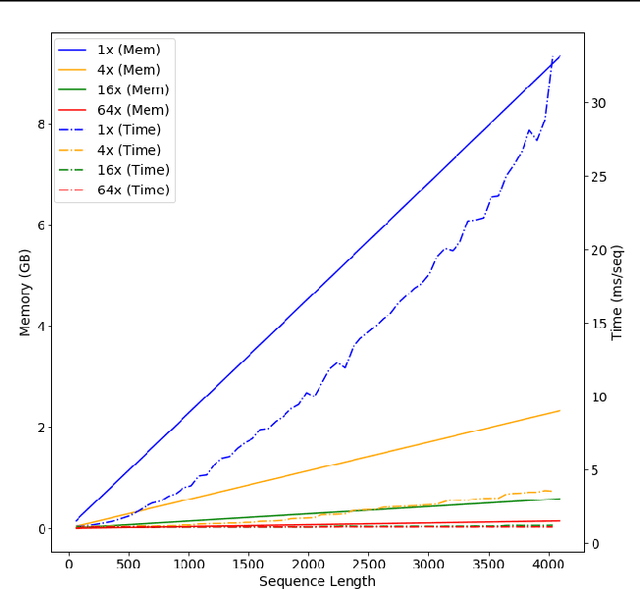
We investigate multi-scale transformer language models that learn representations of text at multiple scales, and present three different architectures that have an inductive bias to handle the hierarchical nature of language. Experiments on large-scale language modeling benchmarks empirically demonstrate favorable likelihood vs memory footprint trade-offs, e.g. we show that it is possible to train a hierarchical variant with 30 layers that has 23% smaller memory footprint and better perplexity, compared to a vanilla transformer with less than half the number of layers, on the Toronto BookCorpus. We analyze the advantages of learned representations at multiple scales in terms of memory footprint, compute time, and perplexity, which are particularly appealing given the quadratic scaling of transformers' run time and memory usage with respect to sequence length.
PERF-Net: Pose Empowered RGB-Flow Net
Sep 28, 2020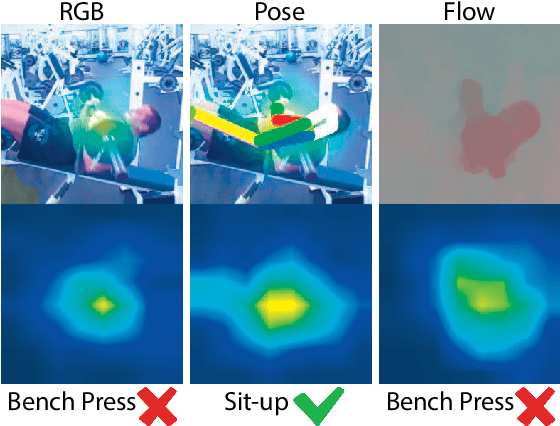
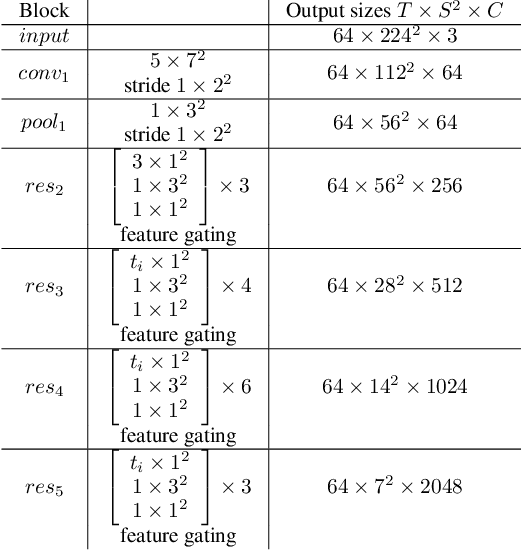

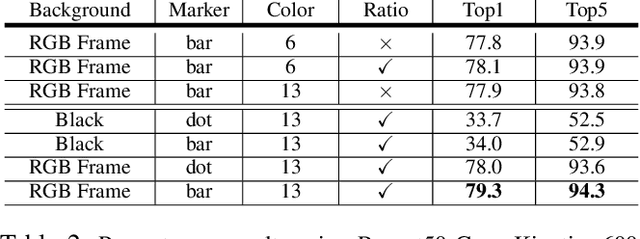
In recent years, many works in the video action recognition literature have shown that two stream models (combining spatial and temporal input streams) are necessary for achieving state of the art performance. In this paper we show the benefits of including yet another stream based on human pose estimated from each frame -- specifically by rendering pose on input RGB frames. At first blush, this additional stream may seem redundant given that human pose is fully determined by RGB pixel values -- however we show (perhaps surprisingly) that this simple and flexible addition can provide complementary gains. Using this insight, we then propose a new model, which we dub PERF-Net (short for Pose Empowered RGB-Flow Net), which combines this new pose stream with the standard RGB and flow based input streams via distillation techniques and show that our model outperforms the state-of-the-art by a large margin in a number of human action recognition datasets while not requiring flow or pose to be explicitly computed at inference time.