 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Deep Neural Network for SSVEP-based Brain Computer Interfaces
Nov 17, 2020
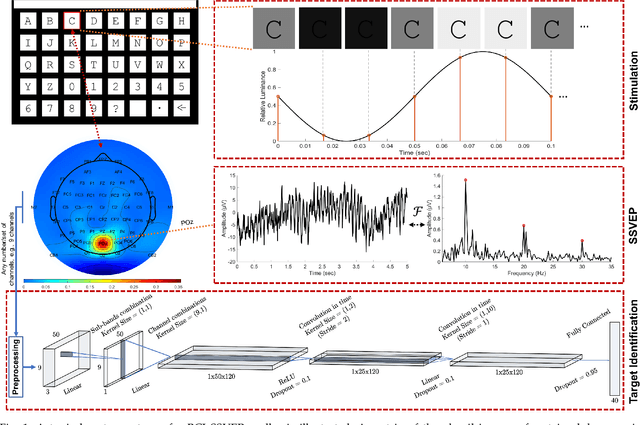
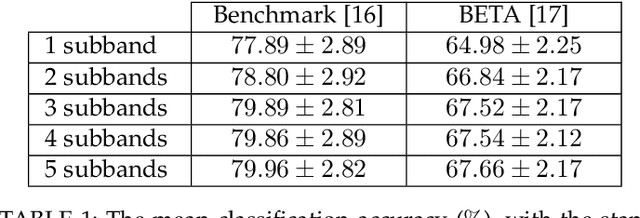

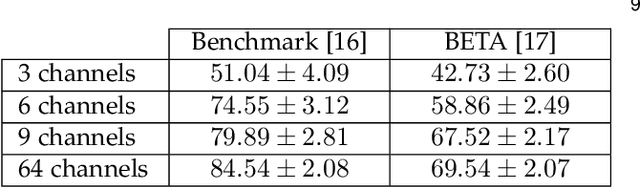
The target identification in brain-computer interface (BCI) speller systems refers to the multi-channel electroencephalogram (EEG) classification for predicting the target character that the user intends to spell. The EEG in such systems is known to include the steady-state visually evoked potentials (SSVEP) signal, which is the brain response when the user concentrates on the target while being visually presented a matrix of certain alphanumeric each of which flickers at a unique frequency. The SSVEP in this setting is characteristically dominated at varying degrees by the harmonics of the stimulation frequency; hence, a pattern analysis of the SSVEP can solve for the mentioned multi-class classification problem. To this end, we propose a novel deep neural network (DNN) architecture for the target identification in BCI SSVEP spellers. The proposed DNN is an end-to-end system: it receives the multi-channel SSVEP signal, proceeds with convolutions across the sub-bands of the harmonics, channels and time, and classifies at the fully connected layer. Our experiments are on two publicly available (the benchmark and the BETA) datasets consisting of in total 105 subjects with 40 characters. We train in two stages. The first stage obtains a global perspective into the whole SSVEP data by exploiting the commonalities, and transfers the global model to the second stage that fine tunes it down to each subject separately by exploiting the individual statistics. In our extensive comparisons, our DNN is demonstrated to significantly outperform the state-of-the-art on the both two datasets, by achieving the information transfer rates (ITR) 265.23 bits/min and 196.59 bits/min, respectively. To the best of our knowledge, our ITRs are the highest ever reported performance results on these datasets. The code, and the proposed DNN model are available at https://github.com/osmanberke/Deep-SSVEP-BCI.
The bi-objective multimodal car-sharing problem
Oct 18, 2020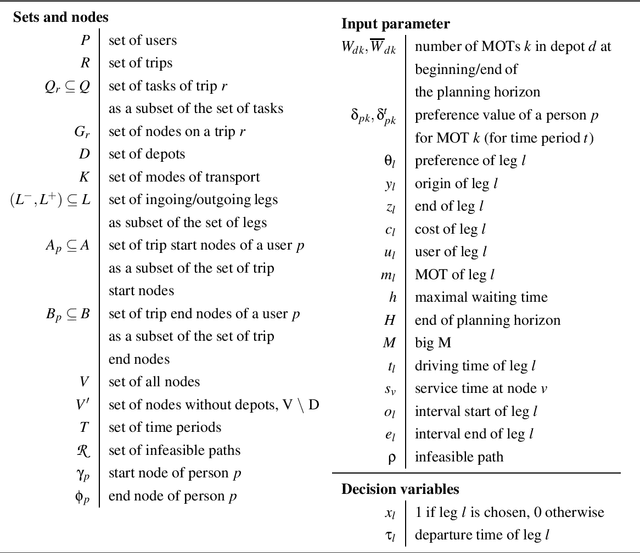
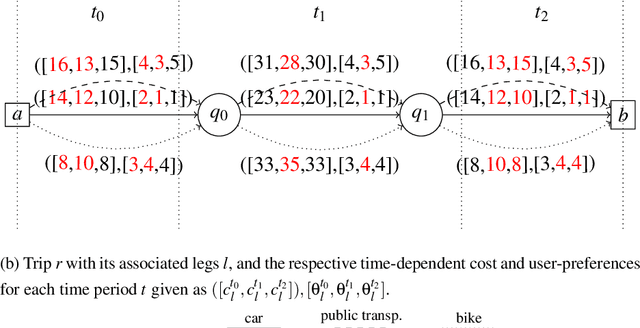
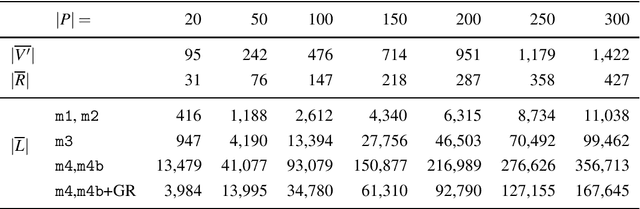
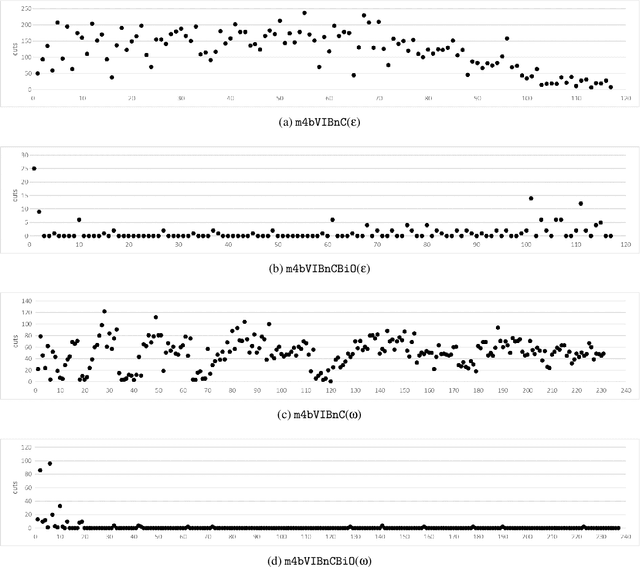
The aim of the bi-objective multimodal car-sharing problem (BiO-MMCP) is to determine the optimal mode of transport assignment for trips and to schedule the routes of available cars and users whilst minimizing cost and maximizing user satisfaction. We investigate the BiO-MMCP from a user-centred point of view. As user satisfaction is a crucial aspect in shared mobility systems, we consider user preferences in a second objective. Users may choose and rank their preferred modes of transport for different times of the day. In this way we account for, e.g., different traffic conditions throughout the planning horizon. We study different variants of the problem. In the base problem, the sequence of tasks a user has to fulfill is fixed in advance and travel times as well as preferences are constant over the planning horizon. In variant 2, time-dependent travel times and preferences are introduced. In variant 3, we examine the challenges when allowing additional routing decisions. Variant 4 integrates variants 2 and 3. For this last variant, we develop a branch-and-cut algorithm which is embedded in two bi-objective frameworks, namely the $\epsilon$-constraint method and a weighting binary search method. Computational experiments show that the branch-and cut algorithm outperforms the MIP formulation and we discuss changing solutions along the Pareto frontier.
Active learning with RESSPECT: Resource allocation for extragalactic astronomical transients
Oct 26, 2020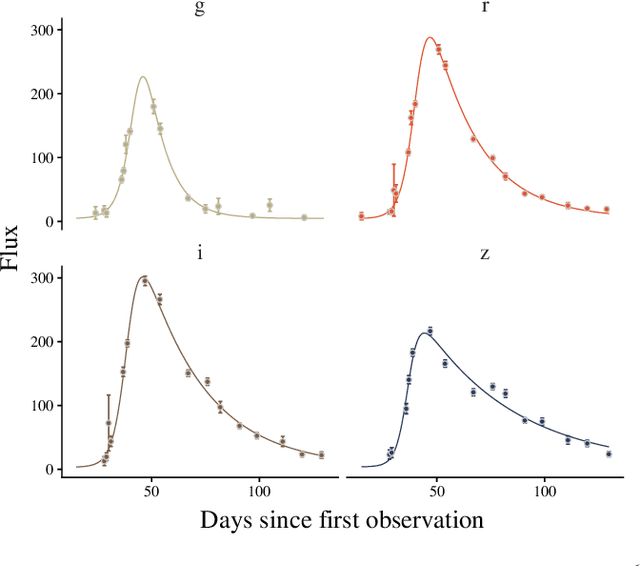
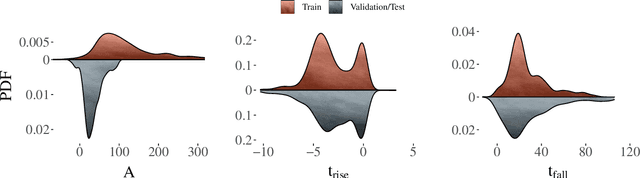
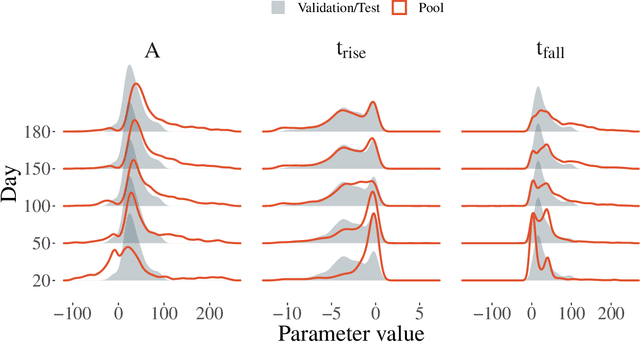
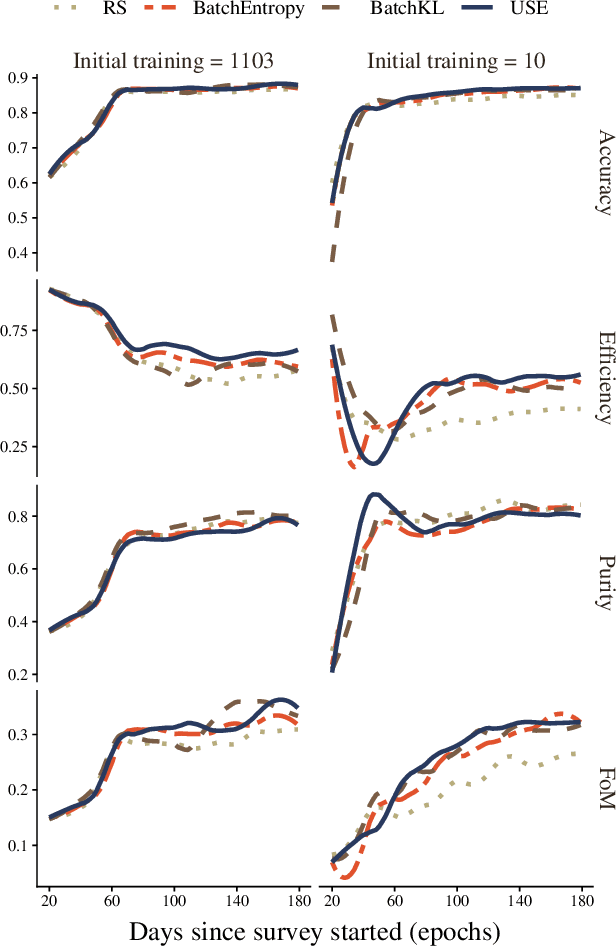
The recent increase in volume and complexity of available astronomical data has led to a wide use of supervised machine learning techniques. Active learning strategies have been proposed as an alternative to optimize the distribution of scarce labeling resources. However, due to the specific conditions in which labels can be acquired, fundamental assumptions, such as sample representativeness and labeling cost stability cannot be fulfilled. The Recommendation System for Spectroscopic follow-up (RESSPECT) project aims to enable the construction of optimized training samples for the Rubin Observatory Legacy Survey of Space and Time (LSST), taking into account a realistic description of the astronomical data environment. In this work, we test the robustness of active learning techniques in a realistic simulated astronomical data scenario. Our experiment takes into account the evolution of training and pool samples, different costs per object, and two different sources of budget. Results show that traditional active learning strategies significantly outperform random sampling. Nevertheless, more complex batch strategies are not able to significantly overcome simple uncertainty sampling techniques. Our findings illustrate three important points: 1) active learning strategies are a powerful tool to optimize the label-acquisition task in astronomy, 2) for upcoming large surveys like LSST, such techniques allow us to tailor the construction of the training sample for the first day of the survey, and 3) the peculiar data environment related to the detection of astronomical transients is a fertile ground that calls for the development of tailored machine learning algorithms.
Decision and Feature Level Fusion of Deep Features Extracted from Public COVID-19 Data-sets
Nov 17, 2020
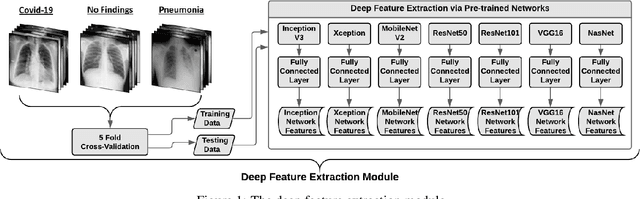
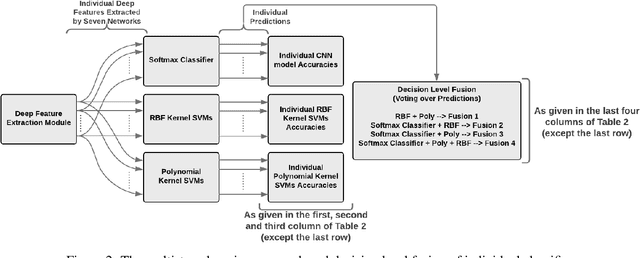
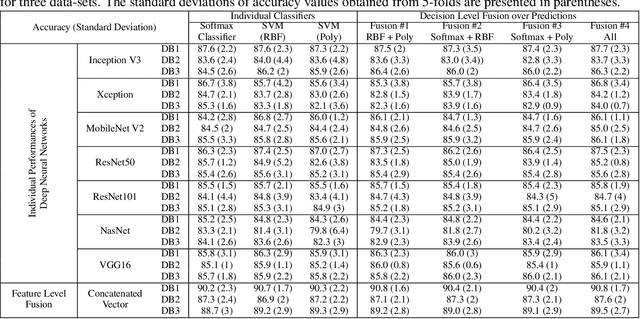
The Coronavirus (COVID-19), which is an infectious pulmonary disorder, has affected millions of people and has been declared as a global pandemic by the WHO. Due to highly contagious nature of COVID-19 and its high possibility of causing severe conditions in the patients, the development of rapid and accurate diagnostic tools have gained importance. The real-time reverse transcription-polymerize chain reaction (RT-PCR) is used to detect the presence of Coronavirus RNA by using the mucus and saliva mixture samples. But, RT-PCR suffers from having low-sensitivity especially in the early stage. Therefore, the usage of chest radiography has been increasing in the early diagnosis of COVID-19 due to its fast imaging speed, significantly low cost and low dosage exposure of radiation. In our study, a computer-aided diagnosis system for X-ray images based on convolutional neural networks (CNNs), which can be used by radiologists as a supporting tool in COVID-19 detection, has been proposed. Deep feature sets extracted by using CNNs were concatenated for feature level fusion and fed to multiple classifiers in terms of decision level fusion idea with the aim of discriminating COVID-19, pneumonia and no-finding classes. In the decision level fusion idea, a majority voting scheme was applied to the resultant decisions of classifiers. The obtained accuracy values and confusion matrix based evaluation criteria were presented for three progressively created data-sets. The aspects of the proposed method that are superior to existing COVID-19 detection studies have been discussed and the fusion performance of proposed approach was validated visually by using Class Activation Mapping technique. The experimental results show that the proposed approach has attained high COVID-19 detection performance that was proven by its comparable accuracy and superior precision/recall values with the existing studies.
EEG to fMRI Synthesis: Is Deep Learning a candidate?
Sep 29, 2020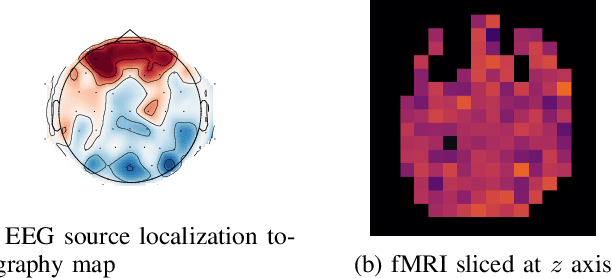
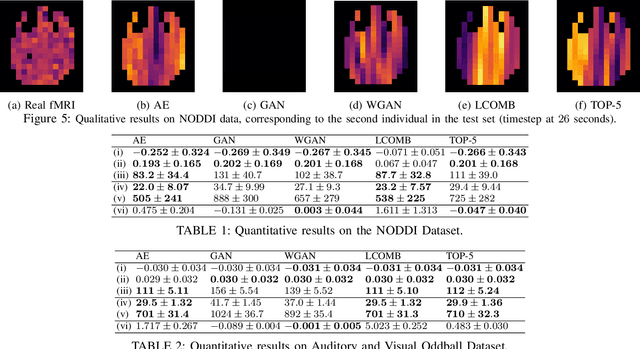
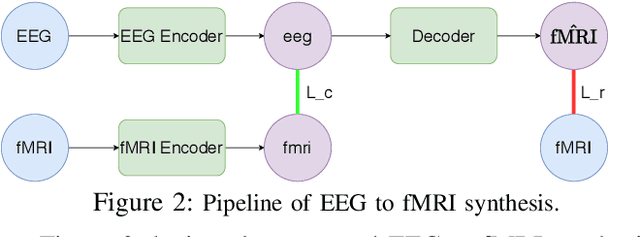
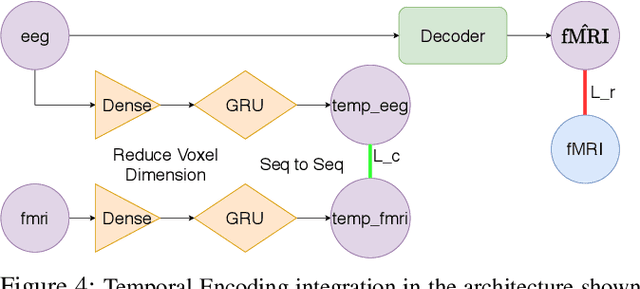
Advances on signal, image and video generation underly major breakthroughs on generative medical imaging tasks, including Brain Image Synthesis. Still, the extent to which functional Magnetic Ressonance Imaging (fMRI) can be mapped from the brain electrophysiology remains largely unexplored. This work provides the first comprehensive view on how to use state-of-the-art principles from Neural Processing to synthesize fMRI data from electroencephalographic (EEG) data. Given the distinct spatiotemporal nature of haemodynamic and electrophysiological signals, this problem is formulated as the task of learning a mapping function between multivariate time series with highly dissimilar structures. A comparison of state-of-the-art synthesis approaches, including Autoencoders, Generative Adversarial Networks and Pairwise Learning, is undertaken. Results highlight the feasibility of EEG to fMRI brain image mappings, pinpointing the role of current advances in Machine Learning and showing the relevance of upcoming contributions to further improve performance. EEG to fMRI synthesis offers a way to enhance and augment brain image data, and guarantee access to more affordable, portable and long-lasting protocols of brain activity monitoring. The code used in this manuscript is available in Github and the datasets are open source.
Learning to Optimise General TSP Instances
Nov 03, 2020
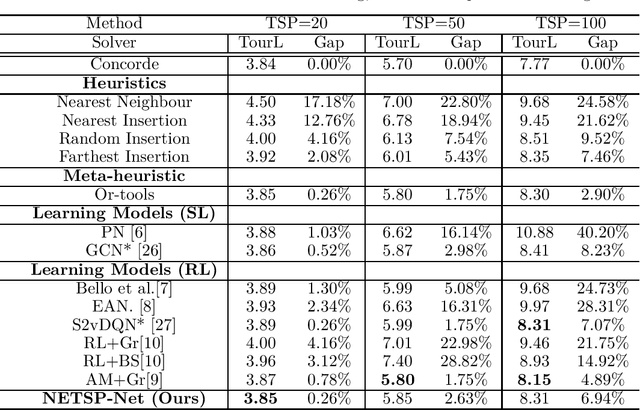
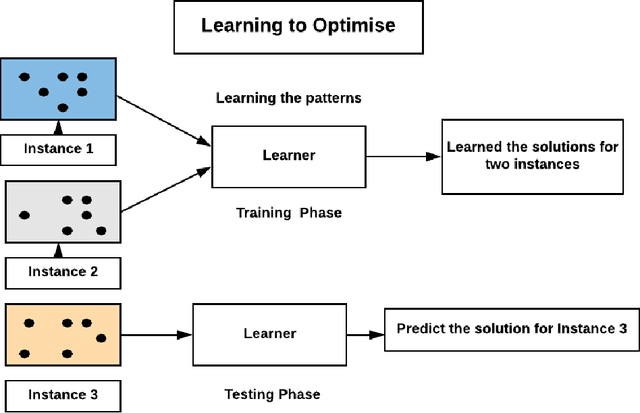
The Travelling Salesman Problem (TSP) is a classical combinatorial optimisation problem. Deep learning has been successfully extended to meta-learning, where previous solving efforts assist in learning how to optimise future optimisation instances. In recent years, learning to optimise approaches have shown success in solving TSP problems. However, they focus on one type of TSP problem, namely ones where the points are uniformly distributed in Euclidean spaces and have issues in generalising to other embedding spaces, e.g., spherical distance spaces, and to TSP instances where the points are distributed in a non-uniform manner. An aim of learning to optimise is to train once and solve across a broad spectrum of (TSP) problems. Although supervised learning approaches have shown to achieve more optimal solutions than unsupervised approaches, they do require the generation of training data and running a solver to obtain solutions to learn from, which can be time-consuming and difficult to find reasonable solutions for harder TSP instances. Hence this paper introduces a new learning-based approach to solve a variety of different and common TSP problems that are trained on easier instances which are faster to train and are easier to obtain better solutions. We name this approach the non-Euclidean TSP network (NETSP-Net). The approach is evaluated on various TSP instances using the benchmark TSPLIB dataset and popular instance generator used in the literature. We performed extensive experiments that indicate our approach generalises across many types of instances and scales to instances that are larger than what was used during training.
Enhanced detection of fetal pose in 3D MRI by Deep Reinforcement Learning with physical structure priors on anatomy
Jul 16, 2020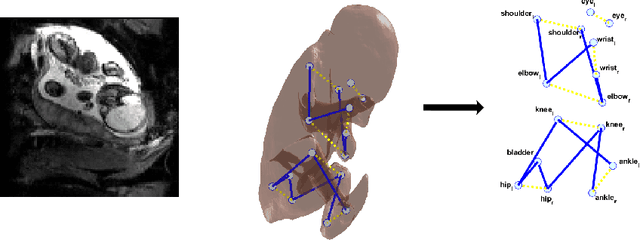
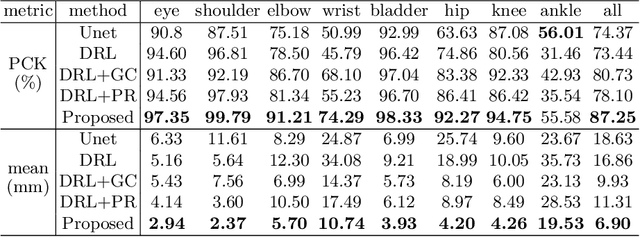
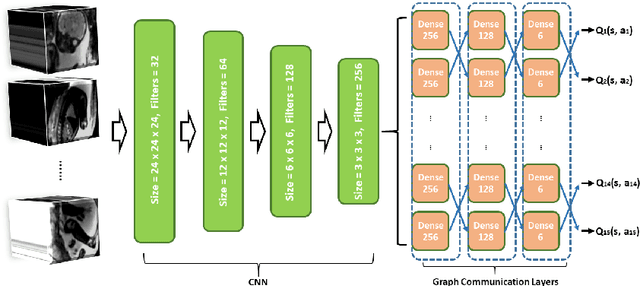
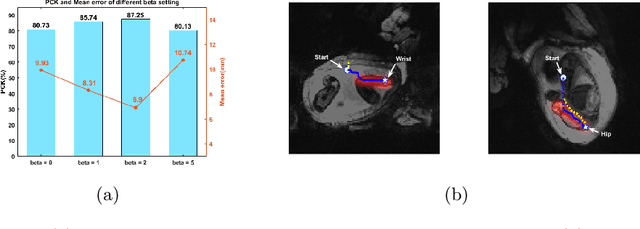
Fetal MRI is heavily constrained by unpredictable and substantial fetal motion that causes image artifacts and limits the set of viable diagnostic image contrasts. Current mitigation of motion artifacts is predominantly performed by fast, single-shot MRI and retrospective motion correction. Estimation of fetal pose in real time during MRI stands to benefit prospective methods to detect and mitigate fetal motion artifacts where inferred fetal motion is combined with online slice prescription with low-latency decision making. Current developments of deep reinforcement learning (DRL), offer a novel approach for fetal landmarks detection. In this task 15 agents are deployed to detect 15 landmarks simultaneously by DRL. The optimization is challenging, and here we propose an improved DRL that incorporates priors on physical structure of the fetal body. First, we use graph communication layers to improve the communication among agents based on a graph where each node represents a fetal-body landmark. Further, additional reward based on the distance between agents and physical structures such as the fetal limbs is used to fully exploit physical structure. Evaluation of this method on a repository of 3-mm resolution in vivo data demonstrates a mean accuracy of landmark estimation within 10 mm of ground truth as 87.3%, and a mean error of 6.9 mm. The proposed DRL for fetal pose landmark search demonstrates a potential clinical utility for online detection of fetal motion that guides real-time mitigation of motion artifacts as well as health diagnosis during MRI of the pregnant mother.
Face Mask Assistant: Detection of Face Mask Service Stage Based on Mobile Phone
Oct 09, 2020



Coronavirus Disease 2019 (COVID-19) has spread all over the world since it broke out massively in December 2019, which has caused a large loss to the whole world. Both the confirmed cases and death cases have reached a relatively frightening number. Syndrome coronaviruses 2 (SARS-CoV-2), the cause of COVID-19, can be transmitted by small respiratory droplets. To curb its spread at the source, wearing masks is a convenient and effective measure. In most cases, people use face masks in a high-frequent but short-time way. Aimed at solving the problem that we don't know which service stage of the mask belongs to, we propose a detection system based on the mobile phone. We first extract four features from the GLCMs of the face mask's micro-photos. Next, a three-result detection system is accomplished by using KNN algorithm. The results of validation experiments show that our system can reach a precision of 82.87% (standard deviation=8.5%) on the testing dataset. In future work, we plan to expand the detection objects to more mask types. This work demonstrates that the proposed mobile microscope system can be used as an assistant for face mask being used, which may play a positive role in fighting against COVID-19.
Animated Cassie: A Dynamic Relatable Robotic Character
Sep 07, 2020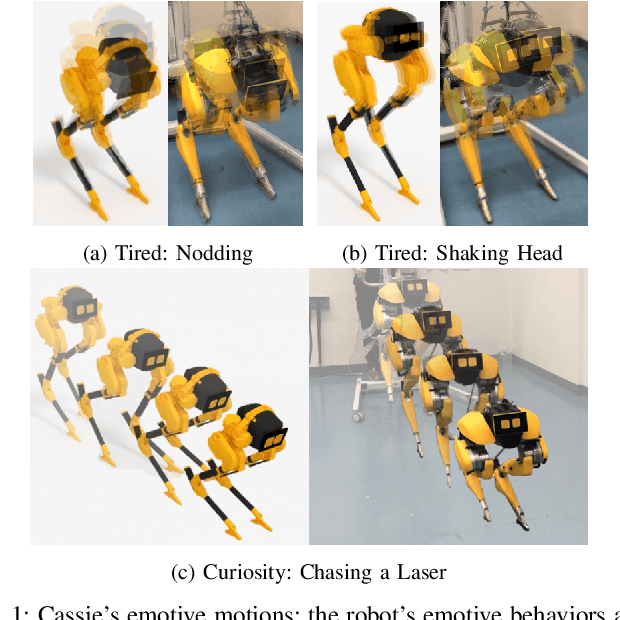
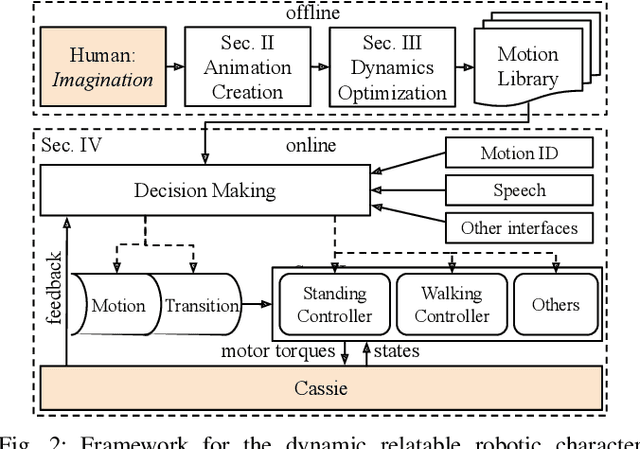
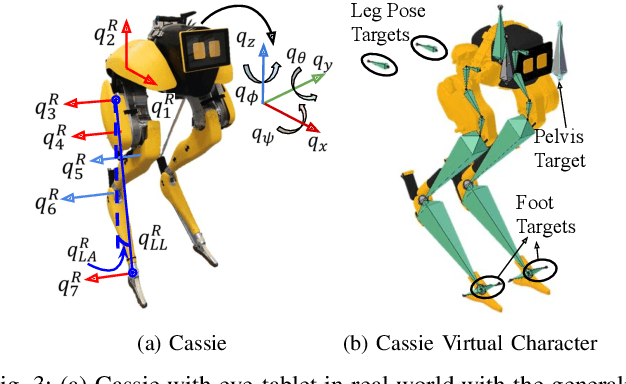
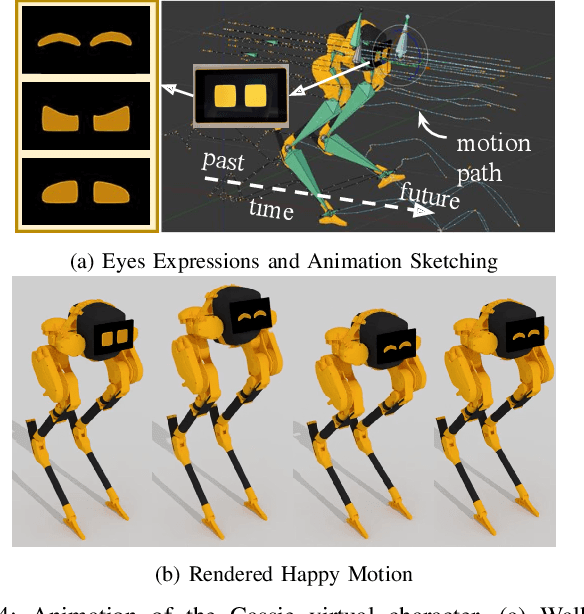
Creating robots with emotional personalities will transform the usability of robots in the real world. As previous emotive social robots are mostly based on statically stable robots whose mobility is limited, this paper develops an animation to real world pipeline that enables dynamic bipedal robots that can twist, wiggle, and walk to behave with emotions. First, an animation method is introduced to design emotive motions for the virtual robot character. Second, a dynamics optimizer is used to convert the animated motion to dynamically feasible motion. Third, real time standing and walking controllers and an automaton are developed to bring the virtual character to life. This framework is deployed on a bipedal robot Cassie and validated in experiments. To the best of our knowledge, this paper is one of the first to present an animatronic dynamic legged robot that is able to perform motions with desired emotional attributes. We term robots that use dynamic motions to convey emotions as Dynamic Relatable Robotic Characters.
Distributed ADMM with Synergetic Communication and Computation
Sep 29, 2020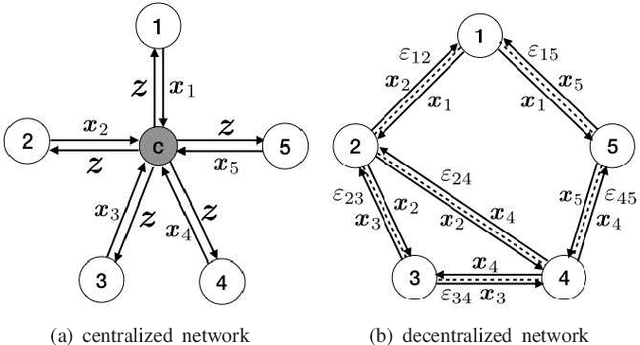
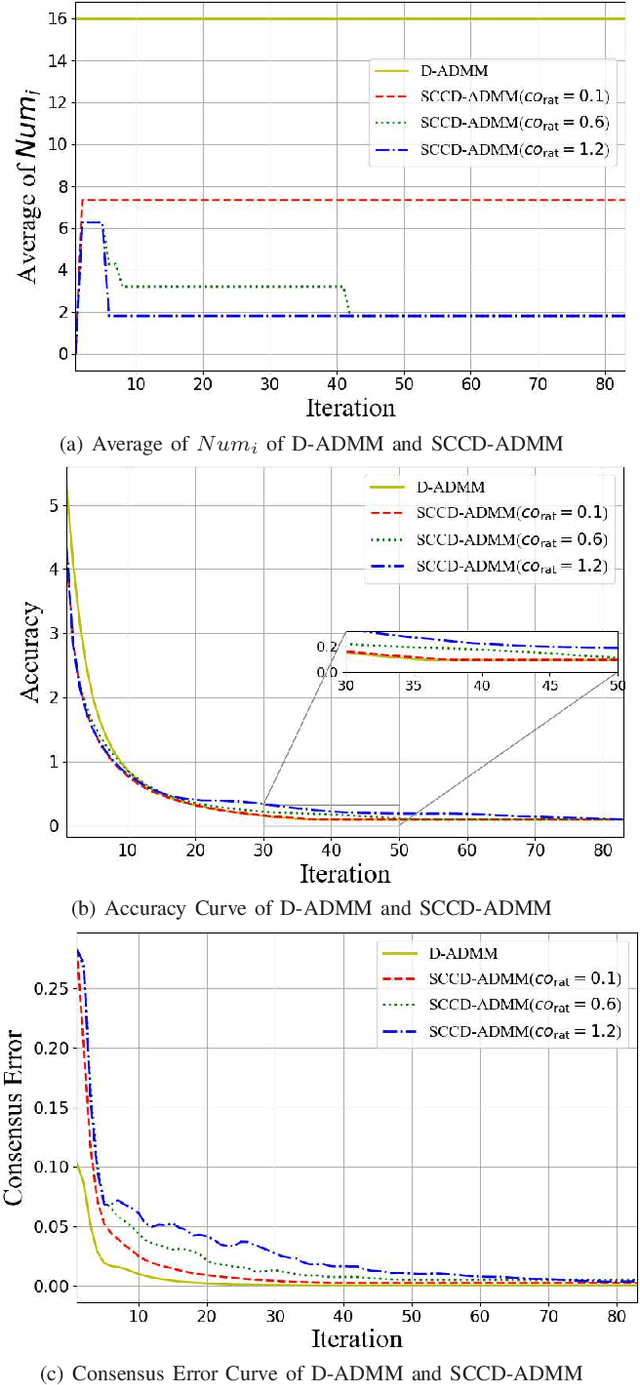
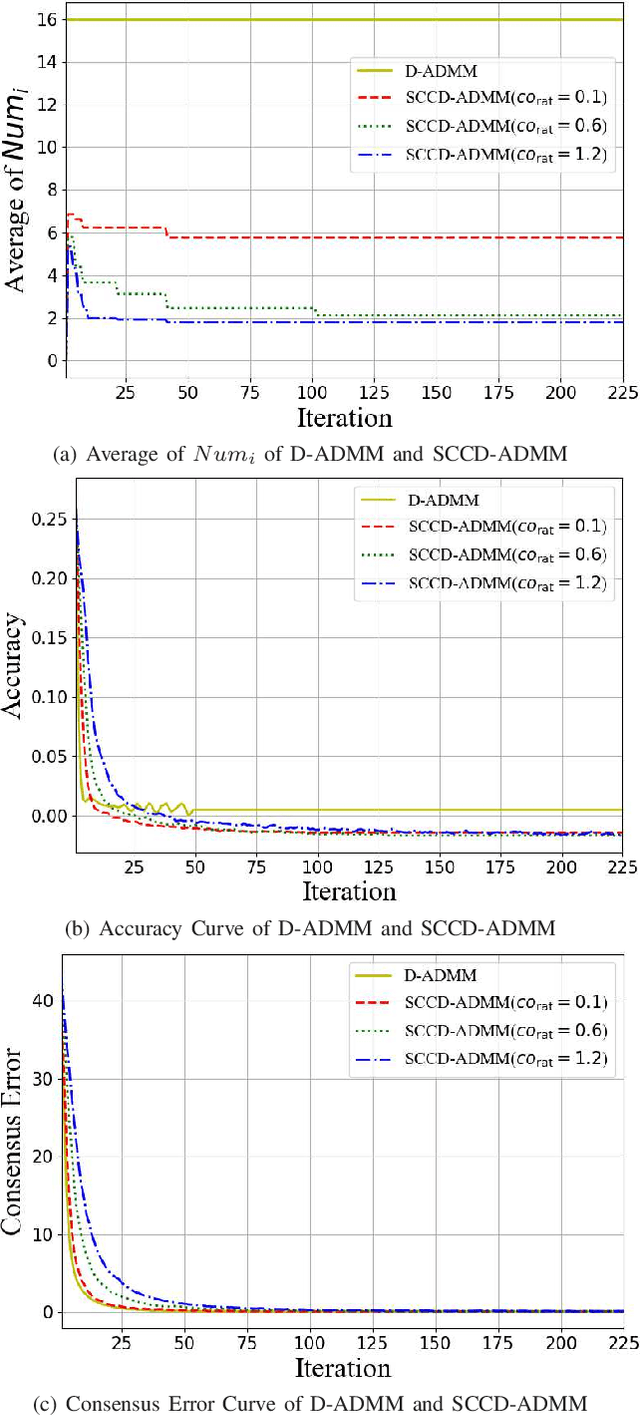
In this paper, we propose a novel distributed alternating direction method of multipliers (ADMM) algorithm with synergetic communication and computation, called SCCD-ADMM, to reduce the total communication and computation cost of the system. Explicitly, in the proposed algorithm, each node interacts with only part of its neighboring nodes, the number of which is progressively determined according to a heuristic searching procedure, which takes into account both the predicted convergence rate and the communication and computation costs at each iteration, resulting in a trade-off between communication and computation. Then the node chooses its neighboring nodes according to an importance sampling distribution derived theoretically to minimize the variance with the latest information it locally stores. Finally, the node updates its local information with a new update rule which adapts to the number of communication nodes. We prove the convergence of the proposed algorithm and provide an upper bound of the convergence variance brought by randomness. Extensive simulations validate the excellent performances of the proposed algorithm in terms of convergence rate and variance, the overall communication and computation cost, the impact of network topology as well as the time for evaluation, in comparison with the traditional counterparts.