 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Superiority of Simplicity: A Lightweight Model for Network Device Workload Prediction
Jul 07, 2020
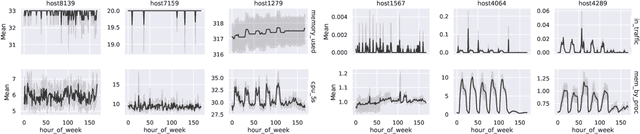
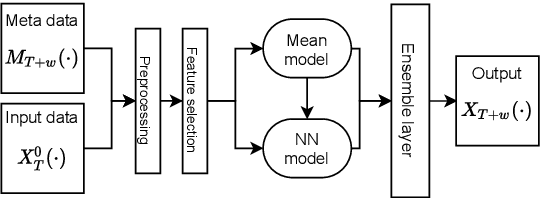
The rapid growth and distribution of IT systems increases their complexity and aggravates operation and maintenance. To sustain control over large sets of hosts and the connecting networks, monitoring solutions are employed and constantly enhanced. They collect diverse key performance indicators (KPIs) (e.g. CPU utilization, allocated memory, etc.) and provide detailed information about the system state. Storing such metrics over a period of time naturally raises the motivation of predicting future KPI progress based on past observations. Although, a variety of time series forecasting methods exist, forecasting the progress of IT system KPIs is very hard. First, KPI types like CPU utilization or allocated memory are very different and hard to be expressed by the same model. Second, system components are interconnected and constantly changing due to soft- or firmware updates and hardware modernization. Thus a frequent model retraining or fine-tuning must be expected. Therefore, we propose a lightweight solution for KPI series prediction based on historic observations. It consists of a weighted heterogeneous ensemble method composed of two models - a neural network and a mean predictor. As ensemble method a weighted summation is used, whereby a heuristic is employed to set the weights. The modelling approach is evaluated on the available FedCSIS 2020 challenge dataset and achieves an overall $R^2$ score of 0.10 on the preliminary 10% test data and 0.15 on the complete test data. We publish our code on the following github repository: https://github.com/citlab/fed_challenge
Online probabilistic label trees
Jul 08, 2020
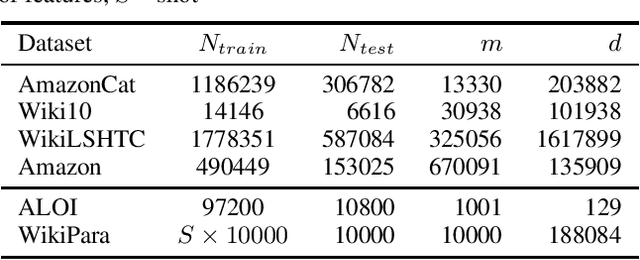
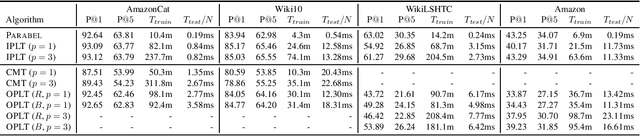
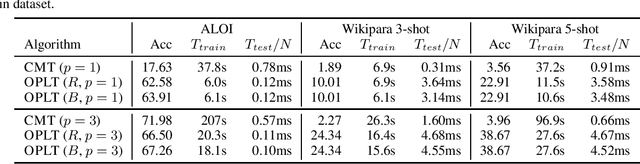
We introduce online probabilistic label trees (OPLTs), an algorithm that trains a label tree classifier in a fully online manner, without any prior knowledge about the number of training instances, their features and labels. OPLTs are characterized by low time and space complexity as well as strong theoretical guarantees. They can be used for online multi-label and multi-class classification, including the very challenging scenarios of one- or few-shot learning. We demonstrate the attractiveness of OPLTs in a wide empirical study on several instances of the tasks mentioned above.
Finding teams that balance expert load and task coverage
Nov 03, 2020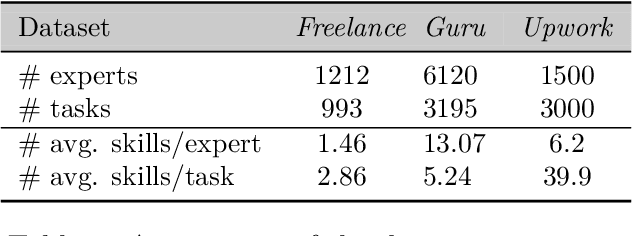
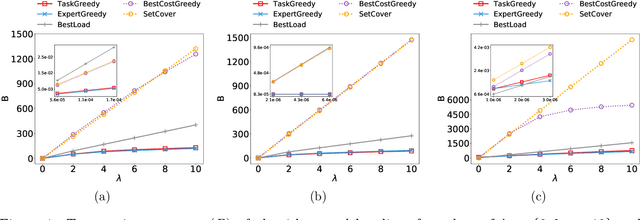
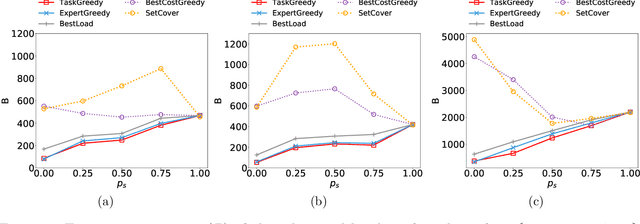
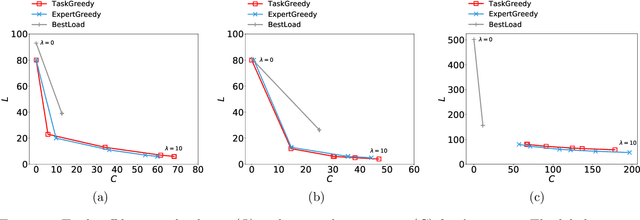
The rise of online labor markets (e.g., Freelancer, Guru and Upwork) has ignited a lot of research on team formation, where experts acquiring different skills form teams to complete tasks. The core idea in this line of work has been the strict requirement that the team of experts assigned to complete a given task should contain a superset of the skills required by the task. However, in many applications the required skills are often a wishlist of the entity that posts the task and not all of the skills are absolutely necessary. Thus, in our setting we relax the complete coverage requirement and we allow for tasks to be partially covered by the formed teams, assuming that the quality of task completion is proportional to the fraction of covered skills per task. At the same time, we assume that when multiple tasks need to be performed, the less the load of an expert the better the performance. We combine these two high-level objectives into one and define the BalancedTA problem. We also consider a generalization of this problem where each task consists of required and optional skills. In this setting, our objective is the same under the constraint that all required skills should be covered. From the technical point of view, we show that the BalancedTA problem (and its variant) is NP-hard and design efficient heuristics for solving it in practice. Using real datasets from three online market places, Freelancer, Guru and Upwork we demonstrate the efficiency of our methods and the practical utility of our framework.
Bunched LPCNet : Vocoder for Low-cost Neural Text-To-Speech Systems
Aug 11, 2020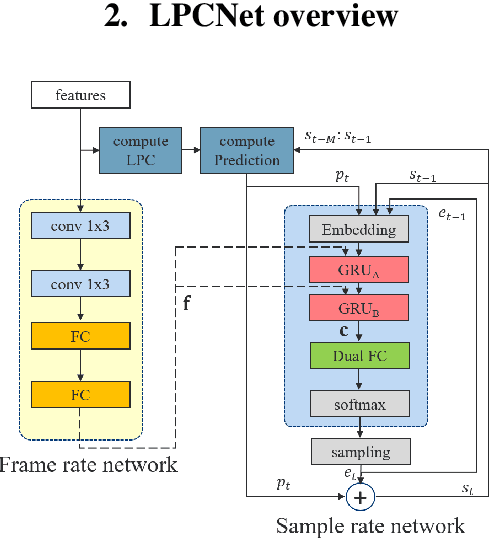
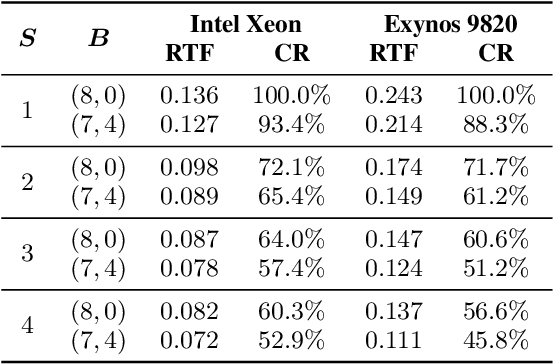
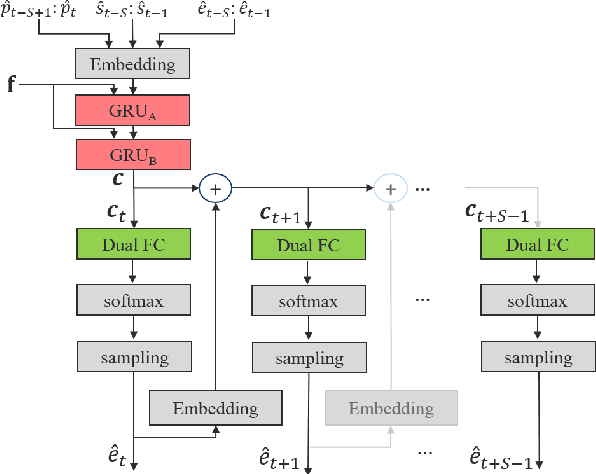
LPCNet is an efficient vocoder that combines linear prediction and deep neural network modules to keep the computational complexity low. In this work, we present two techniques to further reduce it's complexity, aiming for a low-cost LPCNet vocoder-based neural Text-to-Speech (TTS) System. These techniques are: 1) Sample-bunching, which allows LPCNet to generate more than one audio sample per inference; and 2) Bit-bunching, which reduces the computations in the final layer of LPCNet. With the proposed bunching techniques, LPCNet, in conjunction with a Deep Convolutional TTS (DCTTS) acoustic model, shows a 2.19x improvement over the baseline run-time when running on a mobile device, with a less than 0.1 decrease in TTS mean opinion score (MOS).
Hierarchical HMM for Eye Movement Classification
Aug 18, 2020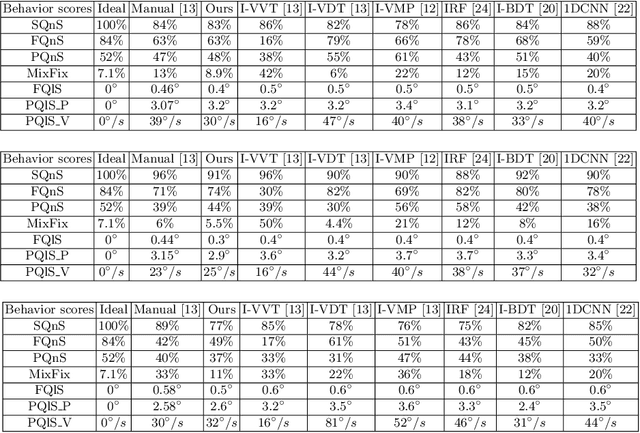
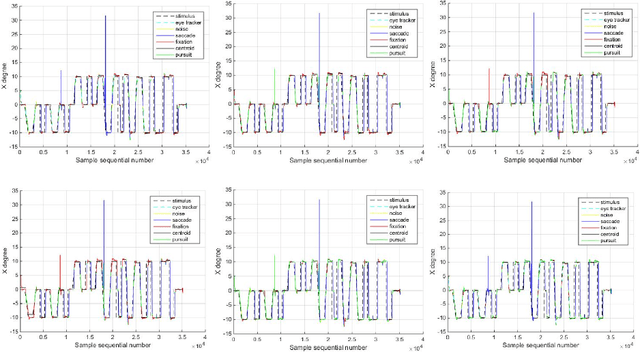
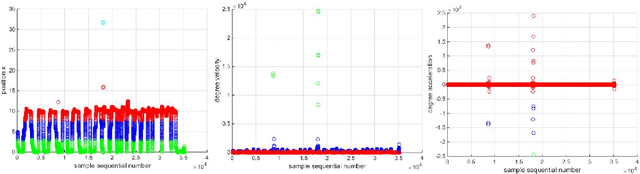
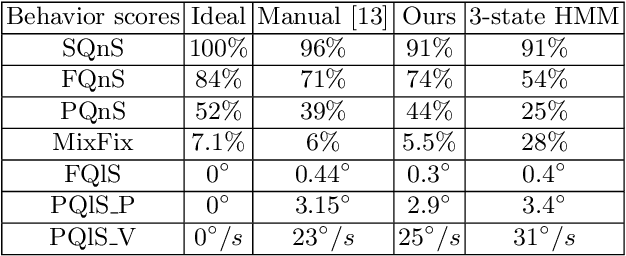
In this work, we tackle the problem of ternary eye movement classification, which aims to separate fixations, saccades and smooth pursuits from the raw eye positional data. The efficient classification of these different types of eye movements helps to better analyze and utilize the eye tracking data. Different from the existing methods that detect eye movement by several pre-defined threshold values, we propose a hierarchical Hidden Markov Model (HMM) statistical algorithm for detecting fixations, saccades and smooth pursuits. The proposed algorithm leverages different features from the recorded raw eye tracking data with a hierarchical classification strategy, separating one type of eye movement each time. Experimental results demonstrate the effectiveness and robustness of the proposed method by achieving competitive or better performance compared to the state-of-the-art methods.
Climbing down Charney's ladder: Machine Learning and the post-Dennard era of computational climate science
May 24, 2020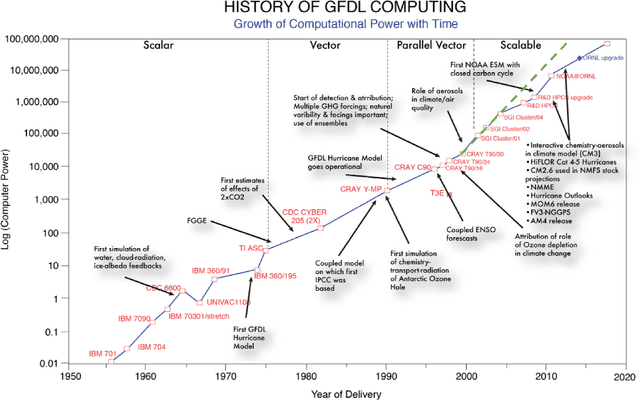
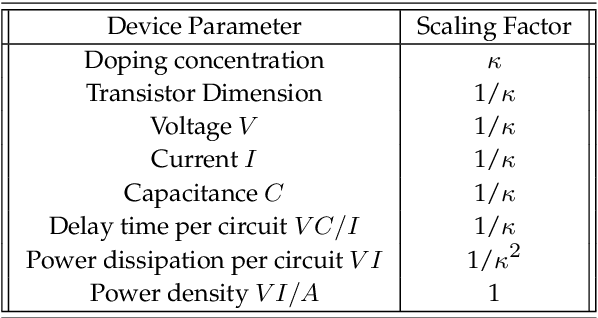

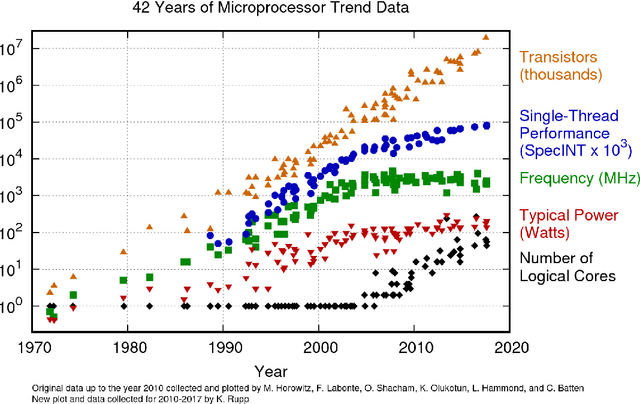
The advent of digital computing in the 1950s sparked a revolution in the science of weather and climate. Meteorology, long practised as an art based on extrapolating patterns in space and time, gave way to computational methods in a decade of advances in numerical weather forecasting. Those same methods also gave rise to computational climate science, studying the behaviour of those same numerical equations over very long time intervals, and changes in external boundary conditions. Several subsequent decades of exponential growth in computational power have brought us to the present day, where models ever grow in resolution and complexity, capable of mastery of many small-scale phenomena with global repercussions, and ever more intricate feedbacks in the Earth system. We have also come to understand the central role played by randomness in an underdetermined physical system. The current juncture in computing, seven decades later, heralds an end to ever smaller computational units and ever faster arithmetic, what is called Dennard scaling. This is prompting a fundamental change in our approach to the simulation of weather and climate, potentially as revolutionary as that wrought by John von Neumann in the 1950s. One approach could return us to an earlier era of pattern recognition and extrapolation, this time aided by computational power. Another approach could lead us to insights that continue to be expressed in mathematical equations. In either approach, or any synthesis of those, it is clearly no longer the steady march of the last few decades, continuing to add detail to ever more elaborate models. In this prospectus, we attempt to show the outlines how this may unfold in the coming decades, a new harnessing of physical knowledge, computation, and data.
A Deep Neural Network for SSVEP-based Brain Computer Interfaces
Nov 17, 2020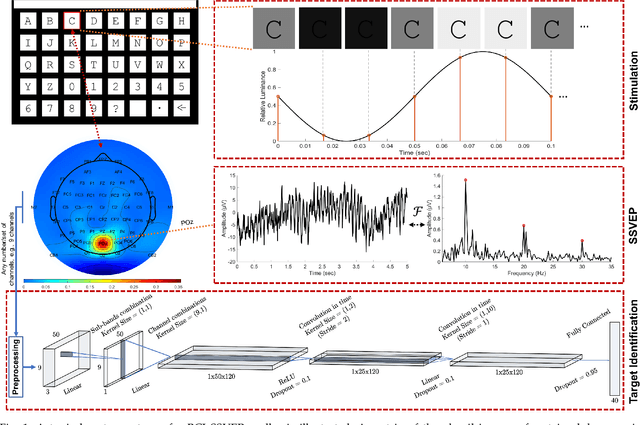
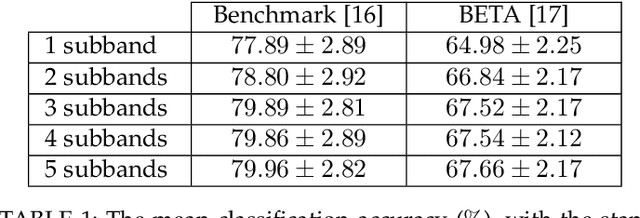

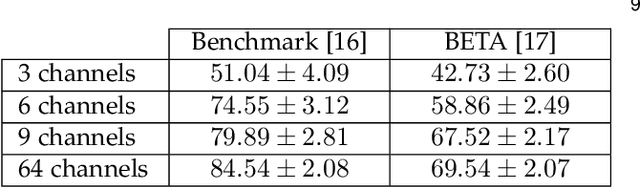
The target identification in brain-computer interface (BCI) speller systems refers to the multi-channel electroencephalogram (EEG) classification for predicting the target character that the user intends to spell. The EEG in such systems is known to include the steady-state visually evoked potentials (SSVEP) signal, which is the brain response when the user concentrates on the target while being visually presented a matrix of certain alphanumeric each of which flickers at a unique frequency. The SSVEP in this setting is characteristically dominated at varying degrees by the harmonics of the stimulation frequency; hence, a pattern analysis of the SSVEP can solve for the mentioned multi-class classification problem. To this end, we propose a novel deep neural network (DNN) architecture for the target identification in BCI SSVEP spellers. The proposed DNN is an end-to-end system: it receives the multi-channel SSVEP signal, proceeds with convolutions across the sub-bands of the harmonics, channels and time, and classifies at the fully connected layer. Our experiments are on two publicly available (the benchmark and the BETA) datasets consisting of in total 105 subjects with 40 characters. We train in two stages. The first stage obtains a global perspective into the whole SSVEP data by exploiting the commonalities, and transfers the global model to the second stage that fine tunes it down to each subject separately by exploiting the individual statistics. In our extensive comparisons, our DNN is demonstrated to significantly outperform the state-of-the-art on the both two datasets, by achieving the information transfer rates (ITR) 265.23 bits/min and 196.59 bits/min, respectively. To the best of our knowledge, our ITRs are the highest ever reported performance results on these datasets. The code, and the proposed DNN model are available at https://github.com/osmanberke/Deep-SSVEP-BCI.
Adaptive and Momentum Methods on Manifolds Through Trivializations
Oct 09, 2020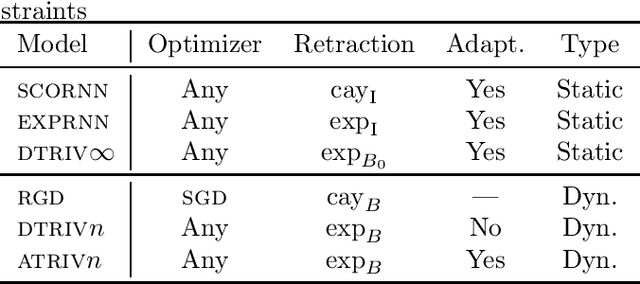
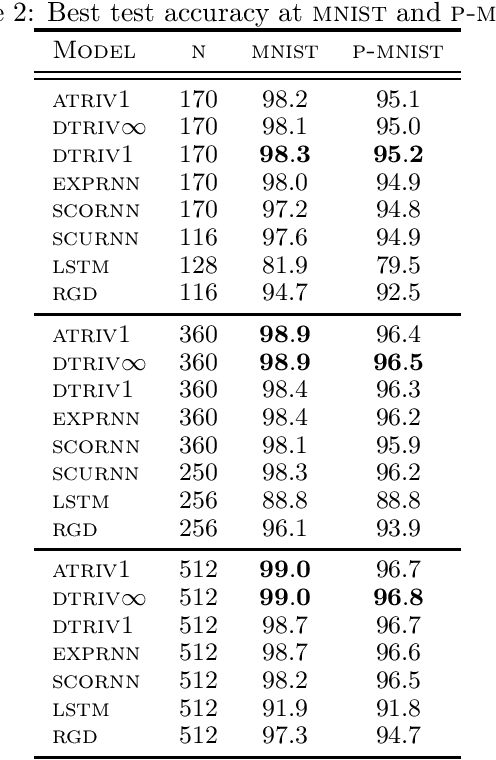
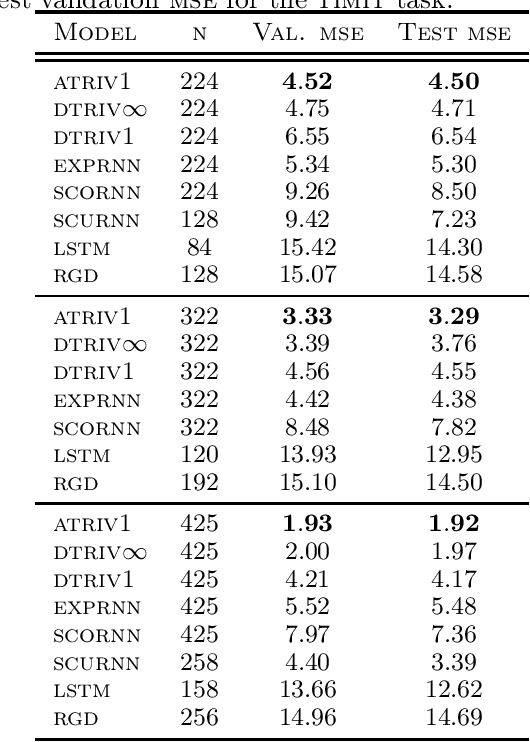

Adaptive methods do not have a direct generalization to manifolds as the adaptive term is not invariant. Momentum methods on manifolds suffer from efficiency problems stemming from the curvature of the manifold. We introduce a framework to generalize adaptive and momentum methods to arbitrary manifolds by noting that for every differentiable manifold, there exists a radially convex open set that covers almost all the manifold. Being radially convex, this set is diffeomorphic to $\mathbb{R}^n$. This gives a natural generalization of any adaptive and momentum-based algorithm to a set that covers almost all the manifold in an arbitrary manifolds. We also show how to extend these methods to the context of gradient descent methods with a retraction. For its implementation, we bring an approximation to the exponential of matrices that needs just of 5 matrix multiplications, making it particularly efficient on GPUs. In practice, we see that this family of algorithms closes the numerical gap created by an incorrect use of momentum and adaptive methods on manifolds. At the same time, we see that the most efficient algorithm of this family is given by simply pulling back the problem to the tangent space at the initial point via the exponential map.
Happy Are Those Who Grade without Seeing: A Multi-Task Learning Approach to Grade Essays Using Gaze Behaviour
May 25, 2020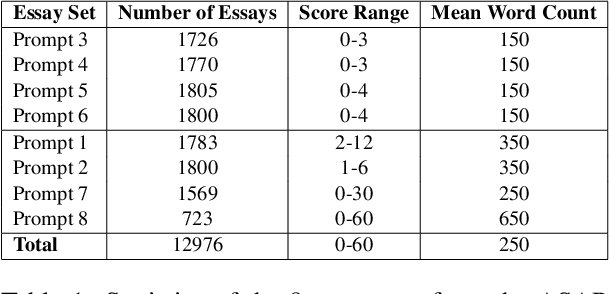
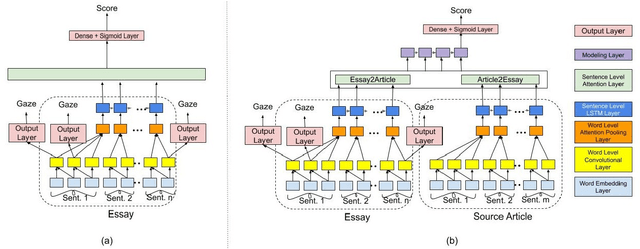
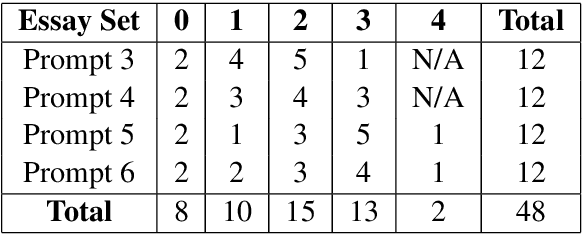

The gaze behaviour of a reader is helpful in solving several NLP tasks such as automatic essay grading, named entity recognition, sarcasm detection $\textit{etc.}$ However, collecting gaze behaviour from readers is costly in terms of time and money. In this paper, we propose a way to improve automatic essay grading using gaze behaviour, where the gaze features are learnt at run time using a multi-task learning framework. To demonstrate the efficacy of this multi-task learning based approach to automatic essay grading, we collect gaze behaviour for 48 essays across 4 essay sets, and learn gaze behaviour for the rest of the essays, numbering over 7000 essays. Using the learnt gaze behaviour, we can achieve a statistically significant improvement in performance over the state-of-the-art system for the essay sets where we have gaze data. We also achieve a statistically significant improvement for 4 other essay sets, numbering about 6000 essays, where we have no gaze behaviour data available. Our approach establishes that learning gaze behaviour improves automatic essay grading.
Towards Building a Real Time Mobile Device Bird Counting System Through Synthetic Data Training and Model Compression
Dec 28, 2019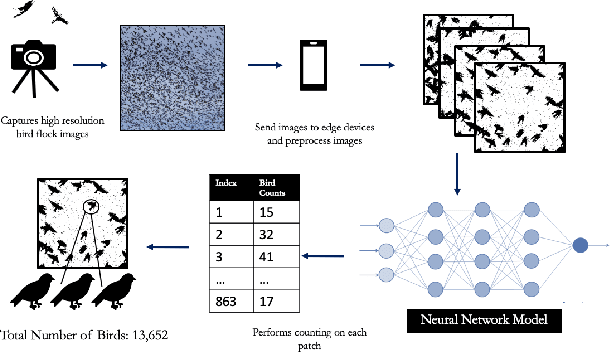

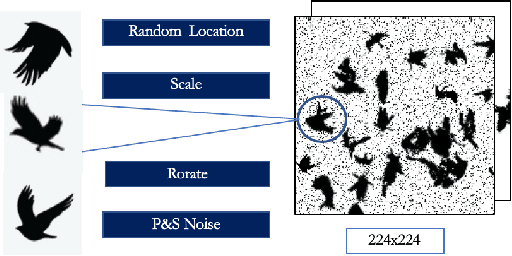
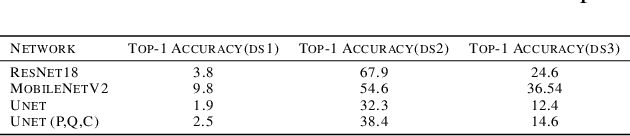
Counting the number of birds in an open sky setting has been an challenging problem due to the large number of bird flocks and the birds can overlap. Another difficulty is the lack of accurate training samples since the cost of labeling images of bird flocks can be extremely high and each sample picture can contain thousands of birds in a high resolution image. Inspired by recent work on training with synthetic data to perform crowd counting, we design a mechanism to generate synthetic bird dataset with precise bird count and the corresponding density maps. We then train a Unet model on the synthetic dataset to perform density map estimation that produces the count for each input. Our method is able to achieve MSE of approximately 12.4 on real dataset. In order to build a scalable system for fast bird counting under storage and computational constraints, we use model compression techniques and efficient model structures to increase the inference speed and save storage cost. We are able to reduce storage cost from 55MB to less than 5MB for the model with minimum loss of accuracy. This paper describes the pipelines of building an efficient bird counting system.