 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Flow Base Bi-path Network for Cross-scene Video Crowd Understanding in Aerial View
Sep 29, 2020


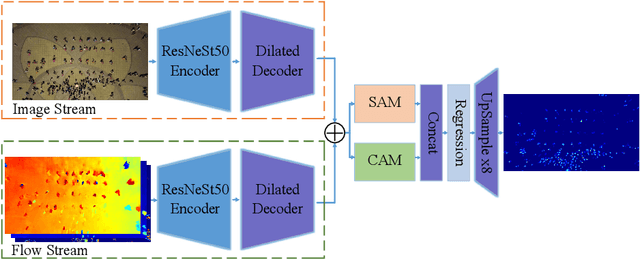

Drones shooting can be applied in dynamic traffic monitoring, object detecting and tracking, and other vision tasks. The variability of the shooting location adds some intractable challenges to these missions, such as varying scale, unstable exposure, and scene migration. In this paper, we strive to tackle the above challenges and automatically understand the crowd from the visual data collected from drones. First, to alleviate the background noise generated in cross-scene testing, a double-stream crowd counting model is proposed, which extracts optical flow and frame difference information as an additional branch. Besides, to improve the model's generalization ability at different scales and time, we randomly combine a variety of data transformation methods to simulate some unseen environments. To tackle the crowd density estimation problem under extreme dark environments, we introduce synthetic data generated by game Grand Theft Auto V(GTAV). Experiment results show the effectiveness of the virtual data. Our method wins the challenge with a mean absolute error (MAE) of 12.70. Moreover, a comprehensive ablation study is conducted to explore each component's contribution.
Forecasting with sktime: Designing sktime's New Forecasting API and Applying It to Replicate and Extend the M4 Study
May 16, 2020
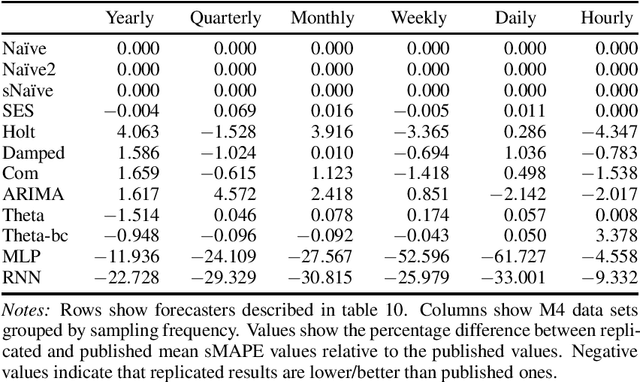
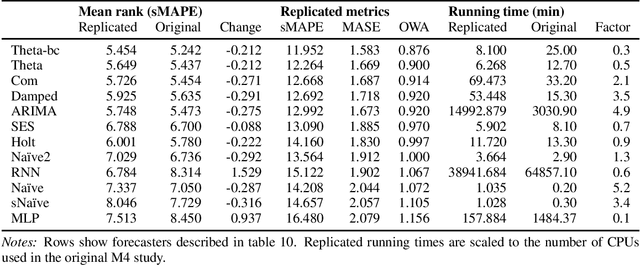

We present a new open-source framework for forecasting in Python. Our framework forms part of sktime, a machine learning toolbox with a unified interface for different time series learning tasks, like forecasting, but also time series classification and regression. We provide a dedicated forecasting interface, common statistical algorithms, and scikit-learn compatible tools for building composite machine learning models. We use sktime to both replicate key results from the M4 forecasting study and to extend it. sktime allows to easily build, tune and evaluate new models. We investigate the potential of common machine learning techniques for univariate forecasting, including reduction, boosting, ensembling, pipelining and tuning. We find that simple hybrid models can boost the performance of statistical models, and that pure machine learning models can achieve competitive forecasting performance on the hourly data sets, outperforming the statistical algorithms and coming close to the M4 winner model.
Understanding Unnatural Questions Improves Reasoning over Text
Oct 19, 2020

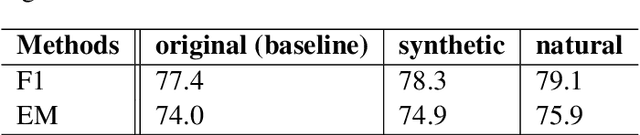
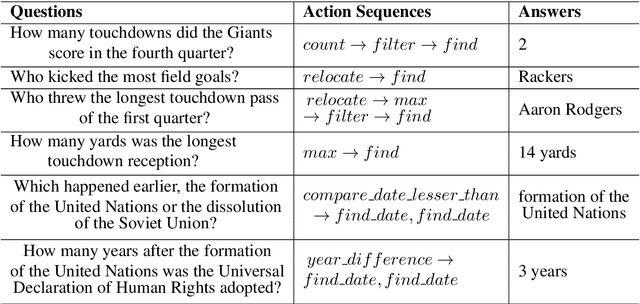
Complex question answering (CQA) over raw text is a challenging task. A prominent approach to this task is based on the programmer-interpreter framework, where the programmer maps the question into a sequence of reasoning actions which is then executed on the raw text by the interpreter. Learning an effective CQA model requires large amounts of human-annotated data,consisting of the ground-truth sequence of reasoning actions, which is time-consuming and expensive to collect at scale. In this paper, we address the challenge of learning a high-quality programmer (parser) by projecting natural human-generated questions into unnatural machine-generated questions which are more convenient to parse. We firstly generate synthetic (question,action sequence) pairs by a data generator, and train a semantic parser that associates synthetic questions with their corresponding action sequences. To capture the diversity when applied tonatural questions, we learn a projection model to map natural questions into their most similar unnatural questions for which the parser can work well. Without any natural training data, our projection model provides high-quality action sequences for the CQA task. Experimental results show that the QA model trained exclusively with synthetic data generated by our method outperforms its state-of-the-art counterpart trained on human-labeled data.
Taking Notes on the Fly Helps BERT Pre-training
Aug 04, 2020
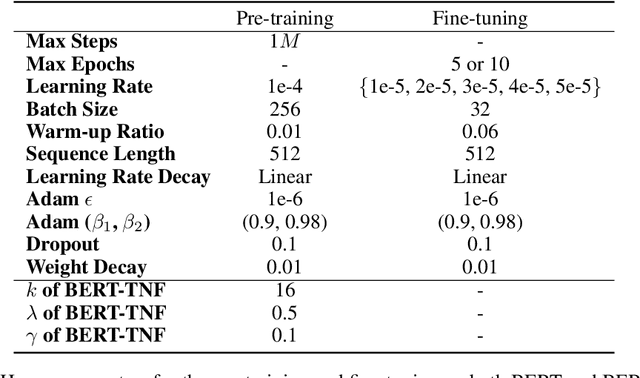
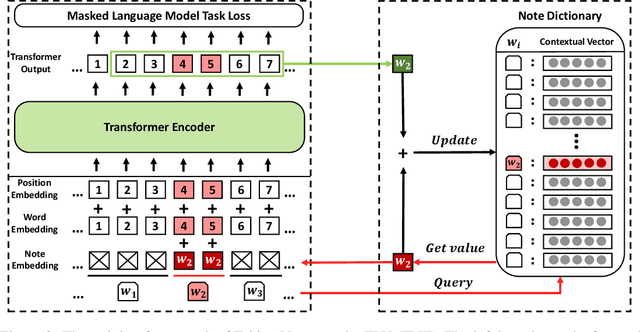

How to make unsupervised language pre-training more efficient and less resource-intensive is an important research direction in NLP. In this paper, we focus on improving the efficiency of language pre-training methods through providing better data utilization. It is well-known that in language data corpus, words follow a heavy-tail distribution. A large proportion of words appear only very few times and the embeddings of rare words are usually poorly optimized. We argue that such embeddings carry inadequate semantic signals. They could make the data utilization inefficient and slow down the pre-training of the entire model. To solve this problem, we propose Taking Notes on the Fly (TNF). TNF takes notes for rare words on the fly during pre-training to help the model understand them when they occur next time. Specifically, TNF maintains a note dictionary and saves a rare word's context information in it as notes when the rare word occurs in a sentence. When the same rare word occurs again in training, TNF employs the note information saved beforehand to enhance the semantics of the current sentence. By doing so, TNF provides a better data utilization since cross-sentence information is employed to cover the inadequate semantics caused by rare words in the sentences. Experimental results show that TNF significantly expedite the BERT pre-training and improve the model's performance on downstream tasks. TNF's training time is $60\%$ less than BERT when reaching the same performance. When trained with same number of iterations, TNF significantly outperforms BERT on most of downstream tasks and the average GLUE score.
Parameter-based Value Functions
Jun 16, 2020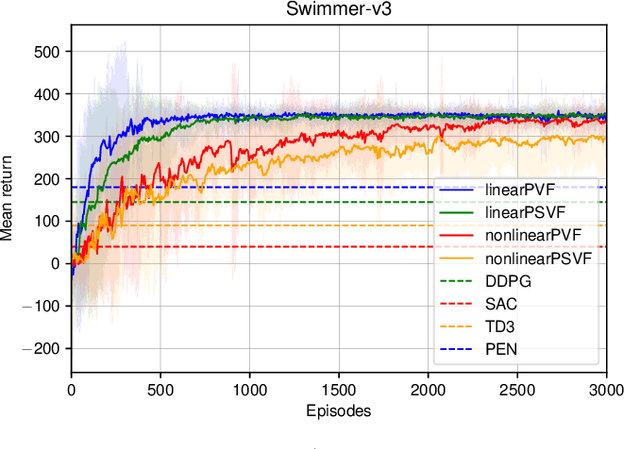
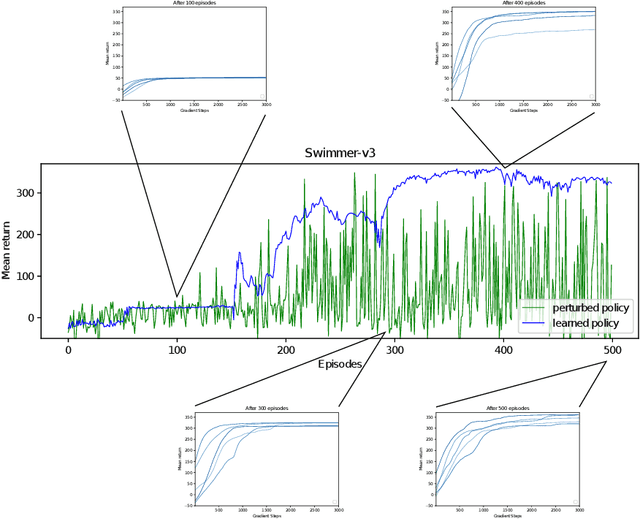
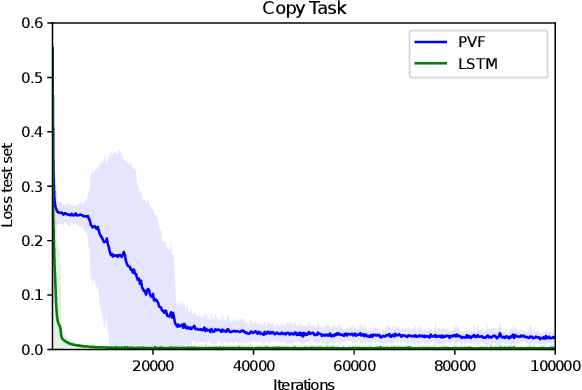
Learning value functions off-policy is at the core of modern Reinforcement Learning (RL). Traditional off-policy actor-critic algorithms, however, only approximate the true policy gradient, since the gradient $\nabla_{\theta} Q^{\pi_{\theta}}(s,a)$ of the action-value function with respect to the policy parameters is often ignored. We introduce a class of value functions called Parameter-based Value Functions (PVFs) whose inputs include the policy parameters. PVFs can evaluate the performance of any policy given a state, a state-action pair, or a distribution over the RL agent's initial states. We show how PVFs yield exact policy gradient theorems. We derive off-policy actor-critic algorithms based on PVFs trained using Monte Carlo or Temporal Difference methods. Preliminary experimental results indicate that PVFs can effectively evaluate deterministic linear and nonlinear policies, outperforming state-of-the-art algorithms in the continuous control environment Swimmer-v3. Finally, we show how recurrent neural networks can be trained through PVFs to solve supervised and RL problems involving partial observability and long time lags between relevant events. This provides an alternative to backpropagation through time.
agtboost: Adaptive and Automatic Gradient Tree Boosting Computations
Aug 28, 2020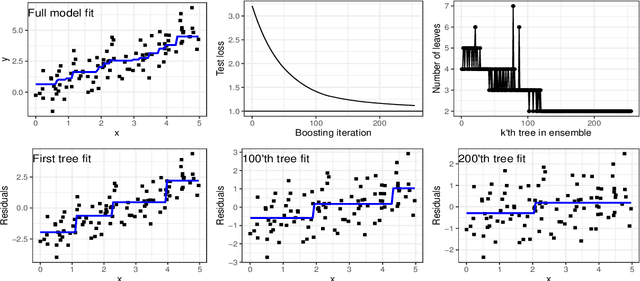

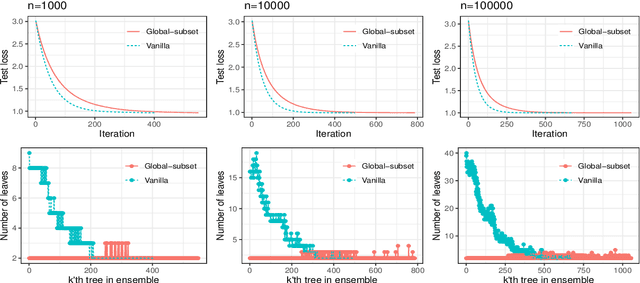
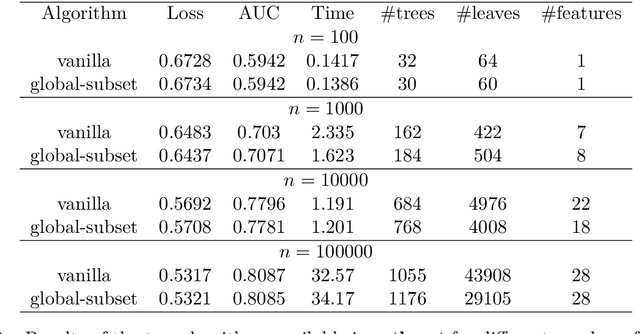
agtboost is an R package implementing fast gradient tree boosting computations in a manner similar to other established frameworks such as xgboost and LightGBM, but with significant decreases in computation time and required mathematical and technical knowledge. The package automatically takes care of split/no-split decisions and selects the number of trees in the gradient tree boosting ensemble, i.e., agtboost adapts the complexity of the ensemble automatically to the information in the data. All of this is done during a single training run, which is made possible by utilizing developments in information theory for tree algorithms {\tt arXiv:2008.05926v1 [stat.ME]}. agtboost also comes with a feature importance function that eliminates the common practice of inserting noise features. Further, a useful model validation function performs the Kolmogorov-Smirnov test on the learned distribution.
Language and Visual Entity Relationship Graph for Agent Navigation
Oct 19, 2020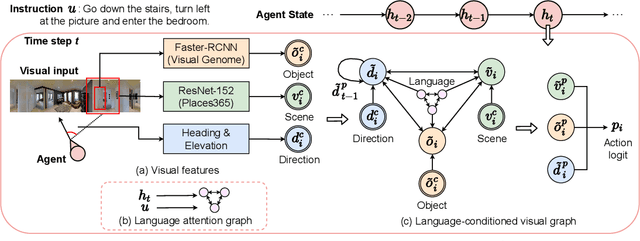
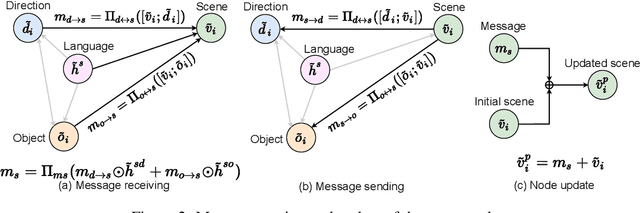
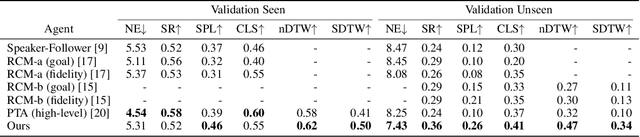
Vision-and-Language Navigation (VLN) requires an agent to navigate in a real-world environment following natural language instructions. From both the textual and visual perspectives, we find that the relationships among the scene, its objects,and directional clues are essential for the agent to interpret complex instructions and correctly perceive the environment. To capture and utilize the relationships, we propose a novel Language and Visual Entity Relationship Graph for modelling the inter-modal relationships between text and vision, and the intra-modal relationships among visual entities. We propose a message passing algorithm for propagating information between language elements and visual entities in the graph, which we then combine to determine the next action to take. Experiments show that by taking advantage of the relationships we are able to improve over state-of-the-art. On the Room-to-Room (R2R) benchmark, our method achieves the new best performance on the test unseen split with success rate weighted by path length (SPL) of 52%. On the Room-for-Room (R4R) dataset, our method significantly improves the previous best from 13% to 34% on the success weighted by normalized dynamic time warping (SDTW). Code is available at: https://github.com/YicongHong/Entity-Graph-VLN.
Double-Uncertainty Weighted Method for Semi-supervised Learning
Oct 19, 2020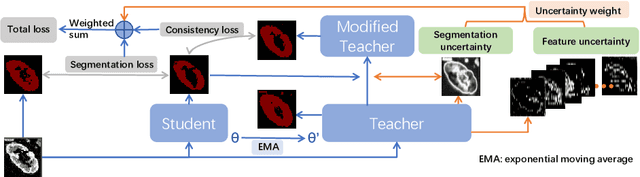
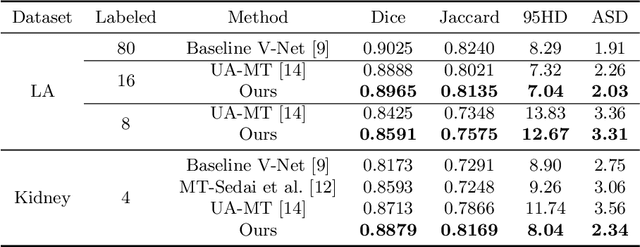
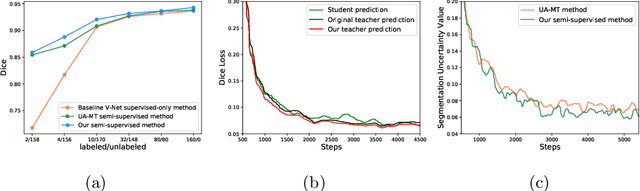
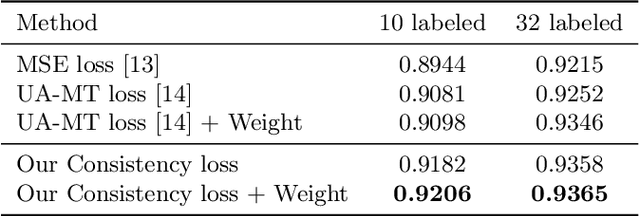
Though deep learning has achieved advanced performance recently, it remains a challenging task in the field of medical imaging, as obtaining reliable labeled training data is time-consuming and expensive. In this paper, we propose a double-uncertainty weighted method for semi-supervised segmentation based on the teacher-student model. The teacher model provides guidance for the student model by penalizing their inconsistent prediction on both labeled and unlabeled data. We train the teacher model using Bayesian deep learning to obtain double-uncertainty, i.e. segmentation uncertainty and feature uncertainty. It is the first to extend segmentation uncertainty estimation to feature uncertainty, which reveals the capability to capture information among channels. A learnable uncertainty consistency loss is designed for the unsupervised learning process in an interactive manner between prediction and uncertainty. With no ground-truth for supervision, it can still incentivize more accurate teacher's predictions and facilitate the model to reduce uncertain estimations. Furthermore, our proposed double-uncertainty serves as a weight on each inconsistency penalty to balance and harmonize supervised and unsupervised training processes. We validate the proposed feature uncertainty and loss function through qualitative and quantitative analyses. Experimental results show that our method outperforms the state-of-the-art uncertainty-based semi-supervised methods on two public medical datasets.
Fast top-K Cosine Similarity Search through XOR-Friendly Binary Quantization on GPUs
Aug 05, 2020
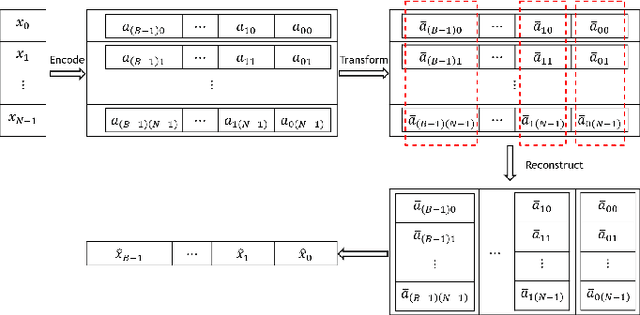
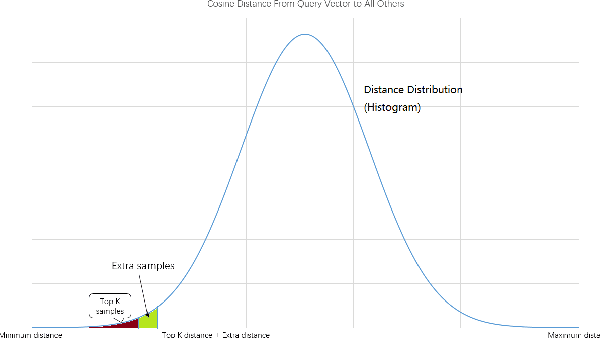

We explore the use of GPU for accelerating large scale nearest neighbor search and we propose a fast vector-quantization-based exhaustive nearest neighbor search algorithm that can achieve high accuracy without any indexing construction specifically designed for cosine similarity. This algorithm uses a novel XOR-friendly binary quantization method to encode floating-point numbers such that high-complexity multiplications can be optimized as low-complexity bitwise operations. Experiments show that, our quantization method takes short preprocessing time, and helps make the search speed of our exhaustive search method much more faster than that of popular approximate nearest neighbor algorithms when high accuracy is needed.
Economy Statistical Recurrent Units For Inferring Nonlinear Granger Causality
Jan 14, 2020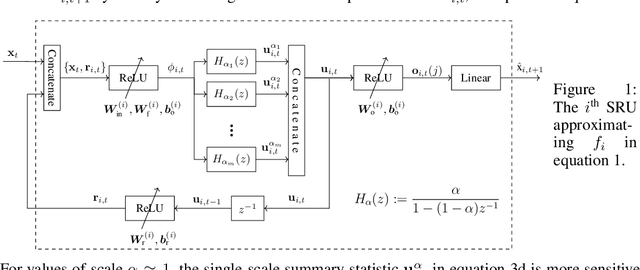

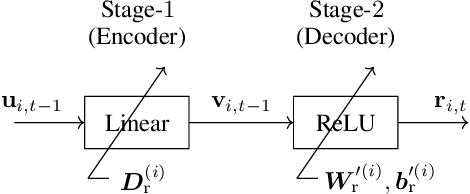
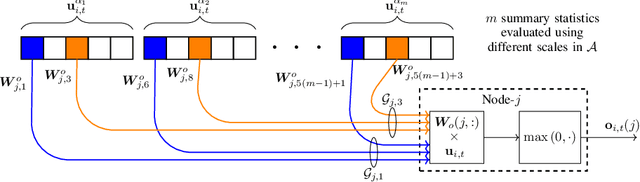
Granger causality is a widely-used criterion for analyzing interactions in large-scale networks. As most physical interactions are inherently nonlinear, we consider the problem of inferring the existence of pairwise Granger causality between nonlinearly interacting stochastic processes from their time series measurements. Our proposed approach relies on modeling the embedded nonlinearities in the measurements using a component-wise time series prediction model based on Statistical Recurrent Units (SRUs). We make a case that the network topology of Granger causal relations is directly inferrable from a structured sparse estimate of the internal parameters of the SRU networks trained to predict the processes$'$ time series measurements. We propose a variant of SRU, called economy-SRU, which, by design has considerably fewer trainable parameters, and therefore less prone to overfitting. The economy-SRU computes a low-dimensional sketch of its high-dimensional hidden state in the form of random projections to generate the feedback for its recurrent processing. Additionally, the internal weight parameters of the economy-SRU are strategically regularized in a group-wise manner to facilitate the proposed network in extracting meaningful predictive features that are highly time-localized to mimic real-world causal events. Extensive experiments are carried out to demonstrate that the proposed economy-SRU based time series prediction model outperforms the MLP, LSTM and attention-gated CNN-based time series models considered previously for inferring Granger causality.